Einleitung
Dieser Leitfaden ist der erste Teil von drei Leitfäden zu Support Vector Machines (SVMs). In dieser Serie werden wir an einem Anwendungsfall für gefälschte Banknoten arbeiten, etwas über die einfache SVM lernen, dann über SVM-Hyperparameter und schließlich ein Konzept namens the Kernel-Trick und erkunden Sie andere Arten von SVMs.
Wenn Sie alle Leitfäden lesen oder sehen möchten, welche Sie am meisten interessieren, finden Sie unten eine Tabelle mit Themen, die in den einzelnen Leitfäden behandelt werden:
1. Implementieren von SVM und Kernel-SVM mit Scikit-Learn von Python
- Anwendungsfall: Banknoten vergessen
- Hintergrund von SVMs
- Einfaches (lineares) SVM-Modell
- Über den Datensatz
- Importieren des Datensatzes
- Exploring das Dataset
- Implementieren von SVM mit Scikit-Learn
- Aufteilen von Daten in Trainings-/Testsätze
- Das Modell trainieren
- Vorhersagen treffen
- Bewertung des Modells
- Ergebnisse interpretieren
2. SVM-Hyperparameter verstehen (kommt bald!)
- Der C-Hyperparameter
- Der Gamma-Hyperparameter
3. Implementieren anderer SVM-Varianten mit Scikit-Learn von Python (kommt bald!)
- Die allgemeine Idee von SVMs (eine Zusammenfassung)
- Kernel (Trick) SVM
- Implementieren von nichtlinearer Kernel-SVM mit Scikit-Learn
- Bibliotheken importieren
- Importieren des Datensatzes
- Aufteilen von Daten in Merkmale (X) und Ziel (y)
- Aufteilen von Daten in Trainings-/Testsätze
- Training des Algorithmus
- Polynomialer Kern
- Vorhersagen treffen
- Bewertung des Algorithmus
- Gaußscher Kernel
- Vorhersage und Bewertung
- Sigmoider Kernel
- Vorhersage und Bewertung
- Vergleich der nichtlinearen Kernelleistungen
Anwendungsfall: Gefälschte Banknoten
Manchmal finden Leute einen Weg, Banknoten zu fälschen. Wenn sich jemand diese Notizen ansieht und ihre Gültigkeit überprüft, kann es schwierig sein, sich von ihnen täuschen zu lassen.
Aber was passiert, wenn es keine Person gibt, die sich jede Notiz ansieht? Gibt es eine Möglichkeit, automatisch zu erkennen, ob Banknoten gefälscht oder echt sind?
Es gibt viele Möglichkeiten, diese Fragen zu beantworten. Eine Antwort besteht darin, jede empfangene Notiz zu fotografieren, ihr Bild mit dem Bild einer gefälschten Notiz zu vergleichen und sie dann als echt oder gefälscht zu klassifizieren. Wenn es mühsam oder kritisch sein könnte, auf die Validierung der Notiz zu warten, wäre es auch interessant, diesen Vergleich schnell durchzuführen.
Da Bilder verwendet werden, können sie komprimiert, auf Graustufen reduziert und ihre Messungen extrahiert oder quantisiert werden. Auf diese Weise würde der Vergleich zwischen Bildmessungen statt der Pixel jedes Bildes erfolgen.
Bisher haben wir einen Weg gefunden, Banknoten zu verarbeiten und zu vergleichen, aber wie werden sie in echt oder gefälscht klassifiziert? Wir können maschinelles Lernen verwenden, um diese Klassifizierung vorzunehmen. Es gibt einen Klassifizierungsalgorithmus namens Unterstützung Vektor Maschine, hauptsächlich bekannt durch seine abgekürzte Form: SVM.
Hintergrund von SVMs
SVMs wurden ursprünglich 1968 von Vladmir Vapnik und Alexey Chervonenkis eingeführt. Damals beschränkte sich ihr Algorithmus auf die Klassifizierung von Daten, die mit nur einer geraden Linie getrennt werden konnten, oder Daten, die es waren linear trennbar. Wir können sehen, wie diese Trennung aussehen würde:

Im obigen Bild haben wir eine Linie in der Mitte, von der sich einige Punkte links und andere rechts von dieser Linie befinden. Beachten Sie, dass beide Punktgruppen perfekt getrennt sind, es gibt keine Punkte zwischen oder auch nur in der Nähe der Linie. Es scheint einen Rand zwischen ähnlichen Punkten und der Linie zu geben, die sie trennt, dieser Rand wird genannt Trenngrenze. Die Funktion des Trennrands besteht darin, den Abstand zwischen ähnlichen Punkten und der sie trennenden Linie zu vergrößern. SVM tut dies, indem es einige Punkte verwendet und seine senkrechten Vektoren berechnet, um die Entscheidung für den Rand der Linie zu unterstützen. Das sind die Stützvektoren die Teil des Namens des Algorithmus sind. Wir werden später mehr über sie erfahren. Und die gerade Linie, die wir in der Mitte sehen, wird durch Methoden gefunden, die maximieren der Abstand zwischen der Linie und den Punkten oder die den Trennrand maximieren. Diese Methoden stammen aus dem Bereich der Optimierungstheorie.
In dem Beispiel, das wir gerade gesehen haben, können beide Punktgruppen leicht getrennt werden, da jeder einzelne Punkt nahe bei seinen ähnlichen Punkten liegt und die beiden Gruppen weit voneinander entfernt sind.
Aber was passiert, wenn es keine Möglichkeit gibt, die Daten mit einer geraden Linie zu trennen? Wenn es unordentliche Punkte gibt oder wenn eine Kurve benötigt wird?
Um dieses Problem zu lösen, wurde SVM später in den 1990er Jahren verfeinert, um auch Daten klassifizieren zu können, die Punkte hatten, die weit von ihrer zentralen Tendenz entfernt waren, wie z. B. Ausreißer, oder komplexere Probleme, die mehr als zwei Dimensionen hatten und nicht linear trennbar waren .
Merkwürdig ist, dass sich SVMs erst in den letzten Jahren weit verbreitet haben, hauptsächlich aufgrund ihrer Fähigkeit, manchmal mehr als 90 % der richtigen Antworten zu erreichen oder Genauigkeit, für schwierige Probleme.
SVMs werden im Vergleich zu anderen maschinellen Lernalgorithmen auf einzigartige Weise implementiert, da sie auf statistischen Erklärungen darüber basieren, was Lernen ist oder worauf Statistische Lerntheorie.
In diesem Artikel sehen wir, was Support Vector Machines-Algorithmen sind, die kurze Theorie hinter einer Support Vector Machine und ihre Implementierung in der Scikit-Learn-Bibliothek von Python. Wir werden dann zu einem anderen SVM-Konzept übergehen, bekannt als Kernel-SVM, oder Kernel-Trick, und wird es auch mit Hilfe von Scikit-Learn implementieren.
Einfaches (lineares) SVM-Modell
Über den Datensatz
Nach dem in der Einleitung gegebenen Beispiel verwenden wir einen Datensatz, der Messungen von echten und gefälschten Banknotenbildern enthält.
Beim Betrachten zweier Noten scannt unser Auge sie normalerweise von links nach rechts und prüft, wo es Ähnlichkeiten oder Unterschiede geben könnte. Wir suchen nach einem schwarzen Punkt, der vor einem grünen Punkt steht, oder nach einer glänzenden Markierung, die sich über einer Illustration befindet. Das bedeutet, dass es eine Reihenfolge gibt, in der wir uns die Notizen ansehen. Wenn wir wüssten, dass es grüne und schwarze Punkte gibt, aber nicht, ob der grüne Punkt vor dem schwarzen oder das schwarze vor dem grünen kommt, wäre es schwieriger, zwischen Noten zu unterscheiden.
Es gibt ein ähnliches Verfahren zu dem, was wir gerade beschrieben haben, das auf die Banknotenbilder angewendet werden kann. Im Allgemeinen besteht diese Methode darin, die Pixel des Bildes in ein Signal zu übersetzen und dann die Reihenfolge zu berücksichtigen, in der jedes unterschiedliche Signal im Bild auftritt, indem es in kleine Wellen umgewandelt wird, oder Wavelets. Nachdem Sie die Wavelets erhalten haben, gibt es eine Möglichkeit, die Reihenfolge zu ermitteln, in der ein Signal vor einem anderen auftritt, oder die Zeit, aber nicht genau welches Signal. Um das zu wissen, müssen die Frequenzen des Bildes ermittelt werden. Sie werden durch ein Verfahren erhalten, das die Zerlegung jedes Signals durchführt, genannt Fourier-Methode.
Sobald die Zeitdimension durch die Wavelets und die Frequenzdimension durch die Fourier-Methode erhalten wurde, wird eine Überlagerung von Zeit und Frequenz vorgenommen, um zu sehen, wann beide übereinstimmen, dies ist die Faltung Analyse. Die Faltung erhält eine Anpassung, die die Wavelets mit den Frequenzen des Bildes abgleicht und herausfindet, welche Frequenzen hervorstechender sind.
Diese Methode, bei der die Wavelets und ihre Frequenzen gefunden und dann beide angepasst werden, wird aufgerufen Wavelet-Transformation. Die Wavelet-Transformation hat Koeffizienten, und diese Koeffizienten wurden verwendet, um die Messungen zu erhalten, die wir im Datensatz haben.
Importieren des Datensatzes
Der Banknoten-Datensatz, den wir in diesem Abschnitt verwenden werden, ist derselbe, der im Klassifizierungsabschnitt des verwendet wurde Anleitung zum Entscheidungsbaum.
Hinweis: Sie können den Datensatz herunterladen hier.
Lassen Sie uns die Daten in einen Panda importieren dataframe Struktur, und werfen Sie einen Blick auf die ersten fünf Zeilen mit dem head() Methode.
Beachten Sie, dass die Daten in a gespeichert werden txt (Text-) Dateiformat, durch Kommas getrennt und ohne Kopfzeile. Wir können es als Tabelle rekonstruieren, indem wir es als lesen csv, Angabe der separator als Komma und Hinzufügen der Spaltennamen mit dem names Argument.
Lassen Sie uns diese drei Schritte gleichzeitig ausführen und uns dann die ersten fünf Zeilen der Daten ansehen:
import pandas as pd data_link = "https://archive.ics.uci.edu/ml/machine-learning-databases/00267/data_banknote_authentication.txt"
col_names = ["variance", "skewness", "curtosis", "entropy", "class"] bankdata = pd.read_csv(data_link, names=col_names, sep=",", header=None)
bankdata.head()
Das führt zu:
variance skewness curtosis entropy class
0 3.62160 8.6661 -2.8073 -0.44699 0
1 4.54590 8.1674 -2.4586 -1.46210 0
2 3.86600 -2.6383 1.9242 0.10645 0
3 3.45660 9.5228 -4.0112 -3.59440 0
4 0.32924 -4.4552 4.5718 -0.98880 0
Hinweis: Sie können die Daten auch lokal speichern und ersetzen data_link für data_path, und übergeben Sie den Pfad zu Ihrer lokalen Datei.
Wir können sehen, dass unser Datensatz fünf Spalten enthält, nämlich variance, skewness, curtosis, entropy und class. In den fünf Zeilen werden die ersten vier Spalten mit Zahlen wie 3.62160, 8.6661, -2.8073 oder XNUMX gefüllt kontinuierlich Werte, und die letzte class Die ersten fünf Zeilen der Spalte sind mit Nullen oder a gefüllt diskret Wert.
Da unser Ziel darin besteht, vorherzusagen, ob eine Banknote echt ist oder nicht, können wir dies anhand der vier Attribute der Banknote tun:
-
variancedes Wavelet-transformierten Bildes. Im Allgemeinen ist die Varianz ein kontinuierlicher Wert, der misst, wie weit die Datenpunkte nahe oder weit vom Durchschnittswert der Daten entfernt sind. Wenn die Punkte näher am Durchschnittswert der Daten liegen, ist die Verteilung näher an einer Normalverteilung, was normalerweise bedeutet, dass ihre Werte besser verteilt und etwas leichter vorherzusagen sind. Im aktuellen Bildkontext ist dies die Varianz der Koeffizienten, die sich aus der Wavelet-Transformation ergeben. Je geringer die Varianz, desto näher waren die Koeffizienten an der Übersetzung des tatsächlichen Bildes. -
skewnessdes Wavelet-transformierten Bildes. Die Schiefe ist ein kontinuierlicher Wert, der die Asymmetrie einer Verteilung angibt. Wenn es links vom Mittelwert mehr Werte gibt, ist die Verteilung negativ verzerrt, wenn es rechts vom Mittelwert mehr Werte gibt, ist die Verteilung positiv verzerrt, und wenn Mittelwert, Modus und Median gleich sind, ist die Verteilung symmetrisch. Je symmetrischer eine Verteilung ist, desto näher kommt sie einer Normalverteilung, und ihre Werte sind auch besser verteilt. Im vorliegenden Zusammenhang ist dies die Schiefe der Koeffizienten, die sich aus der Wavelet-Transformation ergeben. Je symmetrischer, desto näher liegen die Koeffizienten wirvariance,skewness,curtosis,entropybezüglich der Übersetzung des eigentlichen Bildes.
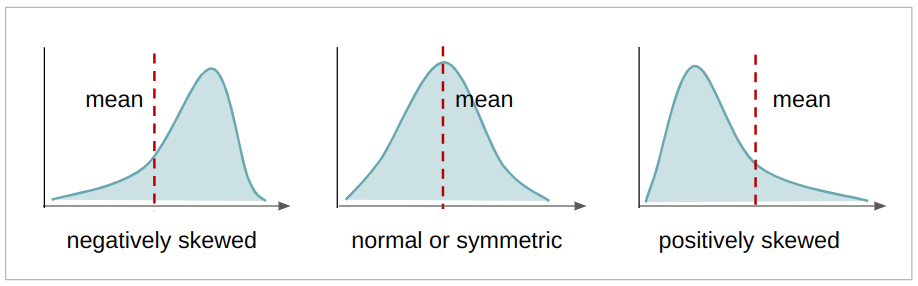
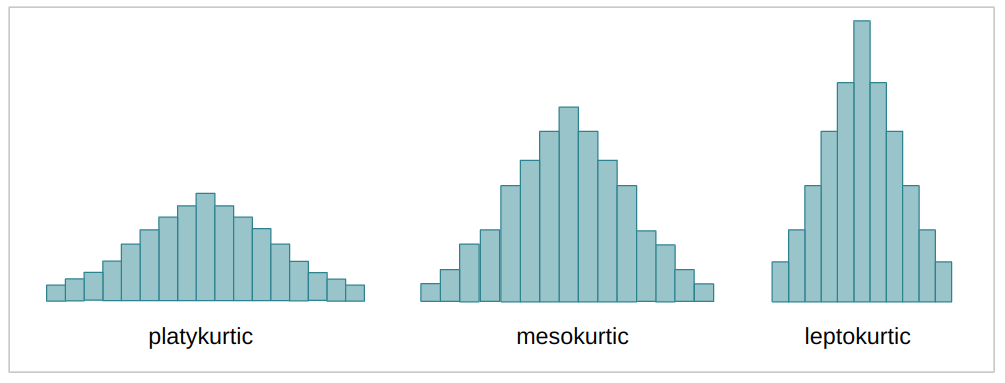
curtosis(oder Kurtosis) des Wavelet-transformierten Bildes. Die Kurtosis ist ein kontinuierlicher Wert, der wie die Schiefe auch die Form einer Verteilung beschreibt. Abhängig vom Kurtosis-Koeffizienten (k) kann eine Verteilung – verglichen mit der Normalverteilung – mehr oder weniger flach sein – oder mehr oder weniger Daten in ihren Extremitäten oder Ausläufern haben. Wenn die Verteilung breiter und flacher ist, heißt es platykurtisch; wenn es weniger ausgebreitet und in der Mitte konzentrierter ist, mesokurtisch; und wenn die Verteilung fast vollständig in der Mitte konzentriert ist, heißt es leptokurtisch. Dies ist derselbe Fall wie bei den vorherigen Fällen der Varianz und Schiefe, je mesokurtischer die Verteilung ist, desto näher waren die Koeffizienten an der Übersetzung des tatsächlichen Bildes.
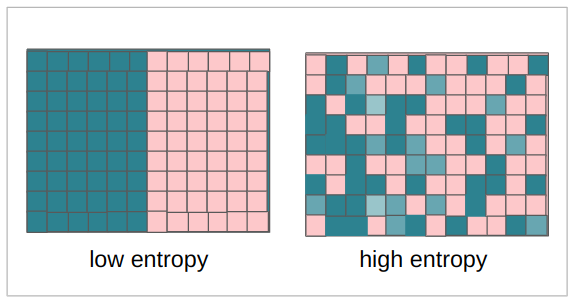
entropydes Bildes. Die Entropie ist ebenfalls eine kontinuierliche Größe, sie misst normalerweise die Zufälligkeit oder Unordnung in einem System. Im Zusammenhang mit einem Bild misst die Entropie den Unterschied zwischen einem Pixel und seinen Nachbarpixeln. Für unseren Kontext gilt: Je mehr Entropie die Koeffizienten haben, desto mehr Verlust gab es bei der Transformation des Bildes – und je kleiner die Entropie, desto geringer der Informationsverlust.
Die fünfte Variable war die class Variable, die wahrscheinlich 0 und 1 Werte hat, die sagen, ob die Notiz echt oder gefälscht war.
Wir können überprüfen, ob die fünfte Spalte Nullen und Einsen mit Pandas enthält. unique() Verfahren:
bankdata['class'].unique()
Die obige Methode gibt zurück:
array([0, 1]) Die obige Methode gibt ein Array mit den Werten 0 und 1 zurück. Das bedeutet, dass die einzigen Werte, die in unseren Klassenzeilen enthalten sind, Nullen und Einsen sind. Es ist bereit, als verwendet zu werden Ziel in unserem überwachten Lernen.
classdes Bildes. Dies ist ein ganzzahliger Wert, er ist 0, wenn das Bild gefälscht ist, und 1, wenn das Bild echt ist.
Da wir eine Spalte mit den Anmerkungen von echten und vergessenen Bildern haben, bedeutet dies, dass unsere Art des Lernens ist Aufsicht.
Hinweis: Um mehr über die Gründe für die Wavelet-Transformation auf den Banknotenbildern und die Verwendung von SVM zu erfahren, lesen Sie das veröffentlichte Papier der Autoren.
Wir können auch sehen, wie viele Datensätze oder Bilder wir haben, indem wir uns die Anzahl der Zeilen in den Daten über ansehen shape Eigentum:
bankdata.shape
Dies gibt aus:
(1372, 5)
Die obige Zeile bedeutet, dass es 1,372 Reihen transformierter Banknotenbilder und 5 Spalten gibt. Dies sind die Daten, die wir analysieren werden.
Wir haben unseren Datensatz importiert und ein paar Kontrollen vorgenommen. Jetzt können wir unsere Daten untersuchen, um sie besser zu verstehen.
Exploring das Dataset
Wir haben gerade gesehen, dass es in der Spalte Klasse nur Nullen und Einsen gibt, aber wir können auch wissen, in welchem Verhältnis sie stehen – mit anderen Worten – ob es mehr Nullen als Einsen, mehr Einsen als Nullen oder ob die Anzahl der Nullen ist dasselbe wie die Anzahl der Einsen, was bedeutet, dass sie sind balanced.
Um den Anteil zu kennen, können wir jeden der Null- und Eins-Werte in den Daten zählen value_counts() Verfahren:
bankdata['class'].value_counts()
Dies gibt aus:
0 762
1 610
Name: class, dtype: int64
Im obigen Ergebnis sehen wir, dass es 762 Nullen und 610 Einsen oder 152 mehr Nullen als Einsen gibt. Dies bedeutet, dass wir ein bisschen mehr gefälschte als echte Bilder haben, und wenn diese Diskrepanz größer wäre, beispielsweise 5500 Nullen und 610 Einsen, könnte dies unsere Ergebnisse negativ beeinflussen. Sobald wir versuchen, diese Beispiele in unserem Modell zu verwenden – je mehr Beispiele vorhanden sind, bedeutet dies normalerweise, dass das Modell mehr Informationen benötigt, um zwischen gefälschten oder echten Noten zu entscheiden – wenn es nur wenige Beispiele für echte Noten gibt, neigt das Modell dazu irren sich, wenn sie versuchen, sie zu erkennen.
Wir wissen bereits, dass es 152 weitere gefälschte Noten gibt, aber können wir sicher sein, dass das genug Beispiele sind, damit das Modell lernen kann? Zu wissen, wie viele Beispiele zum Lernen benötigt werden, ist eine sehr schwer zu beantwortende Frage. Stattdessen können wir versuchen, prozentual zu verstehen, wie groß dieser Unterschied zwischen den Klassen ist.
Der erste Schritt ist die Verwendung von Pandas value_counts() -Methode erneut, aber sehen wir uns jetzt den Prozentsatz an, indem wir das Argument einbeziehen normalize=True:
bankdata['class'].value_counts(normalize=True)
Das normalize=True berechnet den Prozentsatz der Daten für jede Klasse. Bisher beträgt der Prozentsatz an gefälschten (0) und echten Daten (1):
0 0.555394
1 0.444606
Name: class, dtype: float64
Das bedeutet, dass ungefähr (~) 56 % unseres Datensatzes gefälscht und 44 % davon echt sind. Das ergibt ein Verhältnis von 56 % zu 44 %, was einem Unterschied von 12 % entspricht. Dies wird statistisch als kleiner Unterschied angesehen, da er nur etwas über 10 % liegt, sodass die Daten als ausgeglichen gelten. Wenn anstelle eines Verhältnisses von 56:44 ein Verhältnis von 80:20 oder 70:30 vorhanden wäre, würden unsere Daten als unausgewogen betrachtet, und wir müssten eine Ungleichgewichtsbehandlung durchführen, aber glücklicherweise ist dies nicht der Fall.
Wir können diesen Unterschied auch visuell sehen, indem wir uns die Verteilung der Klasse oder des Ziels mit einem von Pandas durchdrungenen Histogramm ansehen, indem wir Folgendes verwenden:
bankdata['class'].plot.hist();
Dies zeichnet ein Histogramm unter Verwendung der Datenrahmenstruktur direkt in Kombination mit der matplotlib Bibliothek, die sich hinter den Kulissen befindet.

Wenn wir uns das Histogramm ansehen, können wir sicher sein, dass unsere Zielwerte entweder 0 oder 1 sind und dass die Daten ausgeglichen sind.
Dies war eine Analyse der Spalte, die wir vorhersagen wollten, aber was ist mit der Analyse der anderen Spalten unserer Daten?
Wir können uns die statistischen Messungen mit ansehen describe() Dataframe-Methode. Können wir auch verwenden .T der Transponierung – zum Invertieren von Spalten und Zeilen, wodurch der Vergleich zwischen Werten direkter wird:
Sehen Sie sich unseren praxisnahen, praktischen Leitfaden zum Erlernen von Git an, mit Best Practices, branchenweit akzeptierten Standards und einem mitgelieferten Spickzettel. Hören Sie auf, Git-Befehle zu googeln und tatsächlich in Verbindung, um es!
bankdata.describe().T
Das führt zu:
count mean std min 25% 50% 75% max
variance 1372.0 0.433735 2.842763 -7.0421 -1.773000 0.49618 2.821475 6.8248
skewness 1372.0 1.922353 5.869047 -13.7731 -1.708200 2.31965 6.814625 12.9516
curtosis 1372.0 1.397627 4.310030 -5.2861 -1.574975 0.61663 3.179250 17.9274
entropy 1372.0 -1.191657 2.101013 -8.5482 -2.413450 -0.58665 0.394810 2.4495
class 1372.0 0.444606 0.497103 0.0000 0.000000 0.00000 1.000000 1.0000
Beachten Sie, dass Schiefe- und Curtosis-Spalten Mittelwerte aufweisen, die weit von den Standardabweichungswerten entfernt sind. Dies weist darauf hin, dass die Werte, die weiter von der zentralen Tendenz der Daten entfernt sind, oder eine größere Variabilität aufweisen.
Wir können auch einen visuellen Blick auf die Verteilung jedes Merkmals werfen, indem wir das Histogramm jedes Merkmals in eine for-Schleife zeichnen. Neben der Betrachtung der Verteilung wäre es interessant zu sehen, wie die Punkte der einzelnen Klassen in Bezug auf die einzelnen Merkmale getrennt werden. Dazu können wir ein Streudiagramm zeichnen, indem wir eine Kombination von Merkmalen zwischen ihnen erstellen, und jedem Punkt in Bezug auf seine Klasse unterschiedliche Farben zuweisen.
Beginnen wir mit der Verteilung der einzelnen Features und zeichnen das Histogramm jeder Datenspalte mit Ausnahme von class Säule. Das class Spalte wird nicht durch ihre Position im Bankdata-Spalten-Array berücksichtigt. Alle Spalten außer der letzten werden mit ausgewählt columns[:-1]:
import matplotlib.pyplot as plt for col in bankdata.columns[:-1]: plt.title(col) bankdata[col].plot.hist() plt.show();
Nachdem wir den obigen Code ausgeführt haben, können wir beides sehen skewness und entropy Datenverteilungen sind negativ verzerrt und curtosis ist positiv schief. Alle Verteilungen sind symmetrisch, und variance ist die einzige Verteilung, die nahezu normal ist.
Wir können jetzt zum zweiten Teil übergehen und das Streudiagramm jeder Variablen zeichnen. Dazu können wir auch alle Spalten außer der Klasse mit markieren columns[:-1], verwenden Sie Seaborns scatterplot() und zwei for-Schleifen, um die Paarungsvariationen für jedes der Merkmale zu erhalten. Wir können auch die Paarung eines Merkmals mit sich selbst ausschließen, indem wir testen, ob das erste Merkmal gleich dem zweiten mit einem ist if statement.
import seaborn as sns for feature_1 in bankdata.columns[:-1]: for feature_2 in bankdata.columns[:-1]: if feature_1 != feature_2: print(feature_1, feature_2) sns.scatterplot(x=feature_1, y=feature_2, data=bankdata, hue='class') plt.show();
Beachten Sie, dass alle Diagramme sowohl echte als auch gefälschte Datenpunkte haben, die nicht klar voneinander getrennt sind, was bedeutet, dass es eine Art Überlagerung von Klassen gibt. Da ein SVM-Modell eine Linie verwendet, um zwischen Klassen zu trennen, könnten diese Gruppen in den Diagrammen mit nur einer Linie getrennt werden? Es scheint unwahrscheinlich. So sehen die meisten realen Daten aus. Am nächsten kommen wir einer Trennung in der Kombination von skewness und variance, oder entropy und variance Grundstücke. Das liegt wohl daran variance Daten mit einer Verteilungsform, die näher an der Normalität liegt.
Es kann jedoch etwas schwierig sein, all diese Grafiken nacheinander zu betrachten. Wir haben die Alternative, alle Verteilungs- und Streudiagramme gemeinsam zu betrachten, indem wir Seaborns verwenden pairplot().
Beide vorherigen for-Schleifen, die wir gemacht haben, können durch diese Zeile ersetzt werden:
sns.pairplot(bankdata, hue='class');
Wenn man sich den Pairplot ansieht, scheint es tatsächlich so zu sein, curtosis und variance wäre die einfachste kombination von merkmalen, so könnten die verschiedenen klassen durch eine linie getrennt werden, oder linear trennbar.
Wenn die meisten Daten weit davon entfernt sind, linear trennbar zu sein, können wir versuchen, sie vorzuverarbeiten, indem wir ihre Dimensionen reduzieren, und auch ihre Werte normalisieren, um zu versuchen, die Verteilung näher an eine Normalverteilung zu bringen.
Lassen Sie uns für diesen Fall die Daten so verwenden, wie sie sind, ohne weitere Vorverarbeitung, und später können wir einen Schritt zurückgehen, die Datenvorverarbeitung ergänzen und die Ergebnisse vergleichen.
Hinweis: Bei der Arbeit mit Daten gehen bei der Transformation meist Informationen verloren, weil wir Annäherungen vornehmen, anstatt weitere Daten zu sammeln. Wenn Sie zunächst mit den Ausgangsdaten so arbeiten, wie sie sind, bietet dies, wenn möglich, eine Basislinie, bevor Sie andere Vorverarbeitungstechniken ausprobieren. Wenn Sie diesem Pfad folgen, kann das anfängliche Ergebnis unter Verwendung von Rohdaten mit einem anderen Ergebnis verglichen werden, das Vorverarbeitungstechniken für die Daten verwendet.
Hinweis: Normalerweise ist es in der Statistik beim Erstellen von Modellen üblich, einem Verfahren zu folgen, das von der Art der Daten (diskret, kontinuierlich, kategorial, numerisch), ihrer Verteilung und den Modellannahmen abhängt. Während in der Informatik (CS) mehr Platz für Versuch, Irrtum und neue Iterationen ist. In CS ist es üblich, eine Basislinie zu haben, mit der man vergleichen kann. In Scikit-learn gibt es eine Implementierung von Dummy-Modellen (oder Dummy-Schätzern), einige sind nicht besser, als eine Münze zu werfen und einfach zu antworten ja (oder 1) 50 % der Zeit. Es ist interessant, Dummy-Modelle als Grundlage für das tatsächliche Modell zu verwenden, wenn Ergebnisse verglichen werden. Es wird erwartet, dass die tatsächlichen Modellergebnisse besser sind als eine zufällige Vermutung, andernfalls wäre die Verwendung eines maschinellen Lernmodells nicht erforderlich.
Implementieren von SVM mit Scikit-Learn
Bevor wir uns eingehender mit der Theorie der Funktionsweise von SVM befassen, können wir unser erstes Basismodell mit den Daten und dem von Scikit-Learn erstellen Support-Vektor-Klassifikator or SVC Klasse.
Unser Modell erhält die Wavelet-Koeffizienten und versucht, sie basierend auf der Klasse zu klassifizieren. Der erste Schritt in diesem Prozess besteht darin, die Koeffizienten oder zu trennen Funktionen aus der Klasse bzw Ziel. Nach diesem Schritt besteht der zweite Schritt darin, die Daten weiter in einen Satz zu unterteilen, der für das Lernen des Modells oder verwendet wird Zug gesetzt und eine andere, die zur Bewertung des Modells verwendet wird, oder Testset.
Hinweis: Die Nomenklatur von Test und Bewertung kann etwas verwirrend sein, da Sie Ihre Daten auch zwischen Zug-, Bewertungs- und Testsets aufteilen können. Anstatt zwei Sätze zu haben, hätten Sie auf diese Weise einen Zwischensatz, den Sie einfach verwenden und sehen können, ob sich die Leistung Ihres Modells verbessert. Dies bedeutet, dass das Modell mit dem Zugsatz trainiert, mit dem Bewertungssatz verbessert und mit dem Testsatz eine endgültige Metrik erhalten würde.
Einige Leute sagen, dass die Bewertung dieser Zwischensatz ist, andere werden sagen, dass der Testsatz der Zwischensatz ist und dass der Bewertungssatz der endgültige Satz ist. Dies ist ein weiterer Weg, um sicherzustellen, dass das Modell nicht dasselbe Beispiel in irgendeiner Weise sieht, oder dass eine Art von Datenlecks nicht passiert, und dass es eine Modellverallgemeinerung durch die Verbesserung der Metriken des letzten Satzes gibt. Wenn Sie diesem Ansatz folgen möchten, können Sie die Daten wie hier beschrieben noch einmal weiter aufteilen train_test_split() von Scikit-Learn – Trainings-, Test- und Validierungssets -Guide.
Aufteilen von Daten in Trainings-/Testsätze
In der vorherigen Sitzung haben wir die Daten verstanden und untersucht. Jetzt können wir unsere Daten in zwei Arrays aufteilen – eines für die vier Features und das andere für das fünfte oder Ziel-Feature. Da wir die Klasse in Abhängigkeit von den Wavelet-Koeffizienten vorhersagen wollen, ist unsere y wird das sein, class Spalte und unsere X werden die variance, skewness, curtosis und entropy Säulen.
Um das Ziel und die Funktionen zu trennen, können wir nur die zuordnen class Spalte zu y, später aus dem Datenrahmen löschen, um die verbleibenden Spalten zuzuordnen X mit .drop() Verfahren:
y = bankdata['class']
X = bankdata.drop('class', axis=1) Sobald die Daten in Attribute und Labels unterteilt sind, können wir sie weiter in Trainings- und Testsätze unterteilen. Dies könnte von Hand erfolgen, aber die model_selection Bibliothek von Scikit-Learn enthält die train_test_split() Methode, mit der wir Daten zufällig in Trainings- und Testsätze aufteilen können.
Um es zu verwenden, können wir die Bibliothek importieren, die aufrufen train_test_split() Methode, eintreten X und y Daten, und definieren Sie a test_size als Argument durchgehen. In diesem Fall definieren wir es als 0.20– das bedeutet, dass 20 % der Daten für Tests und die anderen 80 % für Schulungen verwendet werden.
Diese Methode nimmt zufällig Stichproben unter Berücksichtigung des von uns definierten Prozentsatzes, respektiert jedoch die Xy-Paare, damit die Stichprobe die Beziehung nicht völlig durcheinander bringt.
Da der Stichprobenprozess von Natur aus zufällig ist, werden wir beim Ausführen der Methode immer unterschiedliche Ergebnisse haben. Um die gleichen Ergebnisse oder reproduzierbare Ergebnisse zu erhalten, können wir eine Konstante namens SEED mit dem Wert 42 definieren.
Sie können dazu das folgende Skript ausführen:
from sklearn.model_selection import train_test_split SEED = 42 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = SEED)
Beachten Sie, dass die train_test_split() -Methode gibt bereits die zurück X_train, X_test, y_train, y_test Sätze in dieser Reihenfolge. Wir können die Anzahl der für Training und Test getrennten Proben drucken, indem wir das erste (0) Element von erhalten shape Eigenschaft zurückgegebenes Tupel:
xtrain_samples = X_train.shape[0]
xtest_samples = X_test.shape[0] print(f'There are {xtrain_samples} samples for training and {xtest_samples} samples for testing.')
Dies zeigt, dass es 1097 Proben zum Training und 275 zum Testen gibt.
Das Modell trainieren
Wir haben die Daten in Zug- und Testsätze unterteilt. Jetzt ist es an der Zeit, ein SVM-Modell mit den Zugdaten zu erstellen und zu trainieren. Dazu können wir Scikit-Learns importieren svm Bibliothek zusammen mit der Support-Vektor-Klassifikator Klasse, oder SVC Klasse.
Nach dem Importieren der Klasse können wir eine Instanz davon erstellen – da wir ein einfaches SVM-Modell erstellen, versuchen wir, unsere Daten linear zu trennen, sodass wir eine Linie ziehen können, um unsere Daten zu teilen – was dasselbe ist wie die Verwendung von a lineare Funktion – durch Definieren kernel='linear' als Argument für den Klassifikator:
from sklearn.svm import SVC
svc = SVC(kernel='linear')
Auf diese Weise versucht der Klassifikator, eine lineare Funktion zu finden, die unsere Daten trennt. Lassen Sie uns nach dem Erstellen des Modells es trainieren, oder passen es, mit den Zugdaten, unter Verwendung der fit() Methode und das Geben der X_train Eigenschaften und y_train Ziele als Argumente.
Wir können den folgenden Code ausführen, um das Modell zu trainieren:
svc.fit(X_train, y_train)
Einfach so wird das Modell trainiert. Bisher haben wir die Daten verstanden, aufgeteilt, ein einfaches SVM-Modell erstellt und das Modell an die Zugdaten angepasst.
Der nächste Schritt besteht darin, zu verstehen, wie gut diese Anpassung unsere Daten beschreiben konnte. Mit anderen Worten, um zu beantworten, ob eine lineare SVM eine angemessene Wahl war.
Vorhersagen treffen
Eine Möglichkeit zu beantworten, ob das Modell die Daten beschreiben konnte, besteht darin, eine Klassifizierung zu berechnen und zu betrachten Metriken.
In Anbetracht dessen, dass das Lernen überwacht wird, können wir Vorhersagen treffen X_test und vergleichen Sie diese Vorhersageergebnisse – die wir nennen könnten y_pred – mit dem eigentlichen y_test, oder Grund Wahrheit.
Um einige der Daten vorherzusagen, das Modell predict() Methode angewendet werden kann. Dieses Verfahren erhält die Prüfmerkmale, X_test, als Argument und gibt eine Vorhersage, entweder 0 oder 1, für jeden von zurück X_testDie Zeilen.
Nach der Vorhersage der X_test Daten, die Ergebnisse werden in a gespeichert y_pred Variable. Jede der mit dem einfachen linearen SVM-Modell vorhergesagten Klassen befindet sich nun in der y_pred variabel.
Dies ist der Vorhersagecode:
y_pred = svc.predict(X_test)
Da wir die Vorhersagen haben, können wir sie jetzt mit den tatsächlichen Ergebnissen vergleichen.
Bewertung des Modells
Es gibt mehrere Möglichkeiten, Vorhersagen mit tatsächlichen Ergebnissen zu vergleichen, und sie messen verschiedene Aspekte einer Klassifizierung. Einige der am häufigsten verwendeten Klassifizierungsmetriken sind:
-
Verwirrung Matrix: Wenn wir wissen müssen, für wie viele Proben wir richtig oder falsch waren jede Klasse. Die Werte, die richtig waren und korrekt vorhergesagt wurden, werden aufgerufen wahre positive, diejenigen, die als positiv vorhergesagt wurden, aber keine positiven waren, werden aufgerufen Fehlalarm. Dieselbe Nomenklatur von wahre Negative und falsche Negative wird für negative Werte verwendet;
-
Präzision: Wenn es unser Ziel ist zu verstehen, welche korrekten Vorhersagewerte von unserem Klassifikator als richtig angesehen wurden. Precision dividiert diese wahren positiven Werte durch die Proben, die als positiv vorhergesagt wurden;
$$
Genauigkeit = frac{Text{wahre Positive}}{Text{wahre Positive} + Text{falsche Positive}}
$$
- Erinnern: Wird üblicherweise zusammen mit der Genauigkeit berechnet, um zu verstehen, wie viele der wahren Positiven von unserem Klassifikator identifiziert wurden. Der Rückruf wird berechnet, indem die wahren Positiven durch alles dividiert werden, was als positiv hätte vorhergesagt werden sollen.
$$
Recall = frac{Text{echte Positive}}{Text{echte Positive} + Text{falsche Negative}}
$$
- F1-Punktzahl: ist das ausgewogene oder harmonische Mittel von Präzision und Rückruf. Der niedrigste Wert ist 0 und der höchste 1. Wann
f1-scoregleich 1 ist, bedeutet dies, dass alle Klassen korrekt vorhergesagt wurden – dies ist mit echten Daten sehr schwer zu erreichen (Ausnahmen gibt es fast immer).
$$
text{f1-score} = 2* frac{text{precision} * text{recall}}{text{precision} + text{recall}}
$$
Wir waren bereits mit Konfusionsmatrix-, Präzisions-, Erinnerungs- und F1-Score-Maßen vertraut. Um sie zu berechnen, können wir die von Scikit-Learn importieren metrics Bibliothek. Diese Bibliothek enthält die classification_report und confusion_matrix Methoden gibt die Klassifizierungsberichtsmethode die Genauigkeit, den Abruf und den f1-Score zurück. Beide classification_report und confusion_matrix kann leicht verwendet werden, um die Werte für all diese wichtigen Metriken herauszufinden.
Zur Berechnung der Metriken importieren wir die Methoden, rufen sie auf und übergeben als Argumente die vorhergesagten Klassifikationen, y_test, und die Klassifikationsetiketten, oder y_true.
Zur besseren Visualisierung der Konfusionsmatrix können wir sie in einem Seaborn's darstellen heatmap Zusammen mit Mengenanmerkungen und für den Klassifizierungsbericht ist es am besten, das Ergebnis zu drucken, damit die Ergebnisse formatiert sind. Dies ist der folgende Code:
from sklearn.metrics import classification_report, confusion_matrix cm = confusion_matrix(y_test,y_pred)
sns.heatmap(cm, annot=True, fmt='d').set_title('Confusion matrix of linear SVM') print(classification_report(y_test,y_pred))
Dies zeigt:
precision recall f1-score support 0 0.99 0.99 0.99 148 1 0.98 0.98 0.98 127 accuracy 0.99 275 macro avg 0.99 0.99 0.99 275
weighted avg 0.99 0.99 0.99 275

Im Klassifizierungsbericht wissen wir, dass es eine Genauigkeit von 0.99, einen Erinnerungswert von 0.99 und einen f1-Wert von 0.99 für die gefälschten Noten oder Klasse 0 gibt. Diese Messungen wurden unter Verwendung von 148 Proben erhalten, wie in der Stützspalte gezeigt. In der Zwischenzeit war das Ergebnis für Klasse 1 oder echte Noten eine Einheit darunter, eine Genauigkeit von 0.98, eine Erinnerung von 0.98 und der gleiche f1-Wert. Diesmal wurden 127 Bildmessungen verwendet, um diese Ergebnisse zu erhalten.
Wenn wir uns die Konfusionsmatrix ansehen, können wir auch sehen, dass von 148 Proben der Klasse 0 146 richtig klassifiziert wurden und es 2 falsch positive Ergebnisse gab, während es bei 127 Proben der Klasse 1 2 falsch negative und 125 richtige positive Ergebnisse gab.
Wir können den Klassifizierungsbericht und die Konfusionsmatrix lesen, aber was bedeuten sie?
Ergebnisse interpretieren
Um die Bedeutung herauszufinden, betrachten wir alle Metriken zusammen.
Fast alle Proben der Klasse 1 wurden korrekt klassifiziert, bei unserem Modell gab es 2 Fehler bei der Identifizierung tatsächlicher Banknoten. Dies ist dasselbe wie 0.98 oder 98 % Rückruf. Ähnliches gilt für die Klasse 0, nur 2 Proben wurden falsch klassifiziert, während 148 echte Negative sind, was einer Genauigkeit von 99 % entspricht.
Abgesehen von diesen Ergebnissen markieren alle anderen 0.99, was fast 1 ist, eine sehr hohe Metrik. Wenn eine so hohe Metrik bei realen Daten auftritt, kann dies meistens auf ein Modell hindeuten, das zu stark an die Daten angepasst ist, oder überangepasst.
Wenn es eine Überanpassung gibt, funktioniert das Modell möglicherweise gut, wenn es die bereits bekannten Daten vorhersagt, aber es verliert die Fähigkeit, auf neue Daten zu verallgemeinern, was in realen Szenarien wichtig ist.
Ein schneller Test, um herauszufinden, ob eine Überanpassung vorliegt, ist auch mit Zugdaten möglich. Wenn sich das Modell die Zugdaten einigermaßen eingeprägt hat, liegen die Metriken sehr nahe bei 1 oder 100 %. Denken Sie daran, dass die Zugdaten größer sind als die Testdaten – versuchen Sie aus diesem Grund, sie proportional zu betrachten, mehr Stichproben, mehr Fehlermöglichkeiten, es sei denn, es gab eine Überanpassung.
Um mit Zugdaten vorherzusagen, können wir wiederholen, was wir für Testdaten getan haben, aber jetzt mit X_train:
y_pred_train = svc.predict(X_train) cm_train = confusion_matrix(y_train,y_pred_train)
sns.heatmap(cm_train, annot=True, fmt='d').set_title('Confusion matrix of linear SVM with train data') print(classification_report(y_train,y_pred_train))
Dies gibt aus:
precision recall f1-score support 0 0.99 0.99 0.99 614 1 0.98 0.99 0.99 483 accuracy 0.99 1097 macro avg 0.99 0.99 0.99 1097
weighted avg 0.99 0.99 0.99 1097
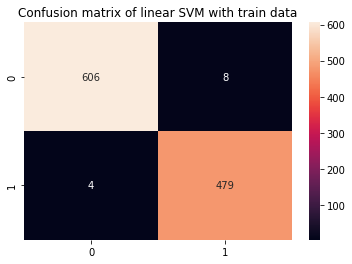
Es ist leicht zu erkennen, dass eine Überanpassung vorliegt, sobald die Zugmetriken 99 % betragen, wenn viermal mehr Daten vorhanden sind. Was kann in diesem Szenario getan werden?
Um die Überanpassung rückgängig zu machen, können wir weitere Zugbeobachtungen hinzufügen, eine Trainingsmethode mit verschiedenen Teilen des Datensatzes verwenden, z Kreuzvalidierung, und ändern Sie auch die Standardparameter, die bereits vor dem Training vorhanden sind, wenn Sie unser Modell erstellen, oder Hyperparameter. Meistens legt Scikit-learn einige Parameter als Standard fest, und dies kann unbemerkt geschehen, wenn nicht viel Zeit zum Lesen der Dokumentation aufgewendet wird.
Sie können den zweiten Teil dieses Leitfadens überprüfen (coming soon!), um zu sehen, wie die Kreuzvalidierung implementiert und eine Hyperparameter-Abstimmung durchgeführt wird.
Zusammenfassung
In diesem Artikel haben wir die einfache lineare Kernel-SVM untersucht. Wir haben die Intuition hinter dem SVM-Algorithmus, haben einen echten Datensatz verwendet, die Daten untersucht und gesehen, wie diese Daten zusammen mit SVM verwendet werden können, indem wir sie mit der Scikit-Learn-Bibliothek von Python implementieren.
Um weiter zu üben, können Sie andere Datensätze aus der realen Welt ausprobieren, die an Orten wie verfügbar sind Kaggle, UCI, Öffentliche Big Query-Datasets, Universitäten und Regierungswebsites.
Ich würde auch vorschlagen, dass Sie die tatsächliche Mathematik hinter dem SVM-Modell untersuchen. Obwohl Sie es nicht unbedingt brauchen werden, um den SVM-Algorithmus zu verwenden, ist es dennoch sehr praktisch zu wissen, was tatsächlich hinter den Kulissen vor sich geht, während Ihr Algorithmus Entscheidungsgrenzen findet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Die Zukunft prägen mit Adryenn Ashley. Hier zugreifen.
- Quelle: https://stackabuse.com/implementing-svm-and-kernel-svm-with-pythons-scikit-learn/

