Inhaltsverzeichnis
In diesem Artikel erfahren Sie, wie das geht Erkennen Sie Gesichter in Echtzeit mit OpenCV. Nachdem wir das Gesicht im Webcam-Stream erkannt haben, speichern wir die Frames, die das Gesicht enthalten. Später werden wir diese Frames (Bilder) an unseren Maskendetektor-Klassifizierer weiterleiten, um herauszufinden, ob die Person eine Maske trägt oder nicht.
Wir werden auch sehen, wie man daraus einen benutzerdefinierten Maskendetektor herstellt Tensorflow und Keras Sie können das aber überspringen, da ich unten die Datei mit dem trainierten Modell anhänge, die Sie herunterladen und verwenden können. Hier ist die Liste der Unterthemen, die wir behandeln werden:
- Was ist Gesichtserkennung?
- Gesichtserkennungsmethoden
- Gesichtserkennungsalgorithmus
- Gesichtserkennung
- Gesichtserkennung mit Python
- Gesichtserkennung mit OpenCV
- Erstellen Sie ein Modell zur Erkennung von Gesichtern, die eine Maske tragen (optional)
- So führen Sie eine Echtzeit-Maskenerkennung durch
Was ist Gesichtserkennung?
Das Ziel der Gesichtserkennung besteht darin, festzustellen, ob Gesichter im Bild oder Video vorhanden sind. Wenn mehrere Gesichter vorhanden sind, ist jedes Gesicht von einem Begrenzungsrahmen umgeben und wir kennen somit die Position der Gesichter
Das Hauptziel von Gesichtserkennungsalgorithmen besteht darin, das Vorhandensein und die Position von Gesichtern in einem Bild oder Video genau und effizient zu bestimmen. Die Algorithmen analysieren den visuellen Inhalt der Daten und suchen nach Mustern und Merkmalen, die Gesichtsmerkmalen entsprechen. Durch den Einsatz verschiedener Techniken wie maschinelles Lernen, Bildverarbeitung und Mustererkennung zielen Gesichtserkennungsalgorithmen darauf ab, Gesichter von anderen Objekten oder Hintergrundelementen innerhalb der visuellen Daten zu unterscheiden.
Menschliche Gesichter sind schwer zu modellieren, da es viele Variablen gibt, die sich ändern können, beispielsweise Gesichtsausdruck, Ausrichtung, Lichtverhältnisse und teilweise Verdeckungen wie Sonnenbrillen, Schals, Masken usw. Das Ergebnis der Erkennung liefert Parameter für die Gesichtsposition, und das könnte der Fall sein in verschiedenen Formen erforderlich sein, zum Beispiel als Rechteck, das den zentralen Teil des Gesichts, Augenzentren oder Orientierungspunkte wie Augen, Nasen- und Mundwinkel, Augenbrauen, Nasenlöcher usw. abdeckt.
Gesichtserkennungsmethoden
Es gibt zwei Hauptansätze zur Gesichtserkennung:
- Feature-Basis-Ansatz
- Bildbasierter Ansatz
Feature-Basis-Ansatz
Objekte erkennt man meist an ihren einzigartigen Merkmalen. Es gibt viele Merkmale in einem menschlichen Gesicht, die man zwischen einem Gesicht und vielen anderen Objekten erkennen kann. Es lokalisiert Gesichter, indem es Strukturmerkmale wie Augen, Nase, Mund usw. extrahiert und diese dann zur Erkennung eines Gesichts verwendet. Typischerweise ist eine Art statistischer Klassifikator geeignet und hilfreich, um zwischen Gesichts- und Nicht-Gesichtsregionen zu unterscheiden. Darüber hinaus verfügen menschliche Gesichter über besondere Texturen, anhand derer sie zwischen einem Gesicht und anderen Objekten unterscheiden können. Darüber hinaus kann der Rand von Merkmalen dabei helfen, Objekte im Gesicht zu erkennen. Im kommenden Abschnitt werden wir einen funktionsbasierten Ansatz implementieren, indem wir das verwenden OpenCV-Tutorial.
Bildbasierter Ansatz
Im Allgemeinen stützen sich bildbasierte Methoden auf Techniken der statistischen Analyse und des maschinellen Lernens, um die relevanten Merkmale von Gesichts- und Nicht-Gesichtsbildern zu ermitteln. Die erlernten Merkmale liegen in Form von Verteilungsmodellen oder Diskriminanzfunktionen vor, die anschließend zur Gesichtserkennung verwendet werden. Bei dieser Methode verwenden wir verschiedene Algorithmen wie neuronale Netze, HMM, SVM, AdaBoost-Lernen. Im kommenden Abschnitt werden wir sehen, wie wir Gesichter mit MTCNN oder Multi-Task Cascaded Convolutional erkennen können Neurales Netzwerk, einem bildbasierten Ansatz zur Gesichtserkennung
Gesichtserkennungsalgorithmus
Einer der beliebtesten Algorithmen, die einen merkmalsbasierten Ansatz verwenden, ist der Viola-Jones-Algorithmus und hier werde ich kurz darauf eingehen. Wenn Sie mehr darüber erfahren möchten, empfehle ich Ihnen, diesen Artikel „Gesichtserkennung mit dem Viola-Jones-Algorithmus“ durchzulesen.
Viola-Jones Der Algorithmus ist nach zwei Computer-Vision-Forschern benannt, die die Methode 2001 vorschlugen: Paul Bratsche und Michael Jones in ihrem Artikel „Rapid Object Detection using a Boosted Cascade of Simple Features“. Obwohl es sich um ein veraltetes Framework handelt, ist Viola-Jones recht leistungsstark und seine Anwendung hat sich bei der Echtzeit-Gesichtserkennung als außerordentlich bemerkenswert erwiesen. Das Trainieren dieses Algorithmus ist äußerst langsam, kann aber Gesichter in Echtzeit mit beeindruckender Geschwindigkeit erkennen.
Bei einem gegebenen Bild (dieser Algorithmus funktioniert bei Graustufenbildern) betrachtet der Algorithmus viele kleinere Teilbereiche und versucht, ein Gesicht zu finden, indem er in jedem Teilbereich nach bestimmten Merkmalen sucht. Es müssen viele verschiedene Positionen und Maßstäbe überprüft werden, da ein Bild viele Gesichter unterschiedlicher Größe enthalten kann. Viola und Jones verwendeten Haar-ähnliche Merkmale, um in diesem Algorithmus Gesichter zu erkennen.
Gesichtserkennung
Gesichtserkennung und Gesichtserkennung werden oft synonym verwendet, sind jedoch sehr unterschiedlich. Tatsächlich ist die Gesichtserkennung nur ein Teil der Gesichtserkennung.
Die Gesichtserkennung ist eine Methode zur Identifizierung oder Überprüfung der Identität einer Person anhand ihres Gesichts. Es gibt verschiedene Algorithmen zur Gesichtserkennung, ihre Genauigkeit kann jedoch variieren. Hier werde ich beschreiben, wie wir Gesichtserkennung mithilfe von Deep Learning durchführen.
Tatsächlich gibt es hier einen Artikel, Face Recognition Python, der zeigt, wie man die Gesichtserkennung implementiert.
Gesichtserkennung mit Python
Wie bereits erwähnt, werden wir hier sehen, wie wir Gesichter mithilfe eines bildbasierten Ansatzes erkennen können. MTCNN oder Multi-Task Cascaded Convolutional Neural Network ist zweifellos eines der beliebtesten und genauesten Gesichtserkennungstools, das dieses Prinzip nutzt. Als solches basiert es auf a tiefe Lernen Architektur besteht sie insbesondere aus drei neuronalen Netzen (P-Net, R-Net und O-Net), die in einer Kaskade verbunden sind.
Sehen wir uns also an, wie wir diesen Algorithmus in Python verwenden können, um Gesichter in Echtzeit zu erkennen. Zuerst müssen Sie die MTCNN-Bibliothek installieren, die ein trainiertes Modell enthält, das Gesichter erkennen kann.
pip install mtcnnSehen wir uns nun an, wie man MTCNN verwendet:
from mtcnn import MTCNN
import cv2
detector = MTCNN()
#Load a videopip TensorFlow
video_capture = cv2.VideoCapture(0) while (True): ret, frame = video_capture.read() frame = cv2.resize(frame, (600, 400)) boxes = detector.detect_faces(frame) if boxes: box = boxes[0]['box'] conf = boxes[0]['confidence'] x, y, w, h = box[0], box[1], box[2], box[3] if conf > 0.5: cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 255), 1) cv2.imshow("Frame", frame) if cv2.waitKey(25) & 0xFF == ord('q'): break video_capture.release()
cv2.destroyAllWindows()
Gesichtserkennung mit OpenCV
In diesem Abschnitt werden wir die Ausführung in Echtzeit durchführen Gesichtserkennung mit OpenCV aus einem Livestream über unsere Webcam.
Wie Sie wissen, bestehen Videos grundsätzlich aus Einzelbildern, also Standbildern. Wir führen eine Gesichtserkennung für jedes Bild in einem Video durch. Wenn es also um die Erkennung eines Gesichts in einem Standbild und die Erkennung eines Gesichts in einem Echtzeit-Videostream geht, gibt es zwischen beiden keinen großen Unterschied.
Wir werden den Haar-Kaskaden-Algorithmus, auch bekannt als Voila-Jones-Algorithmus, zur Gesichtserkennung verwenden. Es handelt sich im Grunde um einen Objekterkennungsalgorithmus für maschinelles Lernen, der zur Identifizierung von Objekten in einem Bild oder Video verwendet wird. In OpenCV verfügen wir über mehrere trainierte Haar Cascade-Modelle, die als XML-Dateien gespeichert werden. Anstatt das Modell von Grund auf zu erstellen und zu trainieren, verwenden wir diese Datei. Wir werden in diesem Projekt die Datei „haarcascade_frontalface_alt2.xml“ verwenden. Beginnen wir nun mit dem Codieren
Der erste Schritt besteht darin, den Pfad zur Datei „haarcascade_frontalface_alt2.xml“ zu finden. Wir tun dies, indem wir das OS-Modul der Python-Sprache verwenden.
import os
cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"Der nächste Schritt besteht darin, unseren Klassifikator zu laden. Der Pfad zur obigen XML-Datei dient als Argument für die CascadeClassifier()-Methode von OpenCV.
faceCascade = cv2.CascadeClassifier(cascPath)Nachdem wir den Klassifikator geladen haben, öffnen wir die Webcam mit diesem einfachen OpenCV-Einzeilercode
video_capture = cv2.VideoCapture(0)Als nächstes müssen wir die Frames aus dem Webcam-Stream abrufen. Dies tun wir mit der Funktion read(). Wir verwenden es in einer Endlosschleife, um alle Frames bis zu dem Zeitpunkt abzurufen, an dem wir den Stream schließen möchten.
while True: # Capture frame-by-frame ret, frame = video_capture.read()Die Funktion read() gibt Folgendes zurück:
- Der tatsächlich gelesene Video-Frame (ein Frame in jeder Schleife)
- Ein Rückkehrcode
Der Rückkehrcode sagt uns, ob uns die Frames ausgehen, was passieren wird, wenn wir aus einer Datei lesen. Dies spielt beim Lesen von der Webcam keine Rolle, da wir ewig aufzeichnen können, also ignorieren wir es.
Damit dieser spezielle Klassifikator funktioniert, müssen wir den Rahmen in Graustufen umwandeln.
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)Das faceCascade-Objekt verfügt über eine Methode discoverMultiScale(), die einen Frame (Bild) als Argument empfängt und die Klassifikatorkaskade über das Bild ausführt. Der Begriff „MultiScale“ weist darauf hin, dass der Algorithmus Teilbereiche des Bildes in mehreren Maßstäben betrachtet, um Gesichter unterschiedlicher Größe zu erkennen.
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE)Lassen Sie uns diese Argumente dieser Funktion durchgehen:
- scaleFactor – Parameter, der angibt, um wie viel die Bildgröße bei jedem Bildmaßstab reduziert wird. Durch Neuskalieren des Eingabebilds können Sie die Größe eines größeren Gesichts in ein kleineres ändern, sodass es für den Algorithmus erkennbar ist. 1.05 ist hierfür ein guter möglicher Wert, was bedeutet, dass Sie bei der Größenänderung einen kleinen Schritt machen, also die Größe um 5 % reduzieren, Sie erhöhen die Chance, dass eine passende Größe mit dem Modell zur Erkennung gefunden wird.
- minNeighbors – Parameter, der angibt, wie viele Nachbarn jedes Kandidatenrechteck haben sollte, um es beizubehalten. Dieser Parameter beeinflusst die Qualität der erkannten Gesichter. Ein höherer Wert führt zu weniger Erkennungen, aber mit höherer Qualität. 3~6 ist dafür ein guter Wert.
- Flags – Betriebsart
- minSize – Minimal mögliche Objektgröße. Kleinere Objekte werden ignoriert.
Die variablen Gesichter enthalten nun alle Erkennungen für das Zielbild. Erkennungen werden als Pixelkoordinaten gespeichert. Jede Erkennung wird durch die Koordinaten der oberen linken Ecke sowie die Breite und Höhe des Rechtecks definiert, das das erkannte Gesicht umfasst.
Um das erkannte Gesicht anzuzeigen, zeichnen wir ein Rechteck darüber. Rechteck() von OpenCV zeichnet Rechtecke über Bilder und muss die Pixelkoordinaten der oberen linken und unteren rechten Ecke kennen. Die Koordinaten geben die Pixelzeile und -spalte im Bild an. Wir können diese Koordinaten leicht aus der variablen Fläche erhalten.
for (x,y,w,h) in faces: cv2.rectangle(frame, (x, y), (x + w, y + h),(0,255,0), 2)rechteck() akzeptiert die folgenden Argumente:
- Das Originalbild
- Die Koordinaten des oberen linken Punkts der Erkennung
- Die Koordinaten des unteren rechten Punkts der Erkennung
- Die Farbe des Rechtecks (ein Tupel, das die Menge an Rot, Grün und Blau definiert (0-255)). In unserem Fall legen wir Grün fest, behalten aber die Grünkomponente bei 255 und den Rest bei Null.
- Die Dicke der Rechtecklinien
Als nächstes zeigen wir einfach den resultierenden Frame an und legen außerdem eine Möglichkeit fest, diese Endlosschleife zu verlassen und den Video-Feed zu schließen. Durch Drücken der Taste „q“ können wir das Skript hier verlassen
cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): breakDie nächsten beiden Zeilen dienen lediglich der Bereinigung und Freigabe des Bildes.
video_capture.release()
cv2.destroyAllWindows()Hier sind der vollständige Code und die Ausgabe.
import cv2
import os
cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE) for (x,y,w,h) in faces: cv2.rectangle(frame, (x, y), (x + w, y + h),(0,255,0), 2) # Display the resulting frame cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()
Ausgang:
Erstellen Sie ein Modell, um Gesichter zu erkennen, die eine Maske tragen
In diesem Abschnitt erstellen wir einen Klassifikator, der zwischen Gesichtern mit und ohne Masken unterscheiden kann. Falls Sie diesen Teil überspringen möchten, finden Sie hier eine Link um das vorab trainierte Modell herunterzuladen. Speichern Sie es und fahren Sie mit dem nächsten Abschnitt fort, um zu erfahren, wie Sie damit Masken mithilfe von OpenCV erkennen. Schauen Sie sich unsere Sammlung an OpenCV-Kurse um Ihnen zu helfen, Ihre Fähigkeiten zu entwickeln und besser zu verstehen.
Um diesen Klassifikator zu erstellen, benötigen wir Daten in Form von Bildern. Glücklicherweise haben wir einen Datensatz mit Bildern von Gesichtern mit und ohne Maske. Da die Anzahl dieser Bilder sehr gering ist, können wir ein neuronales Netzwerk nicht von Grund auf trainieren. Stattdessen optimieren wir ein vorab trainiertes Netzwerk namens MobileNetV2, das auf dem Imagenet-Datensatz trainiert wird.
Importieren wir zunächst alle notwendigen Bibliotheken, die wir benötigen.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import osDer nächste Schritt besteht darin, alle Bilder zu lesen und sie einer Liste zuzuordnen. Hier erhalten wir alle mit diesen Bildern verknüpften Pfade und beschriften sie dann entsprechend. Denken Sie daran, dass unser Datensatz in zwei Ordnern enthalten ist, nämlich „with_masks“ und „without_masks“. So können wir die Beschriftungen leicht erhalten, indem wir den Ordnernamen aus dem Pfad extrahieren. Außerdem verarbeiten wir das Bild vor und ändern seine Größe auf die Abmessungen 224 x 224.
imagePaths = list(paths.list_images('/content/drive/My Drive/dataset'))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths: # extract the class label from the filename label = imagePath.split(os.path.sep)[-2] # load the input image (224x224) and preprocess it image = load_img(imagePath, target_size=(224, 224)) image = img_to_array(image) image = preprocess_input(image) # update the data and labels lists, respectively data.append(image) labels.append(label)
# convert the data and labels to NumPy arrays
data = np.array(data, dtype="float32")
labels = np.array(labels)Der nächste Schritt besteht darin, das vorab trainierte Modell zu laden und es entsprechend unserem Problem anzupassen. Deshalb entfernen wir einfach die obersten Schichten dieses vorab trainierten Modells und fügen einige eigene Schichten hinzu. Wie Sie sehen können, hat die letzte Ebene zwei Knoten, da wir nur zwei Ausgänge haben. Dies nennt man Transferlernen.
baseModel = MobileNetV2(weights="imagenet", include_top=False, input_shape=(224, 224, 3))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(7, 7))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(128, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(2, activation="softmax")(headModel) # place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers: layer.trainable = FalseJetzt müssen wir die Labels in One-Hot-Codierung umwandeln. Anschließend teilen wir die Daten in Trainings- und Testsätze auf, um sie auszuwerten. Der nächste Schritt ist außerdem die Datenerweiterung, die die Vielfalt der für Trainingsmodelle verfügbaren Daten deutlich erhöht, ohne tatsächlich neue Daten zu sammeln. Datenerweiterungstechniken wie Zuschneiden, Drehen, Scheren und horizontales Spiegeln werden üblicherweise zum Trainieren großer neuronaler Netze verwendet.
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.20, stratify=labels, random_state=42)
# construct the training image generator for data augmentation
aug = ImageDataGenerator( rotation_range=20, zoom_range=0.15, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15, horizontal_flip=True, fill_mode="nearest")Der nächste Schritt besteht darin, das Modell zu kompilieren und es anhand der erweiterten Daten zu trainieren.
INIT_LR = 1e-4
EPOCHS = 20
BS = 32
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])
# train the head of the network
print("[INFO] training head...")
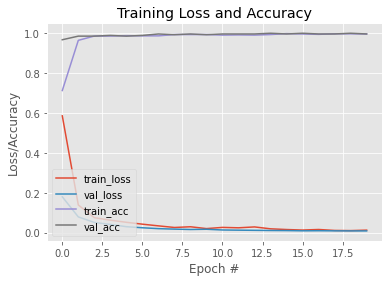
H = model.fit( aug.flow(trainX, trainY, batch_size=BS), steps_per_epoch=len(trainX) // BS, validation_data=(testX, testY), validation_steps=len(testX) // BS, epochs=EPOCHS)Nachdem unser Modell nun trainiert ist, zeichnen wir ein Diagramm, um seine Lernkurve zu sehen. Außerdem speichern wir das Modell zur späteren Verwendung. Hier ist ein Link zu diesem trainierten Modell.
N = EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")Ausgang:
#To save the trained model
model.save('mask_recog_ver2.h5')So führen Sie eine Echtzeit-Maskenerkennung durch
Bevor Sie mit dem nächsten Teil fortfahren, stellen Sie sicher, dass Sie das obige Modell hier herunterladen Link und platzieren Sie es im selben Ordner wie das Python-Skript, in das Sie den folgenden Code schreiben möchten.
Nachdem unser Modell nun trainiert ist, können wir den Code im ersten Abschnitt so ändern, dass er Gesichter erkennt und uns auch mitteilt, ob die Person eine Maske trägt oder nicht.
Damit unser Maskendetektormodell funktioniert, benötigt es Bilder von Gesichtern. Dazu werden wir die Frames mit Gesichtern mithilfe der im ersten Abschnitt gezeigten Methoden erkennen und sie dann nach Vorverarbeitung an unser Modell übergeben. Importieren wir also zunächst alle benötigten Bibliotheken.
import cv2
import os
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
import numpy as npDie ersten Zeilen stimmen exakt mit dem ersten Abschnitt überein. Der einzige Unterschied besteht darin, dass wir unser vorab trainiertes Maskendetektormodell dem Variablenmodell zugewiesen haben.
ascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
model = load_model("mask_recog1.h5") video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE)Als nächstes definieren wir einige Listen. Die faces_list enthält alle Gesichter, die vom faceCascade-Modell erkannt werden, und die preds-Liste wird zum Speichern der vom Maskendetektormodell getroffenen Vorhersagen verwendet.
faces_list=[]
preds=[]Da die Variable „faces“ außerdem die Koordinaten der oberen linken Ecke sowie die Höhe und Breite des die Gesichter umgebenden Rechtecks enthält, können wir damit einen Rahmen des Gesichts erhalten und diesen Rahmen dann vorverarbeiten, damit er zur Vorhersage in das Modell eingespeist werden kann . Die Vorverarbeitungsschritte sind dieselben wie beim Training des Modells im zweiten Abschnitt. Das Modell wird beispielsweise auf RGB-Bilder trainiert, daher konvertieren wir das Bild hier in RGB
for (x, y, w, h) in faces: face_frame = frame[y:y+h,x:x+w] face_frame = cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB) face_frame = cv2.resize(face_frame, (224, 224)) face_frame = img_to_array(face_frame) face_frame = np.expand_dims(face_frame, axis=0) face_frame = preprocess_input(face_frame) faces_list.append(face_frame) if len(faces_list)>0: preds = model.predict(faces_list) for pred in preds: #mask contain probabily of wearing a mask and vice versa (mask, withoutMask) = pred Nachdem wir die Vorhersagen erhalten haben, zeichnen wir ein Rechteck über das Gesicht und versehen es mit einer Beschriftung entsprechend den Vorhersagen.
label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (x, y- 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (x, y), (x + w, y + h),color, 2)Die restlichen Schritte sind die gleichen wie im ersten Abschnitt.
cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()Hier ist der vollständige Code und die Ausgabe:
import cv2
import os
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
import numpy as np cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
model = load_model("mask_recog1.h5") video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE) faces_list=[] preds=[] for (x, y, w, h) in faces: face_frame = frame[y:y+h,x:x+w] face_frame = cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB) face_frame = cv2.resize(face_frame, (224, 224)) face_frame = img_to_array(face_frame) face_frame = np.expand_dims(face_frame, axis=0) face_frame = preprocess_input(face_frame) faces_list.append(face_frame) if len(faces_list)>0: preds = model.predict(faces_list) for pred in preds: (mask, withoutMask) = pred label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (x, y- 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (x, y), (x + w, y + h),color, 2) # Display the resulting frame cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()
Ausgang:
Damit sind wir am Ende dieses Artikels angelangt, wo wir gelernt haben, wie man Gesichter in Echtzeit erkennt, und auch ein Modell entwickelt haben, das Gesichter mit Masken erkennen kann. Mit diesem Modell konnten wir den Gesichtsdetektor in einen Maskendetektor umwandeln.
Aktualisierung: Ich habe ein anderes Modell trainiert, das Bilder in „Maske tragen“, „Maske nicht tragen“ und „Maske nicht richtig tragen“ klassifizieren kann. Hier ist ein Link dazu Kaggle Notizbuch dieses Modells. Sie können es ändern und das Modell auch von dort herunterladen und anstelle des in diesem Artikel trainierten Modells verwenden. Obwohl dieses Modell nicht so effizient ist wie das hier trainierte Modell, verfügt es über eine zusätzliche Funktion zur Erkennung nicht ordnungsgemäß getragener Masken.
Wenn Sie dieses Modell verwenden, müssen Sie einige geringfügige Änderungen am Code vornehmen. Ersetzen Sie die vorherigen Zeilen durch diese Zeilen.
#Here are some minor changes in opencv code
for (box, pred) in zip(locs, preds): # unpack the bounding box and predictions (startX, startY, endX, endY) = box (mask, withoutMask,notproper) = pred # determine the class label and color we'll use to draw # the bounding box and text if (mask > withoutMask and mask>notproper): label = "Without Mask" elif ( withoutMask > notproper and withoutMask > mask): label = "Mask" else: label = "Wear Mask Properly" if label == "Mask": color = (0, 255, 0) elif label=="Without Mask": color = (0, 0, 255) else: color = (255, 140, 0) # include the probability in the label label = "{}: {:.2f}%".format(label, max(mask, withoutMask, notproper) * 100) # display the label and bounding box rectangle on the output # frame cv2.putText(frame, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2)Sie können sich auch mit Great Learning weiterbilden PGP-Kurs für künstliche Intelligenz und maschinelles Lernen. Der Kurs bietet Mentoring durch Branchenführer und Sie haben außerdem die Möglichkeit, in Echtzeit an branchenrelevanten Projekten zu arbeiten.
Weiterführende Literatur
- Echtzeit-Objekterkennung mit TensorFlow
- YOLO-Objekterkennung mit OpenCV
- Objekterkennung in Pytorch | Was ist Objekterkennung?
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- EVM-Finanzen. Einheitliche Schnittstelle für dezentrale Finanzen. Hier zugreifen.
- Quantum Media Group. IR/PR verstärkt. Hier zugreifen.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.mygreatlearning.com/blog/real-time-face-detection/

