Dieser Beitrag wurde gemeinsam mit Pramod Nayak, LakshmiKanth Mannem und Vivek Aggarwal von der Low Latency Group der LSEG verfasst.
Die Transaktionskostenanalyse (TCA) wird von Händlern, Portfoliomanagern und Brokern häufig für Pre- und Post-Trade-Analysen verwendet und hilft ihnen, Transaktionskosten und die Wirksamkeit ihrer Handelsstrategien zu messen und zu optimieren. In diesem Beitrag analysieren wir die Geld-Brief-Spannen von Optionen LSEG-Zeckenverlauf – PCAP Datensatz verwenden Amazon Athena für Apache Spark. Wir zeigen Ihnen, wie Sie auf Daten zugreifen, benutzerdefinierte Funktionen zur Anwendung auf Daten definieren, den Datensatz abfragen und filtern und die Ergebnisse der Analyse visualisieren, ohne dass Sie sich selbst bei großen Datensätzen um die Einrichtung der Infrastruktur oder die Konfiguration von Spark kümmern müssen.
Hintergrund
Die Options Price Reporting Authority (OPRA) fungiert als wichtiger Verarbeiter von Wertpapierinformationen und sammelt, konsolidiert und verbreitet letzte Verkaufsberichte, Kurse und relevante Informationen für US-Optionen. Mit 18 aktiven US-amerikanischen Optionsbörsen und über 1.5 Millionen zugelassenen Verträgen spielt OPRA eine entscheidende Rolle bei der Bereitstellung umfassender Marktdaten.
Am 5. Februar 2024 wird die Securities Industry Automation Corporation (SIAC) den OPRA-Feed von 48 auf 96 Multicast-Kanäle aktualisieren. Diese Verbesserung zielt darauf ab, die Symbolverteilung und Linienkapazitätsauslastung als Reaktion auf die eskalierende Handelsaktivität und Volatilität auf dem US-amerikanischen Optionsmarkt zu optimieren. SIAC hat Unternehmen empfohlen, sich auf Spitzendatenraten von bis zu 37.3 Gbit pro Sekunde vorzubereiten.
Obwohl sich durch das Upgrade nicht sofort das Gesamtvolumen der veröffentlichten Daten ändert, kann OPRA die Daten deutlich schneller verbreiten. Dieser Übergang ist von entscheidender Bedeutung, um den Anforderungen des dynamischen Optionsmarktes gerecht zu werden.
OPRA sticht als einer der umfangreichsten Feeds hervor, mit einem Spitzenwert von 150.4 Milliarden Nachrichten an einem einzigen Tag im dritten Quartal 3 und einem Kapazitätsreservebedarf von 2023 Milliarden Nachrichten an einem einzigen Tag. Die Erfassung jeder einzelnen Nachricht ist für die Transaktionskostenanalyse, die Überwachung der Marktliquidität, die Bewertung der Handelsstrategie und die Marktforschung von entscheidender Bedeutung.
Über die Daten
LSEG-Zeckenverlauf – PCAP ist ein cloudbasiertes Repository mit mehr als 30 PB, das weltweite Marktdaten höchster Qualität enthält. Diese Daten werden sorgfältig direkt in den Rechenzentren der Börse erfasst, wobei redundante Erfassungsprozesse eingesetzt werden, die strategisch in den wichtigsten Primär- und Backup-Rechenzentren der Börse weltweit positioniert sind. Die Erfassungstechnologie von LSEG gewährleistet eine verlustfreie Datenerfassung und nutzt eine GPS-Zeitquelle für eine Zeitstempelpräzision im Nanosekundenbereich. Darüber hinaus werden ausgefeilte Datenarbitrage-Techniken eingesetzt, um etwaige Datenlücken nahtlos zu schließen. Nach der Erfassung werden die Daten einer sorgfältigen Verarbeitung und Schlichtung unterzogen und dann mithilfe von in das Parquet-Format normalisiert LSEGs Real Time Ultra Direct (RTUD) Feed-Handler.
Der Normalisierungsprozess, der ein wesentlicher Bestandteil der Datenvorbereitung für die Analyse ist, generiert bis zu 6 TB komprimierte Parquet-Dateien pro Tag. Das enorme Datenvolumen ist auf den umfassenden Charakter von OPRA zurückzuführen, der sich über mehrere Börsen erstreckt und zahlreiche Optionskontrakte mit unterschiedlichen Merkmalen umfasst. Erhöhte Marktvolatilität und Market-Making-Aktivitäten an den Optionsbörsen tragen zusätzlich zum Umfang der auf OPRA veröffentlichten Daten bei.
Die Eigenschaften von Tick History – PCAP ermöglichen es Unternehmen, verschiedene Analysen durchzuführen, darunter die folgenden:
- Analyse vor dem Handel – Bewerten Sie potenzielle Handelsauswirkungen und erkunden Sie verschiedene Ausführungsstrategien auf der Grundlage historischer Daten
- Bewertung nach dem Handel – Messen Sie die tatsächlichen Ausführungskosten anhand von Benchmarks, um die Leistung von Ausführungsstrategien zu bewerten
- Optimiert Ausführung – Feinabstimmung der Ausführungsstrategien auf der Grundlage historischer Marktmuster, um die Auswirkungen auf den Markt zu minimieren und die gesamten Handelskosten zu senken
- Risikomanagement – Identifizieren Sie Slippage-Muster, identifizieren Sie Ausreißer und steuern Sie proaktiv die mit Handelsaktivitäten verbundenen Risiken
- Leistungszuordnung – Trennen Sie bei der Analyse der Portfolio-Performance die Auswirkungen von Handelsentscheidungen von Investitionsentscheidungen
Der LSEG Tick History – PCAP-Datensatz ist verfügbar in AWS-Datenaustausch und kann unter abgerufen werden AWS-Marktplatz. Mit AWS Data Exchange für Amazon S3können Sie direkt von LSEGs auf PCAP-Daten zugreifen Amazon Simple Storage-Service (Amazon S3)-Buckets, sodass Unternehmen keine eigene Kopie der Daten speichern müssen. Dieser Ansatz rationalisiert die Datenverwaltung und -speicherung und bietet Kunden sofortigen Zugriff auf hochwertige PCAP- oder normalisierte Daten mit einfacher Verwendung, Integration und mehr erhebliche Einsparungen bei der Datenspeicherung.
Athena für Apache Spark
Für analytische Unternehmungen, Athena für Apache Spark bietet ein vereinfachtes Notebook-Erlebnis, auf das über die Athena-Konsole oder Athena-APIs zugegriffen werden kann, sodass Sie interaktive Apache Spark-Anwendungen erstellen können. Mit einer optimierten Spark-Laufzeit unterstützt Athena die Analyse von Petabytes an Daten, indem es die Anzahl der Spark-Engines dynamisch in weniger als einer Sekunde skaliert. Darüber hinaus sind gängige Python-Bibliotheken wie Pandas und NumPy nahtlos integriert, was die Erstellung komplexer Anwendungslogik ermöglicht. Die Flexibilität erstreckt sich auf den Import benutzerdefinierter Bibliotheken zur Verwendung in Notebooks. Athena for Spark unterstützt die meisten Open-Data-Formate und ist nahtlos in das integriert AWS-Kleber Datenkatalog.
Datensatz
Für diese Analyse haben wir den LSEG Tick History – PCAP OPRA-Datensatz vom 17. Mai 2023 verwendet. Dieser Datensatz umfasst die folgenden Komponenten:
- Bestes Gebot und Angebot (BBO) – Meldet den höchsten Geld- und den niedrigsten Briefkurs für ein Wertpapier an einer bestimmten Börse
- Nationales bestes Gebot und Angebot (NBBO) – Meldet das höchste Gebot und den niedrigsten Brief für ein Wertpapier an allen Börsen
- Trades – Zeichnet abgeschlossene Trades an allen Börsen auf
Der Datensatz umfasst folgende Datenmengen:
- Trades – 160 MB verteilt auf ca. 60 komprimierte Parquet-Dateien
- BBO – 2.4 TB verteilt auf ca. 300 komprimierte Parquet-Dateien
- NBBO – 2.8 TB verteilt auf ca. 200 komprimierte Parquet-Dateien
Analyseübersicht
Die Analyse der OPRA-Tick-History-Daten für die Transaktionskostenanalyse (TCA) umfasst die Prüfung von Marktkursen und -geschäften rund um ein bestimmtes Handelsereignis. Im Rahmen dieser Studie verwenden wir die folgenden Kennzahlen:
- Notierter Spread (QS) – Berechnet als Differenz zwischen dem BBO-Brief und dem BBO-Gebot
- Effektive Verbreitung (ES) – Berechnet als Differenz zwischen dem Handelspreis und dem Mittelpunkt des BBO (BBO-Gebot + (BBO-Brief – BBO-Gebot)/2)
- Effektiver/quotierter Spread (EQF) – Berechnet als (ES / QS) * 100
Wir berechnen diese Spreads vor dem Handel und zusätzlich in vier Intervallen nach dem Handel (kurz danach, 1 Sekunde, 10 Sekunden und 60 Sekunden nach dem Handel).
Konfigurieren Sie Athena für Apache Spark
Führen Sie die folgenden Schritte aus, um Athena für Apache Spark zu konfigurieren:
- Auf der Athena-Konsole unter Los geht´sWählen Analysieren Sie Ihre Daten mit PySpark und Spark SQL.
- Wenn Sie Athena Spark zum ersten Mal verwenden, wählen Sie Arbeitsgruppe erstellen.

- Aussichten für Arbeitsgruppenname¸ Geben Sie einen Namen für die Arbeitsgruppe ein, z
tca-analysis. - Im Analytics-Engine Abschnitt auswählen Apache Funken.
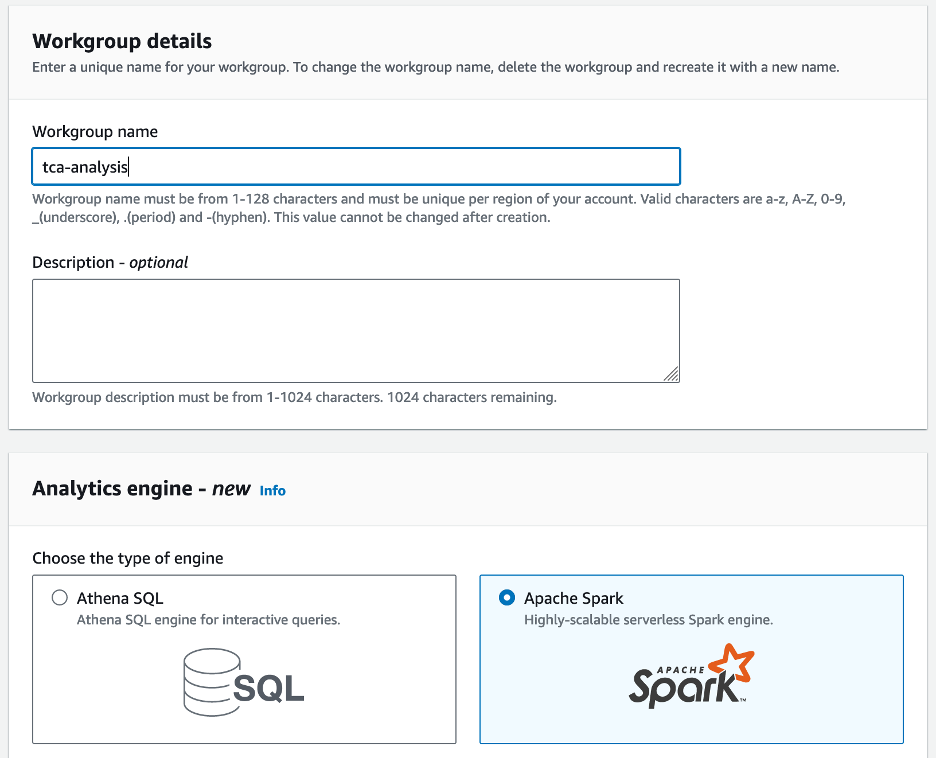
- Im Zusätzliche Konfigurationen Abschnitt, Sie können wählen Standardwerte verwenden oder stellen Sie eine Sonderanfertigung bereit AWS Identity and Access Management and (IAM)-Rolle und Amazon S3-Standort für Berechnungsergebnisse.
- Auswählen
Arbeitsgruppe erstellen.
- Navigieren Sie nach dem Erstellen der Arbeitsgruppe zu Notizbücher Tab und wählen Notizbuch erstellen.
- Geben Sie einen Namen für Ihr Notizbuch ein, z
tca-analysis-with-tick-history. - Auswählen
Erstellen um Ihr Notizbuch zu erstellen.
Starten Sie Ihr Notebook
Wenn Sie bereits eine Spark-Arbeitsgruppe erstellt haben, wählen Sie Starten Sie den Notebook-Editor für Los geht´s.
![]()
Nachdem Ihr Notizbuch erstellt wurde, werden Sie zum interaktiven Notizbuch-Editor weitergeleitet.
![]()
Jetzt können wir den folgenden Code zu unserem Notebook hinzufügen und ausführen.
Erstellen Sie eine Analyse
Führen Sie die folgenden Schritte aus, um eine Analyse zu erstellen:
- Gemeinsame Bibliotheken importieren:
- Erstellen Sie unsere Datenrahmen für BBO, NBBO und Trades:
- Jetzt können wir einen Trade identifizieren, der für die Transaktionskostenanalyse verwendet werden soll:
Wir erhalten folgende Ausgabe:
Wir verwenden künftig die hervorgehobenen Handelsinformationen für das Handelsprodukt (tp), den Handelspreis (tpr) und die Handelszeit (tt).
- Hier erstellen wir eine Reihe von Hilfsfunktionen für unsere Analyse
- In der folgenden Funktion erstellen wir den Datensatz, der alle Kurse vor und nach dem Handel enthält. Athena Spark ermittelt automatisch, wie viele DPUs zur Verarbeitung unseres Datensatzes gestartet werden müssen.
- Rufen wir nun die TCA-Analysefunktion mit den Informationen aus unserem ausgewählten Trade auf:
Visualisieren Sie die Analyseergebnisse
Lassen Sie uns nun die Datenrahmen erstellen, die wir für unsere Visualisierung verwenden. Jeder Datenrahmen enthält Kurse für eines der fünf Zeitintervalle für jeden Datenfeed (BBO, NBBO):
In den folgenden Abschnitten stellen wir Beispielcode zum Erstellen verschiedener Visualisierungen bereit.
Zeichnen Sie QS und NBBO vor dem Handel auf
Verwenden Sie den folgenden Code, um den angegebenen Spread und den NBBO vor dem Handel darzustellen:
![]()
Zeichnen Sie QS für jeden Markt und NBBO nach dem Handel auf
Verwenden Sie den folgenden Code, um den angegebenen Spread für jeden Markt und NBBO unmittelbar nach dem Handel darzustellen:
![]()
Zeichnen Sie QS für jedes Zeitintervall und jeden Markt für BBO auf
Verwenden Sie den folgenden Code, um den notierten Spread für jedes Zeitintervall und jeden Markt für BBO darzustellen:
![]()
Stellen Sie ES für jedes Zeitintervall und jeden Markt für BBO dar
Verwenden Sie den folgenden Code, um den effektiven Spread für jedes Zeitintervall und jeden Markt für BBO darzustellen:
Zeichnen Sie den EQR für jedes Zeitintervall und jeden Markt für BBO auf
Verwenden Sie den folgenden Code, um den effektiven/quotierten Spread für jedes Zeitintervall und jeden Markt für BBO darzustellen:
Athena Spark-Berechnungsleistung
Wenn Sie einen Codeblock ausführen, ermittelt Athena Spark automatisch, wie viele DPUs zum Abschließen der Berechnung erforderlich sind. Im letzten Codeblock, wo wir das aufrufen tca_analysis Funktion weisen wir Spark tatsächlich an, die Daten zu verarbeiten, und konvertieren dann die resultierenden Spark-Datenrahmen in Pandas-Datenrahmen. Dies stellt den verarbeitungsintensivsten Teil der Analyse dar. Wenn Athena Spark diesen Block ausführt, werden der Fortschrittsbalken, die verstrichene Zeit und die Anzahl der DPUs, die derzeit Daten verarbeiten, angezeigt. In der folgenden Berechnung verwendet Athena Spark beispielsweise 18 DPUs.
![]()
Wenn Sie Ihr Athena Spark-Notebook konfigurieren, haben Sie die Möglichkeit, die maximale Anzahl der DPUs festzulegen, die es verwenden kann. Der Standardwert ist 20 DPUs, aber wir haben diese Berechnung mit 10, 20 und 40 DPUs getestet, um zu zeigen, wie Athena Spark automatisch skaliert, um unsere Analyse auszuführen. Wir haben beobachtet, dass Athena Spark linear skaliert und 15 Minuten und 21 Sekunden benötigt, wenn das Notebook mit maximal 10 DPUs konfiguriert ist, 8 Minuten und 23 Sekunden, wenn das Notebook mit 20 DPUs konfiguriert ist, und 4 Minuten und 44 Sekunden, wenn das Notebook konfiguriert ist konfiguriert mit 40 DPUs. Da Athena Spark die Kosten auf Basis der DPU-Nutzung und mit einer Granularität pro Sekunde abrechnet, sind die Kosten für diese Berechnungen ähnlich. Wenn Sie jedoch einen höheren maximalen DPU-Wert festlegen, kann Athena Spark das Ergebnis der Analyse viel schneller zurückgeben. Für weitere Informationen zu den Athena Spark-Preisen klicken Sie bitte hier.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie Sie hochpräzise OPRA-Daten aus dem Tick History-PCAP von LSEG verwenden können, um mit Athena Spark Transaktionskostenanalysen durchzuführen. Die zeitnahe Verfügbarkeit von OPRA-Daten, ergänzt durch die Barrierefreiheitsinnovationen von AWS Data Exchange für Amazon S3, verkürzt die Analysezeit strategisch für Unternehmen, die umsetzbare Erkenntnisse für kritische Handelsentscheidungen gewinnen möchten. OPRA generiert täglich etwa 7 TB normalisierte Parquet-Daten, und die Verwaltung der Infrastruktur zur Bereitstellung von Analysen auf der Grundlage von OPRA-Daten ist eine Herausforderung.
Die Skalierbarkeit von Athena bei der Handhabung umfangreicher Datenverarbeitung für Tick History – PCAP für OPRA-Daten macht es zu einer überzeugenden Wahl für Unternehmen, die schnelle und skalierbare Analyselösungen in AWS suchen. Dieser Beitrag zeigt die nahtlose Interaktion zwischen dem AWS-Ökosystem und Tick History-PCAP-Daten und wie Finanzinstitute diese Synergie nutzen können, um datengesteuerte Entscheidungen für kritische Handels- und Anlagestrategien voranzutreiben.
Über die Autoren
![]() Pramod Nayak ist Director of Product Management der Low Latency Group bei LSEG. Pramod verfügt über mehr als 10 Jahre Erfahrung in der Finanztechnologiebranche mit den Schwerpunkten Softwareentwicklung, Analyse und Datenmanagement. Pramod ist ein ehemaliger Softwareentwickler und begeistert sich für Marktdaten und quantitativen Handel.
Pramod Nayak ist Director of Product Management der Low Latency Group bei LSEG. Pramod verfügt über mehr als 10 Jahre Erfahrung in der Finanztechnologiebranche mit den Schwerpunkten Softwareentwicklung, Analyse und Datenmanagement. Pramod ist ein ehemaliger Softwareentwickler und begeistert sich für Marktdaten und quantitativen Handel.
![]() LakshmiKanth Mannem ist Produktmanager in der Low Latency Group von LSEG. Sein Schwerpunkt liegt auf Daten- und Plattformprodukten für die Marktdatenbranche mit geringer Latenz. LakshmiKanth hilft Kunden dabei, die optimalsten Lösungen für ihre Marktdatenanforderungen zu entwickeln.
LakshmiKanth Mannem ist Produktmanager in der Low Latency Group von LSEG. Sein Schwerpunkt liegt auf Daten- und Plattformprodukten für die Marktdatenbranche mit geringer Latenz. LakshmiKanth hilft Kunden dabei, die optimalsten Lösungen für ihre Marktdatenanforderungen zu entwickeln.
![]() Vivek Aggarwal ist Senior Data Engineer in der Low Latency Group von LSEG. Vivek arbeitet an der Entwicklung und Pflege von Datenpipelines für die Verarbeitung und Bereitstellung erfasster Marktdaten-Feeds und Referenzdaten-Feeds.
Vivek Aggarwal ist Senior Data Engineer in der Low Latency Group von LSEG. Vivek arbeitet an der Entwicklung und Pflege von Datenpipelines für die Verarbeitung und Bereitstellung erfasster Marktdaten-Feeds und Referenzdaten-Feeds.
![]() Alket Memushaj ist Hauptarchitekt im Marktentwicklungsteam für Finanzdienstleistungen bei AWS. Alket ist für die technische Strategie verantwortlich und arbeitet mit Partnern und Kunden zusammen, um selbst die anspruchsvollsten Kapitalmarkt-Workloads in der AWS Cloud bereitzustellen.
Alket Memushaj ist Hauptarchitekt im Marktentwicklungsteam für Finanzdienstleistungen bei AWS. Alket ist für die technische Strategie verantwortlich und arbeitet mit Partnern und Kunden zusammen, um selbst die anspruchsvollsten Kapitalmarkt-Workloads in der AWS Cloud bereitzustellen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/

