Einleitung
Mit dem Aufkommen großer Sprachmodelle (LLMs) haben sie zahlreiche Anwendungen durchdrungen und kleinere Transformatormodelle wie ersetzt BERT oder regelbasierte Modelle in vielen Natürliche Sprachverarbeitung (NLP) Aufgaben. LLMs sind vielseitig und aufgrund ihrer umfassenden Vorschulung in der Lage, Aufgaben wie Textklassifizierung, Zusammenfassung, Stimmungsanalyse und Themenmodellierung zu bewältigen. Trotz ihrer breiten Leistungsfähigkeit weisen LLMs im Vergleich zu ihren kleineren Gegenstücken häufig eine geringere Genauigkeit auf.
Um dieser Einschränkung zu begegnen, besteht eine wirksame Strategie darin, vorab trainierte LLMs so zu optimieren, dass sie bei bestimmten Aufgaben hervorragende Leistungen erbringen. Die Feinabstimmung großer Modelle führt häufig zu optimalen Ergebnissen. Insbesondere bietet Googles Gemini neben anderen großen Modellen Benutzern nun die Möglichkeit, diese Modelle mit ihren eigenen Trainingsdaten zu verfeinern. In diesem Leitfaden führen wir Sie durch den Prozess der Feinabstimmung von Gemini-Modellen für bestimmte Probleme und erfahren, wie Sie einen Datensatz mithilfe von Ressourcen von HuggingFace kuratieren.
Lernziele
- Verstehen Sie die Leistung der Gemini-Modelle von Google.
- Erfahren Sie mehr über die Vorbereitung von Datensätzen für die Feinabstimmung des Gemini-Modells.
- Konfigurieren Sie Parameter für die Feinabstimmung des Gemini-Modells.
- Überwachen Sie den Fortschritt und die Kennzahlen der Feinabstimmung.
- Testen Sie die Leistung des Gemini-Modells anhand neuer Daten.
- Entdecken Sie Gemini-Modellanwendungen für die PII-Maskierung.

Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Google kündigt Tuning für Gemini an
Gemini gibt es in zwei Versionen: Pro und Ultra. In der Pro-Version gibt es Gemini 1.0 Pro und das neue Gemini 1.5 Pro. Diese Modelle von Google konkurrieren mit anderen fortgeschrittenen Modellen wie ChatGPT und Claude. Gemini-Modelle sind über die AI Studio-Benutzeroberfläche und eine kostenlose API für jedermann leicht zugänglich.
Kürzlich hat Google eine neue Funktion für Gemini-Modelle angekündigt: Feinabstimmung. Das bedeutet, dass jeder das Gemini-Modell an seine Bedürfnisse anpassen kann. Sie können Gemini entweder über die AI Studio-Benutzeroberfläche oder deren API optimieren. Bei der Feinabstimmung geben wir unsere eigenen Daten an Gemini weiter, damit sie sich so verhalten können, wie wir es wollen. Google verwendet Parameter Efficient Tuning (PET), um einige wichtige Teile des Gemini-Modells schnell anzupassen und es so für verschiedene Aufgaben nützlich zu machen.
Vorbereiten des Datensatzes
Bevor wir mit der Feinabstimmung des Modells beginnen, beginnen wir mit der Installation der erforderlichen Bibliotheken. Übrigens werden wir für diesen Leitfaden mit Colab zusammenarbeiten.
Notwendige Bibliotheken installieren
Die folgenden Python-Module sind für den Einstieg erforderlich:
!pip install -q google-generativeai datasets- google-generativeai: Es handelt sich um eine Bibliothek des Google-Teams, die uns den Zugriff auf das Google Gemini-Modell ermöglicht. Dieselbe Bibliothek kann zur Feinabstimmung des Gemini-Modells verwendet werden.
- Datensätze: Dies ist eine Bibliothek von HuggingFace, mit der wir arbeiten können, um eine Vielzahl von Datensätzen vom HuggingFace-Hub herunterzuladen. Wir werden mit dieser Datensatzbibliothek arbeiten, um den PII-Datensatz (Personal Identifiable Information) herunterzuladen und ihn zur Feinabstimmung an das Gemini-Modell weiterzugeben.
Durch Ausführen des folgenden Codes werden die Google Generative AI und die Datasets-Bibliothek in unserer Python-Umgebung heruntergeladen und installiert.
OAuth einrichten
Im nächsten Schritt müssen wir ein OAuth für dieses Tutorial einrichten. Das OAuth ist notwendig, damit die Daten, die wir zur Feinabstimmung von Gemini an Google senden, sicher sind. Um den OAuth zu erhalten, folgen Sie diesen Anweisungen Link. Laden Sie dann client_secret.json herunter, nachdem Sie OAuth erstellt haben. Speichern Sie den Inhalt von client_secrent.json in den Colab Secrets unter dem Namen CLIENT_SECRET und führen Sie den folgenden Code aus:
import os
if 'COLAB_RELEASE_TAG' in os.environ:
from google.colab import userdata
import pathlib
pathlib.Path('client_secret.json').write_text(userdata.get('CLIENT_SECRET'))
# Use `--no-browser` in colab
!gcloud auth application-default login --no-browser
--client-id-file client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'
else:
!gcloud auth application-default login --client-id-file
client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'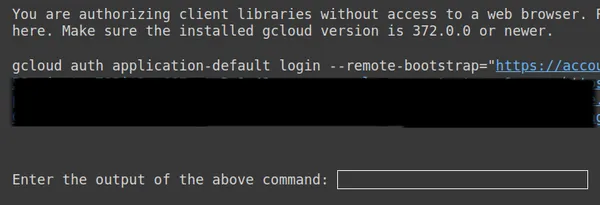
Kopieren Sie oben den zweiten Link, fügen Sie ihn in Ihr lokales CMD-System ein und führen Sie ihn aus.
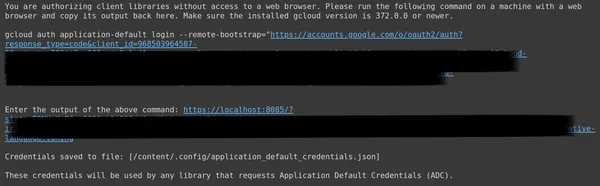
Anschließend werden Sie zum Webbrowser weitergeleitet, um sich mit der E-Mail-Adresse anzumelden, mit der Sie OAuth eingerichtet haben. Nachdem wir uns im CMD angemeldet haben, erhalten wir eine URL. Fügen Sie diese URL nun in die dritte Zeile ein und drücken Sie die Eingabetaste. Jetzt sind wir mit der Durchführung des OAuth mit Google fertig.
Herunterladen und Vorbereiten des Datensatzes
Zunächst laden wir den Datensatz herunter, mit dem wir arbeiten, um ihn an das Gemini-Modell anzupassen. Hierzu arbeiten wir mit der Datasets-Bibliothek. Der Code hierfür lautet:
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
print(dataset)- Hier beginnen wir mit dem Importieren der Funktion „load_dataset“ aus der Datasets-Bibliothek.
- An diese Funktion „load_dataset()“ übergeben wir den Datensatz, den wir herunterladen möchten. Hier in unserem Beispiel ist es „ai4privacy/pii-masking-200k“, das 200 Zeilen maskierter und unmaskierter PII-Daten enthält.
- Anschließend drucken wir den Datensatz aus.

Wir sehen, dass der Datensatz 209261 Zeilen mit Trainingsdaten und keine Testdaten enthält. Und jede Zeile enthält verschiedene Spalten wie masked_text, unmasked_text, Privacy_mask, span_labels, bio_labels und tokenised_text. Die Beispieldaten sind unten aufgeführt:
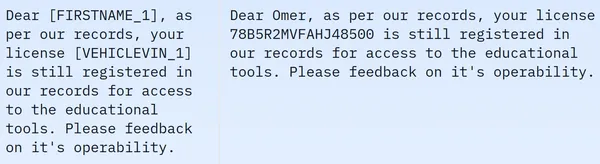
Im angezeigten Bild beobachten wir sowohl maskierte als auch unmaskierte Sätze. Insbesondere werden im maskierten Satz bestimmte Elemente wie der Name und die Fahrzeugnummer der Person durch bestimmte Tags verdeckt. Um die Daten für die weitere Verarbeitung vorzubereiten, müssen wir nun eine Datenvorverarbeitung durchführen. Nachfolgend finden Sie den Code für diesen Vorverarbeitungsschritt:
df = dataset['train'].to_pandas()
df = df[['unmasked_text','masked_text']][:2000]
df.columns = ['input','output']
- Zunächst entnehmen wir den Trainingsteil der Daten aus dem Datensatz (der heruntergeladene Datensatz enthält nur den Trainingsteil). Dann konvertieren wir dies in Pandas Dataframe.
- Zur Feinabstimmung von Gemini benötigen wir hier nur die Spalten unmasked_text und masked_text, also nehmen wir nur diese beiden.
- Dann erhalten wir die ersten 2000 Zeilen der Daten. Wir werden mit den ersten 2000 Reihen arbeiten, um Gemini zu verfeinern.
- Anschließend bearbeiten wir die Spaltennamen von unmasked_text und masked_text in Eingabe- und Ausgabespalten, denn wenn wir die Eingabetextdaten, die die PII (persönliche identifizierbare Informationen) enthalten, an das Gemini-Modell übergeben, erwarten wir, dass es die Ausgabetextdaten generiert, in denen die PII enthalten sind ist maskiert.
Formatieren von Daten zur Feinabstimmung von Gemini
Der nächste Schritt besteht darin, unsere Daten zu formatieren. Dazu erstellen wir eine Formatierungsfunktion:
def formatter(x):
text = f"""
Given the information below, mask the personal identifiable information.
Input:
{x['input']}
Output:
"""
return text
df['text_input'] = df.apply(formatter,axis=1)
print(df['text_input'][0])- Hier definieren wir einen Funktionsformatierer, der x, eine Zeile unserer Daten, aufnimmt.
- Dann definiert es einen variablen Text mit F-Strings, in dem wir den Kontext bereitstellen, gefolgt von den Eingabedaten aus dem Datenrahmen.
- Zum Schluss geben wir den formatierten Text zurück.
- Die letzte Zeile wendet die Formatierungsfunktion auf jede Zeile des Datenrahmens an, den wir mit der Funktion apply() erstellt haben.
- Die Achse = 1 gibt an, dass die Funktion auf jede Zeile des Datenrahmens angewendet wird.
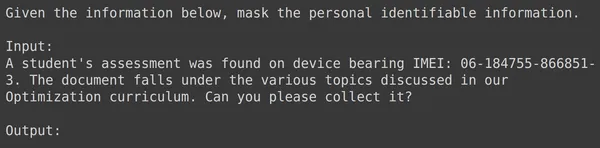
Das Ausführen des Codes führt zur Erstellung einer neuen Spalte namens „Train“, die den formatierten Text für jede Zeile einschließlich des Eingabefelds enthält. Versuchen wir, eines der Elemente des Datenrahmens zu beobachten:
Aufteilen von Daten in Trainings- und Testsätze
Wir können sehen, dass text_input die Daten enthält, wobei jede Zeile den Kontext am Anfang der Daten enthält, der angibt, die PII zu maskieren, gefolgt von den Eingabedaten und gefolgt vom Wort „output“, wo das Modell die Ausgabe generieren muss. Jetzt müssen wir den Datenrahmen in Train und Test unterteilen:
df = df[['text_input','output']]
df_train = df.iloc[:1900,:]
df_test = df.iloc[1900:,:]- Wir beginnen damit, die Daten so zu filtern, dass sie die Spalten „text_input“ und „output“ enthalten. Dies sind die Spalten, die von der Google Fine-Tune-Bibliothek zum Trainieren der Gemini erwartet werden
- Der Zwilling erhält die text_input und lernt, die Ausgabe zu schreiben
- Wir teilen die Daten in df_train auf, das die 1900 Zeilen unserer Originaldaten enthält
- Und ein df_test, der etwa 100 Zeilen der Originaldaten enthält
- Wir trainieren den Gemini auf df_train und testen ihn dann, indem wir 3-4 Beispiele aus df_test nehmen, um die von ihm generierte Ausgabe zu sehen
Wenn wir also den Code ausführen, werden unsere Daten gefiltert und in „Training“ und „Test“ aufgeteilt. Schließlich sind wir mit dem Datenvorverarbeitungsteil fertig.
Feinabstimmung des Gemini-Modells
Befolgen Sie die unten aufgeführten Schritte, um Ihr Gemini-Modell zu optimieren:
Tuning-Parameter einrichten
In diesem Abschnitt werden wir den Prozess der Optimierung des Gemini-Modells durchgehen. Dazu arbeiten wir mit folgendem Code:
import google.generativeai as genai
bm_name = "models/gemini-1.0-pro-001"
name = 'pii-model'
operation = genai.create_tuned_model(
source_model=bm_name,
training_data=df_train,
id = name,
epoch_count = 2,
batch_size=4,
learning_rate=0.001,
)
- Importieren Sie die Bibliothek „google.generativeai“: Diese Bibliothek stellt APIs für die Interaktion mit den generativen KI-Diensten von Google bereit.
- Geben Sie den Basismodellnamen an: Dies ist der Name des vorab trainierten Modells, mit dem wir als Ausgangspunkt für unser feinabgestimmtes Modell arbeiten möchten. Derzeit ist models/gemini-1.0-pro-001 das einzige einstellbare Modell. Wir speichern dies in der Variablen bm_name.
- Geben Sie den Namen des feinabgestimmten Modells an: Dies ist der Name, den wir unserem feinabgestimmten Modell geben möchten. Hier geben wir ihm den Namen „pii-Modell“.
- Erstellen Sie ein Operationsobjekt für ein optimiertes Modell: Dieses Objekt stellt den Vorgang zum Erstellen eines feinabgestimmten Modells dar. Es werden folgende Argumente benötigt:
- source_model: Der Name des Basismodells
- training_data: Die Trainingsdaten für das fein abgestimmte Modell, das wir gerade erstellt haben, nämlich df_train
- id: Die ID/der Name des feinabgestimmten Modells
- epoch_count: Die Anzahl der Trainingsepochen. In diesem Beispiel gehen wir von zwei Epochen aus
- batch_size: Die Batch-Größe für das Training. Für dieses Beispiel verwenden wir den Wert 4
- learning_rate: Die Lernrate für das Training. Hier geben wir einen Wert von 0.001 an
- Wir sind mit der Bereitstellung der Parameter fertig. Wenn Sie diesen Code ausführen, wird ein fein abgestimmtes Modellobjekt erstellt. Jetzt müssen wir mit dem Training des Gemini LLM beginnen. Hierzu arbeiten wir mit folgendem Code.
Wir sind mit dem Einrichten der Parameter fertig. Durch das Ausführen dieses Codes wird ein optimiertes Modellobjekt erstellt. Jetzt müssen wir mit dem Training des Gemini LLM beginnen. Dazu arbeiten wir mit folgendem Code:
model = genai.get_tuned_model(f'tunedModels/{name}')
print(model)Erstellen eines abgestimmten Modells
Hier verwenden wir die Funktion .get_tuned_model() aus der Genai-Bibliothek, übergeben den Namen unseres definierten Modells und starten den Trainingsprozess. Anschließend drucken wir das Modell aus, wie im Bild unten gezeigt:
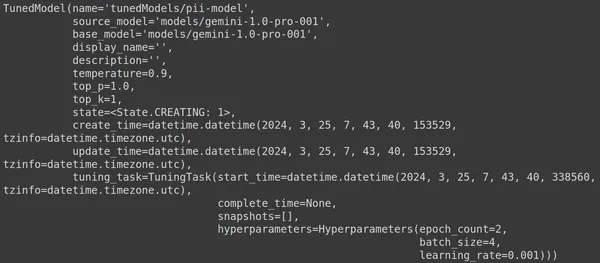
Das Modell ist vom Typ TunedModel. Hier können wir verschiedene Parameter für das von uns definierte Modell beobachten. Sie sind:
- Name: Diese Variable enthält den Namen, den wir für unser optimiertes Modell bereitgestellt haben
- source_model: Dies ist das Quellmodell, das wir optimieren, in unserem Beispiel models/gemini-1.0-pro
- base_model: Dies ist wiederum das Basismodell, das wir optimieren, in unserem Beispiel models/Gemini-1.0-pro. Das Basismodell kann sogar ein zuvor fein abgestimmtes Modell sein. Hier ist es für beide gleich
- display_name: Der Anzeigename für das optimierte Modell
- Beschreibung: Es enthält eine Beschreibung unseres Modells und dessen Inhalt
- Temperatur: Je höher der Wert, desto kreativer werden die Antworten aus dem Large Language Model generiert. Hier ist er standardmäßig auf 0.9 eingestellt
- top_p: Definiert die höchste Wahrscheinlichkeit für die Token-Auswahl beim Generieren von Text. Je mehr top_p, desto mehr Token werden ausgewählt, dh Token werden aus einer größeren Datenstichprobe ausgewählt
- top_k: Es weist darauf hin, dass bei jedem Schritt die k wahrscheinlichsten nächsten Token abgetastet werden sollen. Hier ist top_k 1, was bedeutet, dass der wahrscheinlichste nächste Token ausgewählt wird, dh der Token mit der höchsten Wahrscheinlichkeit wird immer ausgewählt
- Zustand: Der Staat erstellt. Dies impliziert, dass das Modell derzeit verfeinert wird
- create_time: Die Zeit, zu der das Modell erstellt wurde
- update_time: Dies ist die Zeit, zu der das Modell zuletzt optimiert wurde
- tuning_task: Enthält die Parameter, die wir für die Optimierung definiert haben, darunter Temperatur, Epochen und Batch-Größe
Schulungsprozess einleiten
Mit dem folgenden Code können wir sogar den Status und die Metadaten des optimierten Modells abrufen:
print(operation.metadata)
Hier werden die gesamten Schritte angezeigt, also 950, was vorhersehbar ist. Denn in unserem Beispiel haben wir 1900 Zeilen Trainingsdaten. In jedem Schritt nehmen wir einen Stapel von 4, also 4 Zeilen, auf, also haben wir für eine komplette Epoche 1900/4, also 475 Schritte. Wir haben 2 Epochen für das Training festgelegt, was bedeutet, dass 2*475 = 950 Schritte sind.
Überwachung des Schulungsfortschritts
Der folgende Code erstellt eine Statusleiste, die angibt, wie viel Prozent des Trainings abgeschlossen sind und wie lange es dauern wird, bis der gesamte Trainingsprozess abgeschlossen ist:
import time
for status in operation.wait_bar():
time.sleep(30)
Der obige Code erstellt einen Fortschrittsbalken. Wenn er abgeschlossen ist, bedeutet dies, dass unser Optimierungsprozess beendet ist.
Visualisierung der Trainingsleistung
Das Operationsobjekt enthält sogar die Momentaufnahmen des Trainings. Dass es die Bewertungsmetriken wie den „mean_loss“ pro Epoche enthält. Wir können dies mit dem folgenden Code visualisieren:
import pandas as pd
import seaborn as sns
model = operation.result()
snapshots = pd.DataFrame(model.tuning_task.snapshots)
sns.lineplot(data=snapshots, x = 'epoch', y='mean_loss')- Hier erhalten wir das endgültige abgestimmte Modell aus operation.result()
- Wenn wir das Modell trainieren, erstellt das Modell in regelmäßigen Abständen Schnappschüsse. Diese Snapshots enthalten Daten wie den „mean_loss“. Daher extrahieren wir die Snapshots des optimierten Modells, indem wir model.tuning_task.snapshots aufrufen
- Wir erstellen aus diesen Snapshots einen Datenrahmen, indem wir die Snapshots an pd.DataFrame übergeben und sie in der Variablen snapshots speichern
- Abschließend erstellen wir ein Liniendiagramm aus den extrahierten Snapshot-Daten
Das Ausführen des Codes führt zu folgendem Diagramm:
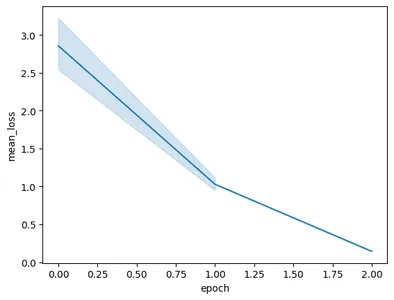
In diesem Bild können wir sehen, dass wir den Verlust in nur zwei Trainingsepochen von 3 auf weniger als 0.5 reduziert haben. Endlich sind wir mit dem Training des Gemini-Modells fertig
Testen des fein abgestimmten Gemini-Modells
In diesem Abschnitt testen wir unser Modell anhand der Testdaten. Um nun mit dem abgestimmten Modell zu arbeiten, arbeiten wir mit dem folgenden Code:
model = genai.GenerativeModel(model_name=f'tunedModels/{name}')Der obige Code lädt das optimierte Modell, das wir gerade mit den personenbezogenen Daten trainiert haben. Nun testen wir dieses Modell anhand einiger Beispiele aus den Testdaten, die wir beiseite gelegt haben. Dazu drucken wir den zufälligen text_input und die entsprechende Ausgabe aus dem Testsatz aus:
print(df_test['text_input'][1900])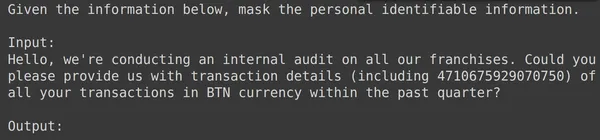
df_test['output'][1900]
Oben sehen wir eine zufällige text_input und die Ausgabe aus dem Testsatz. Jetzt übergeben wir diese Texteingabe an das Modell und beobachten die generierte Ausgabe:
text = df_test['text_input'][1900]
res = model.generate_content(text)
print(res.text)
Wir sehen, dass es dem Modell gelungen ist, die personenbezogenen Daten für den angegebenen text_input zu maskieren, und dass die vom Modell generierte Ausgabe genau mit der Ausgabe des Testsatzes übereinstimmt. Lassen Sie uns das nun anhand einiger weiterer Beispiele ausprobieren:
print(df_test['text_input'][1969])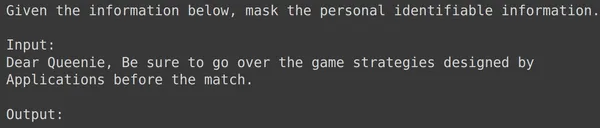
print(df_test['output'][1969])
text = df_test['text_input'][1969]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1987])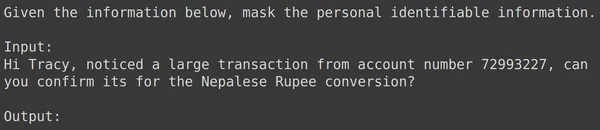
print(df_test['output'][1987])
text = df_test['text_input'][1987]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1933])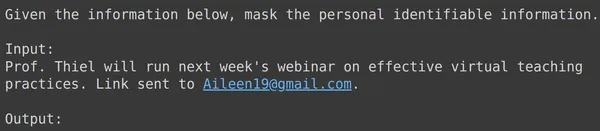
print(df_test['output'][1933])
text = df_test['text_input'][1933]
res = model.generate_content(text)
print(res.text)
Bei allen obigen Beispielen sehen wir, dass die Leistung unseres fein abgestimmten Modells gut ist. Das Modell konnte aus den vorgegebenen Trainingsdaten lernen und die Maskierung korrekt anwenden, um sensible persönliche Informationen zu verbergen. Wir haben also von Anfang bis Ende gesehen, wie man einen Datensatz zur Feinabstimmung erstellt und wie man das Gemini-Modell an einem Datensatz feinabstimmt, und die Ergebnisse, die wir sehen, sehen für ein feinabgestimmtes Modell sehr vielversprechend aus
Zusammenfassung
Zusammenfassend bietet dieser Leitfaden eine umfassende Anleitung zur Feinabstimmung der Flaggschiff-Gemini-Modelle von Google zur Maskierung persönlicher identifizierbarer Informationen (PII). Wir begannen mit der Erkundung des Blogbeitrags von Google über die Feinabstimmungsfunktion für Gemini-Modelle und betonten die Notwendigkeit einer Feinabstimmung dieser Modelle, um aufgabenspezifische Genauigkeit zu erreichen. Durch die im Leitfaden beschriebenen praktischen Schritte, einschließlich der Vorbereitung von Datensätzen, der Feinabstimmung des Gemini-Modells und dem Testen seiner Leistung, können Benutzer die Leistungsfähigkeit großer Sprachmodelle für PII-Maskierungsaufgaben nutzen.
Hier sind die wichtigsten Erkenntnisse aus diesem Leitfaden:
- Gemini-Modelle bieten eine leistungsstarke Bibliothek zur Feinabstimmung, die es Benutzern ermöglicht, sie durch Parameter-Efficient Tuning (PET) an bestimmte Aufgaben anzupassen, einschließlich PII-Maskierung.
- Die Vorbereitung des Datensatzes ist ein entscheidender Schritt. Dazu gehören die Installation der erforderlichen Module, die Initiierung von OAuth für die Datensicherheit und die Formatierung der Daten für das Training
- Der Feinabstimmungsprozess umfasst die Bereitstellung von Parametern wie dem Basismodell, der Epochenanzahl, der Stapelgröße und der Lernrate, um das Gemini-Modell auf dem vorbereiteten Datensatz zu trainieren
- Die Überwachung des Trainingsfortschritts wird durch Statusaktualisierungen und Visualisierungen von Metriken wie dem mittleren Verlust pro Epoche erleichtert
- Das Testen des fein abgestimmten Modells an einem separaten Testdatensatz überprüft seine Leistung bei der genauen Maskierung personenbezogener Daten und gleichzeitiger Wahrung der Datenintegrität
- Die bereitgestellten Beispiele veranschaulichen die Wirksamkeit des fein abgestimmten Gemini-Modells bei der erfolgreichen Maskierung sensibler persönlicher Informationen und weisen auf vielversprechende Ergebnisse für reale Anwendungen hin
Häufig gestellte Fragen
A. Parameter Efficient Tuning (PET) ist eine der Feinabstimmungstechniken, die nur einen kleinen Satz Parameter des Modells feinabstimmt. Dies wird von Google genutzt, um wichtige Schichten im Gemini-Modell schnell zu verfeinern. Es passt das Modell effizient an die Daten des Benutzers an und verbessert so seine Leistung für bestimmte Aufgaben
A. Die Optimierung eines Gemini-Modells umfasst die Bereitstellung von Parametern wie dem Namen des Basismodells, der Epochenanzahl, der Stapelgröße und der Lernrate. Diese Parameter beeinflussen den Trainingsprozess und wirken sich letztendlich auf die Leistung des Modells aus
A. Benutzer können den Trainingsfortschritt eines fein abgestimmten Gemini-Modells durch Statusaktualisierungen, Visualisierungen von Metriken wie dem mittleren Verlust pro Epoche und durch die Beobachtung von Schnappschüssen des Trainingsprozesses überwachen
A. Vor der Feinabstimmung eines Gemini-Modells müssen Benutzer die erforderlichen Bibliotheken wie google-generativeai und datasets installieren. Darüber hinaus sind die Initiierung von OAuth für die Datensicherheit und die Formatierung des Datensatzes für das Training wichtige Schritte
A. Ein fein abgestimmtes Gemini-Modell kann in verschiedenen Bereichen angewendet werden, in denen eine PII-Maskierung erforderlich ist, z. B. Datenanonymisierung, Wahrung der Privatsphäre in NLP-Anwendungen und Einhaltung von Datenschutzbestimmungen wie der DSGVO
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/03/guide-to-fine-tuning-gemini-for-masking-pii-data/

