Dieser Artikel wurde als Teil des veröffentlicht Data-Science-Blogathon.
Deep Learning ist eine Teilmenge des maschinellen Lernens. Deep Learning basiert auf künstlichen neuronalen Netzen, um das menschliche Gehirn nachzuahmen. Beim Deep Learning fügen wir mehrere verborgene Schichten hinzu, um die kleinsten Details zu sammeln, um die Daten für die Vorhersagemodellierung zu lernen.
Deep Learning: Mangelnde Rechenleistung war nicht jedermanns Sache. Angesichts der heutigen exponentiellen Zunahme der Rechenleistung ist die Implementierung von Deep Learning ein Hype.
Deep Belief Networks, Deep Neural Networks und Recurrent Neural Networks sind einige der Deep-Learning-Modelle. In diesem Artikel werden wir drei Modelle vergleichen, nämlich CNN (Convolution Neural Network), DNN (Deep Neural Network) und LSTM (Long Short-Term Memory).
Da der MNIST-Datensatz der beste Weg ist, um mit der Arbeit und dem Üben von bildbasierten Datensätzen zu beginnen, soll die Anwendung dieses Algorithmus in einem medizinischen Bild einen Schritt nach vorne machen, indem er Anzeichen klassifiziert und vorhersagt. Die folgende praktische Umsetzung zeigt die breite Verwendbarkeit, Bilddatensätze in allen Umfang zu bearbeiten, umzusetzen und zu üben.
Datensatzbestätigung
Hier verwenden wir den MNIST-Datensatz handgeschriebener Ziffern von 0 bis 9. Dieser Datensatz wird in zwei Teile aufgeteilt, dh den Trainingssatz und den Testsatz für die Vorhersage. Mithilfe der sklearn-Bibliothek wird der MNIST-Datensatz in das Jupyter-Notebook importiert.

Quelle: https://en.wikipedia.org/wiki/MNIST_database
Sytemimplementierung
Die Implementierung erfolgt im Jupyter Notizbuch. Die gesamte Implementierung ist auf meiner verfügbar Kaggle. Der Link ist unten erwähnt:
Notebook-Link: https://www.kaggle.com/code/shibumohapatra/cnn-dnn-lstm-comparison
Bibliotheken Voraussetzungen
Zunächst importieren wir Bibliotheken für den Algorithmus. Bibliotheken und ihre Verwendung werden im Folgenden erwähnt:
- Numpy: mit Arrays zu arbeiten
- Pandas: Datenverarbeitung
- TensorFlow: Modellverfolgung für die Vorhersage
- matplotlib: Diagramme zu zeichnen
- Keras: API für TensorFlow
- Tensorflow.keras.models: um ein Modell für maschinelles Lernen zu erstellen. Wir importieren Sequential (ein Schichtenstapel mit nur einem Eingabetensor und einem Ausgabetensor).
- Sklearn.Modell: um die Daten in einen Trainingssatz und einen Testsatz aufzuteilen
- Tensorflow.keras.layers: Import verschiedener Ebenen zur Implementierung von Deep Learning. Die Beschreibung der Schichten ist unten erwähnt –
-
- Dicht: Erstellen von neuronalen Feed-Forward-Netzen, was bedeutet, dass jede Eingabe und jede Ausgabe wechselseitig abhängig sind.
- Ebnen: Serialisierung mehrdimensionaler Tensoren.
- Ausfallen: um eine Überanpassung zu verhindern.
- conv2D: eine 2D-Faltungsschicht, um die Beziehung zwischen Pixeln von Bilddaten aufrechtzuerhalten.
- MaxPooling2D: reduzieren die räumlichen s
aus tensorflow.keras.models import Sequential aus tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout, LSTM aus tensorflow.keras.utils import normalize aus sklearn.model_selection import train_test_split
Datenexploration
Hier laden wir die MNIST-Daten und teilen sie in 4 Sets train_x, train_y, test_x und test_y auf. Danach werden wir die Sätze train_x und test_x normalisieren und ihre jeweiligen Datenformen drucken. Dann zeigen wir den Datensatz an, um sicherzustellen, dass die Exploration richtig ist. Ich habe eine for-Schleife implementiert, um 4 Bilder des Datensatzes zu zeichnen.
aus keras.datasets import mnist (train_x, train_y), (test_x, test_y) = mnist.load_data()

train_x = train_x.astype('float32') test_x = test_x.astype('float32') train_x /= 255 test_x /= 255 train_x = train_x.reshape(train_x.shape[0], 28, 28, 1) test_x = test_x .reshape(test_x.form)
# train set print("Die Form von train_x set ist:",train_x.shape) print("Die Form von train_y set ist:",train_y.shape)

Trainieren Sie die Form des MNIST-Datensatzes
# test set print("Die Form von test_x set ist:",test_x.shape) print("Die Form von test_y set ist:",test_y.shape)

Der Test hat die Form des MNIST-Datensatzes festgelegt
für i in range(1): plt.subplot(330 + 1 + i) plt.imshow(train_x[i].reshape(28,28), cmap=plt.get_cmap('gray')) plt.axis(' aus') plt.show()
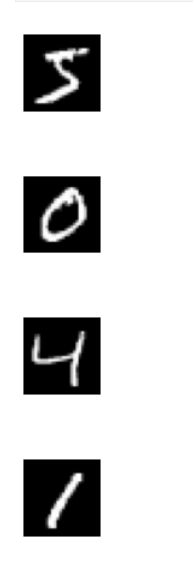
Die ersten vier handschriftlichen Ziffern aus dem MNIST-Datensatz
Daten werden geladen
Sobald wir die Datenexploration weiter implementiert haben, müssen wir den MNIST-Datensatz laden und ihn in 4 Teile x_train, y_train, x_test und y_test unterteilen. Normalisieren Sie dann seinen Trainings- und Testsatz, um seine Integrität zu wahren. Und geben Sie dann die normalisierten Zug- und Testsätze zurück.
Laden von Daten für DNN und RNN (LSTM)
Wir werden die Daten für DNN und RNN (LSTM) mit der Funktion def load_data_NN() laden, den Datensatz laden und die Normalisierung durchführen.
def load_data_NN(): # mnist-Datensatz laden mnist = tf.keras.datasets.mnist # 28 x 28 Bilder von 0-9 (x_train, y_train), (x_test, y_test) = mnist.load_data() # Daten normalisieren x_train = normalisieren (x_train, Achse = 1) x_test = normalize(x_test, Achse = 1) gibt x_train, y_train, x_test, y_test zurück
Laden
Für CNN definieren wir die Funktion def load_data_CNN(), laden den Datensatz auf und formen die Zug- und Testsätze um.
Bei CNN besteht die Notwendigkeit der Umformung darin, dass es eine Faltungsschicht, Max-Pooling, Abflachung und dichte Schichten enthält. Hier werden Zug- und Testsätze in 28 x 28 x 1 (28 Zeilen, 28 Spalten, 1 Farbkanal) umgeformt.
def load_data_CNN(): # mnist-Datensatz laden mnist1 = tf.keras.datasets.mnist # 28 x 28 Bilder von 0-9 (x_train, y_train), (x_test, y_test) = mnist1.load_data() # Daten umformen x_train = x_train .reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1) # Konvertiere von Ganzzahlen in Floats x_train = x_train.astype('float32' ) x_test = x_test.astype('float32') # Daten normalisieren x_train = normalize(x_train, axis = 1) x_test = normalize(x_test, axis = 1) x_train, y_train, x_test, y_test zurückgeben
Modell 1 definieren – DNN (Deep Neural Network)
DNN basiert auf künstlichen neuronalen Netzen und hat mehrere versteckte Schichten zwischen der Eingabe- und Ausgabeschicht. DNN ist kompetent in der Modellierung komplexer nichtlinearer Zusammenhänge. Hier besteht der Hauptzweck darin, Eingaben zu machen, progressive Berechnungen auf der Eingabeschicht zu implementieren und die Ausgabe anzuzeigen oder zu präsentieren, um Probleme zu lösen. Deep Neural Networks (DNNs) gelten als Feed-Forward-Netzwerke, in denen Daten von der Eingabeschicht zur Ausgabeschicht fließen, ohne rückwärts zu gehen, und die Verbindungen zwischen den Schichten unidirektional sind. Dies bedeutet, dass dieser Prozess fortgesetzt wird, ohne den Knoten erneut zu berühren.
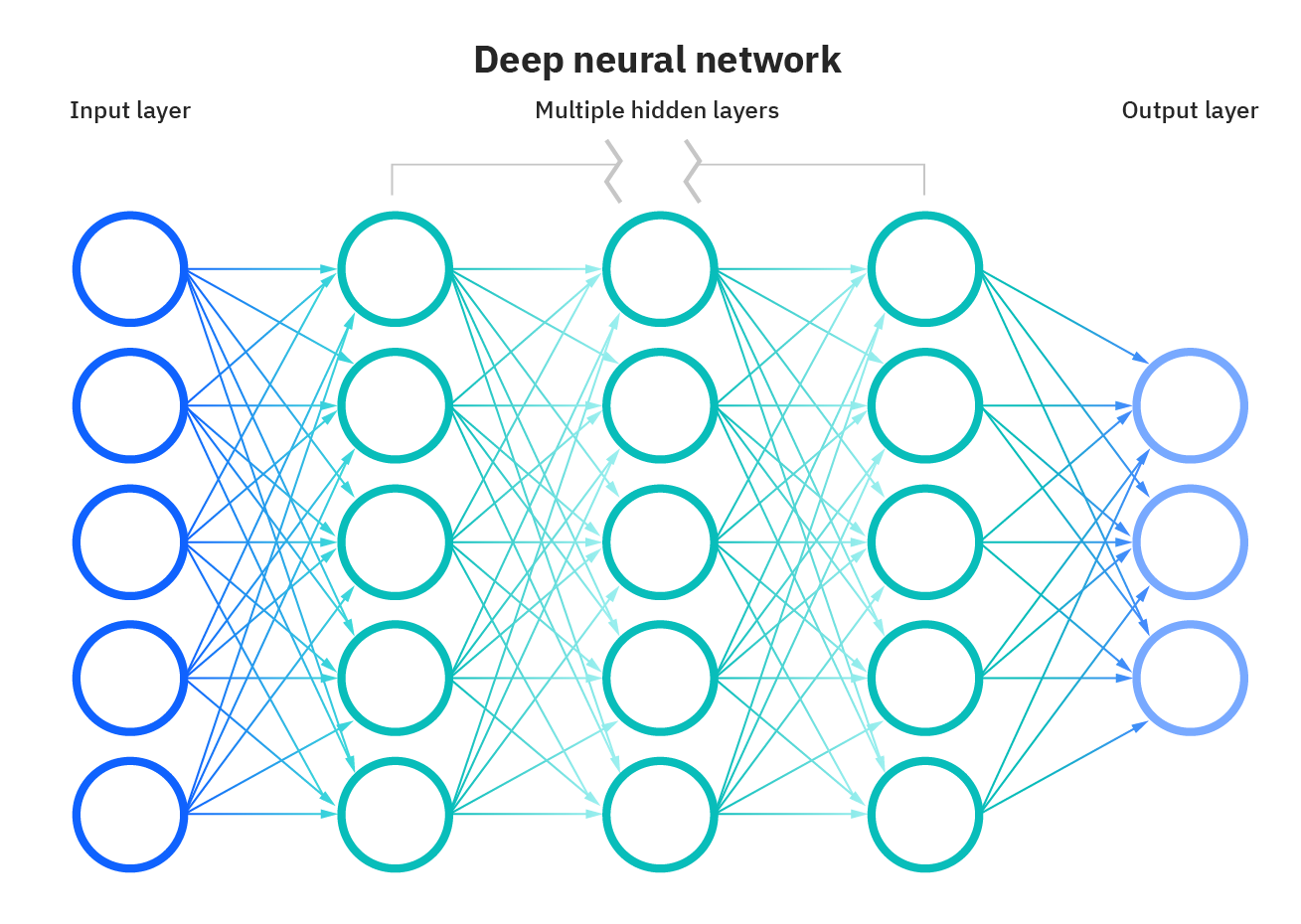
Quelle: https://www.ibm.com/cloud/learn/neural-networks
Für das DNN sind sequentielle, abgeflachte und 3 dichte Schichten implementiert. Ich habe 128 Knoten und eine ReLU-Aktivierungsfunktion für die ersten beiden dichten Schichten. Für die dritte dichte Schicht habe ich 10 Knoten und eine Softmax-Aktivierungsfunktion definiert.
def DNN(): model_dnn = Sequential() model_dnn.add(Flatten()) # Eingabeschicht model_dnn.add(Dense(128, activation = 'relu')) model_dnn.add(Dense(128, activation = 'relu') ) model_dnn.add(Dense(10, activation = 'softmax')) model_dnn.compile(optimizer= "adam", loss= "sparse_categorical_crossentropy", metrics=["accuracy"]) return model_dnn
Beim Kompilieren des DNN-Modells habe ich den Adam-Optimierer und die Sparse-Kategorie-Cross-Entropie-Verlustfunktionen (mehrklassige Kategorisierungsmodelle, bei denen dem Ausgabelabel ein ganzzahliger Wert zugewiesen wird) verwendet. Die Genauigkeit des Modells bestimmt die Metriken.
Modell 2 definieren – RNN (LSTM)
RNN ist eine Kurzform von Recurrent Neural Network, das für die Arbeit mit Zeitreihendaten oder Sequenzdaten angepasst ist.
Hier werden wir LSTM implementieren, das als RNN gilt. LSTMs (Long Short-Term Memory) sind eine besondere Art von RNN, die in der Lage sind, langfristige Abhängigkeiten zu lernen, was RNN dazu bringt, sich an Dinge zu erinnern, die in der Vergangenheit passiert sind, um die nächste Schätzung sinnvoll zu machen.
Die Verwendung von LSTM löst das Problem der langfristigen Abhängigkeiten von RNNs. Das RNN konnte das Wort nicht in langfristigen Abhängigkeiten speichern, aber basierend auf neueren Informationen konnte das RNN genauere Vorhersagen treffen. Aber aufgrund der Zunahme der Lückenlänge liefert RNN keine optimale Leistung. Die Lösung hierfür bietet LSTM, das die Informationen für einen langen Zeitraum aufbewahrt, wodurch der Datenverlust verringert wird. Die Anwendungen von LSTM werden zur Klassifizierung von Zeitreihendaten und Vorhersagen verwendet.
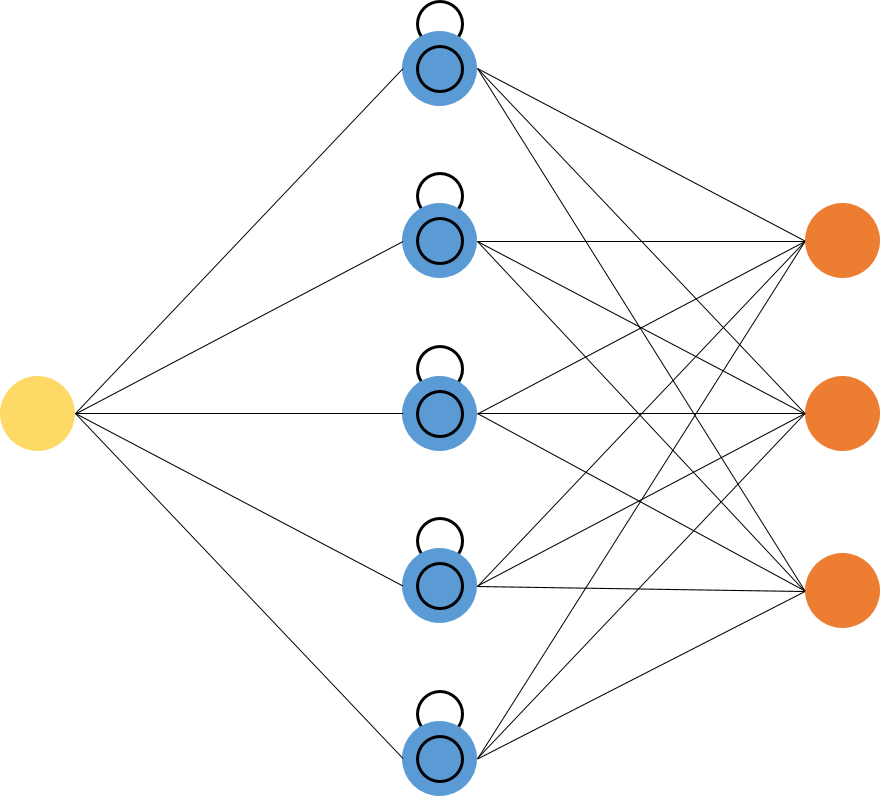
Quelle: https://i.stack.imgur.com/h8HEm.png
Wie für DNN (LSTM) – LSTM-Layer, sequentiell, Dropout-Layer (lässt 0.2 von 20 % der Knoten aus, um eine Überanpassung zu verhindern) und Dense Layer. Die oben genannten Schichten haben ReLU- und Softmax-Aktivierungsfunktionen. Beim Kompilieren des LSTM-Modells habe ich den Adam-Optimierer und die Verlustfunktion (spärliche kategoriale Kreuzentropie) verwendet. Die Genauigkeit des Modells bestimmt die Metriken.
def RNN(input_shape): model_rnn = Sequential() model_rnn.add(LSTM(128, input_shape=input_shape, activation = 'relu', return_sequences=True)) model_rnn.add(Dropout(0.2)) model_rnn.add(LSTM(128 , input_shape=input_shape, activation = 'relu')) model_rnn.add(Dropout(0.2)) model_rnn.add(Dense(32, activation = 'relu')) model_rnn.add(Dropout(0.2)) model_rnn.add(Dense (10, Aktivierung = 'softmax')) model_rnn.compile(optimizer= "adam", loss= "sparse_categorical_crossentropy", metrics=["accuracy"]) gibt model_rnn zurück
Modell 3 definieren – CNN (Convolution Neural Network)
CNN ist eine Kategorie von künstlichen neuronalen Netzen. Beim Deep Learning wird CNN ausgiebig zur Objekterkennung und -kategorisierung verwendet. Mithilfe von CNN erkennt Deep Learning Objekte in einem Bild. Convolutional Neural Networks (CNN oder ConvNet) ist eine Klasse tiefer neuronaler Netzwerke, die am häufigsten zur Analyse visueller Bilder verwendet werden. Die Anwendungen von CNNs sind Videoverständnis, Spracherkennung und NLP-Verständnis. Das CNN hat eine Eingabeschicht, eine Ausgabeschicht, eine oder viele verborgene Schichten und Tonnen von Parametern, die es CNN ermöglichen, komplizierte Muster und Objekte zu lernen.
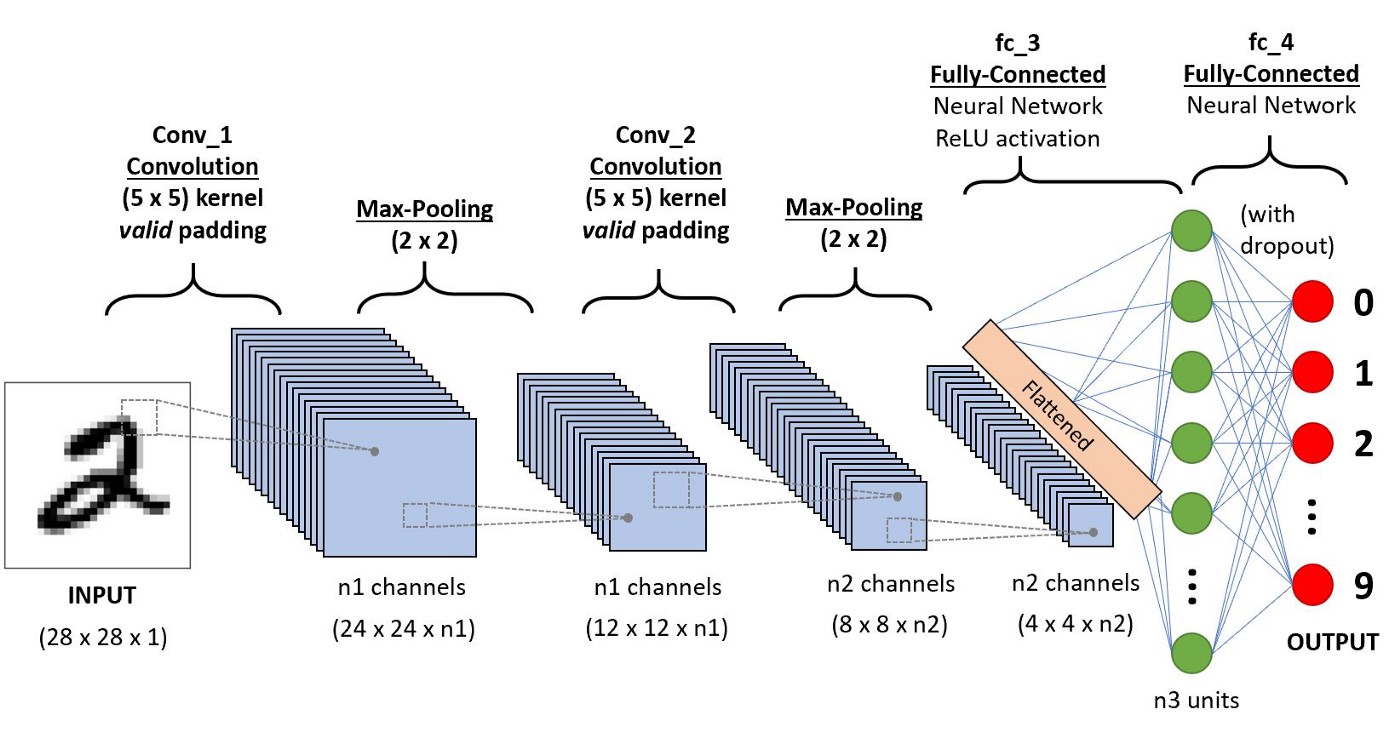
Quelle: https://miro.medium.com/max/1400/1*uAeANQIOQPqWZnnuH-VEyw.jpeg
Für CNN folgen wir dem Sequential und fügen die Conv2D-Schicht, die MaxPooling2D-Schicht und die Dense-Schicht hinzu. ReLU- und Softmax-Aktivierungsfunktionen ähneln den oben genannten Modellen. Beim Kompilieren des LSTM-Modells habe ich den Adam-Optimierer und die Verlustfunktion (spärliche kategoriale Kreuzentropie) verwendet. Die Genauigkeit des Modells bestimmt die Metriken.
def CNN(input_shape): model_cnn = Sequential() model_cnn.add(Conv2D(32, (3,3), input_shape = input_shape)) model_cnn.add(MaxPooling2D(pool_size=(2,2))) model_cnn.add(Flatten ()) # konvertiert 3D-Feature-Maps in 3D-Feature-Vektoren model_cnn.add(Dense(100, activation='relu')) model_cnn.add(Dense(10, activation='softmax')) model_cnn.compile(loss="sparse_categorical_crossentropy ", optimizer="adam", metrics=["accuracy"]) gibt model_cnn zurück
Vorhersagephase
Die folgende Implementierung hilft uns, die vorhergesagte Ausgabe eines bestimmten oder eindeutigen Index des Bilddatensatzes vorherzusagen und zu überprüfen.
Jetzt können wir den Datensatz mit unseren erstellten Modellen trainieren und testen.
def sample_prediction(index): plt.imshow(x_test[index].reshape(28, 28),cmap='Greys') pred = model.predict(x_test[index].reshape(1, 28, 28, 1)) print(np.argmax(pred))
DNN-Modellvorhersage
Damit DNN zuerst vorhersagen kann, laden wir die Funktion load_data_NN(), laden und passen das Modell mit 5 Epochen an. Nach dieser Modellbewertung und dem Test wird die Genauigkeit erfasst, und schließlich definieren wir ein Beispielbild, um zu überprüfen, ob das Modell das Bild mit maximaler Genauigkeit vorhersagt.
if __name__ == "__main__": # Daten laden x_train, y_train, x_test, y_test = load_data_NN() # Modell laden model = DNN() print("nnModel Trainingn") model.fit(x_train, y_train, epochs = 5) print("nnModel Evaluationn") model.evaluate(x_test, y_test) score1 = model.evaluate(x_test, y_test, verbose=1) print('n''DNN-Modelltestgenauigkeit:', score1[1]) print(" nnBeispielvorhersage") sample_prediction(20)
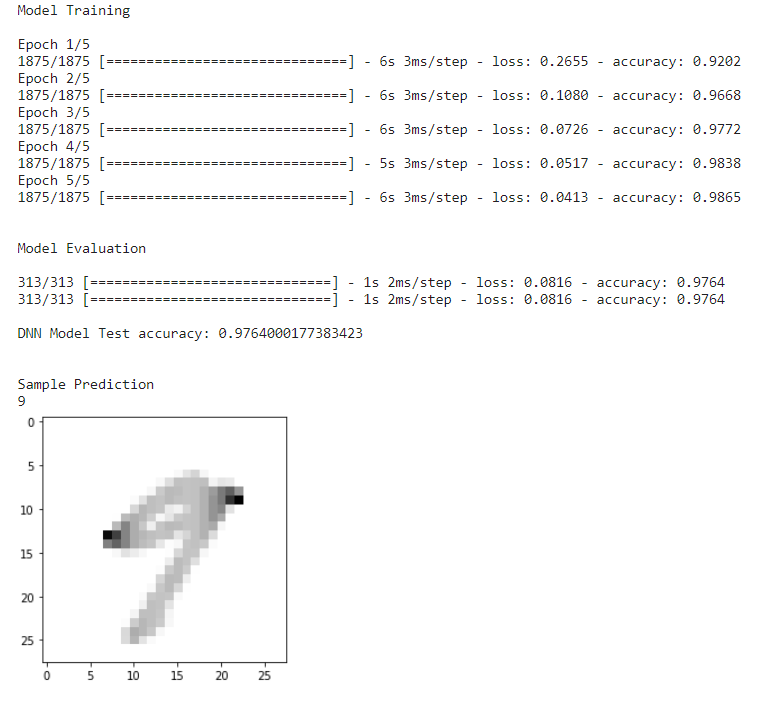
DNN-Modellvorhersage
RNN (LSTM) Modellvorhersage
Der Ansatz für RNN (LSTM) und DNN ist für das Modell gleich.
if __name__ == "__main__": # Daten laden x_train, y_train, x_test, y_test = load_data_NN() # Modell laden model = RNN(x_train.shape[1:]) print("nnModel Trainingn") model.fit(x_train, y_train, epochs = 5) print("nnModel Evaluationn") model.evaluate(x_test, y_test) score2 = model.evaluate(x_test, y_test, verbose=1) print('n''RNN (LSTM) Model Test precision:' , Punktzahl2[1])
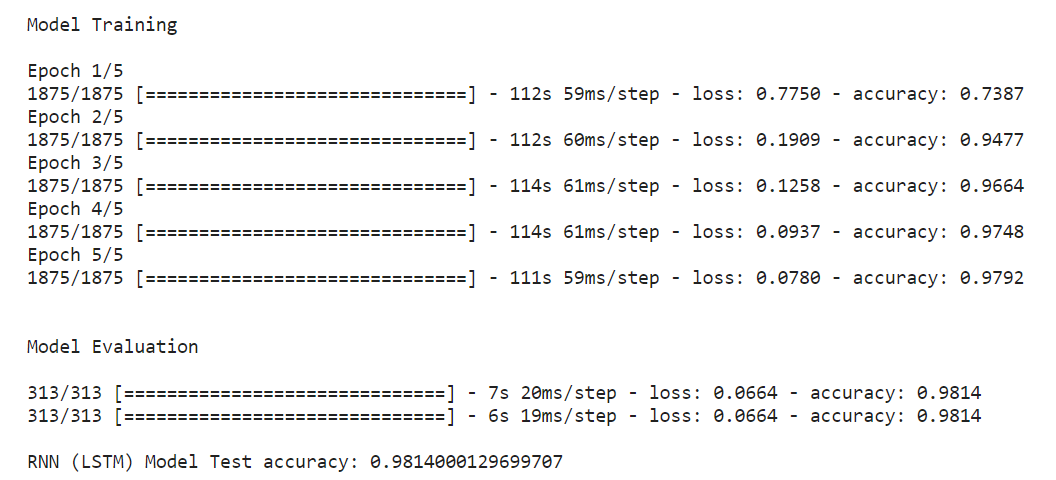
RNN (LSTM) Modellvorhersage
CNN-Modellvorhersage
Für CNN laden wir die Funktion load_data_CNN(); Die CNN-Funktion unterscheidet sich von den anderen beiden, da sie eine Faltungsschicht, Dichte, Abflachung usw. hat. Zusammen mit dem Zug- und Testsatz hat sie auch unterschiedliche Größen. Diese maßgeschneiderte Funktion ist für CNN von Vorteil.
if __name__ == "__main__": # Daten laden x_train, y_train, x_test, y_test = load_data_CNN() # Modell laden input_shape = (28,28,1) model = CNN(input_shape) print("nnModel Trainingn") model.fit (x_train, y_train, epochs = 5) print("nnModel Evaluationn") model.evaluate(x_test, y_test) score3 = model.evaluate(x_test, y_test, verbose=1) print('n''CNN Model Test precision:' , score3[1]) print("nnBeispielvorhersage") sample_prediction(20)
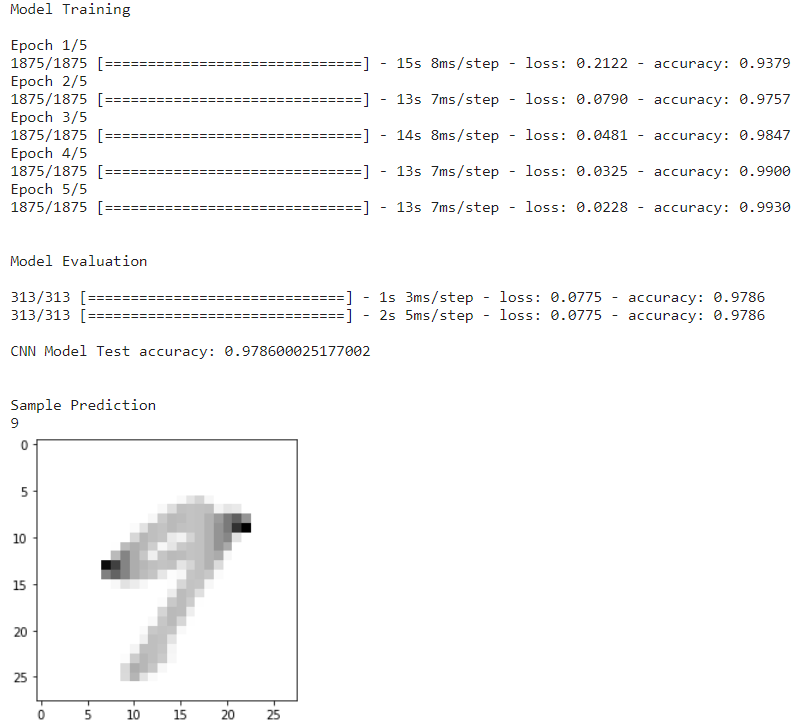
CNN-Modellvorhersage
Nach dem Laden der CNN-Funktion besteht die nächste darin, das Modell mit 5 Epochen anzupassen. Nach dieser Modellbewertung und diesem Test wird die Genauigkeit erlangt und wird ein Mustereingangsbild zum Vorhersagen des Bildes liefern.
Modellgenauigkeiten vergleichen
Nach der Implementierung von drei Modellen und der Erfassung ihrer Punktzahlen ist ein Vergleich dieser Modelle ein Muss, um zu einer endgültigen Aussage zu gelangen. Der unten erwähnte Code stellt ein Tabellenformat dar, das die Modelle von der besten bis zur geringsten Genauigkeit angibt.
Der Code besagt, dass er die Modelle und ihre Genauigkeiten in einem Array-Format aufruft, sie in absteigender Reihenfolge sortiert und die Ausgabe im Tabellenformat anzeigt.
results=pd.DataFrame({'Model':['DNN','RNN (LSTM)','CNN'], 'Genauigkeitspunktzahl':[Punktzahl1[1],Punktzahl2[1],Punktzahl3[1]]} ) result_df=results.sort_values(by='Genauigkeitswert', aufsteigend=False) result_df=result_df.set_index('Model') result_df
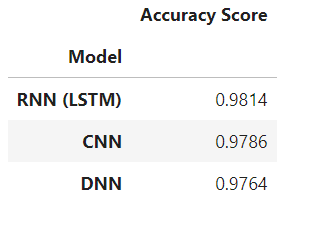
Tabelle der Modellgenauigkeiten
Die oben erstellte Tabelle besagt, dass das RNN (LSTM) die Vorhersage mit einem maximalen Genauigkeitswert anführt, während das CNN auf 2 liegtnd Ort und DNN hat die geringste Genauigkeitsbewertung.
Zusammenfassung
Um die gesamte Ausführung zusammenzufassen:
- Wir haben Bibliotheken importiert. Erkundet und geladen Datensatz, indem Sie einige der Bilder plotten.
- Dann haben wir zwei maßgeschneiderte Funktionen für DNN, RNN (LSTM) und CNN definiert.
- Wir haben Algorithmen für jedes der Deep-Learning-Modelle implementiert.
- Danach begannen wir mit der Vorhersagephase für alle Deep-Learning-Modelle.
- Zuletzt haben wir eine Vergleichstabelle erstellt, um zu erfahren, welche Deep-Learning-Modelle für die Vorhersage von MNIST-Datensätzen geeignet sind.
Somit ist das RNN (LSTM)-Modell der Gewinner in der gesamten Implementierung und erzielte 98.54 %. Das CNN-Modell erhielt 2nd Platz mit 98.08 % und das DNN-Modell auf Platz 3rd Platz mit 97.21 %. Die wichtigsten Erkenntnisse aus der abschließenden Vergleichstabelle sind:
- Durch die schnelle Implementierungszeit erfordert das CNN-Modell weniger Parameter für das Training, und die Modellleistung bleibt erhalten.
- Bei einer schnelleren Ausführung erfordert das DNN-Modell die meisten Parameter für das Training, aber die Modellleistung wird durch weniger Genauigkeit beeinträchtigt.
- Mit der langsamsten Ausführungszeit schnitt der LSTM besser ab als die beiden anderen. Dies kommt dem LSTM zugute, um eine bessere Leistung zu zeigen.
- Daher können wir mit der obigen Implementierung schließen, dass das LSTM-Modell für Deep Learning geeignet ist, um mit MNIST und anderen Bilddatensätzen zu arbeiten.
Hoffentlich hilft Ihnen dieser Artikel zu verstehen, wie Sie geeignete Deep-Learning-Modelle auswählen. Vielen Dank.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- Coinsmart. Europas beste Bitcoin- und Krypto-Börse.Mehr Info
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2022/11/analyzing-and-comparing-deep-learning-models/

