Image by Freepik
Language models have revolutionized the field of natural language processing. While large models like GPT-3 have grabbed headlines, small language models are also advantageous and accessible for various applications. In this article, we will explore the importance and use cases of small language models with all the implementation steps in detail.
Small language models are compact versions of their larger counterparts. They offer several advantages. Some of the advantages are as follows:
- Efficiency: Compared to large models, small models require less computational power, making them suitable for environments with constrained resources.
- Speed: They can do the computation faster, such as generating the texts based on given input more quickly, making them ideal for real-time applications where you can have high daily traffic.
- Customization: You can fine-tune small models based on your requirements for domain-specific tasks.
- Privacy: Smaller models can be used without external servers, which ensures data privacy and integrity.
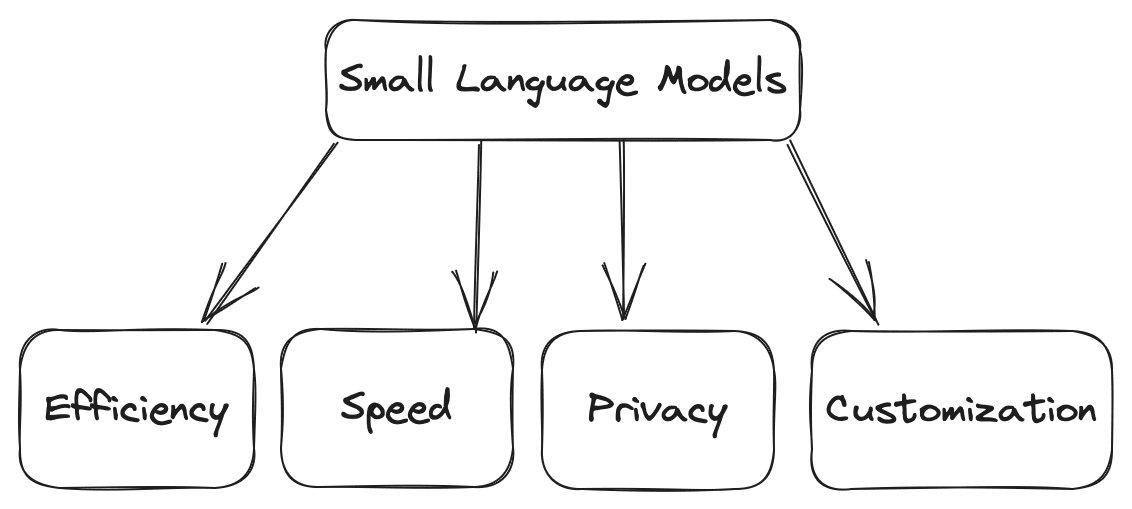
Image by Author
Several use cases for small language models include chatbots, content generation, sentiment analysis, question-answering, and many more.
Before we start deep diving into the working of small language models, you need to set up your environment, which involves installing the necessary libraries and dependencies. Selecting the right frameworks and libraries to build a language model on your local CPU becomes crucial. Popular choices include Python-based libraries like TensorFlow and PyTorch. These frameworks provide many pre-built tools and resources for machine learning and deep learning-based applications.
Installing Required Libraries
In this step, we will install the “llama-cpp-python” and ctransformers library to introduce you to small language models. You must open your terminal and run the following commands to install it. While running the following commands, ensure you have Python and pip installed on your system.
pip install llama-cpp-python
pip install ctransformers -q
Output:

Now that our environment is ready, we can get a pre-trained small language model for local use. For a small language model, we can consider simpler architectures like LSTM or GRU, which are computationally less intensive than more complex models like transformers. You can also use pre-trained word embeddings to enhance your model’s performance while reducing the training time. But for quick working, we will download a pre-trained model from the web.
Downloading a Pre-trained Model
You can find pretrained small language models on platforms like Hugging Face (https://huggingface.co/models). Here is a quick tour of the website, where you can easily observe the sequences of models provided, which you can download easily by logging into the application as these are open-source.
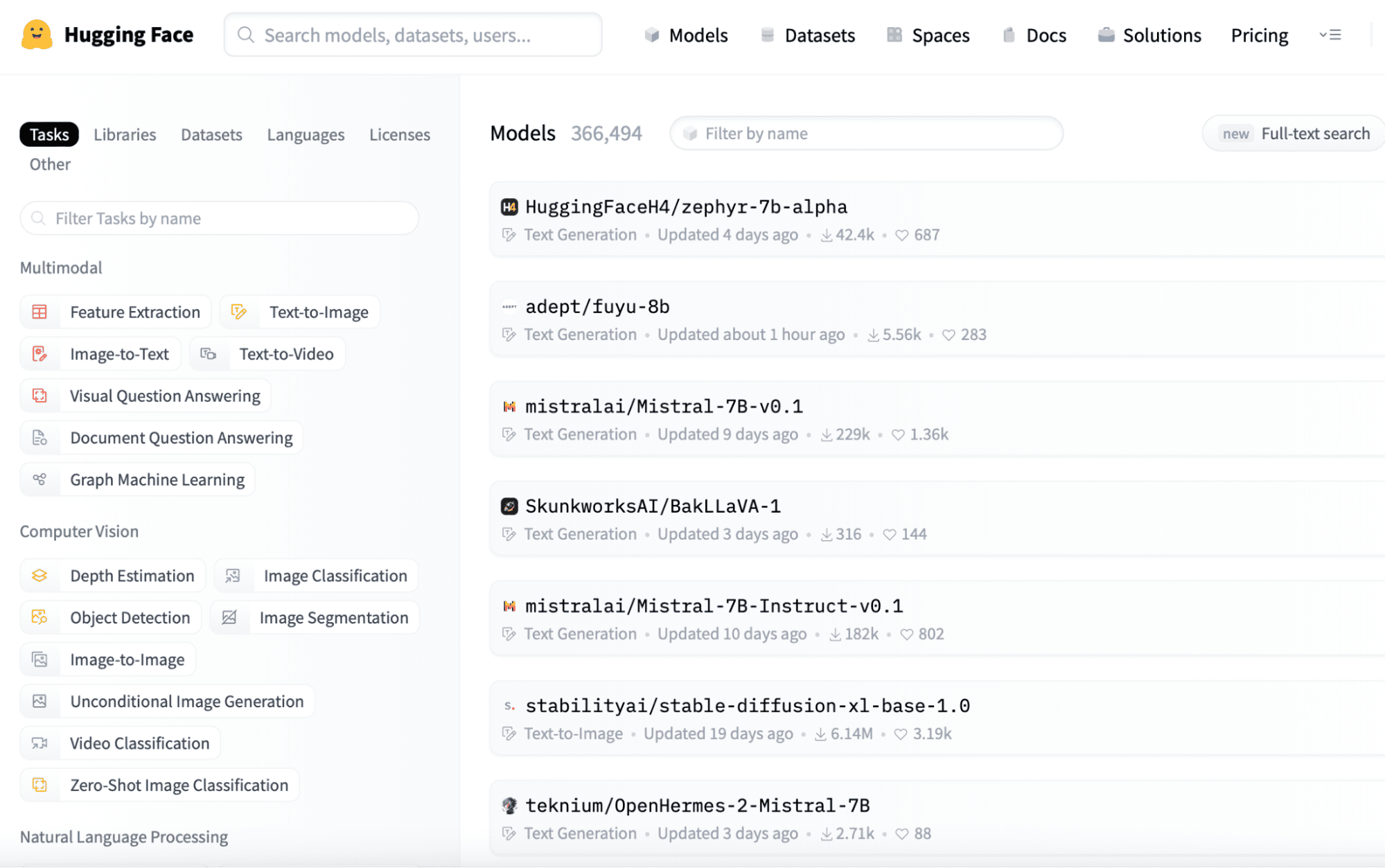
You can easily download the model you need from this link and save it to your local directory for further use.
from ctransformers import AutoModelForCausalLMIn the above step, we have finalized the pre-trained model from Hugging Face. Now, we can use that model by loading it into our environment. We import the AutoModelForCausalLM class from the ctransformers library in the code below. This class can be used for loading and working with models for causal language modeling.
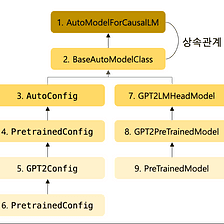
Image from Medium
# Load the pretrained model
llm = AutoModelForCausalLM.from_pretrained('TheBloke/Llama-2-7B-Chat-GGML', model_file = 'llama-2-7b-chat.ggmlv3.q4_K_S.bin' )
Output:

Small language models can be fine-tuned based on your specific needs. If you have to use these models in real-life applications, the main thing to remember is efficiency and scalability. So, to make the small language models efficient compared to large language models, you can adjust the context size and batching(partition data into smaller batches for faster computation), which also results in overcoming the scalability problem.
Modifying Context Size
The context size determines how much text the model considers. Based on your need, you can choose the value of context size. In this example, we will set the value of this hyperparameter as 128 tokens.
model.set_context_size(128)Batching for Efficiency
By introducing the batching technique, it is possible to process multiple data segments simultaneously, which can handle the queries parallely and help scale the application for a large set of users. But while deciding the batch size, you must carefully check your system’s capabilities. Otherwise, your system can cause issues due to heavy load.
model.set_batch_size(16)Up to this step, we are done with making the model, tuning that model, and saving it. Now, we can quickly test it based on our use and check whether it provides the same output we expect. So, let’s give some input queries and generate the text based on our loaded and configured model.
for word in llm('Explain something about Kdnuggets', stream = True): print(word, end='')
Output:

To get the appropriate results for most of the input queries out of your small language model, the following things can be considered.
- Fine-Tuning: If your application demands high performance, i.e., the output of the queries to be resolved in significantly less time, then you have to fine-tune your model on your specific dataset, the corpus on which you are training your model.
- Caching: By using the caching technique, you can store commonly used data based on the user in RAM so that when the user demands that data again, it can easily be provided instead of fetching again from the disk, which requires relatively more time, due to which it can generate results to speed up future requests.
- Common Issues: If you encounter problems while creating, loading, and configuring the model, you can refer to the documentation and user community for troubleshooting tips.
In this article, we discussed how you can create and deploy a small language model on your local CPU by following the seven straightforward steps outlined in this article. This cost-effective approach opens the door to various language processing or computer vision applications and serves as a stepping stone for more advanced projects. But while working on projects, you have to remember the following things to overcome any issues:
- Regularly save checkpoints during training to ensure you can continue training or recover your model in case of interruptions.
- Optimize your code and data pipelines for efficient memory usage, especially when working on a local CPU.
- Consider using GPU acceleration or cloud-based resources if you need to scale up your model in the future.
In conclusion, small language models offer a versatile and efficient solution for various language processing tasks. With the correct setup and optimization, you can leverage their power effectively.
Aryan Garg is a B.Tech. Electrical Engineering student, currently in the final year of his undergrad. His interest lies in the field of Web Development and Machine Learning. He have pursued this interest and am eager to work more in these directions.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.kdnuggets.com/7-steps-to-running-a-small-language-model-on-a-local-cpu?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-running-a-small-language-model-on-a-local-cpu

