Hình ảnh của Tác giả
Khi làm việc với các mô hình, bạn cần nhớ rằng các thuật toán khác nhau có các kiểu học khác nhau khi lấy dữ liệu. Đây là một hình thức học trực quan, giúp mô hình học các mẫu trong tập dữ liệu đã cho, được gọi là đào tạo mô hình.
Sau đó, mô hình sẽ được thử nghiệm trên tập dữ liệu thử nghiệm, một tập dữ liệu mà mô hình chưa từng thấy trước đây. Bạn muốn đạt được mức hiệu suất tối ưu trong đó mô hình có thể tạo ra kết quả đầu ra chính xác trên cả tập dữ liệu huấn luyện và kiểm tra.
Bạn cũng có thể đã nghe nói về bộ xác thực. Đây là phương pháp chia tập dữ liệu của bạn thành hai: tập dữ liệu huấn luyện và tập dữ liệu thử nghiệm. Lần phân tách dữ liệu đầu tiên sẽ được sử dụng để huấn luyện mô hình, trong khi lần phân chia dữ liệu thứ hai sẽ được sử dụng để kiểm tra mô hình.
Tuy nhiên, phương pháp thiết lập xác thực đi kèm với nhược điểm.
Mô hình sẽ học được tất cả các mẫu trong tập dữ liệu huấn luyện, nhưng nó có thể đã bỏ sót thông tin liên quan trong tập dữ liệu thử nghiệm. Điều này đã khiến mô hình bị thiếu thông tin quan trọng có thể cải thiện hiệu suất tổng thể của nó.
Một nhược điểm khác là tập dữ liệu huấn luyện có thể gặp phải các ngoại lệ hoặc lỗi trong dữ liệu mà mô hình sẽ học. Điều này trở thành một phần của cơ sở tri thức của mô hình và sẽ được áp dụng khi thử nghiệm trong giai đoạn thứ hai.
Vậy chúng ta có thể làm gì để cải thiện điều này? lấy mẫu lại.
Lấy mẫu lại là một phương pháp liên quan đến việc lấy mẫu lặp đi lặp lại từ tập dữ liệu huấn luyện. Những mẫu này sau đó được sử dụng để điều chỉnh lại một mô hình cụ thể nhằm lấy thêm thông tin về mô hình đã được trang bị. Mục đích là để thu thập thêm thông tin về một mẫu và cải thiện độ chính xác cũng như ước tính độ không đảm bảo.
Ví dụ: nếu bạn đang xem xét sự phù hợp hồi quy tuyến tính và muốn kiểm tra tính biến thiên. Bạn sẽ liên tục sử dụng các mẫu khác nhau từ dữ liệu huấn luyện và điều chỉnh hồi quy tuyến tính cho từng mẫu. Điều này sẽ cho phép bạn kiểm tra xem các kết quả khác nhau như thế nào dựa trên các mẫu khác nhau, cũng như có được thông tin mới.
Ưu điểm đáng kể của việc lấy mẫu lại là bạn có thể liên tục lấy các mẫu nhỏ từ cùng một quần thể cho đến khi mô hình của bạn đạt được hiệu suất tối ưu. Bạn sẽ tiết kiệm được rất nhiều thời gian và tiền bạc nhờ có thể tái chế cùng một tập dữ liệu và không phải tìm dữ liệu mới.
Lấy mẫu dưới mức và Lấy mẫu quá mức
Nếu bạn đang làm việc với các bộ dữ liệu có độ mất cân bằng cao, thì lấy mẫu lại là một kỹ thuật bạn có thể sử dụng để trợ giúp.
- Lấy mẫu dưới mức là khi bạn loại bỏ các mẫu khỏi nhóm đa số để mang lại sự cân bằng hơn.
- Lấy mẫu quá mức là khi bạn sao chép các mẫu ngẫu nhiên từ nhóm thiểu số do không thu thập đủ dữ liệu.
Tuy nhiên, những đi kèm với nhược điểm. Loại bỏ các mẫu trong quá trình lấy mẫu dưới mức có thể dẫn đến mất thông tin. Sao chép các mẫu ngẫu nhiên từ lớp thiểu số có thể dẫn đến trang bị quá mức.
Hai phương pháp lấy mẫu lại thường được sử dụng trong khoa học dữ liệu:
- Phương pháp Bootstrap
- Xác thực chéo
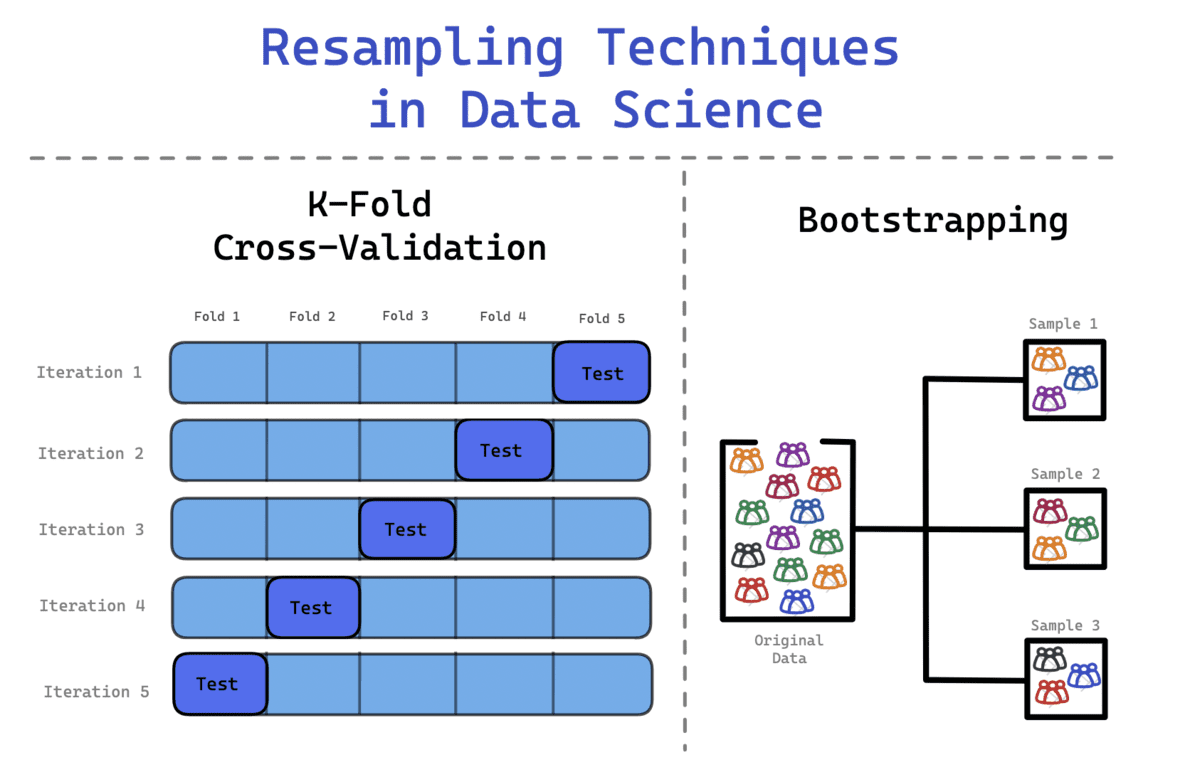
Phương pháp Bootstrap
Bạn sẽ bắt gặp các bộ dữ liệu không tuân theo phân phối chuẩn điển hình. Do đó, phương pháp Bootstrap có thể được áp dụng để kiểm tra thông tin ẩn và phân phối của tập dữ liệu.
Khi sử dụng phương pháp bootstrapping, các mẫu được rút ra sẽ được thay thế và dữ liệu không có trong các mẫu được sử dụng để kiểm tra mô hình. Đây là một phương pháp thống kê linh hoạt có thể giúp các nhà khoa học dữ liệu và kỹ sư máy học định lượng sự không chắc chắn.
quy trình bao gồm
- Liên tục rút ra các quan sát mẫu từ tập dữ liệu
- Thay thế các mẫu này để đảm bảo tập dữ liệu gốc giữ nguyên kích thước.
- Một quan sát có thể xuất hiện nhiều lần hoặc không xuất hiện.
Bạn có thể đã nghe nói về Bagging, kỹ thuật tập hợp. Nó là viết tắt của Bootstrap Aggregation, kết hợp giữa bootstrapping và aggregation để tạo thành một mô hình tập hợp. Nó tạo ra nhiều bộ dữ liệu đào tạo ban đầu, sau đó được tổng hợp để đưa ra dự đoán cuối cùng. Mỗi mô hình học các lỗi của mô hình trước đó.
Một lợi thế của Bootstrapping là chúng có phương sai thấp hơn so với phương pháp phân tách thử nghiệm đào tạo đã đề cập ở trên.
Xác thực chéo
Khi bạn liên tục chia tập dữ liệu một cách ngẫu nhiên, điều này có thể dẫn đến việc mẫu kết thúc trong tập huấn luyện hoặc tập kiểm tra. Thật không may, điều này có thể có ảnh hưởng không cân bằng đến mô hình của bạn trong việc đưa ra các dự đoán chính xác.
Để tránh điều này, bạn có thể sử dụng Xác thực chéo K-Fold để phân chia dữ liệu hiệu quả hơn. Trong quy trình này, dữ liệu được chia thành k bộ bằng nhau, trong đó một bộ được xác định là bộ kiểm tra trong khi các bộ còn lại được sử dụng để huấn luyện mô hình. Quá trình sẽ tiếp tục cho đến khi mỗi bộ đóng vai trò là bộ kiểm tra và tất cả các bộ đã trải qua giai đoạn huấn luyện.
Quá trình bao gồm:
- Dữ liệu được chia thành k-folds. Ví dụ: một tập dữ liệu được chia thành 10 lần – 10 bộ bằng nhau.
- Trong lần lặp đầu tiên, mô hình được huấn luyện trên (k-1) và thử nghiệm trên một tập hợp còn lại. Ví dụ: mô hình được đào tạo trên (10-1 = 9) và được kiểm tra trên 1 bộ còn lại.
- Quá trình này được lặp lại cho đến khi tất cả các nếp gấp đóng vai trò là 1 bộ còn lại trong giai đoạn thử nghiệm.
Điều này cho phép biểu diễn cân bằng từng mẫu, đảm bảo rằng tất cả dữ liệu đã được sử dụng để cải thiện khả năng học tập của mô hình cũng như kiểm tra hiệu suất của mô hình.
Trong bài viết này, bạn sẽ hiểu lấy mẫu lại là gì và cách bạn có thể lấy mẫu tập dữ liệu của mình theo 3 cách khác nhau: phân tách thử nghiệm huấn luyện, bootstrap và xác thực chéo.
Mục đích tổng thể của tất cả các phương pháp này là giúp mô hình thu nhận càng nhiều thông tin càng tốt một cách hiệu quả. Cách duy nhất để đảm bảo rằng mô hình đã học thành công là huấn luyện mô hình trên nhiều điểm dữ liệu khác nhau trong tập dữ liệu.
Lấy mẫu lại là một yếu tố quan trọng của giai đoạn lập mô hình dự đoán; đảm bảo kết quả đầu ra chính xác, mô hình hiệu suất cao và quy trình làm việc hiệu quả.
Nisha Arya là Nhà khoa học dữ liệu và Nhà văn kỹ thuật tự do. Cô ấy đặc biệt quan tâm đến việc cung cấp lời khuyên hoặc hướng dẫn nghề nghiệp về Khoa học Dữ liệu và kiến thức dựa trên lý thuyết về Khoa học Dữ liệu. Cô cũng mong muốn khám phá những cách khác nhau mà Trí tuệ nhân tạo có thể mang lại / có thể mang lại lợi ích cho sự trường tồn của cuộc sống con người. Một người ham học hỏi, tìm cách mở rộng kiến thức công nghệ và kỹ năng viết của mình, đồng thời giúp hướng dẫn người khác.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/2023/02/role-resampling-techniques-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-role-of-resampling-techniques-in-data-science

