Giới thiệu
Trong học máy, sự đánh đổi sai lệch-phương sai là một khái niệm cơ bản ảnh hưởng đến hiệu suất của bất kỳ mô hình dự đoán nào. Nó đề cập đến sự cân bằng tinh tế giữa sai lệch sai lệch và sai số phương sai của một mô hình, vì không thể giảm thiểu đồng thời cả hai. Đạt được sự cân bằng phù hợp là rất quan trọng để đạt được hiệu suất mô hình tối ưu.
Trong bài viết ngắn này, chúng tôi sẽ định nghĩa độ lệch và phương sai, giải thích cách chúng ảnh hưởng đến mô hình học máy và đưa ra một số lời khuyên thiết thực về cách xử lý chúng trong thực tế.
Hiểu Bias và Variance
Trước khi đi sâu vào mối quan hệ giữa sai lệch và phương sai, hãy xác định những thuật ngữ này đại diện cho điều gì trong học máy.
Lỗi thiên vị đề cập đến sự khác biệt giữa dự đoán của một mô hình và các giá trị chính xác mà nó cố gắng dự đoán (sự thật cơ bản). Nói cách khác, sai lệch là lỗi mà một mô hình mắc phải do các giả định không chính xác của nó về phân phối dữ liệu cơ bản. Các mô hình có độ chệch cao thường quá đơn giản, không thể nắm bắt được độ phức tạp của dữ liệu, dẫn đến không phù hợp.
Mặt khác, lỗi phương sai đề cập đến độ nhạy của mô hình đối với các dao động nhỏ trong dữ liệu huấn luyện. Các mô hình có phương sai cao quá phức tạp và có xu hướng phù hợp với nhiễu trong dữ liệu, thay vì mô hình cơ bản, dẫn đến trang bị quá mức. Điều này dẫn đến hiệu suất kém trên dữ liệu mới, chưa thấy.
Độ lệch cao có thể dẫn đến tình trạng thiếu phù hợp, trong đó mô hình quá đơn giản để nắm bắt được độ phức tạp của dữ liệu. Nó đưa ra các giả định mạnh mẽ về dữ liệu và không nắm bắt được mối quan hệ thực sự giữa các biến đầu vào và đầu ra. Mặt khác, phương sai cao có thể dẫn đến tình trạng trang bị quá mức, trong đó mô hình quá phức tạp và học được những nhiễu trong dữ liệu thay vì mối quan hệ cơ bản giữa các biến đầu vào và đầu ra. Do đó, các mô hình trang bị thừa có xu hướng khớp quá chặt chẽ với dữ liệu huấn luyện và sẽ không khái quát hóa tốt với dữ liệu mới, trong khi các mô hình trang bị thiếu thậm chí không thể khớp chính xác với dữ liệu huấn luyện.
Như đã đề cập trước đó, độ chệch và phương sai có liên quan với nhau và một mô hình tốt sẽ cân bằng giữa sai số chệch và sai số phương sai. Đánh đổi sai lệch-phương sai là quá trình tìm kiếm sự cân bằng tối ưu giữa hai nguồn sai số này. Một mô hình có độ lệch thấp và phương sai thấp sẽ có khả năng hoạt động tốt trên cả dữ liệu đào tạo và dữ liệu mới, giảm thiểu tổng lỗi.
Đánh đổi sai lệch-phương sai
Đạt được sự cân bằng giữa độ phức tạp của mô hình và khả năng khái quát hóa dữ liệu chưa biết của nó là cốt lõi của sự đánh đổi sai lệch-phương sai. Nói chung, một mô hình phức tạp hơn sẽ có độ lệch thấp hơn nhưng phương sai cao hơn, trong khi một mô hình đơn giản hơn sẽ có độ lệch cao hơn nhưng phương sai thấp hơn.
Vì không thể đồng thời giảm thiểu sai lệch và phương sai, nên việc tìm ra sự cân bằng tối ưu giữa chúng là rất quan trọng trong việc xây dựng một mô hình học máy mạnh mẽ. Ví dụ: khi chúng tôi tăng độ phức tạp của một mô hình, chúng tôi cũng tăng phương sai. Điều này là do một mô hình phức tạp hơn có nhiều khả năng phù hợp với nhiễu trong dữ liệu huấn luyện, điều này sẽ dẫn đến tình trạng trang bị quá mức.
Mặt khác, nếu chúng ta giữ mô hình quá đơn giản, chúng ta sẽ làm tăng độ chệch. Điều này là do một mô hình đơn giản hơn sẽ không thể nắm bắt được các mối quan hệ cơ bản trong dữ liệu, điều này sẽ dẫn đến sự thiếu phù hợp.
Mục tiêu là đào tạo một mô hình đủ phức tạp để nắm bắt các mối quan hệ cơ bản trong dữ liệu đào tạo, nhưng không phức tạp đến mức phù hợp với nhiễu trong dữ liệu đào tạo.
Bias-Variance Trade-Off trong thực tế
Để chẩn đoán hiệu suất của mô hình, chúng tôi thường tính toán và so sánh các lỗi đào tạo và xác thực. Một công cụ hữu ích để trực quan hóa điều này là đồ thị của các đường cong học tập, hiển thị hiệu suất của mô hình trên cả dữ liệu đào tạo và xác thực trong suốt quá trình đào tạo. Bằng cách kiểm tra các đường cong này, chúng ta có thể xác định xem một mô hình có khớp quá mức (phương sai cao), khớp thiếu (độ chệch cao) hay khớp vừa khít (cân bằng tối ưu giữa độ lệch và phương sai).
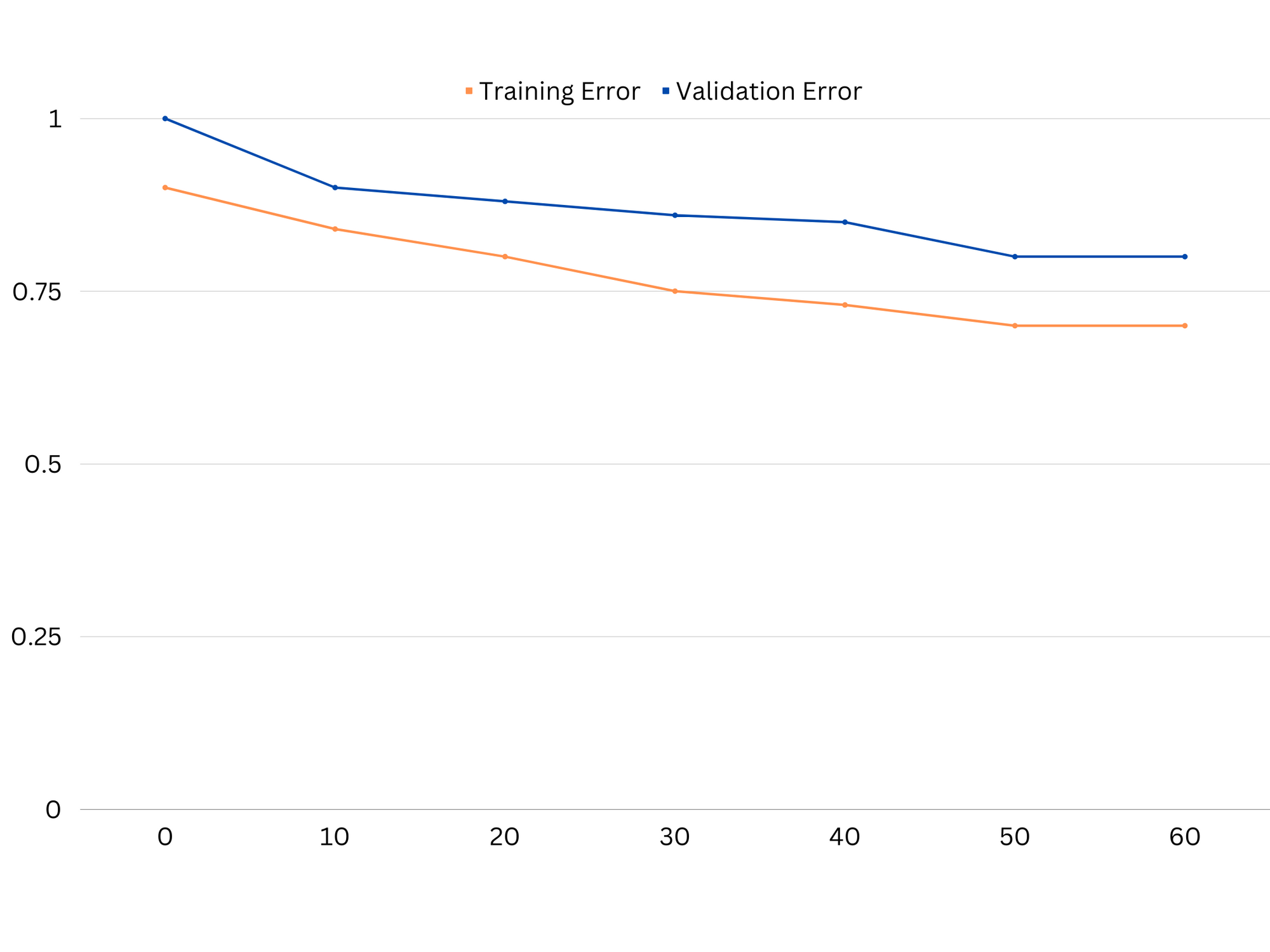
Ví dụ về các đường cong học tập của một mô hình đồ lót. Cả lỗi đào tạo và lỗi xác thực đều cao.
Trong thực tế, hiệu suất thấp trên cả dữ liệu đào tạo và xác thực cho thấy mô hình quá đơn giản, dẫn đến trang bị thiếu. Mặt khác, nếu mô hình hoạt động rất tốt trên dữ liệu huấn luyện nhưng kém trên dữ liệu thử nghiệm, thì độ phức tạp của mô hình có thể quá cao, dẫn đến tình trạng khớp quá mức. Để giải quyết vấn đề thiếu trang bị, chúng ta có thể thử tăng độ phức tạp của mô hình bằng cách thêm nhiều tính năng hơn, thay đổi thuật toán học tập hoặc chọn các siêu đường kính khác nhau. Trong trường hợp trang bị quá mức, chúng ta nên xem xét việc chuẩn hóa mô hình hoặc sử dụng các kỹ thuật như xác thực chéo để cải thiện khả năng khái quát hóa của mô hình.
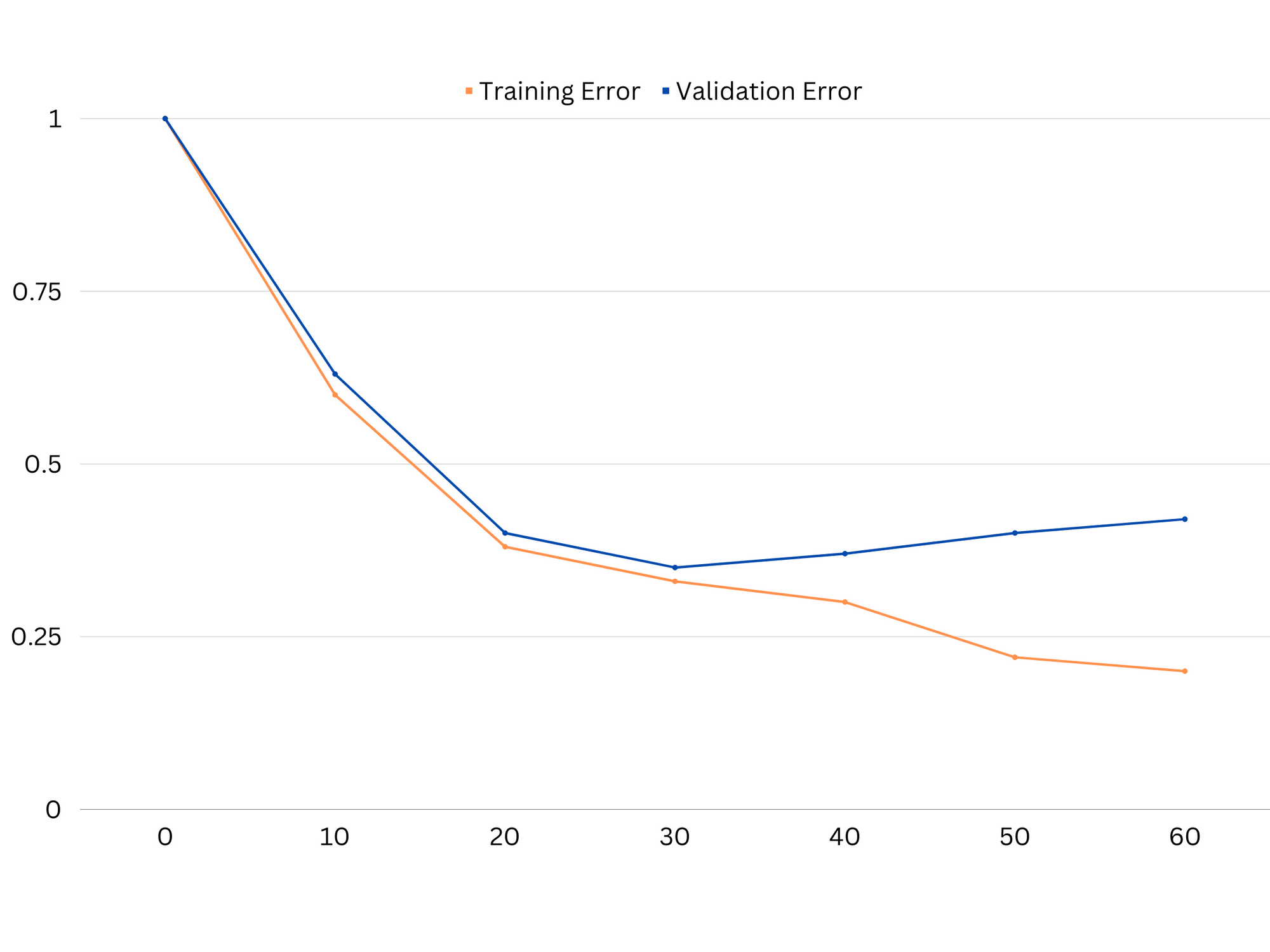
Ví dụ về các đường cong học tập của một mô hình trang bị quá mức. Lỗi đào tạo giảm trong khi lỗi xác thực bắt đầu tăng. Mô hình không thể khái quát hóa.
Chính quy hóa là một kỹ thuật có thể được sử dụng để giảm sai số phương sai trong các mô hình học máy, giúp giải quyết vấn đề đánh đổi sai lệch-phương sai. Có một số kỹ thuật chính quy hóa khác nhau, mỗi kỹ thuật đều có những ưu điểm và nhược điểm riêng. Một số kỹ thuật chính quy hóa phổ biến bao gồm hồi quy sườn, hồi quy lasso và chính quy hóa mạng đàn hồi. Tất cả các kỹ thuật này giúp ngăn chặn việc khớp quá mức bằng cách thêm một điều khoản phạt vào hàm mục tiêu của mô hình, điều này không khuyến khích các giá trị tham số cực đoan và khuyến khích các mô hình đơn giản hơn.
Hồi quy sườn, còn được gọi là chính quy hóa L2, thêm một thuật ngữ phạt tỷ lệ với bình phương của các tham số mô hình. Kỹ thuật này có xu hướng dẫn đến các mô hình có giá trị tham số nhỏ hơn, điều này có thể dẫn đến giảm phương sai và cải thiện khả năng tổng quát hóa. Tuy nhiên, nó không thực hiện lựa chọn tính năng, vì vậy tất cả các tính năng vẫn còn trong mô hình.
Xem hướng dẫn thực hành, thực tế của chúng tôi để học Git, với các phương pháp hay nhất, các tiêu chuẩn được ngành công nghiệp chấp nhận và bảng lừa đảo đi kèm. Dừng lệnh Googling Git và thực sự học nó!
Hồi quy Lasso, hoặc chính quy hóa L1, thêm một điều khoản phạt tỷ lệ thuận với giá trị tuyệt đối của các tham số mô hình. Kỹ thuật này có thể dẫn đến các mô hình có giá trị tham số thưa thớt, thực hiện hiệu quả việc lựa chọn tính năng bằng cách đặt một số tham số thành XNUMX. Điều này có thể dẫn đến các mô hình đơn giản dễ diễn giải hơn.
Chính quy hóa mạng đàn hồi là sự kết hợp của cả chính quy hóa L1 và L2, cho phép cân bằng giữa hồi quy sườn và lasso. Bằng cách kiểm soát tỷ lệ giữa hai điều khoản hình phạt, mạng đàn hồi có thể đạt được những lợi ích của cả hai kỹ thuật, chẳng hạn như cải thiện khả năng khái quát hóa và lựa chọn tính năng.
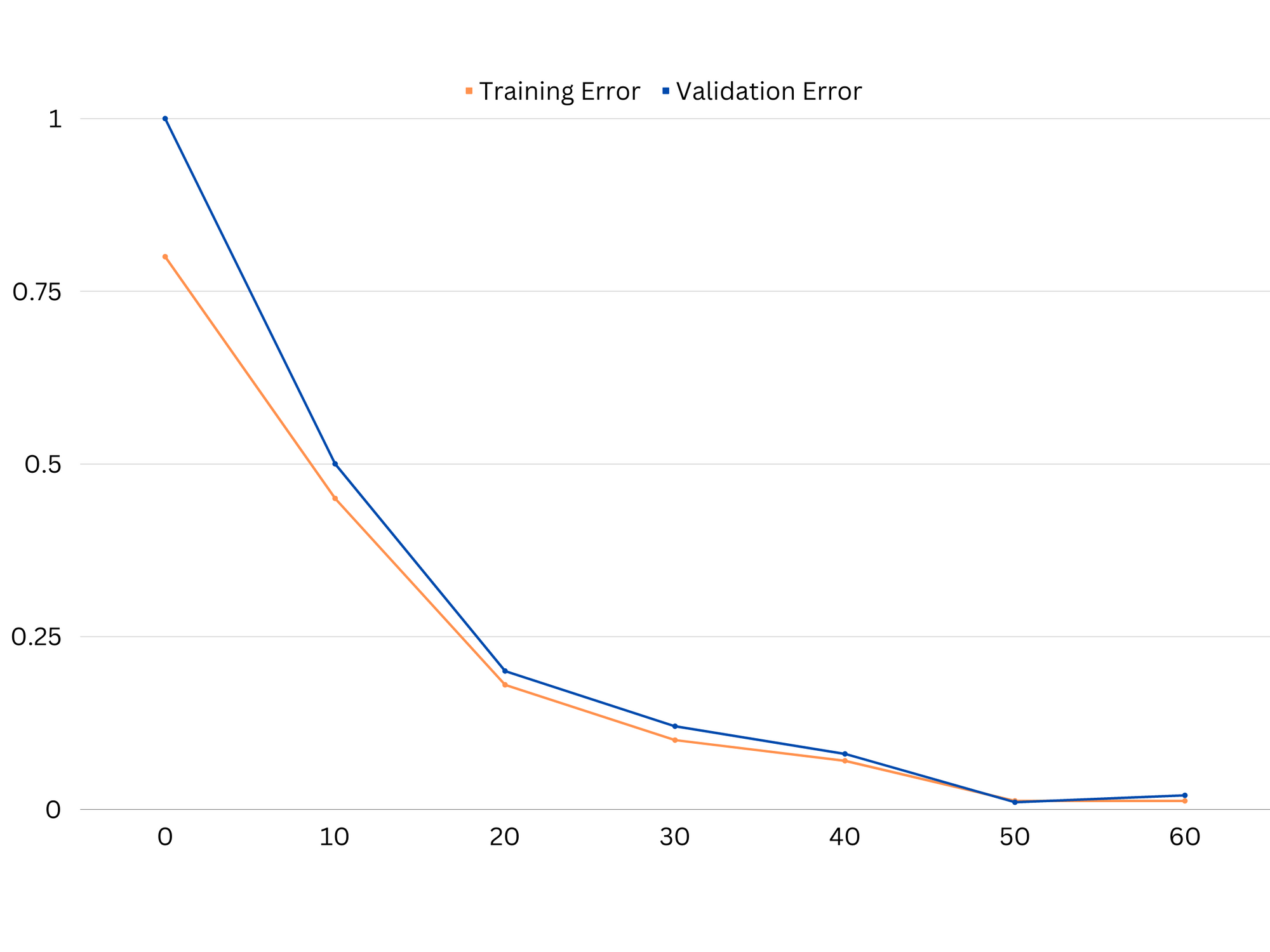
Ví dụ về các đường cong học tập của mô hình phù hợp tốt.
Kết luận
Sự đánh đổi sai lệch-phương sai là một khái niệm quan trọng trong học máy xác định tính hiệu quả và tốt của một mô hình. Mặc dù độ lệch cao dẫn đến trang bị thiếu và phương sai cao dẫn đến trang bị thừa, nhưng việc tìm kiếm sự cân bằng tối ưu giữa hai yếu tố này là cần thiết để xây dựng các mô hình mạnh mẽ giúp khái quát hóa tốt dữ liệu mới.
Với sự trợ giúp của các đường cong học tập, có thể xác định các vấn đề về trang bị thừa hoặc thiếu và bằng cách điều chỉnh độ phức tạp của mô hình hoặc triển khai các kỹ thuật chính quy hóa, có thể cải thiện hiệu suất trên cả dữ liệu đào tạo và xác thực, cũng như dữ liệu thử nghiệm.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://stackabuse.com/the-bias-variance-trade-off-in-machine-learning/

