Студія Amazon SageMaker забезпечує повністю кероване рішення для спеціалістів із обробки даних для інтерактивного створення, навчання та розгортання моделей машинного навчання (ML). У процесі роботи над своїми завданнями ML дослідники даних зазвичай починають свій робочий процес із виявлення відповідних джерел даних і підключення до них. Потім вони використовують SQL, щоб досліджувати, аналізувати, візуалізувати та інтегрувати дані з різних джерел, перш ніж використовувати їх у навчанні ML та висновках. Раніше дослідники даних часто жонглювали декількома інструментами для підтримки SQL у своєму робочому процесі, що заважало продуктивності.
Ми раді повідомити, що блокноти JupyterLab у SageMaker Studio тепер мають вбудовану підтримку SQL. Науковці даних тепер можуть:
- Підключіться до популярних служб передачі даних, в тому числі Амазонка Афіна, Амазонська червона зміна, Amazon DataZone, і Сніжинка безпосередньо в зошитах
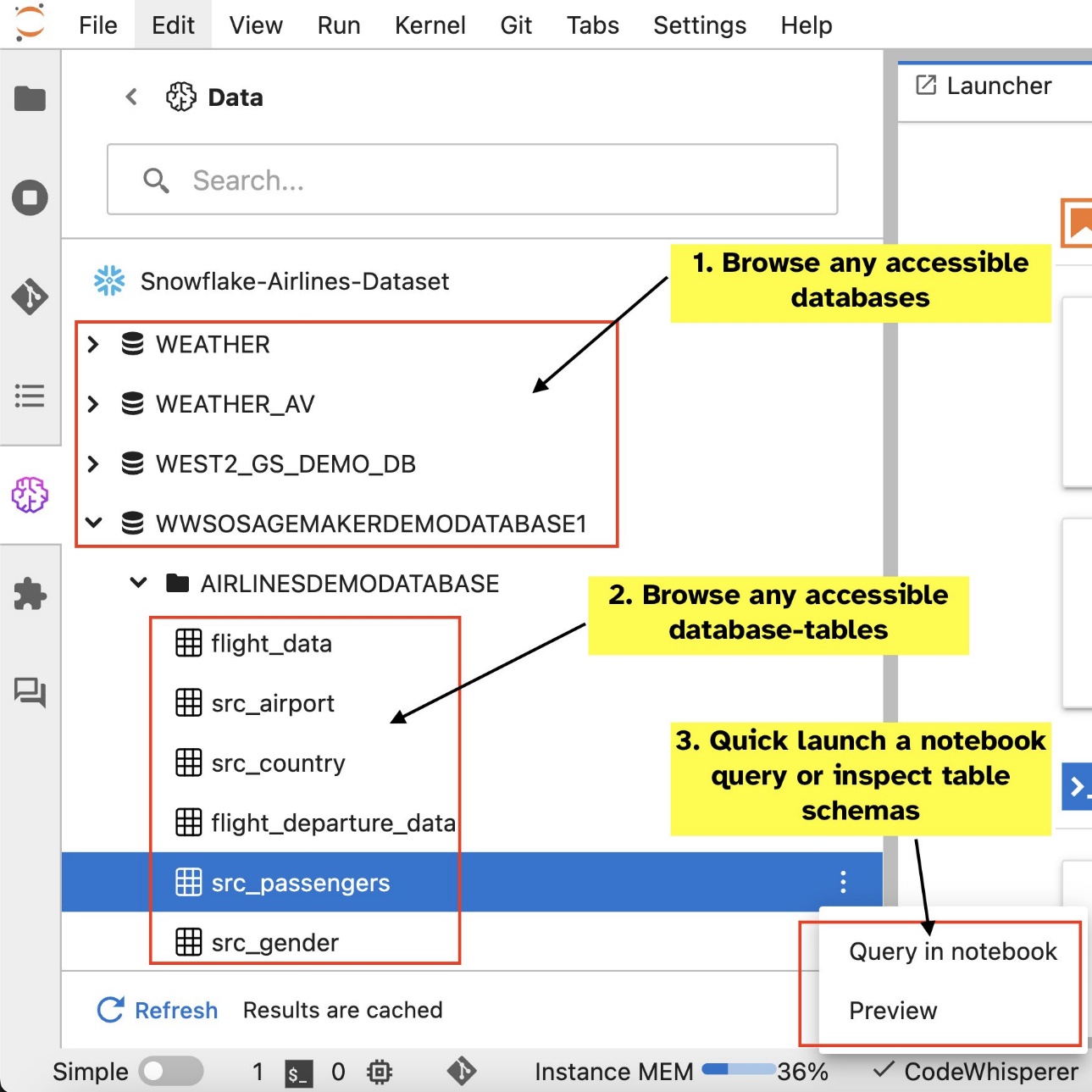
- Огляд і пошук баз даних, схем, таблиць і представлень, а також попередній перегляд даних в інтерфейсі ноутбука
- Змішайте код SQL і Python в одному блокноті для ефективного дослідження та перетворення даних для використання в проектах ML
- Використовуйте функції продуктивності розробника, такі як завершення команд SQL, допомога у форматуванні коду та підсвічування синтаксису, щоб допомогти прискорити розробку коду та підвищити загальну продуктивність розробника
Крім того, адміністратори можуть безпечно керувати з’єднаннями з цими службами обробки даних, дозволяючи дослідникам даних отримувати доступ до авторизованих даних без необхідності керувати обліковими даними вручну.
У цій публікації ми допоможемо вам налаштувати цю функцію в SageMaker Studio та ознайомимося з різними можливостями цієї функції. Потім ми покажемо, як ви можете покращити досвід SQL у ноутбуці за допомогою можливостей Text-to-SQL, які надаються розширеними моделями великих мов (LLM), щоб писати складні запити SQL, використовуючи текст природною мовою як вхідні дані. Нарешті, щоб дати можливість ширшій аудиторії користувачів генерувати SQL-запити з введення природною мовою у своїх блокнотах, ми покажемо вам, як розгорнути ці моделі Text-to-SQL за допомогою Amazon SageMaker кінцеві точки.
Огляд рішення
Завдяки інтеграції SQL у ноутбук SageMaker Studio JupyterLab ви можете підключатися до таких популярних джерел даних, як Snowflake, Athena, Amazon Redshift і Amazon DataZone. Ця нова функція дозволяє виконувати різні функції.
Наприклад, ви можете візуально досліджувати джерела даних, такі як бази даних, таблиці та схеми, безпосередньо з екосистеми JupyterLab. Якщо середовище вашого ноутбука працює на SageMaker Distribution 1.6 або новішої версії, знайдіть новий віджет у лівій частині інтерфейсу JupyterLab. Це доповнення покращує доступність даних і керування ними в середовищі розробки.
Якщо ви наразі не використовуєте рекомендований дистрибутив SageMaker (1.5 або нижчої версії) або не використовуєте спеціальне середовище, зверніться до додатку для отримання додаткової інформації.
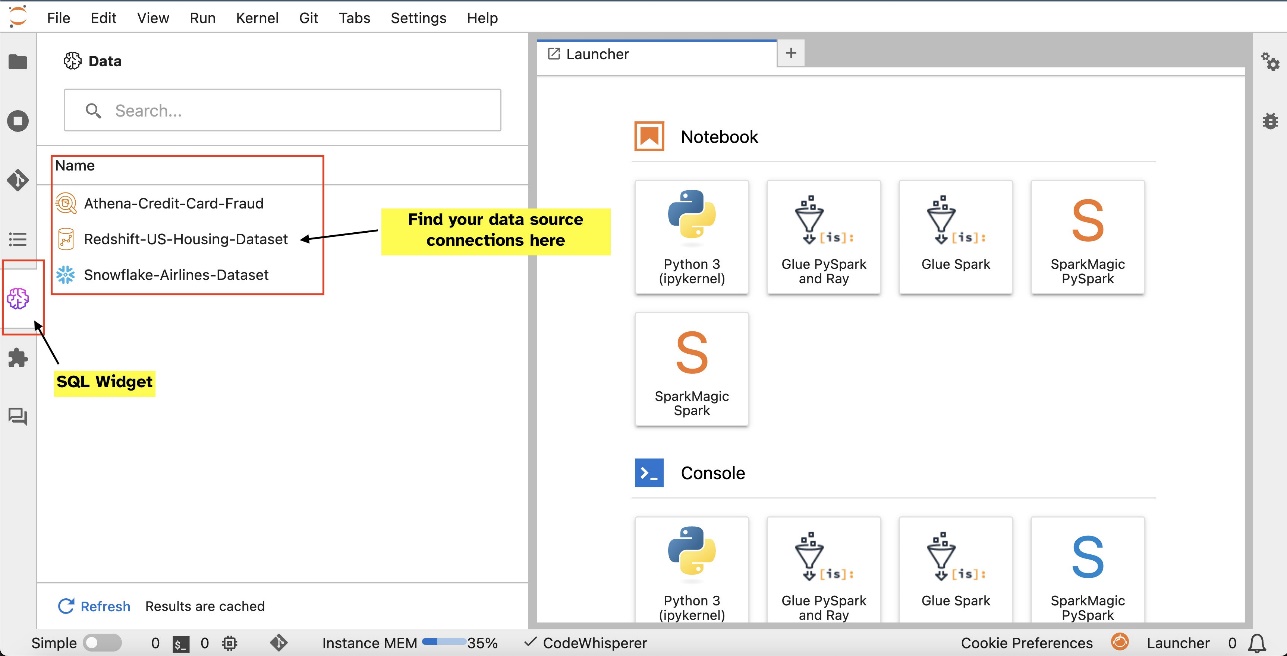
Після встановлення підключень (проілюстровано в наступному розділі) ви можете перераховувати підключення даних, переглядати бази даних і таблиці та перевіряти схеми.
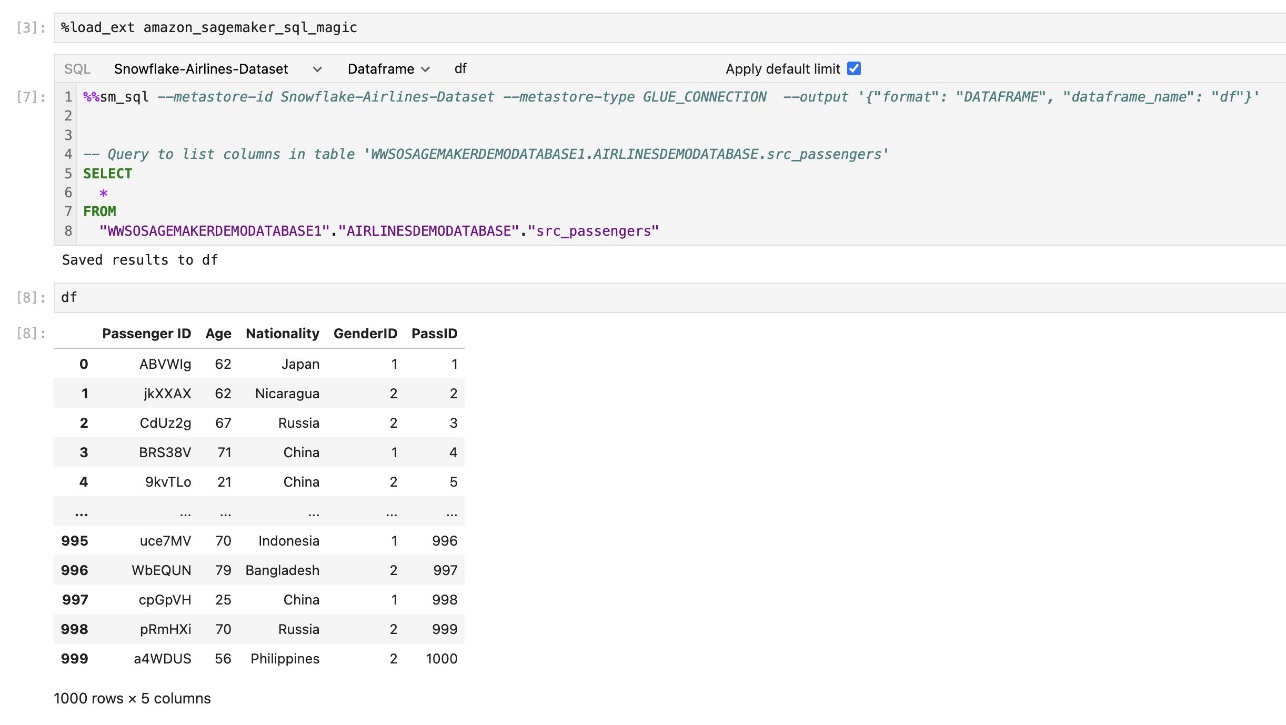
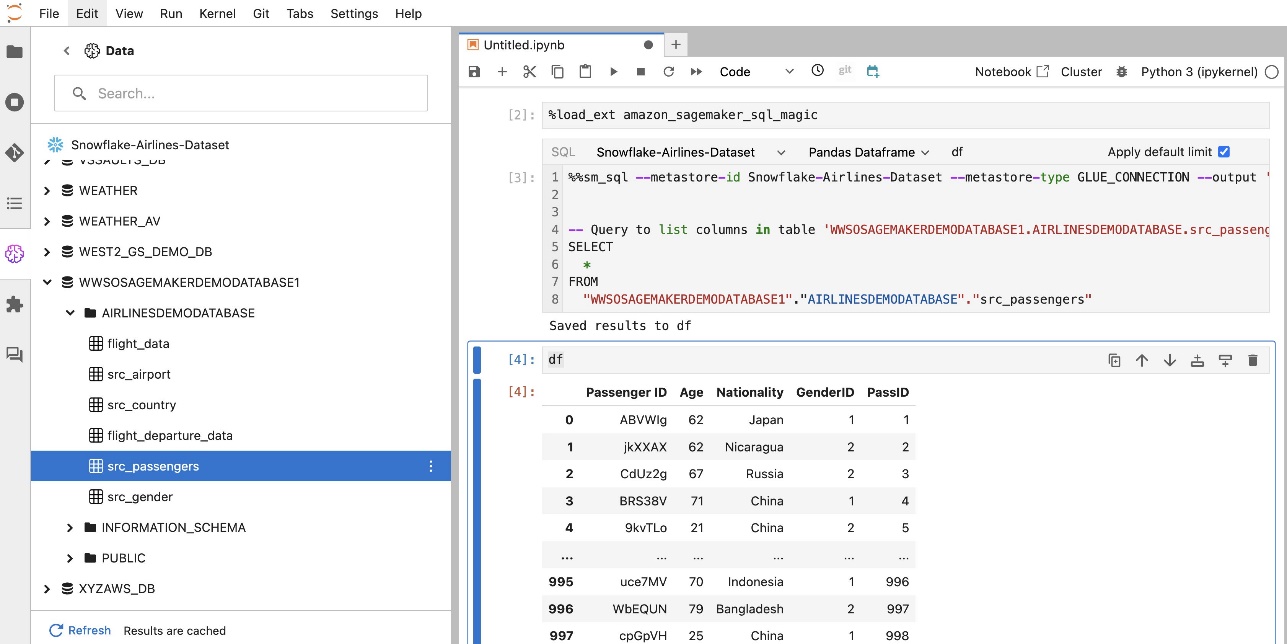
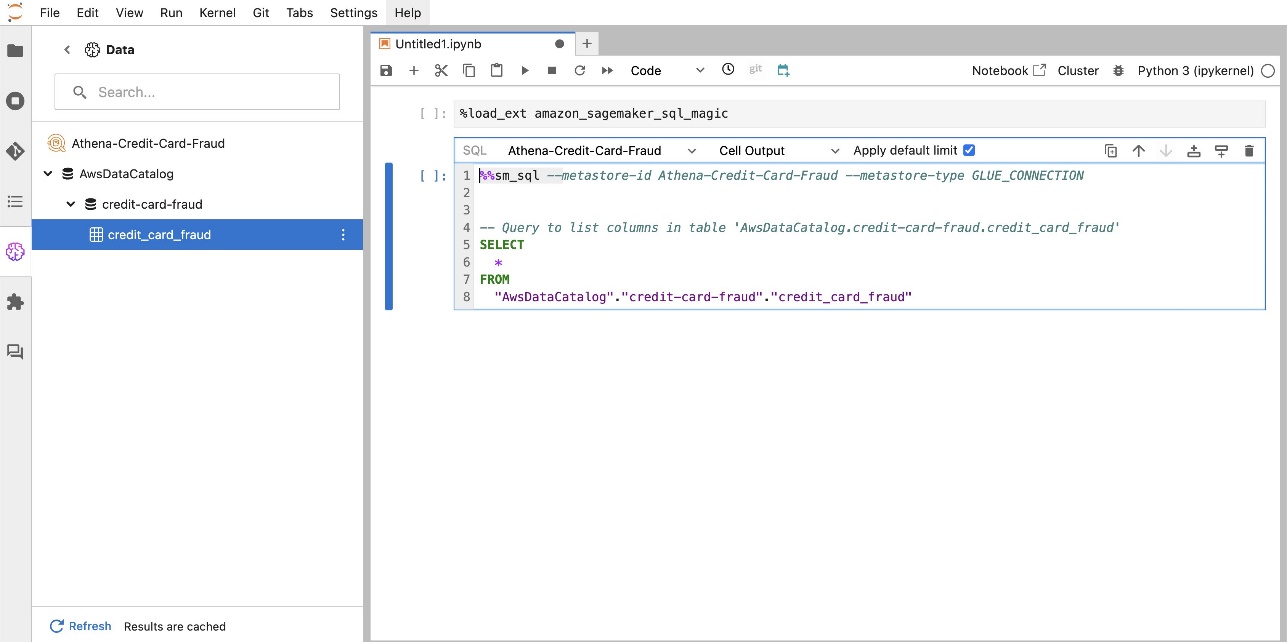
Вбудоване розширення SQL SageMaker Studio JupyterLab також дозволяє запускати SQL-запити безпосередньо з блокнота. Ноутбуки Jupyter можуть розрізняти код SQL і Python за допомогою %%sm_sql чарівна команда, яка повинна бути розміщена у верхній частині будь-якої комірки, що містить код SQL. Ця команда сигналізує JupyterLab, що наступні інструкції є командами SQL, а не кодом Python. Вихідні дані запиту можна відобразити безпосередньо в блокноті, що полегшує бездоганну інтеграцію робочих процесів SQL і Python у ваш аналіз даних.
Вихідні дані запиту можна відобразити візуально як таблиці HTML, як показано на наступному знімку екрана.

Їх також можна записати до a pandas DataFrame.
Передумови
Переконайтеся, що ви задовольнили наведені нижче передумови, щоб використовувати досвід SQL блокнота SageMaker Studio:
- SageMaker Studio V2 – Переконайтеся, що ви використовуєте найновішу версію свого Домен SageMaker Studio та профілі користувачів. Якщо ви зараз використовуєте SageMaker Studio Classic, зверніться до Перехід із Amazon SageMaker Studio Classic.
- Роль IAM – SageMaker вимагає Управління ідентифікацією та доступом AWS (IAM), яку потрібно призначити домену SageMaker Studio або профілю користувача для ефективного керування дозволами. Для перегляду даних і функції запуску SQL може знадобитися оновлення ролі виконання. Наступний приклад політики дозволяє користувачам надавати, перераховувати та запускати Клей AWS, Афіна, Служба простого зберігання Amazon (Amazon S3), Менеджер секретів AWSта ресурси Amazon Redshift:
- JupyterLab Space – Вам потрібен доступ до оновленої SageMaker Studio та JupyterLab Space Розповсюдження SageMaker v1.6 або новіші версії зображень. Якщо ви використовуєте користувацькі зображення для JupyterLab Spaces або старіших версій SageMaker Distribution (версія 1.5 або нижча), зверніться до додатку, щоб отримати інструкції щодо встановлення необхідних пакетів і модулів, щоб увімкнути цю функцію у вашому середовищі. Щоб дізнатися більше про SageMaker Studio JupyterLab Spaces, див Підвищення продуктивності в Amazon SageMaker Studio: представлення JupyterLab Spaces і генеративних інструментів ШІ.
- Облікові дані доступу до джерела даних – Ця функція ноутбука SageMaker Studio вимагає доступу до джерел даних, таких як Snowflake і Amazon Redshift, за допомогою імені користувача та пароля. Створіть доступ на основі імені користувача та пароля до цих джерел даних, якщо у вас його ще немає. На момент написання цієї статті доступ до Snowflake на основі OAuth не підтримується.
- Магія завантаження SQL – Перш ніж запускати SQL-запити з клітинки блокнота Jupyter, важливо завантажити розширення SQL magics. Використовуйте команду
%load_ext amazon_sagemaker_sql_magicщоб увімкнути цю функцію. Крім того, ви можете запустити%sm_sql?команду для перегляду вичерпного списку підтримуваних параметрів для запиту з комірки SQL. Ці параметри включають встановлення ліміту запитів за замовчуванням у 1,000, запуск повного вилучення та введення параметрів запиту, серед іншого. Це налаштування дозволяє гнучко й ефективно маніпулювати даними SQL безпосередньо в середовищі вашого ноутбука.
Створення підключень до бази даних
Вбудовані можливості перегляду та виконання SQL у SageMaker Studio розширені з’єднаннями AWS Glue. З’єднання AWS Glue – це об’єкт AWS Glue Data Catalog, який зберігає важливі дані, такі як облікові дані для входу, рядки URI та інформацію про віртуальну приватну хмару (VPC) для певних сховищ даних. Ці підключення використовуються сканерами, завданнями та кінцевими точками розробки AWS Glue для доступу до різних типів сховищ даних. Ви можете використовувати ці з’єднання як для вихідних, так і для цільових даних і навіть повторно використовувати те саме з’єднання для кількох сканерів або завдань вилучення, трансформації та завантаження (ETL).
Щоб досліджувати джерела даних SQL на лівій панелі SageMaker Studio, вам спочатку потрібно створити об’єкти з’єднання AWS Glue. Ці з’єднання полегшують доступ до різних джерел даних і дозволяють досліджувати їхні схематичні елементи даних.
У наступних розділах ми розповімо про процес створення конекторів AWS Glue для SQL. Це дозволить вам отримувати доступ, переглядати та досліджувати набори даних у різноманітних сховищах даних. Для отримання більш детальної інформації про з’єднання AWS Glue див Підключення до даних.
Створіть з’єднання AWS Glue
Єдиний спосіб перенести джерела даних у SageMaker Studio — це з’єднання AWS Glue. Вам потрібно створити з’єднання AWS Glue з певними типами з’єднань. На момент написання цієї статті єдиним підтримуваним механізмом створення цих підключень є використання Інтерфейс командного рядка AWS (AWS CLI).
JSON-файл визначення підключення
Підключаючись до різних джерел даних у AWS Glue, ви повинні спочатку створити файл JSON, який визначає властивості з’єднання, які називаються файл визначення підключення. Цей файл має вирішальне значення для встановлення з’єднання AWS Glue і має детально описувати всі необхідні конфігурації для доступу до джерела даних. Щоб безпечно зберігати конфіденційну інформацію, наприклад паролі, рекомендуємо використовувати диспетчер секретів. Водночас іншими властивостями з’єднання можна керувати безпосередньо через з’єднання AWS Glue. Цей підхід гарантує захист конфіденційних облікових даних, водночас роблячи конфігурацію підключення доступною та керованою.
Нижче наведено приклад визначення підключення JSON:
Під час налаштування з’єднань AWS Glue для ваших джерел даних слід дотримуватися кількох важливих вказівок, щоб забезпечити функціональність і безпеку:
- Стрінгифікація властивостей – У межах
PythonPropertiesключ, переконайтеся, що всі властивості є рядкові пари ключ-значення. Дуже важливо правильно виключати подвійні лапки за допомогою символу зворотної косої риски (), де це необхідно. Це допомагає підтримувати правильний формат і уникнути синтаксичних помилок у вашому JSON. - Робота з конфіденційною інформацією – Хоча можна включити всі властивості з’єднання
PythonProperties, радимо не включати конфіденційні відомості, наприклад паролі, безпосередньо в ці властивості. Натомість використовуйте диспетчер секретів для обробки конфіденційної інформації. Цей підхід захищає ваші конфіденційні дані, зберігаючи їх у контрольованому та зашифрованому середовищі, подалі від основних конфігураційних файлів.
Створіть з’єднання AWS Glue за допомогою AWS CLI
Після того, як ви включите всі необхідні поля у свій JSON-файл визначення з’єднання, ви готові встановити з’єднання AWS Glue для вашого джерела даних за допомогою AWS CLI та наступної команди:
Ця команда ініціює нове підключення AWS Glue на основі специфікацій, указаних у вашому файлі JSON. Нижче наведено коротку розбивку компонентів команди:
- – регіон – Це визначає регіон AWS, де буде створено ваше з’єднання AWS Glue. Важливо вибрати Регіон, де розташовані джерела даних та інші служби, щоб мінімізувати затримку та відповідати вимогам постійності даних.
- –cli-input-json file:///path/to/file/connection/definition/file.json – Цей параметр спрямовує AWS CLI на читання вхідної конфігурації з локального файлу, який містить визначення підключення у форматі JSON.
Ви повинні мати можливість створювати з’єднання AWS Glue за допомогою попередньої команди AWS CLI з терміналу Studio JupyterLab. На філе меню, виберіть Нові та термінал.

Якщо create-connection команда виконується успішно, ви повинні побачити своє джерело даних у списку на панелі браузера SQL. Якщо ви не бачите свого джерела даних у списку, виберіть оновлення щоб оновити кеш.

Створіть з’єднання «Сніжинка».
У цьому розділі ми зосередимося на інтеграції джерела даних Snowflake із SageMaker Studio. Створення облікових записів, баз даних і сховищ Snowflake виходить за рамки цієї публікації. Щоб почати роботу зі Snowflake, зверніться до Посібник користувача Snowflake. У цій публікації ми зосередимося на створенні JSON-файлу визначення Snowflake і встановленні підключення до джерела даних Snowflake за допомогою AWS Glue.
Створіть секрет менеджера секретів
Ви можете підключитися до свого облікового запису Snowflake за допомогою ідентифікатора користувача та пароля або за допомогою закритих ключів. Щоб підключитися за допомогою ідентифікатора користувача та пароля, вам потрібно надійно зберегти свої облікові дані в диспетчері секретів. Як згадувалося раніше, хоча цю інформацію можна вставити у PythonProperties, не рекомендується зберігати конфіденційну інформацію у форматі звичайного тексту. Завжди переконайтеся, що конфіденційні дані обробляються безпечно, щоб уникнути потенційних ризиків для безпеки.
Щоб зберегти інформацію в диспетчері секретів, виконайте такі дії:
- На консолі Secrets Manager виберіть Зберігайте новий секрет.
- для Секретний типвиберіть Інший тип секрету.
- Для пари ключ-значення виберіть Простий текст і введіть наступне:
- Введіть назву свого секрету, наприклад
sm-sql-snowflake-secret. - Залиште інші налаштування за замовчуванням або налаштуйте, якщо потрібно.
- Створіть секрет.
Створіть з’єднання AWS Glue для Snowflake
Як обговорювалося раніше, з’єднання AWS Glue необхідні для доступу до будь-якого з’єднання із SageMaker Studio. Ви можете знайти список усі підтримувані властивості підключення для Snowflake. Нижче наведено приклад визначення підключення JSON для Snowflake. Замініть значення заповнювачів відповідними значеннями перед збереженням на диск:
Щоб створити об’єкт підключення AWS Glue для джерела даних Snowflake, скористайтеся такою командою:
Ця команда створює нове підключення до джерела даних Snowflake на панелі вашого браузера SQL, яке можна переглядати, і ви можете запускати SQL-запити до нього з комірки блокнота JupyterLab.
Створіть підключення Amazon Redshift
Amazon Redshift — це повністю керована служба сховища даних розміром до петабайтів, яка спрощує та зменшує витрати на аналіз усіх ваших даних за допомогою стандартного SQL. Процедура створення підключення Amazon Redshift дуже схожа на процедуру підключення Snowflake.
Створіть секрет менеджера секретів
Подібно до налаштування Snowflake, щоб підключитися до Amazon Redshift за допомогою ідентифікатора користувача та пароля, вам потрібно безпечно зберігати секретну інформацію в диспетчері секретів. Виконайте наступні дії:
- На консолі Secrets Manager виберіть Зберігайте новий секрет.
- для Секретний типвиберіть Облікові дані для кластера Amazon Redshift.
- Введіть облікові дані, які використовуються для входу, щоб отримати доступ до Amazon Redshift як джерела даних.
- Виберіть кластер Redshift, пов’язаний із секретами.
- Введіть назву для секрету, наприклад
sm-sql-redshift-secret. - Залиште інші налаштування за замовчуванням або налаштуйте, якщо потрібно.
- Створіть секрет.
Виконуючи ці кроки, ви гарантуєте, що ваші облікові дані підключення безпечно обробляються, використовуючи надійні функції безпеки AWS для ефективного керування конфіденційними даними.
Створіть з’єднання AWS Glue для Amazon Redshift
Щоб налаштувати з’єднання з Amazon Redshift за допомогою визначення JSON, заповніть необхідні поля та збережіть таку конфігурацію JSON на диску:
Щоб створити об’єкт підключення AWS Glue для джерела даних Redshift, скористайтеся такою командою AWS CLI:
Ця команда створює з’єднання в AWS Glue із вашим джерелом даних Redshift. Якщо команда виконана успішно, ви зможете побачити своє джерело даних Redshift у блокноті SageMaker Studio JupyterLab, готове для виконання запитів SQL і аналізу даних.

Створіть з'єднання Athena
Athena — це повністю керована служба запитів SQL від AWS, яка дає змогу аналізувати дані, що зберігаються в Amazon S3, за допомогою стандартного SQL. Щоб налаштувати з’єднання Athena як джерело даних у SQL-браузері блокнота JupyterLab, вам потрібно створити JSON визначення підключення Athena. Наступна структура JSON налаштовує необхідні деталі для підключення до Athena, вказуючи каталог даних, проміжний каталог S3 і регіон:
Щоб створити об’єкт підключення AWS Glue для джерела даних Athena, скористайтеся такою командою AWS CLI:
Якщо команда виконана успішно, ви зможете отримати доступ до каталогу даних і таблиць Athena безпосередньо з браузера SQL у вашому блокноті SageMaker Studio JupyterLab.
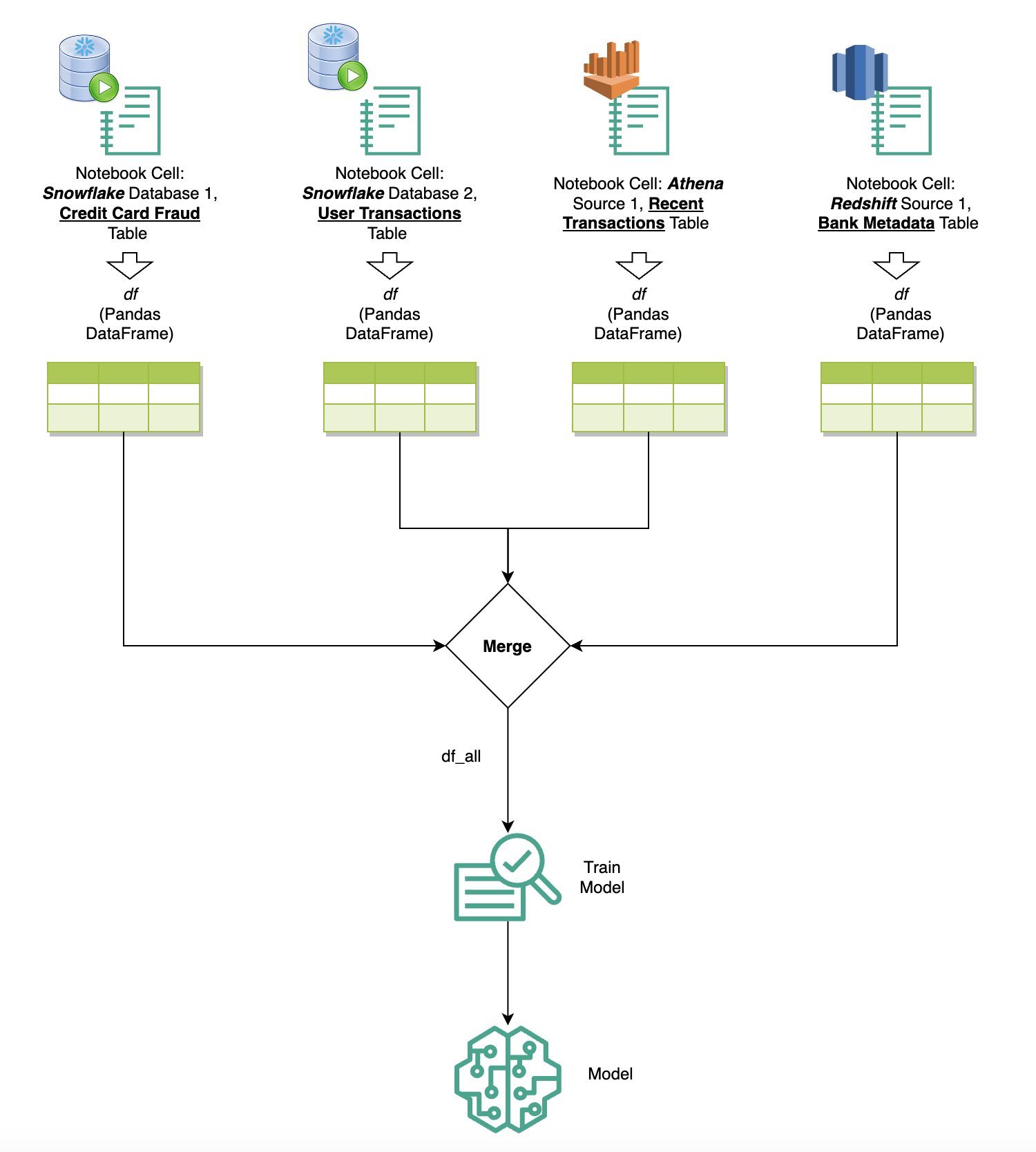
Запитуйте дані з кількох джерел
Якщо у вас є кілька джерел даних, інтегрованих у SageMaker Studio через вбудований SQL-браузер і функцію SQL для ноутбука, ви можете швидко виконувати запити та легко перемикатися між серверними джерелами даних у наступних клітинках блокнота. Ця можливість забезпечує плавний перехід між різними базами даних або джерелами даних під час робочого процесу аналізу.
Ви можете запускати запити до різноманітної колекції джерел даних і переносити результати безпосередньо в простір Python для подальшого аналізу чи візуалізації. Цьому сприяють %%sm_sql магічна команда доступна в блокнотах SageMaker Studio. Щоб вивести результати вашого SQL-запиту в pandas DataFrame, є два варіанти:
- На панелі інструментів комірки блокнота виберіть тип виведення DataFrame і назвіть свою змінну DataFrame
- Додайте наступний параметр до свого
%%sm_sqlкоманда:
Наступна діаграма ілюструє цей робочий процес і демонструє, як можна без зусиль запускати запити до різних джерел у наступних комірках блокнота, а також навчати модель SageMaker за допомогою навчальних завдань або безпосередньо в блокноті за допомогою локальних обчислень. Крім того, на діаграмі показано, як вбудована інтеграція SQL у SageMaker Studio спрощує процеси вилучення та створення безпосередньо в знайомому середовищі клітинки блокнота JupyterLab.
Перетворення тексту на SQL: використання природної мови для вдосконалення створення запитів
SQL — це складна мова, яка потребує розуміння баз даних, таблиць, синтаксису та метаданих. Сьогодні генеративний штучний інтелект (AI) може дозволити вам писати складні SQL-запити, не вимагаючи глибокого досвіду SQL. Розвиток LLM суттєво вплинув на генерацію SQL на основі обробки природної мови (NLP), дозволяючи створювати точні SQL-запити з описів природною мовою — техніка, яка називається Text-to-SQL. Однак важливо визнати суттєві відмінності між людською мовою та SQL. Людська мова іноді може бути неоднозначною або неточною, тоді як SQL є структурованою, явною та однозначною. Подолання цього розриву та точне перетворення природної мови на SQL-запити може стати серйозною проблемою. Отримавши відповідні підказки, LLM можуть допомогти подолати цю прогалину, розуміючи намір людської мови та відповідно генеруючи точні SQL-запити.
З випуском функції SQL-запитів у ноутбуці SageMaker Studio SageMaker Studio спрощує перевірку баз даних і схем, а також створення, виконання та налагодження SQL-запитів, не виходячи з IDE для ноутбука Jupyter. У цьому розділі досліджується, як можливості Text-to-SQL розширених LLM можуть полегшити створення запитів SQL за допомогою природної мови в записниках Jupyter. Ми використовуємо передову модель Text-to-SQL defog/sqlcoder-7b-2 у поєднанні з Jupyter AI, генеративним помічником AI, спеціально розробленим для ноутбуків Jupyter, для створення складних SQL-запитів з природної мови. Використовуючи цю вдосконалену модель, ми можемо легко й ефективно створювати складні SQL-запити, використовуючи природну мову, покращуючи тим самим роботу SQL у ноутбуках.
Створення прототипу ноутбука за допомогою Hugging Face Hub
Щоб почати створення прототипу, вам потрібно:
- Код GitHub – Код, представлений у цьому розділі, доступний у наступному GitHub репо і посилаючись на приклад блокнота.
- JupyterLab Space – Доступ до SageMaker Studio JupyterLab Space, що підтримується екземплярами на основі GPU, є важливим. Для
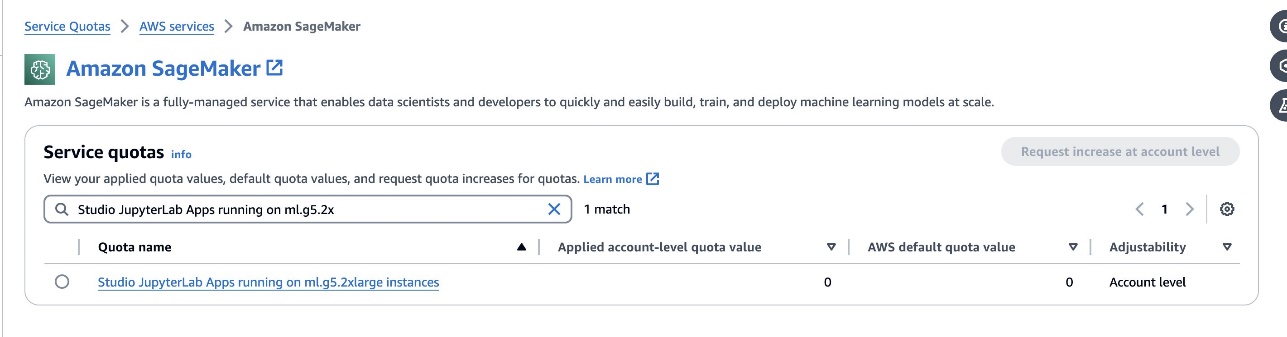
defog/sqlcoder-7b-2моделі, рекомендується модель параметрів 7B, використовуючи примірник ml.g5.2xlarge. Такі альтернативи, якdefog/sqlcoder-70b-alpha абоdefog/sqlcoder-34b-alphaтакож придатні для перетворення природної мови в SQL, але для прототипування можуть знадобитися більші типи екземплярів. Переконайтеся, що у вас є квота для запуску екземпляра з підтримкою GPU, перейшовши до консолі Service Quotas, знайшовши SageMaker і знайшовшиStudio JupyterLab Apps running on <instance type>.
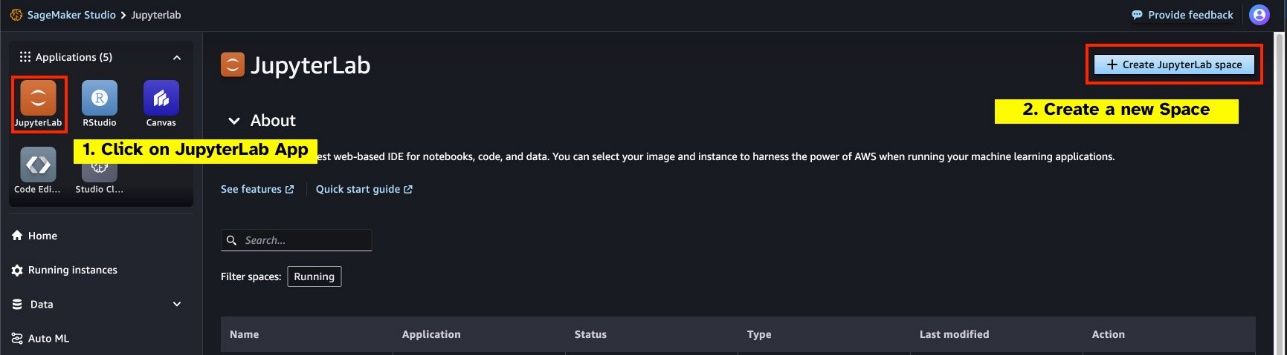
Запустіть новий JupyterLab Space із підтримкою графічного процесора зі своєї SageMaker Studio. Рекомендовано створити новий простір JupyterLab з принаймні 75 ГБ Магазин еластичних блоків Amazon (Amazon EBS) зберігання для моделі параметрів 7B.

- Hugging Face Hub – Якщо ваш домен SageMaker Studio має доступ до завантаження моделей із Hugging Face Hub, ви можете скористатись
AutoModelForCausalLMклас від huggingface/трансформери щоб автоматично завантажувати моделі та закріплювати їх на локальних графічних процесорах. Вага моделі зберігатиметься в кеші вашої локальної машини. Перегляньте наступний код:
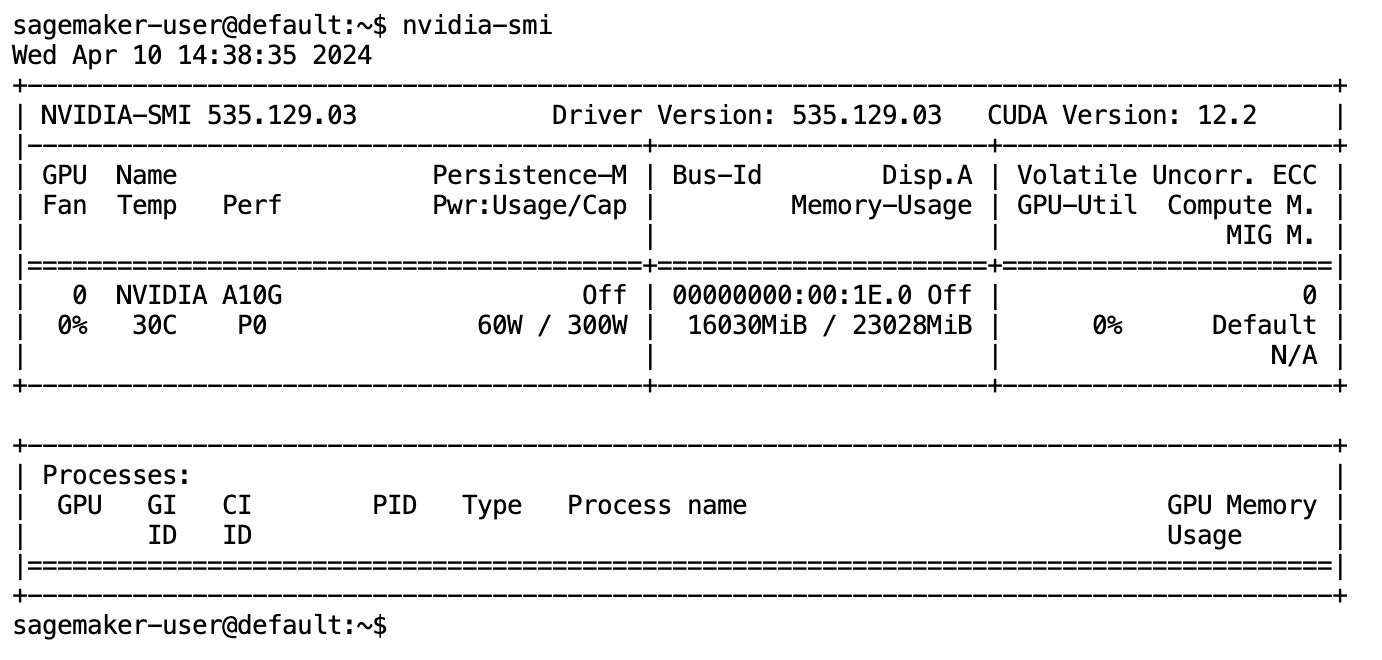
Після того, як модель буде повністю завантажено та завантажено в пам’ять, ви повинні спостерігати збільшення використання GPU на вашій локальній машині. Це вказує на те, що модель активно використовує ресурси GPU для обчислювальних завдань. Ви можете перевірити це у своєму просторі JupyterLab, запустивши nvidia-smi (для одноразового показу) або nvidia-smi —loop=1 (повторювати щосекунди) з терміналу JupyterLab.
Моделі Text-to-SQL чудово розуміють мету та контекст запиту користувача, навіть якщо мова використовується розмовною або неоднозначною. Процес передбачає переклад вхідних даних природною мовою в правильні елементи схеми бази даних, такі як імена таблиць, імена стовпців і умови. Проте стандартна модель Text-to-SQL не буде знати структуру вашого сховища даних, конкретні схеми бази даних або точно інтерпретувати вміст таблиці виключно на основі імен стовпців. Щоб ефективно використовувати ці моделі для створення практичних і ефективних запитів SQL з природної мови, необхідно адаптувати модель генерації тексту SQL до конкретної схеми бази даних сховища. Цю адаптацію полегшує використання LLM підказки. Нижче наведено рекомендований шаблон підказки для моделі перетворення тексту в SQL defog/sqlcoder-7b-2, розділений на чотири частини:
- Завдання – У цьому розділі має бути визначено завдання високого рівня, яке має виконати модель. Він має включати тип серверної частини бази даних (наприклад, Amazon RDS, PostgreSQL або Amazon Redshift), щоб модель усвідомлювала будь-які нюанси синтаксичних відмінностей, які можуть вплинути на створення остаточного SQL-запиту.
- інструкції – Цей розділ має визначати межі завдань і обізнаність про предметну область для моделі, а також може включати невеликі приклади для керівництва моделлю при створенні точно налаштованих запитів SQL.
- Схема бази даних – У цьому розділі мають бути детально описані ваші схеми бази даних сховища, окреслені зв’язки між таблицями та стовпцями, щоб допомогти моделі зрозуміти структуру бази даних.
- Відповідь – Цей розділ зарезервовано для моделі для виведення відповіді на SQL-запит на введення природною мовою.
Приклад схеми бази даних і підказки, які використовуються в цьому розділі, доступні в GitHub Repo.
Підказка полягає не лише у формуванні запитань чи тверджень; це нюанси мистецтва та науки, які суттєво впливають на якість взаємодії з моделлю ШІ. Те, як ви створюєте підказку, може суттєво вплинути на характер і корисність відповіді ШІ. Ця навичка має ключове значення для максимального використання потенціалу взаємодії штучного інтелекту, особливо в складних завданнях, що вимагають спеціального розуміння та детальних відповідей.
Важливо мати можливість швидко побудувати та перевірити відповідь моделі на задану підказку та оптимізувати підказку на основі відповіді. Ноутбуки JupyterLab надають можливість отримувати миттєвий зворотний зв’язок від моделі, що працює на локальному комп’ютері, оптимізувати підказку та додатково налаштувати відповідь моделі або повністю змінити модель. У цій публікації ми використовуємо блокнот SageMaker Studio JupyterLab із підтримкою графічного процесора NVIDIA A5.2G 10 ГБ від ml.g24xlarge, щоб запускати на ноутбуці аналіз моделі Text-to-SQL і інтерактивно створювати підказку моделі, доки відповідь моделі не буде достатньо налаштована, щоб забезпечити відповіді, які безпосередньо виконуються в комірках SQL JupyterLab. Щоб запустити модельний висновок і одночасно потокову передачу відповідей моделі, ми використовуємо комбінацію model.generate та TextIteratorStreamer як визначено в наступному коді:
Вихід моделі можна прикрасити магією SageMaker SQL %%sm_sql ..., що дозволяє блокноту JupyterLab ідентифікувати клітинку як клітинку SQL.
Розміщуйте моделі Text-to-SQL як кінцеві точки SageMaker
Наприкінці етапу прототипування ми вибрали наш бажаний Text-to-SQL LLM, ефективний формат підказки та відповідний тип екземпляра для розміщення моделі (однографічний або багатографічний процесор). SageMaker полегшує масштабоване розміщення користувацьких моделей за допомогою кінцевих точок SageMaker. Ці кінцеві точки можна визначити відповідно до певних критеріїв, що дозволяє розгортати LLM як кінцеві точки. Ця можливість дає змогу масштабувати рішення для ширшої аудиторії, дозволяючи користувачам генерувати SQL-запити з вхідних даних природною мовою за допомогою спеціально розміщених LLM. Наступна діаграма ілюструє цю архітектуру.

Щоб розмістити ваш LLM як кінцеву точку SageMaker, ви створюєте кілька артефактів.
Перший артефакт — це ваги моделі. Обслуговування глибокої бібліотеки Java (DJL) SageMaker Контейнери дозволяють налаштовувати конфігурації через мета обслуговуючі.властивості файл, який дає вам змогу керувати джерелом отримання моделей — безпосередньо з Hugging Face Hub або завантажуючи артефакти моделі з Amazon S3. Якщо ви вкажете model_id=defog/sqlcoder-7b-2, DJL Serving спробує завантажити цю модель безпосередньо з Hugging Face Hub. Однак ви можете стягувати плату за вхід/вихід мережі кожного разу, коли кінцева точка розгортається або еластично масштабується. Щоб уникнути цих стягнень і потенційно пришвидшити завантаження артефактів моделі, рекомендується пропустити використання model_id in serving.properties і збережіть ваги моделі як артефакти S3 і вкажіть їх лише за допомогою s3url=s3://path/to/model/bin.
Зберегти модель (з її токенізером) на диску та завантажити її в Amazon S3 можна за допомогою лише кількох рядків коду:
Ви також використовуєте файл запиту бази даних. У цьому налаштуванні підказка бази даних складається з Task, Instructions, Database Schema та Answer sections. Для поточної архітектури ми виділяємо окремий файл підказок для кожної схеми бази даних. Однак існує можливість розширити цю настройку, щоб включити кілька баз даних у файл підказки, дозволяючи моделі виконувати складні об’єднання між базами даних на одному сервері. На етапі прототипування ми зберігаємо підказку бази даних як текстовий файл з назвою <Database-Glue-Connection-Name>.prompt, Де Database-Glue-Connection-Name відповідає імені підключення, видимому у вашому середовищі JupyterLab. Наприклад, ця публікація стосується підключення Snowflake під назвою Airlines_Dataset, тому файл підказки бази даних називається Airlines_Dataset.prompt. Потім цей файл зберігається на Amazon S3, а потім зчитується та кешується нашою логікою обслуговування моделі.
Крім того, ця архітектура дозволяє будь-яким авторизованим користувачам цієї кінцевої точки визначати, зберігати та генерувати запити SQL природною мовою без необхідності багаторазового повторного розгортання моделі. Ми використовуємо наступне приклад підказки бази даних щоб продемонструвати функціональність Text-to-SQL.
Далі ви створюєте спеціальну логіку служби моделі. У цьому розділі ви окреслюєте настроювану логіку висновку під назвою model.py. Цей сценарій розроблено для оптимізації продуктивності та інтеграції наших служб Text-to-SQL:
- Визначте логіку кешування файлів підказок бази даних – Щоб мінімізувати затримку, ми реалізуємо спеціальну логіку для завантаження та кешування файлів підказок бази даних. Цей механізм гарантує, що підказки легко доступні, зменшуючи накладні витрати, пов’язані з частими завантаженнями.
- Визначте власну логіку висновку моделі – Для підвищення швидкості логічного висновку наша модель перетворення тексту в SQL завантажується у форматі точності float16, а потім перетворюється на модель DeepSpeed. Цей крок дозволяє більш ефективно обчислювати. Крім того, у рамках цієї логіки ви вказуєте, які параметри користувачі можуть регулювати під час викликів висновку, щоб адаптувати функціональність відповідно до своїх потреб.
- Визначте спеціальну логіку введення та виведення – Встановлення чітких і налаштованих форматів вводу/виводу має важливе значення для плавної інтеграції з подальшими програмами. Одним із таких додатків є JupyterAI, який ми обговоримо в наступному розділі.
Крім того, ми включаємо a serving.properties файл, який діє як файл глобальної конфігурації для моделей, розміщених за допомогою служби DJL. Для отримання додаткової інформації див Конфігурації та налаштування.
Нарешті, ви також можете включити a requirements.txt файл, щоб визначити додаткові модулі, необхідні для висновку, і запакувати все в архів для розгортання.
Дивіться наступний код:
Інтегруйте свою кінцеву точку за допомогою помічника SageMaker Studio Jupyter AI
Юпітер А.І це інструмент із відкритим вихідним кодом, який приносить генеративний ШІ в ноутбуки Jupyter, пропонуючи надійну та зручну платформу для дослідження генеративних моделей ШІ. Він підвищує продуктивність JupyterLab і ноутбуків Jupyter, надаючи такі функції, як %%ai magic для створення генеративного ігрового майданчика ШІ всередині блокнотів, власний користувальницький інтерфейс чату в JupyterLab для взаємодії зі штучним інтелектом як розмовного помічника, а також підтримку широкого спектру магістрів права від провайдерам подобається Амазонський титан, AI21, Anthropic, Cohere та Hugging Face або такі керовані служби Amazon Bedrock і кінцеві точки SageMaker. У цій публікації ми використовуємо готову інтеграцію штучного інтелекту Jupyter із кінцевими точками SageMaker, щоб забезпечити можливість перетворення тексту в SQL у ноутбуках JupyterLab. Інструмент Jupyter AI попередньо встановлений у всіх SageMaker Studio JupyterLab Spaces, які підтримуються Зображення дистрибутива SageMaker; Кінцевим користувачам не потрібно робити жодних додаткових конфігурацій, щоб почати використовувати розширення Jupyter AI для інтеграції з кінцевою точкою SageMaker. У цьому розділі ми обговорюємо два способи використання інтегрованого інструменту Jupyter AI.
ШІ Юпітера в блокноті за допомогою магії
ШІ Юпітера %%ai Команда magic дозволяє перетворити ваші ноутбуки SageMaker Studio JupyterLab на відтворюване генеративне середовище ШІ. Щоб почати використовувати магію AI, переконайтеся, що ви завантажили розширення jupyter_ai_magics для використання %%ai магія, і додатково навантаж amazon_sagemaker_sql_magic to use %%sm_sql магія:
Щоб запустити виклик кінцевої точки SageMaker зі свого блокнота за допомогою %%ai магічну команду, надайте наступні параметри та структуруйте команду таким чином:
- – назва регіону – Укажіть регіон, де розгорнуто вашу кінцеву точку. Це гарантує, що запит направляється до правильного географічного розташування.
- –схема запиту – Додайте схему вхідних даних. Ця схема описує очікуваний формат і типи вхідних даних, які потрібні вашій моделі для обробки запиту.
- – шлях відповіді – Визначте шлях у об’єкті відповіді, де розміщено вихідні дані вашої моделі. Цей шлях використовується для отримання відповідних даних із відповіді, яку повертає ваша модель.
- -f (необов'язковий) – Це ан форматування виводу прапорець, що вказує на тип результату, який повертає модель. У контексті блокнота Jupyter, якщо вихідні дані є кодом, цей прапорець має бути встановлено відповідним чином, щоб відформатувати вихідні дані як виконуваний код у верхній частині комірки блокнота Jupyter, за яким слідує область вільного введення тексту для взаємодії з користувачем.
Наприклад, команда в клітинці блокнота Jupyter може виглядати так:
Вікно чату Jupyter AI
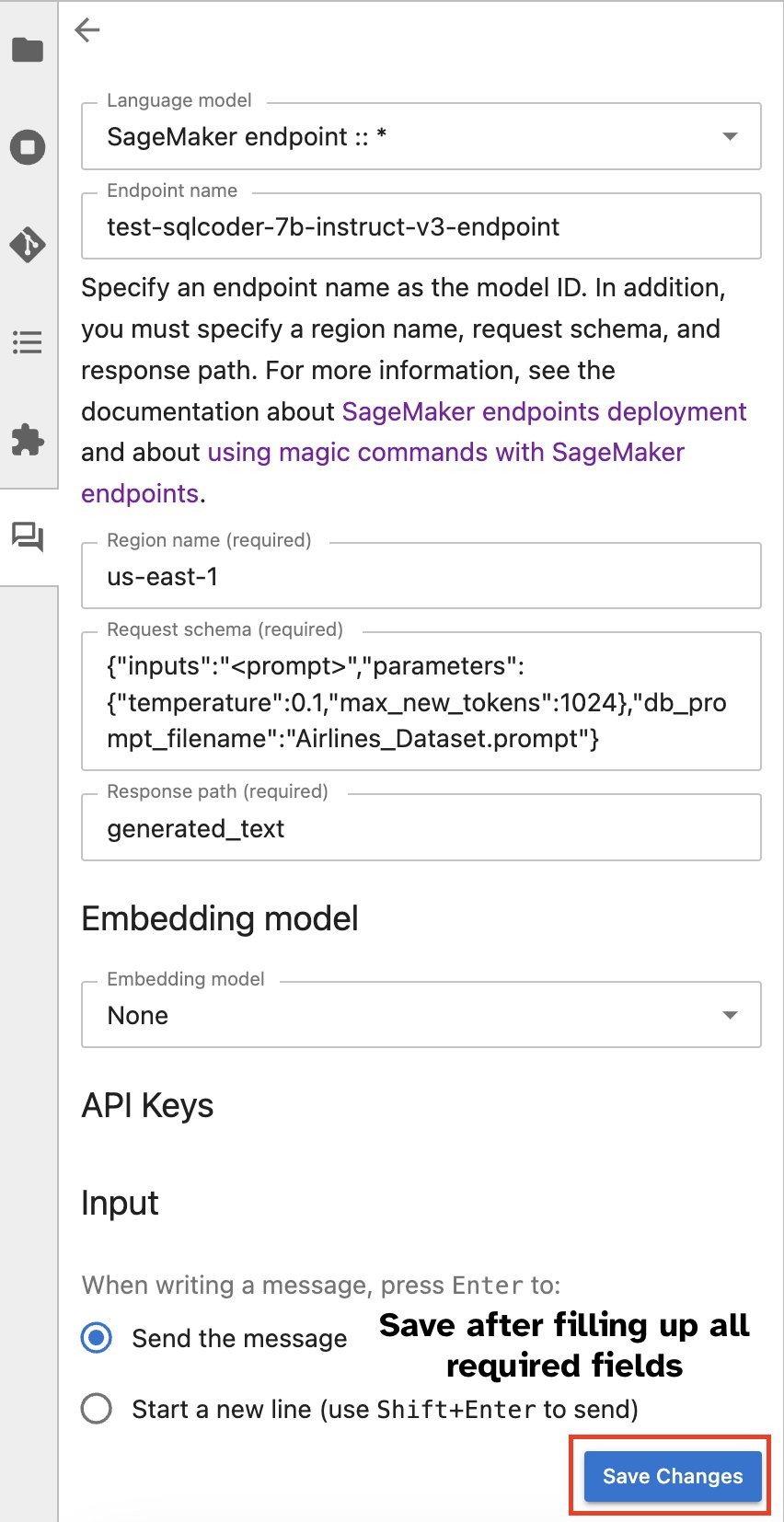
Крім того, ви можете взаємодіяти з кінцевими точками SageMaker через вбудований інтерфейс користувача, що спрощує процес створення запитів або вступу в діалог. Перш ніж розпочати спілкування з вашою кінцевою точкою SageMaker, налаштуйте відповідні параметри в Jupyter AI для кінцевої точки SageMaker, як показано на наступному знімку екрана.
 |
 |
Висновок
Тепер SageMaker Studio спрощує та оптимізує робочий процес спеціаліста з даних, інтегруючи підтримку SQL у блокноти JupyterLab. Це дозволяє дослідникам даних зосередитися на своїх завданнях без необхідності керувати кількома інструментами. Крім того, нова вбудована інтеграція SQL у SageMaker Studio дозволяє користувачам даних легко генерувати SQL-запити, використовуючи текст природною мовою як вхідні дані, тим самим прискорюючи робочий процес.
Ми рекомендуємо вам вивчити ці функції в SageMaker Studio. Для отримання додаткової інформації див Підготуйте дані за допомогою SQL у Studio.
Додаток
Увімкніть SQL-браузер і клітинку SQL блокнота в настроюваних середовищах
Якщо ви не використовуєте образ дистрибутива SageMaker або образи дистрибутива версії 1.5 або старішої, виконайте такі команди, щоб увімкнути функцію перегляду SQL у середовищі JupyterLab:
Перемістіть віджет браузера SQL
Віджети JupyterLab дозволяють переміщати. Залежно від ваших уподобань, ви можете переміщувати віджети по обидві сторони панелі віджетів JupyterLab. За бажанням ви можете перемістити напрямок віджета SQL на протилежний бік (справа наліво) бічної панелі, просто клацнувши правою кнопкою миші піктограму віджета та вибравши Змінити сторону бічної панелі.
 |
 |
Про авторів
 Пранав Мурті є архітектором спеціалістів із штучного інтелекту та ML в AWS. Він зосереджується на допомозі клієнтам створювати, навчати, розгортати та переносити робочі навантаження машинного навчання (ML) на SageMaker. Раніше він працював у напівпровідниковій промисловості, розробляючи моделі великого комп’ютерного зору (CV) і обробки природної мови (NLP) для вдосконалення напівпровідникових процесів за допомогою найсучасніших методів машинного навчання. У вільний час любить грати в шахи та подорожувати. Ви можете знайти Pranav на LinkedIn.
Пранав Мурті є архітектором спеціалістів із штучного інтелекту та ML в AWS. Він зосереджується на допомозі клієнтам створювати, навчати, розгортати та переносити робочі навантаження машинного навчання (ML) на SageMaker. Раніше він працював у напівпровідниковій промисловості, розробляючи моделі великого комп’ютерного зору (CV) і обробки природної мови (NLP) для вдосконалення напівпровідникових процесів за допомогою найсучасніших методів машинного навчання. У вільний час любить грати в шахи та подорожувати. Ви можете знайти Pranav на LinkedIn.
 Варун Шах є інженером-програмістом, який працює над Amazon SageMaker Studio в Amazon Web Services. Він зосереджений на розробці інтерактивних рішень ML, які спрощують обробку та підготовку даних. У вільний час Варун любить активний відпочинок на свіжому повітрі, включаючи походи та катання на лижах, і завжди готовий відкривати нові, захоплюючі місця.
Варун Шах є інженером-програмістом, який працює над Amazon SageMaker Studio в Amazon Web Services. Він зосереджений на розробці інтерактивних рішень ML, які спрощують обробку та підготовку даних. У вільний час Варун любить активний відпочинок на свіжому повітрі, включаючи походи та катання на лижах, і завжди готовий відкривати нові, захоплюючі місця.
 Сумедха Свамі є головним менеджером із продуктів Amazon Web Services, де він очолює команду SageMaker Studio у її місії з розробки обраної IDE для науки про дані та машинного навчання. Останні 15 років він присвятив розробці споживчих і корпоративних продуктів на основі машинного навчання.
Сумедха Свамі є головним менеджером із продуктів Amazon Web Services, де він очолює команду SageMaker Studio у її місії з розробки обраної IDE для науки про дані та машинного навчання. Останні 15 років він присвятив розробці споживчих і корпоративних продуктів на основі машинного навчання.
 Боско Альбукерке є старшим архітектором партнерських рішень в AWS і має понад 20 років досвіду роботи з базами даних і аналітичними продуктами від постачальників корпоративних баз даних і хмарних провайдерів. Він допомагав технологічним компаніям розробляти та впроваджувати рішення та продукти для аналізу даних.
Боско Альбукерке є старшим архітектором партнерських рішень в AWS і має понад 20 років досвіду роботи з базами даних і аналітичними продуктами від постачальників корпоративних баз даних і хмарних провайдерів. Він допомагав технологічним компаніям розробляти та впроваджувати рішення та продукти для аналізу даних.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

