
Editöre göre resim
AWSveya Amazon Web Services, birçok işletmede depolama, analiz, uygulamalar, dağıtım hizmetleri ve diğerleri için kullanılan bir bulut bilişim hizmetidir. Bu, kullandıkça öde planlarıyla sunucusuz bir şekilde işi desteklemek için çeşitli hizmetlerden yararlanan bir platformdur.
Makine öğrenimi modelleme etkinliği de AWS'nin desteklediği etkinliklerden biridir. Modelin geliştirilmesi ve üretime geçirilmesi gibi modelleme faaliyetleri çeşitli hizmetlerle desteklenebilir. AWS, ölçeklenebilirliğe ve hıza ihtiyaç duyan her işletme için gerekli olan çok yönlülüğü göstermiştir.
Bu makalede, AWS bulutundaki bir makine öğrenimi modelinin üretime dağıtılması tartışılacaktır. Bunu nasıl yapabiliriz? Daha fazlasını keşfedelim.
Bu eğitime başlamadan önce bir oluşturmanız gerekir. AWS hesabı, çünkü tüm AWS hizmetlerine erişmeleri için onlara ihtiyacımız olacak. Okuyucunun bu makaleyi takip etmek için ücretsiz katmanı kullanacağını varsayıyorum. Ayrıca okuyucunun Python programlama dilinin nasıl kullanılacağını zaten bildiğini ve makine öğrenimi konusunda temel bilgiye sahip olduğunu varsayıyorum. Ayrıca model konuşlandırma kısmına odaklanacağız ve veri ön işleme ve model değerlendirme gibi veri bilimi faaliyetinin diğer yönlerine odaklanmayacağız.
Bunu aklımızda tutarak, makine öğrenimi modelinizi AWS Bulut hizmetlerinde dağıtma yolculuğumuza başlayacağız.
Bu eğitimde, verilen verilerden kaybı tahmin etmek için bir makine öğrenimi modeli geliştireceğiz. Eğitim veri seti, indirebileceğiniz Kaggle'dan alınmıştır. okuyun.
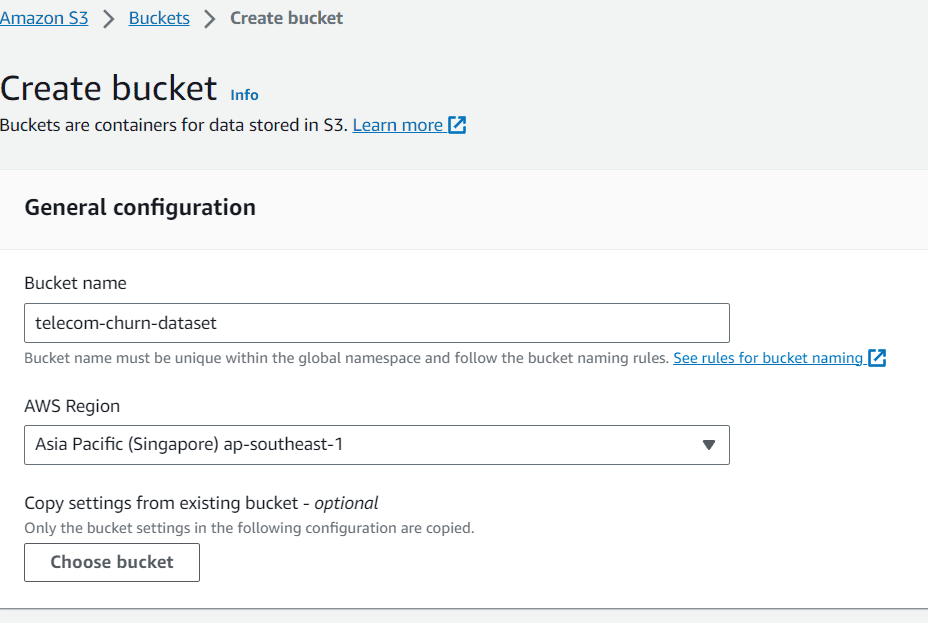
Veri kümesini aldıktan sonra veri kümesini depolamak için bir S3 klasörü oluşturacağız. AWS hizmetlerinde S3'ü arayın ve paketi hazırlayın.
Yazara göre resim
Bu yazıda kovaya “telekom-çalkan-veri kümesi” adını verdim ve Singapur'da bulunuyordum. İsterseniz bunları değiştirebilirsiniz, ancak şimdilik bununla devam edelim.
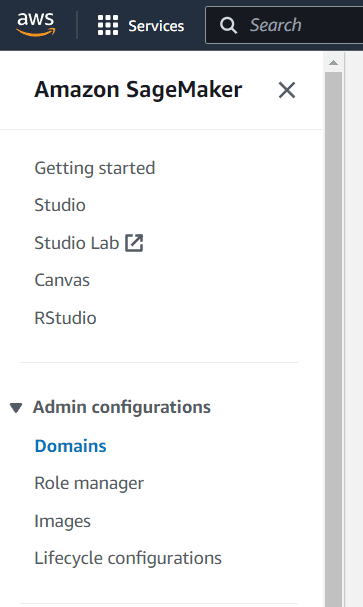
Kovayı oluşturmayı ve verileri paketinize yüklemeyi tamamladıktan sonra AWS SageMaker hizmetine gideceğiz. Bu hizmette çalışma ortamımız olarak Studio'yu kullanacağız. Eğer Studio'yu hiç kullanmadıysanız devam etmeden önce bir alan adı ve kullanıcı oluşturalım.
İlk olarak Amazon SageMaker Admin yapılandırmalarındaki Etki Alanlarını seçin.
Yazara göre resim
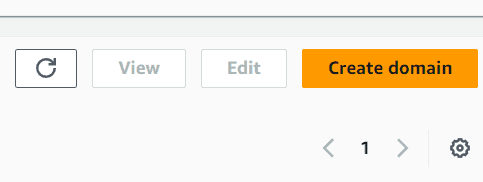
Etki Alanlarında seçebileceğiniz çok sayıda düğme göreceksiniz. Bu ekranda Etki alanı oluştur düğmesini seçin.
Yazara göre resim
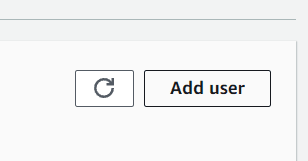
Oluşturma sürecini hızlandırmak istiyorsanız hızlı kurulumu seçin. İşlem tamamlandıktan sonra kontrol panelinde yeni bir alan adının oluşturulduğunu görmelisiniz. Yeni oluşturduğunuz alan adını seçin ve ardından Kullanıcı ekle düğmesine tıklayın.
Yazara göre resim
Daha sonra kullanıcı profilini tercihlerinize göre adlandırmalısınız. Yürütme rolü için, Etki Alanı oluşturma işlemi sırasında oluşturulan rol olduğundan şimdilik bunu varsayılan olarak bırakabilirsiniz.
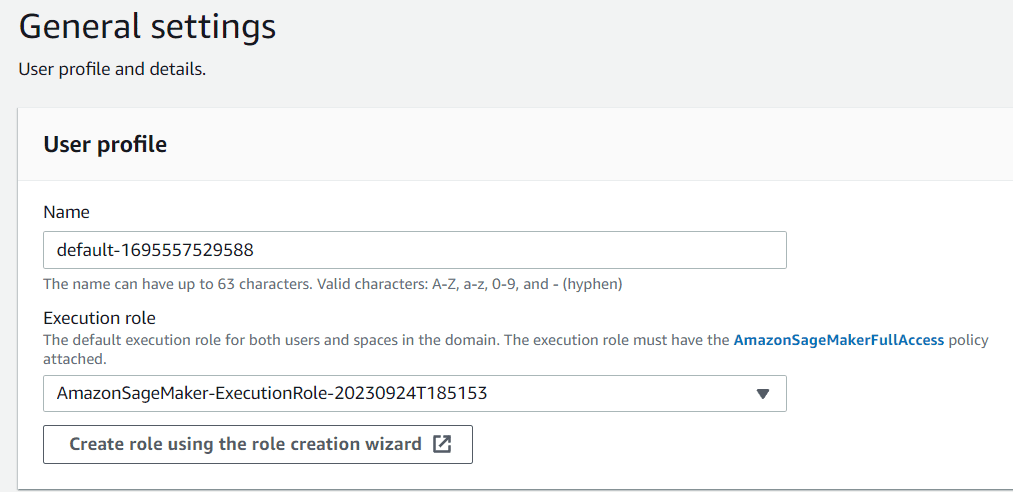
Yazara göre resim
Tuval ayarına kadar ileri'ye tıklamanız yeterlidir. Bu bölümde Time Series Forecasting gibi ihtiyacımız olmayan birkaç ayarı kapatıyorum.
Her şey ayarlandıktan sonra stüdyo seçimine gidin ve az önce oluşturduğunuz kullanıcı adıyla Stüdyoyu aç butonunu seçin.

Yazara göre resim
Studio'nun içinde klasör simgesine benzeyen kenar çubuğuna gidin ve orada yeni bir not defteri oluşturun. Aşağıdaki resimdeki gibi bunlara varsayılan olarak izin verebiliriz.
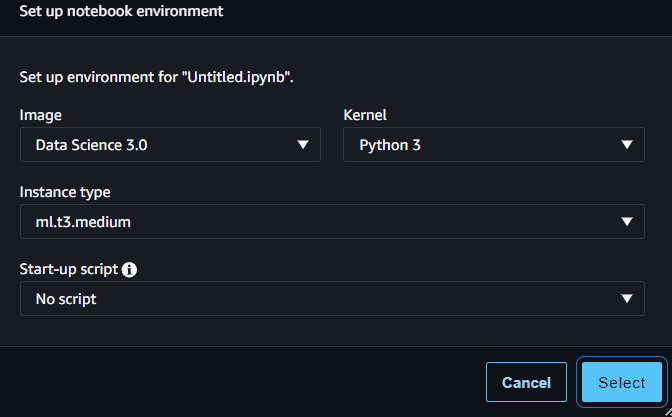
Yazara göre resim
Yeni not defteriyle, bir müşteri kaybı tahmin modeli oluşturmaya ve modeli üretimde kullanabileceğimiz API çıkarımlarına dağıtmaya çalışacağız.
Öncelikle gerekli paketi import edelim ve churn verilerini okuyalım.
import boto3
import pandas as pd
import sagemaker sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role() df = pd.read_csv('s3://telecom-churn-dataset/telecom_churn.csv')

Yazara göre resim
Daha sonra yukarıdaki verileri aşağıdaki kodla eğitim verileri ve test verileri olarak ayıracağız.
from sklearn.model_selection import train_test_split train, test = train_test_split(df, test_size = 0.3, random_state = 42)
Test verilerini orijinal verilerin %30'u olacak şekilde ayarladık. Veri bölmemizle bunları tekrar S3 klasörüne yüklerdik.
bucket = 'telecom-churn-dataset' train.to_csv(f's3://{bucket}/telecom_churn_train.csv', index = False)
test.to_csv(f's3://{bucket}/telecom_churn_test.csv', index = False)
Şu anda üç farklı veri kümesinden oluşan S3 klasörünüzün içindeki verileri görebilirsiniz.
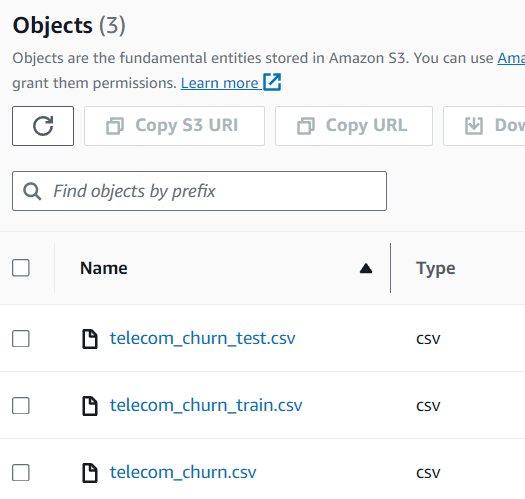
Yazara göre resim
Veri kümemiz hazır olduğunda artık bir müşteri kaybı tahmin modeli geliştirip bunları dağıtacağız. AWS'de makine öğrenimi eğitimi için sıklıkla bir komut dosyası eğitimi yöntemi kullanırız. Bu yüzden eğitime başlamadan önce bir senaryo geliştirirdik.
Bir sonraki adım için aynı klasör içerisinde train.py adını verdiğim ek bir Python dosyası oluşturmamız gerekiyor.
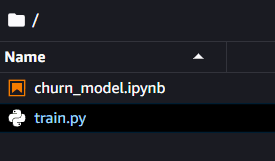
Yazara göre resim
Bu dosyanın içinde, kayıp modelini oluşturmak için model geliştirme sürecimizi ayarlayacağız. Bu eğitim için bazı kodları benimseyeceğim. Ram Vegiraju.
Öncelikle modeli geliştirmek için gerekli tüm paketleri içe aktaracağız.
import argparse
import os
import io
import boto3
import json
import pandas as pd from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import joblib
Daha sonra, eğitim sürecimize girebileceğimiz değişkeni kontrol etmek için ayrıştırıcı yöntemini kullanırız. Modelimizi eğitmek için betiğimize koyacağımız genel kod aşağıdaki koddadır.
if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--estimator', type=int, default=10) parser.add_argument('--sm-model-dir', type=str, default=os.environ.get('SM_MODEL_DIR')) parser.add_argument('--model_dir', type=str) parser.add_argument('--train', type=str, default=os.environ.get('SM_CHANNEL_TRAIN')) args, _ = parser.parse_known_args() estimator = args.estimator model_dir = args.model_dir sm_model_dir = args.sm_model_dir training_dir = args.train s3_client = boto3.client('s3') bucket = 'telecom-churn-dataset' obj = s3_client.get_object(Bucket=bucket, Key='telecom_churn_train.csv') train_data = pd.read_csv(io.BytesIO(obj['Body'].read())) obj = s3_client.get_object(Bucket=bucket, Key='telecom_churn_test.csv') test_data = pd.read_csv(io.BytesIO(obj['Body'].read())) X_train = train_data.drop('Churn', axis =1) X_test = test_data.drop('Churn', axis =1) y_train = train_data['Churn'] y_test = test_data['Churn'] rfc = RandomForestClassifier(n_estimators=estimator) rfc.fit(X_train, y_train) y_pred = rfc.predict(X_test) print('Accuracy Score: ',accuracy_score(y_test, y_pred)) joblib.dump(rfc, os.path.join(args.sm_model_dir, "rfc_model.joblib"))Son olarak SageMaker'ın çıkarım yapabilmesi için ihtiyaç duyduğu dört farklı fonksiyonu koymamız gerekiyor: model_fn, girdi_fn, çıktı_fn ve tahmin_fn.
#Deserialized model to load them def model_fn(model_dir): model = joblib.load(os.path.join(model_dir, "rfc_model.joblib")) return model
#The request input of the application
def input_fn(request_body, request_content_type): if request_content_type == 'application/json': request_body = json.loads(request_body) inp_var = request_body['Input'] return inp_var else: raise ValueError("This model only supports application/json input")
#The prediction functions
def predict_fn(input_data, model): return model.predict(input_data) #The output function
def output_fn(prediction, content_type): res = int(prediction[0]) resJSON = {'Output': res} return resJSON
Senaryomuz hazır olduğundan eğitim sürecini yürütüyoruz. Bir sonraki adımda yukarıda oluşturduğumuz scripti SKLearn tahmin aracına aktaracağız. Bu tahminci, tüm eğitim sürecini yönetecek bir Sagemaker nesnesidir ve yalnızca aşağıdaki koda benzer tüm parametreleri aktarmamız gerekir.
from sagemaker.sklearn import SKLearn sklearn_estimator = SKLearn(entry_point='train.py', role=role, instance_count=1, instance_type='ml.c4.2xlarge', py_version='py3', framework_version='0.23-1', script_mode=True, hyperparameters={ 'estimator': 15})
sklearn_estimator.fit()
Eğitim başarılı olursa aşağıdaki raporla karşılaşacaksınız.

Yazara göre resim
SKLearn eğitimi için Docker imajını ve model yapıtınızın konumunu kontrol etmek istiyorsanız aşağıdaki kodu kullanarak bunlara erişebilirsiniz.
model_artifact = sklearn_estimator.model_data
image_uri = sklearn_estimator.image_uri print(f'The model artifact is saved at: {model_artifact}')
print(f'The image URI is: {image_uri}')
Model mevcut olduğunda, modeli tahmin için kullanabileceğimiz bir API uç noktasına yerleştireceğiz. Bunun için aşağıdaki kodu kullanabiliriz.
import time churn_endpoint_name='churn-rf-model-'+time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime()) churn_predictor=sklearn_estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large',endpoint_name=churn_endpoint_name)
Dağıtım başarılı olursa model uç noktası oluşturulur ve bir tahmin oluşturmak için ona erişebilirsiniz. Ayrıca uç noktayı Sagemaker kontrol panelinde de görebilirsiniz.
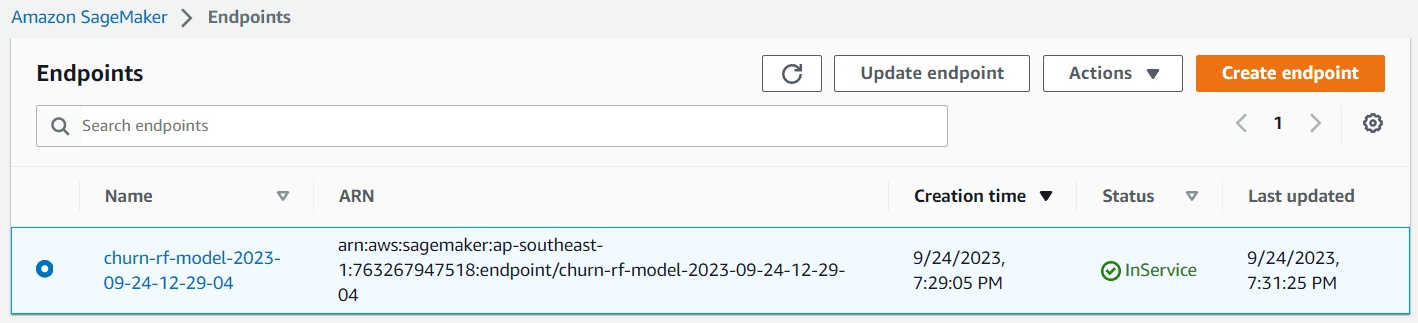
Yazara göre resim
Artık bu uç noktayla tahminlerde bulunabilirsiniz. Bunu yapmak için uç noktayı aşağıdaki kodla test edebilirsiniz.
client = boto3.client('sagemaker-runtime')
content_type = "application/json" #replace with your intended input data
request_body = {"Input": [[128,1,1,2.70,1,265.1,110,89.0, 9.87,10.0]]} #replace with your endpoint name
endpoint_name = "churn-rf-model-2023-09-24-12-29-04" #Data serialization
data = json.loads(json.dumps(request_body))
payload = json.dumps(data) #Invoke the endpoint
response = client.invoke_endpoint( EndpointName=endpoint_name, ContentType=content_type, Body=payload)
result = json.loads(response['Body'].read().decode())['Output']
result
Tebrikler. Artık modelinizi AWS Cloud'da başarıyla devreye aldınız. Test işlemini tamamladıktan sonra uç noktayı temizlemeyi unutmayın. Bunu yapmak için aşağıdaki kodu kullanabilirsiniz.
from sagemaker import Session sagemaker_session = Session()
sagemaker_session.delete_endpoint(endpoint_name='your-endpoint-name')
Artık ihtiyacınız yoksa kullandığınız bulut sunucusunu kapatmayı ve S3 depolama alanını temizlemeyi unutmayın.
Daha fazla okumak için, hakkında daha fazlasını okuyabilirsiniz. SKLearn tahmincisi ve Toplu Dönüşüm çıkarımları bir uç nokta modeline sahip olmayı tercih etmiyorsanız.
AWS Cloud platformu, birçok şirketin işlerini desteklemek için kullandığı çok amaçlı bir platformdur. Sıklıkla kullanılan hizmetlerden biri, özellikle model üretimi olmak üzere veri analitiği amaçlıdır. Bu makalede AWS SageMaker'ın nasıl kullanılacağını ve modelin uç noktaya nasıl dağıtılacağını öğreniyoruz.
Cornellius Yudha Wijaya bir veri bilimi müdür yardımcısı ve veri yazarıdır. Allianz Endonezya'da tam zamanlı çalışırken, sosyal medya ve yazılı medya aracılığıyla Python ve Veri ipuçlarını paylaşmayı seviyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/deploying-your-ml-model-to-production-in-the-cloud?utm_source=rss&utm_medium=rss&utm_campaign=deploying-your-ml-model-to-production-in-the-cloud

