Ortaklık Gönderisi
Python'da büyük veri kümeleriyle, belki de birkaç gigabayt boyutunda çalışıyorsanız, CPU tabanlı pandalar DataFrame'iniz işlemleri gerçekleştirmek için mücadele ederken sorgularınızın bitmesi için saatlerce beklemenin yarattığı hayal kırıklığıyla ilgili olabilirsiniz. Tam olarak bu durum, bir pandalar kullanıcı, veri işleme için GPU'ların gücünden yararlanmayı düşünmelidir. HIZLI cuDF.
Panda benzeri API'si ile RAPIDS cuDF, veri bilimcilerin ve mühendislerin, yalnızca birkaç kod satırı değişikliğiyle GPU'lar üzerindeki muazzam paralel bilgi işlem potansiyelinden hızla yararlanmalarını sağlar.
GPU hızlandırmaya aşina değilseniz, bu gönderi, RAPIDS ekosistemine kolay bir giriş niteliğindedir ve GPU tabanlı pandalar DataFrame muadili olan cuDF'nin en yaygın işlevselliğini gösterir.
Bu ipuçlarının kullanışlı bir özetini ister misiniz? İndirilebilir olanı takip edin cuDF hile sayfası.
cuDF DataFrame ile GPU'lardan yararlanma
cuDF, veri bilimi için bir yapı taşıdır. HIZLI GPU hızlandırmalı kitaplıklar paketi. Verileri işlemek ve yeni özellikler türetmek için veri boru hatları oluşturmak için kullanabileceğiniz bir EDA işgücüdür. RAPIDS paketi içindeki temel bir bileşen olarak cuDF, ortak bir yapı taşı olarak rolünü sağlamlaştırarak diğer kitaplıkların temelini oluşturur. RAPIDS paketindeki tüm bileşenler gibi, cuDF de GPU hesaplamalarına güç sağlamak için CUDA arka ucunu kullanır.
Ancak, kolay ve tanıdık bir Python arayüzü ile cuDF kullanıcılarının doğrudan o katmanla etkileşime girmesi gerekmez.
cuDF, Veri Biliminizin Daha Hızlı Çalışmasını Nasıl Sağlayabilir?
Komut dosyanız çalışırken saate bakmaktan sıkıldınız mı? İster dize verilerini işliyor olun, ister zaman serileri ile çalışıyor olun, verilerinizi ileriye götürmek için cuDF'yi kullanmanın birçok yolu vardır.
- Zaman serisi analizi: İster verileri yeniden örnekliyor, ister özellikleri ayıklıyor veya karmaşık hesaplamalar yapıyor olun, cuDF, zaman serisi analizi için potansiyel olarak pandalardan 880 kata kadar daha hızlı, önemli bir hızlanma sunar.
- Gerçek zamanlı keşif veri analizi (EDA): Büyük veri kümelerine göz atmak, geleneksel araçlarla bir angarya olabilir, ancak cuDF'nin GPU hızlandırmalı işlem gücü, mümkün olan en büyük veri kümelerinin bile gerçek zamanlı olarak keşfedilmesini sağlar
- Makine öğrenimi (ML) veri hazırlama: Veri dönüştürme görevlerini hızlandırın ve verilerinizi regresyon, sınıflandırma ve kümeleme, cuDF'nin hızlandırma yetenekleriyle. Verimli işleme, daha hızlı model geliştirme anlamına gelir ve dağıtıma daha hızlı geçmenizi sağlar.
- Büyük ölçekli veri görselleştirme: İster coğrafi veriler için ısı haritaları oluşturuyor ister karmaşık finansal eğilimleri görselleştiriyor olun, geliştiriciler cuDF ve cuxfilter kullanarak yüksek performanslı ve yüksek FPS'li veri görselleştirme ile veri görselleştirme kitaplıklarını dağıtabilir. Bu entegrasyon, gerçek zamanlı etkileşimin analitik döngünüzün hayati bir bileşeni haline gelmesine olanak tanır.
- Büyük ölçekli veri filtreleme ve dönüştürme: Birkaç gigabaytı aşan büyük veri kümeleri için cuDF kullanarak filtreleme ve dönüştürme görevlerini pandalardan çok daha kısa sürede gerçekleştirebilirsiniz.
- Dizi veri işleme: Geleneksel olarak, dize verilerinin işlenmesi, metin verilerinin karmaşık doğası nedeniyle zorlu ve yavaş bir görev olmuştur. Bu işlemler, GPU hızlandırma ile zahmetsiz hale getirilir
- GroupBy işlemleri: GroupBy işlemleri, veri analizinde temel bir unsurdur ancak yoğun kaynak tüketebilir. cuDF, bu görevleri önemli ölçüde hızlandırır ve verilerinizi bölerken ve toplarken daha hızlı içgörüler elde etmenizi sağlar.

GPU işleme için tanıdık arayüz
RAPIDS'in temel önermesi, popüler veri bilimi araçlarına tanıdık bir kullanıcı deneyimi sağlayarak NVIDIA GPU'ların gücüne tüm uygulayıcıların kolayca erişebilmesini sağlamaktır. ETL gerçekleştiriyor, makine öğrenimi modelleri oluşturuyor veya grafikleri işliyor olun, pandaları biliyorsanız, Dizi, scikit-öğrenme or ağX, RAPIDS kullanırken kendinizi evinizde hissedeceksiniz.
CPU'dan GPU Veri Bilimi yığınına geçmek hiç bu kadar kolay olmamıştı: pandalar yerine cuDF'yi içe aktarmak kadar küçük bir değişiklikle, en sevdiğiniz araçları kullanırken iş yüklerini 10-100 kat hızlandırarak (düşük uçta) NVIDIA GPU'ların muazzam gücünden yararlanabilirsiniz ve daha fazla üretkenliğin keyfini çıkarabilirsiniz.
panda kullanan herkes için cuDF API'nin ne kadar tanıdık olduğunu gösteren aşağıdaki örnek kodu kontrol edin.
import pandas as pd
import cudf
df_cpu = pd.read_csv('/data/sample.csv')
df_gpu = cudf.read_csv('/data/sample.csv')Favori veri kaynaklarınızdan veri yükleme
cuDF'nin okuma ve yazma yetenekleri, RAPIDS'in Ekim 2018'deki ilk sürümünden bu yana önemli ölçüde arttı. Veriler bir makinede yerel olabilir, şirket içi bir kümede veya bulutta depolanabilir. cuDF kullanımları fsspec kitaplığı dosya sistemiyle ilgili görevlerin çoğunu özetler, böylece en önemli olana odaklanabilirsiniz: özellikler oluşturmaya ve modelinizi oluşturmaya.
fsspec sayesinde, yerel veya bulut dosya sisteminden veri okumak, yalnızca ikincisine kimlik bilgileri sağlamayı gerektirir. Aşağıdaki örnek, aynı dosyayı iki farklı konumdan okur,
import cudf
df_local = cudf.read_csv('/data/sample.csv')
df_remote = cudf.read_csv(
's3://<bucket>/sample.csv'
, storage_options = {'anon': True})cuDF birden fazla dosya formatını destekler: CSV/TSV veya JSON gibi metin tabanlı formatlar, sütun odaklı formatlar gibi Parke or ORCveya satır yönelimli biçimler gibi Avro. Dosya sistemi desteği açısından cuDF, yerel dosya sisteminden, AWS S3, Google GS veya Azure Blob/Data Lake gibi bulut sağlayıcılarından, şirket içi veya şirket dışı Hadoop Dosya Sistemlerinden ve ayrıca doğrudan HTTP veya (S)'den dosyaları okuyabilir. )FTP web sunucuları, Dropbox veya Google Drive veya Jupyter Dosya Sistemi.
DataFrame'leri kolaylıkla oluşturma ve kaydetme
cuDF DataFrames oluşturmanın tek yolu dosyaları okumak değildir. Aslında, bunu yapmanın en az 4 yolu vardır:
Bir değerler listesinden bir sütunla DataFrame oluşturabilirsiniz,
cudf.DataFrame([1,2,3,4], columns=['foo'])
Birden çok sütunlu bir DataFrame oluşturmak istiyorsanız bir sözlük iletmek,
cudf.DataFrame({
'foo': [1,2,3,4]
, 'bar': ['a','b','c',None]
})Boş bir DataFrame oluşturma ve sütunlara atama,
df_sample = cudf.DataFrame()
df_sample['foo'] = [1,2,3,4]
df_sample['bar'] = ['a','b','c',None]Tuple listesini geçmek,
cudf.DataFrame([
(1, 'a')
, (2, 'b')
, (3, 'c')
, (4, None)
], columns=['ints', 'strings'])Ayrıca diğer bellek temsillerine ve bunlardan dönüştürebilirsiniz:
- DeviceNDArray olarak temsil edilen dahili bir GPU matrisinden,
- Tensörleri paylaşmak için kullanılan DLPack bellek nesneleri aracılığıyla derin öğrenme çeşitli programlama dillerinden bellek nesnelerini manipüle etmenin çok daha uygun bir yolunu kolaylaştıran çerçeveler ve Apache Arrow formatı,
- Panda DataFrames ve Series'e dönüştürmek için.
Ayrıca cuDF, bir DataFrame'de depolanan verilerin birden çok biçime ve dosya sistemine kaydedilmesini destekler. Aslında, cuDF verileri okuyabildiği tüm biçimlerde depolayabilir.
Tüm bu yetenekler, göreviniz ne olursa olsun veya verileriniz nerede yaşıyor olursa olsun, hızlı bir şekilde çalışmaya başlamanızı mümkün kılar.
Verileri çıkarma, dönüştürme ve özetleme
Temel veri bilimi görevi ve tüm veri bilimcilerin şikayet ettiği görev, temizlik, özellikli ve veri kümesini tanımak. Zamanımızın %80'ini buna harcıyoruz. Neden bu kadar zaman alıyor?
Bunun nedenlerinden biri, sorduğumuz soruların sormak veri kümesinin yanıt vermesi çok uzun sürüyor. Bir CPU üzerinde 2GB'lık bir veri setini okumaya ve işlemeye çalışan herkes neden bahsettiğimizi bilir.
Ek olarak, insan olduğumuz ve hatalar yapabildiğimiz için, bir boru hattını yeniden çalıştırmak kısa sürede tam günlük bir alıştırmaya dönüşebilir. Bu, aşağıdaki tabloya bakarsak üretkenlik kaybına ve muhtemelen bir kahve bağımlılığına neden olur.
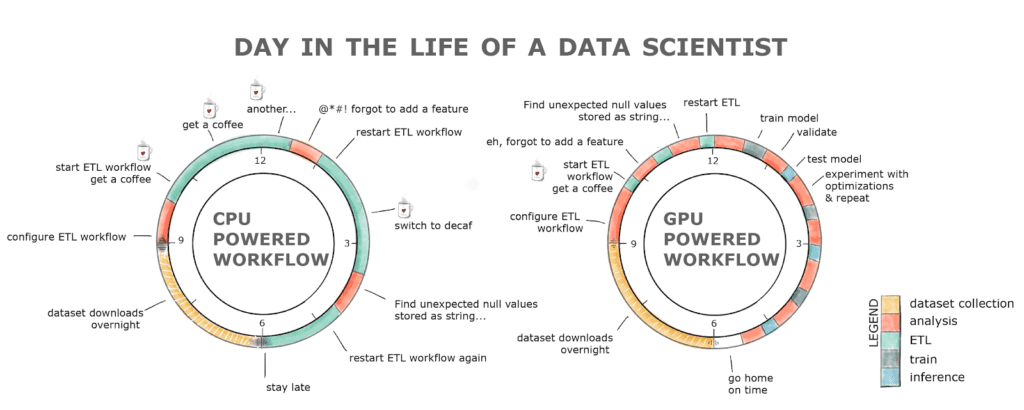
Şekil 1. GPU ve CPU destekli iş akışı kullanan bir geliştirici için tipik bir iş günü
GPU destekli iş akışına sahip RAPIDS, tüm bu engelleri ortadan kaldırır. ETL aşaması normalde 8-20 kat daha hızlıdır, bu nedenle 2 GB veri kümesinin yüklenmesi bir CPU'daki dakikalara kıyasla saniyeler sürer, verilerin temizlenmesi ve dönüştürülmesi de çok daha hızlıdır! Bütün bunlar tanıdık bir arayüz ve minimum kod değişikliği ile.
GPU'larda dizeler ve tarihlerle çalışma
5 yılı aşkın bir süre önce, GPU'larda diziler ve tarihlerle çalışmak neredeyse imkansız ve CUDA gibi düşük seviyeli programlama dillerinin ulaşamayacağı bir şey olarak görülüyordu. Ne de olsa, GPU'lar grafikleri işlemek, yani dizeleri veya tarihleri değil, büyük dizileri ve ints ve float matrislerini manipüle etmek için tasarlandı.
RAPIDS, yalnızca dizeleri GPU belleğine okumanıza değil, aynı zamanda özellikleri çıkarmanıza, işlemenize ve değiştirmenize de olanak tanır. Regex'e aşina iseniz, bir GPU'daki bir belgeden yararlı bilgiler çıkarmak, cuDF sayesinde artık önemsiz bir iştir. Örneğin, belgenizdeki [az]* akış düzeniyle eşleşen tüm sözcükleri bulup ayıklamak istiyorsanız (örneğin, veriakış, Çalışmaakışya da akış) tek yapmanız gereken,
df['string'].str.findall('([a-z]*flow)')
Tarihlerden faydalı özellikleri çıkarmak veya belirli bir zaman dilimindeki verileri sorgulamak da RAPIDS sayesinde daha kolay ve hızlı hale geldi.
dt_to = dt.datetime.strptime("2020-10-03", "%Y-%m-%d")
df.query('dttm <= @dt_to')GPU hızlandırma ile Panda Kullanıcılarını Güçlendirme
RAPIDS ile CPU'dan GPU veri bilimi yığınına geçiş basittir. Pandalar yerine cuDF'yi içe aktarmak, çok büyük faydalar sağlayabilecek küçük bir değişikliktir. İster yerel bir GPU kutusu üzerinde çalışıyor olun, ister tam teşekküllü veri merkezlerine ölçeklendirin, RAPIDS'in GPU hızlandırmalı gücü 10-100 kat hız artışı sağlar (düşük uçta). Bu sadece artan üretkenliğe yol açmakla kalmaz, aynı zamanda en zorlu, büyük ölçekli senaryolarda bile en sevdiğiniz aletlerin verimli bir şekilde kullanılmasına olanak tanır.
RAPIDS, veri bilimcilerin bir zamanlar saatler hatta günler süren görevleri dakikalar içinde tamamlamasına olanak tanıyarak veri işleme alanında gerçek bir devrim yaratarak üretkenliğin artmasına ve toplam maliyetlerin düşmesine yol açtı.
Bu teknikleri veri kümenize uygulamaya başlamak için şu makaleyi okuyun: NVIDIA Teknik Blog'da hızlandırılmış veri analitiği serisi.
Editörün Notu: Bu Facebook post izin alınarak güncellendi ve orijinal olarak NVIDIA Teknik Blogundan uyarlandı.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. Otomotiv / EV'ler, karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- Blok Ofsetleri. Çevre Dengeleme Sahipliğini Modernleştirme. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/07/mastering-gpus-beginners-guide-gpu-accelerated-dataframes-python.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-gpus-a-beginners-guide-to-gpu-accelerated-dataframes-in-python

