Büyük dil modelleri (LLM'ler) genellikle etki alanından bağımsız, halka açık büyük veri kümeleri üzerinde eğitilir. Örneğin, Meta'nın Laması modeller gibi veri kümeleri üzerinde eğitilir Ortak Tarama, C4, Vikipedi ve arXiv. Bu veri kümeleri çok çeşitli konuları ve alanları kapsamaktadır. Ortaya çıkan modeller, metin oluşturma ve varlık tanıma gibi genel görevler için şaşırtıcı derecede iyi sonuçlar vermesine rağmen, alana özgü veri kümeleriyle eğitilen modellerin LLM performansını daha da artırabileceğine dair kanıtlar vardır. Örneğin, kullanılan eğitim verileri BloombergGPT Mali haberler, başvurular ve diğer mali materyaller dahil olmak üzere %51 alana özgü belgelerden oluşur. Ortaya çıkan LLM, finansa özgü görevlerde test edildiğinde, alana özgü olmayan veri kümeleri üzerinde eğitilmiş LLM'lerden daha iyi performans gösteriyor. Yazarları BloombergGPT modellerinin beş finansal görevden dördü için test edilen diğer tüm modellerden daha iyi performans gösterdiği sonucuna vardı. Model, Bloomberg'in iç mali görevleri için geniş bir farkla test edildiğinde daha da iyi bir performans sağladı; 60 üzerinden 100 puana kadar daha iyi. Kapsamlı değerlendirme sonuçları hakkında daha fazla bilgiyi şu adreste bulabilirsiniz: kâğıt, aşağıdaki örnekten alınmıştır BloombergGPT makale size finansal alana özgü verileri kullanarak Yüksek Lisans eğitimi vermenin faydalarına dair bir fikir verebilir. Örnekte gösterildiği gibi BloombergGPT modeli doğru yanıtlar sağlarken alana özgü olmayan diğer modeller zorlandı:
Bu gönderi, özellikle finansal alan için LLM'lerin eğitimi konusunda bir rehber sunmaktadır. Aşağıdaki temel alanları kapsıyoruz:
- Veri toplama ve hazırlama – Etkili model eğitimi için ilgili finansal verilerin sağlanması ve düzenlenmesi konusunda rehberlik
- Sürekli ön eğitim ve ince ayar karşılaştırması – Yüksek Lisansınızın performansını optimize etmek için her bir teknik ne zaman kullanılmalı?
- Verimli sürekli ön eğitim – Sürekli ön eğitim sürecini kolaylaştıracak, zamandan ve kaynaklardan tasarruf sağlayacak stratejiler
Bu gönderi, Amazon Finans Teknolojisi bünyesindeki uygulamalı bilim araştırma ekibinin ve Küresel Finans Sektörüne yönelik AWS Dünya Çapında Uzman ekibinin uzmanlığını bir araya getiriyor. İçeriğin bir kısmı makaleye dayanmaktadır Etki Alanına Özel Büyük Dil Modelleri Oluşturmak için Verimli Sürekli Ön Eğitim.
Finans verilerinin toplanması ve hazırlanması
Etki alanı sürekli ön eğitimi, büyük ölçekli, yüksek kaliteli, alana özgü bir veri kümesi gerektirir. Etki alanı veri kümesi iyileştirmenin ana adımları şunlardır:
- Veri kaynaklarını tanımlayın – Alan adı külliyatı için potansiyel veri kaynakları arasında açık web, Wikipedia, kitaplar, sosyal medya ve dahili belgeler yer alır.
- Etki alanı veri filtreleri – Nihai amaç, alan adının derlenmesini düzenlemek olduğundan, hedef alanla ilgisi olmayan örnekleri filtrelemek için ek adımlar uygulamanız gerekebilir. Bu, sürekli ön eğitim için gereksiz külliyatı azaltır ve eğitim maliyetini azaltır.
- Ön İşleme – Veri kalitesini ve eğitim verimliliğini artırmak için bir dizi ön işleme adımını düşünebilirsiniz. Örneğin, belirli veri kaynakları oldukça fazla sayıda gürültülü token içerebilir; tekilleştirme, veri kalitesini artırmak ve eğitim maliyetini azaltmak için yararlı bir adım olarak kabul edilir.
Finansal LLM'ler geliştirmek için iki önemli veri kaynağını kullanabilirsiniz: News CommonCrawl ve SEC dosyaları. SEC başvurusu, ABD Menkul Kıymetler ve Borsa Komisyonu'na (SEC) sunulan bir mali tablo veya başka bir resmi belgedir. Halka açık şirketlerin düzenli olarak çeşitli belgeler sunması gerekmektedir. Bu, yıllar içinde çok sayıda belge oluşturur. News CommonCrawl, CommonCrawl tarafından 2016 yılında yayınlanan bir veri kümesidir. Dünyanın her yerindeki haber sitelerinden haber makalelerini içerir.
Haberler CommonCrawl şu adreste mevcuttur: Amazon Basit Depolama Hizmeti (Amazon S3) commoncrawl kovalamak crawl-data/CC-NEWS/. Dosya listelerini kullanarak alabilirsiniz. AWS Komut Satırı Arayüzü (AWS CLI) ve aşağıdaki komut:
In Etki Alanına Özel Büyük Dil Modelleri Oluşturmak için Verimli Sürekli Ön Eğitim, yazarlar finansal haber makalelerini genel haberlerden filtrelemek için URL ve anahtar kelimeye dayalı bir yaklaşım kullanıyor. Yazarlar özellikle önemli finansal haber kaynaklarının bir listesini ve finansal haberlerle ilgili bir dizi anahtar kelimeyi tutarlar. Bir makaleyi, finansal haber kaynaklarından geliyorsa veya URL'de herhangi bir anahtar kelime görünüyorsa, finansal haber olarak tanımlarız. Bu basit ama etkili yaklaşım, yalnızca finansal haber kaynaklarından değil, aynı zamanda genel haber kaynaklarının finans bölümlerinden de finansal haberleri tanımlamanıza olanak tanır.
SEC dosyalarına, açık veri erişimi sağlayan SEC'in EDGAR (Elektronik Veri Toplama, Analiz ve Erişim) veritabanı aracılığıyla çevrimiçi olarak ulaşılabilir. Başvuruları doğrudan EDGAR'dan sıyırabilir veya API'leri kullanabilirsiniz. Amazon Adaçayı Yapıcı birkaç satır kodla, herhangi bir süre için ve çok sayıda şerit için (yani, SEC tarafından atanan tanımlayıcı). Daha fazla bilgi edinmek için bkz. SEC Dosya Alma.
Aşağıdaki tablo her iki veri kaynağının temel ayrıntılarını özetlemektedir.
| . | Haberler CommonCrawl | SEC Dosyalama |
| Kapsam | 2016-2022 | 1993-2022 |
| beden | 25.8 milyar kelime | 5.1 milyar kelime |
Yazarlar, veriler bir eğitim algoritmasına beslenmeden önce birkaç ekstra ön işleme adımından geçer. İlk olarak, SEC dosyalarının tablo ve şekillerin kaldırılması nedeniyle gürültülü metinler içerdiğini, dolayısıyla yazarların tablo veya şekil etiketi olduğu düşünülen kısa cümleleri çıkardığını gözlemliyoruz. İkinci olarak, yeni makaleleri ve başvuruları tekilleştirmek için yerelliğe duyarlı bir karma algoritması uyguluyoruz. SEC başvuruları için belge düzeyi yerine bölüm düzeyinde tekilleştirme yapıyoruz. Son olarak, belgeleri uzun bir dize halinde birleştiriyoruz, onu simgeleştiriyoruz ve simgeleştirmeyi, eğitilecek model tarafından desteklenen maksimum giriş uzunluğuna sahip parçalara ayırıyoruz. Bu, sürekli ön eğitimin verimini artırır ve eğitim maliyetini azaltır.
Sürekli ön eğitim ve ince ayar karşılaştırması
Mevcut LLM'lerin çoğu genel amaçlıdır ve alana özgü yeteneklerden yoksundur. Alan Yüksek Lisansı'lar tıbbi, finans veya bilimsel alanlarda önemli bir performans göstermiştir. Bir LLM'nin alana özgü bilgi edinmesi için dört yöntem vardır: sıfırdan eğitim, sürekli ön eğitim, alan görevlerinde talimat ince ayarı ve Alma Artırılmış Üretim (RAG).
Geleneksel modellerde, ince ayar genellikle bir etki alanı için göreve özel modeller oluşturmak amacıyla kullanılır. Bu, varlık çıkarma, amaç sınıflandırması, duygu analizi veya soru yanıtlama gibi birden fazla görev için birden fazla modelin sürdürülmesi anlamına gelir. Yüksek Lisans'ların ortaya çıkışıyla birlikte, bağlam içi öğrenme veya yönlendirme gibi tekniklerin kullanılmasıyla ayrı modellerin sürdürülmesi ihtiyacı ortadan kalktı. Bu, ilgili ancak farklı görevler için bir model yığınını sürdürmek için gereken çabadan tasarruf sağlar.
Sezgisel olarak, LLM'leri alana özgü verilerle sıfırdan eğitebilirsiniz. Her ne kadar alan yüksek lisansı (LLM) oluşturmaya yönelik çalışmaların çoğu sıfırdan eğitime odaklanmış olsa da, bu çok pahalıdır. Örneğin, GPT-4 modelinin maliyetleri 100 milyon dolardan fazla trene. Bu modeller, açık alan verileri ve alan verilerinin bir karışımı üzerinde eğitilir. Sürekli ön eğitim, mevcut bir açık alan yüksek lisans eğitimini yalnızca alan verileri üzerinde önceden eğittiğiniz için sıfırdan ön eğitim maliyetine katlanmadan modellerin alana özgü bilgi edinmesine yardımcı olabilir.
Bir görevde talimat ince ayarı yapıldığında modelin etki alanı bilgisini edinmesini sağlayamazsınız çünkü LLM yalnızca talimat ince ayar veri kümesinde bulunan etki alanı bilgilerini alır. Talimatın ince ayarı için çok büyük bir veri seti kullanılmadığı sürece, alan bilgisini elde etmek yeterli değildir. Yüksek kaliteli talimat veri kümelerini bulmak genellikle zordur ve ilk etapta Yüksek Lisans'ı kullanmanın nedeni budur. Ayrıca, bir göreve ilişkin talimatta ince ayar yapılması, diğer görevlerdeki performansı etkileyebilir (bkz. Bu kağıt). Bununla birlikte, öğretimin ince ayarı, eğitim öncesi alternatiflerin herhangi birinden daha uygun maliyetlidir.
Aşağıdaki şekil geleneksel göreve özel ince ayarı karşılaştırmaktadır. Yüksek Lisans ile bağlam içi öğrenme paradigması vs.
 RAG, bir LLM'nin bir alana dayalı yanıtlar üretmesine rehberlik etmenin en etkili yoludur. Etki alanından yardımcı bilgi olarak gerçekleri sağlayarak yanıtlar oluşturmak için bir modele rehberlik edebilse de, LLM yanıtları oluşturmak için hala alan dışı dil stiline dayandığından alana özgü dili elde etmez.
RAG, bir LLM'nin bir alana dayalı yanıtlar üretmesine rehberlik etmenin en etkili yoludur. Etki alanından yardımcı bilgi olarak gerçekleri sağlayarak yanıtlar oluşturmak için bir modele rehberlik edebilse de, LLM yanıtları oluşturmak için hala alan dışı dil stiline dayandığından alana özgü dili elde etmez.
Sürekli ön eğitim, maliyet açısından ön eğitim ile öğretimin ince ayarı arasında bir orta yol olmakla birlikte, alana özgü bilgi ve stil kazanmaya güçlü bir alternatiftir. Sınırlı talimat verileri üzerinde daha fazla talimat ince ayarının yapılabileceği genel bir model sağlayabilir. Sürekli ön eğitim, aşağı yönlü görev kümesinin büyük olduğu veya bilinmediği ve etiketli talimat ayarlama verilerinin sınırlı olduğu özel alanlar için uygun maliyetli bir strateji olabilir. Diğer senaryolarda talimat ince ayarı veya RAG daha uygun olabilir.
İnce ayar, RAG ve model eğitimi hakkında daha fazla bilgi edinmek için bkz. Bir temel modeline ince ayar yapın, Erişim Artırılmış Nesil (RAG), ve Amazon SageMaker ile Model Eğitin, sırasıyla. Bu yazı için verimli sürekli ön eğitime odaklanıyoruz.
Verimli sürekli ön eğitim metodolojisi
Sürekli ön eğitim aşağıdaki metodolojiden oluşur:
- Etki Alanına Uyarlanabilir Sürekli Ön Eğitim (DACP) - Kağıtta Etki Alanına Özel Büyük Dil Modelleri Oluşturmak için Verimli Sürekli Ön Eğitim, yazarlar Pythia dil modeli paketini finans alanına uyarlamak için finansal külliyat üzerinde sürekli olarak önceden eğitiyorlar. Amaç, tüm finansal alandan verileri açık kaynaklı bir modele besleyerek finansal LLM'ler oluşturmaktır. Eğitim külliyatı, alandaki tüm seçilmiş veri kümelerini içerdiğinden, ortaya çıkan modelin finansa özgü bilgi edinmesi ve böylece çeşitli finansal görevler için çok yönlü bir model haline gelmesi gerekir. Bunun sonucunda FinPythia modelleri ortaya çıkar.
- Göreve Uyarlanabilir Sürekli Ön Eğitim (TACP) – Yazarlar, modelleri belirli görevlere uyarlamak için etiketli ve etiketsiz görev verileri üzerinde daha fazla ön eğitim verir. Belirli durumlarda geliştiriciler, alana özgü bir model yerine, bir grup alan içi görevde daha iyi performans sağlayan modelleri tercih edebilir. TACP, etiketli verilere gerek kalmadan, hedeflenen görevlerde performansı artırmayı amaçlayan sürekli bir ön eğitim olarak tasarlanmıştır. Özellikle, yazarlar açık kaynaklı modelleri görev belirteçleri (etiketler olmadan) üzerinde sürekli olarak önceden eğitirler. TACP'nin birincil sınırlaması, eğitim için yalnızca etiketlenmemiş görev verilerinin kullanılması nedeniyle temel LLM'ler yerine göreve özgü LLM'lerin oluşturulmasında yatmaktadır. DACP çok daha büyük bir derlem kullanmasına rağmen, aşırı derecede pahalıdır. Bu sınırlamaları dengelemek için yazarlar, hedef görevlerde üstün performansı korurken alana özgü temel LLM'ler oluşturmayı amaçlayan iki yaklaşım önermektedir:
- Verimli Görev Benzeri DACP (ETS-DACP) – Yazarlar, gömme benzerliğini kullanarak, görev verilerine oldukça benzeyen bir mali derlem alt kümesinin seçilmesini önermektedir. Bu alt küme, daha verimli hale getirmek amacıyla sürekli ön eğitim için kullanılır. Spesifik olarak, yazarlar açık kaynaklı LLM'yi, dağıtımdaki hedef görevlere yakın olan finansal külliyattan çıkarılan küçük bir külliyat üzerinde sürekli olarak önceden eğitirler. Bu, görev performansının iyileştirilmesine yardımcı olabilir çünkü etiketli verilere gerek olmamasına rağmen, görev belirteçlerinin dağıtımına yönelik modeli benimsiyoruz.
- Verimli Görevden Bağımsız DACP (ETA-DACP) – Yazarlar, verimli bir sürekli ön eğitim için mali külliyattan örnekleri seçmek amacıyla görev verilerini gerektirmeyen şaşkınlık ve belirteç türü entropisi gibi ölçümlerin kullanılmasını önermektedir. Bu yaklaşım, görev verilerinin mevcut olmadığı veya daha geniş etki alanı için daha çok yönlü etki alanı modellerinin tercih edildiği senaryolarla başa çıkmak üzere tasarlanmıştır. Yazarlar, eğitim öncesi alan verilerinin bir alt kümesinden alan bilgisi elde etmek için önemli olan veri örneklerini seçmek için iki boyutu benimser: yenilik ve çeşitlilik. Hedef model tarafından kaydedilen şaşkınlıkla ölçülen yenilik, daha önce LLM tarafından görülmeyen bilgiyi ifade eder. Yenilik düzeyi yüksek veriler Yüksek Lisans için yeni bilgiyi gösterir ve bu tür verilerin öğrenilmesi daha zor olarak görülür. Bu, sürekli ön eğitim sırasında yoğun alan bilgisi ile genel LLM'leri günceller. Öte yandan çeşitlilik, dil modelleme üzerine müfredat öğrenimi araştırmasında yararlı bir özellik olarak belgelenen, alan bütünündeki belirteç türlerinin dağılımlarının çeşitliliğini yakalar.
Aşağıdaki şekilde bir ETS-DACP (solda) ile ETA-DACP (sağda) örneği karşılaştırılmaktadır.

Seçilmiş mali külliyattan veri noktalarını aktif olarak seçmek için iki örnekleme şeması benimsiyoruz: katı örnekleme ve yumuşak örnekleme. İlki, ilk önce mali külliyatın karşılık gelen ölçütlere göre sıralanması ve ardından k'nın eğitim bütçesine göre önceden belirlendiği en iyi k örneklerinin seçilmesiyle yapılır. İkincisi için yazarlar, metrik değerlere göre her veri noktası için örnekleme ağırlıkları atar ve ardından eğitim bütçesini karşılamak için k veri noktasını rastgele örnekler.
Sonuç ve analiz
Yazarlar, sürekli ön eğitimin etkinliğini araştırmak için ortaya çıkan finansal LLM'leri bir dizi finansal görev üzerinde değerlendiriyor:
- Finansal İfade Bankası – Finans haberleriyle ilgili bir duyarlılık sınıflandırma görevi.
- FiQA SA – Finansal haberlere ve manşetlere dayalı, boyuta dayalı bir duygu sınıflandırma görevi.
- Başlık – Bir finansal varlıktaki başlığın belirli bilgileri içerip içermediğine ilişkin ikili sınıflandırma görevi.
- NER – SEC raporlarının kredi riski değerlendirme bölümüne dayanan, finansal olarak adlandırılmış varlık çıkarma görevi. Bu görevdeki kelimelere PER, LOC, ORG ve MISC ek açıklamaları eklenmiştir.
Finansal LLM'lerde talimatlara göre ince ayar yapıldığından, yazarlar sağlamlık adına modelleri her görev için 5 adımlı bir ortamda değerlendirirler. Ortalama olarak FinPythia 6.9B, dört görevde Pythia 6.9B'den %10 daha iyi performans gösteriyor; bu da alana özgü sürekli ön eğitimin etkinliğini gösteriyor. 1B modeli için iyileşme daha az kapsamlıdır ancak performans yine de ortalama %2 oranında artmaktadır.
Aşağıdaki şekil her iki modelde DACP öncesi ve sonrası performans farkını göstermektedir.

Aşağıdaki şekilde Pythia 6.9B ve FinPythia 6.9B tarafından oluşturulan iki nitel örnek gösterilmektedir. Bir yatırımcı yöneticisi ve bir finansal şartla ilgili finansla ilgili iki soru için Pythia 6.9B terimi anlamıyor veya adı tanımıyor; FinPythia 6.9B ise ayrıntılı yanıtları doğru şekilde üretiyor. Niteliksel örnekler, sürekli ön eğitimin LLM'lerin süreç boyunca alan bilgisi edinmesine olanak sağladığını göstermektedir.

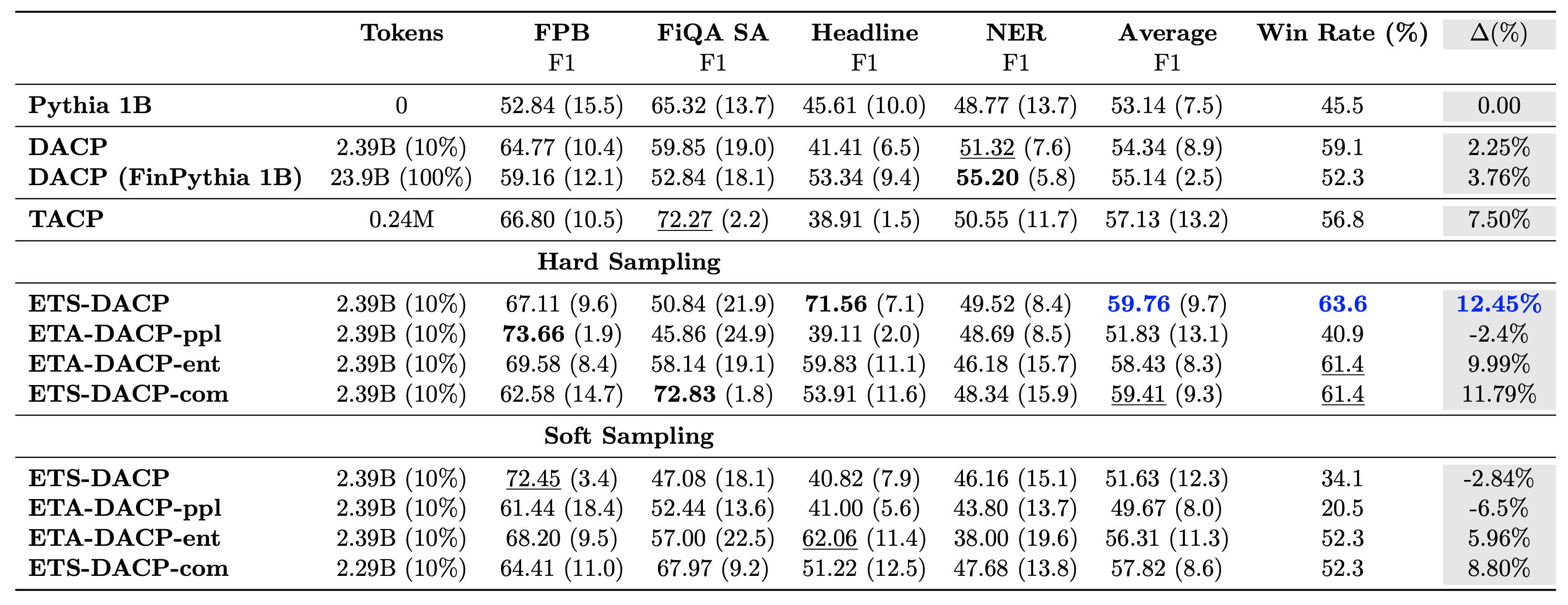
Aşağıdaki tablo çeşitli etkili sürekli eğitim öncesi yaklaşımları karşılaştırmaktadır. ETA-DACP-ppl, şaşkınlık (yenilik) temelli ETA-DACP'dir ve ETA-DACP-ent entropi (çeşitlilik) temeline dayanır. ETS-DACP-com, üç ölçümün hepsinin ortalaması alınarak veri seçimiyle DACP'ye benzer. Sonuçlardan birkaç çıkarım aşağıdadır:
- Veri seçim yöntemleri etkilidir – Antrenman verilerinin yalnızca %10'u ile standart sürekli ön antrenmanı geride bırakıyorlar. Görev-Benzer DACP (ETS-DACP), entropiye dayalı Görev-Agnostik DACP (ESA-DACP-ent) ve her üç ölçümü temel alan Görev-Benzer DACP (ETS-DACP-com) dahil olmak üzere verimli sürekli ön eğitim, standart DACP'den daha iyi performans gösterir Finansal yapının yalnızca %10'u konusunda eğitim almış olmalarına rağmen ortalama olarak.
- Görev bilinçli veri seçimi, küçük dil modelleri araştırması doğrultusunda en iyi sonucu verir – ETS-DACP, tüm yöntemler arasında en iyi ortalama performansı kaydeder ve üç ölçümün tümüne dayanarak ikinci en iyi görev performansını kaydeder. Bu, etiketlenmemiş görev verilerinin kullanılmasının, LLM'lerde görev performansını artırmak için hala etkili bir yaklaşım olduğunu göstermektedir.
- Görevden bağımsız veri seçimi ikinci sıradadır – ESA-DACP-ent, göreve duyarlı veri seçimi yaklaşımının performansını takip eder; bu da, belirli görevlere bağlı olmayan yüksek kaliteli örnekleri aktif olarak seçerek görev performansını hâlâ artırabileceğimizi ima eder. Bu, üstün görev performansına ulaşırken tüm alan için finansal LLM'ler oluşturmanın yolunu açıyor.
Sürekli ön eğitimle ilgili kritik bir soru, bunun alan dışı görevlerdeki performansı olumsuz etkileyip etkilemediğidir. Yazarlar ayrıca sürekli olarak önceden eğitilen modeli yaygın olarak kullanılan dört genel görev üzerinde değerlendiriyor: soru yanıtlama, akıl yürütme ve tamamlama yeteneğini ölçen ARC, MMLU, TruthQA ve HellaSwag. Yazarlar sürekli ön eğitimin alan dışı performansı olumsuz etkilemediğini bulmuşlardır. Daha fazla ayrıntı için bkz. Etki Alanına Özel Büyük Dil Modelleri Oluşturmak için Verimli Sürekli Ön Eğitim.
Sonuç
Bu gönderi, finansal alan için LLM'lerin eğitimi için veri toplama ve sürekli ön eğitim stratejileri hakkında bilgiler sundu. Finansal görevler için kendi LLM'lerinizi eğitmeye başlayabilirsiniz. Amazon SageMaker Eğitimi or Amazon Ana Kayası bugün.
Yazarlar Hakkında
 Yong Xie Amazon FinTech'te uygulamalı bir bilim insanıdır. Finans için büyük dil modelleri ve Üretken Yapay Zeka uygulamaları geliştirmeye odaklanıyor.
Yong Xie Amazon FinTech'te uygulamalı bir bilim insanıdır. Finans için büyük dil modelleri ve Üretken Yapay Zeka uygulamaları geliştirmeye odaklanıyor.
 Karan Aggarwal Amazon FinTech'te, finans kullanım senaryoları için Üretken Yapay Zeka'ya odaklanan Kıdemli Uygulamalı Bilim Adamıdır. Karan'ın zaman serisi analizi ve NLP konusunda geniş deneyimi var ve özellikle sınırlı etiketli verilerden öğrenmeye ilgi duyuyor
Karan Aggarwal Amazon FinTech'te, finans kullanım senaryoları için Üretken Yapay Zeka'ya odaklanan Kıdemli Uygulamalı Bilim Adamıdır. Karan'ın zaman serisi analizi ve NLP konusunda geniş deneyimi var ve özellikle sınırlı etiketli verilerden öğrenmeye ilgi duyuyor
 azaz ahmad Amazon'da Uygulamalı Bilim Müdürü olarak görev yapıyor ve burada Finans alanında Makine Öğrenimi ve Üretken Yapay Zekanın çeşitli uygulamalarını geliştiren bir bilim insanı ekibine liderlik ediyor. Araştırma ilgi alanları NLP, Üretken Yapay Zeka ve Yüksek Lisans Ajanslarıdır. Doktora derecesini Texas A&M Üniversitesi'nden Elektrik Mühendisliği alanında aldı.
azaz ahmad Amazon'da Uygulamalı Bilim Müdürü olarak görev yapıyor ve burada Finans alanında Makine Öğrenimi ve Üretken Yapay Zekanın çeşitli uygulamalarını geliştiren bir bilim insanı ekibine liderlik ediyor. Araştırma ilgi alanları NLP, Üretken Yapay Zeka ve Yüksek Lisans Ajanslarıdır. Doktora derecesini Texas A&M Üniversitesi'nden Elektrik Mühendisliği alanında aldı.
 Qingwei Li Amazon Web Services'te Makine Öğrenimi Uzmanıdır. Doktora derecesini aldı. Danışmanının araştırma bursu hesabını kırması ve söz verdiği Nobel Ödülü'nü verememesi üzerine Yöneylem Araştırması'nda. Şu anda finansal hizmet alanındaki müşterilerin AWS'de makine öğrenimi çözümleri oluşturmasına yardımcı oluyor.
Qingwei Li Amazon Web Services'te Makine Öğrenimi Uzmanıdır. Doktora derecesini aldı. Danışmanının araştırma bursu hesabını kırması ve söz verdiği Nobel Ödülü'nü verememesi üzerine Yöneylem Araştırması'nda. Şu anda finansal hizmet alanındaki müşterilerin AWS'de makine öğrenimi çözümleri oluşturmasına yardımcı oluyor.
 Raghvender Arni AWS Industries bünyesinde Müşteri Hızlandırma Ekibine (CAT) liderlik etmektedir. CAT, müşteriyle yüz yüze görüşen bulut mimarları, yazılım mühendisleri, veri bilimcileri ve yapay zeka/makine öğrenimi uzmanları ve tasarımcılarından oluşan, gelişmiş prototip oluşturma yoluyla yenilikçiliği destekleyen ve uzmanlaşmış teknik uzmanlık aracılığıyla bulut operasyonel mükemmelliğini destekleyen, küresel, çapraz işlevlere sahip bir ekiptir.
Raghvender Arni AWS Industries bünyesinde Müşteri Hızlandırma Ekibine (CAT) liderlik etmektedir. CAT, müşteriyle yüz yüze görüşen bulut mimarları, yazılım mühendisleri, veri bilimcileri ve yapay zeka/makine öğrenimi uzmanları ve tasarımcılarından oluşan, gelişmiş prototip oluşturma yoluyla yenilikçiliği destekleyen ve uzmanlaşmış teknik uzmanlık aracılığıyla bulut operasyonel mükemmelliğini destekleyen, küresel, çapraz işlevlere sahip bir ekiptir.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

