Gelişen üretim ortamında, yapay zeka ve makine öğreniminin (ML) dönüştürücü gücü, operasyonları kolaylaştıran ve üretkenliği artıran dijital bir devrime öncülük ediyor. Ancak bu ilerleme, veriye dayalı çözümler üreten kuruluşlar için benzersiz zorluklar da beraberinde getiriyor. Endüstriyel tesisler, üretim hatlarına dağılmış sensörlerden, telemetri sistemlerinden ve ekipmanlardan kaynaklanan büyük miktarda yapılandırılmamış verilerle boğuşuyor. Gerçek zamanlı veriler, tahmine dayalı bakım ve anormallik tespiti gibi uygulamalar için kritik öneme sahiptir, ancak bu tür zaman serisi verileriyle her endüstriyel kullanım durumu için özel makine öğrenimi modelleri geliştirmek, veri bilimcilerinden önemli miktarda zaman ve kaynak gerektirir ve bu da yaygın olarak benimsenmesini engeller.
üretken yapay zeka gibi önceden eğitilmiş büyük temel modellerin (FM'ler) kullanılması Claude olarak bilinen basit metin istemlerine dayalı olarak konuşma metninden bilgisayar koduna kadar çeşitli içerikleri hızlı bir şekilde üretebilir. sıfır atış uyarısı. Bu, veri bilimcilerinin her kullanım durumu için belirli makine öğrenimi modellerini manuel olarak geliştirme ihtiyacını ortadan kaldırır ve dolayısıyla yapay zeka erişimini demokratikleştirerek küçük üreticilere bile fayda sağlar. Çalışanlar yapay zeka tarafından oluşturulan içgörüler sayesinde üretkenlik kazanıyor, mühendisler anormallikleri proaktif bir şekilde tespit edebiliyor, tedarik zinciri yöneticileri envanterleri optimize edebiliyor ve tesis liderleri bilgiye dayalı, veriye dayalı kararlar alıyor.
Bununla birlikte, bağımsız FM'ler karmaşık endüstriyel verileri bağlam boyutu kısıtlamalarıyla (tipik olarak) işleme konusunda sınırlamalarla karşı karşıyadır. 200,000'den az jeton), bu da zorluklara yol açıyor. Bu sorunu çözmek için FM'nin doğal dil sorgularına (NLQ'lar) yanıt olarak kod oluşturma yeteneğini kullanabilirsiniz. Ajanlar gibi pandalarAI bu kodu yüksek çözünürlüklü zaman serisi verileri üzerinde çalıştırarak ve FM'leri kullanarak hataları işleyerek devreye giriyor. PandasAI, popüler veri analizi ve manipülasyon aracı olan pandalara üretken yapay zeka yetenekleri ekleyen bir Python kütüphanesidir.
Bununla birlikte, zaman serisi veri işleme, çok düzeyli toplama ve pivot veya ortak tablo işlemleri gibi karmaşık NLQ'lar, sıfır atış istemiyle tutarsız Python komut dosyası doğruluğu sağlayabilir.
Kod oluşturma doğruluğunu artırmak için dinamik olarak oluşturmayı öneriyoruz çoklu çekim istemleri NLQ'lar için. Çoklu çekim istemi, FM'ye benzer istemler için istenen çıktıların çeşitli örneklerini göstererek, doğruluğu ve tutarlılığı artırarak ek bağlam sağlar. Bu gönderide, benzer bir veri türünde (örneğin, Nesnelerin İnterneti cihazlarından yüksek çözünürlüklü zaman serisi verileri) çalıştırılan başarılı Python kodunu içeren bir yerleştirmeden çoklu çekim istemleri alınır. Dinamik olarak oluşturulan çoklu çekim istemi, FM ile en ilgili bağlamı sağlar ve FM'in gelişmiş matematik hesaplama, zaman serisi veri işleme ve veri kısaltmalarını anlama konusundaki yeteneğini artırır. Bu iyileştirilmiş yanıt, kurumsal çalışanların ve operasyonel ekiplerin verilerle etkileşime geçmesini ve kapsamlı veri bilimi becerileri gerektirmeden içgörü elde etmesini kolaylaştırır.
Zaman serisi veri analizinin ötesinde, FM'lerin çeşitli endüstriyel uygulamalarda değerli olduğu kanıtlanmıştır. Bakım ekipleri varlık durumunu değerlendirir, görüntüler yakalar Amazon Rekognisyontabanlı işlevsellik özetleri ve akıllı aramaları kullanarak anormallik kök neden analizi Alma Artırılmış Nesil (RAG). AWS, bu iş akışlarını basitleştirmek için Amazon Ana Kayasıgibi son teknoloji ürünü önceden eğitilmiş FM'lerle üretken yapay zeka uygulamaları oluşturmanıza ve ölçeklendirmenize olanak tanır. Claude v2. Ile Amazon Bedrock için Bilgi Tabanlarıile, tesis çalışanları için daha doğru anormallik kök nedeni analizi sağlamak amacıyla RAG geliştirme sürecini basitleştirebilirsiniz. Gönderimiz, Amazon Bedrock tarafından desteklenen, endüstriyel kullanım örneklerine yönelik, NLQ zorluklarını ele alan, görüntülerden parça özetleri oluşturan ve RAG yaklaşımı aracılığıyla ekipman teşhisi için FM yanıtlarını iyileştiren akıllı bir asistanı sergiliyor.
Çözüme genel bakış
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.

İş akışı üç farklı kullanım durumunu içerir:
Kullanım örneği 1: Zaman serisi verileriyle NLQ
NLQ'nun zaman serisi verileriyle iş akışı aşağıdaki adımlardan oluşur:
- Anormallik tespiti için ML yeteneklerine sahip bir durum izleme sistemi kullanıyoruz; Amazon MonitörüEndüstriyel ekipmanın sağlığını izlemek için. Amazon Monitron, ekipmanın titreşim ve sıcaklık ölçümlerinden olası ekipman arızalarını tespit edebiliyor.
- Zaman serisi verilerini işleyerek topluyoruz Amazon Monitörü aracılığıyla veri Amazon Kinesis Veri Akışları ve Amazon Veri Firehose, bunu tablo halinde CSV formatına dönüştürüp bir dosyaya kaydediyoruz. Amazon Basit Depolama Hizmeti (Amazon S3) kovası.
- Son kullanıcı, Streamlit uygulamasına doğal dil sorgusu göndererek Amazon S3'teki zaman serisi verileriyle sohbet etmeye başlayabilir.
- Streamlit uygulaması kullanıcı sorgularını Amazon Bedrock Titan metin yerleştirme modeli Bu sorguyu yerleştirmek için ve bir benzerlik araması gerçekleştirir. Amazon Açık Arama Hizmeti önceki NLQ'ları ve örnek kodları içeren dizin.
- Benzerlik aramasının ardından, NLQ soruları, veri şeması ve Python kodları da dahil olmak üzere en çok benzeyen örnekler özel bir bilgi istemine eklenir.
- PandasAI bu özel istemi Amazon Bedrock Claude v2 modeline gönderir.
- Uygulama, Amazon Bedrock Claude v2 modeliyle etkileşim kurmak için PandasAI aracısını kullanıyor ve Amazon Monitron veri analizi ve NLQ yanıtları için Python kodu oluşturuyor.
- Amazon Bedrock Claude v2 modeli Python kodunu döndürdükten sonra PandasAI, uygulamadan yüklenen Amazon Monitron verileri üzerinde Python sorgusunu çalıştırarak kod çıktılarını toplar ve başarısız çalıştırmalar için gerekli yeniden denemeleri ele alır.
- Streamlit uygulaması, PandasAI aracılığıyla yanıtı topluyor ve çıktıyı kullanıcılara sağlıyor. Çıktı tatmin ediciyse kullanıcı, NLQ ve Claude tarafından oluşturulan Python kodunu OpenSearch Hizmetine kaydederek bunu faydalı olarak işaretleyebilir.
Kullanım senaryosu 2: Arızalı parçaların özet üretimi
Özet oluşturma kullanım durumumuz aşağıdaki adımlardan oluşur:
- Kullanıcı hangi endüstriyel varlığın anormal davranış gösterdiğini öğrendikten sonra, arızalı parçanın resimlerini yükleyerek teknik özelliklerine ve çalışma durumuna göre bu parçada fiziksel bir sorun olup olmadığını tespit edebilir.
- Kullanıcı, Amazon Tanıma DetectText API'si Bu görüntülerden metin verilerini çıkarmak için.
- Çıkarılan metin verileri Amazon Bedrock Claude v2 modeli istemine dahil edilerek modelin arızalı parçanın 200 kelimelik bir özetini oluşturmasına olanak sağlanır. Kullanıcı bu bilgiyi parça üzerinde daha fazla inceleme yapmak için kullanabilir.
Kullanım senaryosu 3: Kök neden teşhisi
Temel neden teşhisi kullanım senaryomuz aşağıdaki adımlardan oluşur:
- Kullanıcı, arızalı varlıklarla ilgili kurumsal verileri çeşitli belge formatlarında (PDF, TXT vb.) alır ve bunları bir S3 klasörüne yükler.
- Bu dosyaların bilgi tabanı, Amazon Bedrock'ta Titan metin yerleştirme modeli ve varsayılan OpenSearch Hizmeti vektör deposuyla oluşturulur.
- Kullanıcı, arızalı ekipmanın temel nedeninin teşhisiyle ilgili sorular sorar. Yanıtlar Amazon Bedrock bilgi tabanı aracılığıyla RAG yaklaşımıyla oluşturulur.
Önkoşullar
Bu gönderiyi takip etmek için aşağıdaki önkoşulları karşılamanız gerekir:
Çözüm altyapısını devreye alın
Çözüm kaynaklarınızı ayarlamak için aşağıdaki adımları tamamlayın:
- dağıtmak AWS CloudFormation şablon opensearchsagemaker.ymlBir OpenSearch Hizmeti koleksiyonu ve dizini oluşturan, Amazon Adaçayı Yapıcı dizüstü bilgisayar örneği ve S3 paketi. Bu AWS CloudFormation yığınını şu şekilde adlandırabilirsiniz:
genai-sagemaker. - JupyterLab'da SageMaker not defteri örneğini açın. Aşağıdakileri bulacaksınız GitHub repo bu örnekte zaten indirildi: endüstriyel operasyonlarda üretken-yap-potansiyelinin kilidini açmak.
- Not defterini bu depodaki aşağıdaki dizinden çalıştırın: endüstriyel operasyonlarda üretken-ai-potansiyelinin kilidinin açılması/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Bu not defteri, anahtar/değer çiftlerini depolamak için SageMaker not defterini kullanarak OpenSearch Hizmeti dizinini yükleyecektir. mevcut 23 NLQ örneği.
- Belgeleri veri klasöründen yükleyin varlıkpartdoc GitHub deposundaki CloudFormation yığın çıktılarında listelenen S3 klasörüne.

Daha sonra Amazon S3'teki belgeler için bilgi tabanını oluşturursunuz.
- Amazon Bedrock konsolunda şunu seçin: Bilgi tabanı Gezinti bölmesinde.
- Klinik Bilgi tabanı oluştur.
- İçin Bilgi tabanı adı, isim girin.
- İçin Çalışma zamanı rolüseçin Yeni bir hizmet rolü oluşturma ve kullanma.
- İçin Veri kaynağı adı, veri kaynağınızın adını girin.
- İçin S3 URI'sı, temel neden belgelerini yüklediğiniz paketin S3 yolunu girin.
- Klinik Sonraki.
 Titan yerleştirme modeli otomatik olarak seçilir.
Titan yerleştirme modeli otomatik olarak seçilir. - seç Hızlı bir şekilde yeni bir vektör mağazası oluşturun.
- Ayarlarınızı gözden geçirin ve seçim yaparak bilgi tabanını oluşturun. Bilgi tabanı oluştur.
- Bilgi tabanı başarıyla oluşturulduktan sonra Senkronizasyon S3 grubunu bilgi tabanıyla senkronize etmek için.

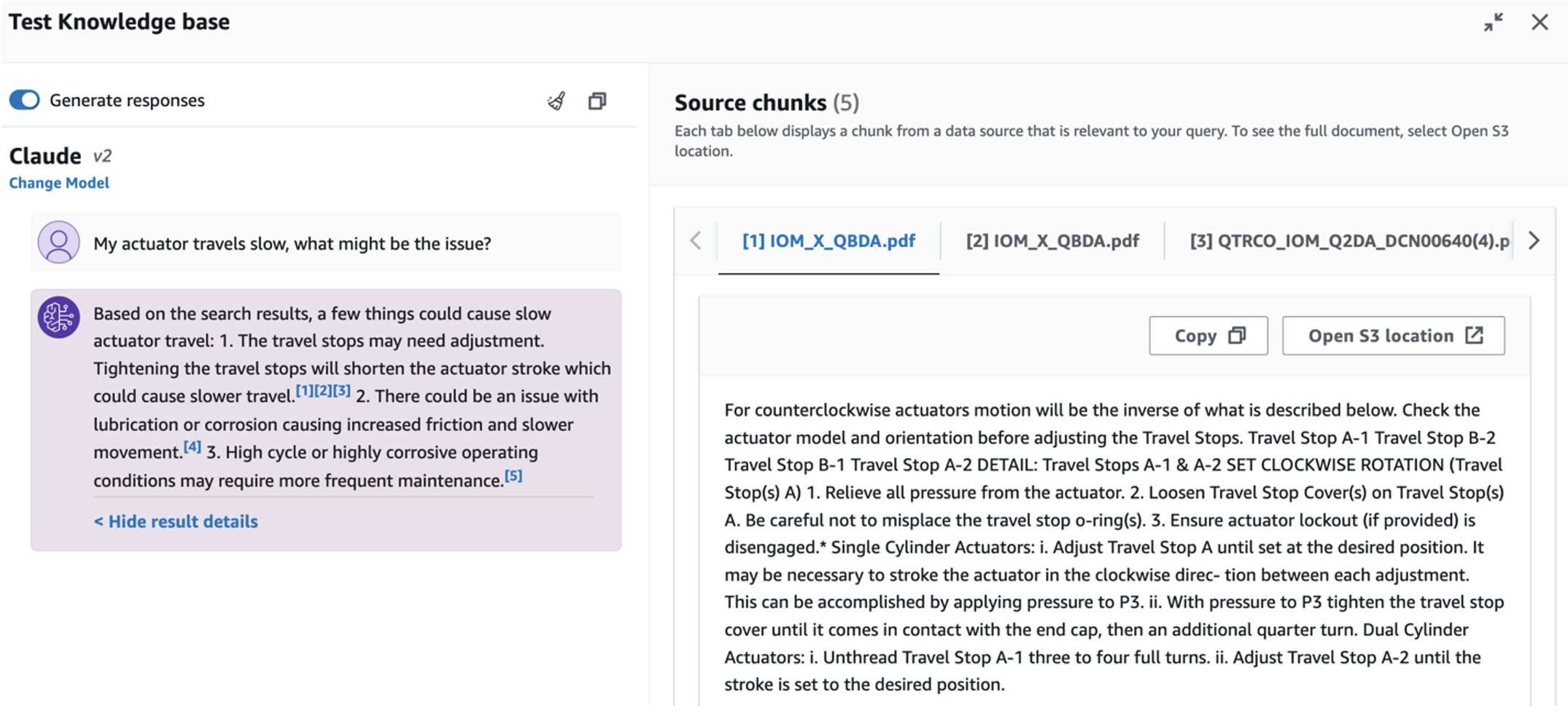
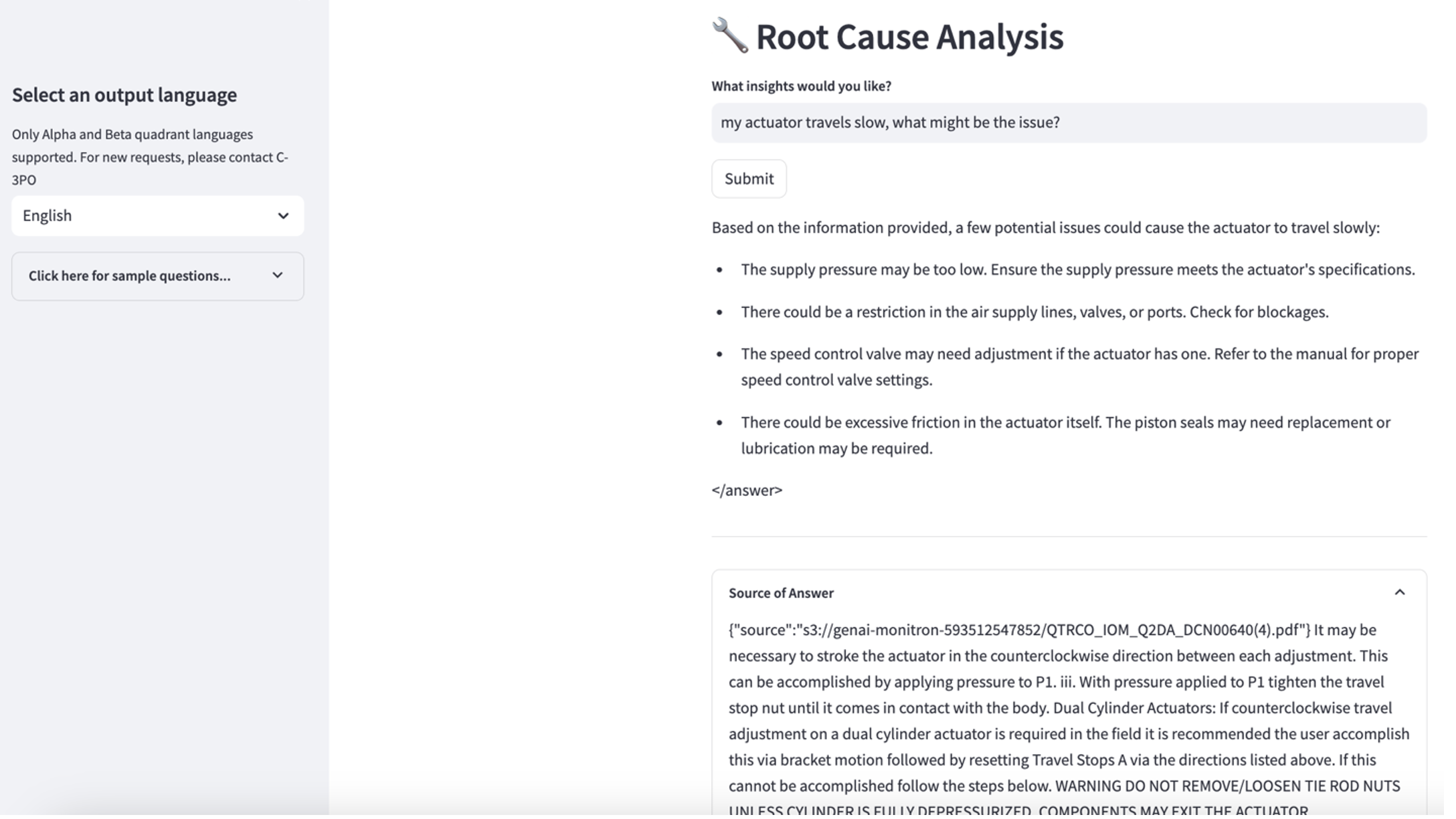
- Bilgi tabanını kurduktan sonra, "Aktüatörüm yavaş hareket ediyor, sorun ne olabilir?" gibi sorular sorarak temel neden teşhisi için RAG yaklaşımını test edebilirsiniz.
Bir sonraki adım, uygulamayı gerekli kitaplık paketleriyle birlikte PC'nize veya bir EC2 örneğine (Ubuntu Server 22.04 LTS) dağıtmaktır.
- AWS kimlik bilgilerinizi ayarlayın Yerel bilgisayarınızdaki AWS CLI ile. Basit olması açısından CloudFormation yığınını dağıtırken kullandığınız yönetici rolünün aynısını kullanabilirsiniz. Amazon EC2 kullanıyorsanız, örneğe uygun bir IAM rolü ekleyin.
- klon GitHub repo:
- dizini değiştir
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcve koşsetup.shLangChain ve PandasAI dahil olmak üzere gerekli paketleri yüklemek için bu klasördeki komut dosyasını kullanın:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Streamlit uygulamasını aşağıdaki komutla çalıştırın:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Önceki adımda Amazon Bedrock'ta oluşturduğunuz OpenSearch Hizmeti koleksiyonu ARN'sini sağlayın.
Varlık sağlığı asistanınızla sohbet edin
Uçtan uca dağıtımı tamamladıktan sonra, web arayüzüne sahip bir tarayıcı penceresi açan 8501 numaralı bağlantı noktasındaki localhost aracılığıyla uygulamaya erişebilirsiniz. Uygulamayı bir EC2 bulut sunucusuna dağıttıysanız güvenlik grubu gelen kuralı aracılığıyla bağlantı noktası 8501 erişimine izin ver. Çeşitli kullanım durumları için farklı sekmelere gidebilirsiniz.
Kullanım senaryosu 1'i keşfedin
İlk kullanım senaryosunu keşfetmek için şunu seçin: Veri Analizi ve Grafik. Zaman serisi verilerinizi yükleyerek başlayın. Kullanabileceğiniz mevcut bir zaman serisi veri dosyanız yoksa aşağıdakileri yükleyebilirsiniz: örnek CSV dosyası anonim Amazon Monitron proje verileriyle. Zaten bir Amazon Monitron projeniz varsa bkz. Amazon Monitron ve Amazon Kinesis ile tahmine dayalı bakım yönetimi için eyleme dönüştürülebilir içgörüler oluşturun Amazon Monitron verilerinizi Amazon S3'e aktarmak ve verilerinizi bu uygulamayla kullanmak için.
Yükleme tamamlandığında verilerinizle bir görüşme başlatmak için bir sorgu girin. Sol kenar çubuğu size kolaylık sağlamak için bir dizi örnek soru sunar. Aşağıdaki ekran görüntüleri, "Sırasıyla Uyarı veya Alarm olarak gösterilen her site için benzersiz sensör sayısını söyle?" gibi bir soru girildiğinde FM tarafından oluşturulan yanıtı ve Python kodunu göstermektedir. (zor seviyeli bir soru) veya "Sıcaklık sinyali SAĞLIKLI OLMAYAN olarak gösterilen sensörler için, anormal titreşim sinyali gösterilen her sensörün zaman süresini gün cinsinden hesaplayabilir misiniz?" (zorluk düzeyinde bir soru). Uygulama sorunuza yanıt verecek ve aynı zamanda bu tür sonuçları oluşturmak için gerçekleştirdiği Python veri analizi komut dosyasını da gösterecektir.


Cevaptan memnun kaldıysanız, olarak işaretleyebilirsiniz. YararlıNLQ ve Claude tarafından oluşturulan Python kodunu bir OpenSearch Hizmeti dizinine kaydederek.

Kullanım senaryosu 2'i keşfedin
İkinci kullanım senaryosunu keşfetmek için Yakalanan Görüntü Özeti Streamlit uygulamasındaki sekme. Endüstriyel varlığınızın bir görselini yükleyebilirsiniz; uygulama, görsel bilgilerine dayanarak teknik özellikleri ve çalışma durumunun 200 kelimelik bir özetini oluşturacaktır. Aşağıdaki ekran görüntüsünde bir kayışlı motor tahrikinin görüntüsünden oluşturulan özet gösterilmektedir. Bu özelliği test etmek için uygun bir görseliniz yoksa aşağıdakileri kullanabilirsiniz. örnek resim.
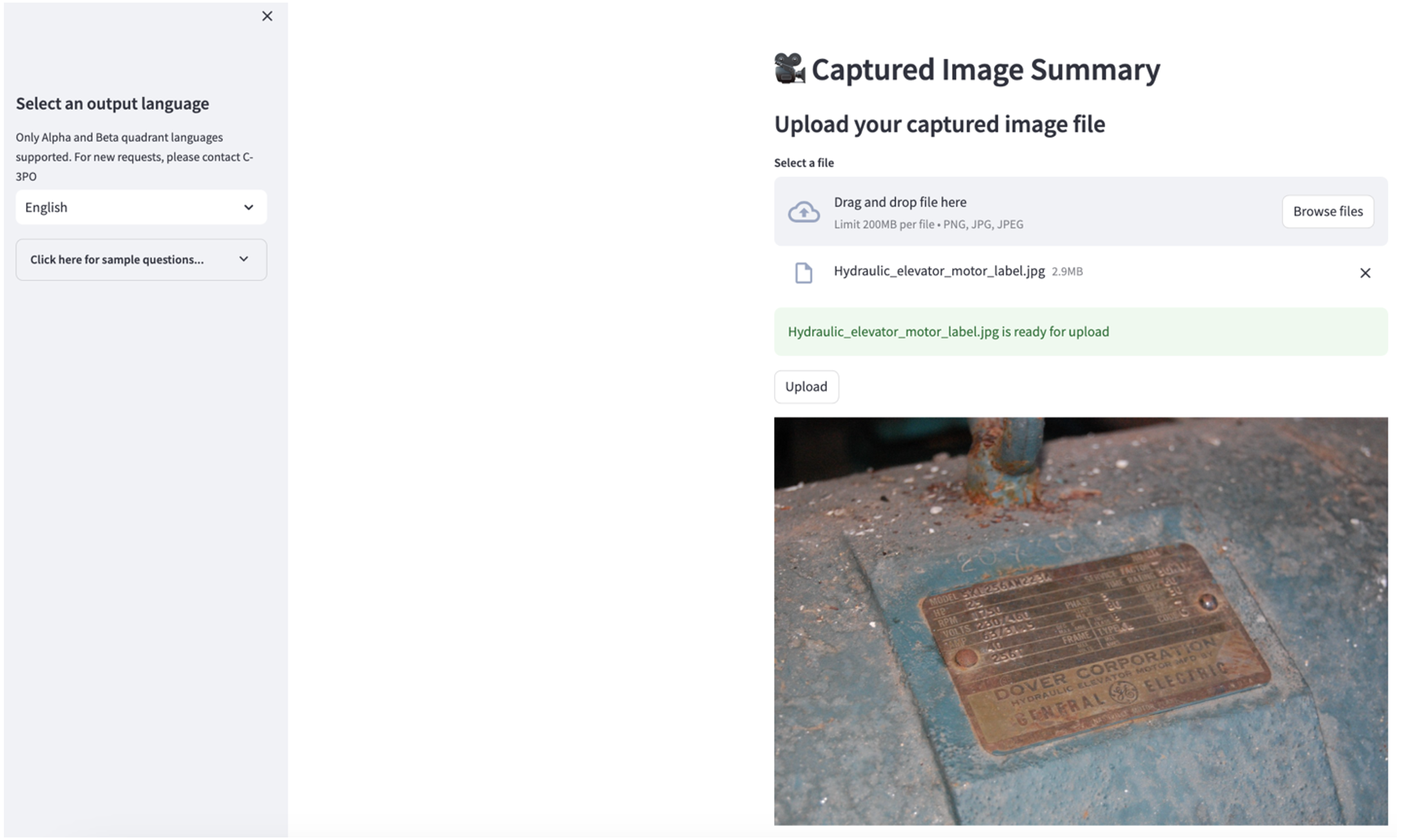
Hidrolik asansör motoru etiketi” Clarence Risher tarafından lisanslanmıştır CC BY-SA 2.0.

Kullanım senaryosu 3'i keşfedin
Üçüncü kullanım senaryosunu keşfetmek için Kök neden teşhisi sekmesi. Arızalı endüstriyel varlığınızla ilgili "Aktüatörüm yavaş hareket ediyor, sorun ne olabilir?" gibi bir sorgu girin. Aşağıdaki ekran görüntüsünde gösterildiği gibi uygulama, yanıtı oluşturmak için kullanılan kaynak belge alıntısıyla birlikte bir yanıt sunar.
Kullanım örneği 1: Tasarım ayrıntıları
Bu bölümde, ilk kullanım senaryosu için uygulama iş akışının tasarım ayrıntılarını tartışıyoruz.
Özel istem oluşturma
Kullanıcının doğal dil sorgusu farklı zorluk seviyeleriyle birlikte gelir: kolay, zor ve zorlu.
Basit sorular aşağıdaki istekleri içerebilir:
- Benzersiz değerleri seçin
- Toplam sayıları say
- Değerleri sırala
Bu sorular için PandasAI, işlenmek üzere Python komut dosyaları oluşturmak üzere FM ile doğrudan etkileşime girebilir.
Zor sorular, aşağıdaki gibi temel toplama işlemini veya zaman serisi analizini gerektirir:
- Önce değeri seçin ve sonuçları hiyerarşik olarak gruplayın
- İlk kayıt seçiminden sonra istatistikleri gerçekleştirin
- Zaman damgası sayısı (örneğin minimum ve maksimum)
Zor sorular için ayrıntılı adım adım talimatlar içeren bir bilgi istemi şablonu, FM'lerin doğru yanıtlar vermesine yardımcı olur.
Zorluk düzeyindeki sorular, aşağıdakiler gibi ileri düzey matematik hesaplamalarına ve zaman serisi işlemlerine ihtiyaç duyar:
- Her sensör için anormallik süresini hesaplayın
- Site için anormallik sensörlerini aylık olarak hesaplayın
- Normal çalışma ve anormal koşullar altında sensör okumalarını karşılaştırın
Bu sorular için, yanıt doğruluğunu artırmak amacıyla özel bir istemde çoklu çekimleri kullanabilirsiniz. Bu tür çoklu çekimler, gelişmiş zaman serisi işleme ve matematik hesaplama örneklerini gösterir ve FM'nin benzer analizler üzerinden ilgili çıkarımları yapması için bağlam sağlar. Bir NLQ soru bankasındaki en alakalı örnekleri istemin içine dinamik olarak eklemek zor olabilir. Çözümlerden biri, mevcut NLQ soru örneklerinden eklemeler oluşturmak ve bu eklemeleri OpenSearch Hizmeti gibi bir vektör deposuna kaydetmektir. Streamlit uygulamasına bir soru gönderildiğinde soru şu şekilde vektörleştirilecektir: Ana Kaya Gömmeleri. Bu soruyla en alakalı ilk N yerleştirme, kullanılarak alınır. opensearch_vector_search.similarity_search ve çoklu çekim istemi olarak bilgi istemi şablonuna eklenir.
Aşağıdaki şemada bu iş akışı gösterilmektedir.
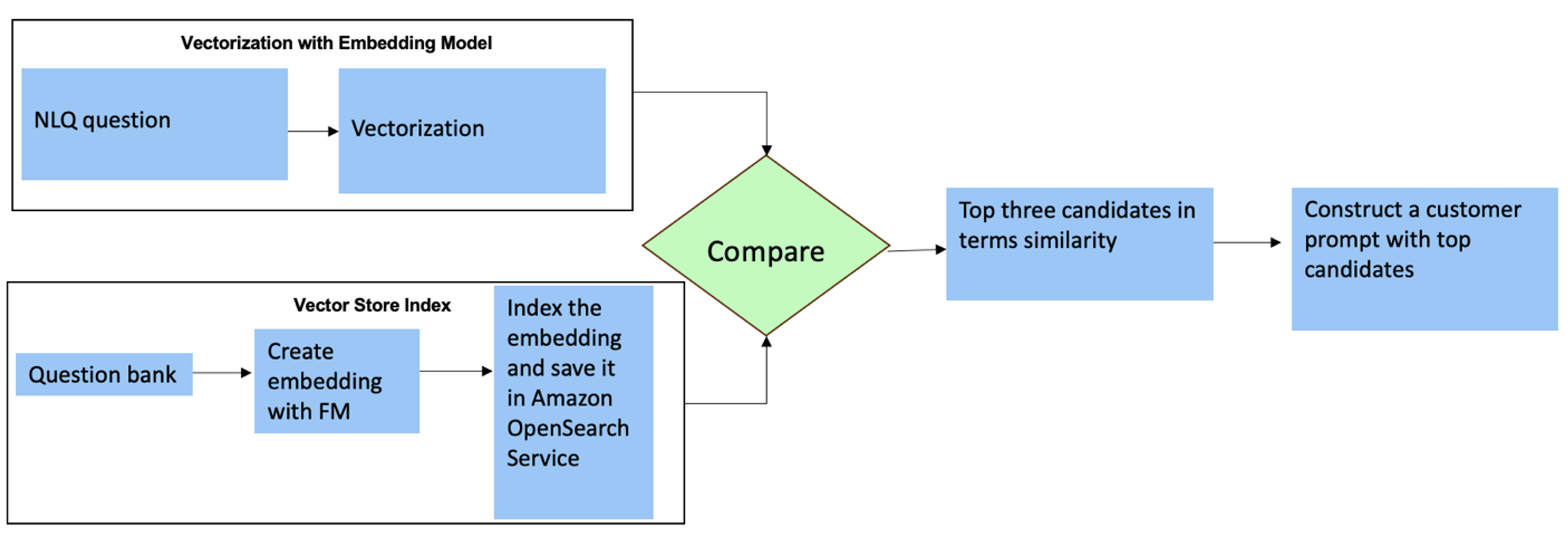
Gömme katmanı üç temel araç kullanılarak oluşturulur:
- Gömme modeli – Amazon Bedrock aracılığıyla sunulan Amazon Titan Gömmelerini kullanıyoruz (amazon.titan-embed-text-v1) metinsel belgelerin sayısal temsillerini oluşturmak için.
- Vektör mağazası – Vektör mağazamız için LangChain çerçevesi aracılığıyla OpenSearch Hizmetini kullanıyoruz ve bu not defterindeki NLQ örneklerinden oluşturulan yerleştirmelerin depolanmasını kolaylaştırıyoruz.
- indeks – OpenSearch Hizmeti dizini, girdi yerleştirmelerini belge yerleştirmeleriyle karşılaştırmada ve ilgili belgelerin alınmasını kolaylaştırmada çok önemli bir rol oynar. Python örnek kodları bir JSON dosyası olarak kaydedildiğinden, OpenSearch Hizmetinde vektörler olarak bir dizine eklendi. OpenSearchVevtorSearch.fromtexts API çağrısı.
Streamlit aracılığıyla insan tarafından denetlenen örneklerin sürekli toplanması
Uygulama geliştirmenin başlangıcında, OpenSearch Service dizininde yerleştirme olarak kaydedilen yalnızca 23 örnekle başladık. Uygulama sahada yayına girdikçe kullanıcılar NLQ'larını uygulama aracılığıyla girmeye başlıyor. Ancak şablondaki örneklerin sınırlı olması nedeniyle bazı NLQ'lar benzer istemleri bulamayabilir. Bu yerleştirmeleri sürekli olarak zenginleştirmek ve daha alakalı kullanıcı istemleri sunmak için, insan tarafından denetlenen örnekleri toplamak amacıyla Streamlit uygulamasını kullanabilirsiniz.
Uygulama içinde aşağıdaki işlev bu amaca hizmet eder. Son kullanıcılar çıktıyı yararlı bulup seçtiklerinde Yararlı, uygulama şu adımları takip eder:
- Python betiğini toplamak için PandasAI'nin geri çağırma yöntemini kullanın.
- Python betiğini, giriş sorusunu ve CSV meta verilerini bir dize halinde yeniden biçimlendirin.
- Bu NLQ örneğinin mevcut OpenSearch Hizmeti dizininde zaten mevcut olup olmadığını kullanarak kontrol edin. opensearch_vector_search.similarity_search_with_score.
- Benzer bir örnek yoksa, bu NLQ, kullanılarak OpenSearch Hizmeti dizinine eklenir. opensearch_vector_search.add_texts.
Kullanıcının seçim yapması durumunda Yararlı değil, herhangi bir işlem yapılmaz. Bu yinelemeli süreç, kullanıcının katkıda bulunduğu örnekleri birleştirerek sistemin sürekli olarak gelişmesini sağlar.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
İnsan denetiminin dahil edilmesiyle, OpenSearch Hizmeti'ndeki hızlı yerleştirme için mevcut örneklerin miktarı, uygulama kullanım kazandıkça artar. Bu genişletilmiş yerleştirme veri kümesi, zaman içinde gelişmiş arama doğruluğu sağlar. Spesifik olarak, zorlu NLQ'lar için, her NLQ sorusu için özel istemler oluşturmak üzere benzer örnekleri dinamik olarak eklerken FM'nin yanıt doğruluğu yaklaşık %90'a ulaşır. Bu, çoklu çekim istemlerinin olmadığı senaryolarla karşılaştırıldığında %28'lik kayda değer bir artışı temsil ediyor.
Kullanım örneği 2: Tasarım ayrıntıları
Streamlit uygulamasının Yakalanan Görüntü Özeti sekmesinde doğrudan bir görüntü dosyası yükleyebilirsiniz. Bu, Amazon Rekognition API'sini başlatır (tespit_metni API), makine özelliklerini ayrıntılı olarak gösteren resim etiketinden metin ayıklanıyor. Daha sonra çıkarılan metin verileri, bir istemin bağlamı olarak Amazon Bedrock Claude modeline gönderilir ve sonuçta 200 kelimelik bir özet elde edilir.
Kullanıcı deneyimi açısından bakıldığında, bir metin özetleme görevi için akış işlevinin etkinleştirilmesi çok önemlidir; bu, kullanıcıların çıktının tamamını beklemek yerine FM tarafından oluşturulan özeti daha küçük parçalar halinde okumasına olanak tanır. Amazon Bedrock, API'si aracılığıyla akışı kolaylaştırır (bedrock_runtime.invoke_model_with_response_stream).
Kullanım örneği 3: Tasarım ayrıntıları
Bu senaryoda RAG yaklaşımını kullanarak kök neden analizine odaklanan bir chatbot uygulaması geliştirdik. Bu sohbet robotu, temel neden analizini kolaylaştırmak için rulman ekipmanıyla ilgili birden fazla belgeden yararlanıyor. Bu RAG tabanlı kök neden analizi sohbet robotu, vektör metin temsilleri veya yerleştirmeler oluşturmak için bilgi tabanlarını kullanır. Amazon Bedrock için Bilgi Tabanları, veri kaynaklarına özel entegrasyonlar oluşturmanıza veya veri akışlarını ve RAG uygulama ayrıntılarını yönetmenize gerek kalmadan, alımdan almaya ve istem artırmaya kadar tüm RAG iş akışını uygulamanıza yardımcı olan, tam olarak yönetilen bir yetenektir.
Amazon Bedrock'un bilgi tabanı yanıtından memnun kaldığınızda, temel neden yanıtını bilgi tabanından Streamlit uygulamasına entegre edebilirsiniz.
Temizlemek
Maliyetlerden tasarruf etmek için bu gönderide oluşturduğunuz kaynakları silin:
- Bilgi tabanını Amazon Bedrock'tan silin.
- OpenSearch Hizmeti dizinini silin.
- genai-sagemaker CloudFormation yığınını silin.
- Streamlit uygulamasını çalıştırmak için bir EC2 bulut sunucusu kullandıysanız EC2 bulut sunucusunu durdurun.
Sonuç
Üretken yapay zeka uygulamaları halihazırda çeşitli iş süreçlerini dönüştürerek çalışanların üretkenliğini ve becerilerini artırdı. Bununla birlikte, FM'lerin zaman serisi veri analizini işleme konusundaki sınırlamaları, bunların endüstriyel müşteriler tarafından tam olarak kullanılmasını engellemiştir. Bu kısıtlama, üretken yapay zekanın günlük olarak işlenen baskın veri türüne uygulanmasını engelledi.
Bu yazıda, endüstriyel kullanıcılar için bu zorluğu hafifletmek üzere tasarlanmış üretken bir Yapay Zeka Uygulama çözümünü tanıttık. Bu uygulama, FM'in zaman serisi analiz yeteneğini güçlendirmek için açık kaynaklı bir aracı olan PandasAI'yi kullanır. Uygulama, zaman serisi verilerini doğrudan FM'lere göndermek yerine, yapılandırılmamış zaman serisi verilerinin analizi için Python kodu oluşturmak üzere PandasAI'yi kullanıyor. Python kod oluşturma işleminin doğruluğunu artırmak için insan denetimiyle özel bir bilgi istemi oluşturma iş akışı uygulandı.
Varlık sağlığına ilişkin içgörülerle desteklenen endüstriyel çalışanlar, temel neden teşhisi ve parça değiştirme planlaması da dahil olmak üzere çeşitli kullanım senaryolarında üretken yapay zekanın potansiyelinden tam anlamıyla yararlanabilirler. Amazon Bedrock için Bilgi Tabanları ile RAG çözümünü geliştiricilerin oluşturması ve yönetmesi kolaydır.
Kurumsal veri yönetimi ve operasyonlarının gidişatı, operasyonel sağlıkla ilgili kapsamlı bilgiler için açıkça üretken yapay zeka ile daha derin entegrasyona doğru ilerliyor. Amazon Bedrock'un öncülük ettiği bu değişim, LLM'lerin artan sağlamlığı ve potansiyeli ile önemli ölçüde güçleniyor. Amazon Ana Kayası Claude 3 çözümleri daha da geliştirmek. Daha fazla bilgi edinmek için şu adresi ziyaret edin: Amazon Bedrock belgelerive uygulamalı olarak çalışın Amazon Ana Kayası atölyesi.
yazarlar hakkında
 Julia Hu Amazon Web Services'te Kıdemli AI/ML Çözüm Mimarıdır. Üretken Yapay Zeka, Uygulamalı Veri Bilimi ve Nesnelerin İnterneti mimarisi konularında uzmandır. Şu anda Amazon Q ekibinin bir parçası ve Makine Öğrenimi Teknik Alan Topluluğu'nun aktif bir üyesi/akıl hocası. AWSome üretken yapay zeka çözümleri geliştirmek için yeni kurulan şirketlerden şirketlere kadar geniş bir yelpazedeki müşterilerle çalışıyor. Gelişmiş veri analitiği için Büyük Dil Modellerinden yararlanma ve gerçek dünyadaki zorluklara yönelik pratik uygulamaları keşfetme konusunda özellikle tutkulu.
Julia Hu Amazon Web Services'te Kıdemli AI/ML Çözüm Mimarıdır. Üretken Yapay Zeka, Uygulamalı Veri Bilimi ve Nesnelerin İnterneti mimarisi konularında uzmandır. Şu anda Amazon Q ekibinin bir parçası ve Makine Öğrenimi Teknik Alan Topluluğu'nun aktif bir üyesi/akıl hocası. AWSome üretken yapay zeka çözümleri geliştirmek için yeni kurulan şirketlerden şirketlere kadar geniş bir yelpazedeki müşterilerle çalışıyor. Gelişmiş veri analitiği için Büyük Dil Modellerinden yararlanma ve gerçek dünyadaki zorluklara yönelik pratik uygulamaları keşfetme konusunda özellikle tutkulu.
 Sudeesh Sasidharan AWS'de Enerji ekibinde Kıdemli Çözüm Mimarıdır. Sudeesh, yeni teknolojileri denemeyi ve karmaşık iş zorluklarını çözen yenilikçi çözümler geliştirmeyi seviyor. Çözümler tasarlamadığı veya en son teknolojilerle uğraşmadığı zamanlarda, onu tenis kortunda backhand'i üzerinde çalışırken bulabilirsiniz.
Sudeesh Sasidharan AWS'de Enerji ekibinde Kıdemli Çözüm Mimarıdır. Sudeesh, yeni teknolojileri denemeyi ve karmaşık iş zorluklarını çözen yenilikçi çözümler geliştirmeyi seviyor. Çözümler tasarlamadığı veya en son teknolojilerle uğraşmadığı zamanlarda, onu tenis kortunda backhand'i üzerinde çalışırken bulabilirsiniz.
 Neil Desai yapay zeka (AI), veri bilimi, yazılım mühendisliği ve kurumsal mimari alanlarında 20 yılı aşkın deneyime sahip bir teknoloji yöneticisidir. AWS'de, müşterilerin yenilikçi Üretken AI destekli çözümler oluşturmasına, en iyi uygulamaları müşterilerle paylaşmasına ve ürün yol haritasını yönlendirmesine yardımcı olan, Dünya çapındaki AI hizmetleri uzman çözüm mimarlarından oluşan bir ekibe liderlik ediyor. Vestas, Honeywell ve Quest Diagnostics'teki önceki görevlerinde Neil, şirketlerin operasyonlarını iyileştirmesine, maliyetleri azaltmasına ve gelirini artırmasına yardımcı olan yenilikçi ürün ve hizmetlerin geliştirilmesinde ve piyasaya sürülmesinde liderlik rollerinde bulundu. Gerçek dünyadaki sorunları çözmek için teknolojiyi kullanma konusunda tutkuludur ve kanıtlanmış başarı geçmişine sahip bir stratejik düşünürdür.
Neil Desai yapay zeka (AI), veri bilimi, yazılım mühendisliği ve kurumsal mimari alanlarında 20 yılı aşkın deneyime sahip bir teknoloji yöneticisidir. AWS'de, müşterilerin yenilikçi Üretken AI destekli çözümler oluşturmasına, en iyi uygulamaları müşterilerle paylaşmasına ve ürün yol haritasını yönlendirmesine yardımcı olan, Dünya çapındaki AI hizmetleri uzman çözüm mimarlarından oluşan bir ekibe liderlik ediyor. Vestas, Honeywell ve Quest Diagnostics'teki önceki görevlerinde Neil, şirketlerin operasyonlarını iyileştirmesine, maliyetleri azaltmasına ve gelirini artırmasına yardımcı olan yenilikçi ürün ve hizmetlerin geliştirilmesinde ve piyasaya sürülmesinde liderlik rollerinde bulundu. Gerçek dünyadaki sorunları çözmek için teknolojiyi kullanma konusunda tutkuludur ve kanıtlanmış başarı geçmişine sahip bir stratejik düşünürdür.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

