Giriş
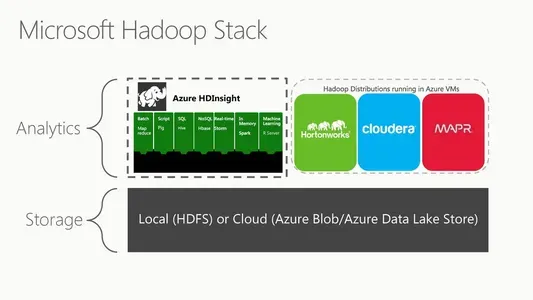
Microsoft Azure HDInsight(veya Microsoft HDFS) bulut tabanlı bir Hadoop Dağıtılmış Dosya Sistemi sürümüdür. Dağıtılmış bir dosya sistemi, emtia donanımı üzerinde çalışır ve büyük veri koleksiyonlarını yönetir. Muazzam hacimlerde verileri analiz etmek ve işlemek için tamamen yönetilen bulut tabanlı bir ortamdır. HDInsight, MapReduce, Hive, Pig ve Spark gibi teknolojileri içeren Hadoop ekosistemiyle sorunsuz bir şekilde çalışır. Ayrıca Microsoft'un Azure Data Lake Storage ve Azure Blob Storage gibi güçlü veri işleme teknolojileriyle de uyumludur.
Ölçeklenebilirlik, HDInsight'ın en temel özelliklerinden biridir. Microsoft Azure HDInsight ayrıca rol tabanlı erişim denetimi, şifreleme ve ağ yalıtımı gibi kurumsal düzeyde güvenlik özelliklerine sahiptir. HDInsight, Microsoft'un Power BI, Azure Stream Analytics ve Azure Data Factory gibi diğer bulut hizmetleriyle kolayca bütünleşir. Son olarak, tamamen yönetilen bulut tabanlı bir hizmettir; bu, Microsoft'un temel altyapı, bakım ve yükseltmelerden sorumlu olduğu anlamına gelir.
Öğrenme hedefleri
- Microsoft HDFS'yi ve önemli bir veri bağlamında nasıl çalıştığını inceleyeceğiz.
- Muazzam miktarda veriyi işlemek ve analiz etmek için bulutta Azure HDInsight'ı nasıl kullanacağınızı anlama
- MapReduce, Hive ve Spark gibi Hadoop araçlarını ve bunların HDInsight ile nasıl kullanılabileceğini inceleyeceğiz.
- HDInsight'ta farklı düğümlerin işlevleri hakkında da bilgi edineceksiniz.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Azure'ın HDInsight'ı, Apache Hadoop ve Apache Spark gibi önemli veri işleme teknolojilerini çalıştıran, tümüyle yönetilen bir bulut çözümüdür. Dağıtılmış bir sistemde büyük veri işleme ve analiz için bulut tabanlı bir Hadoop uygulamasıdır. Hadoop, muazzam veri kümelerini bilgi işlem düğümleri arasında paylaşmak için ücretsiz olarak kullanılabilen bir yazılım çerçevesidir. Genel Hadoop altyapısında çok önemli bir rol oynar. Uygulama verilerini çeşitli konumlardaki ucuz emtia sunucularında depolayarak yüksek hızlarda erişilebilir kılan dağıtılmış bir dosya sistemidir. HDFS'nin ana/bağımlı mimarisi, en büyük veri kümelerinin bile herhangi bir bütünlük veya performans kaybı olmadan saklanabilmesini ve yönetilebilmesini sağlar.
HDInsight'ın dağıtılmış dosya sistemi HDFS'dir. Kullanıcılar görevleri HDInsight'a gönderdiğinde, veriler küme düğümleri arasında otomatik olarak dağıtılır ve HDFS'ye kaydedilir. HDInsight, verileri HDFS'de işlemek ve analiz etmek için MapReduce, Hive, Pig ve Spark gibi diğer Hadoop ekosistem bileşenlerini de içerir. HDInsight, müşterilerin altyapı yönetimi gerektirmeden Hadoop ve ekosistem ürünlerinin yeteneklerinden yararlanmasını sağlayan bulut tabanlı bir platformdur. Dağıtılmış veri depolamayı ve işlemeyi kolaylaştırmak için dosya sistemi olarak HDFS'yi kullanır.

Kaynak: hkrtrainings.com
S2. Microsoft Azure Data Lake Storage 2. Nesil HDFS ile Nasıl Çalışır?
Microsoft Azure Veri Gölü Depolama Gen2, büyük hacimli verileri depolamak ve analiz etmek için hiyerarşik bir dosya sistemine sahip bulut tabanlı bir depolama çözümüdür. Hadoop ve Spark gibi büyük veri işleme platformlarıyla etkileşime girmesi ve HDFS ile sorunsuz arabirim oluşturması amaçlanmıştır. Azure Data Lake Storage 2. Hadoop Uyumlu Dosya Sistemi (HCFS) arabirimi içerir ve Hadoop ve diğer büyük veri işleme araçlarının Data Lake Storage 2. Müşteriler, mevcut Hadoop araçlarını ve uygulamalarını kullanarak Data Lake Storage Gen2'de depolanan verileri işleyebilir ve analiz edebilir.
Hadoop işleri HDInsight'ta yürütüldüğünde, veriler kümedeki düğümler arasında otomatik olarak dağıtılır ve HDFS'de depolanır. Ancak Azure Data Lake Storage 2., verileri bir HDInsight koleksiyonu oluşturmadan doğrudan depolama hesabında depolayabilir. Bu verilere daha sonra HDFS ile aynı işlevselliği sağlayan HCFS arayüzü kullanılarak erişilebilir. Azure Data Lake Storage 2. ayrıca Azure Blob Storage tümleştirmesi, Azure Active Directory tümleştirmesi gibi gelişmiş özellikler ve rol tabanlı erişim denetimi ve şifreleme gibi kurumsal düzeyde güvenlik özellikleri sunar. Genel olarak, Data Lake Storage Gen2, büyük veri işleme ve analizi için ölçeklenebilir ve güvenli bir depolama çözümü sağlar ve Hadoop ve HDFS ile sorunsuz bir şekilde entegre olur.
S3. HDFS'de NameNode ve DataNode'un Rolünü Açıklayabilir misiniz?
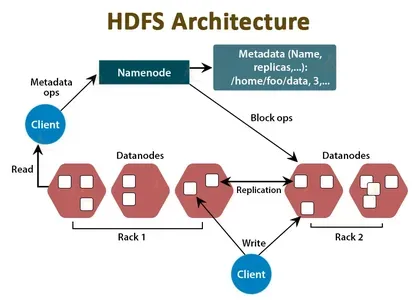
HDFS'nin NameNode ve DataNode bileşenleri, büyük veri kümeleri için dağıtılmış bir depolama ve işleme ortamı oluşturur. İşte nasıl çalışırlar:
- AdDüğümü: NameNode, HDFS kümesinin merkezi koordinatörü ve meta veri deposu olarak hizmet verir. Dosya konumları, hiyerarşi ve dosya ve dizin özellikleri hakkında bilgi tutar. NameNode bu bilgileri bellekte ve diskte depolar ve HDFS verilerine erişimi yönetmekten sorumludur. Bir istemci uygulamasının HDFS'den veri okuması veya yazması gerektiğinde, verilerin konumunu ve diğer bilgileri almak için önce NameNode ile iletişim kurar.
- Veri Düğümü: DataNode, HDFS'nin işgücüdür. Dosyaları oluşturan veri bloklarının HDFS'de depolanmasından sorumludur. Her DataNode, HDFS kümesindeki verilerin bir alt kümesi için depolamayı yönetir ve artıklık ve hata toleransı için verileri diğer DataNode'lara çoğaltır. Bir istemci uygulamasının veri okuması veya yazması gerektiğinde, doğrudan veri bloklarını tutan veri düğümleriyle konuşur.
Özetle, NameNode ve DataNode, büyük veri kümelerini depolayabilen ve işleyebilen dağıtılmış bir dosya sistemi oluşturmak için işbirliği yapar. NameNode dosya bilgilerini işlerken, DataNodes gerçek veri bloklarını içerir. Veri fazlalığı, hata toleransı ve hızlı veri alımı sağlamak için NameNode ve DataNode'lar birbirleriyle etkileşime girer.
S4. HDFS, veri güvenilirliğini ve hata toleransını nasıl sağlar?
Büyük veri kümeleri için hataya dayanıklı depolama sunmayı amaçlamaktadır. Bunu, verileri birkaç küme düğümü üzerinde çoğaltarak, hataları tespit edip düzelterek ve veri depolama güvenilirliğini ve doğruluğunu koruyarak yapar. HDFS, aşağıdaki şekillerde veri güvenilirliğini ve hata toleransını sağlar:
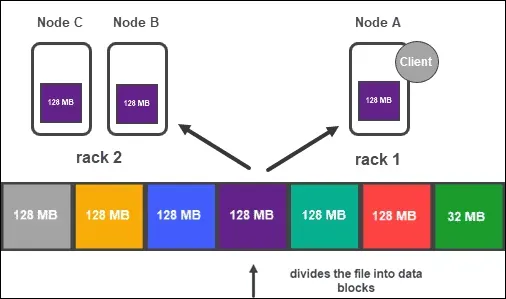
- Verileri, kümedeki birkaç veri düğümünde çoğaltılan bloklarda depolar. Her blok, varsayılan olarak üç kez çoğaltılır, ancak bu, uygulamanın ihtiyaçlarına göre değiştirilebilir. Birkaç düğüm üzerinden veri çoğaltma, bir veya daha fazla hata olsa bile verilerin diğer düğümlerde kullanılabilir olmasını garanti eder.
- Arıza tespiti ve kurtarma: HDFS, kümenin veri düğümlerinin durumunu sürekli olarak kontrol eder. Bir DataNode başarısız olduğunda veya yanıt vermediğinde, NameNode hatayı fark eder ve başarısız olan düğümün verilerini kümedeki diğer düğümlere kopyalar. Ardından NameNode, çoğaltılan veri bloklarının yeni konumlarını yansıtmak için meta verileri günceller.
- Veri tutarlılığı: Bir kez yaz çok kez oku (WORM) mimarisi kullanan HDFS, verilerin güvenilir ve hassas bir şekilde kaydedilmesini sağlar. HDFS'ye yazılan veriler değiştirilemez. Bu, çok sayıda istemci aynı verilere aynı anda eriştiğinde bile veri tutarlılığının korunmasını garanti eder.
- Blok yerleşimi: Veri bloklarının kümedeki farklı raflara yerleştirilmesini garanti etmek için HDFS, rafa duyarlı bir yerleştirme stratejisi kullanır. Bu, çerçevenin tamamı arızalansa bile, kümenin diğer raflarında verilere hala erişilebilir olmasını sağlar.
Genel olarak, birkaç düğüm üzerinde verileri çoğaltarak, arızaları tespit edip bunlardan kurtararak, veri tutarlılığını garanti ederek ve raf arızalarından kaynaklanan veri kaybını azaltmak için rafa duyarlı bir yerleştirme politikası uygulayarak HDFS, büyük veri kümeleri için güvenilir ve hataya dayanıklı bir depolama çözümü sağlar.
S5. HDFS'de NameNode ve DataNode Rollerinin Ne Olduğunu Açıklayabilir misiniz?
HDFS, bir kümede emtia donanımı üzerindeki büyük veri kümelerini depolayan ve yöneten dağıtılmış bir dosya sistemidir. Önceki soruda açıklandığı gibi, HDFS mimarisi iki temel bileşenden oluşur: NameNode ve DataNode. Veri güvenilirliği ve hata toleransı sağlamak için NameNode ve DataNode etkileşimde bulunur. Bir istemcinin HDFS'den veri okuması veya yazması gerektiğinde, veri bloklarını bulmak için NameNode ile konuşur. İstemci daha sonra veri bloklarını okumak veya yazmak için doğrudan DataNodes ile görüşür.
Dağıtılmış bir veri işleme çerçevesi olan MapReduce, sıklıkla HDFS ile birleştirilir. MapReduce, büyük veri kümelerini daha küçük parçalara bölerek, bu parçaların işlenmesini bir işlemci kümesine yayarak ve sonuçları toplayarak işlemek için tasarlanmıştır. MapReduce, HDFS ile şu şekilde etkileşime girer:
- Giriş verileri HDFS'ye kaydedilir. MapReduce, HDFS'den girdi verilerini alır ve onu girdi bölmeleri adı verilen daha küçük parçalara böler.
- Giriş bölmeleri, küme genelinde dağıtılır ve MapReduce kullanılarak belirli Harita işlerine atanır. Her Harita işi, tek bir giriş ayrımını işler ve ara anahtar/değer çiftleri üretir.
- Ardından, ara anahtar/değer çiftleri, Azalt işlerine gönderilmeden önce sıralanır ve karıştırılır. Her bir Azaltma işi, ara girdileri toplar ve nihai sonucu oluşturur.
- Nihai sonuç HDFS'ye kaydedilir.
Genel olarak, HDFS ve MapReduce, büyük veri kümesi işleme için ölçeklenebilir, hataya dayanıklı bir mimari oluşturmak üzere işbirliği yapar. Girdi ve çıktı verileri için güvenilir depolama sunarken, MapReduce veri işlemeyi küme boyunca yayar.
S6.HDFS'yi diğer dosya sistemlerinden farklı kılan nedir ve HDFS'yi büyük bir veri ortamında kullanmanın faydaları nelerdir?
HDFS, çok sayıda önemli alanda standart dosya sistemlerinden farklılık gösterir ve bu ayrımlar, büyük miktarda veriyle çalışırken çeşitli avantajlar sağlar. Bunlar, büyük bir veri ortamında HDFS kullanmanın bazı önemli farklılıkları ve avantajlarıdır:
- Ölçeklenebilirlik: Geleneksel dosya sistemleri, büyük veri durumlarında sık görülen çok büyük miktardaki verileri yönetmek için tasarlanmamıştır. Yatay olarak büyümek üzere tasarlanmıştır; bu, verileri bir ticari donanım kümesi üzerinden dağıtarak petabaytlarca, hatta eksabaytlarca veri depolama ve işlemeyi barındırabileceği anlamına gelir.
- Hata toleransı: Hataya dayanıklı olacak şekilde üretilmiştir. Verileri kümedeki birkaç düğümde çoğaltarak kümedeki tek tek düğümlerin başarısızlığına dayanabilir. Ayrıca, düğüm hatalarını otomatik olarak algılamak ve bunlardan kurtulmak için tekniklere de sahiptir.
- Hem okuma hem de veri yazma için yüksek bir verime sahip olması amaçlanmıştır. HDFS, büyük dosyalarla çalışırken, büyük veri aktarımları için özel olduğundan hızlı okuma ve yazma hızlarına ulaşabilir.
- Veri konumu: Veri yerelliğini en üst düzeye çıkarmak için tasarlanmıştır; bu, verilerin mümkün olan her yerde aynı küme düğümlerinde saklanması ve işlenmesi anlamına gelir. Ağ üzerinden veri geçişini azaltmak, ağ trafiğini en aza indirir ve performansı artırır.
- Maliyet etkinliği: Ticari donanım üzerinde çalışacak şekilde tasarlandığından, düşük maliyetli sunucularda veya bulutta uygulanabilir. Sonuç olarak, büyük hacimli verileri depolamak ve işlemek için düşük maliyetli bir seçenek sunar.
Genel olarak, bir büyük veri bağlamında HDFS kullanmanın faydaları ölçeklenebilirlik, hata toleransı, yüksek verim, veri yerelleştirme ve maliyet etkinliğidir. Kuruluşlar, bu özelliklerden yararlanarak, büyük veri kümelerini geleneksel dosya sistemlerinden daha verimli ve uygun maliyetli bir şekilde depolayabilir, yönetebilir ve analiz edebilir.
Sonuç
Bu yazıda, Microsoft HDFS'nin tanıtımı, mimarisi, Azure Data Lake Storage 2. ile çalışması ve MapReduce'daki işlevi dahil olmak üzere farklı özelliklerini inceledik. Ayrıca hem Amazon hem de Microsoft kurulumlarında ortak görüşme sorularını inceledik. Büyük veri kümeleri için ölçeklenebilir ve hataya dayanıklı depolama sağladığı için büyük veri uygulamaları için önemlidir. Tasarım ve operasyonu anlamak, büyük veri çözümleriyle çalışan veri mühendisleri ve geliştiriciler için çok önemlidir.
İşte bazı önemli paket servis noktaları:
- Bir kümede emtia donanımı üzerindeki devasa veri kümelerini depolayan ve yöneten dağıtılmış bir dosya sistemidir.
- NameNode ve DataNode, HDFS'nin iki temel bileşenidir. NameNode, dosya sisteminin bilgilerini tutarken DataNode, dosyaları oluşturan gerçek veri bloklarını depolar.
- Son derece hataya dayanıklı olacak ve büyük veri uygulamaları için güvenilir depolama sağlayacak şekilde üretilmiştir. Verileri bir ticari bilgisayar kümesine yayarak petabaytlarca, hatta eksabaytlarca veri depolama ve işlemeyi barındırabilir.
- Dağıtılmış bir veri işleme çerçevesi olan MapReduce, HDFS ile birlikte kullanılabilir. MapReduce, büyük veri kümelerini daha küçük bitlere böler ve bunların işlenmesini bir işlemci kümesine dağıtır.
- Son olarak Microsoft, HDFS, MapReduce ve diğer bileşenleri içeren bulut tabanlı bir Hadoop dağıtımı olan HDInsight'ı sağlar.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/03/top-6-microsoft-hdfs-interview-questions/

