2006 yılındaki lansmanından bu yana, Amazon Basit Depolama Hizmeti (Amazon S3), web siteleri barındırma, veri gölleri oluşturma, tüketici uygulamaları için nesne depolama hizmeti verme, günlükleri depolama ve verileri arşivleme gibi birden çok kullanım durumunu destekleyerek büyük bir büyüme kaydetti. Uygulama portföyü büyüdükçe, müşteriler birden çok uygulamadan ve farklı iş işlevlerinden gelen verileri tek bir S3 klasöründe depolama eğilimindedir; bu da S3 klasörlerindeki depolamayı yüzlerce TB'a çıkarabilir. bu AWS Faturalandırması konsol, Amazon S3'te depolanan verilerin toplam depolama maliyetine bakmanın bir yolunu sunar, ancak bazen BT kuruluşlarının belirli bir S3 klasörünün maliyetlerinin, belirli bir kullanıcı veya uygulamaya karşılık gelen çeşitli öneklere veya nesnelere göre dökümünü anlaması gerekir. Harcama dökümünü belirlemek, dahili ters ibrazlar yapmak, iş birimine ve uygulamaya göre maliyet dökümünü anlamak ve daha pek çok şey gibi S3 gruplarının maliyetlerini analiz etmek için çeşitli nedenler vardır. Bu yazı itibariyle, nesnelere ve öneklere göre S3 gruplarının maliyet dökümünü yapmanın kolay bir yolu yoktur.
Bu yazıda, kullanarak bir çözümü tartışıyoruz Amazon Atina sorgulamak AWS Maliyet ve Kullanım Raporları ve Amazon S3 Envanteri maliyeti bir S3 kovasındaki öneklere ve nesnelere göre analiz etmek için raporlar.
Çözüme genel bakış
Aşağıdaki şekilde bu çözümün mimarisi gösterilmektedir. İlk olarak, çıktıyı önceden oluşturulmuş iki ayrı S3 klasörüne kaydeden AWS Maliyet ve Kullanım Raporlarını (AWS CUR) ve Amazon S3 Envanteri özelliklerini etkinleştiriyoruz. Daha sonra AWS CUR verileri için bu S3 klasörlerini ve nesne veya önek düzeyinde maliyet dökümünü ilişkilendirmek ve tahsis etmek için S3 nesne envanteri verilerini sorgulamak üzere Athena'yı kullanırız.
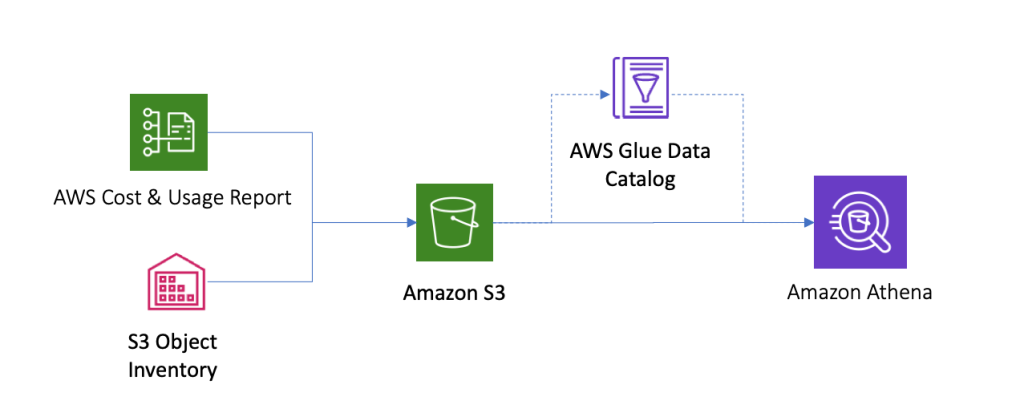
Çözümü uygulamak için aşağıdaki adımları tamamlıyoruz:
- AWS CUR, S3 nesne envanteri ve Athena sonuçları için S3 klasörleri oluşturun. Alternatif olarak, ilgili bireysel özellikleri etkinleştirirken bu ilgili grupları oluşturabilirsiniz, ancak bu yazının amacı doğrultusunda, hepsini başlangıçta oluşturuyoruz.
- Maliyet ve Kullanım Raporlarını etkinleştirin.
- Amazon S3 Inventory yapılandırmasını etkinleştirin.
- oluşturmak AWS Tutkal Athena kullanarak sorgulamak için CUR ve S3 nesne envanteri için Veri Kataloğu tabloları.
- Athena'da sorguları çalıştırın.
Önkoşullar
Bu izlenecek yol için aşağıdaki ön koşullara sahip olmalısınız:
S3 klasörleri oluşturun
Amazon S3, sektör lideri ölçeklenebilirlik, veri kullanılabilirliği, güvenlik ve performans sunan bir nesne depolama hizmetidir. Her ölçekten ve sektörden müşteri, veri gölleri, bulut tabanlı uygulamalar ve mobil uygulamalar gibi neredeyse her kullanım durumu için her miktarda veriyi depolayabilir ve koruyabilir. Uygun maliyetli depolama sınıfları ve kullanımı kolay yönetim özellikleriyle maliyetleri optimize edebilir, verileri düzenleyebilir ve belirli iş, organizasyon ve uyumluluk gereksinimlerini karşılamak için ince ayarlanmış erişim denetimlerini yapılandırabilirsiniz.
Bu gönderi için, maliyet tahsisi için birincil grup olarak S3 kovası s3-nesne-maliyet tahsisini kullanıyoruz. Bu S3 grubu, paketin toplam maliyetine dayalı olarak maliyet tahsisinin yapılması gereken farklı boyutlarda birkaç önek ve nesne içerecek şekilde uygun bir şekilde modellenmiştir. Gerçek dünya senaryosunda, birden çok ekip için veri içeren ve maliyetleri önek veya nesneye göre ayırmanız gereken bir grup kullanmalısınız. Bundan sonra, bu kovayı birincil nesne grubu olarak adlandıracağız.
Aşağıdaki ekran görüntüsü, S3 grubumuzu ve klasörlerimizi göstermektedir.
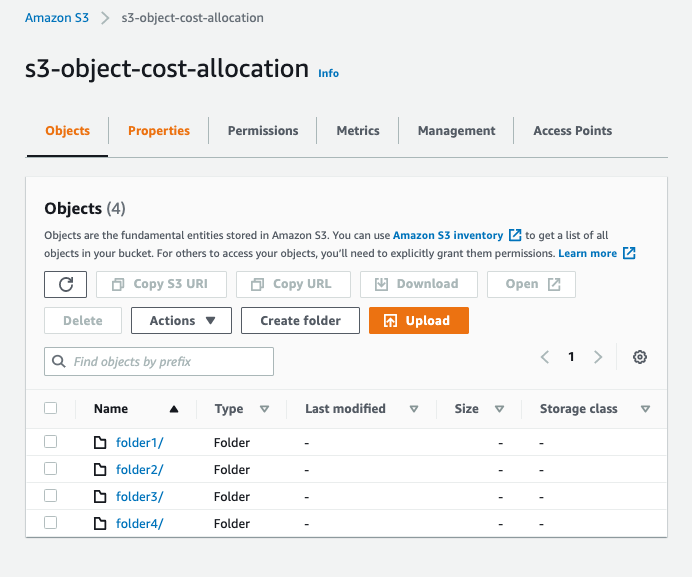
Şimdi nesnelerin maliyetlerini hesaplamak için oluşturulan veri kümelerini depolamak üzere üç ek operasyonel S3 klasörünü oluşturalım. Gerektiğinde aşağıdaki grupları veya mevcut grupları oluşturabilirsiniz:
cur-cost-usage-reports-<account_number>– Bu kova, hesabın Maliyet ve Kullanım Raporlarını kaydetmek için kullanılır.S3-inventory-configurations-<account_number>– Bu grup, birincil nesne grubumuzun envanter yapılandırmalarını kaydetmek için kullanılır.athena-query-bucket-<account_number>– Bu kova, Athena'dan gelen sorgu sonuçlarını kaydetmek için kullanılır.
S3 gruplarınızı oluşturmak için aşağıdaki adımları tamamlayın:
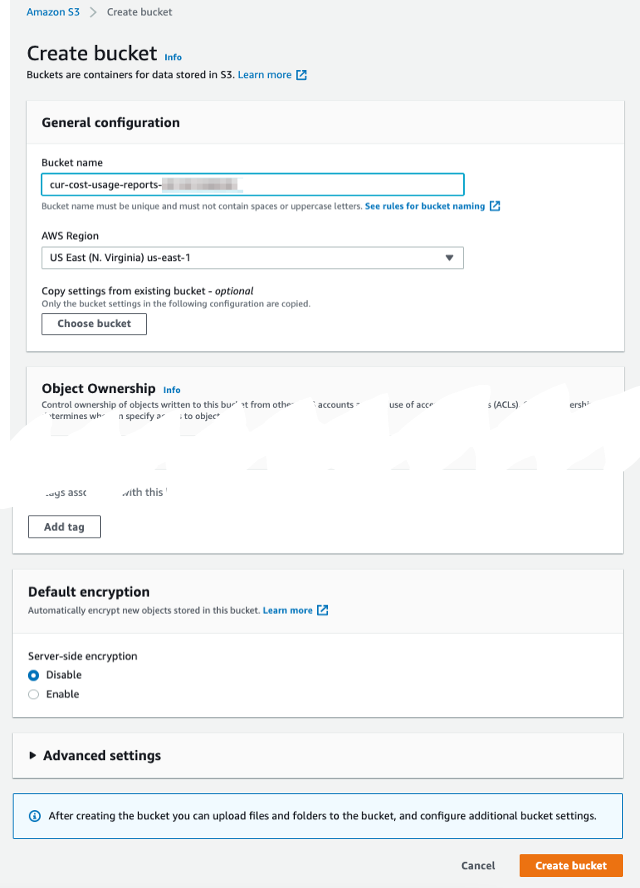
- Amazon S3 konsolunda şunu seçin: Kepçeler Gezinti bölmesinde.
- Klinik Grup oluştur.
- İçin Bölüm adı, paketinizin adını girin (
cur-cost-usage-reports-<account_number>). - İçin AWS Bölgesi, tercih ettiğiniz Bölgeyi seçin.
- Diğer tüm ayarları varsayılan olarak (veya kuruluşunuzun standartlarına göre) bırakın.
- Klinik Grup oluştur.
- oluşturmak için bu adımları tekrarlayın.
s3-inventory-configurations-<account_number>veathena-query-bucket-<account_number>.
Maliyet ve Kullanım Raporlarını Etkinleştirin
AWS Maliyet ve Kullanım Raporları (AWS CUR), mevcut olan en kapsamlı maliyet ve kullanım verilerini içerir. AWS faturalandırma raporlarınızı sahip olduğunuz bir S3 klasörüne yayınlamak için Maliyet ve Kullanım Raporlarını kullanabilirsiniz. Maliyetlerinizi saate, güne veya aya göre kıran raporlar alabilirsiniz; ürün veya ürün kaynağına göre; veya kendi tanımladığınız etiketlerle.
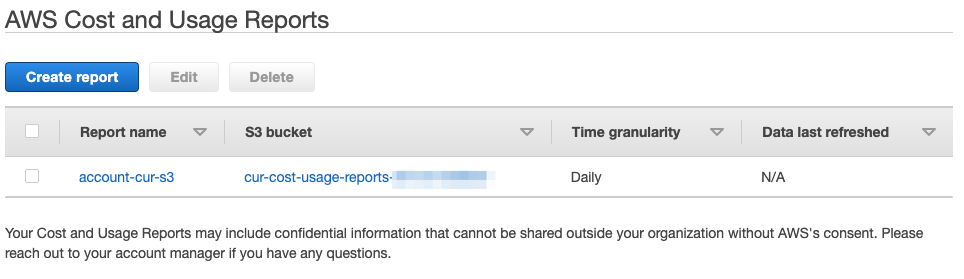
Hesabınız için Maliyet ve Kullanım Raporlarını etkinleştirmek üzere aşağıdaki adımları tamamlayın:
- AWS Faturalandırma konsolundaki gezinti bölmesinde Maliyet ve Kullanım Raporları.
- Klinik Rapor oluştur.
- İçin Rapor Adı, raporunuz için bir ad girin, örneğin
account-cur-s3. - İçin Ek rapor ayrıntılarıseçin Kaynak kimliklerini dahil et rapora her bir kaynağın kimliklerini dahil etmek için.Kaynak kimliklerinin dahil edilmesi, kaynaklarınızın her biri için ayrı satır öğeleri oluşturur. Bu, Maliyet ve Kullanım Raporları dosyalarınızın boyutunu önemli ölçüde artırabilir ve bu da AWS kullanımınıza bağlı olarak CUR'nuz için S3 depolama maliyetlerini etkileyebilir. Bu gönderi için bu özelliğin etkinleştirilmesine ihtiyacımız var.
- İçin Veri yenileme ayarları, faturanızı tamamladıktan sonra AWS hesabınıza geri ödemeler, krediler veya destek ücretleri uygularsa Maliyet ve Kullanım Raporlarının yenilenmesini isteyip istemediğinizi seçin. Bir rapor yenilendiğinde Amazon S3'e yeni bir rapor yüklenir.
- Klinik Sonraki.
- İçin S3 kepçe, seçmek yapılandırma.
- İçin S3 Kovasını Yapılandır, önceki bölümde oluşturulmuş mevcut bir grubu seçin (
cur-cost-usage-reports-<account_number>) ve Seç Sonraki. - Paket politikasını inceleyin, seçin Bu politikanın doğru olduğunu onayladım, ve Seç İndirim. Bu varsayılan klasör ilkesi, Amazon S3'e veri yazmak için Maliyet ve Kullanım Raporlarına erişim sağlar.
- İçin Rapor yolu öneki, girmek
cur-data/account-cur-daily. - İçin Zaman ayrıntı düzeyi, seçmek Günlük.
- İçin Rapor sürümü, seçmek Mevcut raporun üzerine yaz.
- İçin Şunun için rapor veri entegrasyonunu etkinleştir:seçin Amazon Atina.
- Klinik Sonraki.
- Raporunuz için ayarları gözden geçirdikten sonra, İncele ve Tamamla.
Maliyet ve Kullanım raporları, 3 saat içinde S24 klasörlerine iletilecektir.
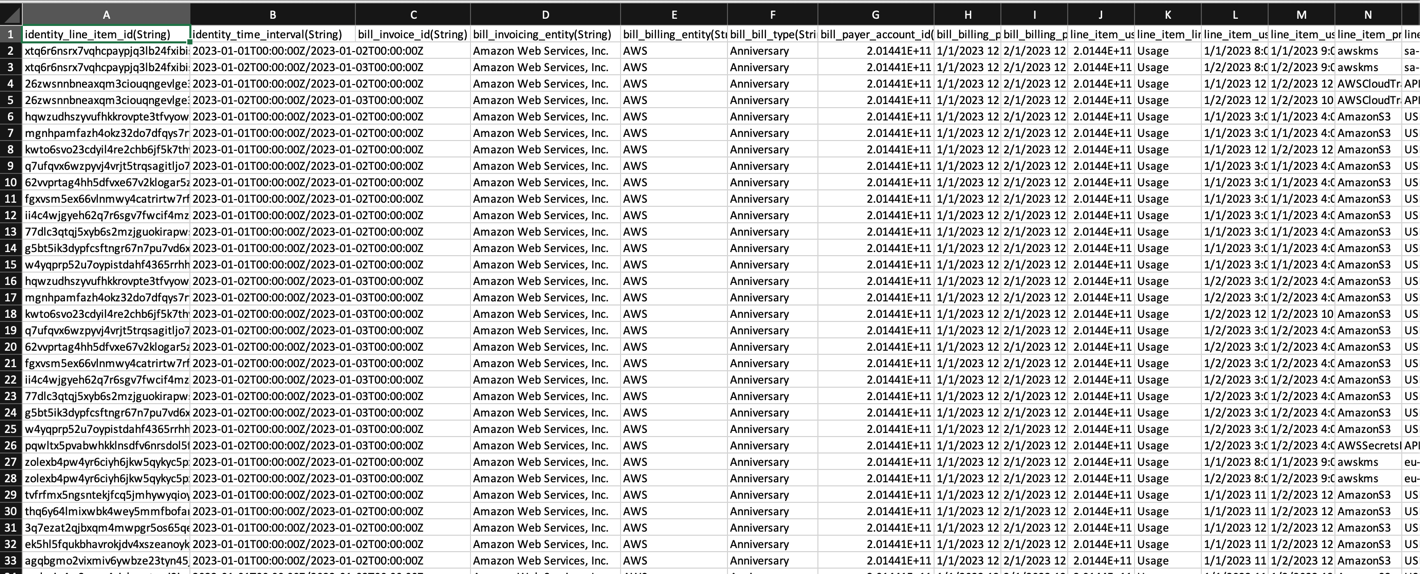
Aşağıdaki CSV biçimindeki örnek CUR, Maliyet ve Kullanım Raporunun farklı sütunlarını gösterir: bill_invoice_id, bill_invoicing_entity, bill_payer_account_id, ve line_item_product_code, Birkaç isim.
Amazon S3 Inventory yapılandırmasını etkinleştirin
Amazon S3 Envanteri, depolama alanınızı yönetmenize yardımcı olmak için Amazon S3'ün sağladığı araçlardan biridir. İş, uyumluluk ve düzenleyici ihtiyaçlar için nesnelerinizin çoğaltma ve şifreleme durumunu denetlemek ve raporlamak için kullanabilirsiniz. Amazon S3 Inventory, bir S3 klasörü veya paylaşılan önek (nesneler) için nesnelerinizi ve bunlara karşılık gelen meta verileri günlük veya haftalık olarak listeleyen virgülle ayrılmış değerler (CSV), Apache Optimize Edilmiş Satır Sütunu (ORC) veya Apache Parquet çıktı dosyaları sağlar. ortak bir dizeyle başlayan adlara sahip olmak).
Birincil nesne paketinde Amazon S3 Inventory'yi etkinleştirmek için aşağıdaki adımları tamamlayın:
- Amazon S3 konsolunda şunu seçin: Kepçeler Gezinti bölmesinde.
- Amazon S3 Envanterini yapılandırmak istediğiniz klasörü seçin.
Bu, hesabınızda analiz edilmesi gereken verileri içeren mevcut grup olacaktır. Bu, veri gölünüz veya uygulama S3 klasörünüz olabilir. kovayı oluşturduks3-object-cost-allocationbazı örnek veriler ve klasör yapısı ile. - Klinik Yönetim.
- Altında Envanter yapılandırmaları, seçmek Envanter yapılandırması oluştur.
- İçin Envanter yapılandırma adı, girmek
s3-object-cost-allocation. - İçin Envanter kapsamı, ayrılmak Önek boş.
Bu, tüm nesnelerin rapor için kapsanmasını sağlamak içindir. - İçin Nesne Sürümleriseçin Yalnızca geçerli sürüm.
- İçin Rapor ayrıntıları, seçmek Bu hesap.
- İçin Varış yeri, oluşturduğumuz hedef grubu seçin (
s3-inventory-configurations-<account_number>). - İçin Sıklık, seçmek Günlük.
- İçin Çıkış biçimiolarak seçin Apache Parke.
- İçin Durum, seçmek etkinleştirme.
- Sunucu tarafı şifrelemeyi devre dışı bırakın. Sunucu tarafı şifrelemeyi kullanmak için seçin etkinleştirme ve şifreleme anahtarını belirtin.
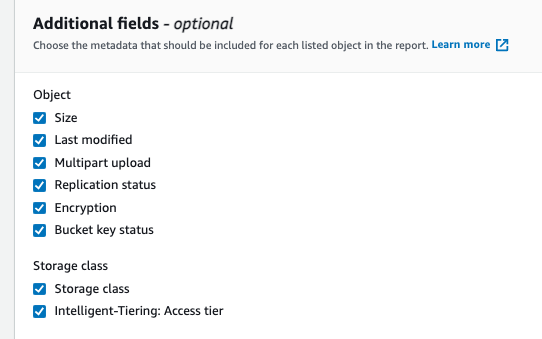
- İçin Ek alanlar, envanter raporuna eklemek için aşağıdakini seçin:
- beden – Bayt cinsinden nesne boyutu.
- Son değiştirilme tarihi – Nesne oluşturma tarihi veya son değiştirilme tarihi, hangisi en geçse.
- Çok parçalı yükleme – Nesnenin çok parçalı bir yükleme olarak yüklendiğini belirtir. Daha fazla bilgi için bakınız Çok parçalı yüklemeyi kullanarak nesneleri karşıya yükleme ve kopyalama.
- Çoğaltma durumu – Nesnenin çoğaltma durumu. Daha fazla bilgi için bakınız S3 konsolunu kullanma.
- Şifreleme durumu – Nesneyi şifrelemek için kullanılan sunucu tarafı şifreleme. Daha fazla bilgi için bakınız Sunucu tarafı şifreleme kullanarak verileri koruma.
- Paket anahtarı durumu – AWS KMS tarafından oluşturulan klasör düzeyinde bir anahtarın nesne için geçerli olup olmadığını gösterir.
- Depolama sınıfı – Nesneyi depolamak için kullanılan depolama sınıfı.
- Akıllı Katmanlama: Erişim katmanı – Intelligent-Tie'da saklanmışsa, nesnenin erişim katmanını gösterir
- Klinik oluşturmak.
Teslim edilmesi 48 saati bulabilir. ilk rapor.
CUR ve Amazon S3 Inventory raporları için AWS Glue Data Catalog tabloları oluşturun
Önceki adımın raporları oluşturması için 48 saate kadar bekleyin. Bu bölümde, Maliyet ve Kullanım Raporları ve Amazon S3 Envanter raporları kullanılarak oluşturulan veriler için AWS Glue Data Catalog tabloları oluşturmak ve tanımlamak için Athena'yı kullanıyoruz.
Athena, açık kaynak çerçeveler üzerine kurulu, açık tablo ve dosya biçimlerini destekleyen, sunucusuz, etkileşimli bir analitik hizmetidir. Athena, yaşadığı yerde petabaytlarca veriyi analiz etmek için basitleştirilmiş, esnek bir yol sağlar.
Athena'yı kullanarak tabloları oluşturmak için aşağıdaki adımları tamamlayın:
- Athena konsoluna gidin.
- Athena'yı ilk kez kullanıyorsanız Amazon S3'te bir sorgu sonucu konumu ayarlamanız gerekir. Bunu Athena'da önceden yapılandırdıysanız, bu adımı atlayabilirsiniz.
- Klinik Ayarları görüntüle.

- Klinik Yönet.
- Bölümde Sorgu sonucu konumu ve şifreleme, seçmek S3'e göz atın ve oluşturduğumuz grubu seçin (
athena-query-bucket-<account_number>). - Klinik İndirim.
- Athena sorgu düzenleyicisine geri dönün.
- Klinik Ayarları görüntüle.
- Athena'da aşağıdaki sorguyu çalıştırın. bir tablo oluştur Maliyet ve Kullanım Raporları için. için bölümü doğrulayın ve güncelleyin < > sorgunun sonunda ve doğru S3 klasörüne ve konumuna işaret edin. Yeni tablo adının olması gerektiğini unutmayın.
account_cur.CREATE EXTERNAL TABLE `account_cur`( `identity_line_item_id` string, `identity_time_interval` string, `bill_invoice_id` string, `bill_billing_entity` string, `bill_bill_type` string, `bill_payer_account_id` string, `bill_billing_period_start_date` timestamp, `bill_billing_period_end_date` timestamp, `line_item_usage_account_id` string, `line_item_line_item_type` string, `line_item_usage_start_date` timestamp, `line_item_usage_end_date` timestamp, `line_item_product_code` string, `line_item_usage_type` string, `line_item_operation` string, `line_item_availability_zone` string, `line_item_resource_id` string, `line_item_usage_amount` double, `line_item_normalization_factor` double, `line_item_normalized_usage_amount` double, `line_item_currency_code` string, `line_item_unblended_rate` string, `line_item_unblended_cost` double, `line_item_blended_rate` string, `line_item_blended_cost` double, `line_item_line_item_description` string, `line_item_tax_type` string, `line_item_legal_entity` string, `product_product_name` string, `product_availability` string, `product_description` string, `product_durability` string, `product_event_type` string, `product_fee_code` string, `product_fee_description` string, `product_free_query_types` string, `product_from_location` string, `product_from_location_type` string, `product_from_region_code` string, `product_group` string, `product_group_description` string, `product_location` string, `product_location_type` string, `product_message_delivery_frequency` string, `product_message_delivery_order` string, `product_operation` string, `product_platopricingtype` string, `product_product_family` string, `product_queue_type` string, `product_region` string, `product_region_code` string, `product_servicecode` string, `product_servicename` string, `product_sku` string, `product_storage_class` string, `product_storage_media` string, `product_to_location` string, `product_to_location_type` string, `product_to_region_code` string, `product_transfer_type` string, `product_usagetype` string, `product_version` string, `product_volume_type` string, `pricing_rate_code` string, `pricing_rate_id` string, `pricing_currency` string, `pricing_public_on_demand_cost` double, `pricing_public_on_demand_rate` string, `pricing_term` string, `pricing_unit` string, `reservation_amortized_upfront_cost_for_usage` double, `reservation_amortized_upfront_fee_for_billing_period` double, `reservation_effective_cost` double, `reservation_end_time` string, `reservation_modification_status` string, `reservation_normalized_units_per_reservation` string, `reservation_number_of_reservations` string, `reservation_recurring_fee_for_usage` double, `reservation_start_time` string, `reservation_subscription_id` string, `reservation_total_reserved_normalized_units` string, `reservation_total_reserved_units` string, `reservation_units_per_reservation` string, `reservation_unused_amortized_upfront_fee_for_billing_period` double, `reservation_unused_normalized_unit_quantity` double, `reservation_unused_quantity` double, `reservation_unused_recurring_fee` double, `reservation_upfront_value` double, `savings_plan_total_commitment_to_date` double, `savings_plan_savings_plan_a_r_n` string, `savings_plan_savings_plan_rate` double, `savings_plan_used_commitment` double, `savings_plan_savings_plan_effective_cost` double, `savings_plan_amortized_upfront_commitment_for_billing_period` double, `savings_plan_recurring_commitment_for_billing_period` double, `resource_tags_user_bucket_name` string, `resource_tags_user_cost_tracking` string) PARTITIONED BY ( `year` string, `month` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '<<LOCATION>>' - Amazon S3 Inventory tablosunu oluşturmak için Athena'da aşağıdaki sorguyu çalıştırın. için bölümü doğrulayın ve güncelleyin < > sorgunun sonunda ve doğru S3 klasörüne ve konumuna işaret edin.
- Konumun tam değerini almak için envanter yapılandırmalarının depolandığı klasöre gidin ve klasör yoluna gidin
Hive. Değiştirmek için S3 URI'sini kullanın < > sorguda.
CREATE EXTERNAL TABLE s3_object_inventory( bucket string, key string, version_id string, is_latest boolean, is_delete_marker boolean, size bigint, last_modified_date bigint, storage_class string, is_multipart_uploaded boolean, replication_status string, encryption_status string, intelligent_tiering_access_tier string, bucket_key_status string ) PARTITIONED BY ( dt string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat' LOCATION '<<LOCATION>>';
- Konumun tam değerini almak için envanter yapılandırmalarının depolandığı klasöre gidin ve klasör yoluna gidin
- Bölümleri yenilememiz ve tabloya yeni envanter listeleri eklememiz gerekiyor. CUR tablosuna ve Amazon S3 Inventory tablosuna veri eklemek için aşağıdaki komutları kullanın:
MSCK REPAIR TABLE `account_cur`; MSCK REPAIR TABLE s3_object_inventory;
Bir S3 klasöründeki nesnelerin maliyetini tahsis etmek için Athena'da sorgular çalıştırın
Artık önek düzeyinde bir maliyet tahsis dökümü elde etmek için elimizdeki verileri sorgulayabiliriz.
Aşağıdaki sorgularda bazı bilgiler vermemiz gerekiyor:
- Güncelleme < > Verileri analiz etmek istediğiniz tarih ile
- Güncelleme < > analiz edilmesi gereken grubunuz için önek değerleri ile
- Güncelleme < > analiz edilmesi gereken kovanın adıyla
Maliyetini hesaplamak istediğimiz hedef öneki tarafından kullanılan depolama boyutunu hesaplamak için sorgunun aşağıdaki bölümünü kullanırız:
select date_parse(dt,'%Y-%m-%d-%H-%i') dt, cast (sum(size) as double) targetPrefixBytes
from s3_object_inventory
where date_parse(dt,'%Y-%m-%d-%H-%i') = cast('<<YYYY-MM-DD>>' as timestamp)
and key like '<<prefix>>/%'
group by dtArdından, o tarihteki kovanın toplam boyutunu hesaplıyoruz:
select date_parse(dt,'%Y-%m-%d-%H-%i') dt, cast (sum(size) as double) totalBytes
from s3_object_inventory
where date_parse(dt,'%Y-%m-%d-%H-%i') = cast('<<YYYY-MM-DD>>' as timestamp)
group by dtBelirli bir tarihteki belirli bir bölümün maliyetini almak için CUR tablosunu sorgularız:
select line_item_usage_start_date as dt, sum(line_item_blended_cost) as line_item_blended_cost
from "account_cur"
where line_item_product_code = 'AmazonS3'
and product_servicecode = 'AmazonS3'
and line_item_operation = 'StandardStorage'
and line_item_resource_id = '<<bucket_name>>'
and line_item_usage_start_date = cast('<<YYYY-MM-DD>>' as timestamp)
group by line_item_usage_start_dateTüm bunları bir araya getirerek, belirli bir önekin (klasör veya dosya) belirli bir tarihteki maliyetini hesaplayabiliriz. Tam sorgu aşağıdaki gibidir:
with
cost as (select line_item_usage_start_date as dt, sum(line_item_blended_cost) as line_item_blended_cost
from "account_cur"
where line_item_product_code = 'AmazonS3'
and product_servicecode = 'AmazonS3'
and line_item_operation = 'StandardStorage'
and line_item_resource_id = '<<bucket_name>>'
and line_item_usage_start_date = cast('<<YYYY-MM-DD>>' as timestamp)
group by line_item_usage_start_date),
total as (select date_parse(dt,'%Y-%m-%d-%H-%i') dt, cast (sum(size) as double) totalBytes
from s3_object_inventory
where date_parse(dt,'%Y-%m-%d-%H-%i') = cast('<<YYYY-MM-DD>>' as timestamp)
group by dt),
target as (select date_parse(dt,'%Y-%m-%d-%H-%i') dt, cast (sum(size) as double) targetPrefixBytes
from s3_object_inventory
where date_parse(dt,'%Y-%m-%d-%H-%i') = cast('<<YYYY-MM-DD>>' as timestamp)
and key like '<<prefix>>/%'
group by dt)
select target.dt,
(target.targetPrefixBytes/ total.totalBytes * 100) percentUsed,
cost.line_item_blended_cost totalCost,
cost.line_item_blended_cost*(target.targetPrefixBytes/ total.totalBytes) as prefixCost
from target, total, cost
where target.dt = total.dt
and target.dt = cost.dtAşağıdaki ekran görüntüsü, bu gönderide kullandığımız örnek verilerin sonuç tablosunu göstermektedir. Aşağıdaki bilgileri alıyoruz:
- dt - Tarih
- yüzdeKullanılan – Genel kova alanına kıyasla önek alanının yüzdesi
- toplam tutar – Kovanın toplam maliyeti
- önekMaliyeti – Önek tarafından kullanılan alanın maliyeti

Temizlemek
Ortaya çıkan maliyetleri durdurmak için şunları yaptığınızdan emin olun: Amazon S3 Inventory'yi devre dışı bırakın ve Maliyet ve Kullanım Raporları işin bittiğinde
Depolama ücretlerinden kaçınmak için Amazon S3 Envanter raporları ile Maliyet ve Kullanım Raporları için oluşturulan S3 klasörlerini silin.
Amazon S3 depolama analizi için diğer yöntemler
Amazon S3 Depolama Lensi tüm Amazon S3 depolama alanınız genelinde nesne depolama kullanımı ve etkinliğine ilişkin tek bir görünüm sağlayabilir. S3 Storage Lens ile tüm kuruluşunuza, belirli hesaplara, Bölgelere, gruplara veya öneklere ilişkin verileri bir araya getirmek için 29'dan fazla kullanım ve etkinlik ölçümü ve etkileşimli panolarla depolamayı anlayabilir, analiz edebilir ve optimize edebilirsiniz. Tüm bu verilere Amazon S3 konsolundan veya bir S3 klasöründeki ham veriler olarak erişilebilir.
S3 Storage Lens, tek bir gruptaki bir nesneye veya ön eke dayalı maliyet analizi sağlamaz. Tüm depolama ayak izi genelinde depolama kullanımının ve eğilimlerin görünürlüğünün yanı sıra maliyet verimliliği ve veri koruma en iyi uygulamalarına ilişkin öneriler istiyorsanız, S3 Storage Lens doğru seçenektir. Ancak, belirli S3 gruplarının maliyet analizini yapmak istiyorsanız ve S3 nesnelerinin maliyet tahsisini nesne veya önek düzeyinde elde etmenin yollarını arıyorsanız, bu gönderideki çözüm en uygun çözüm olacaktır.
Sonuç
Bu gönderide, birden fazla iş birimi ve uygulama için veri içeren S3 klasörleri için nesne veya önek düzeyinde bir maliyet döküm modelinin nasıl oluşturulacağını ayrıntılarıyla anlattık. AWS CUR ve Amazon S3 Inventory özellikleri tarafından üretilen raporları ve veri kümelerini sorgulamak için Athena'yı kullandık; bunlar ilişkilendirildiğinde bize nesne ve önek düzeyinde maliyet tahsisi sağlar. Bu çözüm, dahili ters ibrazlar için veya yalnızca paylaşılan bir S3 klasöründeki nesne veya önek başına harcamayı bilmek için kullanılabilen bağımsız nesneler ve ön ekler için maliyetleri hesaplamanın kolay bir yolunu sunar.
Yazarlar Hakkında
 Dagar Katyal Chicago, Illinois merkezli AWS'de Kıdemli Çözüm Mimarıdır. Müşterilerle birlikte çalışır ve onların işi için önemli olan kilit stratejik girişimler için rehberlik sağlar. Dagar MBA derecesine sahiptir ve 15 yılı aşkın bir süredir müşterilerle analitik stratejisi, yol haritası ve verileri önemli bir farklılaştırıcı olarak kullanma projeleri üzerinde çalışmaktadır. Dagar, müşterilerle çalışmadığı zamanlarda ailesiyle vakit geçiriyor ve ev geliştirme projeleri yapıyor.
Dagar Katyal Chicago, Illinois merkezli AWS'de Kıdemli Çözüm Mimarıdır. Müşterilerle birlikte çalışır ve onların işi için önemli olan kilit stratejik girişimler için rehberlik sağlar. Dagar MBA derecesine sahiptir ve 15 yılı aşkın bir süredir müşterilerle analitik stratejisi, yol haritası ve verileri önemli bir farklılaştırıcı olarak kullanma projeleri üzerinde çalışmaktadır. Dagar, müşterilerle çalışmadığı zamanlarda ailesiyle vakit geçiriyor ve ev geliştirme projeleri yapıyor.
 Saiteja Pudi AWS'de Dallas, Tx merkezli bir Çözüm Mimarıdır. 3 yılı aşkın bir süredir AWS'de çalışıyor ve müşterilerin güvenilir danışmanları olarak AWS'nin gerçek potansiyelini elde etmelerine yardımcı oluyor. Veri Bilimi ve Makine Öğrenimi ile ilgilenen bir uygulama geliştirme geçmişinden geliyor.
Saiteja Pudi AWS'de Dallas, Tx merkezli bir Çözüm Mimarıdır. 3 yılı aşkın bir süredir AWS'de çalışıyor ve müşterilerin güvenilir danışmanları olarak AWS'nin gerçek potansiyelini elde etmelerine yardımcı oluyor. Veri Bilimi ve Makine Öğrenimi ile ilgilenen bir uygulama geliştirme geçmişinden geliyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/analyze-amazon-s3-storage-costs-using-aws-cost-and-usage-reports-amazon-s3-inventory-and-amazon-athena/

