Apache Flink uygulamalarını çalıştırırken Apache Flink için Amazon Yönetilen Hizmeti, sunucusuz yapısından yararlanmanın benzersiz avantajına sahip olursunuz. Bu, maliyet optimizasyon çalışmalarının her an yapılabileceği anlamına gelir; bunların artık planlama aşamasında olmasına gerek yoktur. Apache Flink için Yönetilen Hizmet ile tek bir düğmeyi tıklatarak bilgi işlem ekleyebilir ve kaldırabilirsiniz.
Apache Flink, kritik iş uygulamalarında yüzlerce şirket ve iş yükleri için akış işleme ihtiyaçları olan binlerce geliştirici tarafından kullanılan açık kaynaklı bir akış işleme çerçevesidir. Yüksek oranda kullanılabilir ve ölçeklenebilir olup, en zorlu akış işleme uygulamaları için yüksek verim ve düşük gecikme süresi sunar. Apache Flink'in bu ölçeklenebilir özellikleri, buluttaki maliyetinizi optimize etmenin anahtarı olabilir.
Apache Flink için Yönetilen Hizmet, Apache Flink uygulamalarını oluşturma ve yönetme karmaşıklığını azaltan, tam olarak yönetilen bir hizmettir. Apache Flink için Yönetilen Hizmet, dayanıklı uygulama durumu, ölçümler, günlükler ve daha fazlasını sağlayan temel altyapıyı ve Apache Flink bileşenlerini yönetir.
Bu yazıda Apache Flink için Yönetilen Hizmet maliyet modeli, Apache Flink uygulamalarınızda maliyetten tasarruf edebileceğiniz alanlar hakkında bilgi edinebilir ve genel olarak veri işleme işlem hatlarınızı daha iyi anlayabilirsiniz. Maliyetlerinizi anlamak, uygulamanızın aşırı tedarik edilip edilmediğini anlamak, otomatik olarak ölçeklendirme hakkında nasıl düşünmeniz gerektiğini ve maliyetten tasarruf etmek için Apache Flink uygulamalarınızı optimize etmenin yollarını derinlemesine inceliyoruz. Son olarak Apache Flink'in kullanım durumunuz için doğru teknoloji olup olmadığını belirlemek amacıyla iş yükünüz hakkında önemli sorular soruyoruz.
Apache Flink için Yönetilen Hizmette maliyetler nasıl hesaplanır?
Apache Flink için Yönetilen Hizmet uygulamanıza ilişkin maliyetleri optimize etmek amacıyla, yönetilen hizmetin fiyatlandırmasına nelerin dahil olduğu konusunda iyi bir fikre sahip olmak yardımcı olabilir.
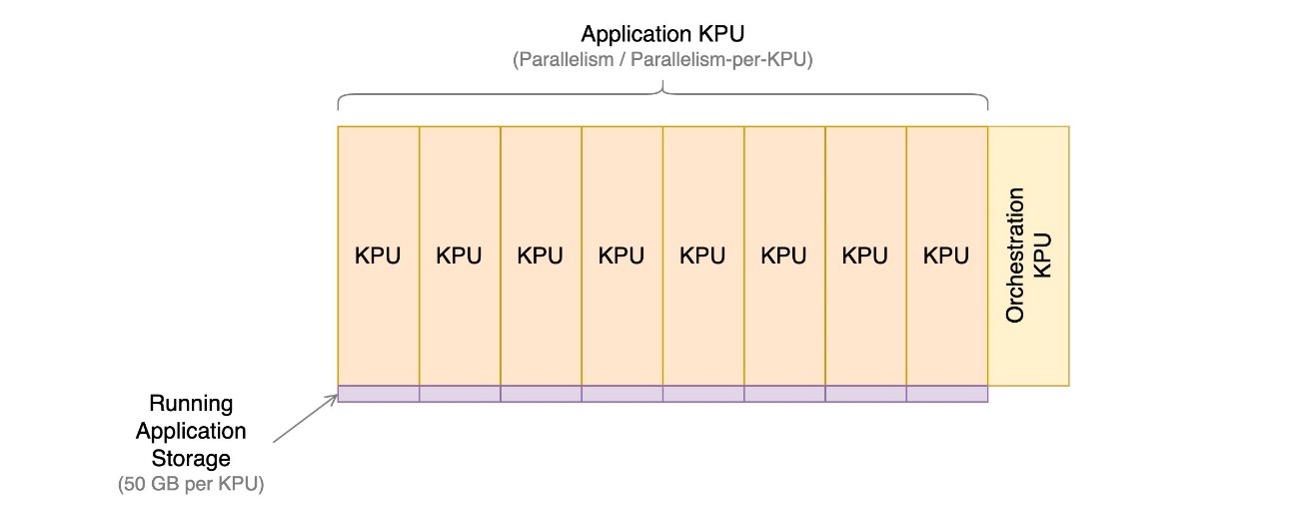
Apache Flink uygulamaları için Yönetilen Hizmet, 1 sanal CPU ve 4 GB bellekten oluşan bilgi işlem örnekleri olan Kinesis İşleme Birimlerinden (KPU'lar) oluşur. Uygulamaya atanan toplam KPU sayısı, doğrudan kontrol ettiğiniz iki parametrenin çarpılmasıyla belirlenir:
- paralellik – Apache Flink uygulamasındaki paralel işleme düzeyi
- KPU başına paralellik – Her paralelliğe ayrılmış kaynak sayısı
KPU'ların sayısı basit formülle belirlenir: KPU = Paralellik / ParalellikKPU başına, bir sonraki tam sayıya yuvarlanır.
Düzenleme için uygulama başına ek bir KPU da ücretlendirilir ve doğrudan veri işleme için kullanılmaz.
Toplam KPU sayısı, uygulamaya ayrılan kaynakların, CPU'nun, belleğin ve uygulama depolama alanının sayısını belirler. Uygulama, her KPU için 1 vCPU ve 4 GB bellek alır; bunun 3 GB'ı varsayılan olarak çalışan uygulamaya ayrılır ve geri kalan 1 GB, uygulama durumu deposu yönetimi için kullanılır. Her KPU ayrıca uygulamaya bağlı 50 GB depolama alanıyla birlikte gelir. Apache Flink, uygulama durumunu yapılandırılabilir bir sınıra kadar bellekte tutar ve bağlı depolama birimine yayılmayı sağlar.
Üçüncü maliyet bileşeni ise dayanıklı uygulama yedeklemeleridir veya anlık. Bu tamamen isteğe bağlıdır ve çok sayıda anlık görüntüyü saklamadığınız sürece genel maliyet üzerindeki etkisi küçüktür.
Bu yazının yazıldığı sırada, ABD Doğu (Ohio) AWS Bölgesindeki her KPU'nun maliyeti saat başına 0.11 ABD dolarıdır ve ekli uygulama depolama alanının GB başına aylık 0.10 ABD doları maliyeti vardır. Dayanıklı uygulama yedeklemesinin (anlık görüntüler) maliyeti GB başına aylık 0.023 USD'dir. Bakınız Apache Flink Fiyatlandırması için Amazon Yönetilen Hizmet güncel fiyatlandırma ve farklı Bölgeler için.
Aşağıdaki şemada, Apache Flink için Yönetilen Hizmet üzerinde çalışan bir uygulamanın maliyet bileşenlerinin göreceli oranları gösterilmektedir. KPU sayısını KPU başına paralellik ve paralellik parametreleri aracılığıyla kontrol edersiniz. Dayanıklı uygulama yedekleme depolaması temsil edilmez.
Aşağıdaki bölümlerde maliyetlerinizi nasıl izleyeceğinizi, uygulama kaynaklarının kullanımını nasıl optimize edeceğinizi ve üretim profilinizi yönetmek için gereken sayıda KPU'yu nasıl bulacağınızı inceliyoruz.
AWS Cost Explorer ve faturanızı anlama
Apache Flink için mevcut Yönetilen Hizmet harcamanızın ne kadar olduğunu görmek için şunu kullanabilirsiniz: AWS Maliyet Gezgini.
Maliyet Gezgini konsolunda, Apache Flink uygulamalarına yönelik Yönetilen Hizmet harcamalarınızı izole etmek için tarih aralığına, kullanım türüne ve hizmete göre filtreleme yapabilirsiniz. Aşağıdaki ekran görüntüsü, önceki bölümde açıklanan fiyat kategorilerine göre ayrılmış son 12 aylık maliyeti göstermektedir. Bu ayların çoğunda harcamaların çoğunluğu etkileşimli KPU'lardan yapıldı. Apache Flink Studio için Amazon Yönetilen Hizmeti.
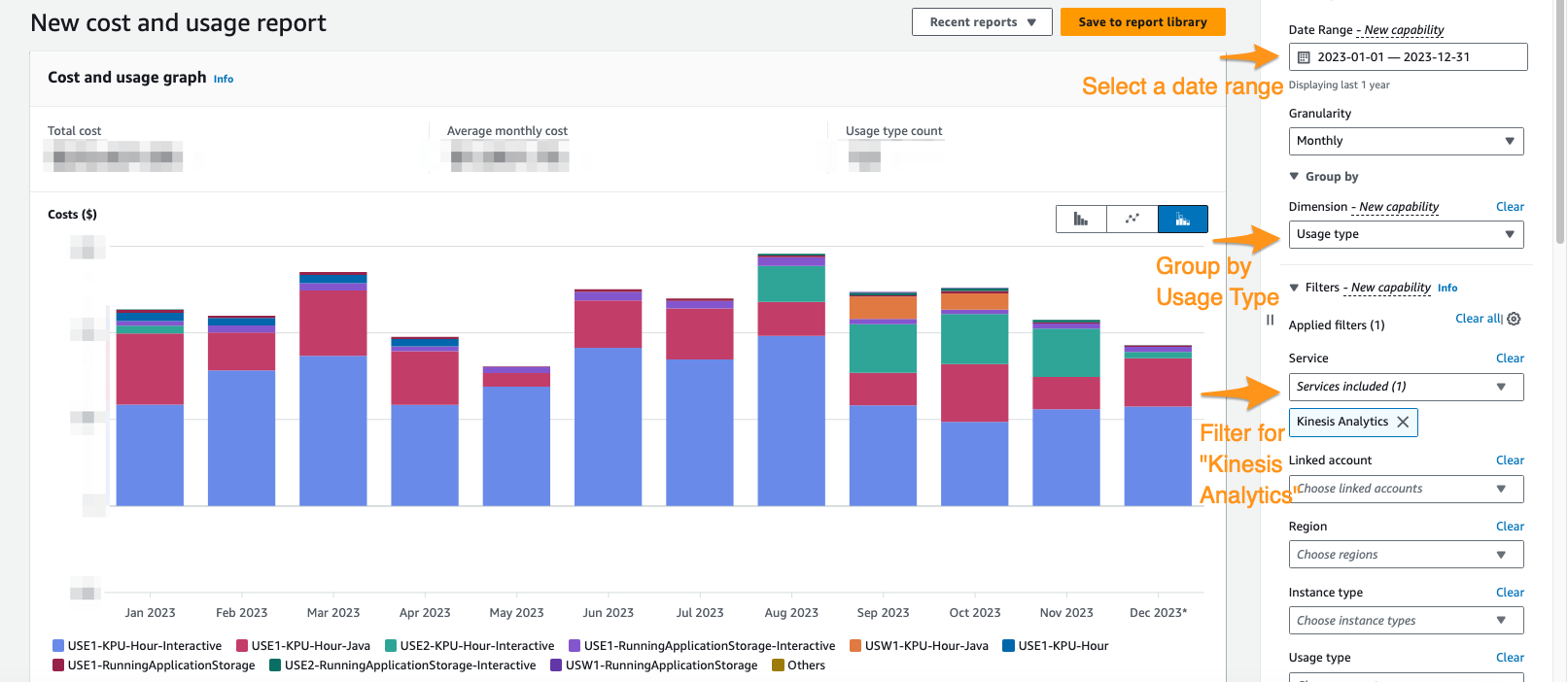
Maliyet Gezgini'ni kullanmak yalnızca faturanızı anlamanıza yardımcı olmakla kalmaz, aynı zamanda otomatik olarak veya üretim gereksinimleri nedeniyle beklentilerin ötesinde ölçeklenen belirli uygulamaları daha da optimize etmenize yardımcı olur. Uygun uygulama etiketlemeyle, hangi uygulamaların maliyeti oluşturduğunu görmek için bu harcamayı uygulamaya göre de ayırabilirsiniz.
Kaynakların aşırı tedarik edildiğine veya verimsiz kullanıldığına dair işaretler
Apache Flink uygulamalarına yönelik Yönetilen Hizmetle ilişkili maliyetleri en aza indirmek için basit bir yaklaşım, uygulamalarınızın kullandığı KPU sayısını azaltmayı içerir. Ancak bu azalmanın kapsamlı bir şekilde değerlendirilip test edilmemesi durumunda performansı olumsuz yönde etkileyebileceğinin bilincinde olmak çok önemlidir. Uygulamalarınızın aşırı provizyona tabi tutulup tutulmayacağını hızlı bir şekilde ölçmek için CPU ve bellek kullanımı, uygulama işlevselliği ve veri dağıtımı gibi temel göstergeleri inceleyin. Bununla birlikte, bu göstergeler olası aşırı provizyonu gösterse de, KPU sayısında herhangi bir ayarlama yapmadan önce performans testi yapmanız ve ölçeklendirme modellerinizi doğrulamanız önemlidir.
Metrikleri
Analiz uygulamanız için ölçümler on Amazon Bulut İzleme aşırı tedarikin açık sinyallerini ortaya çıkarabilir. Eğer containerCPUUtilization ve containerMemoryUtilization Uygulamanızın trafik modelleri için istatistiksel olarak anlamlı bir süre boyunca metrikler sürekli olarak %20'nin altında kalırsa, ölçeği küçültmek ve daha az makineye daha fazla veri tahsis etmek uygun olabilir. Genel olarak, aşağıdaki durumlarda uygun boyuttaki uygulamaları dikkate alırız: containerCPUUtilization %50-75 arasında seyrediyor. Rağmen containerMemoryUtilization gün boyunca dalgalanabilir ve kod optimizasyonundan etkilenebilir; önemli bir süre boyunca sürekli olarak düşük bir değer, potansiyel aşırı provizyonun göstergesi olabilir.
Yeterince kullanılmayan KPU başına paralellik
Uygulamanızın aşırı provizyonlandığının bir diğer ince işareti, uygulamanızın tamamen G/Ç bağlantılı olması veya yalnızca veritabanlarına ve CPU yoğun olmayan işlemlere basit çağrılar yapmasıdır. Durum böyleyse, tek bir işlem birimine daha fazla görev yüklemek için Apache Flink için Yönetilen Hizmet içindeki KPU başına paralellik parametresini kullanabilirsiniz.
KPU başına paralellik parametresini, bilgi işlem ve bellek kaynağı (KPU) birimi başına iş yükü yoğunluğunun bir ölçüsü olarak görüntüleyebilirsiniz. KPU başına paralelliği varsayılan değer olan 1'in üzerine çıkarmak, işlemeyi daha yoğun hale getirerek tek bir KPU'ya daha fazla paralel işlem tahsis edilmesini sağlar.
Aşağıdaki diyagram, uygulama paralelliğini sabit tutarak (örneğin, 4) ve KPU başına paralelliği artırarak (örneğin, 1'den 2'ye), uygulamanızın aynı düzeyde paralel çalıştırmayla nasıl daha az kaynak kullandığını gösterir.
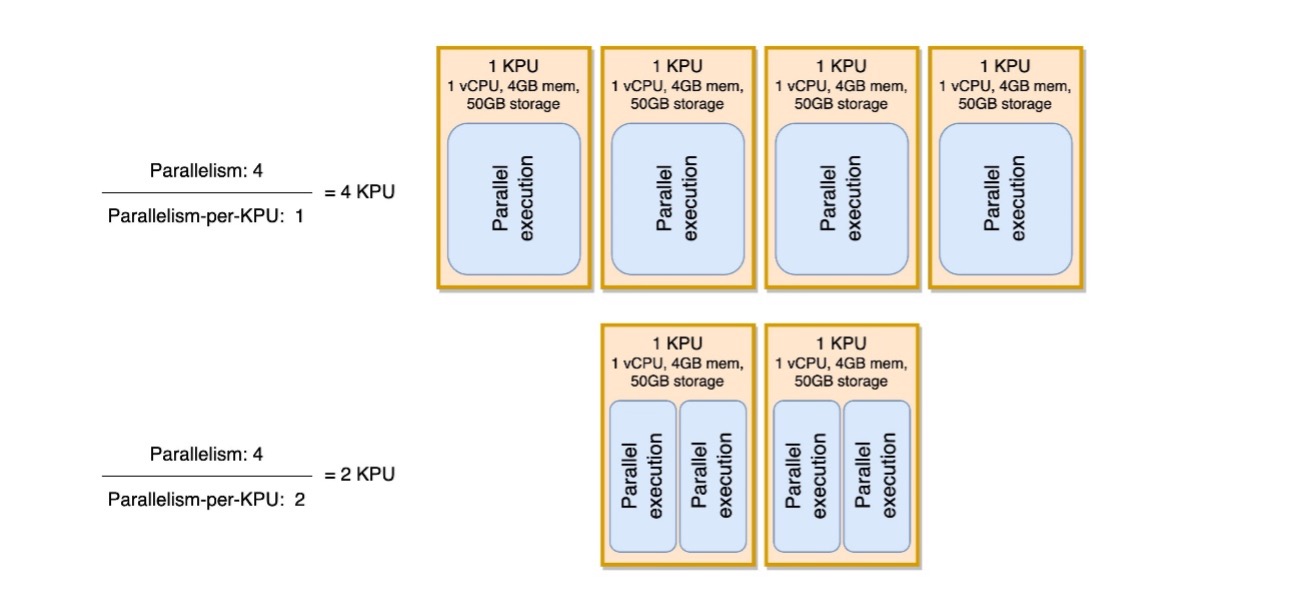
Bu yazıdaki tüm öneriler gibi, KPU başına paralelliği artırma kararı da büyük bir dikkatle alınmalıdır. KPU değeri başına paralelliği artırmak, tek bir KPU'ya daha fazla yük getirebilir ve KPU'nun bu yükü tolere etmeye istekli olması gerekir. G/Ç bağlantılı işlemler CPU veya bellek kullanımını anlamlı bir şekilde artırmaz, ancak verilere karşı birçok karmaşık işlemi hesaplayan bir işlem işlevi, kaynakları aşırı doldurabileceğinden tek bir KPU'da derlemek için ideal bir işlem olmayacaktır. Performans testi yapın ve bunun uygulamalarınız için iyi bir seçenek olup olmadığını değerlendirin.
Boyutlandırmaya nasıl yaklaşılır?
Apache Flink uygulaması için Yönetilen Hizmet oluşturmadan önce uygulamanız için ayırmanız gereken KPU sayısını tahmin etmek zor olabilir. Genel olarak, tahmin yapmadan önce trafik kalıplarınız hakkında iyi bir fikir sahibi olmanız gerekir. Trafik modellerinizi saniyede megabayt besleme hızı bazında anlamak, yaklaşık olarak bir başlangıç noktası belirlemenize yardımcı olabilir.
Genel kural olarak, uygulamanızın işleyeceği 1 MB/sn başına bir KPU ile başlayabilirsiniz. Örneğin uygulamanız 10 MB/sn (ortalama) işliyorsa, uygulamanıza başlangıç noktası olarak 10 KPU ayırırsınız. Bunun genel bir tahmin için etkili olduğunu gördüğümüz çok üst düzey bir yaklaşım olduğunu unutmayın. Bununla birlikte, uzun bir süre boyunca metriklere (CPU, bellek, gecikme, genel iş performansı) dayalı olarak uzun vadede performans testi yapmanız ve bunun uygun bir boyutlandırma olup olmadığını değerlendirmeniz gerekir.
Uygulamanıza uygun boyutlandırmayı bulmak için Apache Flink uygulamasının ölçeğini büyütüp küçültmeniz gerekir. Belirtildiği gibi Apache Flink için Yönetilen Hizmet'te iki ayrı kontrolünüz vardır: KPU başına paralellik ve paralellik. Bu parametreler birlikte uygulama içindeki paralel işleme düzeyini ve mevcut genel bilgi işlem, bellek ve depolama kaynaklarını belirler.
Önerilen test metodolojisi, doğru boyutlandırmayı bulmaya çalışırken paralellik veya paralelliği KPU başına ayrı ayrı değiştirmektir. Genel olarak, genel kaynakları artırmadan paralel G/Ç bağlantılı işlemlerin sayısını artırmak için yalnızca KPU başına paralelliği değiştirin. Diğer tüm durumlarda, iş yükünüz için doğru boyutu bulmak amacıyla yalnızca paralelliği değiştirin (KPU buna bağlı olarak değişecektir).
Ayrıca şunları da yapabilirsiniz operatör seviyesinde paralelliği ayarlayın kaynakları, havuzları veya kısıtlanması gerekebilecek ve ölçeklendirme mekanizmalarından bağımsız olması gerekebilecek diğer operatörleri kısıtlamak için. Bunu, 10 bölüme sahip bir Apache Kafka konusundan okuyan bir Apache Flink uygulaması için kullanabilirsiniz. İle setParallelism() yöntemiyle, KafkaSource'u 10 ile sınırlayabilirsiniz, ancak Apache Flink için Yönetilen Hizmet uygulamasını, Kafka kaynağı için boş görevler oluşturmadan 10'dan yüksek bir paralelliğe ölçeklendirebilirsiniz. Diğer veri işleme durumları için, operatör paralelliğinin statik bir değere statik olarak ayarlanması değil, genel uygulama ölçeklendiğinde ölçeklenmesi için uygulama paralelliğinin bir fonksiyonunun ayarlanması önerilir.
Ölçeklendirme ve otomatik ölçeklendirme
Apache Flink için Yönetilen Hizmet'te, KPU başına paralelliği veya paralelliği değiştirmek, uygulama yapılandırmasının güncellenmesidir. Uygulamanın otomatik olarak bir süre almasına neden olur enstantane (devre dışı bırakılmadığı sürece), uygulamayı durdurun ve yeni boyutlandırmayla yeniden başlatarak durumu anlık görüntüden geri yükleyin. Ölçeklendirme işlemleri veri kaybına veya tutarsızlıklara neden olmaz ancak altyapı eklenirken veya kaldırılırken veri işlemeyi kısa süreliğine duraklatır. Bu, üretim ortamında yeniden ölçeklendirirken dikkate almanız gereken bir şeydir.
Test ve optimizasyon süreci sırasında devre dışı bırakmanızı öneririz. otomatik ölçeklendirme ve optimum değerleri bulmak için KPU başına paralellik ve paralelliğin değiştirilmesi. Belirtildiği gibi, manuel ölçeklendirme yalnızca uygulama yapılandırmasının bir güncellemesidir ve AWS Yönetim Konsolu veya API ile Uygulamayı Güncelle eylemi.
En uygun boyutlandırmayı bulduğunuzda, alınan aktarım hızınızın önemli ölçüde değişmesini bekliyorsanız otomatik ölçeklendirmeyi etkinleştirmeye karar verebilirsiniz.
Apache Flink için Yönetilen Hizmet'te birden çok türde otomatik ölçeklendirme kullanabilirsiniz:
- Kullanıma hazır otomatik ölçeklendirme – Uygulama paralelliğini otomatik olarak ayarlamak için bunu etkinleştirebilirsiniz.
containerCPUUtilizationmetrik. Otomatik ölçeklendirme yeni uygulamalarda varsayılan olarak etkindir. Otomatik ölçeklendirme algoritmasıyla ilgili ayrıntılar için bkz. Otomatik Ölçeklendirme. - İnce taneli, metrik tabanlı otomatik ölçeklendirme – Bunun uygulanması basittir. Otomasyon, aşağıdakiler de dahil olmak üzere hemen hemen tüm ölçümlere dayanabilir: özel ölçümler uygulamanız ortaya çıkar.
- Zamanlanmış ölçeklendirme – Günün belirli saatlerinde veya haftanın günlerinde iş yükünün zirveye çıkmasını bekliyorsanız bu yararlı olabilir.
Kullanıma hazır otomatik ölçeklendirme ve ince taneli metrik tabanlı ölçeklendirme birbirini dışlar. Ayrıntılı metrik tabanlı otomatik ölçeklendirme ve zamanlanmış ölçeklendirme hakkında daha fazla ayrıntı ve tam olarak çalışan bir kod örneği için bkz. Amazon Managed Service for Apache Flink için metrik tabanlı ve planlanmış ölçeklendirmeyi etkinleştirin.
Kod optimizasyonları
Apache Flink uygulamalarına yönelik Yönetilen Hizmetinizde maliyet tasarrufuna yaklaşmanın başka bir yolu da kod optimizasyonudur. Optimize edilmemiş kod, aynı hesaplamaları gerçekleştirmek için daha fazla makinenin kullanılmasını gerektirecektir. Kodun optimize edilmesi, genel kaynak kullanımının daha düşük olmasına olanak tanıyabilir ve bu da ölçek küçültülmesine ve buna göre maliyet tasarrufuna olanak sağlayabilir.
Kod performansınızı anlamanın ilk adımı, Apache Flink'teki yerleşik yardımcı programdır. Alev Grafikleri.
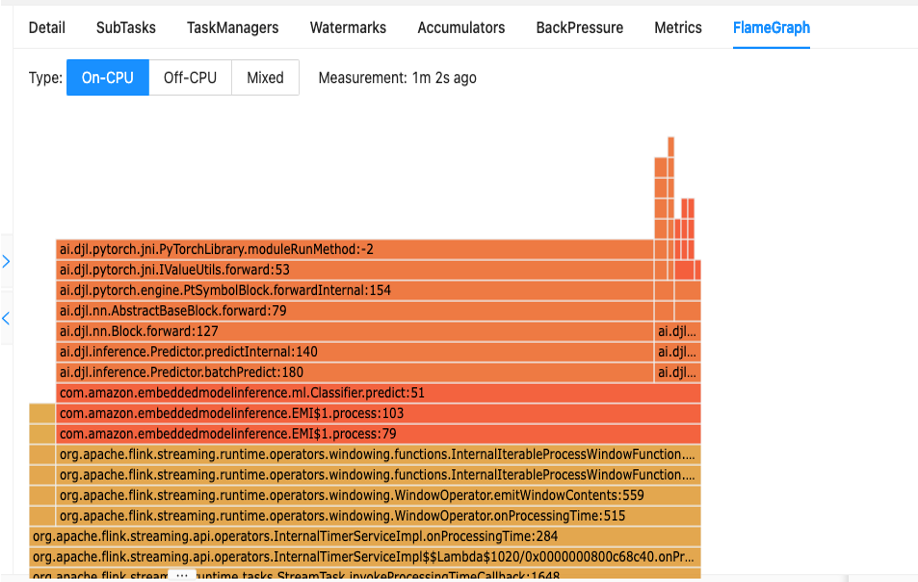
Apache Flink panosundan erişilebilen Alev Grafikleri size yığın izlemenizin görsel bir temsilini sunar. Bir yöntem her çağrıldığında, yığın izinde o yöntem çağrısını temsil eden çubuk, toplam örnek sayısıyla orantılı olarak büyür. Bu, alev grafiğinde çok uzun bir çubuk bulunan verimsiz bir kod parçanız varsa, bu kodun nasıl daha verimli hale getirilebileceği konusunda araştırma yapılmasına neden olabileceği anlamına gelir. Ek olarak şunları kullanabilirsiniz: Amazon CodeGuru Profil Oluşturucu için Apache Flink için Yönetilen Hizmet üzerinde çalışan Apache Flink uygulamalarınızı izleyin ve optimize edin.
Uygulamalarınızı tasarlarken, belirli bir zamanda belirli bir işlem için gerekli olan en üst düzey API'yi kullanmanız önerilir. Apache Flink dört düzeyde API desteği sunar: Flink SQL, Table API, Datastream API ve ProcessFunction Artan karmaşıklık ve sorumluluk düzeylerine sahip API'ler. Uygulamanız tamamen Flink SQL veya Table API'de yazılabiliyorsa, bunu kullanmak, durumu ve hesaplamaları manuel olarak yönetmek yerine Apache Flink çerçevesinden yararlanmanıza yardımcı olabilir.
Veri çarpıklığı
Apache Flink kontrol panelinde, Apache Flink için Yönetilen Hizmet işleriniz hakkında diğer yararlı bilgileri toplayabilirsiniz.
Kontrol panelinde iş başvurusu grafiğinizdeki görevleri tek tek inceleyebilirsiniz. Her mavi kutu bir görevi temsil eder ve her görev, o göreve ilişkin alt görevlerden veya dağıtılmış iş birimlerinden oluşur. Alt görevler arasındaki veri çarpıklığını bu şekilde tanımlayabilirsiniz.
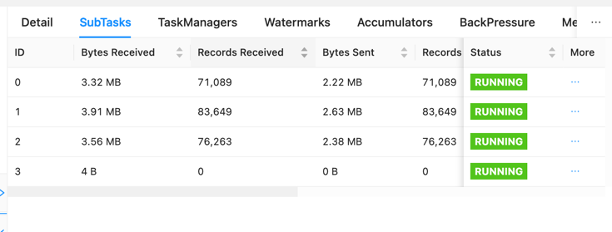
Veri çarpıklığı, bir alt göreve diğerine göre daha fazla veri gönderildiğinin ve daha fazla veri alan bir alt görevin diğerinden daha fazla iş yaptığını gösteren bir göstergedir. Bu tür veri çarpıklığı belirtileri yaşıyorsanız kaynağı belirleyerek ortadan kaldırmaya çalışabilirsiniz. Örneğin, bir GroupBy or KeyedStream anahtarda bir çarpıklık olabilir. Bu, verilerin anahtarlar arasında eşit şekilde dağılmaması anlamına gelir ve bu da Apache Flink hesaplama örnekleri arasında eşit olmayan bir iş dağılımına neden olur. Şuna göre gruplandırdığınız bir senaryo düşünün: userIdancak uygulamanız bir kullanıcıdan diğerlerinden çok daha fazla veri alıyor. Bu, veri çarpıklığına neden olabilir. Bunu ortadan kaldırmak için verileri alt görevlere eşit şekilde dağıtmak üzere farklı bir gruplandırma anahtarı seçebilirsiniz. Bunun farklı bir anahtar seçmek için kod değişikliği gerektireceğini unutmayın.
Veri çarpıklığı ortadan kaldırıldığında eski ekrana geri dönebilirsiniz. containerCPUUtilization ve containerMemoryUtilization KPU sayısını azaltmaya yönelik ölçümler.
Kod optimizasyonunun diğer alanları arasında harici sistemlere Eşzamansız G/Ç API'si veya bir veri akışı birleşimi aracılığıyla, çünkü bir veri deposuna gönderilen senkronize bir sorgu, kontrol noktası belirlemede yavaşlamalara ve sorunlara neden olabilir. Ek olarak, bkz. Sorun Giderme Performansı Uygulamanın geri tepmesine neden olabilecek yavaş kontrol noktaları veya günlük kaydıyla karşılaşabileceğiniz sorunlar için.
Apache Flink'in doğru teknoloji olup olmadığı nasıl belirlenir
Uygulamanız Apache Flink çerçevesinin ve Apache Flink için Yönetilen Hizmetin arkasındaki güçlü özelliklerden herhangi birini kullanmıyorsa, daha basit bir şey kullanarak muhtemelen maliyetten tasarruf edebilirsiniz.
Apache Flink'in sloganı "Veri Akışları Üzerinde Durum Bilgili Hesaplamalar"dır. Bu bağlamda durum bilgisi, Apache Flink durum yapısını kullandığınız anlamına gelir. Apache Flink'teki State, geçmişte gördüğünüz mesajları daha uzun süre hatırlamanıza olanak tanıyarak akış birleştirmeleri, veri tekilleştirme, tam olarak bir kez işleme, pencereleme ve geç veri işleme gibi şeyleri mümkün kılar. Bunu bir bellek içi durum deposunu kullanarak yapar. Apache Flink için Yönetilen Hizmet'te şunu kullanır: RocksDB durumunu korumaktır.
Uygulamanız durum bilgisi olan işlemler içermiyorsa aşağıdaki gibi alternatifleri düşünebilirsiniz: AWS Lambda, kapsayıcıya alınmış uygulamalar veya Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2) uygulamanızı çalıştıran örnek. Bu gibi durumlarda Apache Flink'in karmaşıklığı gerekli olmayabilir. Önbelleğe alınmış veriler veya bağımsız akış konumu belleği gerektiren zenginleştirme prosedürleri de dahil olmak üzere durum bilgisi olan hesaplamalar, Apache Flink'in durum bilgisi olan yeteneklerini garanti edebilir. Uygulamanızın gelecekte, uzun süreli veri saklama veya diğer durum bilgisi gereksinimleri nedeniyle durum bilgisi olan hale gelme potansiyeli varsa, Apache Flink'i kullanmaya devam etmek daha kolay olabilir. Akış işleme yetenekleri için Apache Flink'i vurgulayan kuruluşlar, tüm uygulamalarının verileri aynı şekilde işlemesi için durum bilgisi olan ve durum bilgisi olmayan uygulamalar için Apache Flink'e bağlı kalmayı tercih edebilir. Apache Flink'ten alternatiflere geçmeden önce tam olarak bir kez işleme, yayma yetenekleri ve dağıtılmış hesaplama gibi düzenleme özelliklerini de hesaba katmalısınız.
Dikkate alınması gereken diğer bir husus gecikme gereksinimlerinizdir. Apache Flink, gerçek zamanlı veri işleme konusunda üstün olduğundan, bunu 6 saatlik veya 1 günlük gecikme gereksinimi olan bir uygulama için kullanmak mantıklı değildir. Geçici toplu işleme geçiş sayesinde maliyet tasarrufu Amazon Basit Depolama Hizmeti (Amazon S3) örneğin önemli olacaktır.
Sonuç
Bu yazıda, Apache Flink için Yönetilen Hizmete yönelik maliyet tasarrufu önlemlerini almaya çalışırken dikkate alınması gereken bazı hususları ele aldık. Yönetilen hizmetteki genel harcamanızı nasıl belirleyeceğinizi, KPU'larınızın ölçeğini küçültürken izleyeceğiniz bazı yararlı ölçümleri, ölçeği küçültmek için kodunuzu nasıl optimize edebileceğinizi ve Apache Flink'in kullanım durumunuz için doğru olup olmadığını nasıl belirleyeceğinizi tartıştık.
Bu maliyet tasarrufu sağlayan stratejileri uygulamak yalnızca maliyet verimliliğinizi artırmakla kalmaz, aynı zamanda akıcı ve iyi optimize edilmiş bir Apache Flink dağıtımı sağlar. Genel harcamanıza dikkat ederek, temel ölçümleri kullanarak ve kaynakları azaltma konusunda bilinçli kararlar alarak, performanstan ödün vermeden uygun maliyetli bir operasyon gerçekleştirebilirsiniz. Apache Flink ortamında gezinirken, bunun özel kullanım durumunuza uygun olup olmadığını sürekli olarak değerlendirmek çok önemli hale gelir; böylece veri işleme ihtiyaçlarınız için özel ve etkili bir çözüm elde edebilirsiniz.
Bu gönderide tartışılan önerilerden herhangi biri iş yükünüze uygunsa bunları denemenizi öneririz. Belirlenen ölçümler ve iş yüklerinizi nasıl daha iyi anlayacağınıza ilişkin ipuçları sayesinde artık Apache Flink için Yönetilen Hizmette Apache Flink iş yüklerinizi verimli bir şekilde optimize etmek için ihtiyacınız olan her şeye sahip olmalısınız. Bu yazıyı desteklemek için kullanabileceğiniz bazı yararlı kaynaklar şunlardır:
Yazarlar Hakkında
 Jeremy Ber son 10 yıldır telemetri veri alanında Yazılım Mühendisi, Makine Öğrenim Mühendisi ve son olarak Veri Mühendisi olarak çalışmaktadır. AWS'de Akış Uzmanı Çözüm Mimarıdır ve hem Apache Kafka için Amazon Yönetilen Akışı (Amazon MSK) hem de Apache Flink için Amazon Yönetilen Hizmeti desteklemektedir.
Jeremy Ber son 10 yıldır telemetri veri alanında Yazılım Mühendisi, Makine Öğrenim Mühendisi ve son olarak Veri Mühendisi olarak çalışmaktadır. AWS'de Akış Uzmanı Çözüm Mimarıdır ve hem Apache Kafka için Amazon Yönetilen Akışı (Amazon MSK) hem de Apache Flink için Amazon Yönetilen Hizmeti desteklemektedir.
 Lorenzo Nicora AWS'de Kıdemli Yayın Çözümü Mimarı olarak çalışıyor ve EMEA genelindeki müşterilere yardımcı oluyor. 25 yılı aşkın süredir bulut tabanlı, veri yoğunluklu sistemler kuruyor, finans sektöründe hem danışmanlıklar aracılığıyla hem de FinTech ürün şirketleri için çalışıyor. Açık kaynak teknolojilerinden kapsamlı bir şekilde yararlandı ve Apache Flink de dahil olmak üzere birçok projeye katkıda bulundu.
Lorenzo Nicora AWS'de Kıdemli Yayın Çözümü Mimarı olarak çalışıyor ve EMEA genelindeki müşterilere yardımcı oluyor. 25 yılı aşkın süredir bulut tabanlı, veri yoğunluklu sistemler kuruyor, finans sektöründe hem danışmanlıklar aracılığıyla hem de FinTech ürün şirketleri için çalışıyor. Açık kaynak teknolojilerinden kapsamlı bir şekilde yararlandı ve Apache Flink de dahil olmak üzere birçok projeye katkıda bulundu.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/real-time-cost-savings-for-amazon-managed-service-for-apache-flink/

