Büyük dil modelleri (LLM'ler) için dağıtılmış derin öğrenme alanında, özellikle de ChatGPT'nin Aralık 2022'de piyasaya sürülmesinden sonra muazzam ilerleme kaydedildi. LLM'ler milyarlarca, hatta trilyonlarca parametreyle boyut olarak büyümeye devam ediyor ve çoğu zaman büyümeyecekler. Bellek sınırlamaları nedeniyle GPU gibi tek bir hızlandırıcı cihaza veya ml.p5.32xlarge gibi tek bir düğüme bile sığar. LLM'lere eğitim veren müşteriler genellikle iş yüklerini yüzlerce hatta binlerce GPU'ya dağıtmak zorundadır. Bu kadar büyük bir ölçekte eğitimin sağlanması, dağıtılmış eğitimde bir zorluk olmaya devam ediyor ve bu kadar büyük bir sistemde verimli bir şekilde eğitim verilmesi de aynı derecede önemli bir sorundur. Geçtiğimiz yıllarda, dağıtılmış eğitim topluluğu bu tür zorlukların üstesinden gelmek için 3 boyutlu paralelliği (veri paralelliği, boru hattı paralelliği ve tensör paralelliği) ve diğer teknikleri (dizi paralelliği ve uzman paralelliği gibi) tanıttı.
Aralık 2023'te Amazon, SageMaker modeli paralel kitaplığı 2.0 (SMP) ile birlikte büyük model eğitiminde son teknoloji verimliliği yakalayan SageMaker dağıtılmış veri paralelliği kütüphanesi (SMDDP). Bu sürüm, 1.x'in önemli bir güncellemesidir: SMP artık açık kaynak PyTorch ile entegredir Tamamen Parçalanmış Veri Paralel (FSDP) API'leri, büyük modelleri eğitirken tanıdık bir arayüz kullanmanızı sağlar ve aşağıdakilerle uyumludur: Trafo Motoru (TE), ilk kez FSDP ile birlikte tensör paralellik tekniklerinin kilidini açıyor. Sürüm hakkında daha fazla bilgi edinmek için bkz. Amazon SageMaker model paralel kitaplığı artık PyTorch FSDP iş yüklerini %20'ye kadar hızlandırıyor.
Bu yazıda performans avantajlarını araştırıyoruz. Amazon Adaçayı Yapıcı (SMP ve SMDDP dahil) ve büyük modelleri SageMaker'da verimli bir şekilde eğitmek için kitaplığı nasıl kullanabileceğinizi öğrenin. SageMaker'ın performansını, 4 örneğe kadar ml.p24d.128xlarge kümelerindeki kıyaslamalarla ve Llama 16 modeli için bfloat2 ile FSDP karma hassasiyetiyle gösteriyoruz. SageMaker için doğrusala yakın ölçeklendirme verimliliklerinin gösterimiyle başlıyoruz, ardından optimum verim için her özelliğin katkılarını analiz ediyoruz ve tensör paralelliği aracılığıyla 32,768'e kadar çeşitli dizi uzunluklarıyla verimli eğitimle sonlandırıyoruz.
SageMaker ile doğrusala yakın ölçeklendirme
LLM modellerinin genel eğitim süresini azaltmak için, büyük kümelere (binlerce GPU) ölçeklenirken yüksek verimi korumak, düğümler arası iletişim ek yükü göz önüne alındığında çok önemlidir. Bu yazıda, hem SMP'yi hem de SMDDP'yi çağıran p4d bulut sunucularında sağlam ve doğrusala yakın ölçeklendirmenin (sabit bir toplam sorun boyutu için GPU sayısını değiştirerek) verimliliklerini gösteriyoruz.
Bu bölümde SMP'nin doğrusala yakın ölçeklendirme performansını gösteriyoruz. Burada, 2 sabit dizi uzunluğu, toplu iletişim için SMDDP arka ucu, TE etkin, 7 ila 13 p70d düğümü ile 4,096 milyon küresel toplu iş boyutu kullanarak çeşitli boyutlardaki (4B, 16B ve 128B parametreleri) Llama 4 modellerini eğitiyoruz. . Aşağıdaki tablo, optimum yapılandırmamızı ve eğitim performansımızı özetlemektedir (saniyedeki TFLOP modeli).
| Model boyutu | Düğüm sayısı | TFLOP'lar* | SDP* | TP* | boşaltma* | Ölçekleme verimliliği |
| 7B | 16 | 136.76 | 32 | 1 | N | %100.0 |
| 32 | 132.65 | 64 | 1 | N | %97.0 | |
| 64 | 125.31 | 64 | 1 | N | %91.6 | |
| 128 | 115.01 | 64 | 1 | N | %84.1 | |
| 13B | 16 | 141.43 | 32 | 1 | Y | %100.0 |
| 32 | 139.46 | 256 | 1 | N | %98.6 | |
| 64 | 132.17 | 128 | 1 | N | %93.5 | |
| 128 | 120.75 | 128 | 1 | N | %85.4 | |
| 70B | 32 | 154.33 | 256 | 1 | Y | %100.0 |
| 64 | 149.60 | 256 | 1 | N | %96.9 | |
| 128 | 136.52 | 64 | 2 | N | %88.5 |
*Verilen model boyutu, dizi uzunluğu ve düğüm sayısında, çeşitli sdp, tp ve aktivasyon boşaltma kombinasyonlarını araştırdıktan sonra küresel olarak en uygun verimi ve konfigürasyonları gösteririz.
Önceki tablo, parçalanmış veri paralel (sdp) derecesine (tipik olarak tam parçalama yerine FSDP karma parçalamayı kullanır; bir sonraki bölümde daha fazla ayrıntıyla birlikte), tensör paralel (tp) derecesine ve aktivasyon boşaltma değeri değişikliklerine tabi olan optimum üretim sayılarını özetlemektedir. SMDDP ile birlikte SMP için doğrusala yakın bir ölçeklendirme gösteriyor. Örneğin, Llama 2 modelinin 7B boyutu ve 4,096 dizi uzunluğu göz önüne alındığında, genel olarak 97.0, 91.6 ve 84.1 düğümde sırasıyla %16, %32 ve %64 (128 düğüme göre) ölçeklendirme verimliliğine ulaşır. Ölçeklendirme verimliliği farklı model boyutlarında sabittir ve model boyutu büyüdükçe biraz artar.
SMP ve SMDDP ayrıca 2,048 ve 8,192 gibi diğer dizi uzunlukları için de benzer ölçeklendirme verimlilikleri göstermektedir.
SageMaker modeli paralel kütüphane 2.0 performansı: Llama 2 70B
Model boyutları, LLM topluluğundaki sık sık yapılan son teknoloji performans güncellemeleriyle birlikte geçtiğimiz yıllarda büyümeye devam etti. Bu bölümde, 2B sabit model boyutu, 70 dizi uzunluğu ve 4,096 milyon küresel toplu iş boyutu kullanarak Llama 4 modeli için SageMaker'daki performansı gösteriyoruz. Önceki tablonun genel olarak optimum konfigürasyonu ve verimi (SMDDP arka uç, tipik olarak FSDP hibrit parçalama ve TE ile) ile karşılaştırmak için aşağıdaki tablo, dağıtılmış arka uçtaki (NCCL ve SMDDP) ekstra spesifikasyonlarla diğer optimum verimleri (potansiyel olarak tensör paralelliği ile) kapsar. FSDP parçalama stratejileri (tam parçalama ve hibrit parçalama) ve TE'nin etkinleştirilip etkinleştirilmediği (varsayılan).
| Model boyutu | Düğüm sayısı | Teraflop | TFLOP #3 yapılandırması | TFLOP'larda taban çizgisine göre iyileşme | ||||||||
| . | . | NCCL tam parçalama: #0 | SMDDP tam parçalama: #1 | SMDDP hibrit parçalama: #2 | TE ile SMDDP hibrit parçalama: #3 | SDP* | TP* | boşaltma* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | %0.1 | %2.9 | %2.3 |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | %0.0 | %0.7 | %2.9 | %3.6 | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | %50.4 | %26.8 | %4.5 | %99.2 | |
*Verilen model boyutu, sıra uzunluğu ve düğüm sayısında, çeşitli sdp, tp ve aktivasyon boşaltma kombinasyonlarını araştırdıktan sonra genel olarak en uygun verimi ve konfigürasyonu gösteririz.
SMP ve SMDDP'nin en son sürümü, yerel PyTorch FSDP, genişletilmiş ve daha esnek hibrit parçalama, transformatör motoru entegrasyonu, tensör paralelliği ve optimize edilmiş tüm toplu toplama operasyonları dahil olmak üzere çok sayıda özelliği destekler. SageMaker'ın LLM'ler için verimli dağıtılmış eğitime nasıl ulaştığını daha iyi anlamak için SMDDP'nin ve aşağıdaki SMP'nin artan katkılarını araştırıyoruz. çekirdek özellikleri:
- FSDP tam parçalamayla NCCL üzerinden SMDDP geliştirmesi
- FSDP tam parçalamanın, verimi artırmak için iletişim maliyetini azaltan hibrit parçalamayla değiştirilmesi
- Tensör paralelliği devre dışı bırakıldığında bile TE ile üretimde daha fazla artış
- Daha düşük kaynak ayarlarında, etkinleştirme yükünün boşaltılması, yüksek bellek baskısı nedeniyle aksi takdirde uygulanamaz veya çok yavaş olacak eğitime olanak tanıyabilir
FSDP tam parçalama: NCCL üzerinden SMDDP geliştirmesi
Önceki tabloda gösterildiği gibi, modeller FSDP ile tamamen parçalandığında, NCCL (TFLOP #0) ve SMDDP (TFLOP #1) aktarımları 32 veya 64 düğümde karşılaştırılabilir olmasına rağmen, NCCL'den SMDDP'ye %50.4'lük büyük bir iyileşme vardır. 128 düğümde.
Daha küçük model boyutlarında, SMDDP'nin iletişim darboğazını etkili bir şekilde azaltabilmesi nedeniyle, daha küçük küme boyutlarından başlayarak NCCL'ye göre SMDDP ile tutarlı ve önemli gelişmeler gözlemliyoruz.
İletişim maliyetini azaltmak için FSDP hibrit parçalama
SMP 1.0'da başlattık parçalanmış veri paralelliğiAmazon'un kendi bünyesinde desteklediği dağıtılmış bir eğitim tekniği Mikrofonlar teknoloji. SMP 2.0'da, FSDP tam parçalamada olduğu gibi, modellerin tüm eğitim GPU'ları yerine GPU'ların bir alt kümesi arasında paylaştırılmasına olanak tanıyan genişletilebilir ve daha esnek bir hibrit parçalama tekniği olan SMP hibrit parçalamayı sunuyoruz. GPU başına bellek kısıtlamalarını karşılamak amacıyla kümenin tamamında parçalanması gerekmeyen orta boyutlu modeller için kullanışlıdır. Bu, kümelerin birden fazla model kopyasına sahip olmasına ve her GPU'nun çalışma zamanında daha az sayıda eşle iletişim kurmasına yol açar.
SMP'nin hibrit parçalama özelliği, bellek yetersizliği sorunu olmayan en küçük parça derecesinden tüm küme boyutuna (bu da tam parçalamaya eşittir) kadar daha geniş bir aralıkta verimli model parçalamaya olanak tanır.
Aşağıdaki şekil, kolaylık sağlamak amacıyla tp = 1'de sdp'ye olan üretim bağımlılığını göstermektedir. Her ne kadar önceki tabloda NCCL veya SMDDP tam parçalama için en uygun tp değeriyle aynı olmasa da sayılar oldukça yakındır. Hem NCCL hem de SMDDP için geçerli olan 128 düğümden oluşan büyük bir küme boyutunda tam parçalamadan hibrit parçalamaya geçişin değerini açıkça doğrular. Daha küçük model boyutları için, hibrit parçalamayla ilgili önemli iyileştirmeler daha küçük küme boyutlarında başlar ve küme boyutu arttıkça fark artmaya devam eder.
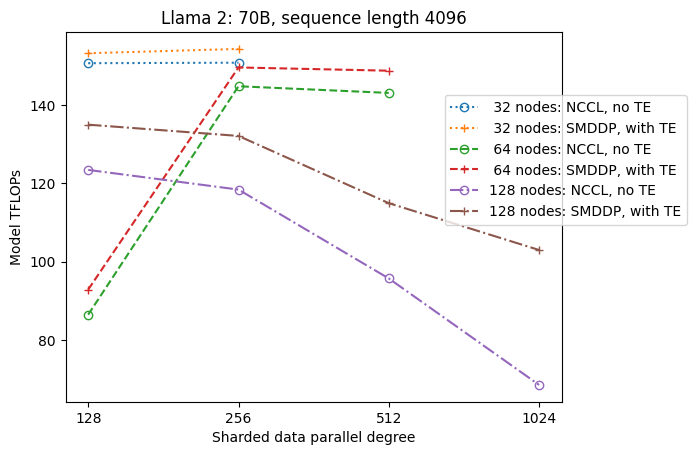
TE ile iyileştirmeler
TE, NVIDIA GPU'larda Yüksek Lisans eğitimini hızlandırmak için tasarlanmıştır. FP8'i p4d bulut sunucularında desteklenmediği için kullanmamamıza rağmen, p4d'de TE ile hala önemli bir hızlanma görüyoruz.
SMDDP arka ucuyla eğitilen MiCS'nin yanı sıra TE, tensör paralelliği devre dışı bırakıldığında bile (tensör paralellik derecesi 128'dir) tüm küme boyutlarında (tek istisna 1 düğümde tam parçalamadır) aktarım için tutarlı bir artış sunar.
Daha küçük model boyutları veya çeşitli dizi uzunlukları için TE artışı yaklaşık %3-7.6 aralığında stabildir ve önemsiz değildir.
Düşük kaynak ayarlarında etkinleştirme yükünü boşaltma
Düşük kaynak ayarlarında (az sayıda düğüm göz önüne alındığında), etkinleştirme denetim noktası etkinleştirildiğinde FSDP yüksek bellek baskısıyla (veya en kötü durumda belleğin yetersiz kalmasıyla) karşılaşabilir. Bellekte darboğaz yaşanan bu tür senaryolarda, etkinleştirme yükünün azaltılması performansı artırmaya yönelik bir seçenek olabilir.
Örneğin, daha önce gördüğümüz gibi, model boyutu 2B ve dizi uzunluğu 13 olan Llama 4,096, aktivasyon kontrol noktasıyla ve aktivasyon boşaltması olmadan en az 32 düğümle en iyi şekilde eğitim alabilmesine rağmen, 16 ile sınırlı olduğunda aktivasyon boşaltma ile en iyi verimi elde eder. düğümler.
Uzun dizilerle eğitimi etkinleştirin: SMP tensör paralelliği
Uzun konuşmalar ve bağlam için daha uzun dizi uzunlukları istenmektedir ve LLM topluluğunda daha fazla ilgi görmektedir. Bu nedenle aşağıdaki tabloda çeşitli uzun dizi çıktılarını rapor ediyoruz. Tablo, SageMaker'da Llama 2 eğitimi için 2,048'den 32,768'e kadar çeşitli dizi uzunluklarıyla en uygun verimi gösterir. 32,768 dizi uzunluğunda, yerel FSDP eğitimi, 32 milyonluk küresel toplu iş boyutunda 4 düğümle mümkün değildir.
| . | . | . | Teraflop | ||
| Model boyutu | dizi uzunluğu | Düğüm sayısı | Yerel FSDP ve NCCL | SMP ve SMDDP | SMP iyileştirmesi |
| 7B | 2048 | 32 | 129.25 | 138.17 | %6.9 |
| 4096 | 32 | 124.38 | 132.65 | %6.6 | |
| 8192 | 32 | 115.25 | 123.11 | %6.8 | |
| 16384 | 32 | 100.73 | 109.11 | %8.3 | |
| 32768 | 32 | NA | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | %4.7 |
| 4096 | 32 | 133.30 | 139.46 | %4.6 | |
| 8192 | 32 | 125.04 | 130.08 | %4.0 | |
| 16384 | 32 | 111.58 | 117.01 | %4.9 | |
| 32768 | 32 | NA | 92.38 | . | |
| *: maksimum | . | . | . | . | %8.3 |
| *: medyan | . | . | . | . | %5.8 |
Küme boyutu büyük olduğunda ve sabit bir genel toplu iş boyutu verildiğinde, bazı model eğitimleri, yerleşik bir ardışık düzen veya tensör paralellik desteğinin bulunmadığı yerel PyTorch FSDP ile mümkün olmayabilir. Önceki tabloda, 4 milyonluk genel toplu iş boyutu, 32 düğüm ve dizi uzunluğu 32,768 göz önüne alındığında, GPU başına etkin toplu iş boyutu 0.5'tir (örneğin, toplu iş boyutu 2 ile tp = 1); tensör paralelliği.
Sonuç
Bu yazıda, p4d bulut sunucularında SMP ve SMDDP ile verimli LLM eğitimi gösterdik; katkıları NCCL üzerinden SMDDP geliştirmesi, tam parçalama yerine esnek FSDP hibrit parçalama, TE entegrasyonu ve tensör paralelliğini etkinleştirme gibi birden fazla temel özelliğe atfettik. uzun dizi uzunlukları. Çeşitli modeller, model boyutları ve dizi uzunluklarıyla geniş bir ayar yelpazesinde test edildikten sonra, SageMaker'da 128 p4d örneğine kadar güçlü, doğrusala yakın ölçeklendirme verimliliği sergiliyor. Özetle SageMaker, LLM araştırmacıları ve uygulayıcıları için güçlü bir araç olmaya devam ediyor.
Daha fazla bilgi edinmek için bkz. SageMaker model paralellik kitaplığı v2veya şu adresten SMP ekibiyle iletişime geçin: sm-model-parallel-feedback@amazon.com.
Teşekkür
Yapıcı geri bildirimleri ve tartışmaları için Robert Van Dusen, Ben Snyder, Gautam Kumar ve Luis Quintela'ya teşekkür ederiz.
Yazarlar Hakkında

Xinle Sheila Liu Amazon SageMaker'da bir SDE'dir. Boş zamanlarında kitap okumaktan ve açık hava sporlarından hoşlanmaktadır.
 Sühit Kodgüle AWS Yapay Zeka grubunda derin öğrenme çerçeveleri üzerinde çalışan bir Yazılım Geliştirme Mühendisidir. Boş zamanlarında yürüyüş yapmaktan, seyahat etmekten ve yemek yapmaktan hoşlanıyor.
Sühit Kodgüle AWS Yapay Zeka grubunda derin öğrenme çerçeveleri üzerinde çalışan bir Yazılım Geliştirme Mühendisidir. Boş zamanlarında yürüyüş yapmaktan, seyahat etmekten ve yemek yapmaktan hoşlanıyor.
 Victor Zhu Amazon Web Services'te Dağıtılmış Derin Öğrenme alanında Yazılım Mühendisidir. SF Körfez Bölgesi çevresinde yürüyüş ve masa oyunlarının tadını çıkarırken bulunabilir.
Victor Zhu Amazon Web Services'te Dağıtılmış Derin Öğrenme alanında Yazılım Mühendisidir. SF Körfez Bölgesi çevresinde yürüyüş ve masa oyunlarının tadını çıkarırken bulunabilir.
 Derya Çavdar AWS'de yazılım mühendisi olarak çalışıyor. İlgi alanları arasında derin öğrenme ve dağıtılmış eğitim optimizasyonu yer almaktadır.
Derya Çavdar AWS'de yazılım mühendisi olarak çalışıyor. İlgi alanları arasında derin öğrenme ve dağıtılmış eğitim optimizasyonu yer almaktadır.
 Teng Xu AWS AI'daki Dağıtılmış Eğitim grubunda Yazılım Geliştirme Mühendisidir. Okumaktan hoşlanıyor.
Teng Xu AWS AI'daki Dağıtılmış Eğitim grubunda Yazılım Geliştirme Mühendisidir. Okumaktan hoşlanıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

