Büyük bir dil modeli (LLM) dağıtırken, makine öğrenimi (ML) uygulayıcıları genellikle model sunma performansı için iki ölçüme önem verir: tek bir jeton oluşturmak için geçen süre ile tanımlanan gecikme ve üretilen jeton sayısıyla tanımlanan aktarım hızı. her saniye. Dağıtılan uç noktaya yapılan tek bir istek, yaklaşık olarak model gecikmesinin tersine eşit bir verim sergilese de, uç noktaya aynı anda birden fazla eşzamanlı isteğin gönderildiği durum mutlaka böyle değildir. Eşzamanlı isteklerin istemci tarafında sürekli olarak gruplanması gibi model sunma teknikleri nedeniyle gecikme ve aktarım hızı, model mimarisine, hizmet yapılandırmalarına, örnek tipi donanıma, eşzamanlı isteklerin sayısına ve giriş yüklerindeki değişikliklere bağlı olarak önemli ölçüde değişen karmaşık bir ilişkiye sahiptir. giriş jetonlarının ve çıkış jetonlarının sayısı olarak.
Bu gönderi, Llama 2, Falcon ve Mistral çeşitleri de dahil olmak üzere Amazon SageMaker JumpStart'ta bulunan LLM'lerin kapsamlı bir karşılaştırması yoluyla bu ilişkileri araştırıyor. SageMaker JumpStart ile makine öğrenimi uygulayıcıları, özel olarak dağıtılmak üzere halka açık temel modellerin geniş bir yelpazesi arasından seçim yapabilirler. Amazon Adaçayı Yapıcı ağdan yalıtılmış bir ortamdaki örnekler. Hızlandırıcı spesifikasyonlarının LLM kıyaslamasını nasıl etkilediğine dair teorik ilkeler sağlıyoruz. Ayrıca tek bir uç noktanın arkasında birden fazla örneğin dağıtılmasının etkisini de gösteriyoruz. Son olarak, SageMaker JumpStart dağıtım sürecini gecikme, verim, maliyet ve mevcut bulut sunucusu türlerindeki kısıtlamalarla ilgili gereksinimlerinize uygun hale getirecek şekilde uyarlamak için pratik öneriler sunuyoruz. Tüm kıyaslama sonuçları ve öneriler çok yönlü bir temele dayanmaktadır. defter kullanım durumunuza uyarlayabilirsiniz.
Dağıtılan uç nokta kıyaslaması
Aşağıdaki şekil, çeşitli model türleri ve bulut sunucusu türleri genelinde dağıtım yapılandırmaları için en düşük gecikme sürelerini (solda) ve en yüksek aktarım hızını (sağda) gösterir. Daha da önemlisi, bu model konuşlandırmalarının her biri, dağıtım için istenen model kimliği ve örnek türü göz önüne alındığında SageMaker JumpStart tarafından sağlanan varsayılan yapılandırmaları kullanır.
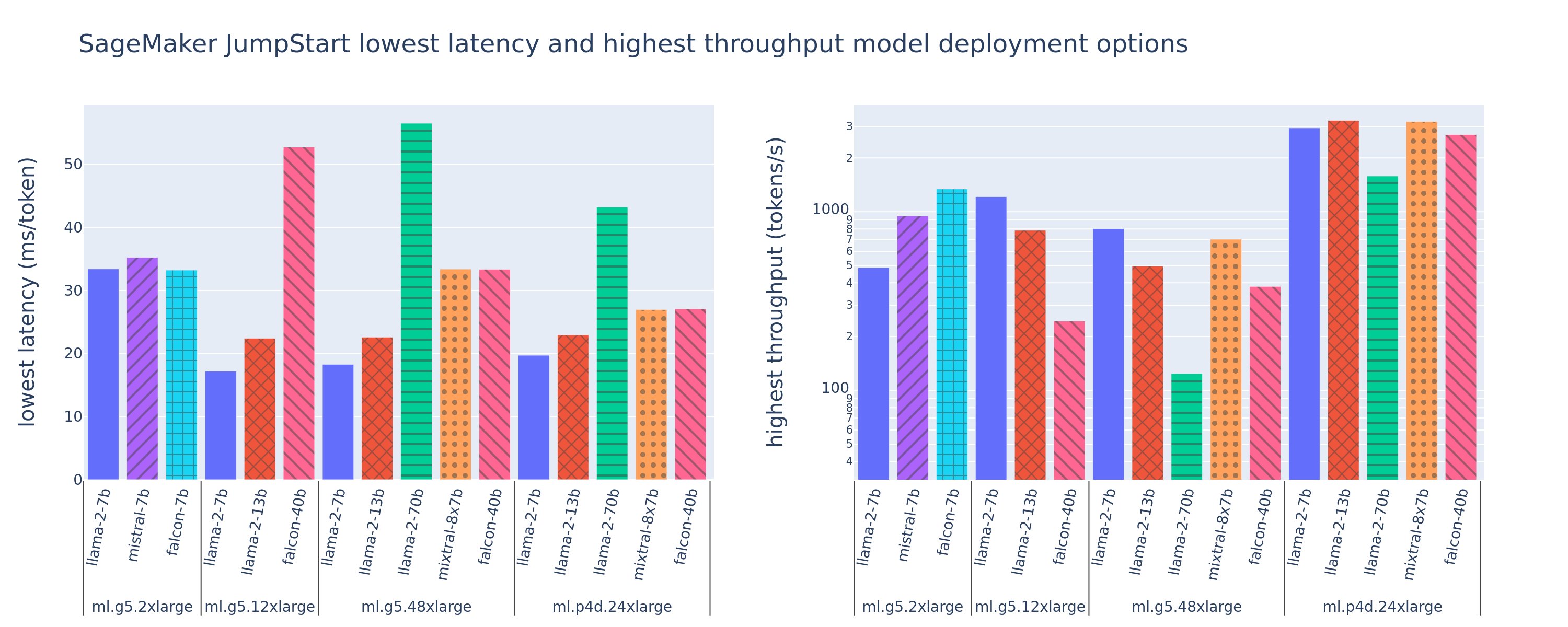
Bu gecikme ve aktarım hızı değerleri, 256 giriş jetonu ve 256 çıkış jetonu içeren yüklere karşılık gelir. En düşük gecikme süreli yapılandırma, tek bir eşzamanlı isteğe hizmet veren modeli sınırlar ve en yüksek aktarım hızı yapılandırması, olası eşzamanlı istek sayısını en üst düzeye çıkarır. Kıyaslamamızda görebileceğimiz gibi, eşzamanlı isteklerin artması verimi monoton bir şekilde artırırken, büyük eşzamanlı istekler için iyileştirmenin azalmasına neden olur. Ayrıca modeller desteklenen örnekte tamamen parçalanmıştır. Örneğin, ml.g5.48xlarge örneğinin 8 GPU'su olması nedeniyle, bu örneği kullanan tüm SageMaker JumpStart modelleri, mevcut sekiz hızlandırıcının tamamında tensör paralelliği kullanılarak parçalanır.
Bu rakamdan birkaç sonuç çıkarabiliriz. İlk olarak, tüm modeller tüm örneklerde desteklenmez; Falcon 7B gibi bazı küçük modeller model parçalamayı desteklemezken, daha büyük modeller daha yüksek bilgi işlem kaynağı gereksinimlerine sahiptir. İkincisi, parçalama arttıkça performans genellikle artar, ancak küçük modeller için mutlaka iyileşme olmayabilir. Bunun nedeni, 7B ve 13B gibi küçük modellerin, çok fazla hızlandırıcı arasında paylaştırıldığında önemli bir iletişim yüküne neden olmasıdır. Bunu daha sonra daha derinlemesine tartışacağız. Son olarak, ml.p4d.24xlarge bulut sunucuları, A100'ün A10G GPU'lara göre bellek bant genişliği iyileştirmeleri nedeniyle önemli ölçüde daha iyi aktarım hızına sahip olma eğilimindedir. Daha sonra tartışacağımız gibi, belirli bir bulut sunucusu tipini kullanma kararı, gecikme, aktarım hızı ve maliyet kısıtlamaları da dahil olmak üzere dağıtım gereksinimlerinize bağlıdır.
Bu en düşük gecikme süresi ve en yüksek aktarım hızı yapılandırma değerlerini nasıl elde edebilirsiniz? Aşağıdaki eğride görüldüğü gibi, 2 giriş tokenı ve 7 çıkış tokenı içeren bir veri yükü için bir ml.g5.12xlarge örneğindeki Llama 256 256B uç noktası için gecikme ve verim grafiğini çizerek başlayalım. Dağıtılan her LLM uç noktası için benzer bir eğri mevcuttur.

Eşzamanlılık arttıkça verim ve gecikme de monoton bir şekilde artar. Bu nedenle, en düşük gecikme noktası eşzamanlı istek değeri 1 olduğunda ortaya çıkar ve eşzamanlı istekleri artırarak sistem verimini uygun maliyetli bir şekilde artırabilirsiniz. Bu eğride belirgin bir "diz" vardır; burada ek eşzamanlılıkla ilişkili üretim kazanımlarının, gecikmedeki ilişkili artıştan daha ağır basmadığı açıktır. Bu dizin tam konumu kullanım durumuna özeldir; bazı uygulayıcılar dizini önceden belirlenmiş bir gecikme gereksiniminin aşıldığı noktada tanımlayabilir (örneğin, 100 ms/jeton), diğerleri ise yük testi kıyaslamalarını ve yarı gecikme kuralı gibi kuyruk teorisi yöntemlerini kullanabilir ve diğerleri bunu kullanabilir. teorik hızlandırıcı özellikleri.
Ayrıca maksimum eşzamanlı istek sayısının sınırlı olduğunu da not ediyoruz. Önceki şekilde hat izleme 192 eşzamanlı istekle bitiyor. Bu sınırlamanın kaynağı, SageMaker uç noktalarının 60 saniye sonra bir çağrı yanıtını zaman aşımına uğrattığı SageMaker çağrı zaman aşımı sınırıdır. Bu ayar hesaba özeldir ve tek bir uç nokta için yapılandırılamaz. LLM'ler için çok sayıda çıktı tokenı oluşturmak saniyeler, hatta dakikalar sürebilir. Bu nedenle, büyük giriş veya çıkış verileri, çağrı isteklerinin başarısız olmasına neden olabilir. Ayrıca, eşzamanlı isteklerin sayısı çok fazlaysa, birçok istekte uzun kuyruk süreleri yaşanacak ve bu da 60 saniyelik zaman aşımı sınırına neden olacaktır. Bu çalışmanın amacı doğrultusunda, bir model dağıtımı için mümkün olan maksimum verimi tanımlamak için zaman aşımı sınırını kullanıyoruz. Daha da önemlisi, bir SageMaker uç noktası çok sayıda eşzamanlı isteği bir çağrı yanıt zaman aşımı gözlemlemeden işleyebilse de, gecikme-verim eğrisindeki dizine göre maksimum eşzamanlı istekleri tanımlamak isteyebilirsiniz. Bu muhtemelen yatay ölçeklendirmeyi dikkate almaya başladığınız noktadır; burada tek bir uç nokta, model replikalarıyla birden fazla örneği tedarik eder ve daha eşzamanlı istekleri desteklemek için replikalar arasında gelen istekleri yük dengeler.
Bunu bir adım daha ileri götürerek, aşağıdaki tabloda Llama 2 7B modelinin farklı sayıdaki giriş ve çıkış belirteçleri, örnek türleri ve eşzamanlı istek sayısı dahil olmak üzere farklı yapılandırmalara ilişkin kıyaslama sonuçları yer almaktadır. Önceki şeklin bu tablonun yalnızca tek bir satırını çizdiğine dikkat edin.
| . | Verim (jeton/sn) | Gecikme (ms/jeton) | ||||||||||||||||||
| Eşzamanlı İstekler | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Toplam jeton sayısı: 512, Çıkış jetonu sayısı: 256 | ||||||||||||||||||||
| ml.g5.2xlarge | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xlarge | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xlarge | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xlarge | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Toplam jeton sayısı: 4096, Çıkış jetonu sayısı: 256 | ||||||||||||||||||||
| ml.g5.2xlarge | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xlarge | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xlarge | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xlarge | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
Bu verilerde bazı ek modeller gözlemliyoruz. Bağlam boyutu artırıldığında gecikme artar ve aktarım hızı azalır. Örneğin, eşzamanlılık 5.2 olan ml.g1xlarge'de, toplam token sayısı 30 olduğunda aktarım hızı 512 token/sn olurken, toplam token sayısı 20 olduğunda 4,096 token/sn olur. Bunun nedeni, daha büyük girdiyi işlemenin daha fazla zaman almasıdır. Ayrıca GPU kapasitesinin ve parçalamanın artırılmasının maksimum verimi ve desteklenen maksimum eşzamanlı istekleri etkilediğini de görebiliriz. Tablo, Llama 2 7B'nin farklı bulut sunucusu türleri için oldukça farklı maksimum verim değerlerine sahip olduğunu ve bu maksimum verim değerlerinin eşzamanlı isteklerin farklı değerlerinde meydana geldiğini göstermektedir. Bu özellikler, bir makine öğrenimi uygulayıcısını bir örneğin maliyetini diğerine göre haklı çıkarmaya yönlendirecektir. Örneğin, düşük gecikme gereksinimi göz önüne alındığında uygulayıcı, bir ml.g5.12xlarge örneği (4 A10G GPU) yerine bir ml.g5.2xlarge örneğini (1 A10G GPU) seçebilir. Yüksek bir aktarım hızı gereksinimi göz önüne alındığında, tam parçalamalı bir ml.p4d.24xlarge örneğinin (8 A100 GPU) kullanılması yalnızca yüksek eşzamanlılık durumunda haklı gösterilebilir. Bununla birlikte, bir 7B modelinin birden çok çıkarım bileşenini tek bir ml.p4d.24xlarge örneğine yüklemenin genellikle yararlı olduğunu unutmayın; bu tür çoklu model desteği bu yazının ilerleyen kısımlarında tartışılacaktır.
Önceki gözlemler Llama 2 7B modeli için yapılmıştır. Ancak benzer modeller diğer modeller için de geçerli. Temel çıkarımlardan biri, gecikme ve aktarım hızı performans rakamlarının veri yüküne, bulut sunucusu tipine ve eşzamanlı isteklerin sayısına bağlı olmasıdır; dolayısıyla özel uygulamanız için ideal yapılandırmayı bulmanız gerekecektir. Kullanım durumunuza yönelik önceki sayıları oluşturmak için bağlantılı defterModeliniz, bulut sunucusu tipiniz ve yükünüz için bu yük testi analizini yapılandırabileceğiniz yer.
Hızlandırıcı spesifikasyonlarını anlama
LLM çıkarımı için uygun donanımın seçilmesi büyük ölçüde belirli kullanım senaryolarına, kullanıcı deneyimi hedeflerine ve seçilen LLM'ye bağlıdır. Bu bölüm, hızlandırıcı spesifikasyonlarına dayanan yüksek düzey ilkelere göre gecikme-geçiş eğrisindeki dizin anlaşılmasını sağlamaya çalışmaktadır. Bu ilkeler tek başına karar vermek için yeterli değildir; gerçek ölçütler gereklidir. Dönem cihaz burada tüm ML donanım hızlandırıcılarını kapsayacak şekilde kullanılır. Gecikme-çıktı eğrisindeki dizinin iki faktörden biri tarafından yönlendirildiğini ileri sürüyoruz:
- Hızlandırıcı, KV matrislerini önbelleğe almak için belleği tükettiğinden sonraki istekler sıraya alınır
- Hızlandırıcının KV önbelleği için hala yedek belleği var, ancak işlem süresinin bellek bant genişliği yerine hesaplama işlemi gecikmesi tarafından yönlendirilmesini sağlayacak kadar büyük bir toplu iş boyutu kullanıyor
Genellikle ikinci faktörle sınırlı kalmayı tercih ederiz çünkü bu, hızlandırıcı kaynaklarının doymuş olduğu anlamına gelir. Temel olarak, ödediğiniz kaynakları maksimuma çıkarıyorsunuz. Bu iddiayı daha ayrıntılı olarak inceleyelim.
KV önbelleğe alma ve cihaz belleği
Standart transformatör dikkat mekanizmaları, her yeni jeton için dikkati önceki tüm jetonlara göre hesaplar. Çoğu modern ML sunucusu, her adımda yeniden hesaplamayı önlemek için dikkat anahtarlarını ve değerlerini cihaz belleğinde (DRAM) önbelleğe alır. Buna buna denir KV önbelleğive toplu iş boyutu ve sıra uzunluğu ile birlikte büyür. Kaç kullanıcı isteğinin paralel olarak sunulabileceğini tanımlar ve daha önce bahsedilen ikinci senaryodaki hesaplamaya bağlı rejimin mevcut DRAM göz önüne alındığında henüz karşılanmaması durumunda gecikme-verim eğrisindeki dizini belirler. Aşağıdaki formül, maksimum KV önbellek boyutu için kaba bir yaklaşımdır.

Bu formülde B parti büyüklüğü, N ise hızlandırıcı sayısıdır. Örneğin, bir A2G GPU'da (7 GB DRAM) sunulan FP16'daki Llama 2 10B modeli (24 bayt/parametre), yaklaşık 14 GB tüketir ve KV önbelleği için 10 GB bırakır. Modelin tam bağlam uzunluğunu (N = 4096) ve kalan parametreleri (n_layers=32, n_kv_attention_heads=32 ve d_attention_head=128) taktığımızda, bu ifade, DRAM kısıtlamaları nedeniyle paralel olarak dört kullanıcıdan oluşan bir toplu iş boyutuna hizmet vermeyle sınırlı olduğumuzu gösterir. . Önceki tabloda karşılık gelen kıyaslamaları gözlemlerseniz, bu, bu gecikme-geçiş eğrisinde gözlemlenen diz için iyi bir yaklaşımdır. Gibi yöntemler gruplandırılmış sorgu dikkati (GQA), KV önbellek boyutunu azaltabilir; GQA durumunda, aynı faktörle KV kafalarının sayısını azaltır.
Aritmetik yoğunluk ve cihaz hafıza bant genişliği
ML hızlandırıcılarının hesaplama gücündeki artış, bellek bant genişliklerini geride bıraktı; bu da, her veri baytı üzerinde, o bayta erişmek için gereken süre boyunca çok daha fazla hesaplama gerçekleştirebilecekleri anlamına geliyor.
The aritmetik yoğunlukveya bir işlem için hesaplama işlemlerinin bellek erişimlerine oranı, işlemin seçilen donanımdaki bellek bant genişliği veya işlem kapasitesi ile sınırlı olup olmadığını belirler. Örneğin, 10 TFLOPS FP5 ve 70 GB/sn bant genişliğine sahip bir A16G GPU (g600 bulut sunucusu tipi ailesi), yaklaşık 116 işlem/bayt hesaplama yapabilir. Bir A100 GPU (p4d bulut sunucusu tipi ailesi) yaklaşık 208 işlem/bayt hesaplama yapabilir. Bir transformatör modelinin aritmetik yoğunluğu bu değerin altındaysa belleğe bağlıdır; yukarıdaysa, hesaplamaya bağlıdır. Llama 2 7B'nin dikkat mekanizması, toplu iş boyutu 62 için 1 işlem/bayt gerektirir (açıklama için bkz. LLM çıkarımı ve performansına yönelik bir rehber), bu da belleğe bağlı olduğu anlamına gelir. Dikkat mekanizması belleğe bağlı olduğunda pahalı FLOPS kullanılmaz hale gelir.
Hızlandırıcıyı daha iyi kullanmanın ve aritmetik yoğunluğu artırmanın iki yolu vardır: işlem için gerekli bellek erişimlerini azaltmak (bu, FlashDikkat odaklanır) veya toplu iş boyutunu artırır. Ancak DRAM'imiz karşılık gelen KV önbelleğini tutamayacak kadar küçükse, toplu iş boyutumuzu hesaplamaya bağlı bir rejime ulaşacak kadar artıramayabiliriz. Standart GPT kod çözücü çıkarımı için hesaplamaya bağlı rejimleri belleğe bağlı rejimlerden ayıran kritik toplu iş boyutu B*'nin kaba bir yaklaşımı aşağıdaki ifadeyle açıklanmaktadır; burada A_mb, hızlandırıcı bellek bant genişliğidir, A_f, hızlandırıcı FLOPS'tur ve N, sayıdır hızlandırıcılar. Bu kritik toplu iş boyutu, bellek erişim süresinin hesaplama süresine eşit olduğu noktanın bulunmasıyla elde edilebilir. Bakınız Bu blog yazısı Denklem 2'yi ve varsayımlarını daha ayrıntılı olarak anlamak.
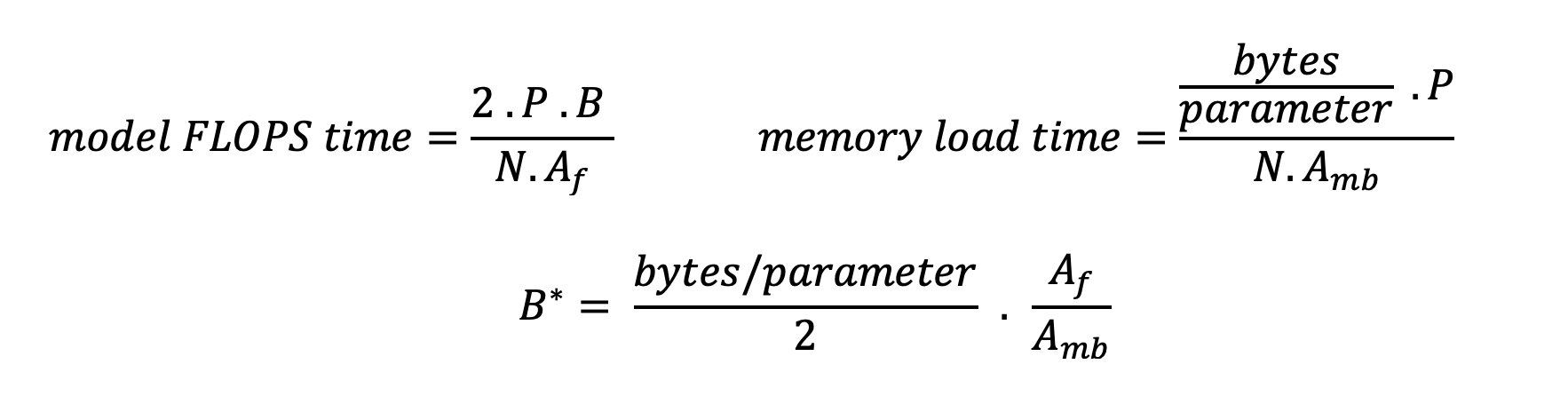
Bu, daha önce A10G için hesapladığımız işlem/bayt oranının aynısıdır, dolayısıyla bu GPU'daki kritik toplu iş boyutu 116'dır. Bu teorik, kritik toplu iş boyutuna yaklaşmanın bir yolu, model parçalamayı artırmak ve önbelleği daha fazla N hızlandırıcıya bölmektir. Bu, KV önbellek kapasitesinin yanı sıra belleğe bağlı toplu iş boyutunu da etkili bir şekilde artırır.
Model parçalamanın bir diğer yararı da model parametresini ve veri yükleme işini N hızlandırıcılara bölmektir. Bu parçalama türü, aynı zamanda şu şekilde de adlandırılan bir model paralelliği türüdür: tensör paralelliği. Saf bir şekilde, toplamda bellek bant genişliğinin ve hesaplama gücünün N katı vardır. Herhangi bir ek yükün (iletişim, yazılım vb.) bulunmadığını varsayarsak, belleğe bağlıysak bu, jeton başına kod çözme gecikmesini N kadar azaltır, çünkü bu rejimdeki jeton kod çözme gecikmesi, modeli yüklemek için gereken süreye bağlıdır. ağırlıklar ve önbellek. Ancak gerçek hayatta parçalama derecesinin arttırılması, her model katmanında ara aktivasyonların paylaşılması için cihazlar arasındaki iletişimin artmasına neden olur. Bu iletişim hızı, cihazın ara bağlantı bant genişliği ile sınırlıdır. Etkisini tam olarak tahmin etmek zordur (ayrıntılar için bkz. Model paralellik), ancak bu sonuçta fayda sağlamayı durdurabilir veya performansı düşürebilir; bu özellikle küçük modeller için geçerlidir çünkü daha küçük veri aktarımları daha düşük aktarım hızlarına yol açar.
ML hızlandırıcılarını özelliklerine göre karşılaştırmak için aşağıdakileri öneririz. İlk olarak, ikinci denkleme göre her bir hızlandırıcı türü için yaklaşık kritik parti boyutunu ve birinci denkleme göre kritik parti büyüklüğü için KV önbellek boyutunu hesaplayın. Daha sonra, KV önbelleğine ve model parametrelerine uyacak minimum hızlandırıcı sayısını hesaplamak için hızlandırıcıdaki mevcut DRAM'i kullanabilirsiniz. Birden fazla hızlandırıcı arasında karar verirseniz, hızlandırıcılara GB/sn bellek bant genişliği başına en düşük maliyete göre öncelik verin. Son olarak, bu yapılandırmaları karşılaştırın ve istediğiniz gecikmenin üst sınırı için en iyi maliyet/belirtecin ne olduğunu doğrulayın.
Bir uç nokta dağıtım yapılandırması seçin
SageMaker JumpStart tarafından dağıtılan birçok LLM, metin oluşturma çıkarımı (TGI) SageMaker kabı model sunumu için. Aşağıdaki tabloda, gecikme-iş hacmi eğrisini etkileyen model hizmetini etkilemek veya uç noktayı aşırı yükleyecek isteklere karşı uç noktayı korumak için çeşitli model sunma parametrelerinin nasıl ayarlanacağı açıklanmaktadır. Bunlar, kullanım durumunuza göre uç nokta dağıtımınızı yapılandırmak için kullanabileceğiniz birincil parametrelerdir. Aksi belirtilmedikçe varsayılanı kullanırız metin oluşturma verisi parametreleri ve TGI ortam değişkenleri.
| Çevre değişkeni | Açıklama | SageMaker JumpStart Varsayılan Değeri |
| Model sunma yapılandırmaları | . | . |
MAX_BATCH_PREFILL_TOKENS |
Ön doldurma işlemindeki jeton sayısını sınırlar. Bu işlem, yeni bir giriş istemi dizisi için KV önbelleğini oluşturur. Bellek yoğundur ve hesaplamaya bağlıdır, dolayısıyla bu değer, tek bir ön doldurma işleminde izin verilen belirteç sayısını sınırlar. Diğer sorgulara ilişkin kod çözme adımları, önceden doldurma işlemi sırasında duraklatılır. | 4096 (varsayılan TGI) veya modele özgü maksimum desteklenen içerik uzunluğu (SageMaker JumpStart sağlanmıştır), hangisi daha büyükse. |
MAX_BATCH_TOTAL_TOKENS |
Kod çözme sırasında bir gruba dahil edilecek maksimum belirteç sayısını veya modelden tek bir ileri geçişi kontrol eder. İdeal olarak bu, mevcut tüm donanımların kullanımını en üst düzeye çıkaracak şekilde ayarlanmıştır. | Belirtilmedi (TGI varsayılanı). TGI, modelin ısınması sırasında kalan CUDA belleğine göre bu değeri ayarlayacaktır. |
SM_NUM_GPUS |
Kullanılacak parça sayısı. Yani modeli tensör paralelliği kullanarak çalıştırmak için kullanılan GPU sayısı. | Örneğe bağımlı (SageMaker JumpStart sağlanır). Belirli bir model için desteklenen her örnek için SageMaker JumpStart, tensör paralelliği için en iyi ayarı sağlar. |
| Uç noktanızı korumaya yönelik yapılandırmalar (bunları kullanım durumunuz için ayarlayın) | . | . |
MAX_TOTAL_TOKENS |
Bu, giriş dizisindeki belirteçlerin sayısını ve çıktı dizisindeki belirteçlerin sayısını sınırlayarak tek bir istemci isteğinin bellek bütçesini sınırlar ( max_new_tokens yük parametresi). |
Modele özgü maksimum desteklenen bağlam uzunluğu. Örneğin Lama 4096 için 2. |
MAX_INPUT_LENGTH |
Tek bir istemci isteği için giriş sırasında izin verilen maksimum belirteç sayısını tanımlar. Bu değeri artırırken göz önünde bulundurulması gereken noktalar şunlardır: daha uzun giriş dizileri daha fazla bellek gerektirir, bu da sürekli toplu işlemi etkiler ve çoğu modelde aşılmaması gereken desteklenen bir bağlam uzunluğu bulunur. | Modele özgü maksimum desteklenen bağlam uzunluğu. Örneğin Lama 4095 için 2. |
MAX_CONCURRENT_REQUESTS |
Dağıtılan uç nokta tarafından izin verilen maksimum eşzamanlı istek sayısı. Bu sınırı aşan yeni istekler, mevcut işleme istekleri için düşük gecikmeyi önlemek amacıyla hemen bir model aşırı yükleme hatasına yol açacaktır. | 128 (TGI varsayılanı). Bu ayar, çeşitli kullanım durumları için yüksek verim elde etmenize olanak tanır, ancak SageMaker başlatma zaman aşımı hatalarını azaltmak için uygun şekilde sabitlemelisiniz. |
TGI sunucusu, tek bir model çıkarımı ileri geçişini paylaşmak için eşzamanlı istekleri dinamik olarak bir araya toplayan sürekli toplu işlemeyi kullanır. İki tür ileri geçiş vardır: önceden doldurma ve kod çözme. Her yeni isteğin, giriş sırası belirteçleri için KV önbelleğini doldurmak amacıyla tek bir ön doldurma ileri geçişi çalıştırması gerekir. KV önbelleği doldurulduktan sonra, kod çözme ileri geçişi, tüm toplu istekler için tek bir sonraki belirteç tahminini gerçekleştirir ve bu, çıktı dizisini oluşturmak için yinelemeli olarak tekrarlanır. Sunucuya yeni istekler gönderildikçe, ön doldurma adımının yeni istekler için çalışabilmesi için bir sonraki kod çözme adımının beklemesi gerekir. Bu yeni isteklerin sonraki sürekli toplu kod çözme adımlarına dahil edilmesinden önce bunun gerçekleşmesi gerekir. Donanım kısıtlamaları nedeniyle kod çözme için kullanılan sürekli toplu işlem, tüm istekleri içermeyebilir. Bu noktada, istekler bir işleme kuyruğuna girer ve çıkarım gecikmesi yalnızca küçük bir verim artışıyla önemli ölçüde artmaya başlar.
LLM gecikme kıyaslama analizlerini ön doldurma gecikmesi, kod çözme gecikmesi ve kuyruk gecikmesi olarak ayırmak mümkündür. Bu bileşenlerin her biri tarafından tüketilen süre, doğası gereği temel olarak farklıdır: ön doldurma tek seferlik bir hesaplamadır, kod çözme, çıktı sırasındaki her belirteç için bir kez gerçekleşir ve sıraya alma, sunucu toplu işlem süreçlerini içerir. Birden fazla eşzamanlı istek işlendiğinde, bu bileşenlerin her birinden gecikmeleri ayırmak zorlaşır çünkü herhangi bir istemci isteğinin yaşadığı gecikme, yeni eşzamanlı isteklerin önceden doldurulması ihtiyacından kaynaklanan kuyruk gecikmelerinin yanı sıra dahil edilmenin yol açtığı kuyruk gecikmelerini de içerir. Toplu kod çözme işlemlerinde isteğin. Bu nedenle bu yazı uçtan uca işleme gecikmesine odaklanıyor. Gecikme-verim eğrisindeki diz, kuyruk gecikmelerinin önemli ölçüde artmaya başladığı doyma noktasında meydana gelir. Bu olay herhangi bir model çıkarım sunucusunda meydana gelir ve hızlandırıcı belirtimleri tarafından yönlendirilir.
Dağıtım sırasındaki ortak gereksinimler arasında gerekli minimum aktarım hızının, izin verilen maksimum gecikme süresinin, saat başına maksimum maliyetin ve 1 milyon jeton oluşturmanın maksimum maliyetinin karşılanması yer alır. Bu gereksinimleri, son kullanıcı isteklerini temsil eden yüklere göre koşullandırmalısınız. Bu gereksinimleri karşılayacak bir tasarım, belirli model mimarisi, modelin boyutu, örnek türleri ve örnek sayısı (yatay ölçeklendirme) dahil olmak üzere birçok faktörü dikkate almalıdır. Aşağıdaki bölümlerde gecikmeyi en aza indirmek, verimi en üst düzeye çıkarmak ve maliyeti en aza indirmek için uç noktaların dağıtımına odaklanıyoruz. Bu analizde toplam 512 token ve 256 çıktı tokeni dikkate alınır.
Gecikmeyi en aza indirin
Gecikme, birçok gerçek zamanlı kullanım durumunda önemli bir gerekliliktir. Aşağıdaki tabloda her model ve her bulut sunucusu türü için minimum gecikmeyi inceliyoruz. Ayarlayarak minimum gecikmeyi elde edebilirsiniz. MAX_CONCURRENT_REQUESTS = 1.
| Minimum Gecikme (ms/jeton) | |||||
| Model numarası | ml.g5.2xlarge | ml.g5.12xlarge | ml.g5.48xlarge | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Lama 2 7B | 33 | 17 | 18 | 20 | - |
| Lama 2 7B Sohbet | 33 | 17 | 18 | 20 | - |
| Lama 2 13B | - | 22 | 23 | 23 | - |
| Lama 2 13B Sohbet | - | 23 | 23 | 23 | - |
| Lama 2 70B | - | - | 57 | 43 | - |
| Lama 2 70B Sohbet | - | - | 57 | 45 | - |
| Mistral 7B | 35 | - | - | - | - |
| Mistral 7B Talimatı | 35 | - | - | - | - |
| Karışım 8x7B | - | - | 33 | 27 | - |
| Şahin 7B | 33 | - | - | - | - |
| Falcon 7B Talimatı | 33 | - | - | - | - |
| Şahin 40B | - | 53 | 33 | 27 | - |
| Falcon 40B Talimatı | - | 53 | 33 | 28 | - |
| Şahin 180B | - | - | - | - | 42 |
| Falcon 180B Sohbeti | - | - | - | - | 42 |
Bir model için minimum gecikmeyi elde etmek amacıyla istediğiniz model kimliğini ve örnek türünü değiştirirken aşağıdaki kodu kullanabilirsiniz:
Gecikme sayılarının giriş ve çıkış jetonlarının sayısına bağlı olarak değiştiğini unutmayın. Ancak dağıtım süreci, ortam değişkenleri dışında aynı kalır MAX_INPUT_TOKENS ve MAX_TOTAL_TOKENS. Burada, bu ortam değişkenleri uç nokta gecikme gereksinimlerini garanti etmeye yardımcı olacak şekilde ayarlanmıştır çünkü daha büyük giriş dizileri gecikme gereksinimini ihlal edebilir. Örnek türünü seçerken SageMaker JumpStart'ın diğer optimum ortam değişkenlerini zaten sağladığını unutmayın; örneğin ml.g5.12xlarge kullanıldığında, SM_NUM_GPUS Model ortamında 4'e.
Verimi en üst düzeye çıkarın
Bu bölümde saniyede üretilen token sayısını maksimuma çıkarıyoruz. Bu genellikle model ve örnek türü için maksimum geçerli eşzamanlı isteklerde elde edilir. Aşağıdaki tabloda, herhangi bir istek için SageMaker çağrı zaman aşımı ile karşılaşmadan önce elde edilen en büyük eşzamanlı istek değerinde elde edilen verimi rapor ediyoruz.
| Maksimum Verim (jeton/sn), Eşzamanlı İstekler | |||||
| Model numarası | ml.g5.2xlarge | ml.g5.12xlarge | ml.g5.48xlarge | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Lama 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Lama 2 7B Sohbet | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Lama 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Lama 2 13B Sohbet | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Lama 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Lama 2 70B Sohbet | - | - | 114 (16) | 1546 (256) | - |
| Mistral 7B | 947 (64) | - | - | - | - |
| Mistral 7B Talimatı | 986 (128) | - | - | - | - |
| Karışım 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Şahin 7B | 1340 (128) | - | - | - | - |
| Falcon 7B Talimatı | 1313 (128) | - | - | - | - |
| Şahin 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Falcon 40B Talimatı | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Şahin 180B | - | - | - | - | 1100 (128) |
| Falcon 180B Sohbeti | - | - | - | - | 1081 (128) |
Bir model için maksimum verimi elde etmek için aşağıdaki kodu kullanabilirsiniz:
Maksimum eşzamanlı istek sayısının model türüne, örnek tipine, maksimum giriş jetonu sayısına ve maksimum çıkış jetonu sayısına bağlı olduğunu unutmayın. Bu nedenle, ayarlamadan önce bu parametreleri ayarlamanız gerekir. MAX_CONCURRENT_REQUESTS.
Ayrıca, gecikmeyi en aza indirmekle ilgilenen bir kullanıcının, verimi en üst düzeye çıkarmakla ilgilenen bir kullanıcıyla genellikle anlaşmazlığa düştüğünü unutmayın. İlki gerçek zamanlı yanıtlarla ilgilenirken ikincisi, uç nokta kuyruğunun her zaman doymuş olmasını sağlayacak şekilde toplu işlemeyle ilgilenir ve böylece işlem aksama süresini en aza indirir. Gecikme gereksinimlerine bağlı olarak verimi en üst düzeye çıkarmak isteyen kullanıcılar genellikle gecikme-verim eğrisinde diz üstü çalışmakla ilgilenirler.
Maliyeti en aza indirin
Maliyeti en aza indirmenin ilk seçeneği, saat başına maliyeti en aza indirmeyi içerir. Bununla, seçilen bir modeli SageMaker örneğinde saat başına en düşük maliyetle dağıtabilirsiniz. SageMaker örneklerinin gerçek zamanlı fiyatlandırması için bkz. Amazon SageMaker fiyatlandırması. Genel olarak SageMaker JumpStart LLM'ler için varsayılan bulut sunucusu tipi en düşük maliyetli dağıtım seçeneğidir.
Maliyeti en aza indirmenin ikinci seçeneği, 1 milyon token üretme maliyetini en aza indirmeyi içerir. Bu, verimi en üst düzeye çıkarmak için daha önce tartıştığımız tablonun basit bir dönüşümüdür; burada ilk önce 1 milyon token (1e6 / verim / 3600) üretmek için gereken süreyi saat cinsinden hesaplayabilirsiniz. Daha sonra bu süreyi, belirtilen SageMaker örneğinin saat başına fiyatıyla 1 milyon jeton oluşturmak için çarpabilirsiniz.
Saat başına en düşük maliyete sahip bulut sunucularının, 1 milyon jeton üretme maliyeti en düşük olan bulut sunucularıyla aynı olmadığını unutmayın. Örneğin, çağırma istekleri düzensizse saat başına en düşük maliyete sahip bir örnek en uygun olabilirken, azaltma senaryolarında bir milyon jeton oluşturmanın en düşük maliyeti daha uygun olabilir.
Tensör paraleli ve çoklu model değişimi
Önceki analizlerin tümünde, dağıtım bulut sunucusu tipindeki GPU sayısına eşit tensör paralel derecesine sahip tek bir model kopyası dağıtmayı düşündük. Bu, varsayılan SageMaker JumpStart davranışıdır. Bununla birlikte, daha önce belirtildiği gibi, bir modelin parçalanması, model gecikmesini ve verimini yalnızca belirli bir sınıra kadar artırabilir; bu sınırın ötesinde, cihazlar arası iletişim gereksinimleri hesaplama süresine hakim olur. Bu, daha yüksek tensör paralel derecesine sahip tek bir model yerine, tek bir örnekte daha düşük tensör paralel derecesine sahip birden fazla modelin dağıtılmasının genellikle faydalı olduğu anlamına gelir.
Burada Llama 2, 7B ve 13B uç noktalarını tensör paralel (TP) dereceleri 4, 24, 1 ve 2 olan ml.p4d.8xlarge örneklerine yerleştiriyoruz. Model davranışında netlik sağlamak için bu uç noktaların her biri yalnızca tek bir model yükler.
| . | Verim (jeton/sn) | Gecikme (ms/jeton) | ||||||||||||||||||
| Eşzamanlı İstekler | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| TP Derecesi | Lama 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Lama 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Önceki analizlerimiz zaten ml.p4d.24xlarge bulut sunucularında önemli aktarım hızı avantajları göstermişti; bu da genellikle yüksek eşzamanlı istek yükü koşulları altında g1 bulut sunucusu ailesi üzerinden 5 milyon token üretmenin maliyeti açısından daha iyi performans anlamına geliyor. Bu analiz, tek bir örnekte model parçalama ile model çoğaltma arasındaki dengeyi dikkate almanız gerektiğini açıkça göstermektedir; yani tamamen parçalanmış bir model, genellikle 4B ve 24B model aileleri için ml.p7d.13xlarge bilgi işlem kaynaklarının en iyi kullanımı değildir. Aslında 7B model ailesi için, tensör paralel derecesi 4 yerine 8 olan tek bir model kopyası için en iyi verimi elde edersiniz.
Buradan, 7B modeli için en yüksek üretim konfigürasyonunun, sekiz model kopyası ile tensör paralel derecesi 1'i içerdiğini ve 13B modeli için en yüksek üretim konfigürasyonunun muhtemelen dört model kopyası ile tensör paralel derecesi 2 olduğunu tahmin edebilirsiniz. Bunun nasıl gerçekleştirileceği hakkında daha fazla bilgi edinmek için bkz. Amazon SageMaker'ın en yeni özelliklerini kullanarak model dağıtım maliyetlerini ortalama %50 azaltınÇıkarım bileşeni tabanlı uç noktaların kullanımını gösteren. Yük dengeleme teknikleri, sunucu yönlendirmesi ve CPU kaynaklarının paylaşımı nedeniyle, kopya sayısı ile tek bir kopyanın aktarım hızı çarpımına tam olarak eşit olan aktarım hızı iyileştirmelerini tam olarak elde edemeyebilirsiniz.
yatay ölçekleme
Daha önce gözlemlendiği gibi, her uç nokta dağıtımının, giriş ve çıkış jetonlarının yanı sıra örnek tipine bağlı olarak eşzamanlı isteklerin sayısında bir sınırlaması vardır. Bu, aktarım hızı veya eşzamanlı istek gereksinimlerinizi karşılamıyorsa, dağıtılan uç noktanın arkasında birden fazla örnekten yararlanmak için ölçeği artırabilirsiniz. SageMaker, örnekler arasında sorguların yük dengelemesini otomatik olarak gerçekleştirir. Örneğin, aşağıdaki kod üç örnek tarafından desteklenen bir uç noktayı dağıtır:
Aşağıdaki tablo, Llama 2 7B modeli için örnek sayısı faktörü olarak üretim kazancını göstermektedir.
| . | . | Verim (jeton/sn) | Gecikme (ms/jeton) | ||||||||||||||
| . | Eşzamanlı İstekler | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Örnek Sayısı | Örnek Türü | Toplam jeton sayısı: 512, Çıkış jetonu sayısı: 256 | |||||||||||||||
| 1 | ml.g5.2xlarge | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xlarge | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xlarge | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Özellikle gecikme-verim eğrisindeki diz sağa kayar çünkü daha yüksek örnek sayıları, çoklu örnek uç noktası içindeki daha fazla sayıda eşzamanlı isteği işleyebilir. Bu tablo için eşzamanlı istek değeri, her bir örneğin aldığı eşzamanlı isteklerin sayısı değil, uç noktanın tamamı içindir.
Ayrıca iş yüklerinizi izlemeye ve kapasiteyi dinamik olarak ayarlayarak istikrarlı ve öngörülebilir performansı mümkün olan en düşük maliyetle sürdürmeye yönelik bir özellik olan otomatik ölçeklendirmeyi de kullanabilirsiniz. Bu, bu yazının kapsamı dışındadır. Otomatik ölçeklendirme hakkında daha fazla bilgi edinmek için bkz. Amazon SageMaker'da otomatik ölçeklendirme çıkarım uç noktalarını yapılandırma.
Eşzamanlı isteklerle uç noktayı çağırma
Yüksek aktarım hızı koşulları altında konuşlandırılmış bir modelden yanıtlar oluşturmak için kullanmak istediğiniz büyük miktarda sorgunuzun olduğunu varsayalım. Örneğin, aşağıdaki kod bloğunda, her bir payload 1,000 token oluşturulmasını talep eden 100 payload'un bir listesini derliyoruz. Toplamda 100,000 token üretilmesini talep ediyoruz.
SageMaker çalışma zamanı API'sine çok sayıda istek gönderirken kısıtlama hatalarıyla karşılaşabilirsiniz. Bunu azaltmak için yeniden deneme denemelerinin sayısını artıran özel bir SageMaker çalışma zamanı istemcisi oluşturabilirsiniz. Ortaya çıkan SageMaker oturum nesnesini şunlardan birine sağlayabilirsiniz: JumpStartModel yapıcı veya sagemaker.predictor.retrieve_default Zaten konuşlandırılmış bir uç noktaya yeni bir tahminci eklemek istiyorsanız. Aşağıdaki kodda, bir Llama 2 modelini varsayılan SageMaker JumpStart yapılandırmalarıyla dağıtırken bu oturum nesnesini kullanıyoruz:
Bu dağıtılan uç noktanın MAX_CONCURRENT_REQUESTS = 128 varsayılan olarak. Aşağıdaki blokta, 128 çalışan iş parçacığına sahip tüm veriler için uç noktanın çağrılması üzerinde yineleme yapmak amacıyla eşzamanlı vadeli işlemler kitaplığını kullanıyoruz. Uç nokta en fazla 128 eşzamanlı isteği işleyecektir ve bir istek yanıt verdiğinde, yürütücü uç noktaya hemen yeni bir istek gönderecektir.
Bu, tek bir ml.g100,000xlarge örneğinde 1255 jeton/sn'lik bir aktarım hızıyla toplam 5.2 jetonun üretilmesiyle sonuçlanır. Bunun işlenmesi yaklaşık 80 saniye sürer.
Bu aktarım hızı değerinin, bu gönderinin önceki tablolarında ml.g2xlarge üzerinde Llama 7 5.2B için maksimum aktarım hızından önemli ölçüde farklı olduğunu unutmayın (486 eşzamanlı istekte 64 jeton/sn). Bunun nedeni, giriş yükünün 8 yerine 256 jeton kullanması, çıkış jeton sayısının 100 yerine 256 olması ve daha küçük jeton sayımlarının 128 eşzamanlı isteğe izin vermesidir. Bu, tüm gecikme ve üretim rakamlarının veri yüküne bağlı olduğuna dair son bir hatırlatmadır! Yük jetonu sayılarının değiştirilmesi, model sunumu sırasında toplu işlem süreçlerini etkileyecektir ve bu da uygulamanız için ortaya çıkan ön doldurma, kod çözme ve kuyruk sürelerini etkileyecektir.
Sonuç
Bu yazıda Llama 2, Mistral ve Falcon dahil SageMaker JumpStart LLM'lerin kıyaslamasını sunduk. Ayrıca uç nokta dağıtım yapılandırmanız için gecikmeyi, verimi ve maliyeti optimize etmeye yönelik bir kılavuz da sunduk. Çalıştırarak başlayabilirsiniz ilişkili not defteri kullanım durumunuzu kıyaslamak için.
Yazarlar Hakkında
 Doktor Kyle Ulrich Amazon SageMaker JumpStart ekibinde bir Uygulamalı Bilim Adamıdır. Araştırma ilgi alanları arasında ölçeklenebilir makine öğrenimi algoritmaları, bilgisayar görüşü, zaman serileri, Bayes parametrik olmayanları ve Gauss süreçleri yer alır. Doktorası Duke Üniversitesi'ndendir ve NeurIPS, Cell ve Neuron'da yayınlanmış makaleleri vardır.
Doktor Kyle Ulrich Amazon SageMaker JumpStart ekibinde bir Uygulamalı Bilim Adamıdır. Araştırma ilgi alanları arasında ölçeklenebilir makine öğrenimi algoritmaları, bilgisayar görüşü, zaman serileri, Bayes parametrik olmayanları ve Gauss süreçleri yer alır. Doktorası Duke Üniversitesi'ndendir ve NeurIPS, Cell ve Neuron'da yayınlanmış makaleleri vardır.
 Dr. Vivek Madan Amazon SageMaker JumpStart ekibinde Uygulamalı Bilim Adamıdır. Doktorasını Urbana-Champaign'deki Illinois Üniversitesi'nden aldı ve Georgia Tech'de Doktora Sonrası Araştırmacıydı. Makine öğrenimi ve algoritma tasarımında aktif bir araştırmacıdır ve EMNLP, ICLR, COLT, FOCS ve SODA konferanslarında makaleler yayınlamıştır.
Dr. Vivek Madan Amazon SageMaker JumpStart ekibinde Uygulamalı Bilim Adamıdır. Doktorasını Urbana-Champaign'deki Illinois Üniversitesi'nden aldı ve Georgia Tech'de Doktora Sonrası Araştırmacıydı. Makine öğrenimi ve algoritma tasarımında aktif bir araştırmacıdır ve EMNLP, ICLR, COLT, FOCS ve SODA konferanslarında makaleler yayınlamıştır.
 Ashish Khetan Amazon SageMaker JumpStart'ta Kıdemli Uygulamalı Bilim Adamıdır ve makine öğrenimi algoritmalarının geliştirilmesine yardımcı olur. Doktora derecesini University of Illinois Urbana-Champaign'den almıştır. Makine öğrenimi ve istatistiksel çıkarım alanlarında aktif bir araştırmacıdır ve NeurIPS, ICML, ICLR, JMLR, ACL ve EMNLP konferanslarında birçok makale yayınlamıştır.
Ashish Khetan Amazon SageMaker JumpStart'ta Kıdemli Uygulamalı Bilim Adamıdır ve makine öğrenimi algoritmalarının geliştirilmesine yardımcı olur. Doktora derecesini University of Illinois Urbana-Champaign'den almıştır. Makine öğrenimi ve istatistiksel çıkarım alanlarında aktif bir araştırmacıdır ve NeurIPS, ICML, ICLR, JMLR, ACL ve EMNLP konferanslarında birçok makale yayınlamıştır.
 Joao Moura AWS'de Kıdemli AI/ML Uzman Çözüm Mimarıdır. João, küçük girişimlerden büyük kuruluşlara kadar AWS müşterilerinin büyük modelleri verimli bir şekilde eğitip dağıtmalarına ve AWS üzerinde daha geniş kapsamlı makine öğrenimi platformları oluşturmalarına yardımcı oluyor.
Joao Moura AWS'de Kıdemli AI/ML Uzman Çözüm Mimarıdır. João, küçük girişimlerden büyük kuruluşlara kadar AWS müşterilerinin büyük modelleri verimli bir şekilde eğitip dağıtmalarına ve AWS üzerinde daha geniş kapsamlı makine öğrenimi platformları oluşturmalarına yardımcı oluyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/

