Bu, Meta'nın PyTorch ekibiyle birlikte yazılan bir misafir yazısıdır ve Bölüm 1 PyTorch 2.0'ı AWS'de çalıştırmanın performansını ve kolaylığını gösterdiğimiz bu serinin.
Makine öğrenimi (ML) araştırması, önemli ölçüde büyük veri kümeleriyle eğitilen büyük dil modellerinin (LLM'ler) daha iyi model kalitesiyle sonuçlandığını kanıtladı. Son birkaç yılda mevcut nesil modellerin boyutu önemli ölçüde arttı ve bunların verimli ve uygun ölçekte eğitilebilmesi için modern araçlara ve altyapıya ihtiyaç duyuluyor. PyTorch Dağıtılmış Veri Paralelliği (DDP), verilerin basit ve sağlam bir şekilde geniş ölçekte işlenmesine yardımcı olur, ancak modelin tek bir GPU'ya sığmasını gerektirir. PyTorch Tamamen Parçalanmış Veri Paralel (FSDP) kitaplığı, veri paralel çalışanları arasında büyük modelleri eğitmek için model parçalamayı etkinleştirerek bu engeli ortadan kaldırır.
Dağıtılmış model eğitimi, ölçeklenebilen bir çalışan düğüm kümesi gerektirir. Amazon Elastik Kubernetes Hizmeti (Amazon EKS), AI/ML iş yüklerini çalıştırma sürecini büyük ölçüde basitleştiren, daha yönetilebilir ve daha az zaman alıcı hale getiren popüler bir Kubernetes uyumlu hizmettir.
Bu blog yazısında AWS, Amazon EKS'yi kullanarak AWS'deki derin öğrenme modellerinin doğrusal ölçeklendirilmesini sorunsuz bir şekilde gerçekleştirmek için PyTorch FSDP kitaplığının nasıl kullanılacağını tartışmak üzere Meta'nın PyTorch ekibiyle işbirliği yapıyor ve AWS Derin Öğrenme Kapları (DLC'ler). Bunu, 7'lı Amazon EKS'yi kullanarak 13B, 70B ve 2B Llama16 modellerinin eğitiminin adım adım uygulanmasıyla gösteriyoruz. Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2) p4de.24xlarge bulut sunucuları (her biri 8 NVIDIA A100 Tensor Core GPU'ya ve her biri 80 GB HBM2e belleğe sahip GPU'ya sahiptir) veya 16 EC2 s5.48xlarge örnekler (her biri 8 NVIDIA H100 Tensor Core GPU'ya ve her biri 80 GB HBM3 belleğe sahip GPU'ya sahiptir), üretimde neredeyse doğrusal ölçeklendirme elde eder ve sonuç olarak daha hızlı eğitim süresi sağlar.
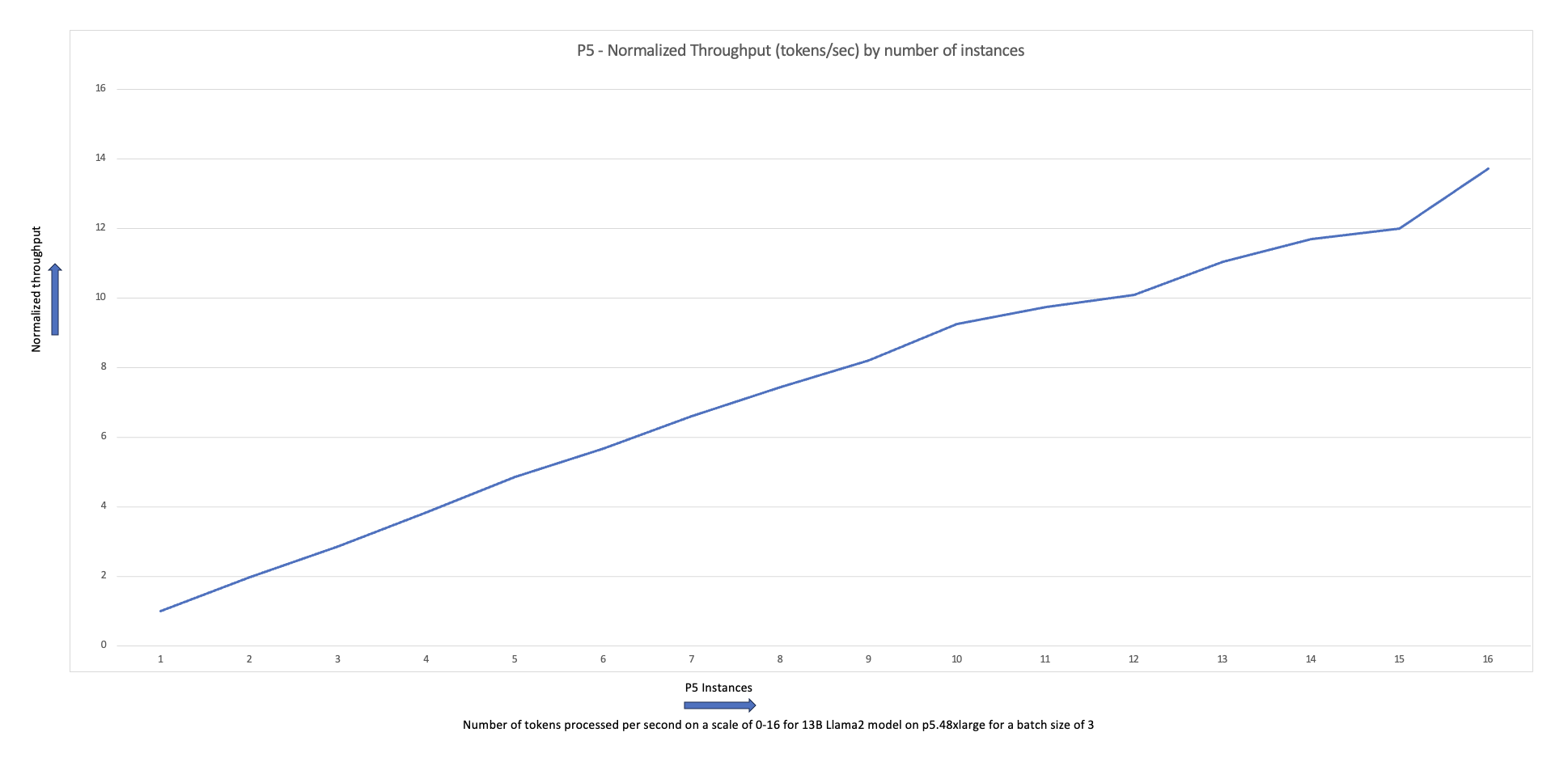
Aşağıdaki ölçeklendirme grafiği, p5.48xlarge bulut sunucularının 87 düğümlü küme yapılandırmasında FSDP Llama2 ince ayarıyla %16 ölçeklendirme verimliliği sunduğunu göstermektedir.
Yüksek Lisans eğitiminin zorlukları
İşletmeler, çeşitli uygulamalarda verimliliği ve doğruluğu artırmak için sanal asistanlar, çeviri, içerik oluşturma ve bilgisayarla görme gibi bir dizi görev için LLM'leri giderek daha fazla benimsiyor.
Ancak bu büyük modellerin özel bir kullanım durumu için eğitilmesi veya ince ayarlanması büyük miktarda veri ve bilgi işlem gücü gerektirir ve bu da makine öğrenimi yığınının genel mühendislik karmaşıklığını artırır. Bunun nedeni aynı zamanda tek bir GPU'da bulunan sınırlı belleğin eğitilebilecek modelin boyutunu ve ayrıca eğitim sırasında kullanılan GPU başına toplu iş boyutunu sınırlamasıdır.
Bu zorluğun üstesinden gelmek için çeşitli model paralellik teknikleri, örneğin Derin Hız Sıfır ve PyTorch FSDP sınırlı GPU belleği engelini aşmanıza olanak sağlamak için oluşturuldu. Bu, her hızlandırıcının yalnızca bir dilim (bir dilim) tuttuğu parçalanmış veri paralel tekniği benimsenerek yapılır. çömlek kırığı) tüm model kopyası yerine bir model kopyasının kullanılması, eğitim işinin bellek ayak izini önemli ölçüde azaltır.
Bu gönderi, Amazon EKS'yi kullanarak Llama2 modelinde ince ayar yapmak için PyTorch FSDP'yi nasıl kullanabileceğinizi gösterir. Bunu, model gereksinimlerini karşılamak için bilgi işlem ve GPU kapasitesinin ölçeğini genişleterek başarıyoruz.
FSDP'ye genel bakış
PyTorch DDP eğitiminde her GPU (bir işçi PyTorch bağlamında), model ağırlıkları, degradeler ve optimize edici durumları dahil olmak üzere modelin tam bir kopyasını içerir. Her çalışan bir veri kümesini işler ve geriye doğru geçişin sonunda bir veri kümesi kullanır. tamamen azalt Farklı çalışanlar arasındaki degradeleri senkronize etme işlemi.
Her GPU'da modelin bir kopyasının bulunması, DDP iş akışında barındırılabilecek modelin boyutunu kısıtlar. FSDP, veri paralelliğinin basitliğini korurken model parametrelerini, optimize edici durumlarını ve eğimleri veri paralel çalışanları arasında paylaştırarak bu sınırlamanın aşılmasına yardımcı olur.
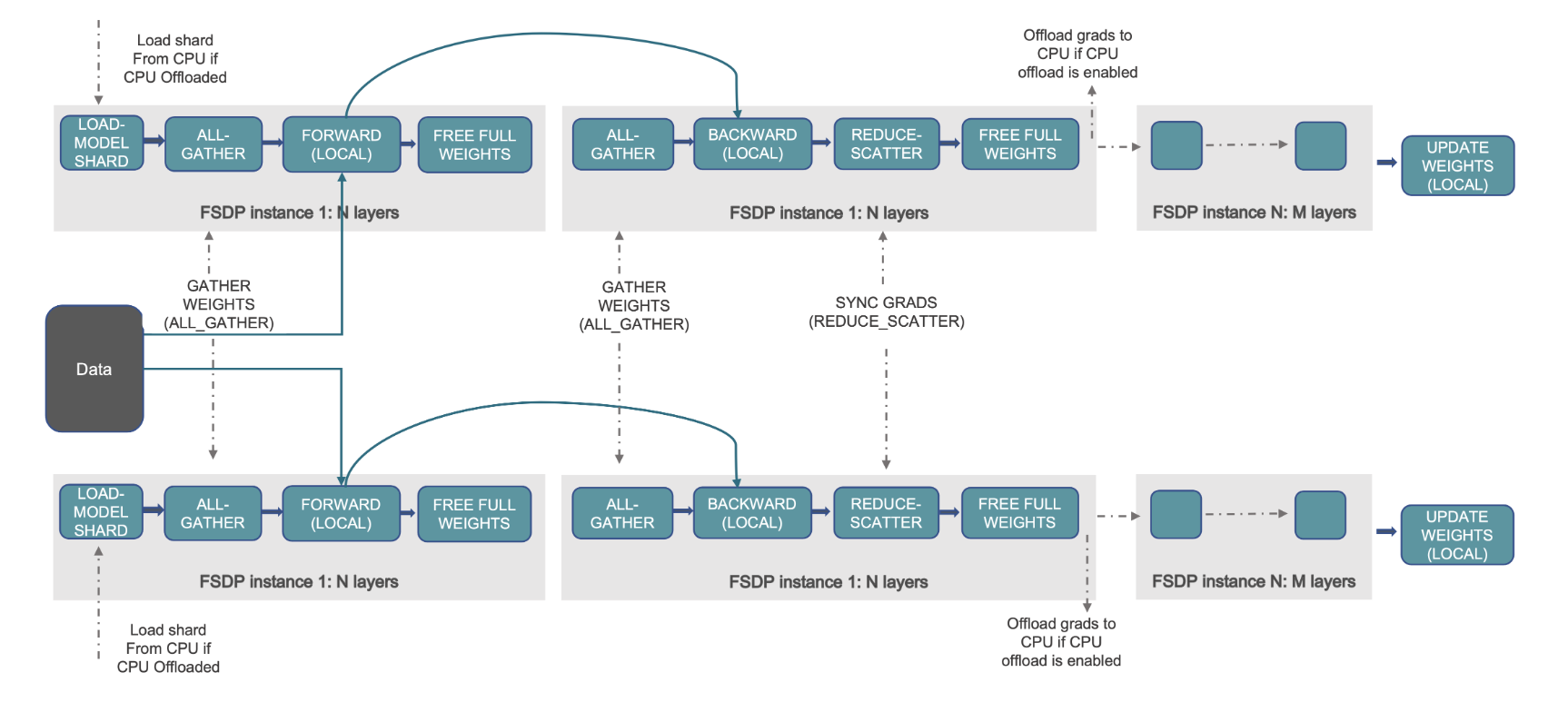
Bu, aşağıdaki diyagramda gösterilmektedir; burada DDP durumunda her GPU, optimize edici durumu (OS), degradeler (G) ve parametreler (P) dahil olmak üzere model durumunun tam bir kopyasını tutar: M(OS + G) + P). FSDP'de her GPU, optimize edici durumu (OS), degradeler (G) ve parametreler (P) dahil olmak üzere model durumunun yalnızca bir dilimini tutar: M (İşletim Sistemi + G + P). FSDP'nin kullanılması, tüm çalışanlarda DDP'ye kıyasla önemli ölçüde daha küçük bir GPU bellek alanıyla sonuçlanır; bu da çok büyük modellerin eğitimine veya eğitim işleri için daha büyük parti boyutlarının kullanılmasına olanak tanır.

Ancak bu, iletişim ve hesaplama süreçlerinin örtüşmesi gibi FSDP optimizasyonları aracılığıyla azaltılan artan iletişim ek yükünün maliyetine yol açar: önceden getirme. Daha ayrıntılı bilgi için bkz. Tamamen Parçalanmış Veri Paralel'e (FSDP) Başlarken.
FSDP, eğitim işlerinizin performansını ve verimliliğini ayarlamanıza olanak tanıyan çeşitli parametreler sunar. FSDP'nin temel özelliklerinden ve yeteneklerinden bazıları şunlardır:
- Trafo sarma politikası
- Esnek karma hassasiyet
- Aktivasyon kontrol noktası
- Farklı ağ hızlarına ve küme topolojilerine uyacak çeşitli parçalama stratejileri:
- FULL_SHARD – Parça modeli parametreleri, degradeler ve optimize edici durumları
- HYBRID_SHARD – Düğümler arasında bir düğüm DDP'si içindeki tam parça; modelin tam kopyası (HSDP) için esnek bir parçalama grubunu destekler
- SHARD_GRAD_OP – Yalnızca degradeleri ve optimize edici durumlarını parçalayın
- NO_SHARD – DDP'ye benzer
FSDP hakkında daha fazla bilgi için bkz. Pytorch FSDP ve AWS ile Verimli Büyük Ölçekli Eğitim.
Aşağıdaki şekil FSDP'nin iki paralel veri işlemi için nasıl çalıştığını göstermektedir.
Çözüme genel bakış
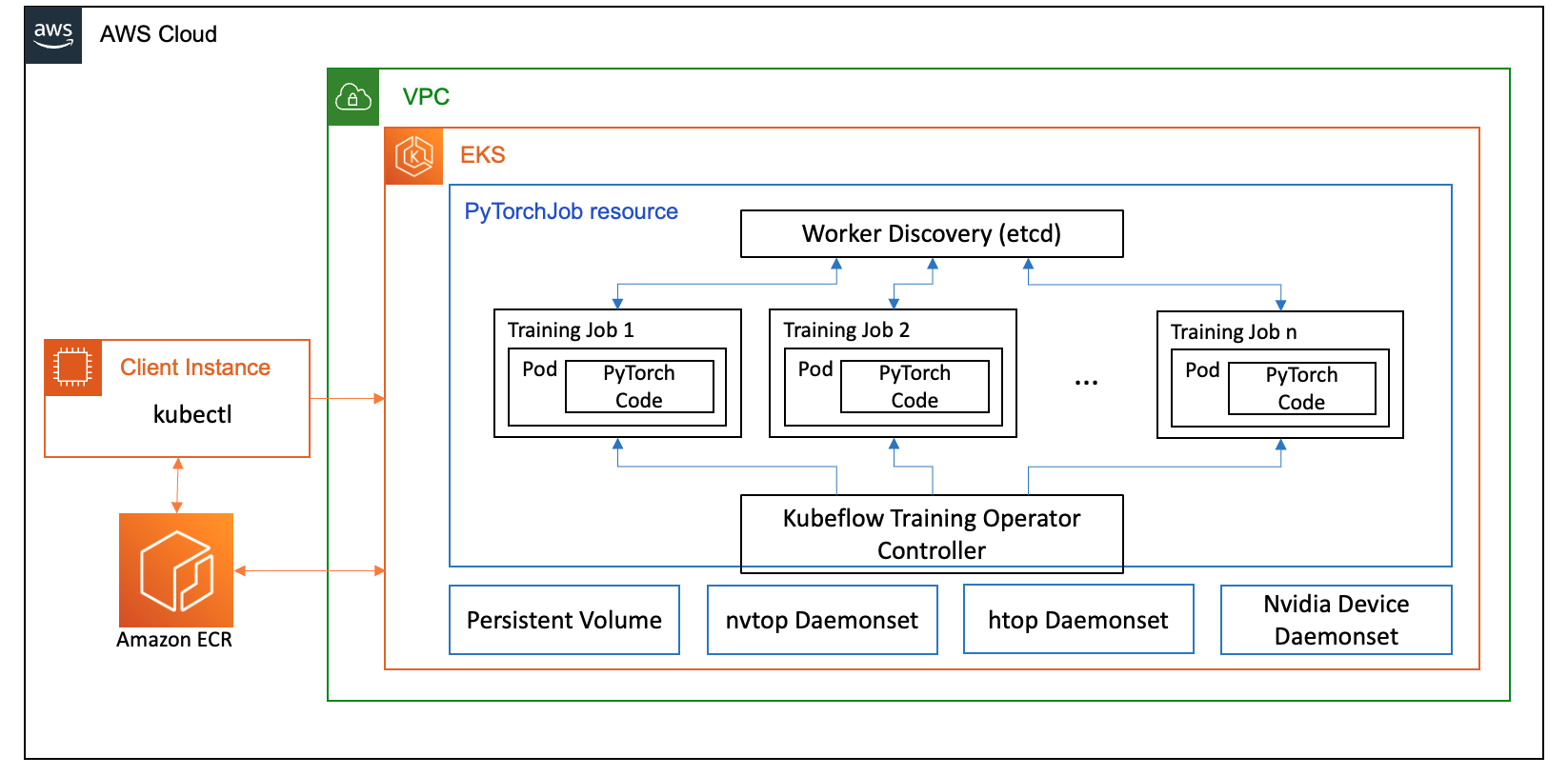
Bu yazıda, Kubernetes'i AWS Cloud'da ve şirket içi veri merkezlerinde çalıştırmak için yönetilen bir hizmet olan Amazon EKS'yi kullanarak bir bilgi işlem kümesi oluşturduk. Birçok müşteri, Kubernetes tabanlı AI/ML iş yüklerini çalıştırmak için Amazon EKS'yi benimsiyor; Amazon EKS'nin performansı, ölçeklenebilirliği, güvenilirliği ve kullanılabilirliğinin yanı sıra AWS ağ iletişimi, güvenlik ve diğer hizmetlerle entegrasyonlarından da yararlanıyor.
FSDP kullanım durumumuz için şunu kullanıyoruz: Kubeflow Eğitim Operatörü Makine öğrenimi modelleri için ince ayar yapılmasını ve ölçeklenebilir dağıtılmış eğitimi kolaylaştıran, Kubernetes'te yerel bir proje olan Amazon EKS'de. PyTorch eğitim işlerini geniş ölçekte dağıtmak ve yönetmek için kullanabileceğiniz PyTorch da dahil olmak üzere çeşitli makine öğrenimi çerçevelerini destekler.
Kubeflow Eğitim Operatörünün PyTorchJob özel kaynağını kullanarak, kaynak kullanımını optimize etmemize olanak tanıyan yapılandırılabilir sayıda çalışan kopyasıyla Kubernetes üzerinde eğitim işleri yürütüyoruz.
Aşağıdakiler, Llama2 ince ayar kullanım senaryomuzda rol oynayan eğitim operatörünün birkaç bileşenidir:
- PyTorch için dağıtılmış eğitim işlerini düzenleyen merkezi bir Kubernetes denetleyicisi.
- Kubeflow Eğitim Operatörü tarafından Kubernetes'te Llama2 eğitim işlerini tanımlamak ve dağıtmak için sağlanan PyTorch için özel bir Kubernetes kaynağı olan PyTorchJob.
- PyTorch modellerinin dağıtılmış eğitimini koordine etmek için buluşma mekanizmasının uygulanmasıyla ilgili olan vb. Bu
etcdSunucu, buluşma sürecinin bir parçası olarak, dağıtılmış eğitim sırasında katılımcı çalışanların koordinasyonunu ve senkronizasyonunu kolaylaştırır.
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.
Ayrıntıların çoğu, Llama2 örneğini çalıştırmak için kullandığımız otomasyon komut dosyaları tarafından soyutlanacaktır.
Bu kullanım durumunda aşağıdaki kod referanslarını kullanırız:
Lama2 nedir?
Llama2, 2 trilyon metin ve kod jetonu üzerinde önceden eğitilmiş bir Yüksek Lisans'tır. Bugün mevcut olan en büyük ve en güçlü Yüksek Lisans'lardan biridir. Llama2'yi doğal dil işleme (NLP), metin oluşturma ve çeviri dahil olmak üzere çeşitli görevler için kullanabilirsiniz. Daha fazla bilgi için bkz. Lama'yı kullanmaya başlama.
Llama2 üç farklı model boyutunda mevcuttur:
- Lama2-70b – Bu, 2 milyar parametreyle en büyük Llama70 modelidir. En güçlü Llama2 modelidir ve en zorlu görevlerde kullanılabilir.
- Lama2-13b – Bu, 2 milyar parametreli orta büyüklükte bir Llama13 modelidir. Performans ve verimlilik arasında iyi bir denge sağlar ve çeşitli görevler için kullanılabilir.
- Lama2-7b – Bu, 2 milyar parametreyle en küçük Llama7 modelidir. En verimli Llama2 modelidir ve en yüksek düzeyde performans gerektirmeyen görevlerde kullanılabilir.
Bu gönderi, Amazon EKS'de tüm bu modellere ince ayar yapmanızı sağlar. Bir EKS kümesi oluşturma ve üzerinde FSDP işlerini çalıştırma konusunda basit ve tekrarlanabilir bir deneyim sağlamak için, aws-do-eks proje. Örnek aynı zamanda önceden var olan bir EKS kümesiyle de çalışacaktır.
Komut dosyası içeren bir izlenecek yol şu adreste mevcuttur: GitHub alışılmışın dışında bir deneyim için. İlerleyen bölümlerde uçtan uca süreci daha detaylı açıklıyoruz.
Çözüm altyapısını sağlayın
Bu yazıda açıklanan deneyler için p4de (A100 GPU) ve p5 (H100 GPU) düğümlerine sahip kümeler kullanıyoruz.
p4de.24xlarge düğümlerine sahip küme
P4de düğümlerine sahip kümemiz için aşağıdakileri kullanıyoruz eks-gpu-p4de-odcr.yaml senaryo:
kullanma eksctl ve önceki küme bildiriminde, p4de düğümlerine sahip bir küme oluşturuyoruz:
p5.48xlarge düğümleri içeren küme
P5 düğümlerine sahip bir EKS kümesi için bir dünya biçimi şablonu aşağıda yer almaktadır GitHub repo.
Kümeyi şu yolla özelleştirebilirsiniz: değişkenler.tf dosyanızı oluşturun ve ardından bunu Terraform CLI aracılığıyla oluşturun:
Basit bir kubectl komutunu çalıştırarak kümenin kullanılabilirliğini doğrulayabilirsiniz:
Bu komutun çıktısı, Hazır durumdaki beklenen düğüm sayısını gösteriyorsa küme sağlıklıdır.
Önkoşulları dağıtma
Amazon EKS'de FSDP'yi çalıştırmak için şunu kullanırız: PyTorchJob özel kaynak. Gerektirir vb. ve Kubeflow Eğitim Operatörü ön koşullar olarak.
Etcd'yi aşağıdaki kodla dağıtın:
Kubeflow Training Operator'ı aşağıdaki kodla dağıtın:
Bir FSDP kapsayıcı görüntüsü oluşturun ve Amazon ECR'ye aktarın
Bir FSDP kapsayıcı görüntüsü oluşturmak için aşağıdaki kodu kullanın ve bunu Amazon Elastik Konteyner Kayıt Defteri (Amazon ECR'si):
FSDP PyTorchJob bildirimini oluşturun
sizin yanınızdaki ekleme Sarılma yüz jetonu çalıştırmadan önce aşağıdaki kod parçasında:
PyTorchJob'unuzu şununla yapılandırın: .env dosyanızda veya doğrudan ortam değişkenlerinizde aşağıdaki gibi:
Kullanarak PyTorchJob bildirimini oluşturun fsdp şablonu ve created.sh komut dosyasını kullanın veya aşağıdaki komut dosyasını kullanarak doğrudan oluşturun:
PyTorchJob'u çalıştırın
PyTorchJob'u aşağıdaki kodla çalıştırın:
Belirtilen sayıda FDSP çalışan bölmesinin oluşturulduğunu göreceksiniz ve görüntüyü çektikten sonra Çalışıyor durumuna gireceklerdir.
PyTorchJob'un durumunu görmek için aşağıdaki kodu kullanın:
PyTorchJob'u durdurmak için aşağıdaki kodu kullanın:
Bir iş tamamlandıktan sonra yeni bir çalıştırma başlatılmadan önce silinmesi gerekir. Ayrıca şunu da gözlemledik:etcdpod'u kullanmak ve yeni bir işi başlatmadan önce yeniden başlatılmasına izin vermek, RendezvousClosedError.
Kümeyi ölçeklendirin
Kümedeki çalışan düğümlerin sayısını ve örnek türünü değiştirirken iş oluşturma ve çalıştırmanın önceki adımlarını tekrarlayabilirsiniz. Bu, daha önce gösterilene benzer ölçeklendirme grafikleri oluşturmanıza olanak sağlar. Genel olarak, kümeye daha fazla düğüm eklendiğinde GPU bellek ayak izinde bir azalma, çağ süresinde bir azalma ve üretimde bir artış görmelisiniz. Önceki grafik, boyutları 5 ila 1 düğüm arasında değişen bir p16 düğüm grubu kullanılarak çeşitli deneyler yapılarak üretildi.
FSDP eğitim iş yükünü gözlemleyin
Üretken yapay zeka iş yüklerinin gözlemlenebilirliği, yürütülen işlerinizin görünürlüğüne olanak tanımanın yanı sıra bilgi işlem kaynaklarınızın kullanımını en üst düzeye çıkarmanıza yardımcı olması açısından önemlidir. Bu yazıda, bu amaçla birkaç Kubernetes yerel ve açık kaynak gözlemlenebilirlik aracı kullanıyoruz. Bu araçlar hataları, istatistikleri ve model davranışını izlemenize olanak tanıyarak yapay zekanın gözlemlenebilirliğini herhangi bir iş kullanımının önemli bir parçası haline getirir. Bu bölümde FSDP eğitim işlerini gözlemlemek için çeşitli yaklaşımlar gösteriyoruz.
Çalışan bölmesi günlükleri
En temel düzeyde, eğitim bölmelerinizin günlüklerini görebilmeniz gerekir. Bu, Kubernetes'in yerel komutları kullanılarak kolayca yapılabilir.
Öncelikle bölmelerin listesini alın ve günlüklerini görmek istediğiniz bölmenin adını bulun:
Ardından seçilen bölmeye ilişkin günlükleri görüntüleyin:

Yalnızca bir çalışan (seçilmiş lider) bölmesi günlüğü, genel iş istatistiklerini listeler. Seçilen lider bölmesinin adı, anahtarla tanımlanan her çalışan bölmesi günlüğünün başında bulunur master_addr=.
CPU kullanımı
Dağıtılmış eğitim iş yükleri hem CPU hem de GPU kaynaklarını gerektirir. Bu iş yüklerini optimize etmek için bu kaynakların nasıl kullanıldığını anlamak önemlidir. Neyse ki CPU ve GPU kullanımını görselleştirmeye yardımcı olan bazı harika açık kaynak yardımcı programları mevcuttur. CPU kullanımını görüntülemek için şunları kullanabilirsiniz:htop. Çalışan bölmeleriniz bu yardımcı programı içeriyorsa, bir bölmede bir kabuk açmak ve ardından çalıştırmak için aşağıdaki komutu kullanabilirsiniz.htop.
Alternatif olarak bir htop dağıtabilirsinizdaemonsetaşağıdaki şekilde verilen gibi GitHub repo.
Thedaemonsether düğümde hafif bir htop bölmesi çalıştıracaktır. Bu bölmelerden herhangi birinde çalıştırabilir ve çalıştırabilirsiniz.htopkomut:
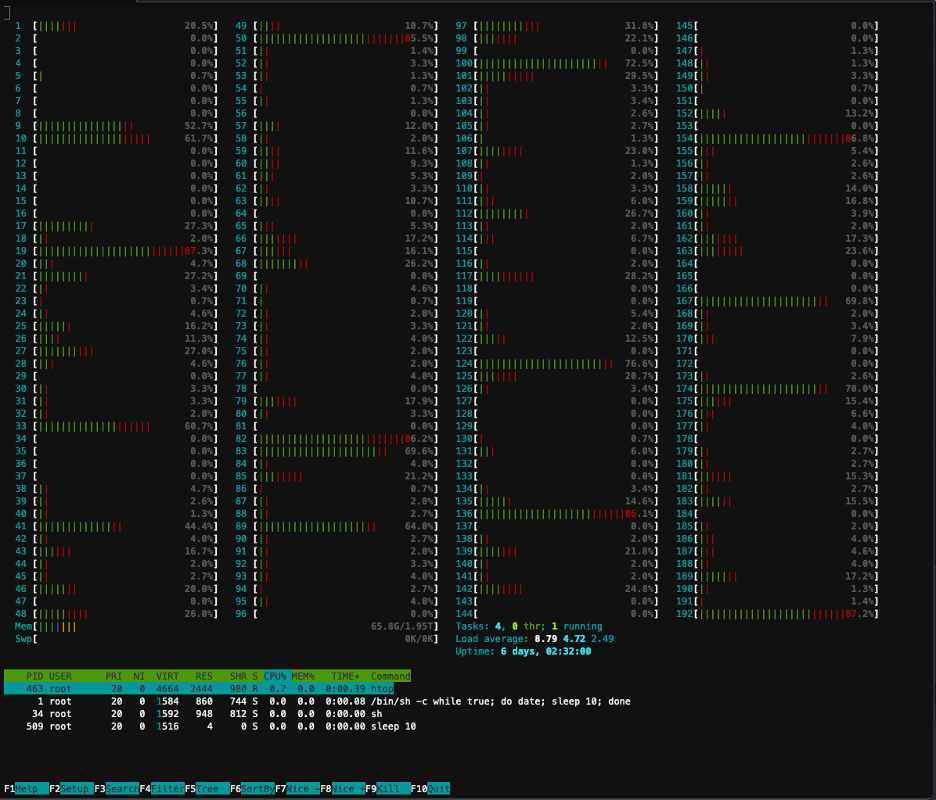
Aşağıdaki ekran görüntüsü kümedeki düğümlerden birindeki CPU kullanımını göstermektedir. Bu durumda, 5.48 vCPU'ya sahip bir P192xlarge örneğine bakıyoruz. Model ağırlıkları indirilirken işlemci çekirdekleri boşta kalıyor ve model ağırlıkları GPU belleğine yüklenirken kullanımın arttığını görüyoruz.
GPU kullanımı
EğernvtopPod'unuzda yardımcı program mevcutsa, aşağıdakini kullanarak onu çalıştırabilir ve ardından çalıştırabilirsiniz.nvtop.
Alternatif olarak bir nvtop dağıtabilirsinizdaemonsetaşağıdaki şekilde verilen gibi GitHub repo.
Bu bir çalıştıracaknvtopher düğümdeki bölme. Bu bölmelerden herhangi birine girip koşabilirsiniznvtop:
Aşağıdaki ekran görüntüsü, eğitim kümesindeki düğümlerden birindeki GPU kullanımını göstermektedir. Bu durumda, 5.48 NVIDIA H8 GPU'ya sahip bir P100xlarge örneğine bakıyoruz. Model ağırlıkları indirilirken GPU'lar boştadır, ardından model ağırlıkları GPU'ya yüklenirken GPU bellek kullanımı artar ve eğitim yinelemeleri devam ederken GPU kullanımı %100'e yükselir.

Grafana kontrol paneli
Artık sisteminizin kapsül ve düğüm düzeyinde nasıl çalıştığını anladığınıza göre, küme düzeyindeki metriklere bakmak da önemlidir. Toplu kullanım ölçümleri NVIDIA DCGM Exporter ve Prometheus tarafından toplanabilir ve Grafana'da görselleştirilebilir.
Örnek bir Prometheus-Grafana konuşlandırması aşağıda mevcuttur GitHub repo.
Örnek bir DCGM dışa aktarıcı dağıtımı aşağıdaki adreste mevcuttur GitHub repo.
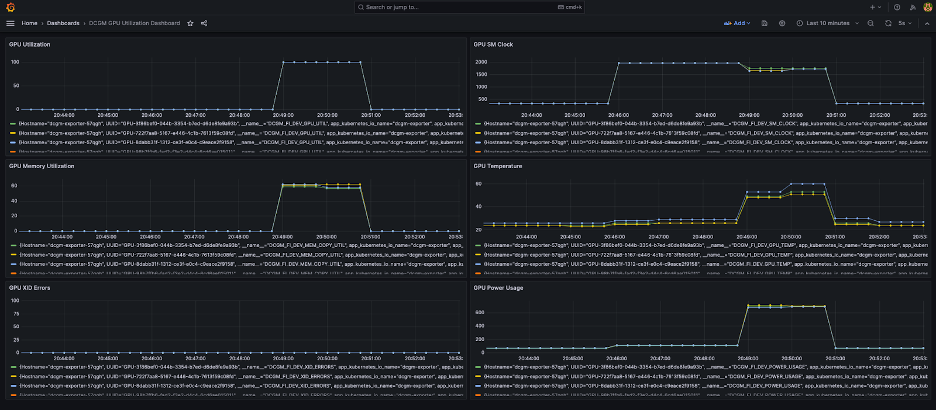
Aşağıdaki ekran görüntüsünde basit bir Grafana kontrol paneli gösterilmektedir. Aşağıdaki DCGM metrikleri seçilerek oluşturulmuştur: DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMP, ve DCGM_FI_DEV_POWER_USAGE. Kontrol paneli Prometheus'a şuradan aktarılabilir: GitHub.
Aşağıdaki kontrol paneli, Llama2 7b tek dönemli eğitim işinin bir çalışmasını göstermektedir. Grafikler, akışlı çok işlemcili (SM) saat arttıkça GPU ve bellek kullanımının yanı sıra GPU'ların güç tüketiminin ve sıcaklığının da arttığını göstermektedir. Ayrıca bu çalıştırma sırasında XID hatası olmadığını ve GPU'ların sağlıklı olduğunu da görebilirsiniz.
Mart 2024'ten beri EKS için GPU gözlemlenebilirliği yerel olarak desteklenmektedir CloudWatch Container Insights. Bu işlevselliği etkinleştirmek için CloudWatch Observability Eklentisini EKS kümenizde dağıtmanız yeterlidir. Ardından, Container Insights'taki önceden yapılandırılmış ve özelleştirilebilir kontrol panelleri aracılığıyla bölme, düğüm ve küme düzeyindeki ölçümlere göz atabileceksiniz.
Temizlemek
Kümenizi bu blogda verilen örnekleri kullanarak oluşturduysanız, kümeyi ve VPC dahil onunla ilişkili tüm kaynakları silmek için aşağıdaki kodu çalıştırabilirsiniz:
eksctl için:
Terraform için:
Gelecek özellikler
FSDP'nin, GPU başına bellek alanını daha da iyileştirmeyi amaçlayan parametre başına parçalama özelliği içermesi bekleniyor. Ek olarak, FP8 desteğinin devam eden gelişimi, H100 GPU'larda FSDP performansını iyileştirmeyi amaçlamaktadır. Son olarak, FSDP ile entegre edildiğindetorch.compile, ek performans iyileştirmeleri görmeyi ve seçici etkinleştirme kontrol noktası belirleme gibi özelliklerin etkinleştirilmesini görmeyi umuyoruz.
Sonuç
Bu yazıda, FSDP'nin her bir GPU'daki bellek alanını nasıl azalttığını, daha büyük modellerin daha verimli bir şekilde eğitilmesine olanak sağladığını ve üretimde neredeyse doğrusal ölçeklendirmeye nasıl ulaştığını tartıştık. Bunu, P2de ve P4 bulut sunucularında Amazon EKS kullanarak bir Llama5 modeli eğitiminin adım adım uygulanmasıyla gösterdik ve günlüklerin yanı sıra CPU ve GPU kullanımını izlemek için kubectl, htop, nvtop ve dcgm gibi gözlemlenebilirlik araçlarını kullandık.
Kendi LLM eğitim işleriniz için PyTorch FSDP'den yararlanmanızı öneririz. Başlangıç tarihi: aws-do-fsdp.
Yazarlar Hakkında
 Kanwaljit Khurmi Amazon Web Services'te Baş AI/ML Çözüm Mimarıdır. Rehberlik ve teknik destek sağlamak için AWS müşterileriyle birlikte çalışarak onların AWS'deki makine öğrenimi çözümlerinin değerini artırmalarına yardımcı oluyor. Kanwaljit, konteynerli, dağıtılmış bilgi işlem ve derin öğrenme uygulamaları konusunda müşterilere yardımcı olma konusunda uzmanlaşmıştır.
Kanwaljit Khurmi Amazon Web Services'te Baş AI/ML Çözüm Mimarıdır. Rehberlik ve teknik destek sağlamak için AWS müşterileriyle birlikte çalışarak onların AWS'deki makine öğrenimi çözümlerinin değerini artırmalarına yardımcı oluyor. Kanwaljit, konteynerli, dağıtılmış bilgi işlem ve derin öğrenme uygulamaları konusunda müşterilere yardımcı olma konusunda uzmanlaşmıştır.
 Alex Iankoulski AWS'de Kendi Kendini Yöneten Makine Öğrenimi Baş Çözüm Mimarıdır. Kendisi, derinlemesine, uygulamalı işler yapmayı seven, tam kapsamlı bir yazılım ve altyapı mühendisidir. Görevi gereği, konteyner destekli AWS hizmetlerinde ML ve AI iş yüklerinin konteynerleştirilmesi ve düzenlenmesi konusunda müşterilere yardımcı olmaya odaklanıyor. Aynı zamanda açık kaynağın da yazarıdır. çerçeve yap ve dünyanın en büyük zorluklarını çözerken inovasyonun hızını artırmak için konteyner teknolojilerini uygulamayı seven bir Docker kaptanı.
Alex Iankoulski AWS'de Kendi Kendini Yöneten Makine Öğrenimi Baş Çözüm Mimarıdır. Kendisi, derinlemesine, uygulamalı işler yapmayı seven, tam kapsamlı bir yazılım ve altyapı mühendisidir. Görevi gereği, konteyner destekli AWS hizmetlerinde ML ve AI iş yüklerinin konteynerleştirilmesi ve düzenlenmesi konusunda müşterilere yardımcı olmaya odaklanıyor. Aynı zamanda açık kaynağın da yazarıdır. çerçeve yap ve dünyanın en büyük zorluklarını çözerken inovasyonun hızını artırmak için konteyner teknolojilerini uygulamayı seven bir Docker kaptanı.
 ana simoes AWS'de ML Çerçeveleri Baş Makine Öğrenimi Uzmanıdır. Buluttaki HPC altyapısında AI, ML ve üretken yapay zekayı büyük ölçekte dağıtan müşterileri destekliyor. Ana, yeni iş yükleri ve üretken yapay zeka ve makine öğrenimi kullanım senaryoları için fiyat-performans elde etme konusunda müşterileri desteklemeye odaklanıyor.
ana simoes AWS'de ML Çerçeveleri Baş Makine Öğrenimi Uzmanıdır. Buluttaki HPC altyapısında AI, ML ve üretken yapay zekayı büyük ölçekte dağıtan müşterileri destekliyor. Ana, yeni iş yükleri ve üretken yapay zeka ve makine öğrenimi kullanım senaryoları için fiyat-performans elde etme konusunda müşterileri desteklemeye odaklanıyor.
 Hamid Şojanazeri PyTorch'ta açık kaynak, yüksek performanslı model optimizasyonu, dağıtılmış eğitim (FSDP) ve çıkarım. O, ortak yaratıcıdır lama tarifi ve katkıda bulunan TorchServis. Başlıca ilgi alanı, maliyet verimliliğini artırmak ve yapay zekayı daha geniş bir topluluk için daha erişilebilir hale getirmektir.
Hamid Şojanazeri PyTorch'ta açık kaynak, yüksek performanslı model optimizasyonu, dağıtılmış eğitim (FSDP) ve çıkarım. O, ortak yaratıcıdır lama tarifi ve katkıda bulunan TorchServis. Başlıca ilgi alanı, maliyet verimliliğini artırmak ve yapay zekayı daha geniş bir topluluk için daha erişilebilir hale getirmektir.
 Daha az Wright PyTorch'ta Yapay Zeka/Ortak Mühendisidir. Triton/CUDA çekirdekleri üzerinde çalışıyor (SplitK iş ayrıştırmasıyla Dequant'ı hızlandırma); sayfalanmış, akışlı ve nicemlenmiş optimize ediciler; ve PyTorch Dağıtılmış (PyTorch FSDP).
Daha az Wright PyTorch'ta Yapay Zeka/Ortak Mühendisidir. Triton/CUDA çekirdekleri üzerinde çalışıyor (SplitK iş ayrıştırmasıyla Dequant'ı hızlandırma); sayfalanmış, akışlı ve nicemlenmiş optimize ediciler; ve PyTorch Dağıtılmış (PyTorch FSDP).
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

