Doğrulama finansal hizmetler, FinTech, kripto, oyun, mobilite ve çevrimiçi pazarlardaki öncüler de dahil olmak üzere yenilikçi, büyüme odaklı kuruluşlar için bir kimlik doğrulama platformu ortağıdır. Yapay zeka destekli otomasyonu insan geri bildirimi, derin içgörüler ve uzmanlıkla birleştiren ileri teknoloji sağlarlar.

Veriff, müşterilerinin, müşteri yolculuklarının tüm ilgili anlarında kullanıcılarının kimliklerine ve kişisel özelliklerine güven duymasını sağlayan kanıtlanmış bir altyapı sunar. Veriff, Bolt, Deel, Monese, Starship, Super Awesome, Trustpilot ve Wise gibi müşteriler tarafından güvenilmektedir.
Yapay zeka destekli bir çözüm olarak Veriff'in düzinelerce makine öğrenimi (ML) modelini uygun maliyetli bir şekilde oluşturup çalıştırması gerekiyor. Bu modeller, hafif ağaç tabanlı modellerden, düşük gecikme süresi elde etmek ve kullanıcı deneyimini geliştirmek için GPU'lar üzerinde çalışması gereken derin öğrenme bilgisayarlı görme modellerine kadar çeşitlilik gösterir. Veriff ayrıca müşterileri için son derece kişiselleştirilmiş bir çözümü hedefleyerek şu anda tekliflerine daha fazla ürün ekliyor. Farklı müşterilere farklı modeller sunmak, ölçeklenebilir bir model hizmet çözümü ihtiyacını artırıyor.
Bu yazıda size Veriff'in model dağıtım iş akışını aşağıdakileri kullanarak nasıl standartlaştırdığını gösteriyoruz: Amazon Adaçayı Yapıcımaliyetleri ve geliştirme süresini azaltır.
Altyapı ve kalkınma zorlukları
Veriff'in arka uç mimarisi, hizmetlerin AWS altyapısında barındırılan farklı Kubernetes kümelerinde çalıştığı bir mikro hizmet modelini temel alır. Bu yaklaşım başlangıçta pahalı görüntü işleme makine öğrenimi modellerini çalıştıran mikro hizmetler de dahil olmak üzere tüm şirket hizmetleri için kullanıldı.
Bu modellerden bazıları GPU bulut sunucularında dağıtım gerektiriyordu. GPU destekli bulut sunucusu türlerinin nispeten daha yüksek maliyetinin bilincinde olan Veriff, özel çözüm Belirli bir GPU'nun kaynaklarını farklı hizmet kopyaları arasında paylaşmak için Kubernetes'te. Tek bir GPU, genellikle Veriff'in bilgisayarlı görüş modellerinin çoğunu bellekte tutmaya yetecek kadar VRAM'e sahiptir.
Çözüm, GPU maliyetlerini azaltsa da veri bilimcilerinin, modellerinin ne kadar GPU belleği gerektireceğini önceden belirtmeleri gereken kısıtlamayı da beraberinde getirdi. Ayrıca DevOps, talep modellerine yanıt olarak GPU örneklerini manuel olarak hazırlamakla yükümlüydü. Bu, operasyonel ek yüke ve bulut sunucularının aşırı tedarik edilmesine neden oldu ve bu da optimumun altında bir maliyet profiliyle sonuçlandı.
Bu kurulum, GPU sağlamanın yanı sıra, veri bilimcilerinin her model için bir REST API sarmalayıcısı oluşturmasını da gerektiriyordu; bu sarmalayıcı, diğer şirket hizmetlerinin tüketmesi için genel bir arayüz sağlamak ve model verilerinin ön işlemesini ve son işlemesini kapsüllemek için gerekliydi. Bu API'ler üretim düzeyinde kod gerektiriyordu ve bu da veri bilimcilerinin modelleri üretmesini zorlaştırıyordu.
Veriff'in veri bilimi platformu ekibi bu yaklaşımın alternatif yollarını aradı. Ana amaç, daha basit dağıtım hatları sağlayarak şirketin veri bilimcilerini araştırmadan üretime daha iyi bir geçişle desteklemekti. İkincil amaç ise GPU bulut sunucularının sağlanmasına ilişkin operasyonel maliyetleri azaltmaktı.
Çözüme genel bakış
Veriff'in iki sorunu çözecek yeni bir çözüme ihtiyacı vardı:
- ML modellerinin etrafında REST API sarmalayıcılarının kolaylıkla oluşturulmasına izin verin
- Tedarik edilen GPU örneği kapasitesinin en iyi şekilde ve mümkünse otomatik olarak yönetilmesine izin ver
Sonuçta, makine öğrenimi platformu ekibi şunu kullanma kararında birleşti: Sagemaker çoklu model uç noktaları (MME'ler). Bu karar, MME'nin NVIDIA'ya verdiği destekten kaynaklandı. Triton Çıkarım Sunucusu (modelleri REST API'leri olarak sarmayı kolaylaştıran ML odaklı bir sunucu; Veriff ayrıca zaten Triton ile denemeler yapıyordu) ve ayrıca basit otomatik ölçeklendirme politikaları aracılığıyla GPU örneklerinin otomatik ölçeklendirmesini yerel olarak yönetme yeteneği.
Veriff'te biri sahneleme, diğeri prodüksiyon için olmak üzere iki MME oluşturuldu. Bu yaklaşım, üretim modellerini etkilemeden bir hazırlama ortamında test adımlarını yürütmelerine olanak tanır.
SageMaker MME'leri
SageMaker, geliştiricilere ve veri bilimcilere makine öğrenimi modellerini hızlı bir şekilde oluşturma, eğitme ve dağıtma yeteneği sağlayan, tam olarak yönetilen bir hizmettir. SageMaker MME'leri, gerçek zamanlı çıkarım için çok sayıda modeli dağıtmak için ölçeklenebilir ve uygun maliyetli bir çözüm sunar. MME'ler, tüm modellerinizi barındırmak için GPU'lar gibi hızlandırılmış örnekleri kullanabilen paylaşılan bir hizmet konteyneri ve bir kaynak filosu kullanır. Bu, tek model uç noktaları kullanmaya kıyasla uç nokta kullanımını en üst düzeye çıkararak barındırma maliyetlerini azaltır. Ayrıca, SageMaker bellekteki yükleme ve boşaltma modellerini yönettiği ve bunları uç noktanın trafik modellerine göre ölçeklendirdiği için konuşlandırma yükünü de azaltır. Ek olarak, tüm SageMaker gerçek zamanlı uç noktaları, modelleri yönetmek ve izlemek için yerleşik özelliklerden yararlanır. gölge varyantları, otomatik ölçeklendirmeve yerel entegrasyon Amazon Bulut İzleme (daha fazla bilgi için bkz. Çok Modelli Uç Nokta Dağıtımları için CloudWatch Metrikleri).
Özel Triton topluluk modelleri
Veriff'in Triton Inference Server'ı kullanmaya karar vermesinin birkaç nedeni vardı; başlıcaları:
- Veri bilimcilerinin, model yapıt dosyalarını standart bir dizin biçiminde düzenleyerek modellerden REST API'leri oluşturmasına olanak tanır (kod çözümü yok)
- Tüm önemli AI çerçeveleriyle uyumludur (PyTorch, Tensorflow, XGBoost ve daha fazlası)
- ML'ye özel düşük seviye ve sunucu optimizasyonları sağlar. dinamik yığınlama isteklerin
Triton'u kullanmak, veri bilimcilerinin modelleri kolaylıkla dağıtmalarına olanak tanır çünkü REST API'leri oluşturmak için kod yazmak yerine yalnızca biçimlendirilmiş model depoları oluşturmaları gerekir (Triton ayrıca Python modelleri özel çıkarım mantığı gerekiyorsa). Bu, model dağıtım süresini azaltır ve veri bilimcilerine, modelleri dağıtmak yerine oluşturmaya odaklanmaları için daha fazla zaman tanır.
Triton'un bir diğer önemli özelliği de inşa etmenize olanak sağlamasıdır. modeli topluluklarıbirbirine zincirlenmiş model gruplarıdır. Bu topluluklar sanki tek bir Triton modeliymiş gibi çalıştırılabilir. Veriff şu anda Python modellerini kullanarak (daha önce belirtildiği gibi) her ML modelinde ön işleme ve son işleme mantığını dağıtmak için bu özelliği kullanıyor ve modeller üretimde kullanıldığında giriş verilerinde veya model çıkışında herhangi bir uyumsuzluk olmamasını sağlıyor.
Bu iş yükü için tipik bir Triton model deposunun görünümü aşağıdadır:
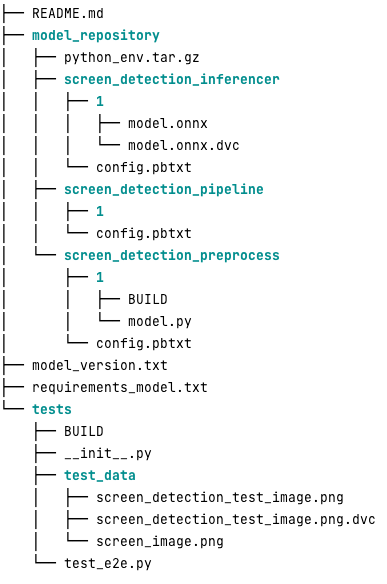
The model.py Dosya ön işleme ve son işleme kodunu içerir. Eğitilen model ağırlıkları screen_detection_inferencer dizin, model sürümü altında 1 (bu örnekte model ONNX formatındadır ancak TensorFlow, PyTorch formatı veya diğerleri de olabilir). Topluluk modeli tanımı şuradadır: screen_detection_pipeline Adımlar arasındaki giriş ve çıkışların bir yapılandırma dosyasında eşlendiği dizin.
Python modellerini çalıştırmak için gereken ek bağımlılıklar bir belgede ayrıntılı olarak açıklanmıştır. requirements.txt dosyasıdır ve bir Conda ortamı oluşturmak için conda paketlenmesi gerekir (python_env.tar.gz). Daha fazla bilgi için bkz. Python Çalışma Zamanını ve Kitaplıklarını Yönetme. Ayrıca Python adımlarına ilişkin yapılandırma dosyalarının şunu işaret etmesi gerekir: python_env.tar.gz ile EXECUTION_ENV_PATH Direktif.
Daha sonra model klasörünün TAR ile sıkıştırılması ve kullanılarak yeniden adlandırılması gerekir. model_version.txt. Son olarak ortaya çıkan <model_name>_<model_version>.tar.gz dosya şuraya kopyalanır: Amazon Basit Depolama Hizmeti (Amazon S3) kovası MME'ye bağlanarak SageMaker'ın modeli tespit etmesine ve sunmasına olanak tanır.
Model versiyonlama ve sürekli dağıtım
Önceki bölümde açıkça görüldüğü gibi, bir Triton model deposu oluşturmak basittir. Ancak, dağıtmak için gerekli tüm adımların çalıştırılması sıkıcıdır ve manuel olarak çalıştırıldığında hataya açıktır. Bunun üstesinden gelmek için Veriff, veri bilimcilerinin Gitflow benzeri bir yaklaşımla işbirliği yaptığı MME'lere dağıtılacak tüm modelleri içeren bir monorepo oluşturdu. Bu monorepo aşağıdaki özelliklere sahiptir:
- Kullanılarak yönetilir Pantolon.
- Black ve MyPy gibi kod kalitesi araçları Pants kullanılarak uygulanır.
- Her model için, model çıktısının belirli bir model girdisi için beklenen çıktı olup olmadığını kontrol eden birim testleri tanımlanır.
- Model ağırlıkları model depolarının yanında saklanır. Bu ağırlıklar büyük ikili dosyalar olabilir, dolayısıyla CVD bunları Git ile sürümlendirilmiş bir şekilde senkronize etmek için kullanılır.
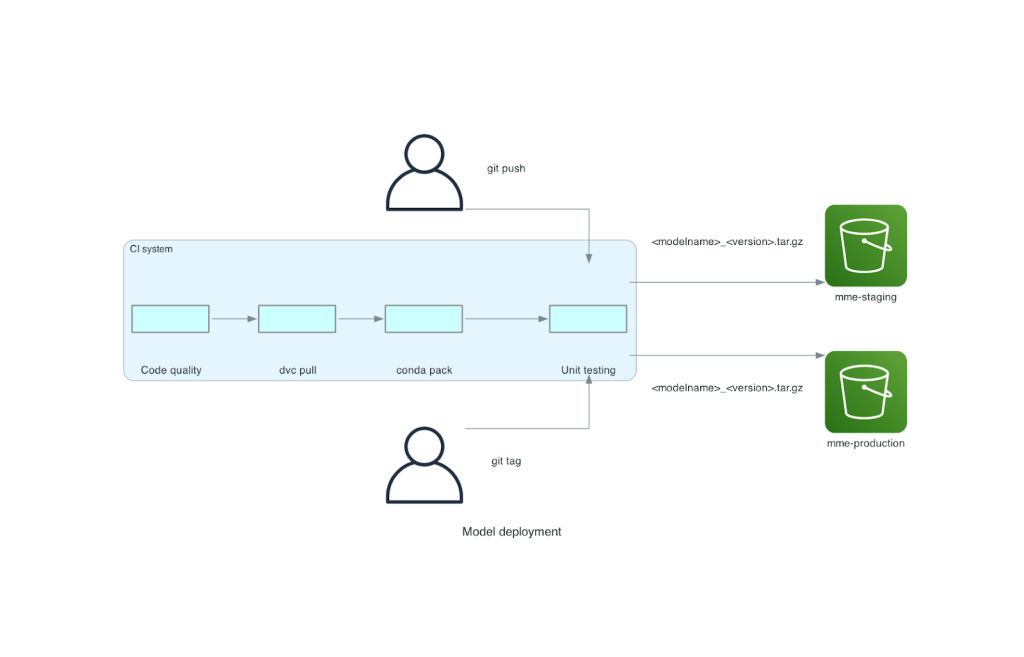
Bu monorepo, sürekli entegrasyon (CI) aracıyla entegre edilmiştir. Repoya veya yeni modele yapılan her yeni aktarım için aşağıdaki adımlar gerçekleştirilir:
- Kod kalite kontrolünü geçin.
- Model ağırlıklarını indirin.
- Conda ortamını oluşturun.
- Conda ortamını kullanarak bir Triton sunucusunu başlatın ve bunu birim testlerinde tanımlanan istekleri işlemek için kullanın.
- Son model TAR dosyasını oluşturun (
<model_name>_<model_version>.tar.gz).
Bu adımlar, modellerin dağıtım için gereken kaliteye sahip olmasını sağlar; böylece bir repo şubesine yapılan her gönderimde, elde edilen TAR dosyası (başka bir CI adımında) hazırlama S3 klasörüne kopyalanır. Ana dalda gönderimler yapıldığında model dosyası üretim S3 klasörüne kopyalanır. Aşağıdaki şemada bu CI/CD sistemi gösterilmektedir.
Maliyet ve dağıtım hızı avantajları
MME'lerin kullanılması, Veriff'in modelleri üretime dağıtmak için monorepo yaklaşımını kullanmasına olanak tanır. Özetle Veriff'in yeni model konuşlandırma iş akışı aşağıdaki adımlardan oluşuyor:
- Yeni model veya model sürümüyle monorepo'da bir dal oluşturun.
- Bir geliştirme makinesinde birim testlerini tanımlayın ve çalıştırın.
- Model hazırlama ortamında test edilmeye hazır olduğunda dalı itin.
- Model üretimde kullanılmaya hazır olduğunda dalı ana ile birleştirin.
Bu yeni çözüm uygulandığında Veriff'te bir modelin devreye alınması, geliştirme sürecinin basit bir parçasıdır. Yeni model geliştirme süresi 10 günden ortalama 2 güne düştü.
SageMaker'ın yönetilen altyapı tedariki ve otomatik ölçeklendirme özellikleri, Veriff'e ek faydalar sağladı. Onlar kullandılar Başlatma PerÖrneği Trafik modellerine göre ölçeklendirme sağlayan CloudWatch ölçümü, güvenilirlikten ödün vermeden maliyetlerden tasarruf sağlar. Metriğin eşik değerini tanımlamak için gecikme ile maliyet arasındaki en iyi dengeyi bulmak amacıyla hazırlama uç noktasında yük testi gerçekleştirdiler.
Yedi üretim modelini MME'lere dağıttıktan ve harcamaları analiz ettikten sonra Veriff, orijinal Kubernetes tabanlı çözümle karşılaştırıldığında GPU modeli hizmet maliyetinde %75'lik bir azalma bildirdi. Şirketin DevOps mühendislerinin bulut sunucularını manuel olarak sağlama yükü ortadan kalktığı için operasyonel maliyetler de azaldı.
Sonuç
Bu yazıda Veriff'in Kubernetes'te kendi kendine yönetilen model dağıtımı yerine neden Sagemaker MME'leri seçtiğini inceledik. SageMaker, Veriff'in model geliştirme süresini kısaltmasına, mühendislik verimliliğini artırmasına ve iş açısından kritik operasyonlar için gereken performansı korurken gerçek zamanlı çıkarım maliyetini önemli ölçüde düşürmesine olanak tanıyarak, farklılaşmamış ağır yükü üstlenir. Son olarak, yazılım geliştirmedeki en iyi uygulamaları ve SageMaker MME'leri birleştirmenin referans uygulaması olarak kullanılabilecek Veriff'in basit ama etkili model konuşlandırma CI/CD hattını ve model sürüm oluşturma mekanizmasını sergiledik. SageMaker MME'leri kullanarak birden fazla modeli barındırmaya ilişkin kod örneklerini şu adreste bulabilirsiniz: GitHub.
Yazarlar Hakkında
 Ricard Borràs Veriff'te Makine Öğrenimi Kıdemlisi olarak görev yapıyor ve şirketteki MLOps çalışmalarına liderlik ediyor. Şirkette bir Veri Bilimi Platformu oluşturarak ve çeşitli açık kaynak çözümlerini AWS hizmetleriyle birleştirerek veri bilimcilerinin daha hızlı ve daha iyi AI/ML ürünleri oluşturmasına yardımcı oluyor.
Ricard Borràs Veriff'te Makine Öğrenimi Kıdemlisi olarak görev yapıyor ve şirketteki MLOps çalışmalarına liderlik ediyor. Şirkette bir Veri Bilimi Platformu oluşturarak ve çeşitli açık kaynak çözümlerini AWS hizmetleriyle birleştirerek veri bilimcilerinin daha hızlı ve daha iyi AI/ML ürünleri oluşturmasına yardımcı oluyor.
 Joao Moura İspanya merkezli AWS'de AI/ML Uzman Çözüm Mimarıdır. Müşterilere derin öğrenme modelinin büyük ölçekli eğitimi ve çıkarım optimizasyonunun yanı sıra daha geniş anlamda AWS'de büyük ölçekli makine öğrenimi platformları oluşturma konusunda yardımcı oluyor.
Joao Moura İspanya merkezli AWS'de AI/ML Uzman Çözüm Mimarıdır. Müşterilere derin öğrenme modelinin büyük ölçekli eğitimi ve çıkarım optimizasyonunun yanı sıra daha geniş anlamda AWS'de büyük ölçekli makine öğrenimi platformları oluşturma konusunda yardımcı oluyor.
 miguel ferreira Helsinki, Finlandiya merkezli AWS'de Kıdemli Çözüm Mimarı olarak çalışıyor. Yapay zeka/ML'ye ömür boyu ilgi duyuldu ve birden fazla müşterinin Amazon SageMaker'ı makine öğrenimi iş akışlarına entegre etmesine yardımcı oldu.
miguel ferreira Helsinki, Finlandiya merkezli AWS'de Kıdemli Çözüm Mimarı olarak çalışıyor. Yapay zeka/ML'ye ömür boyu ilgi duyuldu ve birden fazla müşterinin Amazon SageMaker'ı makine öğrenimi iş akışlarına entegre etmesine yardımcı oldu.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/how-veriff-decreased-deployment-time-by-80-using-amazon-sagemaker-multi-model-endpoints/

