Bu yazıda United Airlines'ın iş birliğiyle nasıl çalıştığını tartışacağız. Amazon Makine Öğrenimi Çözümleri Laboratuvarı, yolcu belgelerinin işlenmesini otomatikleştirmek için AWS üzerinde aktif bir öğrenme çerçevesi oluşturun.
“Yolcularımıza en iyi uçuş deneyimini sunmak ve dahili iş sürecimizi olabildiğince verimli hale getirmek amacıyla AWS'de otomatik makine öğrenimi tabanlı bir belge işleme hattı geliştirdik. Bu uygulamaların yanı sıra bilgisayarlı görme gibi diğer veri yöntemlerini kullanan uygulamalara da güç vermek için verilere hızlı bir şekilde açıklama eklemek, modelleri eğitmek ve değerlendirmek ve hızlı bir şekilde yinelemek için sağlam ve verimli bir iş akışına ihtiyacımız var. Birkaç ay süren kurs boyunca United, AWS CDK'yı kullanarak yeniden kullanılabilir, büyük/küçük harften bağımsız bir aktif öğrenme iş akışı tasarlamak ve geliştirmek için Amazon Machine Learning Solutions Labs ile ortaklık kurdu. Bu iş akışı, insanların etiketleme çabasını en aza indirmemize, hızlı bir şekilde güçlü model performansı sunmamıza ve veri kaymasına uyum sağlamamıza olanak sağlayacağından, yapılandırılmamış veri tabanlı makine öğrenimi uygulamalarımızın temelini oluşturacaktır."
– Jon Nelson, United Airlines Veri Bilimi ve Makine Öğrenimi Kıdemli Müdürü.
Sorun
United'ın Dijital Teknoloji ekibi, iş sonuçlarını artırmak ve müşteri memnuniyeti düzeylerini yüksek tutmak için en son teknolojiyle birlikte çalışan, dünya çapında çeşitliliğe sahip kişilerden oluşur. Belge işleme hatlarını otomatikleştirmek için bilgisayarlı görme (CV) ve doğal dil işleme (NLP) gibi makine öğrenimi (ML) tekniklerinden yararlanmak istiyorlardı. Bu stratejinin bir parçası olarak yolcu kimliklerini doğrulamak için şirket içi bir pasaport analiz modeli geliştirdiler. Süreç, çok maliyetli olan makine öğrenimi modellerini eğitmek için manuel ek açıklamalara dayanır.
United, pasaport bilgilerinin doğrulanmasını otomatikleştirmek, yolcu kimliklerini doğrulamak ve olası sahte belgeleri tespit etmek için esnek, dayanıklı ve uygun maliyetli bir makine öğrenimi çerçevesi oluşturmak istiyordu. United'ın gelecekteki yolcu artışı karşısında birinci sınıf hizmet sunmaya devam etmesine olanak tanıyan bu hedefe ulaşmaya yardımcı olmak için ML Çözüm Laboratuvarı ile iletişime geçtiler.
Çözüme genel bakış
Ortak ekibimiz, aşağıdakilerle desteklenen aktif bir öğrenme çerçevesi tasarladı ve geliştirdi: AWS Bulut Geliştirme Kiti (AWS CDK), gerekli tüm AWS hizmetlerini program aracılığıyla yapılandırır ve sağlar. Çerçevenin kullandığı Amazon Adaçayı Yapıcı etiketlenmemiş verileri işlemek, yumuşak etiketler oluşturmak, manuel etiketleme işlerini başlatmak için Amazon SageMaker Yer Gerçeğive elde edilen veri kümesiyle isteğe bağlı bir ML modelini eğitir. Kullandığımız Amazon Metin Yazısı ad ve pasaport numarası gibi belirli belge alanlarından bilgi çıkarmayı otomatikleştirmek için. Yüksek düzeyde yaklaşım aşağıdaki diyagramla açıklanabilir.
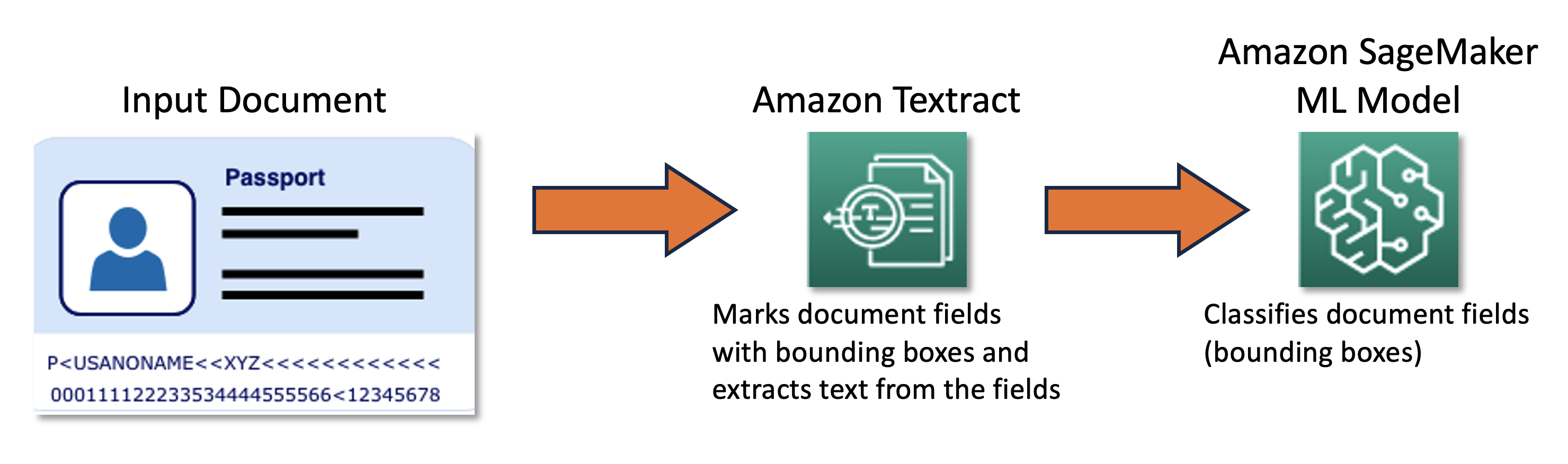
Veri
Bu sorunun birincil veri kümesi, kişisel bilgilerin (isim, doğum tarihi, pasaport numarası vb.) çıkarılması gereken on binlerce ana sayfa pasaport resminden oluşur. Görüntü boyutu, düzeni ve yapısı belgeyi veren ülkeye göre değişir. Bu görüntüleri, aktif öğrenme hattı (otomatik etiketleme ve çıkarım) için işlevsel girdiyi oluşturan bir dizi tek tip küçük resim halinde normalleştiririz.
İkinci veri kümesi, ham pasaport görüntülerini, küçük resim görüntülerini ve yumuşak etiketler ve sınırlayıcı kutu konumları gibi etiket bilgilerini ilişkilendiren JSON satırı formatlı bildirim dosyalarını içerir. Manifest dosyaları, çeşitli AWS hizmetlerinden elde edilen sonuçları birleşik bir biçimde depolayan bir meta veri kümesi görevi görür ve aktif öğrenme hattını United tarafından kullanılan alt hizmetlerden ayırır. Aşağıdaki diyagram bu mimariyi göstermektedir.
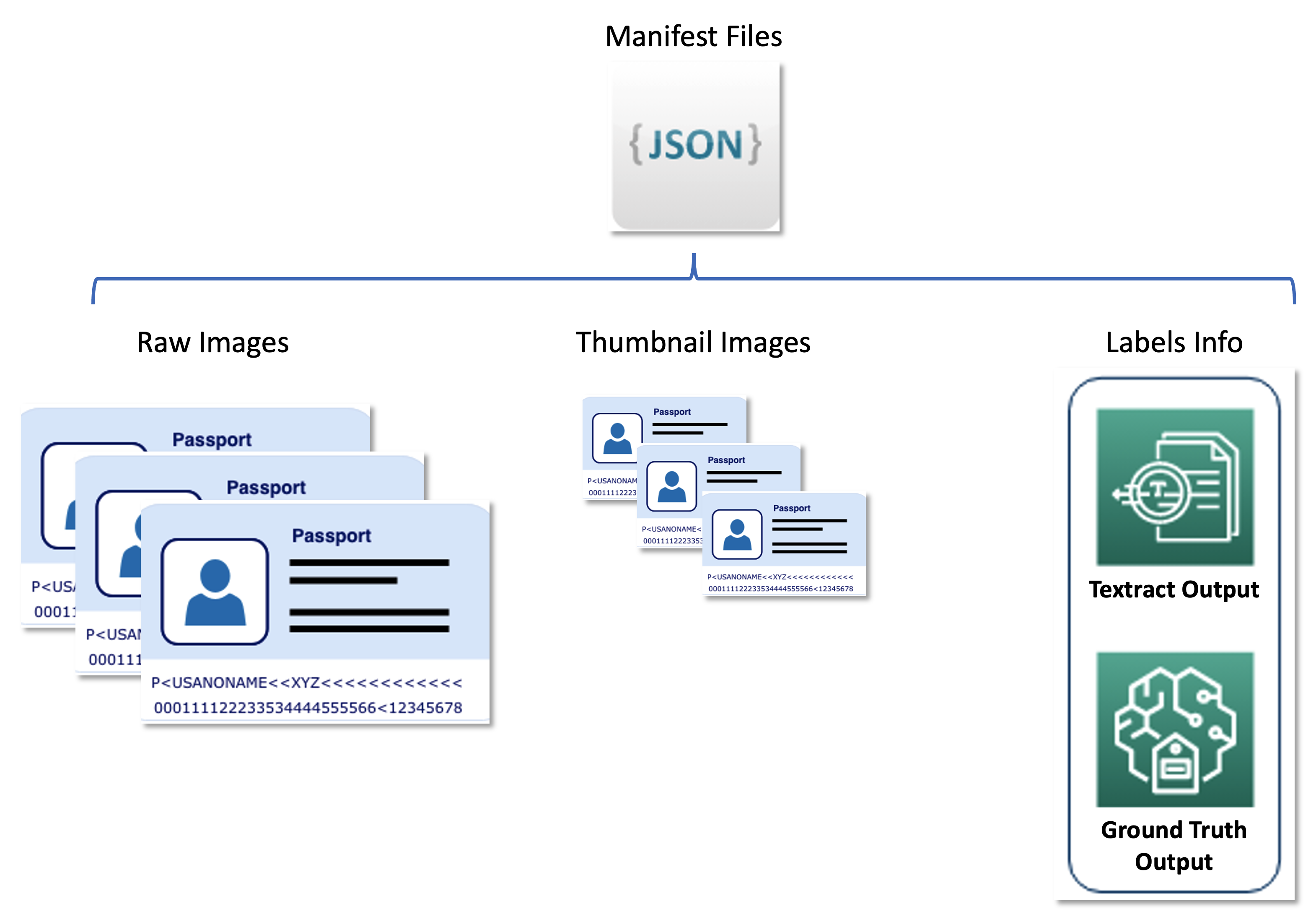
Aşağıdaki kod örnek bir bildirim dosyasıdır:
Çözüm bileşenleri
Çözüm iki ana bileşenden oluşuyor:
- Modelin eğitilmesinden sorumlu olan bir ML çerçevesi
- Eğitimli model doğruluğunun uygun maliyetli bir şekilde iyileştirilmesinden sorumlu bir otomatik etiketleme hattı
ML çerçevesi, ML modelinin eğitilmesinden ve bunun bir SageMaker uç noktası olarak dağıtılmasından sorumludur. Otomatik etiketleme hattı, SageMaker Ground Truth işlerini otomatikleştirmeye ve bu işler aracılığıyla etiketleme için görüntüleri örneklemeye odaklanıyor.
İki bileşen birbirinden ayrılmıştır ve yalnızca otomatik etiketleme hattı tarafından üretilen etiketli görüntüler kümesi aracılığıyla etkileşime girer. Yani etiketleme hattı, daha sonra ML çerçevesi tarafından ML modelini eğitmek için kullanılacak etiketleri oluşturur.
Makine öğrenimi çerçevesi
ML Solutions Lab ekibi, ML çerçevesini en son teknoloji LayoutLMV2 modelinin Hugging Face uygulamasını kullanarak oluşturdu (LayoutLMv2: Görsel Açıdan Zengin Belge Anlayışı için Çok Modlu Ön Eğitim, Yang Xu ve diğerleri). Eğitim, ön işlemci görevi gören ve ilgilenilen metnin etrafında sınırlayıcı kutular üreten Amazon Textract çıktılarına dayanıyordu. Çerçeve, dağıtılmış eğitim kullanır ve ek bağımlılıklarla (önceden oluşturulmuş SageMaker Docker görüntüsünde eksik olan ancak Hugging Face LayoutLMv2 için gerekli olan bağımlılıklar) SageMaker'ın önceden oluşturulmuş Hugging Face görüntüsünü temel alan özel bir Docker konteynerinde çalışır.
ML modeli, belge alanlarını aşağıdaki 11 sınıfta sınıflandırmak için eğitildi:
Eğitim hattı aşağıdaki şemada özetlenebilir.
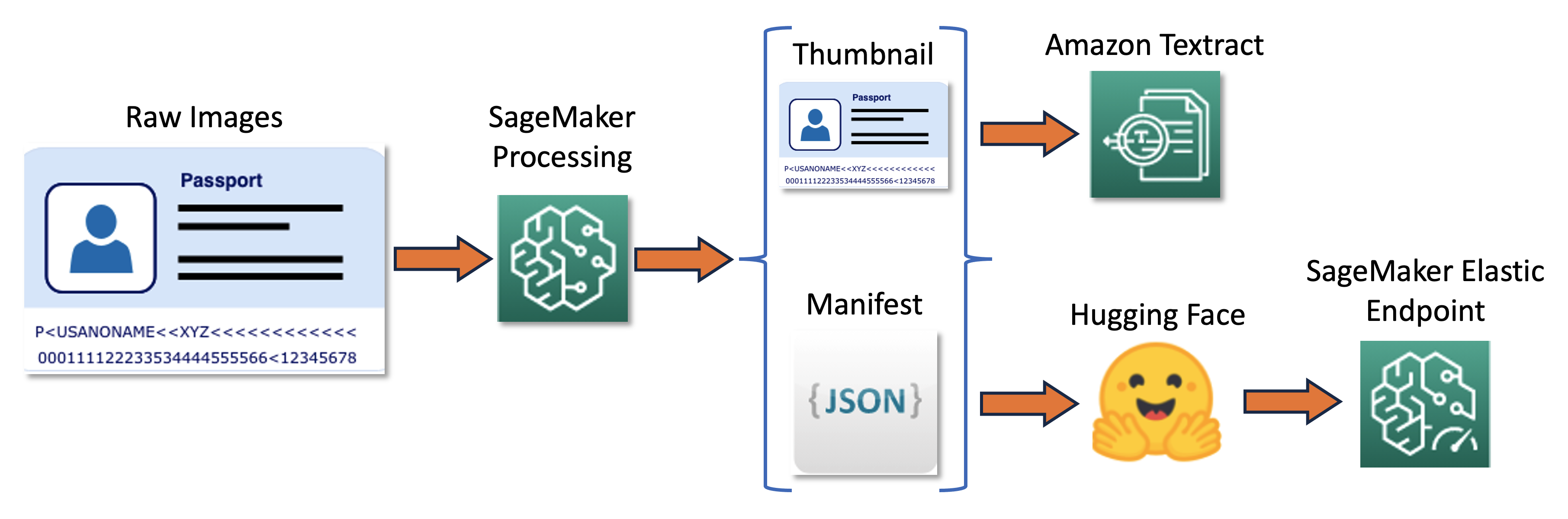
İlk olarak, bir grup ham görüntüyü yeniden boyutlandırıp normalleştirerek küçük resimlere dönüştürüyoruz. Aynı zamanda, toplu işteki ham ve küçük resimlerle ilgili bilgilerin yer aldığı, görüntü başına bir satır içeren bir JSON satır bildirim dosyası oluşturulur. Daha sonra, küçük resim görsellerindeki metin sınırlayıcı kutuları çıkarmak için Amazon Textract'ı kullanıyoruz. Amazon Texttract tarafından üretilen tüm bilgiler aynı manifest dosyasına kaydedilir. Son olarak, daha sonra SageMaker uç noktası olarak konuşlandırılan bir modeli eğitmek için küçük resim görüntülerini ve bildirim verilerini kullanırız.
Otomatik etiketleme ardışık düzeni
Aşağıdaki işlevleri gerçekleştirmek üzere tasarlanmış bir otomatik etiketleme hattı geliştirdik:
- Etiketlenmemiş bir veri kümesinde periyodik toplu çıkarımı çalıştırın.
- Sonuçları belirli bir belirsizlik örnekleme stratejisine göre filtreleyin.
- Örneklenen görüntüleri insan iş gücü kullanarak etiketlemek için bir SageMaker Ground Truth işini tetikleyin.
- Daha sonraki model iyileştirmeleri için eğitim veri kümesine yeni etiketli görüntüler ekleyin.
Belirsizlik örnekleme stratejisi, model doğruluğunun iyileştirilmesine en fazla katkıda bulunabilecek görüntüleri seçerek insan etiketleme işine gönderilen görüntü sayısını azaltır. İnsan etiketlemesi pahalı bir iş olduğundan, bu tür bir numune alma önemli bir maliyet azaltma tekniğidir. Depolanan bir parametre olarak seçilebilen dört örnekleme stratejisini destekliyoruz. Parametre Deposu, yeteneği AWS Sistem Yöneticisi:
- En az güven
- Marj güveni
- Güven oranı
- Entropi
Otomatik etiketleme iş akışının tamamı şu şekilde uygulandı: AWS Basamak İşlevleriişleme işini (toplu çıkarım için elastik uç nokta olarak adlandırılır), belirsizlik örneklemesini ve SageMaker Ground Truth'u düzenleyen. Aşağıdaki şemada Step Functions iş akışı gösterilmektedir.
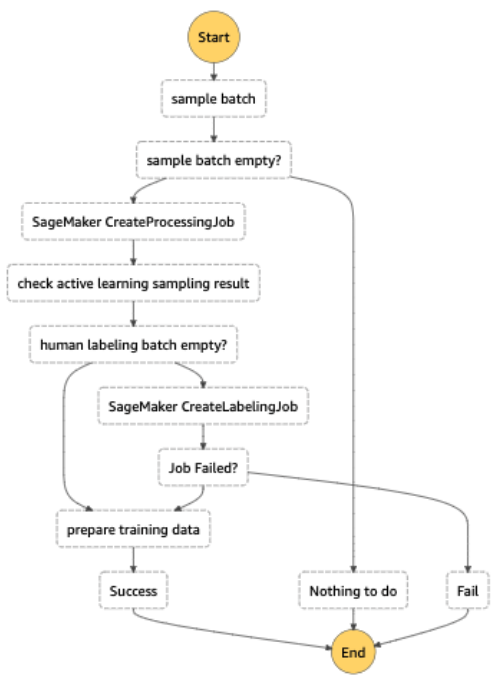
Maliyet etkinliği
Etiketleme maliyetlerini etkileyen ana faktör manuel açıklamadır. Bu çözümü uygulamaya koymadan önce United ekibinin, pahalı manuel veri açıklaması ve üçüncü taraf OCR ayrıştırma tekniklerini gerektiren kural tabanlı bir yaklaşım kullanması gerekiyordu. Çözümümüzle United, yalnızca en büyük model iyileştirmeleriyle sonuçlanacak görüntüleri manuel olarak etiketleyerek manuel etiketleme iş yükünü azalttı. Çerçeve modelden bağımsız olduğundan, diğer benzer senaryolarda da kullanılabilir ve değerini pasaport resimlerinin ötesinde çok daha geniş bir belge kümesine genişletebilir.
Aşağıdaki varsayımlara dayanarak bir maliyet analizi yaptık:
- Her grup 1,000 görsel içerir
- Eğitim mlg4dn.16xlarge örneği kullanılarak gerçekleştirilir
- Çıkarım bir mlg4dn.xlarge örneğinde gerçekleştirilir
- Eğitim, her partiden sonra %10'luk açıklamalı etiketlerle yapılır.
- Her eğitim turu aşağıdaki doğruluk iyileştirmeleriyle sonuçlanır:
- İlk partiden sonra %50
- İkinci partiden sonra %25
- Üçüncü partiden sonra %10
Analizimiz, aktif öğrenme olmadan eğitim maliyetinin sabit ve yüksek kaldığını gösteriyor. Aktif öğrenmenin dahil edilmesi, her yeni veri grubuyla birlikte maliyetlerin katlanarak azalmasıyla sonuçlanır.
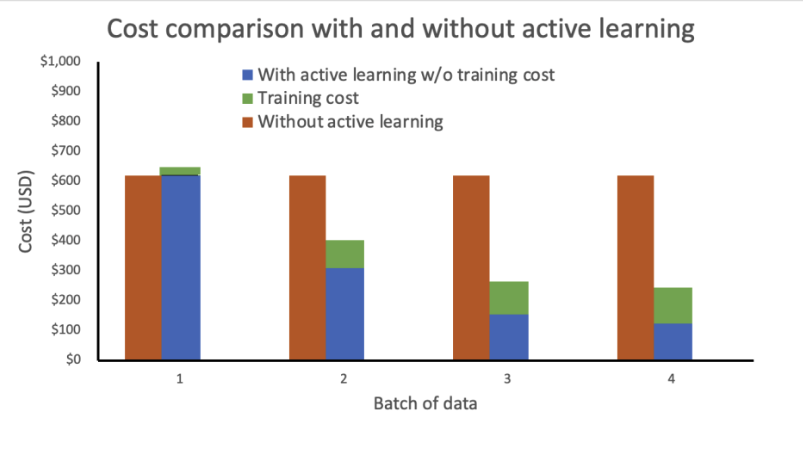
Otomatik ölçeklendirme politikası ekleyerek çıkarım uç noktasını elastik bir uç nokta olarak dağıtarak maliyetleri daha da düşürdük. Uç nokta kaynaklarının ölçeği sıfır ile yapılandırılmış maksimum örnek sayısı arasında artırılabilir veya azaltılabilir.
Nihai çözüm mimarisi
Odak noktamız, United ekibinin ölçeklenebilir ve esnek bir bulut uygulaması oluştururken işlevsel gereksinimlerini karşılamasına yardımcı olmaktı. ML Solutions Lab ekibi, AWS CDK'nın yardımıyla tüm bulut kaynaklarının ve hizmetlerinin yönetimini ve tedarikini otomatikleştiren, üretime hazır eksiksiz bir çözüm geliştirdi. Nihai bulut uygulaması tek bir uygulama olarak devreye alındı AWS CloudFormation her biri tek bir işlevsel bileşeni temsil eden dört iç içe yığından oluşan yığın.
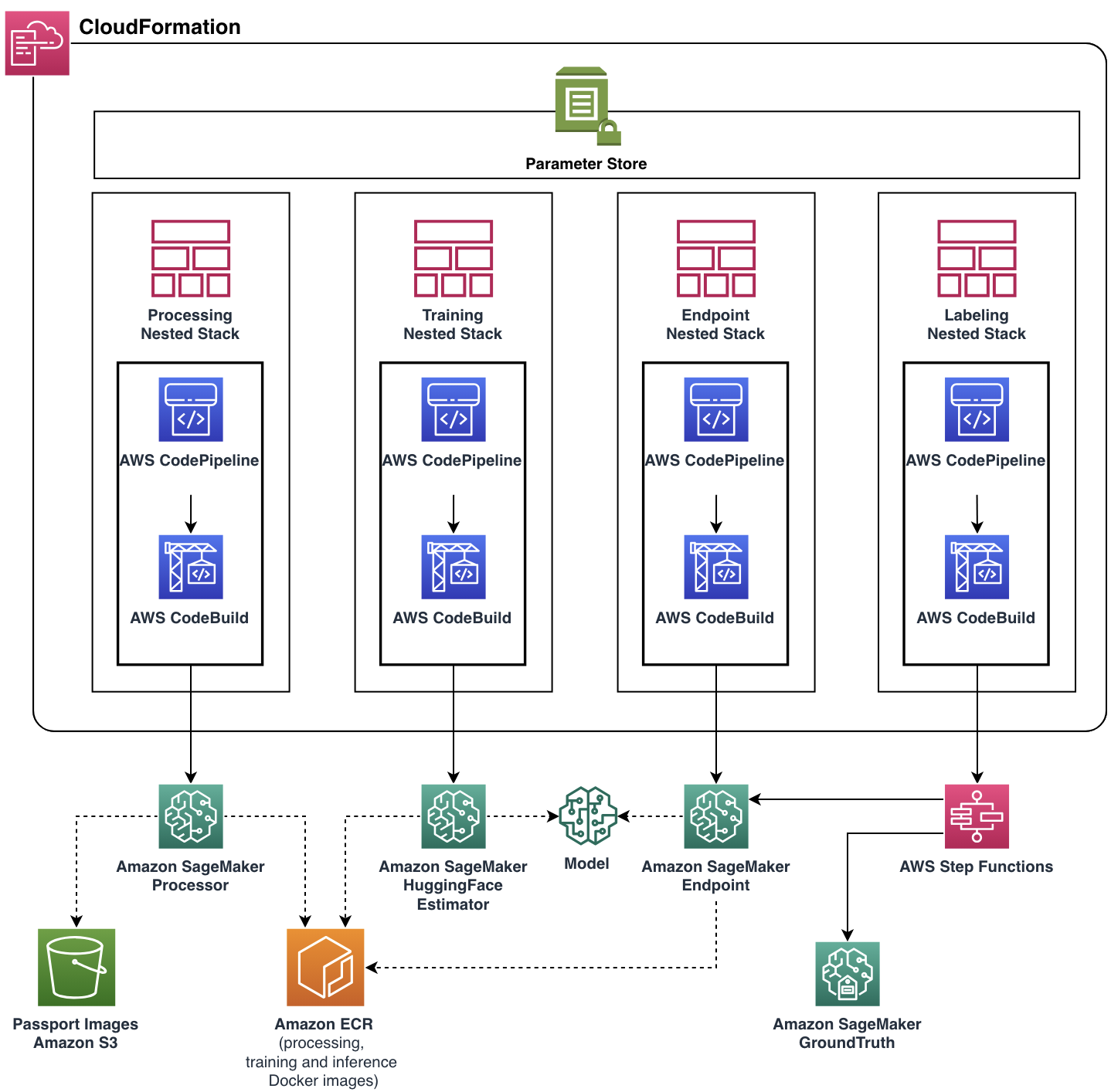
Docker görüntüleri, uç nokta otomatik ölçeklendirme politikası ve daha fazlası dahil olmak üzere hemen hemen her işlem hattı özelliği, Parametre Deposu aracılığıyla parametrelendirildi. Böyle bir esneklikle, aynı işlem hattı örneği geniş bir ayar yelpazesiyle çalıştırılabilir ve bu da deneme olanağı sağlar.
Sonuç
Bu yazıda United Airlines'ın ML Solutions Lab ile iş birliği yaparak yolcu belgelerinin işlenmesini otomatikleştirmek için AWS üzerinde nasıl aktif bir öğrenme çerçevesi oluşturduğunu tartıştık. Çözümün United'ın otomasyon hedeflerinin iki önemli yönü üzerinde büyük etkisi oldu:
- Reus yeteneği – Modüler tasarım ve modelden bağımsız uygulama sayesinde, United Airlines bu çözümü hemen hemen tüm diğer otomatik etiketleme makine öğrenimi kullanım durumlarında yeniden kullanabilir.
- Tekrarlanan maliyet düşüşü – United ekibi, manuel ve otomatik etiketleme süreçlerini akıllıca birleştirerek ortalama etiketleme maliyetlerini azaltabilir ve pahalı üçüncü taraf etiketleme hizmetlerinin yerini alabilir.
Benzer bir çözümü uygulamakla ilgileniyorsanız veya ML Çözüm Laboratuvarı hakkında daha fazla bilgi edinmek istiyorsanız hesap yöneticinizle iletişime geçin veya şu adresten bizi ziyaret edin: Amazon Makine Öğrenimi Çözümleri Laboratuvarı.
Yazarlar Hakkında
 Xin Gu United Airlines'ın Gelişmiş Analitik ve İnovasyon bölümünde Baş Veri Bilimcisi - Makine Öğrenimidir. Makine öğrenimi destekli belge anlama otomasyonunun tasarlanmasına önemli ölçüde katkıda bulundu ve çeşitli görevler ve modeller genelinde veri açıklaması aktif öğrenme iş akışlarının genişletilmesinde önemli bir rol oynadı. Uzmanlığı, United Airlines'ta akıllı teknolojik gelişmeler alanında dikkate değer ilerlemeler elde ederek yapay zekanın etkinliğini ve verimliliğini artırmada yatmaktadır.
Xin Gu United Airlines'ın Gelişmiş Analitik ve İnovasyon bölümünde Baş Veri Bilimcisi - Makine Öğrenimidir. Makine öğrenimi destekli belge anlama otomasyonunun tasarlanmasına önemli ölçüde katkıda bulundu ve çeşitli görevler ve modeller genelinde veri açıklaması aktif öğrenme iş akışlarının genişletilmesinde önemli bir rol oynadı. Uzmanlığı, United Airlines'ta akıllı teknolojik gelişmeler alanında dikkate değer ilerlemeler elde ederek yapay zekanın etkinliğini ve verimliliğini artırmada yatmaktadır.
 Jon Nelson United Airlines'ta Veri Bilimi ve Makine Öğrenimi Kıdemli Müdürüdür.
Jon Nelson United Airlines'ta Veri Bilimi ve Makine Öğrenimi Kıdemli Müdürüdür.
 Alex Goryainov Amazon AWS'de Makine Öğrenimi Mühendisidir. AWS CDK tarafından desteklenen aktif öğrenme ve otomatik etiketleme işlem hattının mimarisini oluşturuyor ve temel bileşenlerini uyguluyor. Alex, MLOps, bulut bilişim mimarisi, istatistiksel veri analizi ve büyük ölçekli veri işleme konularında uzmandır.
Alex Goryainov Amazon AWS'de Makine Öğrenimi Mühendisidir. AWS CDK tarafından desteklenen aktif öğrenme ve otomatik etiketleme işlem hattının mimarisini oluşturuyor ve temel bileşenlerini uyguluyor. Alex, MLOps, bulut bilişim mimarisi, istatistiksel veri analizi ve büyük ölçekli veri işleme konularında uzmandır.
 Vishal Das Amazon ML Solutions Lab'da Uygulamalı Bilim Adamıdır. MLSL'den önce Vishal, Enerji, AWS'de Çözüm Mimarıydı. Doktora derecesini Jeofizik alanında, doktora yan dalını ise Stanford Üniversitesi'nden İstatistik alanında aldı. Müşterilerin büyük düşünmelerine ve iş sonuçları sunmalarına yardımcı olmak için onlarla birlikte çalışmaya kararlıdır. Makine öğrenimi ve iş sorunlarının çözümünde uygulanması konusunda uzmandır.
Vishal Das Amazon ML Solutions Lab'da Uygulamalı Bilim Adamıdır. MLSL'den önce Vishal, Enerji, AWS'de Çözüm Mimarıydı. Doktora derecesini Jeofizik alanında, doktora yan dalını ise Stanford Üniversitesi'nden İstatistik alanında aldı. Müşterilerin büyük düşünmelerine ve iş sonuçları sunmalarına yardımcı olmak için onlarla birlikte çalışmaya kararlıdır. Makine öğrenimi ve iş sorunlarının çözümünde uygulanması konusunda uzmandır.
 Tianyi Mao Chicago bölgesi dışında bulunan AWS'de Uygulamalı Bilim Adamıdır. Makine öğrenimi ve derin öğrenme çözümleri oluşturma konusunda 5 yıldan fazla deneyime sahiptir ve insan geri bildirimleriyle bilgisayarlı görme ve takviyeli öğrenmeye odaklanmaktadır. AWS hizmetlerini kullanarak yenilikçi çözümler yaratarak karşılaştıkları zorlukları anlamak ve bunları çözmek için müşterilerle birlikte çalışmaktan hoşlanıyor.
Tianyi Mao Chicago bölgesi dışında bulunan AWS'de Uygulamalı Bilim Adamıdır. Makine öğrenimi ve derin öğrenme çözümleri oluşturma konusunda 5 yıldan fazla deneyime sahiptir ve insan geri bildirimleriyle bilgisayarlı görme ve takviyeli öğrenmeye odaklanmaktadır. AWS hizmetlerini kullanarak yenilikçi çözümler yaratarak karşılaştıkları zorlukları anlamak ve bunları çözmek için müşterilerle birlikte çalışmaktan hoşlanıyor.
 Yunzhi Shi Amazon ML Çözümleri Laboratuvarı'nda Uygulamalı Bilim Adamıdır ve burada farklı sektörlerdeki müşterilerle birlikte çalışarak onların iş zorluklarını çözmek için AWS Bulut hizmetleri üzerine inşa edilen AI/ML çözümlerini düşünmelerine, geliştirmelerine ve dağıtmalarına yardımcı olur. Otomotiv, jeouzaysal, ulaşım ve üretim alanlarındaki müşterilerle çalıştı. Yunzhi doktora derecesini aldı. Austin'deki Texas Üniversitesi'nden Jeofizik alanında.
Yunzhi Shi Amazon ML Çözümleri Laboratuvarı'nda Uygulamalı Bilim Adamıdır ve burada farklı sektörlerdeki müşterilerle birlikte çalışarak onların iş zorluklarını çözmek için AWS Bulut hizmetleri üzerine inşa edilen AI/ML çözümlerini düşünmelerine, geliştirmelerine ve dağıtmalarına yardımcı olur. Otomotiv, jeouzaysal, ulaşım ve üretim alanlarındaki müşterilerle çalıştı. Yunzhi doktora derecesini aldı. Austin'deki Texas Üniversitesi'nden Jeofizik alanında.
 Diego Socolinsky AWS Üretken Yapay Zeka İnovasyon Merkezi'nde Kıdemli Uygulamalı Bilim Yöneticisidir ve burada Doğu ABD ve Latin Amerika bölgelerine yönelik dağıtım ekibine liderlik etmektedir. Makine öğrenimi ve bilgisayarlı görme alanında yirmi yıldan fazla deneyime sahiptir ve Johns Hopkins Üniversitesi'nden matematik alanında doktora derecesine sahiptir.
Diego Socolinsky AWS Üretken Yapay Zeka İnovasyon Merkezi'nde Kıdemli Uygulamalı Bilim Yöneticisidir ve burada Doğu ABD ve Latin Amerika bölgelerine yönelik dağıtım ekibine liderlik etmektedir. Makine öğrenimi ve bilgisayarlı görme alanında yirmi yıldan fazla deneyime sahiptir ve Johns Hopkins Üniversitesi'nden matematik alanında doktora derecesine sahiptir.
 Xin Chen şu anda Amazon People eXperience Technology (PXT, diğer adıyla HR) Central Science'da İnsan Bilimi Çözümleri Laboratuvarı Başkanıdır. Mekanizmaları ve süreç iyileştirmelerini proaktif olarak belirlemek ve başlatmak için üretim düzeyinde bilim çözümleri oluşturmak üzere uygulamalı bilim adamlarından oluşan bir ekibe liderlik ediyor. Daha önce AWS Makine Öğrenimi Çözümleri Laboratuvarı'nda Orta ABD, Büyük Çin Bölgesi, LATAM ve Otomotiv Dikey'in başkanlığını yapıyordu. AWS müşterilerinin, kuruluşlarının en yüksek yatırım getirisi sağlayan makine öğrenimi fırsatlarını ele alacak makine öğrenimi çözümlerini belirlemelerine ve geliştirmelerine yardımcı oldu. Xin, Northwestern Üniversitesi ve Illinois Teknoloji Enstitüsü'nde yardımcı öğretim üyesidir. Doktora derecesini Notre Dame Üniversitesi'nde Bilgisayar Bilimi ve Mühendisliği alanında aldı.
Xin Chen şu anda Amazon People eXperience Technology (PXT, diğer adıyla HR) Central Science'da İnsan Bilimi Çözümleri Laboratuvarı Başkanıdır. Mekanizmaları ve süreç iyileştirmelerini proaktif olarak belirlemek ve başlatmak için üretim düzeyinde bilim çözümleri oluşturmak üzere uygulamalı bilim adamlarından oluşan bir ekibe liderlik ediyor. Daha önce AWS Makine Öğrenimi Çözümleri Laboratuvarı'nda Orta ABD, Büyük Çin Bölgesi, LATAM ve Otomotiv Dikey'in başkanlığını yapıyordu. AWS müşterilerinin, kuruluşlarının en yüksek yatırım getirisi sağlayan makine öğrenimi fırsatlarını ele alacak makine öğrenimi çözümlerini belirlemelerine ve geliştirmelerine yardımcı oldu. Xin, Northwestern Üniversitesi ve Illinois Teknoloji Enstitüsü'nde yardımcı öğretim üyesidir. Doktora derecesini Notre Dame Üniversitesi'nde Bilgisayar Bilimi ve Mühendisliği alanında aldı.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/how-united-airlines-built-a-cost-efficient-optical-character-recognition-active-learning-pipeline/

