Yaklaşan Olimpiyat Oyunlarına hazırlanırken, çok uluslu bir Amerikan şirketi ve dünyanın en büyük teknoloji şirketlerinden biri olan Intel®, 3D Sporcu Takibi (3DAT) etrafında bir konsept geliştirdi. 3DAT, yayınlar sırasında hayran katılımını artırmak için yarışan sporcuların gerçek zamanlı dijital modellerini oluşturmaya yönelik bir makine öğrenimi (ML) çözümüdür. Intel, seçkin sporculara koçluk yapmak ve onları eğitmek amacıyla bu teknolojiden yararlanmak istiyordu.
3D poz rekonstrüksiyonu için klasik bilgisayarla görme yöntemlerinin, bu modellerin çoğunlukla bir atlete ek sensörler yerleştirmeye dayanması ve 3D etiket ve modellerin bulunmaması göz önüne alındığında, çoğu bilim insanı için külfetli olduğu kanıtlanmıştır. Normal cep telefonlarını kullanarak sorunsuz veri toplama mekanizmalarını devreye sokabilsek de, 3B videolardaki bilgi derinliği eksikliği göz önüne alındığında, 2B video verilerini kullanarak 2B modeller geliştirmek zorlu bir iştir. Intel'in 3DAT ekibi, Amazon ML Çözümleri Laboratuvarı (MLSL), antrenörlerin sporcularının performansının biyomekanik ve diğer metriklerini çıkarması için hafif bir çözüm oluşturmak amacıyla 3B videolar üzerinde 2B insan pozu tahmin teknikleri geliştirmek.
Bu benzersiz iş birliği, standart cep telefonlarından alınan 3B videoları girdi olarak kullanan bir 2B çok kişili poz tahmin işlem hattı geliştirmek için Intel'in inovasyon alanındaki zengin tarihini ve Amazon ML Solution Lab'ın bilgisayar görme uzmanlığını bir araya getirdi. Amazon SageMaker Stüdyosu geliştirme ortamı olarak dizüstü bilgisayarlar (SM Studio).
Olimpik Teknoloji Grubu Intel Spor Performansı Direktörü Jonathan Lee, “MLSL ekibi, gereksinimlerimizi dinleyerek ve müşterilerimizin ihtiyaçlarını karşılayacak bir çözüm önererek harika bir iş çıkardı. Ekip, yalnızca iki hafta içinde cep telefonlarıyla çekilen 3B videoları kullanarak bir 2B poz tahmin hattı geliştirerek beklentilerimizi aştı. Makine öğrenimi iş yükümüzü Amazon SageMaker'da standartlaştırarak, modellerimizde ortalama %97 gibi olağanüstü bir doğruluk elde ettik."
Bu gönderi, 3B poz tahmin modellerini nasıl kullandığımızı ve ABD'den dekatloncu ve iki kez Olimpiyat altın madalyası kazanan Ashton Eaton'dan farklı açılar kullanarak toplanan 3B video verileri üzerinde nasıl 2B çıktılar oluşturduğumuzu tartışıyor. Ayrıca, farklı açılardan çekilen videoları hizalamak için iki bilgisayarla görme tekniği sunar, böylece koçların koşu boyunca benzersiz bir 3B koordinat seti kullanmasına olanak tanır.
Zorluklar
İnsan poz tahmin teknikleri, bir sahnede tespit edilen bir kişinin grafiksel bir iskeletini sağlamayı amaçlayan bilgisayar görüşünü kullanır. Kollar, boyun ve kalçalar gibi insan eklemlerine karşılık gelen önceden tanımlanmış anahtar noktaların koordinatlarını içerirler. Bu koordinatlar, poz izleme, duruş analizi ve müteakip değerlendirme gibi daha ileri analizler için vücudun oryantasyonunu yakalamak için kullanılır. Bilgisayar görüşü ve derin öğrenmedeki son gelişmeler, bilim insanlarının, Z ekseninin 3B poz tahminine kıyasla ek içgörüler sağladığı bir 2B alanda poz tahminini keşfetmelerini sağladı. Bu ek içgörüler, daha kapsamlı görselleştirme ve analiz için kullanılabilir. Ancak sıfırdan bir 3B poz tahmin modeli oluşturmak zordur çünkü 3B etiketlerle birlikte görüntüleme verileri gerektirir. Bu nedenle, birçok araştırmacı önceden eğitilmiş 3B poz tahmin modelleri kullanır.
Veri işleme hattı
Birkaç bileşeni kapsayan SM Studio'yu kullanarak aşağıdaki şemada gösterilen uçtan uca bir 3B poz tahmin hattı tasarladık:
- Amazon Basit Depolama Hizmeti Video verilerini barındırmak için (Amazon S3) grubu
- Video verilerini statik görüntülere dönüştürmek için çerçeve çıkarma modülü
- Her çerçevedeki kişilerin sınırlayıcı kutularını algılamak için nesne algılama modülleri
- Gelecekteki değerlendirme amaçları için 2B poz tahmini
- Her çerçevedeki her kişi için 3B koordinatlar oluşturmak için 3B poz tahmin modülü
- Değerlendirme ve görselleştirme modülleri
![]()
![]()
SM Studio, Amazon S3'teki verilere kolay erişim, bilgi işlem yeteneğinin kullanılabilirliği, yazılım ve kitaplık kullanılabilirliği ve makine öğrenimi uygulamaları için entegre bir geliştirme deneyimi (IDE) dahil olmak üzere geliştirme sürecini kolaylaştıran çok çeşitli özellikler sunar.
İlk olarak, S3 kovasındaki video verilerini okuduk ve 2B çerçeveleri, çerçeve düzeyinde geliştirme için taşınabilir bir ağ grafiği (PNG) formatında çıkardık. Bir çerçevede algılanan her bir kişinin sınırlayıcı kutusunu oluşturmak için YOLOv3 nesne algılamayı kullandık. Daha fazla bilgi için, bkz. Apache MXNet ile CNN Tabanlı Dedektörler için Eğitim Süresini Kıyaslama.
Daha sonra, değerlendirme ve görselleştirme için kilit noktaları oluşturmak üzere çerçeveleri ve ilgili sınırlayıcı kutu bilgilerini 3B poz tahmin modeline aktardık. Çerçevelere bir 2B poz tahmin tekniği uyguladık ve geliştirme ve değerlendirme için çerçeve başına kilit noktalar oluşturduk. Aşağıdaki bölümlerde, 3B ardışık düzendeki her bir modülün ayrıntıları ele alınmaktadır.
Veri ön işleme
İlk adım, aşağıdaki şekilde gösterildiği gibi OpenCV kullanarak belirli bir videodan kareler çıkarmaktı. Videolar farklı kare/saniye (FPS) hızlarında çekildiğinden, zamanı ve kare sayısını takip etmek için sırasıyla iki sayaç kullandık. Daha sonra görüntülerin sırasını şu şekilde sakladık:video_name + second_count + frame_countPNG formatında.
![]()
Nesne (kişi) algılama
Çerçevelerdeki kişileri tespit etmek için Pascal VOC veri setine dayalı önceden eğitilmiş YOLOv3 modelleri kullandık. Daha fazla bilgi için, bkz Amazon SageMaker'da Gluon ve Apache MXNet ile oluşturulmuş özel modellerin devreye alınması. YOLOv3 algoritması, aşağıdaki animasyonlarda gösterilen sınırlayıcı kutuları üretti (orijinal görüntüler 910×512 piksel olarak yeniden boyutlandırıldı).
![]()
Sınırlayıcı kutu koordinatlarını, satırların çerçeve indeksini, sınırlayıcı kutu bilgilerini bir liste olarak ve bunların güven puanlarını gösterdiği bir CSV dosyasında sakladık.
2D poz tahmini
Önceden eğitilmiş poz tahmin modeli olarak ResNet-18 V1b'yi seçtik; bu, nesne algılama modeli tarafından çıkarılan sınırlayıcı kutular içindeki insan pozlarını tahmin etmek için yukarıdan aşağıya bir stratejiyi dikkate alır. Maksimum olmayan bastırma (NMS) işleminin daha hızlı gerçekleştirilebilmesi için dedektör sınıflarını insanları içerecek şekilde daha da sıfırladık. Anahtar noktaların ısı haritalarını tahmin etmek için Basit Poz ağı uygulandı (aşağıdaki animasyonda olduğu gibi) ve ısı haritalarındaki en yüksek değerler, orijinal görüntülerdeki koordinatlara eşlendi.
![]()
3D poz tahmini
3DMPPE (Moon ve diğ.) olarak adlandırılan, RGB çerçevesi başına çok kişi için kamera mesafesine duyarlı yukarıdan aşağıya yöntemini kapsayan son teknoloji bir 3D poz tahmin algoritması kullandık. Bu algoritma iki ana aşamadan oluşuyordu:
- Kök Ağ – Kırpılmış bir çerçevede bir kişinin kökünün kamera merkezli koordinatlarını tahmin eder
- poznet – Kırpılan görüntüdeki göreli 3B poz koordinatlarını tahmin etmek için yukarıdan aşağıya bir yaklaşım kullanır
Daha sonra, 3B koordinatları orijinal uzaya geri yansıtmak için sınırlayıcı kutu bilgisini kullandık. 3DMPPE, Human36 ve MuCo3D veri kümeleri kullanılarak eğitilmiş iki önceden eğitilmiş model sunmuştur (daha fazla bilgi için bkz. GitHub repo), aşağıdaki animasyonlarda gösterildiği gibi sırasıyla 17 ve 21 anahtar noktayı içerir. Görselleştirme ve değerlendirme amacıyla önceden eğitilmiş iki model tarafından tahmin edilen 3B poz koordinatlarını kullandık.
![]()
![]()
![]()
Değerlendirme
2B ve 3B poz tahmin modellerinin performansını değerlendirmek için, belirli bir videodaki her kare için oluşturulan her eklem için 2B poz (x,y) ve 3B poz (x,y,z) koordinatlarını kullandık. Kilit noktaların sayısı, veri kümelerine göre değişiklik gösteriyordu; örneğin, Leeds Sports Pose Veri Seti (LSP) 14 tane içerirken, Human3.6M'ye atıfta bulunan eklemli insan pozu tahminini değerlendirmek için son teknoloji bir kıyaslama noktası olan MPII Human Pose veri seti 16 temel nokta içerir. Değerlendirme ile ilgili bir sonraki bölümde açıklandığı gibi, hem 2B hem de 3B poz tahmini için yaygın olarak kullanılan iki ölçü kullandık. Uygulamamızda, varsayılan anahtar noktalar sözlüğümüz, 17 anahtar nokta içeren (aşağıdaki resme bakın) COCO algılama veri setini takip etti ve sıra şu şekilde tanımlandı:
KEY POINTS = { 0: "nose", 1: "left_eye", 2: "right_eye", 3: "left_ear", 4: "right_ear", 5: "left_shoulder", 6: "right_shoulder", 7: "left_elbow", 8: "right_elbow", 9: "left_wrist", 10: "right_wrist", 11: "left_hip", 12: "right_hip", 13: "left_knee", 14: "right_knee", 15: "left_ankle", 16: "right_ankle"}
![]()
Ortak konum hatası başına ortalama
Ortak konum hatası başına ortalama (MPJPE), temel gerçek ile ortak bir tahmin arasındaki Öklid mesafesidir. MPJPE hata veya kayıp mesafesini ölçtüğünden ve daha düşük değerler daha yüksek kesinliği gösterir.
Aşağıdaki sözde kodu kullanıyoruz:
- G belirtelim
ground_truth_jointve G'yi şu şekilde ön işleme tabi tutun:- G'deki boş girişleri [0,0] (2B) veya [0,0,0] (3B) ile değiştirme
- Boş girişlerin konumunu depolamak için bir Boole matrisi B kullanma
- P belirtelim
predicted_joint matrixve herhangi bir çerçevenin sonucu yoksa veya etiketlenmemişse sıfır vektörü ekleyerek G ve P'yi çerçeve dizinine göre hizalayın - G ve P arasındaki öğe bazında Öklid mesafesini hesaplayın ve D'nin mesafe matrisini göstermesine izin verin
- D'yi değiştiri,j B ise 0 ilei,j
- Eklem konumu başına ortalama, D'nin her bir sütununun ortalama değeridirs,tDi,j ≠ 0
Aşağıdaki şekil, m*n boyutuna sahip bir matris olan bir video eklem hatası örneğini görselleştirir; burada m, bir videodaki kare sayısını ve n, eklem sayısını (temel noktalar) belirtir. Matris, solda eklem pozisyonu başına hatanın ısı haritasının bir örneğini ve sağda eklem pozisyonu başına ortalama hatanın bir örneğini gösterir.
![]()
Aşağıdaki şekil, videonun birleşim başına hatası örneğini, m*n boyutuna sahip bir matrisi görselleştirir; burada m, bir videodaki kare sayısını ve n, eklem sayısını (temel noktalar) belirtir. Matris, solda eklem pozisyonu başına hatanın ısı haritasının bir örneğini ve sağda eklem pozisyonu başına ortalama hatanın bir örneğini gösterir.
Doğru kilit noktaların yüzdesi
Doğru anahtar noktaların yüzdesi (PCK), tahmin edilen ve gerçek eklem arasındaki mesafe belirli bir eşiğin içindeyse tespit edilen bir eklemin doğru kabul edildiği bir poz değerlendirme metriğini temsil eder; bu eşik değişebilir ve bu da birkaç farklı metrik varyasyonuna yol açar. Yaygın olarak üç varyasyon kullanılır:
- PCKh@0.5, eşiğin 0.5 * baş kemik bağlantısı olarak tanımlandığı zamandır
- PCK@0.2, yani tahmin edilen ve gerçek eklem arasındaki mesafe < 0.2 * gövde çapı olduğunda
- Sert eşik olarak 150 mm
Çözümümüzde, baş-kemik bağlantısını hesaplamak için kullanabileceğimiz baş sınırlama kutusunu içeren temel doğruluk XML verimiz olarak PCKh@0.5'i kullandık. Bildiğimiz kadarıyla, mevcut hiçbir paket bu ölçüm için kullanımı kolay bir uygulama içermiyor; bu nedenle, metriği kurum içinde uyguladık.
Sözde kod
Aşağıdaki sözde kodu kullandık:
- G, yer-gerçeği eklemini göstersin ve G'yi şu şekilde önişlesin:
- G'deki boş girişleri [0,0] (2B) veya [0,0,0] (3B) ile değiştirme
- Boş girişlerin konumunu depolamak için bir Boole matrisi B kullanma
- Her çerçeve için Fi, bbox B'yi kullanıni=(xdk,ydk,xmaksimum,ymaksimum) her çerçevenin karşılık gelen baş-kemik bağlantısını H hesaplamak içini , nerede Hi=((xmaksimum-xdk)2+(emaksimum-ydk)2)½
- P tahmin edilen ortak matrisi göstersin ve G ve P'yi çerçeve indeksine göre hizalasın; herhangi bir çerçeve eksikse sıfır tensör ekleyin
- G ve P arasındaki eleman bazında 2-norm hatasını hesaplayın; E hata matrisini göstersin, burada Ei,j=||Gi,j-Pi,j||
- Ölçekli bir matris S=H*I hesaplayın, burada I, E ile aynı boyuta sahip bir birim matrisi temsil eder.
- 0'a bölmekten kaçınmak için S'yi değiştirini,j B ise 0.000001 ilei,j=1
- Hesaplama ölçekli hata matrisi Si,j=Ei,j/Si,j
- Eşik = 0.5 ile SE'yi filtreleyin ve C'nin karşı matrisi göstermesine izin verin, burada Ci,j=1 SE isei,j<0.5 ve Ci,j=0 aksi halde
- C'de kaç tane 1 olduğunu sayın*,j c⃗ olarak ve B'de kaç tane 0 olduğunu sayın*,j b⃗ olarak
- PCKh@0.5=ortalama(c⃗/b⃗)
Altıncı adımda (S'yi değiştirini,jB ise 0.000001 ilei,j=1), 0 girişi 0.00001 ile değiştirerek ölçeklenmiş hata matrisi için bir tuzak kurduk. Herhangi bir sayıyı küçük bir sayıya bölmek, büyütülmüş bir sayı üretir. Daha sonra > 0.5'i yanlış tahminleri filtrelemek için bir eşik olarak kullandığımız için, boş girişler çok büyük olduğu için doğru tahminden çıkarıldı. Daha sonra Boole matrisindeki yalnızca boş olmayan girişleri saydık. Bu şekilde, boş girişleri tüm veri kümesinden de çıkardık. Bu uygulamada, yer gerçeğindeki etiketlenmemiş kilit noktalardan veya hiç kimsenin algılanmadığı çerçevelerden boş girişleri filtrelemek için bir mühendislik hilesi önerdik.
video hizalama
Sporculardan video verilerini yakalamak için iki farklı kamera yapılandırması, yani hat ve kutu kurulumları düşündük. Hat kurulumu bir hat boyunca yerleştirilmiş dört kameradan, kutu kurulumu ise bir dikdörtgenin her bir köşesine yerleştirilmiş dört kameradan oluşur. Kameralar hat konfigürasyonunda senkronize edildi ve ardından hafifçe örtüşen kamera açıları kullanılarak birbirlerinden önceden tanımlanmış bir mesafede dizildi. Çizgi konfigürasyonunda video hizalamanın amacı, tekrarlanan ve boş kareleri kaldırmak için ardışık kameraları birbirine bağlayan zaman damgalarını belirlemekti. Nesne algılamaya ve optik akışların çapraz korelasyonuna dayalı iki yaklaşım uyguladık.
nesne algılama algoritması
Bu yaklaşımda, önceki adımlardan kişilerin sınırlayıcı kutuları da dahil olmak üzere nesne algılama sonuçlarını kullandık. Nesne algılama teknikleri, her çerçevede kişi başına bir olasılık (skor) üretti. Bu nedenle, bir videodaki puanları çizmek, ilk kişinin göründüğü veya kaybolduğu kareyi bulmamızı sağladı. Kutu konfigürasyonundaki referans kare her videodan çıkarıldı ve ardından tüm kameralar ilk karenin referanslarına göre senkronize edildi. Satır yapılandırmasında, hem başlangıç hem de bitiş zaman damgaları çıkarıldı ve aşağıdaki görüntülerde gösterildiği gibi ardışık videoları bağlamak ve hizalamak için kural tabanlı bir algoritma uygulandı.
Aşağıdaki şekilde en üstteki videolar, hat konfigürasyonundaki orijinal videoları gösterir. Bunun altında kişi algılama puanları bulunur. Sonraki satırlar puanlara uygulanan 0.75 eşiğini gösterir ve uygun başlangıç ve bitiş zaman damgaları çıkarılır. Alt sıra, daha fazla analiz için hizalanmış videoları gösterir.
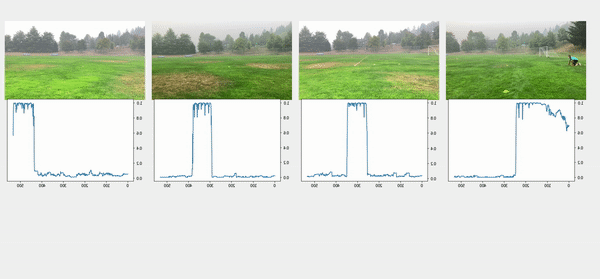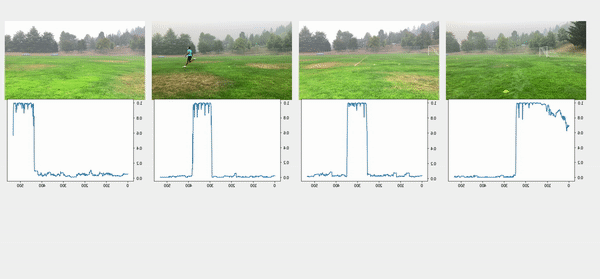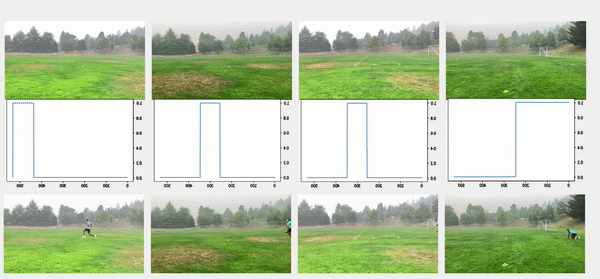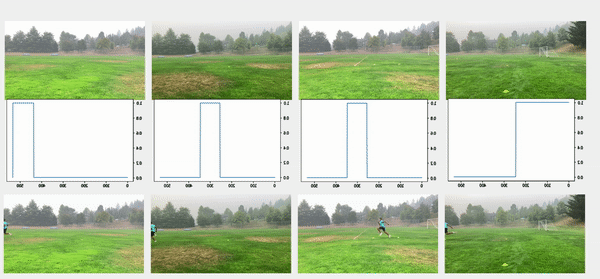
çırpma anı
Bir olayın veya oyunun ne zaman başladığını gösteren, iyi bilinen bir hizalama yaklaşımı olan ani hareket anını (MOS) tanıttık. Bir sporcu sahaya girerken veya çıkarken çerçeve numarasını belirlemek istedik. Tipik olarak, koşu alanında ani hareketin başlangıcından önce ve bitiminden sonra nispeten az hareket meydana gelirken, atlet koşarken nispeten önemli hareket meydana gelir. Bu nedenle, sezgisel olarak, videonun kareden önceki ve sonraki hareketinde nispeten büyük farklar olan video karelerini bularak MOS karesini bulabiliriz. Bu amaçla, MOS'u tahmin etmek için videoda standart bir hareket ölçüsü olan yoğunluk optik akışını kullandık. İlk olarak, bir video verildiğinde, her iki ardışık kare için optik akışı hesapladık. Aşağıdaki videolar, yatay eksende yoğun optik akışın görselleştirilmesini sunar.
![]()
Daha sonra iki ardışık çerçevenin optik akışları arasındaki çapraz korelasyonu ölçtük, çünkü çapraz korelasyon aralarındaki farkı ölçer. Her açının kamera tarafından yakalanan videosu için, MOS'unu bulmak için algoritmayı tekrarladık. Son olarak, videoları farklı açılardan hizalamak için ana çerçeve olarak MOS çerçevesini kullandık. Aşağıdaki video bu adımları detaylandırmaktadır.
![]()
Sonuç
Bu gönderide gösterilen çalışmanın teknik amacı, 3B videolar kullanarak 2B poz tahmini koordinatları üreten derin öğrenmeye dayalı bir çözüm geliştirmekti. 3B çok kişili poz tahmini elde etmek için yukarıdan aşağıya bir yaklaşımla mesafeye duyarlı bir kamera tekniği kullandık. Ayrıca, nesne algılama, çapraz korelasyon ve optik akış algoritmalarını kullanarak farklı açılardan çekilen videoları hizaladık.
Bu çalışma, koçların hız gibi biyomekanik ölçümleri ölçmek ve nicel ve nitel yöntemler kullanarak sporcuların performansını izlemek için zaman içinde sporcuların 3B poz tahminini analiz etmelerini sağladı.
Bu gönderi, yüzme veya takım sporları gibi diğer sporlarda koçluk için ölçeklendirilebilen, gerçek dünya senaryolarında 3D pozları çıkarmak için basitleştirilmiş bir süreç gösterdi.
Ürün ve hizmetlerinizde makine öğrenimi kullanımını hızlandırma konusunda yardım almak isterseniz lütfen şu adresle iletişime geçin: Amazon ML Çözümleri Laboratuvarı programı.
Referanslar
Moon, Gyeongsik, Ju Yong Chang ve Kyoung Mu Lee. "Tek bir RGB görüntüsünden 3 boyutlu çok kişili poz tahmini için kamera mesafesine duyarlı yukarıdan aşağıya yaklaşımı." İçinde IEEE Uluslararası Bilgisayarla Görme Konferansı Bildirileri, pp, 10133-10142. 2019.
Yazar Hakkında
![]() Saman Sarraf bir Veri Bilimcisidir. Amazon ML Çözümleri Laboratuvarı. Geçmişi, derin öğrenme, bilgisayarla görme ve zaman serisi veri tahmini dahil olmak üzere uygulamalı makine öğrenimindedir.
Saman Sarraf bir Veri Bilimcisidir. Amazon ML Çözümleri Laboratuvarı. Geçmişi, derin öğrenme, bilgisayarla görme ve zaman serisi veri tahmini dahil olmak üzere uygulamalı makine öğrenimindedir.
![]() Amery Cong Olimpiyat Oyunlarında biyomekanik analizleri yürütmek için makine öğrenimi ve bilgisayarla görme teknolojileri geliştirdiği Intel'de bir Algoritma Mühendisidir. Özellikle spor performansı bağlamında yapay zeka ile insan fizyolojisini ölçmekle ilgileniyor.
Amery Cong Olimpiyat Oyunlarında biyomekanik analizleri yürütmek için makine öğrenimi ve bilgisayarla görme teknolojileri geliştirdiği Intel'de bir Algoritma Mühendisidir. Özellikle spor performansı bağlamında yapay zeka ile insan fizyolojisini ölçmekle ilgileniyor.
![]() Ashton Eaton Intel'de bir Ürün Geliştirme Mühendisidir ve burada spor performansını ilerletmeyi amaçlayan teknolojilerin tasarlanmasına ve test edilmesine yardımcı olur. Müşteri ihtiyaçlarına hizmet eden ürünleri belirlemek ve geliştirmek için müşterilerle ve mühendislik ekibiyle birlikte çalışır. Bilim ve teknolojiyi insan performansına uygulamakla ilgileniyor.
Ashton Eaton Intel'de bir Ürün Geliştirme Mühendisidir ve burada spor performansını ilerletmeyi amaçlayan teknolojilerin tasarlanmasına ve test edilmesine yardımcı olur. Müşteri ihtiyaçlarına hizmet eden ürünleri belirlemek ve geliştirmek için müşterilerle ve mühendislik ekibiyle birlikte çalışır. Bilim ve teknolojiyi insan performansına uygulamakla ilgileniyor.
![]() Jonathan Lee Intel'de Olimpik Teknoloji Grubu Spor Performans Teknolojisi Direktörüdür. UCLA'da lisans öğrencisi olarak ve Oxford Üniversitesi'nde yüksek lisans eğitimi sırasında makine öğreniminin sağlığa uygulanması konusunda çalıştı. Kariyeri, sağlık ve insan performansı için algoritma ve sensör geliştirmeye odaklanmıştır. Şimdi Intel'de 3D Sporcu Takip projesini yönetiyor.
Jonathan Lee Intel'de Olimpik Teknoloji Grubu Spor Performans Teknolojisi Direktörüdür. UCLA'da lisans öğrencisi olarak ve Oxford Üniversitesi'nde yüksek lisans eğitimi sırasında makine öğreniminin sağlığa uygulanması konusunda çalıştı. Kariyeri, sağlık ve insan performansı için algoritma ve sensör geliştirmeye odaklanmıştır. Şimdi Intel'de 3D Sporcu Takip projesini yönetiyor.
![]() nelson leung atlet performansını artıran son teknoloji ürünler için uçtan uca mimariyi tanımladığı Intel'deki Sports Performance CoE'de Platform Mimarıdır. Ayrıca, bu makine öğrenimi çözümlerinin farklı Intel ortaklarına uygun ölçekte uygulanmasına, devreye alınmasına ve ürünleştirilmesine liderlik ediyor.
nelson leung atlet performansını artıran son teknoloji ürünler için uçtan uca mimariyi tanımladığı Intel'deki Sports Performance CoE'de Platform Mimarıdır. Ayrıca, bu makine öğrenimi çözümlerinin farklı Intel ortaklarına uygun ölçekte uygulanmasına, devreye alınmasına ve ürünleştirilmesine liderlik ediyor.
![]() Suchitra Sathyanarayana şirketinde yöneticidir Amazon ML Çözümleri Laboratuvarı, burada farklı sektör sektörlerindeki AWS müşterilerinin yapay zeka ve bulut benimsemelerini hızlandırmasına yardımcı oluyor. Singapur'daki Nanyang Teknoloji Üniversitesi'nden Bilgisayarla Görme alanında doktora derecesine sahiptir.
Suchitra Sathyanarayana şirketinde yöneticidir Amazon ML Çözümleri Laboratuvarı, burada farklı sektör sektörlerindeki AWS müşterilerinin yapay zeka ve bulut benimsemelerini hızlandırmasına yardımcı oluyor. Singapur'daki Nanyang Teknoloji Üniversitesi'nden Bilgisayarla Görme alanında doktora derecesine sahiptir.
![]()
Wenzhen Zhu olan bir veri bilimcisidir. Amazon ML Çözüm Laboratuvarı Amazon Web Services ekibi. AWS müşterileri için sektörlerdeki çeşitli sorunları çözmek için Makine Öğrenimi ve Derin Öğrenmeden yararlanıyor.
Coinsmart. Europa İçindeki En İyi Bitcoin-Börse
Kaynak: https://aws.amazon.com/blogs/machine-learning/estimating-3d-pose-for-athlete-tracking-using-2d-videos-and-amazon-sagemaker-studio/

