İşletmeler büyüdükçe kurumsal ağ içindeki IP adreslerine olan talep çoğu zaman arzı aşıyor. Bir kuruluşun ağı genellikle gelecekteki gereksinimlerin öngörülmesiyle tasarlanır, ancak kuruluşlar geliştikçe bilgi teknolojisi (BT) ihtiyaçları önceden tasarlanan ağı aşar. Şirketler sınırlı IP adresi havuzunu yönetmekte zorluk yaşayabilirler.
Veri mühendisliği iş yükleri için AWS Tutkal Böyle kısıtlı bir ağ yapılandırmasında kullanıldığında ekibiniz bazen birçok işi aynı anda yürütürken engellerle karşılaşabilir. Bunun nedeni, veritabanlarına gerekli bağlantıları desteklemek için yeterli IP adresiniz olmaması olabilir. Bu eksikliğin üstesinden gelmek için ekip, kurumsal ağ havuzunuzdan daha fazla IP adresi alabilir. Elde edilen bu IP adresleri, kurumsal ağınızda tekrar kullanıldığında benzersiz (örtüşmeyen) veya örtüşen IP adresleri olabilir.
Çakışan IP adresleri kullandığınızda bağlantı kurmak için ek bir ağ yönetimine ihtiyacınız vardır. Ağ çözümleri aşağıdaki gibi seçenekleri içerebilir: özel Ağ Adresi Çevirisi (NAT) ağ geçitleri, AWS Özel Bağlantıveya IP adreslerini çevirmek için kendi kendini yöneten NAT cihazları.
Bu yazıda AWS Glue işlerini ölçeklendirmek için iki stratejiyi tartışacağız:
- Veri İşleme Birimlerini (DPU'lar) doğru boyutlandırarak, AWS Glue'nun Otomatik Ölçeklendirme özelliğini kullanarak ve işlerde ince ayar yaparak IP adresi tüketimini optimize etme.
- Özel bir NAT ağ geçidi ile ek yönlendirilemeyen Sınıfsız Etki Alanları Arası Yönlendirme (CIDR) aralığını kullanarak ağ kapasitesini genişletme.
Bu çözümlere derinlemesine dalmadan önce AWS Glue'nun nasıl kullandığını anlayalım. Elastik Ağ Arayüzü (ENI) bağlantı kurmak için. Bir VPC içindeki veri depolarına erişimi etkinleştirmek için VPC'nize bağlı bir AWS Glue bağlantısı oluşturmanız gerekir. VPC'nizde bir AWS Glue işi çalıştırıldığında iş, her veri bağlantısı için yapılandırılmış VPC'nin içinde bir ENI oluşturur ve bu ENI, belirtilen VPC'deki bir IP adresini kullanır. Bu ENI'ler kısa ömürlüdür ve iş tamamlanana kadar aktiftir.
Şimdi AWS Glue IP adresi tüketimini optimize etmeyi açıklayan ilk çözüme bakalım.
Verimli IP adresi tüketimine yönelik stratejiler
AWS Glue'da bir işin kullandığı çalışan sayısı, VPC alt ağınızdan kullanılan IP adreslerinin sayısını belirler. Bunun nedeni, her çalışanın bir ENI ile eşleşen bir IP adresine ihtiyaç duymasıdır. AWS Glue alt ağına ayrılmış yeterli CIDR aralığınız olmadığında IP adresi tükenme hataları gözlemleyebilirsiniz. AWS Glue IP adresi tüketimini optimize etmek için en iyi uygulamalardan bazıları şunlardır:
- İşin DPU'larını doğru boyutlandırma – AWS Glue, dağıtılmış bir işleme motorudur. Görevleri paralel olarak çalıştırabildiğinde verimli çalışır. Bir iş gerekli DPU'lardan daha fazlasına sahipse her zaman daha hızlı çalışmaz. Dolayısıyla doğru sayıda DPU'yu bulmak, IP adreslerini en iyi şekilde kullandığınızdan emin olmanızı sağlayacaktır. Sistemde gözlemlenebilirlik oluşturarak ve iş performansını analiz ederek, ENI tüketim eğilimlerine ilişkin öngörüler elde edebilir ve ardından işteki uygun kapasiteyi doğru boyuta göre yapılandırabilirsiniz. Daha fazla ayrıntı için bkz. DPU kapasite planlamasının izlenmesi. Spark kullanıcı arayüzü, AWS Glue işlerinin çalışanlarının kullanımını izlemek için yararlı bir araçtır. Daha fazla ayrıntı için bkz. Apache Spark web kullanıcı arayüzünü kullanarak işleri izleme.
- AWS Glue Auto Scaling – Bir işin kapasite gereksinimlerini önceden tahmin etmek genellikle zordur. AWS Glue'nun Otomatik Ölçeklendirme özelliğinin etkinleştirilmesi bu sorumluluğun bir kısmını AWS'ye yükleyecektir. Çalışma zamanında, iş yükü gereksinimlerine göre iş, çalışan düğümlerini tanımlanan maksimum yapılandırmaya göre otomatik olarak ölçeklendirir. Ek bir ihtiyaç yoksa, AWS Glue çalışanlara aşırı tedarik sağlamaz, böylece kaynaklardan tasarruf sağlar ve maliyeti düşürür. Otomatik Ölçeklendirme özelliği AWS Glue 3.0 ve sonraki sürümlerde mevcuttur. Daha fazla bilgi için bkz. AWS Glue Auto Scaling ile Tanışın: Optimize edilmiş Apache Spark ile sunucusuz bilgi işlem kaynaklarını daha düşük maliyetle otomatik olarak yeniden boyutlandırın.
- İş düzeyinde optimizasyon – İş düzeyindeki optimizasyonları aşağıdakileri kullanarak tanımlayın: AWS Glue iş ölçümleri ve en iyi uygulamaları uygulayın Apache Spark işleri için AWS Glue'nun performansını ayarlamaya yönelik en iyi uygulamalar.
Şimdi ağ kapasitesinin genişletilmesini detaylandıran ikinci çözüme bakalım.
Ağ boyutu (IP adresi) genişletmeye yönelik çözümler
Bu bölümde ağ boyutunu genişletmek için iki olası çözümü daha ayrıntılı olarak tartışacağız.
Yönlendirilebilir adreslerle VPC CIDR aralıklarını genişletin
Çözümlerden biri, daha fazla özel IPv4 CIDR aralığı eklemektir. RFC 1918 VPC'nize. Teorik olarak her AWS hesabı bu IP adresi CIDR'lerinin bir kısmına veya tümüne atanabilir. IP Adresi Yönetimi (IPAM) ekibiniz, birden fazla AWS hesabında veya iş biriminde IP adreslerinin çakışmasını önlemek için genellikle her iş biriminin RFC1918'den kullanabileceği IP adreslerinin tahsisini yönetir. IPAM ekibi tarafından tahsis edilen mevcut yönlendirilebilir IP adresi kotanız yeterli değilse daha fazlasını talep edebilirsiniz.
IPAM ekibiniz size çakışmayan ek bir CIDR aralığı verirse bunu mevcut VPC'nize ikincil bir CIDR olarak ekleyebilir veya onunla yeni bir VPC oluşturabilirsiniz. Yeni bir VPC oluşturmayı planlıyorsanız VPC'leri şu adresten birbirine bağlayabilirsiniz: VPC eşlemesi or AWS Toplu Taşıma Ağ Geçidi.
Bu ek kapasite, tüm işlerinizi tanımlanan zaman çerçevesinde yürütmek için yeterliyse, bu basit ve uygun maliyetli bir çözümdür. Aksi takdirde, aşağıdaki bölümde açıklandığı gibi, özel bir NAT ağ geçidiyle çakışan IP adreslerini benimsemeyi düşünebilirsiniz. Bu iki VPC'de çakışan CIDR aralıkları olduğunda VPC eşlemesi mümkün olmadığından, aşağıdaki çözümle VPC'leri bağlamak için Transit Gateway'i kullanmanız gerekir.
Yönlendirilemeyen CIDR'yi özel bir NAT ağ geçidiyle yapılandırma
AWS teknik incelemesinde açıklandığı gibi Ölçeklenebilir ve Güvenli Çoklu VPC AWS Ağ Altyapısı Oluşturma, yönlendirilemeyen bir IP adresi alt ağı oluşturarak ve trafiği yönlendirmek için yönlendirilebilir bir IP adresi alanında (örtüşmeyen) bulunan özel bir NAT ağ geçidi kullanarak ağ kapasitenizi genişletebilirsiniz. Özel bir NAT ağ geçidi, yönlendirilemeyen IP adresleri ile yönlendirilebilir IP adresleri arasındaki trafiği çevirir ve yönlendirir. Aşağıdaki şemada AWS Glue'ya referansla çözüm gösterilmektedir.
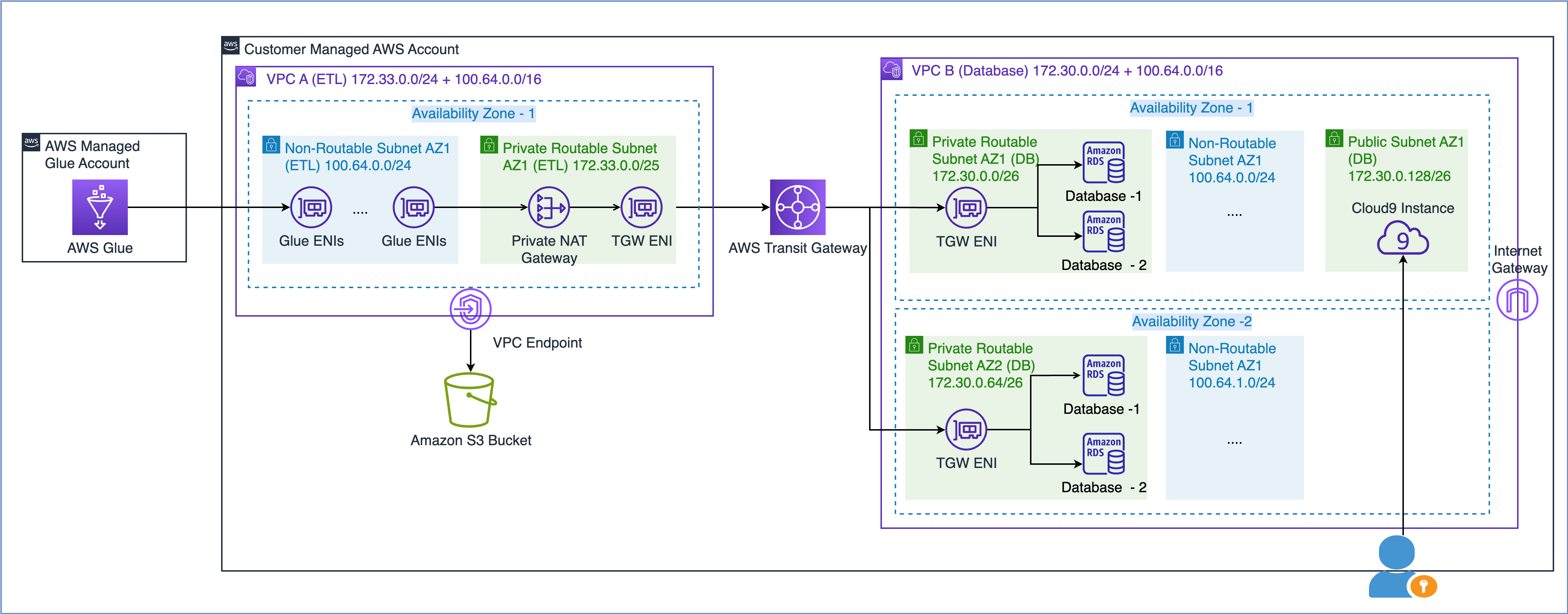
Yukarıdaki şemada görebileceğiniz gibi, VPC A'ya (ETL) bağlı iki CIDR aralığı vardır. Daha küçük olan CIDR aralığı 172.33.0.0/24, hiçbir yerde yeniden kullanılmadığı için yönlendirilebilirken, daha büyük olan CIDR aralığı 100.64.0.0/16, veritabanı VPC'sinde yeniden kullanıldığı için yönlendirilemez.
VPC B'de (Veritabanı), 172.30.0.0/26 ve 172.30.0.64/26 yönlendirilebilir alt ağlarda iki veritabanını barındırdık. Bu iki alt ağ, yüksek kullanılabilirlik için iki ayrı Erişilebilirlik Alanında bulunur. Yönlendirilemeyen bir kurulumu simüle etmek için ayrıca kullanılmayan iki alt ağımız daha var: 100.64.0.0/24 ve 100.64.1.0/24.
Kapasite gereksinimlerinize göre yönlendirilemeyen CIDR aralığının boyutunu seçebilirsiniz. IP adreslerini yeniden kullanabildiğiniz için gerektiğinde çok büyük bir alt ağ oluşturabilirsiniz. Örneğin, /16'lık bir CIDR maskesi size yaklaşık 65,000 IPv4 adresi verecektir. Ağ mühendisliği ekibinizle birlikte çalışabilir ve alt ağları boyutlandırabilirsiniz.
Kısacası, kullanılabilir IP adresi havuzunu en üst düzeye çıkarmak için AWS Glue işlerini VPC'nizdeki hem yönlendirilebilen hem de yönlendirilemeyen alt ağları kullanacak şekilde yapılandırabilirsiniz.
Şimdi yönlendirilemeyen bir alt ağdaki Glue ENI'lerin başka bir VPC'deki veri kaynaklarıyla nasıl iletişim kurduğunu anlayalım.
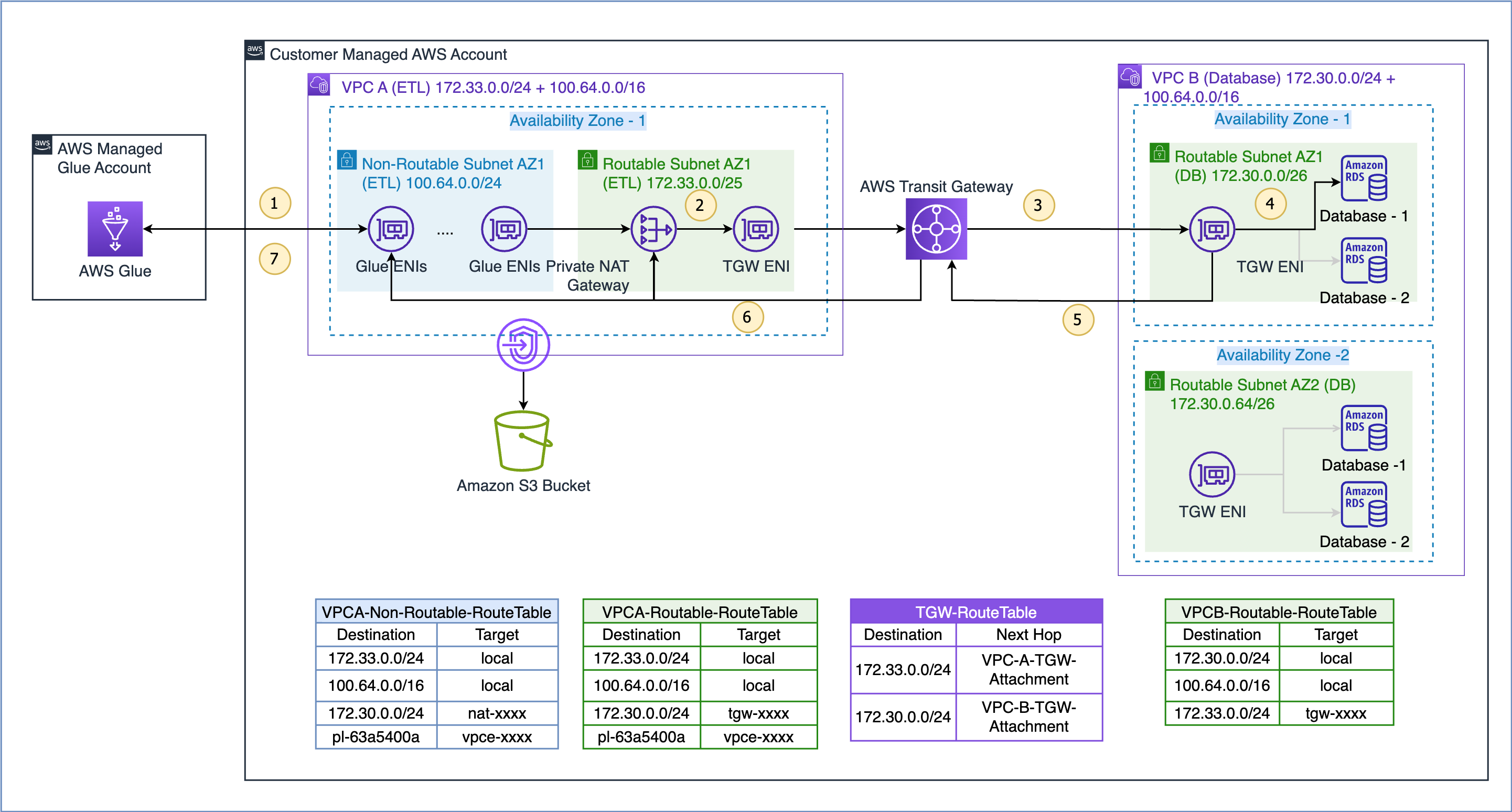
Burada gösterilen kullanım senaryosuna ilişkin veri akışı aşağıdaki gibidir (yukarıdaki şekilde numaralandırılmış adımlara atıfta bulunarak):
- Bir AWS Glue işinin bir veri kaynağına erişmesi gerektiğinde, öncelikle işteki AWS Glue bağlantısını kullanır ve VPC A'daki yönlendirilemeyen alt ağ 100.64.0.0/24'te ENI'leri oluşturur. Daha sonra AWS Glue, veritabanı bağlantı yapılandırmasını kullanır ve VPC B 172.30.0.0/24'teki veritabanına bağlanmaya çalışır.
- Rota tablosuna göre
VPCA-Non-Routable-RouteTable172.30.0.0/24 hedefi özel bir NAT ağ geçidi için yapılandırılmıştır. İstek NAT ağ geçidine gönderilir ve daha sonra kaynak IP adresini yönlendirilemeyen bir IP adresinden yönlendirilebilir bir IP adresine çevirir. Daha sonra trafik, VPC A'daki transit ağ geçidi ekine gönderilir çünkü bu,VPCA-Routable-RouteTableVPC A'daki rota tablosu. - Transit Gateway, 172.30.0.0/24 rotasını kullanır ve trafiği VPC B transit ağ geçidi ekine gönderir.
- VPC B'deki transit ağ geçidi ENI, veritabanı uç noktasına bağlanmak ve verileri sorgulamak için VPC B'nin yerel yolunu kullanır.
- Sorgu tamamlandığında yanıt VPC A'ya geri gönderilir. Yanıt trafiği, VPC B'deki toplu taşıma ağ geçidi ekine yönlendirilir, ardından Transit Ağ Geçidi 172.33.0.0/24 rotasını kullanır ve trafiği VPC A toplu taşıma ağ geçidi ekine gönderir. .
- VPC A'daki transit ağ geçidi ENI, trafiği özel NAT ağ geçidine iletmek için yerel rotayı kullanır; bu ağ, hedef IP adresini, yönlendirilemeyen alt ağdaki ENI'lerinkine çevirir.
- Son olarak AWS Glue işi verileri alır ve işlemeye devam eder.
Özel NAT ağ geçidi çözümü, kuruluşunuzdaki yönlendirilebilir bir ağdan alamadığınızda ekstra IP adreslerine ihtiyaç duymanız durumunda bir seçenektir. Bazen her ek hizmetin ek bir maliyeti olabilir ve bu ödünleşim, hedeflerinize ulaşmak için gereklidir. NAT Ağ Geçidi fiyatlandırma bölümüne bakın. Amazon VPC fiyatlandırma sayfası daha fazla bilgi için.
Önkoşullar
Özel NAT ağ geçidi çözümünün gözden geçirilmesini tamamlamak için aşağıdakilere ihtiyacınız vardır:
Çözümü dağıtın
Çözümü uygulamak için aşağıdaki adımları tamamlayın:
- AWS yönetim konsolunuzda oturum açın.
- Çözümü tıklatarak dağıtın
 . Bu yığın varsayılan olarak
. Bu yığın varsayılan olarak us-east-1, istediğiniz Bölgeyi seçebilirsiniz. - Tıkla sonraki ve ardından yığın ayrıntılarını belirtin. Giriş parametrelerini önceden doldurulmuş varsayılan değerlerde tutabilir veya bunları gerektiği gibi değiştirebilirsiniz.
- İçin
DatabaseUserPassword, seçtiğiniz alfasayısal şifreyi girin ve daha sonra kullanmak üzere not ettiğinizden emin olun. - İçin
S3BucketName, benzersiz bir değer girin Amazon Basit Depolama Hizmeti (Amazon S3) paket adı. Bu klasör, bir AWS genel kod deposundan kopyalanacak AWS Glue iş komut dosyasını depolar.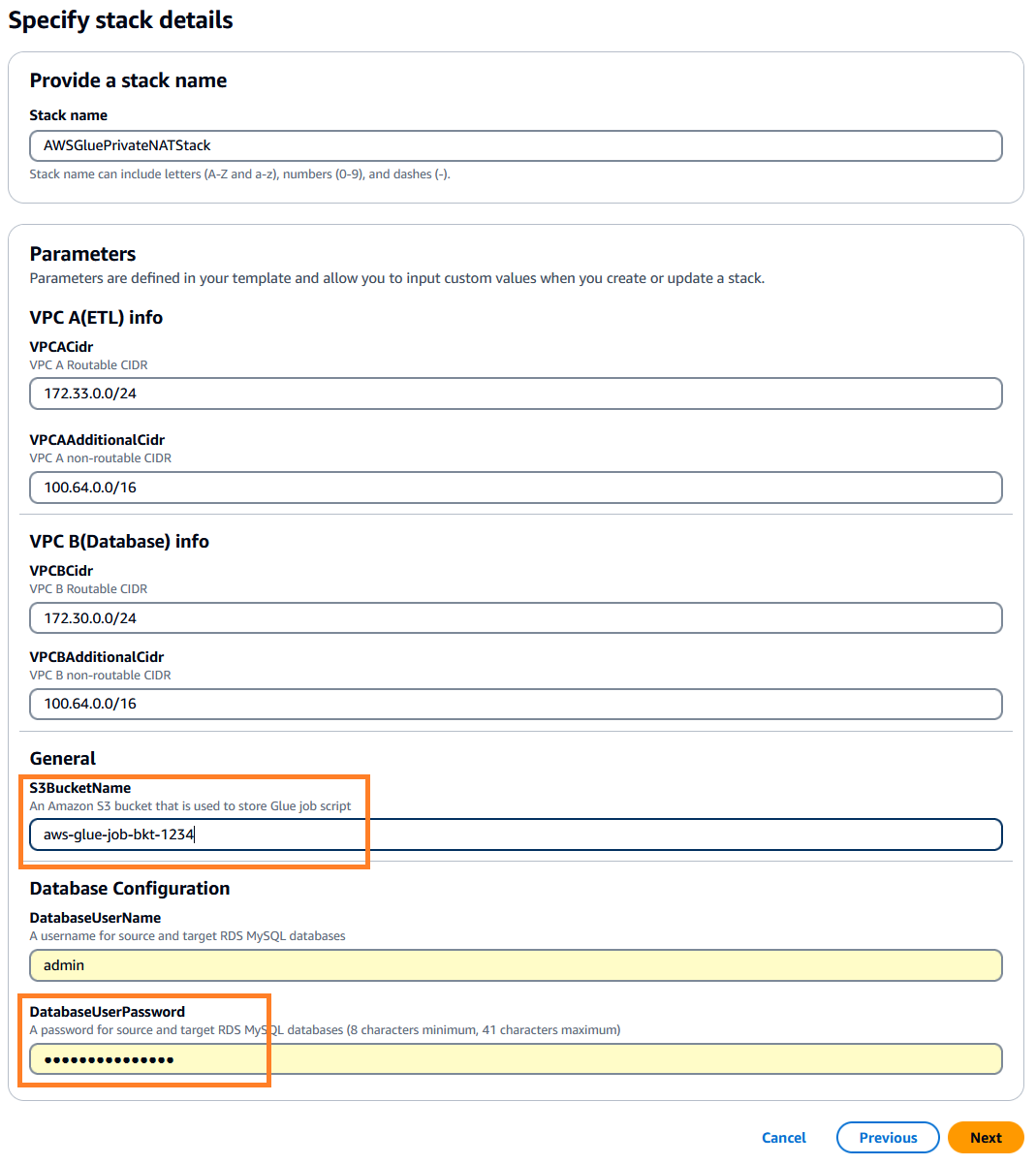
- Tıkla sonraki.
- Varsayılan değerleri bırakın ve tıklayın. sonraki tekrar.
- Ayrıntıları inceleyin, IAM kaynaklarının oluşturulduğunu onaylayın ve tıklayın sunmak konuşlandırmayı başlatmak için.
AWS CloudFormation konsolunda oluşturulan kaynakları görmek için olayları izleyebilirsiniz. Yığın kaynaklarının oluşturulması yaklaşık 20 dakika sürebilir.
Yığın oluşturma işlemi tamamlandıktan sonra AWS CloudFormation konsolundaki Çıkışlar sekmesine gidin ve daha sonra kullanmak üzere aşağıdaki değerleri not edin:
DBSourceDBTargetSourceCrawlerTargetCrawler
Bir AWS Cloud9 örneğine bağlanın
Daha sonra, MySQL tabloları için Amazon RDS'yi kaynak ve hedef olarak hazırlamamız gerekiyor. AWS Bulut9 misal. Aşağıdaki adımları tamamlayın:
- AWS Cloud9 konsol sayfasında,
aws-glue-cloud9ortamı. - Cloud9 IDE sütununda, üzerine tıklayın Açılış AWS Cloud9 bulut sunucunuzu yeni bir web tarayıcısında başlatmak için.
Kaynak MySQL tablosunu hazırlayın
Kaynak tablonuzu hazırlamak için aşağıdaki adımları tamamlayın:
- AWS Cloud9 terminalinden aşağıdaki komutu kullanarak MySQL istemcisini yükleyin:
sudo yum update -y && sudo yum install -y mysql - Aşağıdaki komutu kullanarak kaynak veritabanına bağlanın. Kaynak ana bilgisayar adını daha önce yakaladığınız DBSource değeriyle değiştirin. İstendiğinde yığın oluşturma sırasında belirttiğiniz veritabanı parolasını girin.
mysql -h <Source Hostname> -P 3306 -u admin -p - Kaynağı oluşturmak için aşağıdaki komut dosyalarını çalıştırın
emptabloyu açın ve test verilerini yükleyin:-- connect to source database USE srcdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid)); -- Create a stored procedure to load sample records into emp table DELIMITER $$ CREATE PROCEDURE sp_load_emp_source_data() BEGIN DECLARE empid INT; DECLARE ename VARCHAR(100); DECLARE edept VARCHAR(50); DECLARE cnt INT DEFAULT 1; -- Initialize counter to 1 to auto-increment the PK DECLARE rec_count INT DEFAULT 1000; -- Initialize sample records counter TRUNCATE TABLE emp; -- Truncate the emp table WHILE cnt <= rec_count DO -- Loop and load the required number of sample records SET ename = CONCAT('Employee_', FLOOR(RAND() * 100) + 1); -- Generate random employee name SET edept = CONCAT('Dept_', FLOOR(RAND() * 100) + 1); -- Generate random employee department -- Insert record with auto-incrementing empid INSERT INTO emp (ename, edept) VALUES (ename, edept); -- Increment counter for next record SET cnt = cnt + 1; END WHILE; COMMIT; END$$ DELIMITER ; -- Call the above stored procedure to load sample records into emp table CALL sp_load_emp_source_data(); - kaynağı kontrol et
empaşağıdaki SQL sorgusunu kullanarak tablonun sayısını hesaplayın (buna daha sonraki adımda doğrulama için ihtiyacınız olacaktır).select count(*) from emp; - MySQL istemci yardımcı programından çıkıp AWS Cloud9 örneğinin terminaline dönmek için aşağıdaki komutu çalıştırın:
quit;
Hedef MySQL tablosunu hazırlayın
Hedef tabloyu hazırlamak için aşağıdaki adımları tamamlayın:
- Aşağıdaki komutu kullanarak hedef veritabanına bağlanın. Hedef ana bilgisayar adını daha önce yakaladığınız DBTarget değeriyle değiştirin. İstendiğinde, yığın oluşturma sırasında belirttiğiniz veritabanı parolasını girin.
mysql -h <Target Hostname> -P 3306 -u admin -p - Hedefi oluşturmak için aşağıdaki komut dosyalarını çalıştırın
empmasa. Bu tablo bir sonraki adımda AWS Glue işi tarafından yüklenecektir.-- connect to the target database USE targetdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid) );
Ağ kurulumunu doğrulayın (İsteğe bağlı)
Aşağıdaki adımlar, özel NAT ağ geçidi çözümünün NAT ağ geçidini, rota tablolarını ve geçiş ağ geçidi yapılandırmalarını anlamak için faydalıdır. Bu bileşenler CloudFormation yığını oluşturma sırasında oluşturuldu.
- Amazon VPC konsol sayfasında Sanal özel bulut bölümüne gidin ve NAT ağ geçitlerini bulun.
- Adıyla NAT Ağ Geçidini arayın
Glue-OverlappingCIDR-NATGWve daha fazlasını keşfedin. Aşağıdaki ekran görüntüsünde görebileceğiniz gibi, NAT ağ geçidi, yönlendirilebilir alt ağdaki VPC A'da (ETL) oluşturulmuştur.
- Sol taraftaki gezinme bölmesinde, sanal özel bulut bölümünün altındaki Rota tablolarına gidin.
- Aramak
VPCA-Non-Routable-RouteTableve daha fazlasını keşfedin. Yön tablosunun, NAT ağ geçidini kullanarak trafiği çakışan CIDR'den çevirecek şekilde yapılandırıldığını görebilirsiniz.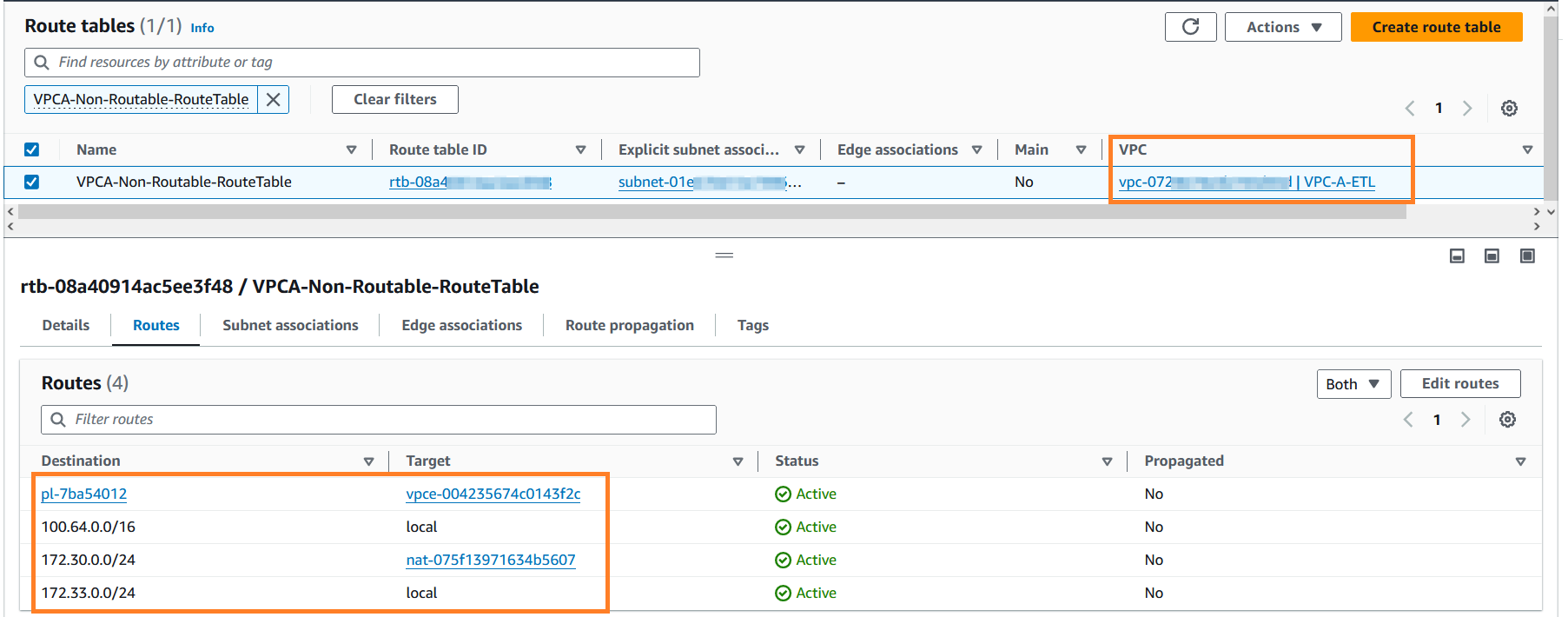
- Sol taraftaki gezinme bölmesinde Transit ağ geçitleri bölümüne gidin ve Transit ağ geçidi eklerine tıklayın. Girmek
VPC-arama kutusunda yeni oluşturulan iki toplu taşıma ağ geçidi ekini bulun. - Yapılandırmalarını öğrenmek için bu ekleri daha ayrıntılı olarak inceleyebilirsiniz.
AWS Glue tarayıcılarını çalıştırın
Kaynağı ve hedefi kataloglamak için gereken AWS Glue tarayıcılarını çalıştırmak için aşağıdaki adımları tamamlayın emp tablolar. Bu, AWS Glue işini çalıştırmak için bir önkoşul adımdır.
- AWS Glue Console sayfasında, gezinme bölmesindeki Veri Kataloğu bölümünün altında şuna tıklayın: Tarayıcıları.
- Daha önce not ettiğiniz kaynak ve hedef tarayıcıları bulun.
- Bu tarayıcıları seçin ve tıklayın koşmak İlgili AWS Glue Data Catalog tablolarını oluşturmak için.
- Başarılı bir tamamlama için AWS Glue tarayıcılarını izleyebilirsiniz. Her iki tarayıcının da tamamlanması yaklaşık 3-4 dakika sürebilir. Tamamlandığında işin son çalıştırma durumu Başarılı olarak değişir ve ayrıca bu çalıştırmadan oluşturulan iki AWS Glue katalog tablosunun olduğunu da görebilirsiniz.

AWS Glue ETL işini çalıştırın
Tabloları ayarlayıp önkoşul adımlarını tamamladıktan sonra artık CloudFormation şablonunu kullanarak oluşturduğunuz AWS Glue işini çalıştırmaya hazırsınız. Bu iş, kaynak RDS for MySQL veritabanına bağlanır, verileri çıkarır ve verileri hedef RDS for MySQL veritabanına yükler. Bu iş, kaynak MySQL tablosundaki verileri okur ve bunu özel NAT ağ geçidi çözümünü kullanarak hedef MySQL tablosuna yükler. AWS Glue işini çalıştırmak için aşağıdaki adımları tamamlayın:
- AWS Glue konsolunda şuna tıklayın: ETL işleri Gezinti bölmesinde.
- İşe tıklayın
glue-private-nat-job. - Tıkla koşmak başlatmak için.
Bu ETL işi için PySpark betiği aşağıdadır:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="glue_cat_db_source",
table_name="srcdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("empid", "int", "empid", "int"),
("ename", "string", "ename", "string"),
("edept", "string", "edept", "string"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.write_dynamic_frame.from_catalog(
frame=ChangeSchema_node,
database="glue_cat_db_target",
table_name="targetdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
job.commit()
AWS Glue, işin DPU yapılandırmasına bağlı olarak, AWS Glue bağlantısında yapılandırılmış yönlendirilemeyen alt ağda bir dizi ENI oluşturur. Bu ENI'leri Ağ Arayüzleri sayfasından izleyebilirsiniz. Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2) konsolu.
Aşağıdaki ekran görüntüsü, iş parametrelerinde yapılandırılan talep edilen işçi sayısıyla eşleşmek üzere iş çalıştırması için oluşturulan 10 ENI'yi gösterir. Beklendiği gibi ENI'ler, VPC A'nın yönlendirilemeyen alt ağında oluşturuldu ve IP adreslerinin ölçeklenebilirliğine olanak tanıdı. İş tamamlandıktan sonra bu ENI'ler AWS Glue tarafından otomatik olarak yayınlanacaktır.
AWS Glue işi çalışırken durumunu izleyebilirsiniz. Başarılı bir şekilde tamamlandıktan sonra işin durumu şu şekilde değişir: başarılı.
Sonuçları doğrulayın
AWS Glue işi tamamlandıktan sonra hedef MySQL veritabanına bağlanın. Hedef kayıt sayısının kaynakla eşleşip eşleşmediğini doğrulayın. AWS Cloud9 terminalinde aşağıdaki SQL sorgusunu kullanabilirsiniz.
USE targetdb;
SELECT count(*) from emp;Son olarak aşağıdaki komutu kullanarak MySQL istemci yardımcı programından çıkın ve AWS Cloud9 terminaline dönün: quit;
Artık AWS Glue'nun, yönlendirilemeyen bir alt ağdaki IP adreslerini kullanarak hedef veritabanına veri yükleme işini başarıyla tamamladığını doğrulayabilirsiniz. Bu, özel NAT ağ geçidi çözümünün uçtan uca testini tamamlar.
Temizlemek
Gelecekte ücret alınmasını önlemek için aşağıdaki adımları tamamlayarak CloudFormation yığını aracılığıyla oluşturulan kaynağı silin:
- AWS CloudFormation konsolunda gezinme bölmesinde Yığınlar'a tıklayın.
- yığını seçin
AWSGluePrivateNATStack. - Yığını silmek için Sil'e tıklayın. İstendiğinde yığın silme işlemini onaylayın.
Sonuç
Bu gönderide, özel bir NAT ağ geçidi çözümü kullanarak IP adresi tüketimini optimize ederek ve ağ kapasitenizi genişleterek AWS Glue işlerini nasıl ölçeklendirebileceğinizi gösterdik. Bu iki yönlü yaklaşım, IP adresi kapasitesi kısıtlamalarının olduğu bir ortamda engellemenin kaldırılmasına yardımcı olur. AWS Glue IP adresi optimizasyonu bölümünde ele alınan seçenekler, IP adresi genişletme çözümlerini tamamlayıcı niteliktedir ve veri platformunuzu olgunlaştırmak için yinelemeli olarak derleme yapabilirsiniz.
AWS Glue işi optimizasyon teknikleri hakkında daha fazla bilgiyi şuradan alabilirsiniz: AWS Glue for Apache Spark'ta maliyeti izleyin ve optimize edin ve AWS Glue ile Apache Spark işlerini ölçeklendirmek ve verileri bölümlemek için en iyi uygulamalar.
yazarlar hakkında
 Sushanth Kothapally Amazon Web Services'te Otomotiv ve Üretim müşterilerini destekleyen bir Çözüm Mimarıdır. İş hedeflerine ulaşmak için teknoloji çözümleri tasarlama konusunda tutkuludur ve sunucusuz ve olay odaklı mimarilere büyük ilgi duymaktadır.
Sushanth Kothapally Amazon Web Services'te Otomotiv ve Üretim müşterilerini destekleyen bir Çözüm Mimarıdır. İş hedeflerine ulaşmak için teknoloji çözümleri tasarlama konusunda tutkuludur ve sunucusuz ve olay odaklı mimarilere büyük ilgi duymaktadır.
 Senthil Kamala Rathinam Amazon Web Services'te Veri ve Analitik konusunda uzmanlaşmış bir Çözüm Mimarıdır. Müşterilerin modern veri platformları tasarlamalarına ve oluşturmalarına yardımcı olma konusunda tutkulu. Senthil boş zamanlarında ailesiyle vakit geçirmeyi ve badminton oynamayı seviyor.
Senthil Kamala Rathinam Amazon Web Services'te Veri ve Analitik konusunda uzmanlaşmış bir Çözüm Mimarıdır. Müşterilerin modern veri platformları tasarlamalarına ve oluşturmalarına yardımcı olma konusunda tutkulu. Senthil boş zamanlarında ailesiyle vakit geçirmeyi ve badminton oynamayı seviyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/scale-aws-glue-jobs-by-optimizing-ip-address-consumption-and-expanding-network-capacity-using-a-private-nat-gateway/

