"Data är i centrum för varje ansökan, process och affärsbeslut. När data används för att förbättra kundupplevelser och driva innovation kan det leda till affärstillväxt.”
- Swami Sivasubramanian, VP för databas, analys och maskininlärning på AWS i Med en noll-ETL-metod hjälper AWS byggare att realisera analyser i nästan realtid.
Kunder inom olika branscher blir mer datadrivna och vill öka intäkterna, minska kostnaderna och optimera sin affärsverksamhet genom att implementera nästan realtidsanalyser på transaktionsdata, och därigenom förbättra smidigheten. Baserat på kundernas behov och deras feedback, investerar AWS och går stadigt framåt mot att förverkliga vår noll-ETL-vision så att byggare kan fokusera mer på att skapa värde från data istället för att förbereda data för analys.
Vår noll-ETL integration med Amazon RedShift underlättar punkt-till-punkt datarörelse för att göra den redo för analys, artificiell intelligens (AI) och maskininlärning (ML) med Amazon Redshift på petabyte data. Inom några sekunder efter att transaktionsdata har skrivits in uppburen AWS-databaser, zero-ETL gör data sömlöst tillgänglig i Amazon Redshift, vilket tar bort behovet av att bygga och underhålla komplexa datapipelines som utför extrahera, transformera och ladda (ETL) operationer.
För att hjälpa dig fokusera på att skapa värde från data istället för att investera odifferentierad tid och resurser på att bygga och hantera ETL-pipelines mellan transaktionsdatabaser och datalager, tillkännagav fyra AWS-databas noll-ETL-integrationer med Amazon Redshift på AWS re:Invent 2023:
I det här inlägget ger vi steg-för-steg-vägledning om hur du kommer igång med operationsanalyser i nästan realtid med hjälp av Amazon Aurora PostgreSQL noll-ETL-integration med Amazon Redshift.
Lösningsöversikt
För att skapa en noll-ETL-integration anger du en Amazon Aurora PostgreSQL-kompatibel utgåva kluster (kompatibelt med PostgreSQL 15.4 och noll-ETL-stöd) som källa, och ett Redshift-datalager som mål. Integrationen replikerar data från källdatabasen till måldatalagret.
Du måste skapa Aurora PostgreSQL DB-provisionerade kluster inom Amazon RDS Database Preview Environment och en rödförskjutning tillhandahållet förhandsgranskningskluster or serverlös förhandsgranskningsarbetsgrupp, i US East (Ohio) AWS-regionen. För Amazon Redshift, se till att du väljer preview_2023-spåret för att använda noll-ETL-integrationer.
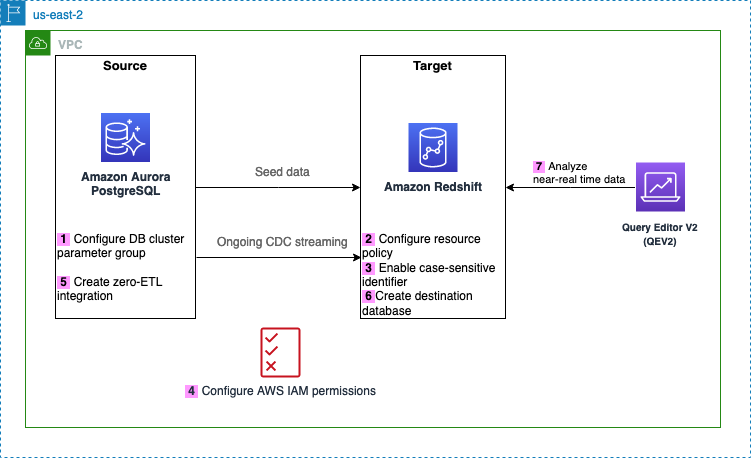
Följande diagram illustrerar arkitekturen som implementeras i det här inlägget.
Följande är stegen som behövs för att ställa in noll-ETL-integrationen för den här lösningen. För fullständiga guider för att komma igång, se Arbetar med Aurora zero-ETL-integrationer med Amazon Redshift och Arbeta med noll-ETL-integrationer.
Efter steg 1 kan du också hoppa över steg 2–4 och direkt börja skapa din noll-ETL-integration från steg 5, i vilket fall Amazon RDS visar ett meddelande om saknade konfigurationer och du kan välja Fixa det åt mig för att låta Amazon RDS automatiskt konfigurera stegen.
- Konfigurera Aurora PostgreSQL-källan med en anpassad DB-klusterparametergrupp.
- Konfigurera Amazon Redshift Serverlös destination med den nödvändiga resurspolicyn för dess namnområde.
- Uppdatera Redshift Serverless-arbetsgruppen för att aktivera skiftlägeskänsliga identifierare.
- Konfigurera de nödvändiga behörigheterna.
- Skapa noll-ETL-integrationen.
- Skapa en databas från integrationen i Amazon Redshift.
- Börja analysera transaktionsdata nästan i realtid.
Konfigurera Aurora PostgreSQL-källan med en anpassad DB-klusterparametergrupp
För Aurora PostgreSQL DB-kluster måste du skapa den anpassade parametergruppen inom Amazon RDS Database Preview Environment, i USA:s östra region (Ohio). Du kan direkt åtkomst till Amazon RDS Preview Environment.
För att skapa en Aurora PostgreSQL-databas, utför följande steg:
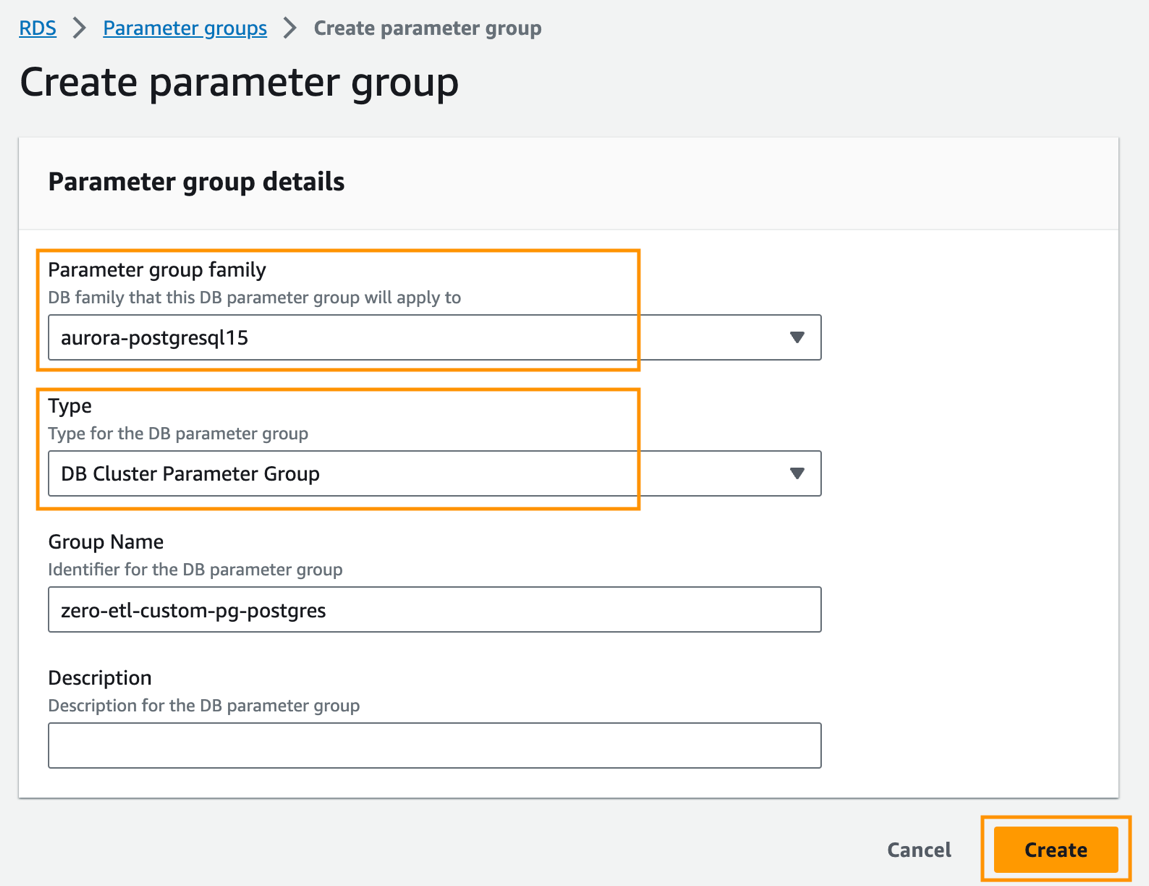
- Välj på Amazon RDS-konsolen Parametergrupper i navigeringsfönstret.
- Välja Skapa parametergrupp.
- För Parametergruppfamiljväljer
aurora-postgresql15. - För Typväljer
DB Cluster Parameter Group. - För Grupp namn, ange ett namn (t.ex.
zero-etl-custom-pg-postgres). - Välja Skapa.
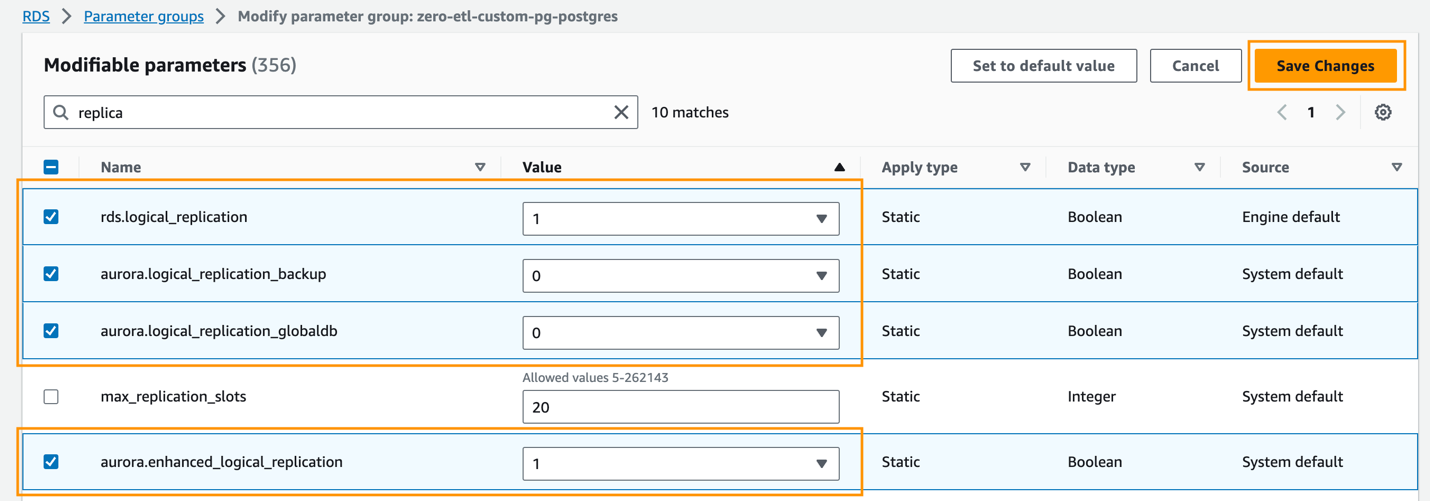
Aurora PostgreSQL noll-ETL-integrationer med Amazon Redshift kräver specifika värden för Aurora DB-klusterparametrar, som kräver förbättrad logisk replikering (aurora.enhanced_logical_replication).
- På Parametergrupper sida, välj den nyskapade parametergruppen.
- På Handlingar meny, välj Redigera.
- Ställ in följande Aurora PostgreSQL (aurora-postgresql15 familj) klusterparameterinställningar:
rds.logical_replication=1aurora.enhanced_logical_replication=1aurora.logical_replication_backup=0aurora.logical_replication_globaldb=0
Aktivering av utökad logisk replikering (aurora.enhanced_logical_replication) ställer automatiskt in parametern REPLICA IDENTITY till FULL, vilket innebär att alla kolumnvärden skrivs till loggen för skrivning framåt (WAL).
- Välja Spara ändringar.
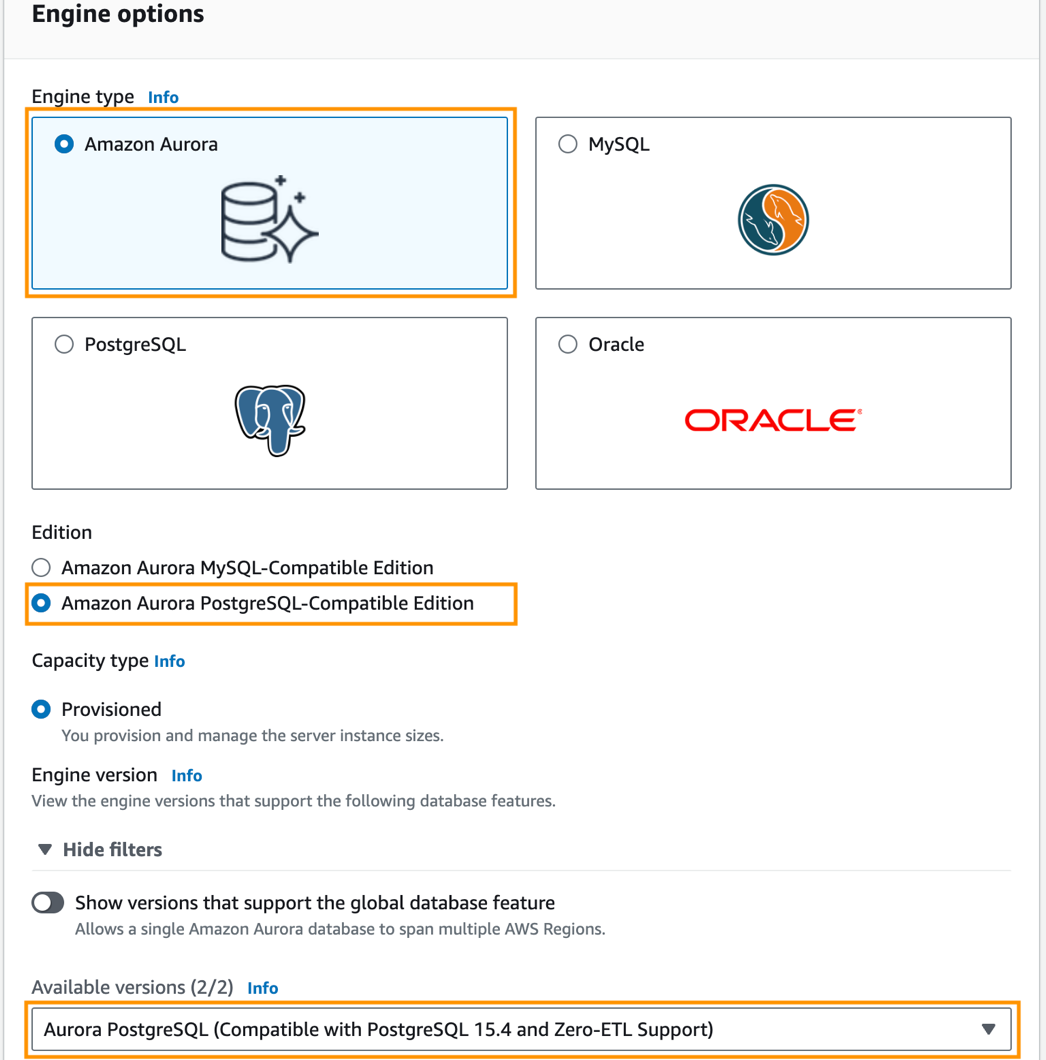
- Välja Databaser i navigeringsfönstret och välj sedan Skapa databas.

- För Motortyp, Välj Amazon-Aurora.
- För edition, Välj Amazon Aurora PostgreSQL-kompatibel utgåva.
- För Tillgängliga versionerväljer Aurora PostgreSQL (kompatibel med PostgreSQL 15.4 och Zero-ETL Support).
- För Mallar, Välj Produktion.
- För DB-klusteridentifierare, stiga på
zero-etl-source-pg.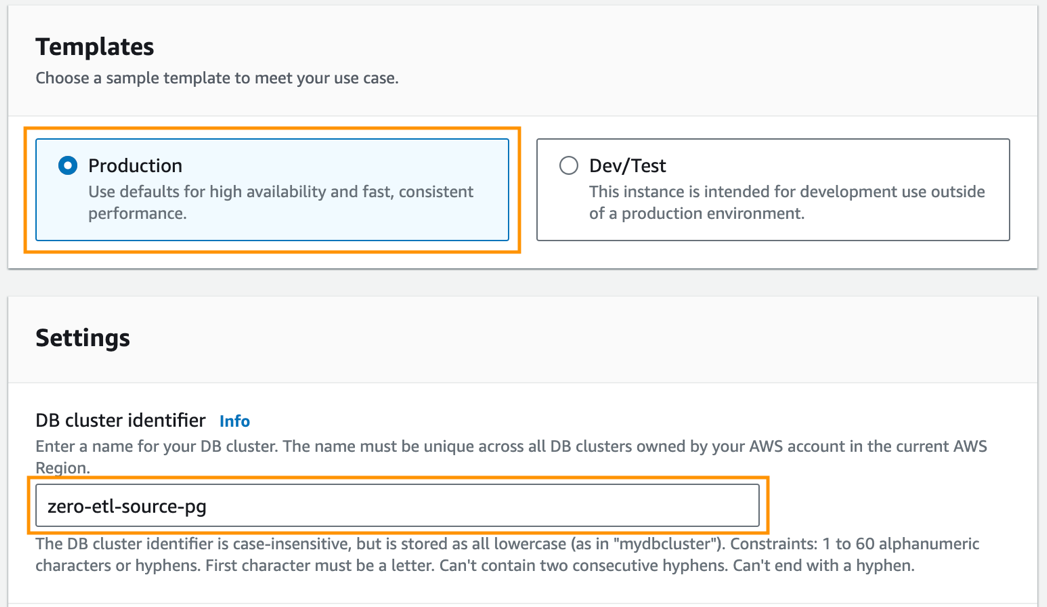
- Enligt Autentiseringsinställningar, ange ett lösenord för Huvudlösenord eller använd alternativet för att automatiskt skapa ett lösenord åt dig.
- I Avsnittet Instanskonfiguration, Välj Minnesoptimerade klasser.
- Välj en lämplig instansstorlek (standard är
db.r5.2xlarge).
- Enligt Ytterligare konfiguration, För DB-klusterparametergrupp, välj parametergruppen du skapade tidigare (
zero-etl-custom-pg-postgres).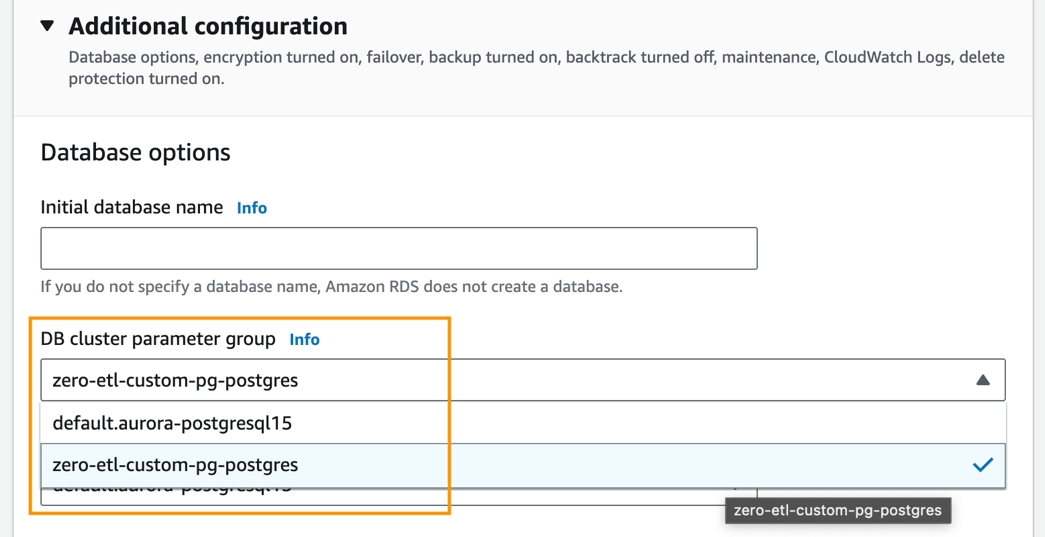
- Lämna standardinställningarna för de återstående konfigurationerna.
- Välja Skapa databas.
Om några minuter bör detta spinna upp ett Aurora PostgreSQL-kluster, med en skribent- och en läsarinstans, med status som ändras från Skapa till Tillgängliga. Det nyskapade Aurora PostgreSQL-klustret kommer att vara källan för noll-ETL-integrationen.
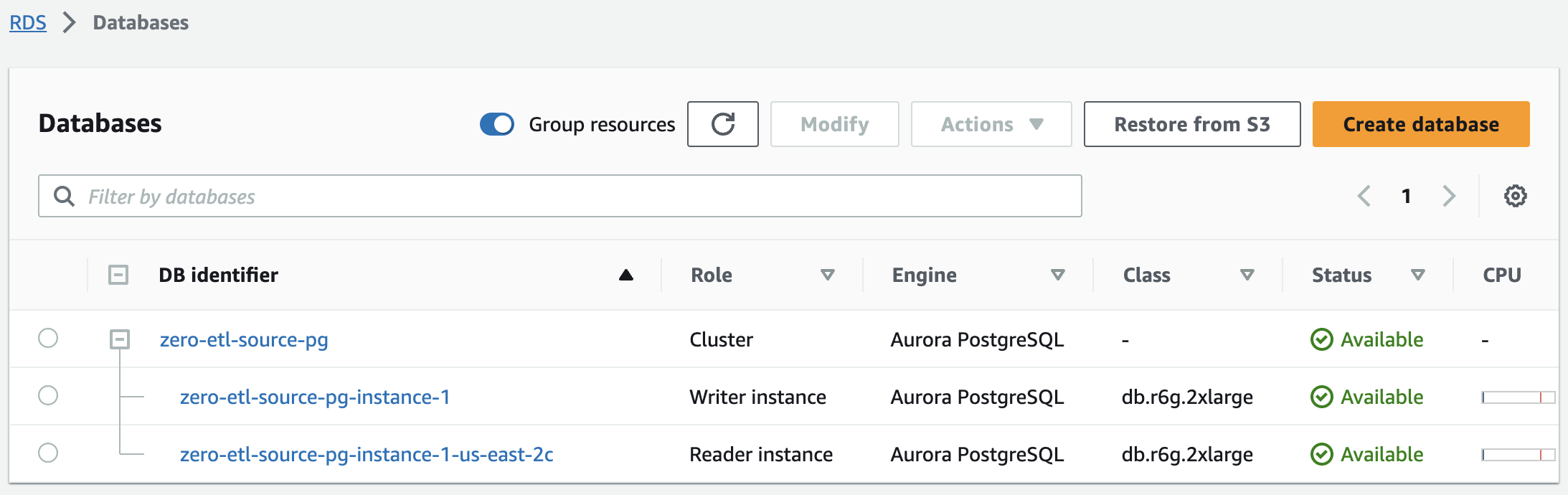
Nästa steg är att skapa en namngiven databas i Amazon Aurora PostgreSQL för noll-ETL-integrationen.
Med PostgreSQL-resursmodellen kan du skapa flera databaser inom ett kluster. Under steget att skapa noll-ETL-integrering måste du därför ange vilken databas du vill använda som källa för din integration.
När du ställer in PostgreSQL får du tre standarddatabaser ur lådan: template0, template1 och postgres. När du skapar en ny databas i PostgreSQL, baserar du den faktiskt på en av dessa tre databaser i ditt kluster. Databasen som skapades när Aurora PostgreSQL-kluster skapades är baserad på mall0. De CREATE DATABASE kommandot fungerar genom att kopiera en befintlig databas, och om det inte uttryckligen anges, kopierar det som standard standardsystemets databasmall1. För den namngivna databasen för noll-ETL-integrering måste databasen skapas med mall1 och inte mall0. Därför, om ett initialt databasnamn läggs till under Ytterligare konfiguration, som skulle skapas med template0 och kan inte användas för noll-ETL-integrering.
- För att skapa en ny namngiven databas med
CREATE DATABASEinom det nya Aurora PostgreSQL-klustretzero-etl-source-pg, skaffa först slutpunkten för skribentinstansen av PostgreSQL-klustret.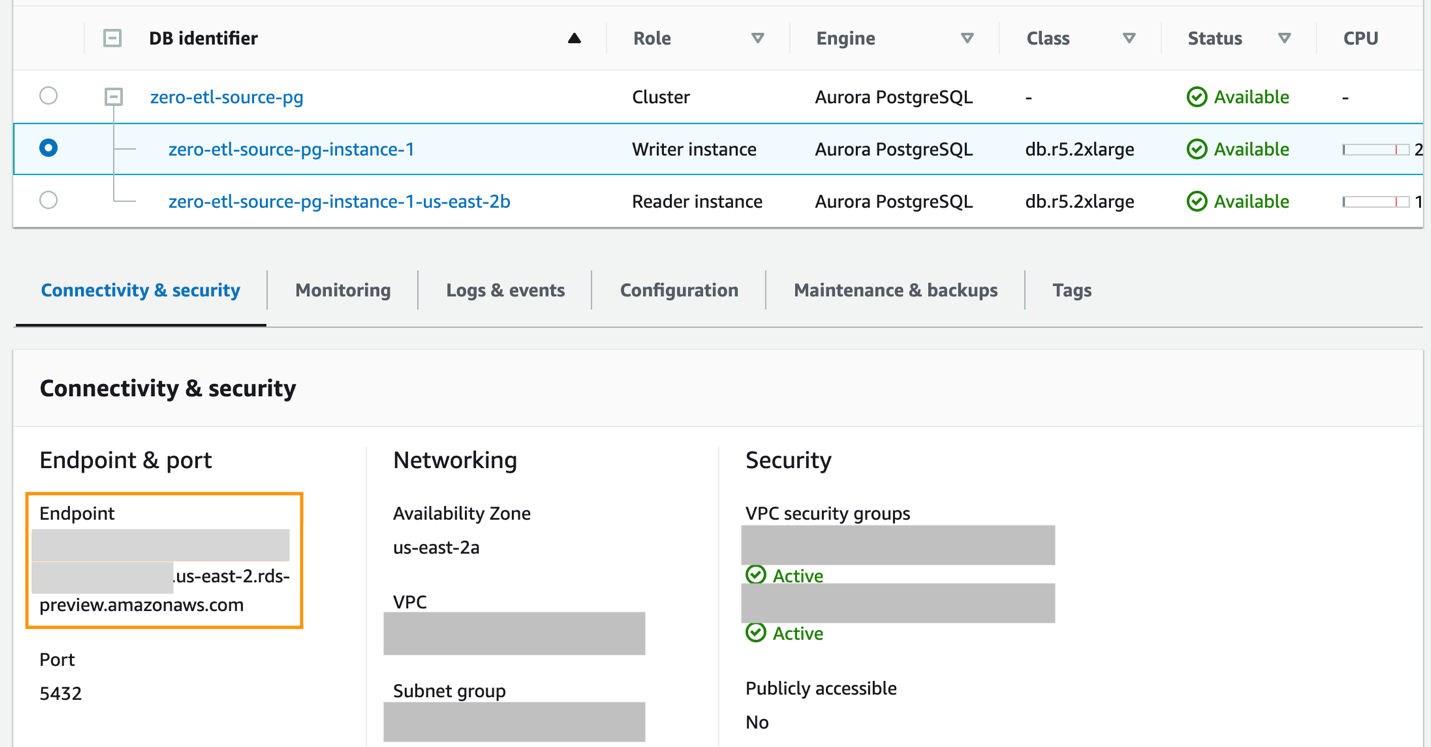
- Från en terminal eller med hjälp av AWS CloudShell, SSH i PostgreSQL-klustret och kör följande kommandon för att installera psql och skapa en ny databas
zeroetl_db:
Lägga template template1 är valfritt, eftersom som standard, om det inte nämns, CREATE DATABASE kommer att använda template1.
Du kan också ansluta via en klient och skapa databasen. Hänvisa till Anslut till ett Aurora PostgreSQL DB-kluster för alternativen att ansluta till PostgreSQL-klustret.
Konfigurera Redshift Serverless som destination
När du har skapat ditt Aurora PostgreSQL-källdatabaskluster konfigurerar du ett Redshift-måldatalager. Datalagret måste uppfylla följande krav:
- Skapad i förhandsvisning (endast för Aurora PostgreSQL-källor)
- Använder en RA3-nodtyp (ra3.16xlarge, ra3.4xlarge eller ra3.xlplus) med minst två noder, eller Redshift Serverless
- Krypterad (om du använder ett tillhandahållet kluster)
För det här inlägget skapar och konfigurerar vi en Redshift Serverless-arbetsgrupp och namnutrymme som måldatalager, genom att följa dessa steg:
- Välj på Amazon Redshift-konsolen Serverlös instrumentpanel i navigeringsfönstret.
Eftersom noll-ETL-integrationen för Amazon Aurora PostgreSQL till Amazon Redshift har lanserats i förhandsvisning (inte för produktionsändamål), måste du skapa måldatalagret i en förhandsgranskningsmiljö.
- Välja Skapa förhandsgranskningsarbetsgrupp.
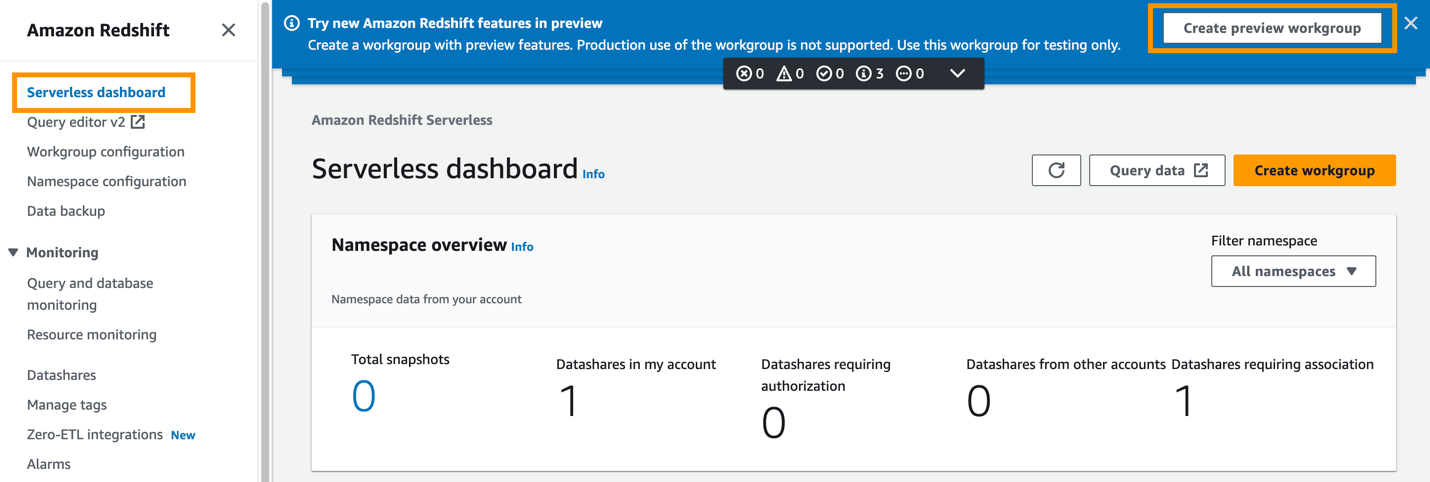
Det första steget är att konfigurera Redshift Serverless-arbetsgruppen.
- För Arbetsgruppens namn, ange ett namn (t.ex.
zero-etl-target-rs-wg).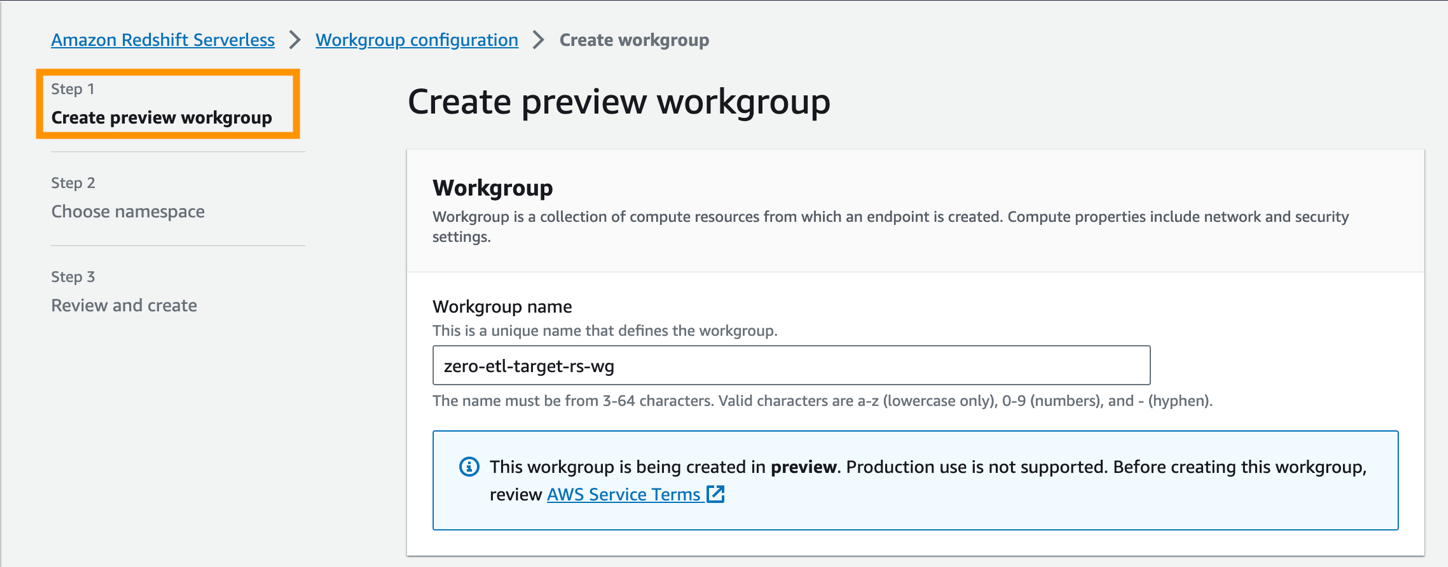
- Dessutom kan du välja kapacitet för att begränsa datalagrets beräkningsresurser. Kapaciteten kan konfigureras i steg om 8, från 8–512 RPU:er. För detta inlägg, ställ in detta till
8RPU:er. - Välja Nästa.

Därefter måste du konfigurera namnutrymmet för datalagret.
- Välja Skapa ett nytt namnområde.
- För namespace, ange ett namn (t.ex.
zero-etl-target-rs-ns). - Välja Nästa.
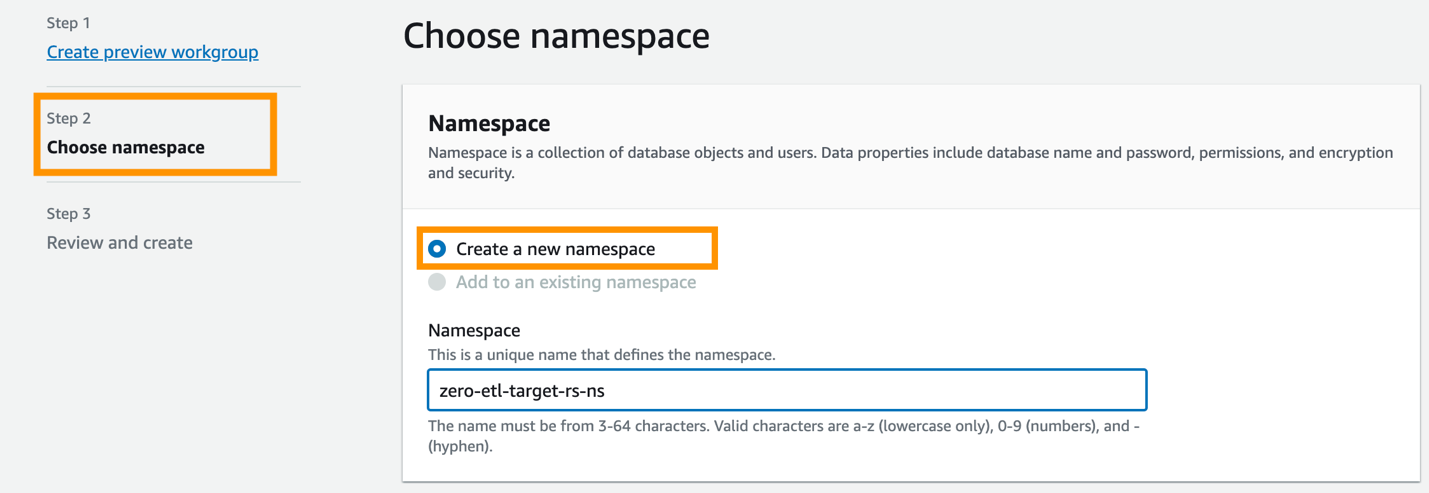
- Välja Skapa arbetsgrupp.
- När arbetsgruppen och namnutrymmet har skapats väljer du Namnutrymmeskonfigurationer i navigeringsfönstret och öppna namnutrymmeskonfigurationen.
- På Resurspolicy fliken, välj Lägg till auktoriserade huvudmän.
En auktoriserad huvudman identifierar användaren eller rollen som kan skapa noll-ETL-integrationer i datalagret.

- För IAM-huvudman ARN eller AWS konto-ID, kan du antingen ange ARN för AWS-användaren eller rollen, eller ID:t för AWS-kontot som du vill ge åtkomst för att skapa noll-ETL-integrationer. (Ett konto-ID lagras som ett ARN.)
- Välja Spara ändringar.
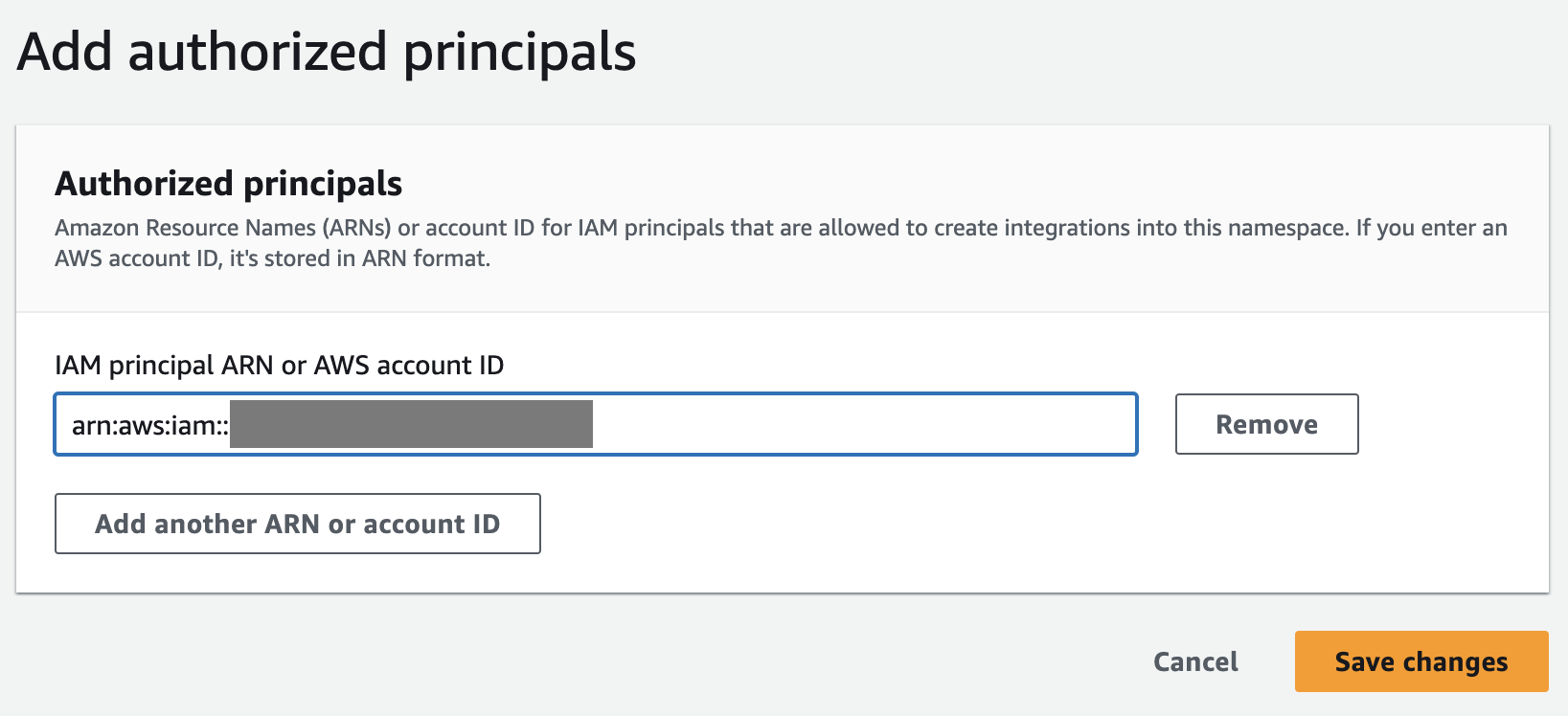
Efter att den auktoriserade huvudmannen har konfigurerats måste du tillåta källdatabasen att uppdatera ditt Redshift-datalager. Därför måste du lägga till källdatabasen som en auktoriserad integrationskälla till namnområdet.
- Välja Lägg till auktoriserad integrationskälla.
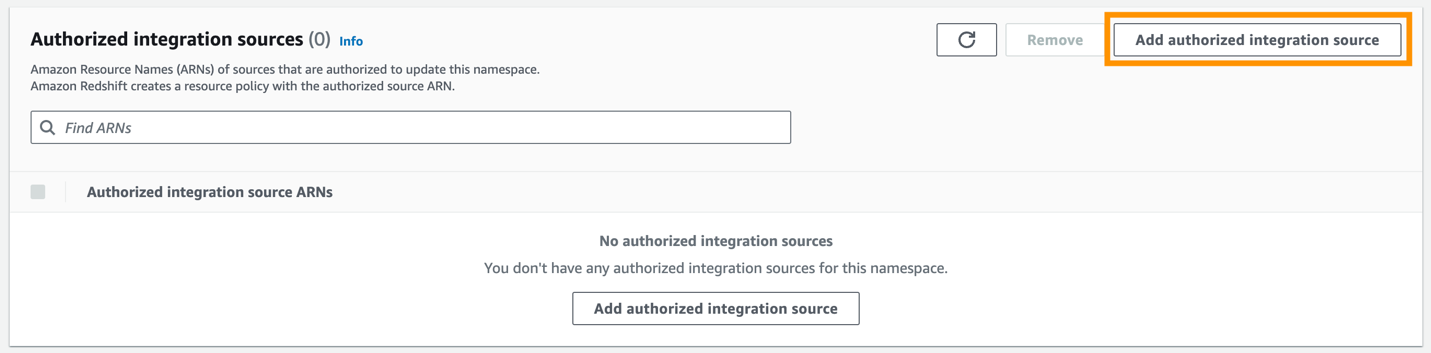
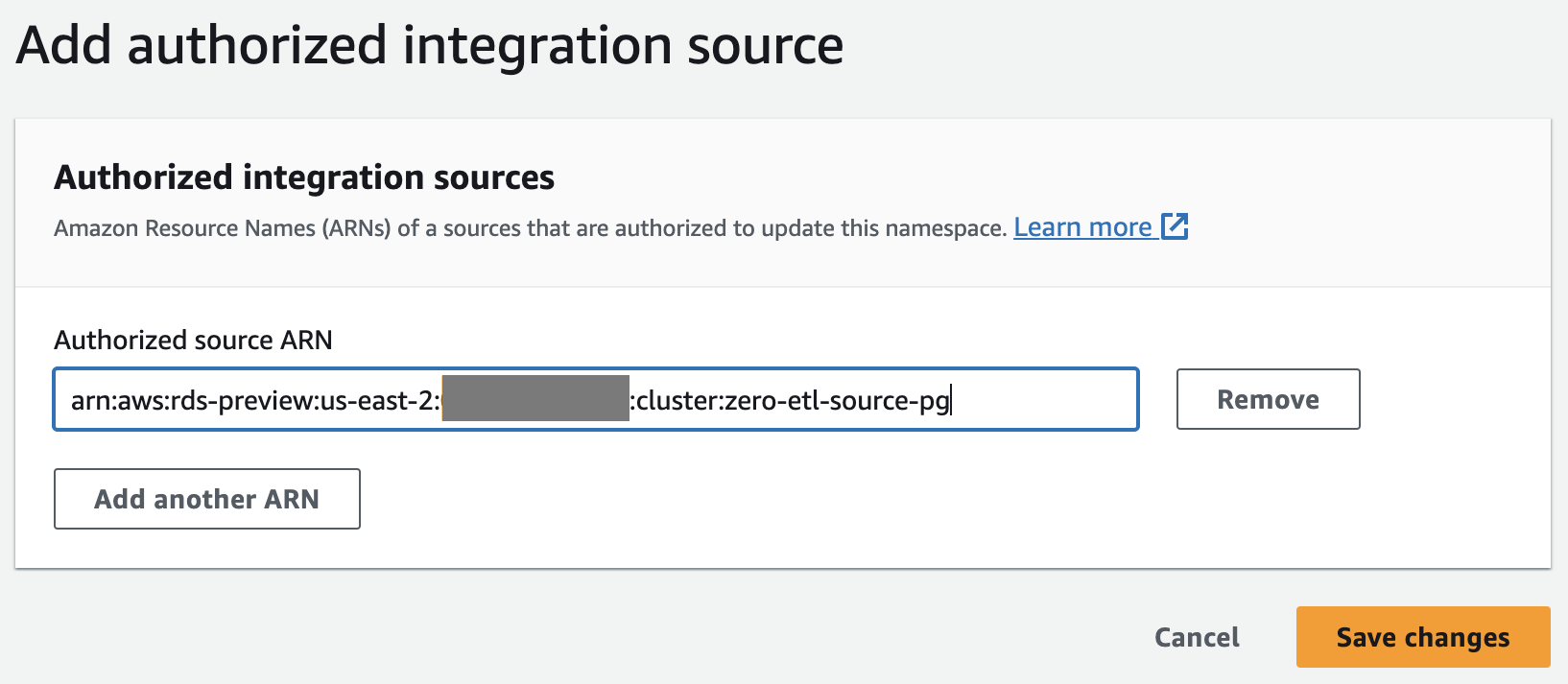
- För Behörig källa ARN, ange ARN för Aurora PostgreSQL-klustret, eftersom det är källan till noll-ETL-integrationen.
Du kan erhålla ARN för Aurora PostgreSQL-klustret på Amazon RDS-konsolen, konfiguration fliken under Amazon resursnamn.
- Välja Spara ändringar.
Uppdatera Redshift Serverless-arbetsgruppen för att aktivera skiftlägeskänsliga identifierare
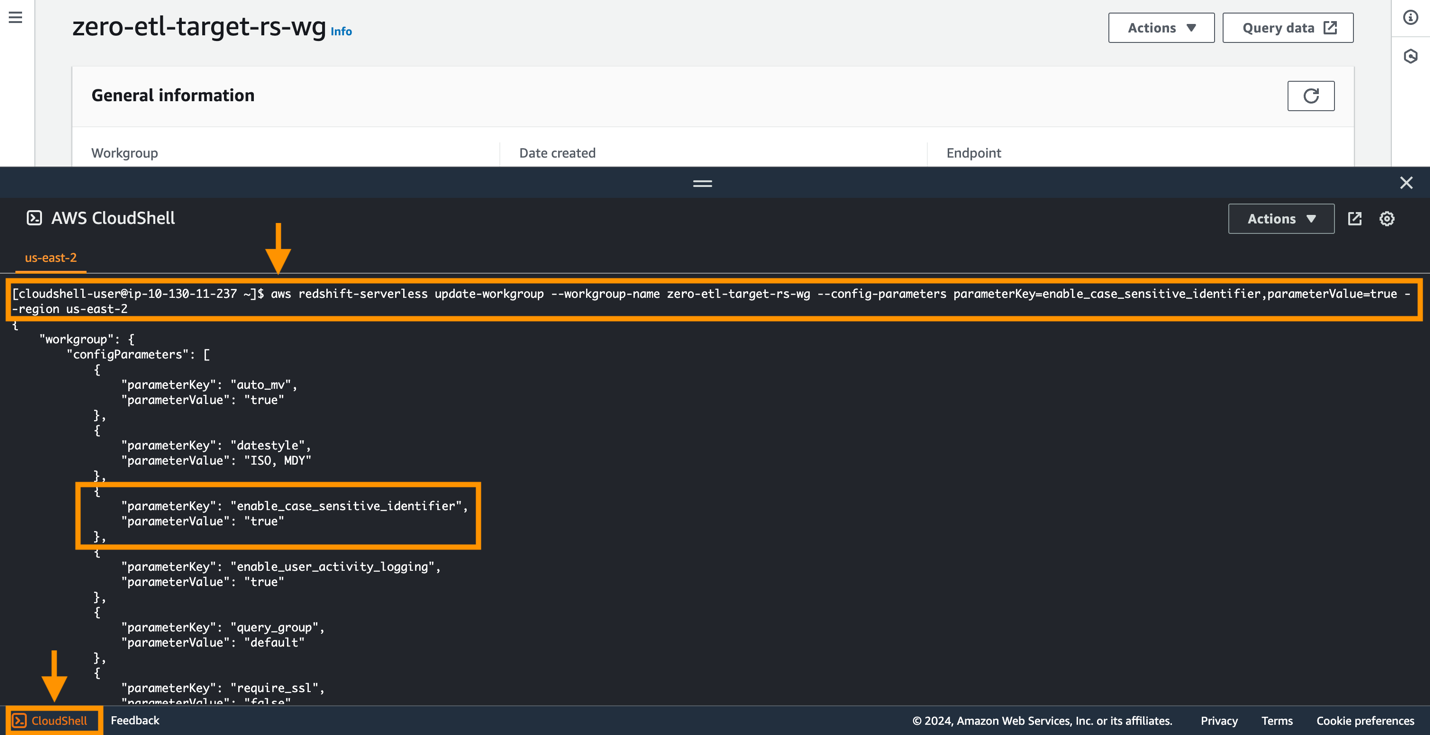
Amazon Aurora PostgreSQL är skiftlägeskänslig som standard, och skiftlägeskänslighet är inaktiverad på alla provisionerade kluster och Redshift Serverless-arbetsgrupper. För att integrationen ska bli framgångsrik, parametern skiftlägeskänslighet aktivera_skiftlägeskänslig_identifierare måste vara aktiverat för datalagret.
För att ändra enable_case_sensitive_identifier parametern i en Redshift Serverless-arbetsgrupp måste du använda AWS-kommandoradsgränssnitt (AWS CLI), eftersom Amazon Redshift-konsolen för närvarande inte stöder modifiering av Redshift Serverless-parametervärden. Kör följande kommando för att uppdatera parametern:
Ett enkelt sätt att ansluta till AWS CLI är att använda CloudShell, som är ett webbläsarbaserat skal som ger kommandoradsåtkomst till AWS-resurserna och verktygen direkt från en webbläsare. Följande skärmdump illustrerar hur du kör kommandot i CloudShell.
Konfigurera nödvändiga behörigheter
För att skapa en noll-ETL-integration måste din användare eller roll ha en bifogad identitetsbaserad policy med lämpligt AWS identitets- och åtkomsthantering (IAM) behörigheter. En AWS-kontoägare kan konfigurera nödvändiga behörigheter för användare eller roller som kan skapa noll-ETL-integrationer. Exempelpolicyn tillåter den associerade huvudmannen att utföra följande åtgärder:
- Skapa noll-ETL-integrationer för käll Aurora DB-klustret.
- Visa och ta bort alla noll-ETL-integreringar.
- Skapa inkommande integrationer i måldatalagret. Amazon Redshift har ett annat ARN-format för provisionerad och serverlös:
- Provisionerat kluster -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Server -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
Denna behörighet krävs inte om samma konto äger Redshifts datalager och detta konto är en auktoriserad huvudman för det datalagret.
Slutför följande steg för att konfigurera behörigheterna:
- Välj på IAM-konsolen policies i navigeringsfönstret.
- Välja Skapa policy.
- Skapa en ny policy som heter rds-integrations med följande JSON. För Amazon Aurora PostgreSQL-förhandsgranskningen, alla ARN:er och åtgärder inom Amazon RDS Database Preview Environment har -förhandsvisning lagt till tjänstens namnutrymme. Därför, i följande policy, istället för rds, måste du använda
rds-preview. Till exempel,rds-preview:CreateIntegration.
- Bifoga policyn du skapade till din IAM-användar- eller rollbehörighet.
Skapa noll-ETL-integrationen
Utför följande steg för att skapa noll-ETL-integrationen:
- Välj på Amazon RDS-konsolen Noll-ETL-integrationer i navigeringsfönstret.
- Välja Skapa noll-ETL-integration.
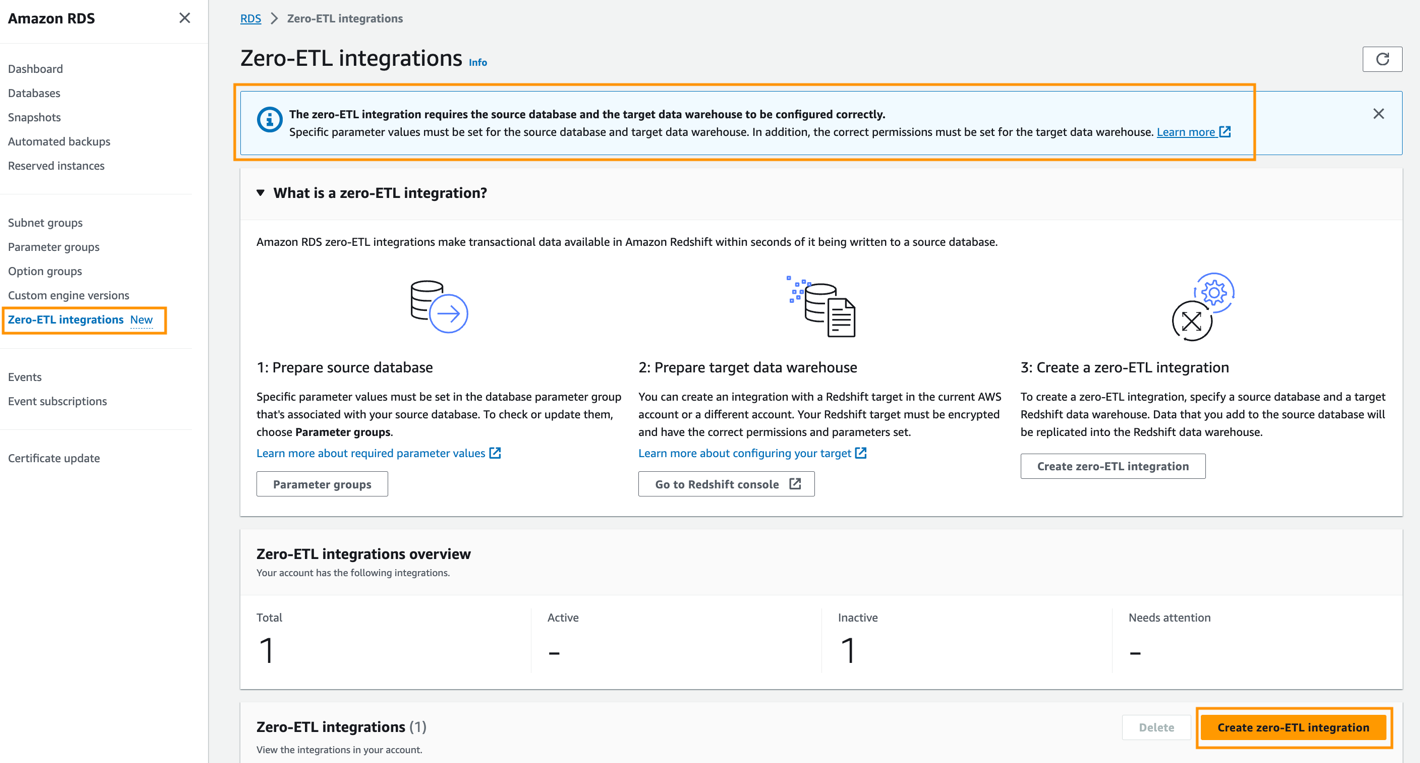
- För Integrationsidentifierare, ange till exempel ett namn
zero-etl-demo. - Välja Nästa.

- För Källdatabasväljer Bläddra i RDS-databaser.
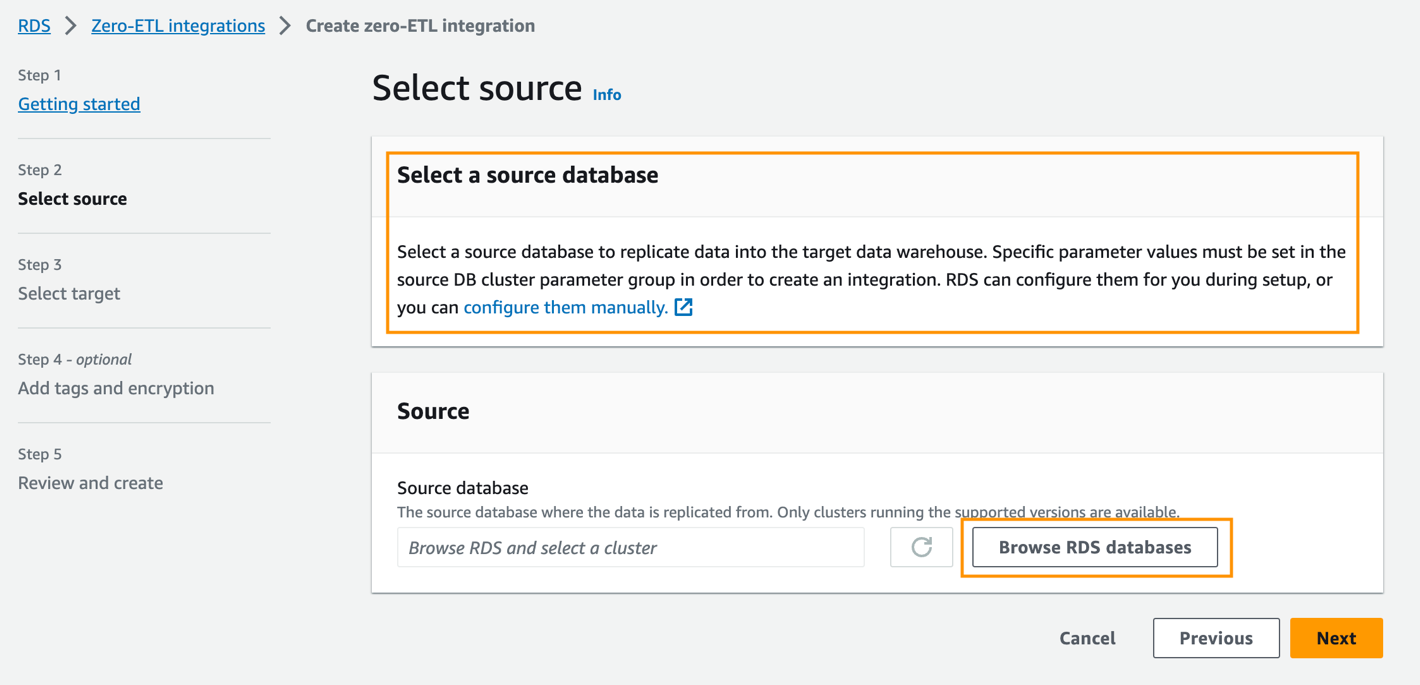
- Välj källdatabasen
zero-etl-source-pgOch välj Välja. - För Namngiven databas, ange namnet på den nya databasen som skapats i Amazon Aurora PostgreSQL (
zeroetl-db). - Välja Nästa.
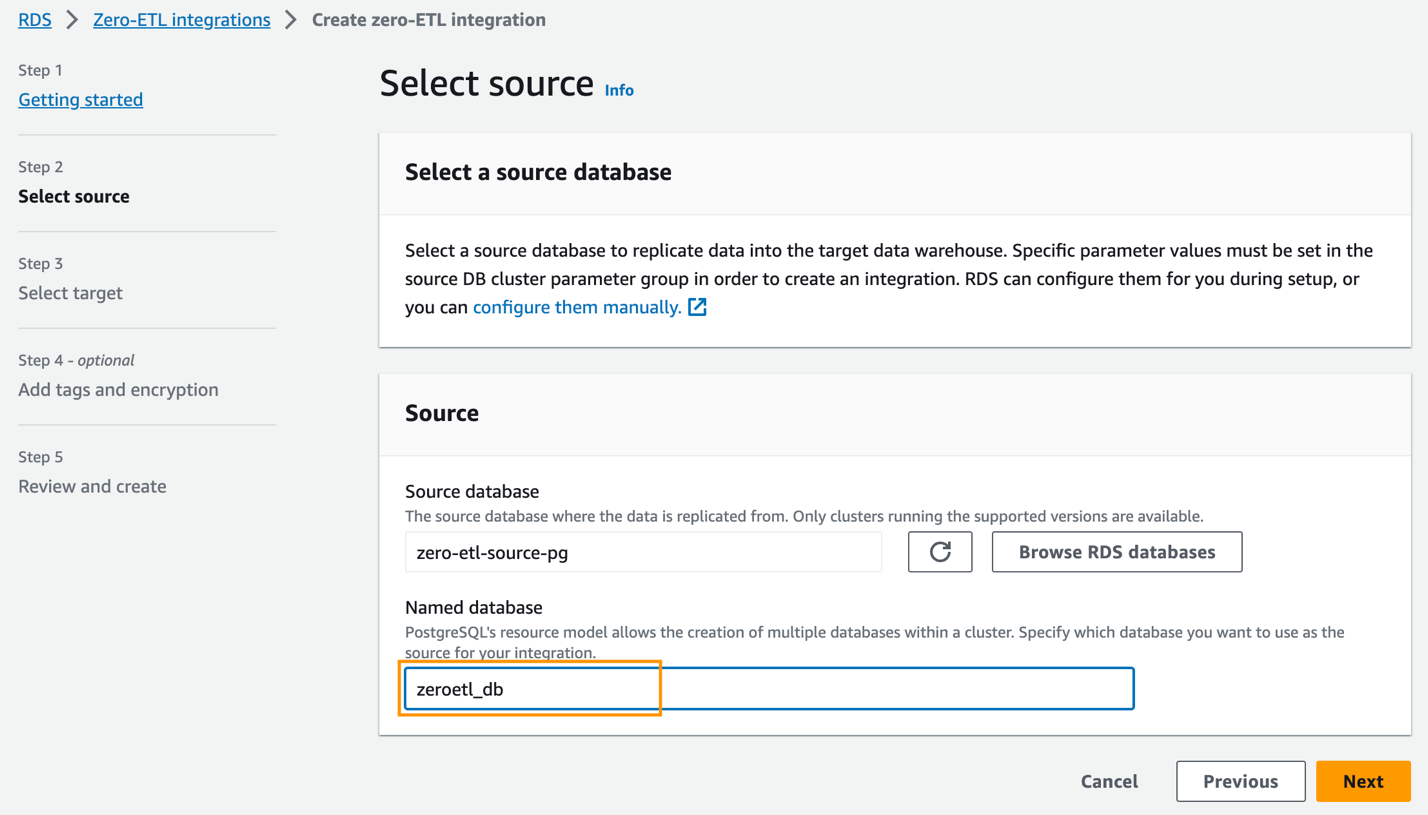
- I Målsektion, För AWS-konto, Välj Använd det aktuella kontot.
- För Amazon Redshift datalagerväljer Bläddra i Redshifts datalager.

Vi diskuterar Ange ett annat konto alternativ senare i det här avsnittet.
- Välj destinationsnamnområdet Redshift Serverless (
zero-etl-target-rs-ns) och välj Välja.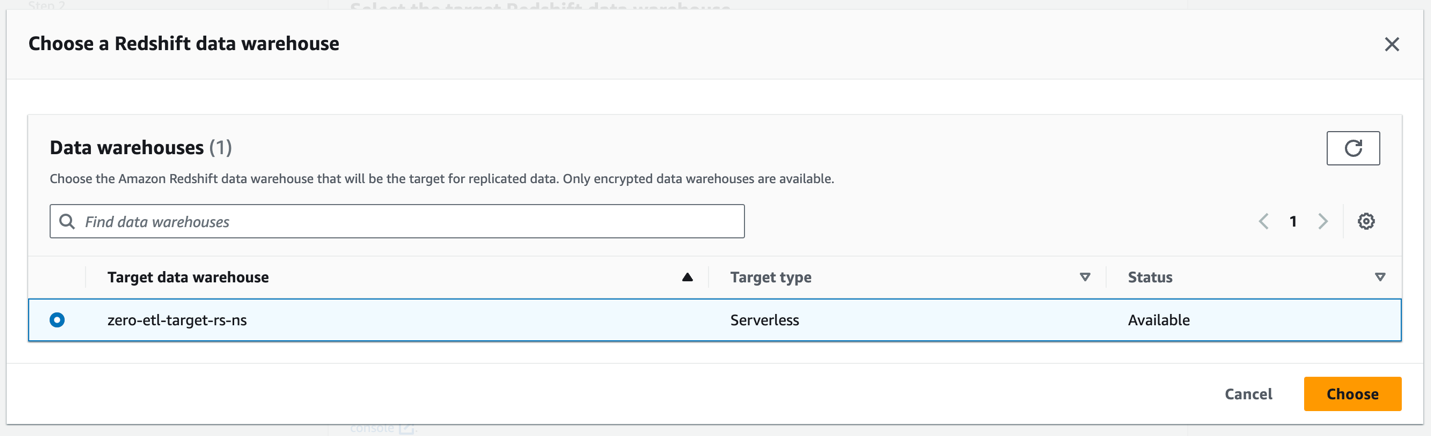
- Lägg till taggar och kryptering, om tillämpligt, och välj Nästa.
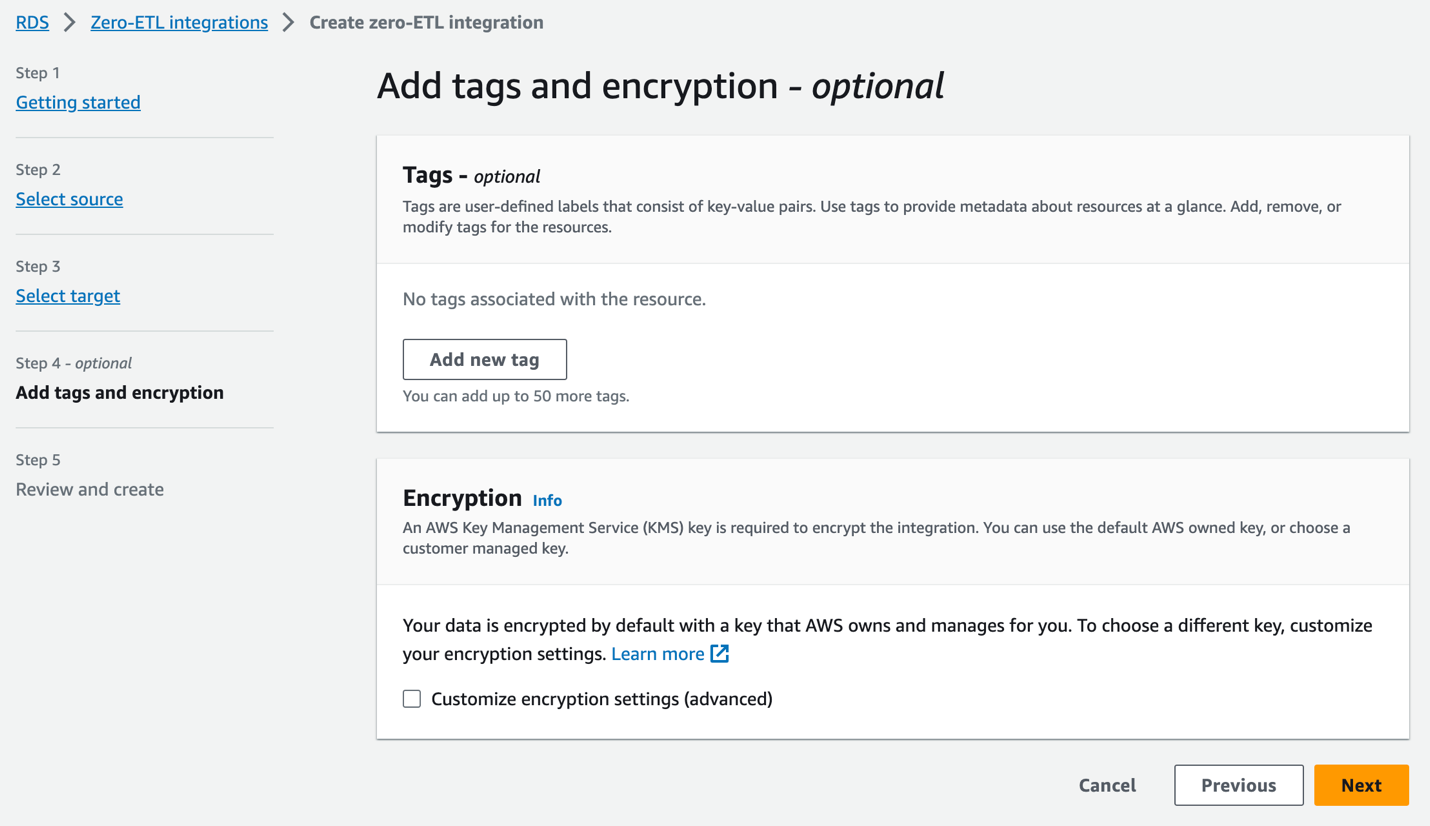
- Verifiera integrationens namn, källa, mål och andra inställningar och välj Skapa noll-ETL-integration.
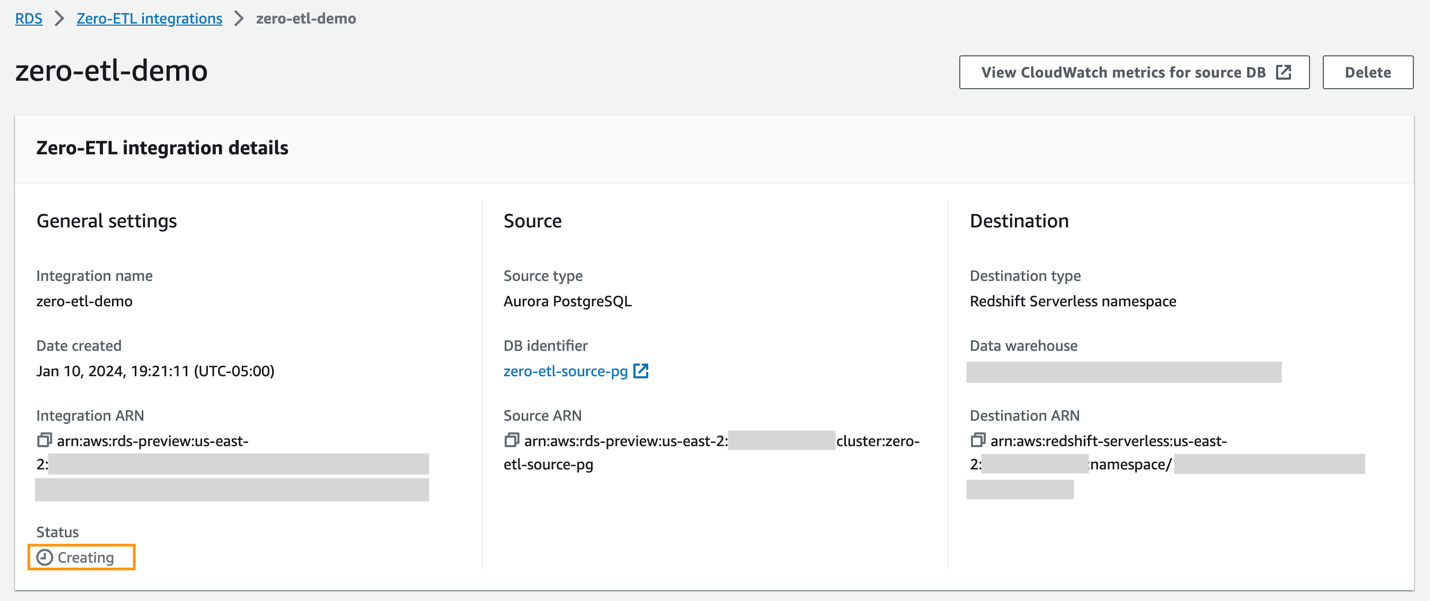
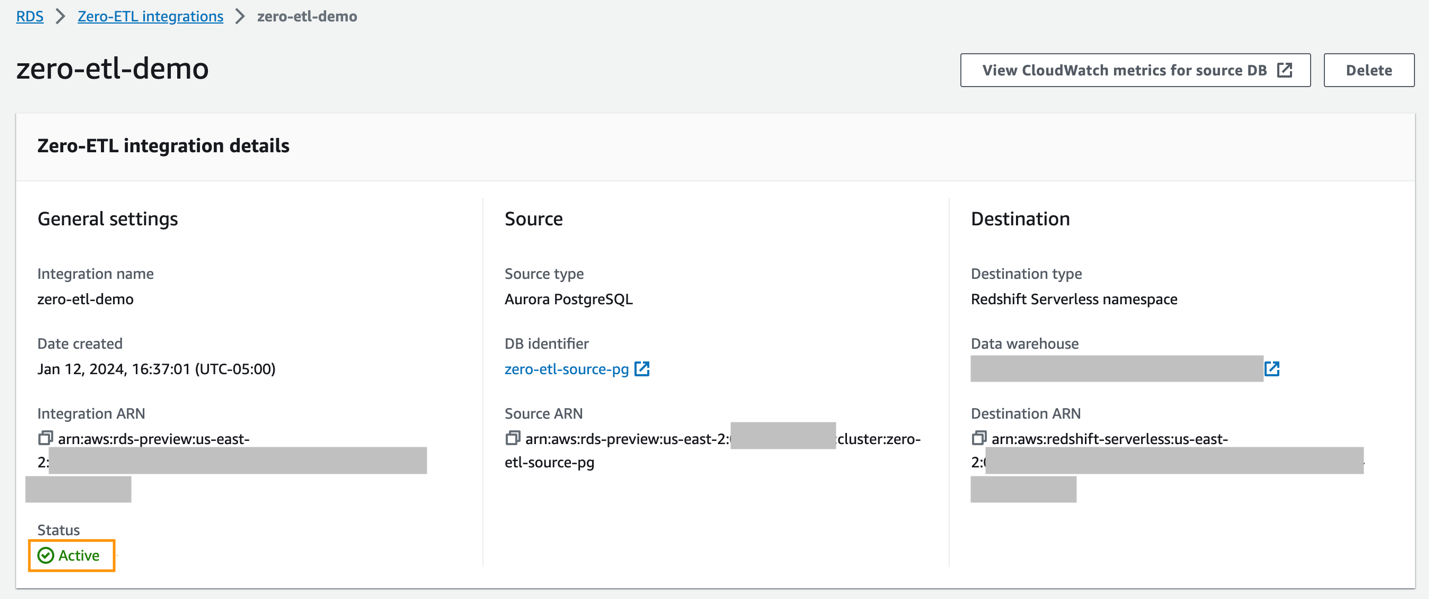
Du kan välja integrationen på Amazon RDS-konsolen för att se detaljerna och övervaka dess framsteg. Det tar cirka 30 minuter att ändra status från Skapa till Aktiva, beroende på storleken på datamängden som redan är tillgänglig i källan.
För att ange ett mål Redshift-datalager som finns i ett annat AWS-konto, måste du skapa en roll som tillåter användare i det aktuella kontot att komma åt resurser i målkontot. För mer information, se Ge åtkomst till en IAM-användare i ett annat AWS-konto som du äger.
Skapa en roll i målkontot med följande behörigheter:
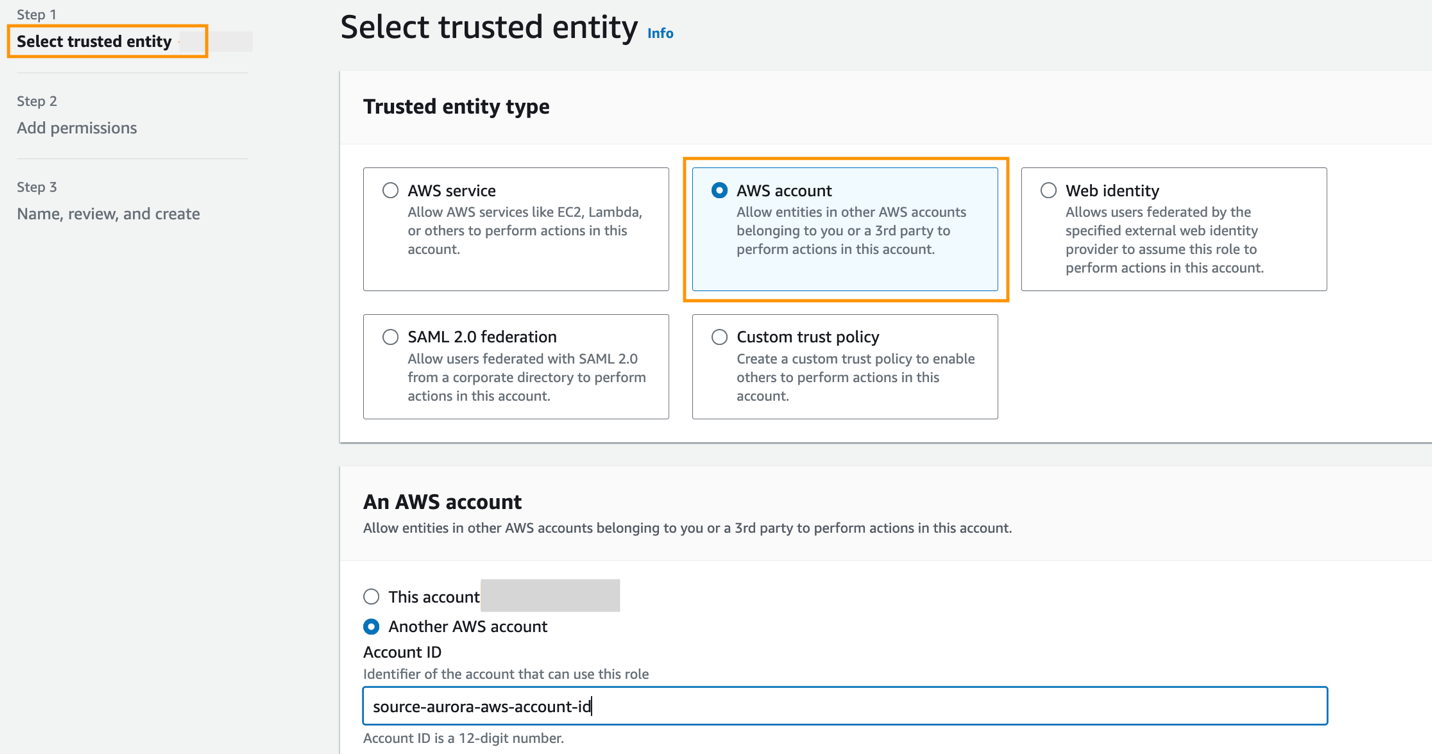
Rollen måste ha följande förtroendepolicy, som anger målkonto-ID. Du kan göra detta genom att skapa en roll med en betrodd enhet som ett AWS-konto-ID i ett annat konto.
Följande skärmdump illustrerar att du skapar detta på IAM-konsolen.
Sedan, medan du skapar noll-ETL-integrationen, för Ange ett annat konto, välj destinationskonto-ID och namnet på rollen du skapade.
Skapa en databas från integrationen i Amazon Redshift
Utför följande steg för att skapa din databas:
- På Redshift Serverless-instrumentpanelen, navigera till
zero-etl-target-rs-nsnamnområde. - Välja Fråga data för att öppna frågeredigeraren v2.

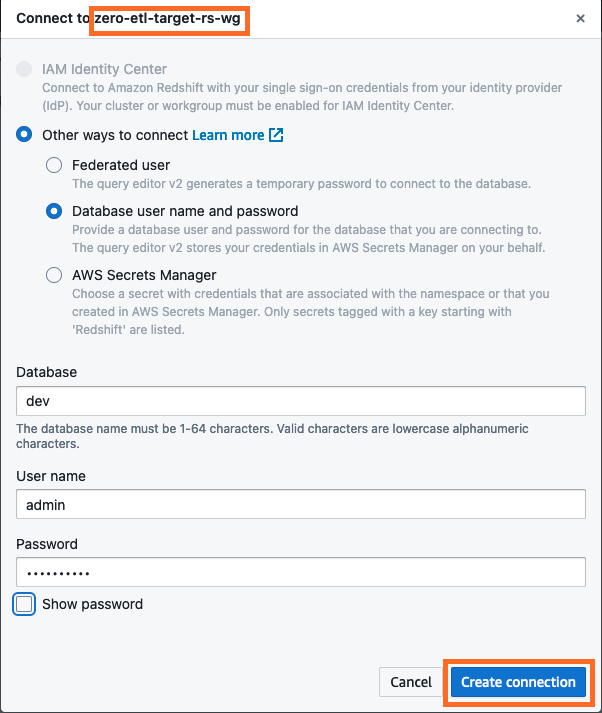
- Anslut till Redshift Serverless data warehouse genom att välja Skapa anslutning.
- Skaffa
integration_idfrånsvv_integrationsystemtabell: - Använd
integration_idfrån föregående steg för att skapa en ny databas från integrationen. Du måste också inkludera en referens till den namngivna databasen i klustret som du angav när du skapade integrationen.CREATE DATABASE aurora_pg_zetl FROM INTEGRATION '<result from above>' DATABASE zeroetl_db;
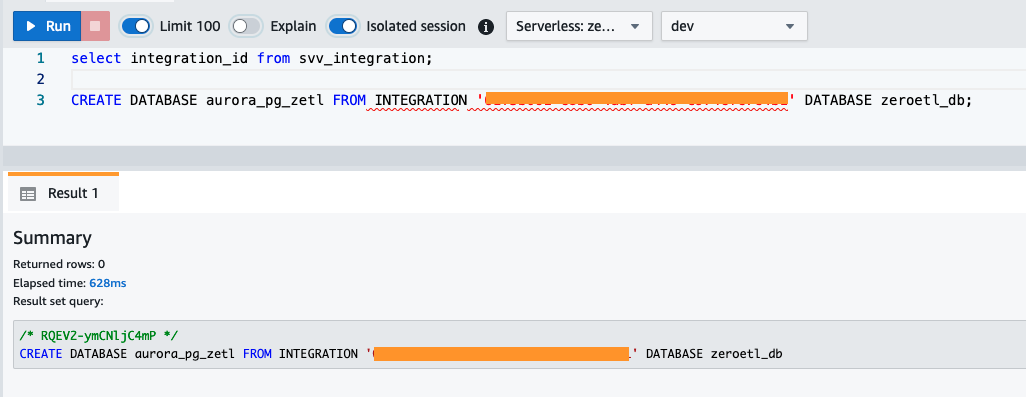
Integrationen är nu klar och en hel ögonblicksbild av källan kommer att återspegla som den är i destinationen. Pågående ändringar kommer att synkroniseras i nästan realtid.
Analysera transaktionsdata nästan i realtid
Nu kan du börja analysera nästan realtidsdata från Amazon Aurora PostgreSQL-källan till Amazon Redshift-målet:
- Anslut till din källdatabas för Aurora PostgreSQL. I denna demo använder vi psql för att ansluta till Amazon Aurora PostgreSQL:

- Skapa en exempeltabell med en primärnyckel. Se till att alla tabeller som ska replikeras från källa till mål har en primärnyckel. Tabeller utan en primärnyckel kan inte replikeras till målet.
- Infoga dummydata i nationstabellen och kontrollera om data är korrekt laddade:

Denna exempeldata ska nu replikeras i Amazon Redshift.
Analysera källdata i destinationen
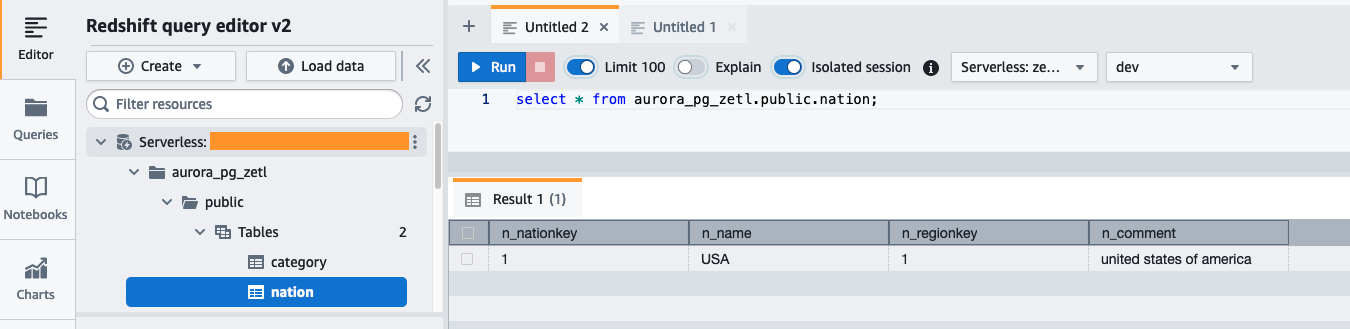
Öppna query editor v2 på Redshift Serverless-instrumentpanelen och anslut till databasen aurora_pg_zetl du skapade tidigare.
Kör följande fråga för att validera framgångsrik replikering av källdata till Amazon Redshift:
Du kan också använda följande fråga för att validera den initiala ögonblicksbilden eller pågående datainsamlingsaktiviteten (CDC):
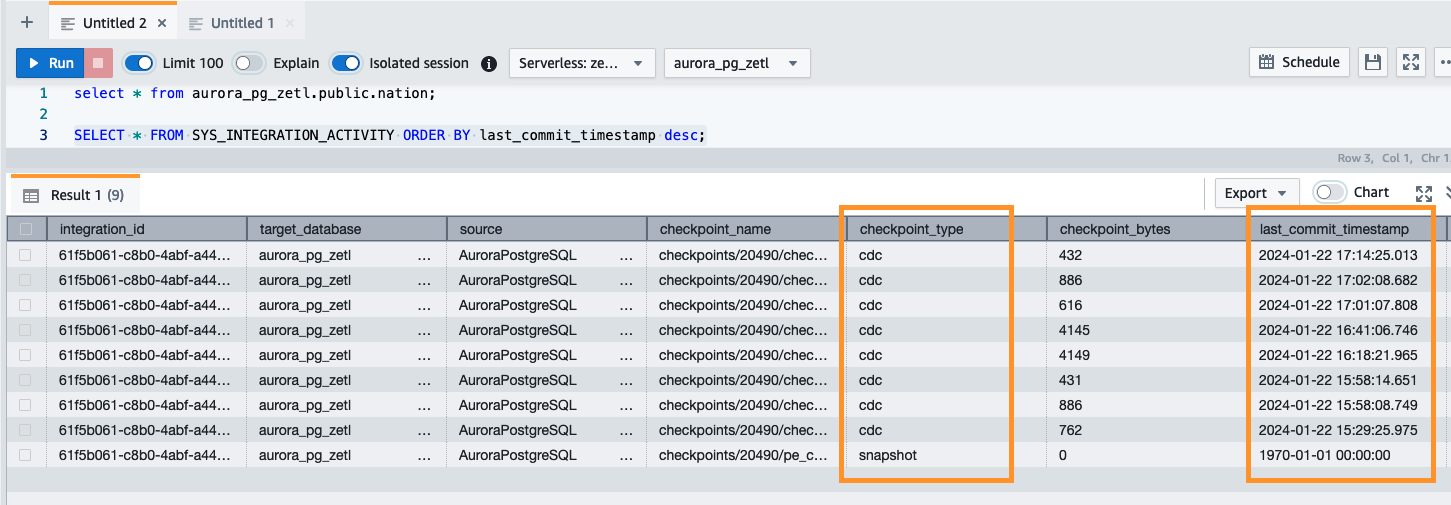
Övervakning
Det finns flera alternativ för att få statistik om prestanda och status för Aurora PostgreSQL noll-ETL-integrationen med Amazon Redshift.
Om du navigerar till Amazon Redshift-konsolen kan du välja Noll-ETL-integrationer i navigeringsfönstret. Du kan välja den noll-ETL-integration du vill ha och visa amazoncloudwatch mätvärden relaterade till integrationen. Dessa mätvärden är också direkt tillgängliga i CloudWatch.
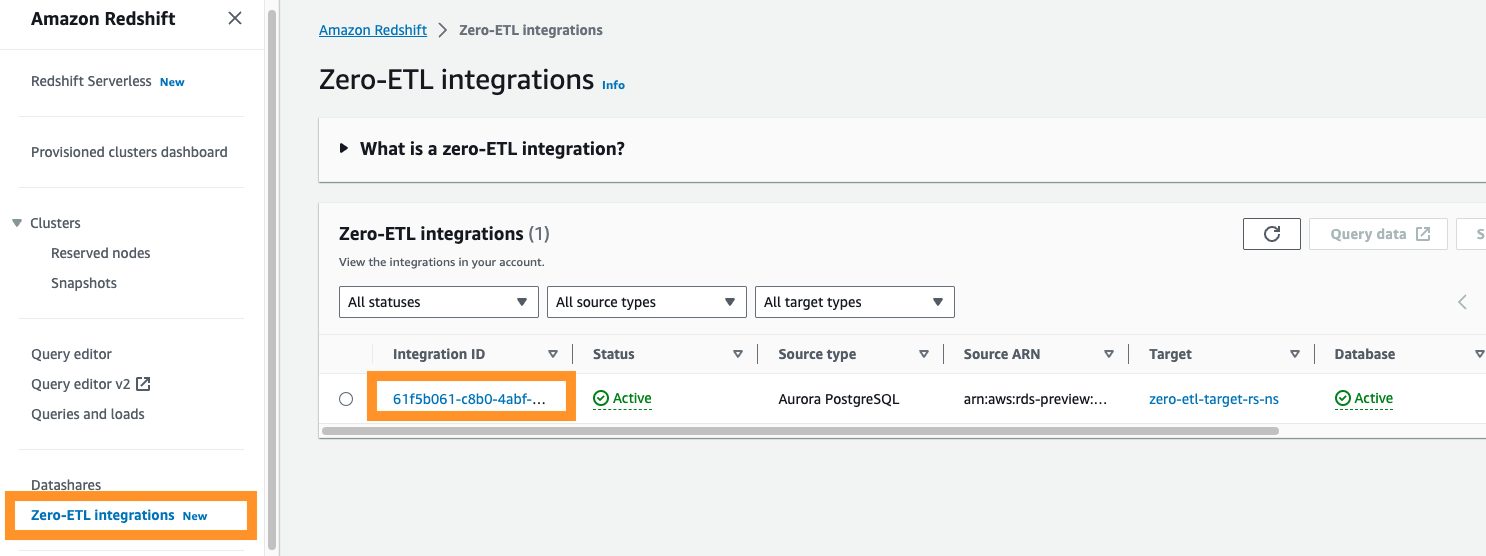
För varje integration finns det två flikar med information tillgänglig:
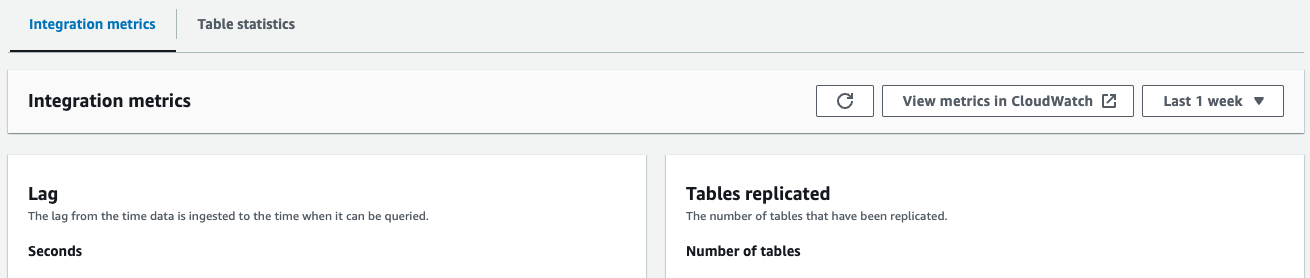
- Integrationsmått – Visar mätvärden som antalet framgångsrikt replikerade tabeller och fördröjningsdetaljer
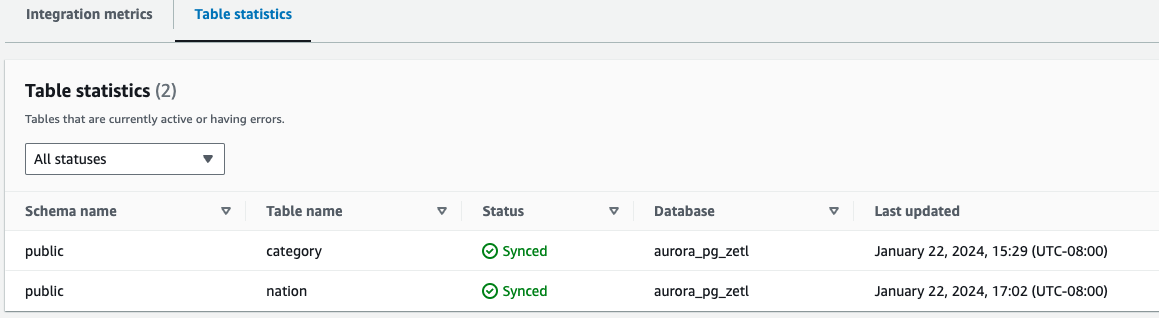
- Tabellstatistik – Visar detaljer om varje tabell replikerad från Amazon Aurora PostgreSQL till Amazon Redshift
Förutom CloudWatch-statistiken kan du fråga följande systemvyer, som ger information om integrationerna:
Städa upp
När du tar bort en noll-ETL-integrering raderas inte dina transaktionsdata från Aurora eller Amazon Redshift, men Aurora skickar inte ny data till Amazon Redshift.
För att ta bort en noll-ETL-integrering, utför följande steg:
- Välj på Amazon RDS-konsolen Noll-ETL-integrationer i navigeringsfönstret.
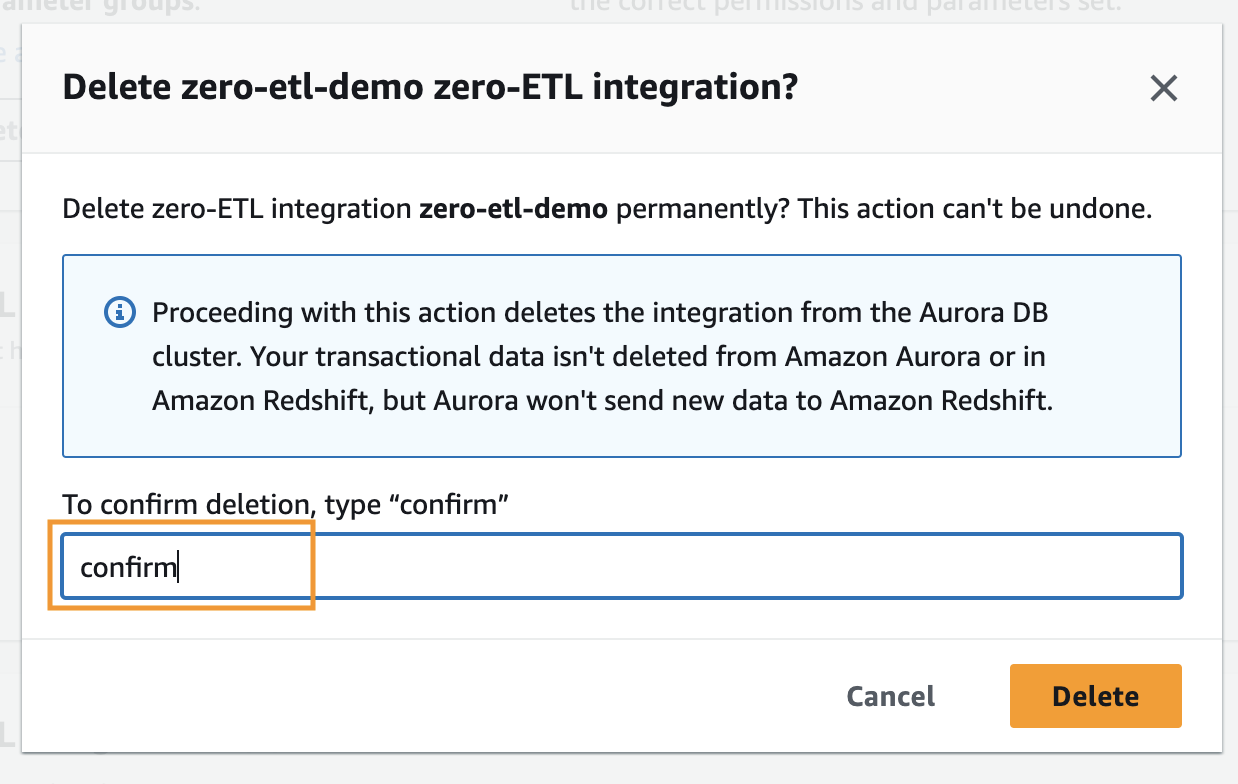
- Välj den noll-ETL-integrering som du vill ta bort och välj Radera.

- För att bekräfta raderingen, ange bekräfta och välj Radera.
Slutsats
I det här inlägget förklarade vi hur du kan ställa in noll-ETL-integrationen från Amazon Aurora PostgreSQL till Amazon Redshift, en funktion som minskar ansträngningen att underhålla datapipelines och möjliggör nästan realtidsanalys av transaktions- och operationsdata.
För att lära dig mer om noll-ETL-integration, se Arbetar med Aurora zero-ETL-integrationer med Amazon Redshift och Begränsningar.
Om författarna
 Raks Khare är en Analytics Specialist Solutions Architect på AWS baserad i Pennsylvania. Han hjälper kunder att bygga dataanalyslösningar i stor skala på AWS-plattformen.
Raks Khare är en Analytics Specialist Solutions Architect på AWS baserad i Pennsylvania. Han hjälper kunder att bygga dataanalyslösningar i stor skala på AWS-plattformen.
 Juan Luis Polo Garzon är en Associate Specialist Solutions Architect på AWS, specialiserad på analytiska arbetsbelastningar. Han har erfarenhet av att hjälpa kunder att designa, bygga och modernisera deras molnbaserade analyslösningar. Utanför jobbet tycker han om att resa, utomhus och vandra och att delta i livemusikevenemang.
Juan Luis Polo Garzon är en Associate Specialist Solutions Architect på AWS, specialiserad på analytiska arbetsbelastningar. Han har erfarenhet av att hjälpa kunder att designa, bygga och modernisera deras molnbaserade analyslösningar. Utanför jobbet tycker han om att resa, utomhus och vandra och att delta i livemusikevenemang.
 Sushmita Barthakur är en Senior Solutions Architect på Amazon Web Services, som stödjer företagskunder med att utforma deras arbetsbelastningar på AWS. Med en stark bakgrund inom dataanalys och datahantering har hon lång erfarenhet av att hjälpa kunder att utforma och bygga Business Intelligence och Analytics-lösningar, både på plats och i molnet. Sushmita är baserat från Tampa, FL och tycker om att resa, läsa och spela tennis.
Sushmita Barthakur är en Senior Solutions Architect på Amazon Web Services, som stödjer företagskunder med att utforma deras arbetsbelastningar på AWS. Med en stark bakgrund inom dataanalys och datahantering har hon lång erfarenhet av att hjälpa kunder att utforma och bygga Business Intelligence och Analytics-lösningar, både på plats och i molnet. Sushmita är baserat från Tampa, FL och tycker om att resa, läsa och spela tennis.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/achieve-near-real-time-operational-analytics-using-amazon-aurora-postgresql-zero-etl-integration-with-amazon-redshift/

