Beskrivning
I dagens snabba digitala värld har spridning av falska nyheter blivit ett stort problem. Med den ökande lättheten för åtkomst till sociala medieplattformar och andra informationskällor online har det blivit mer utmanande att skilja mellan riktiga och falska nyheter. I den här projektbaserade artikeln kommer vi att lära oss hur man bygger en maskininlärningsmodell för att upptäcka falska nyheter exakt.

Lärandemål:
- Förstå grunderna i naturlig språkbehandling (NLP) och hur det kan användas för att förbehandla textdata för maskininlärningsmodeller.
- Lär dig hur du använder klassen CountVectorizer från scikit-learn-biblioteket för att konvertera textdata till numeriska funktionsvektorer.
- Bygg ett system för upptäckt av falska nyheter med hjälp av maskininlärningsalgoritmer som logistisk regression och utvärdera dess prestanda.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
projekt beskrivning
Spridningen av falska nyheter har blivit ett stort bekymmer i dagens samhälle och det är viktigt att kunna identifiera nyhetsartiklar som inte är baserade på fakta eller är avsiktligt vilseledande. I det här projektet kommer vi att använda maskininlärning för att klassificera nyhetsartiklar som antingen äkta eller falska baserat på deras innehåll. Genom att identifiera falska nyhetsartiklar kan vi förhindra spridningen av desinformation och hjälpa människor att fatta mer välgrundade beslut.
Det här projektet är relevant för mediebranschen, nyhetskanaler och sociala medieplattformar som ansvarar för att dela nyhetsartiklar. Att klassificera nyhetsartiklar som äkta eller falska kan hjälpa dessa organisationer att förbättra sin innehållsmoderering och minska spridningen av falska nyheter.
Problemdeklaration
Detta projekt syftar till att klassificera nyhetsartiklar som äkta eller falska baserat på deras innehåll. Specifikt kommer vi att använda maskininlärning för att bygga en modell för att förutsäga om en given nyhetsartikel är verklig eller falsk baserat på dess text.
Förutsättningar
För att slutföra detta projekt bör du förstå Python-programmering, datamanipulation, visualiseringsbibliotek som Pandas och Matplotlib, och maskininlärningsbibliotek som Scikit-Learn. Dessutom skulle viss bakgrundskunskap om naturliga språkbehandlingstekniker (NLP) och textklassificeringsmetoder vara till hjälp.
Dataset Beskrivning
Datauppsättningen som används i det här projektet är "Fake and real news dataset" tillgänglig på Kaggle, som innehåller 50,000 XNUMX nyhetsartiklar märkta som antingen äkta eller falska. Datauppsättningen samlades in från olika nyhetswebbplatser och har förbehandlats för att ta bort främmande innehåll som HTML-taggar, annonser och bottentext. Datauppsättningen innehåller funktioner som varje nyhetsartikels titel, text, ämne och publiceringsdatum. Datauppsättningen kan laddas ner från följande länk: https://www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset.
Stegen vi kommer att följa i detta projekt är:
- Datainsamling och utforskning
- Förbehandling av text
- Särdragsextraktion
- Modellutbildning och utvärdering
- konfiguration
1. Datainsamling och utforskning
För detta projekt kommer vi att använda Fake and Real News Dataset som finns tillgängligt på Kaggle. Datauppsättningen innehåller två CSV-filer: en med riktiga nyhetsartiklar och en annan med falska nyhetsartiklar. Du kan ladda ner datasetet från denna länk: https://www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset
När du har laddat ner datauppsättningen kan du ladda den till en Pandas DataFrame.
Den "riktiga_nyheter' DataFrame innehåller riktiga nyhetsartiklar och deras etiketter, ochfake_news' DataFrame innehåller falska nyhetsartiklar och deras etiketter. Låt oss ta en titt på de första raderna i varje DataFrame för att få en uppfattning om hur data ser ut::
Python-kod:
Som vi kan se innehåller uppgifterna flera kolumner: artikelns titel, artikelns text, artikelns ämne och det datum då den publicerades. Vi kommer att använda rubrik- och textkolumnerna för att träna vår modell.
Innan vi kan börja träna vår modell måste vi göra lite utforskande dataanalys för att få en känsla av data. Till exempel kan vi plotta fördelningen av artikellängder i varje datamängd med hjälp av följande kod:
import matplotlib.pyplot as plt real_lengths = real_news['text'].apply(len)
fake_lengths = fake_news['text'].apply(len) plt.hist(real_lengths, bins=50, alpha=0.5, label='Real')
plt.hist(fake_lengths, bins=50, alpha=0.5, label='Fake')
plt.title('Article Lengths')
plt.xlabel('Length')
plt.ylabel('Count')
plt.legend()
plt.show()
Utgången ska se ut så här:
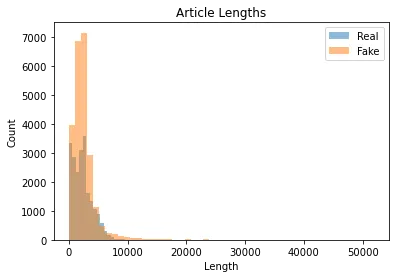
Som vi kan se är längden på artiklarna mycket varierande, med vissa artiklar mycket korta (mindre än 1000 40,000 tecken) och andra är ganska långa (mer än XNUMX XNUMX tecken). Vi måste ta hänsyn till detta när vi förbearbetar texten.
Vi kan också titta på de vanligaste orden i varje datamängd med hjälp av följande kod:
from collections import Counter
import nltk
#downloading stopwords and punkt
nltk.download('stopwords')
nltk.download('punkt') def get_most_common_words(texts, num_words=10): all_words = [] for text in texts: all_words.extend(nltk.word_tokenize(text.lower())) stop_words = set(nltk.corpus.stopwords.words('english')) words = [word for word in all_words if word.isalpha() and word not in stop_words] word_counts = Counter(words) return word_counts.most_common(num_words) real_words = get_most_common_words(real_news['text'])
fake_words = get_most_common_words(fake_news['text']) print('Real News:', real_words)
print('Fake News:', fake_words)
Utgången ska se ut så här:
Real News: [('trump', 32505), ('said', 15757), ('us', 15247), ('president', 12788), ('would', 12337), ('people', 10749), ('one', 10681), ('also', 9927), ('new', 9825), ('state', 9820)]
Fake News: [('trump', 10382), ('said', 7161), ('hillary', 3890), ('clinton', 3588), ('one', 3466), ('people', 3305), ('would', 3257), ('us', 3073), ('like', 3056), ('also', 3005)]Som vi kan se är några av de vanligaste orden i båda datamängderna relaterade till politik och USA:s nuvarande president, Donald Trump. Det finns dock vissa skillnader mellan de två datamängderna, med den falska nyhetsuppsättningen som innehåller fler referenser till Hillary Clinton och en större användning av ord som "gilla".
Modellprestanda utan att ta bort stoppord (använder logistisk regression)
Accuracy: 0.9953
Precision: 0.9940
Recall: 0.9963
F1 Score: 0.99512. Textförbehandling
Innan vi kan börja träna vår modell måste vi förbehandla textdatan. Förbehandlingsstegen vi kommer att utföra är:
- Förminska texten
- Ta bort skiljetecken och siffror
- Ta bort stoppord
- Stämma eller lemmatisera texten
Förminska texten
Med små bokstäver avses att konvertera alla bokstäver i en textbit till gemener. Detta är ett vanligt textförbehandlingssteg som kan vara användbart för att förbättra noggrannheten i textklassificeringsmodeller. Till exempel skulle "Hej" och "hej" betraktas som två olika ord av en modell som inte tar hänsyn till skiftläge, medan om texten konverteras till gemener, skulle de behandlas som samma ord.
Ta bort interpunktion och siffror
Att ta bort skiljetecken och siffror avser att ta bort icke-alfabetiska tecken från en text. Detta kan vara användbart för att minska textens komplexitet och göra det lättare för en modell att analysera. Till exempel orden "Hej" och "Hej!" skulle betraktas som olika ord av en textanalysmodell om den inte tar hänsyn till skiljetecken.
Ta bort stoppord
Stoppord är ord som är mycket vanliga i ett språk och som inte har någon större betydelse, som "det", "och", "i" etc. Att ta bort stoppord från en text kan hjälpa till att minska dimensionaliteten hos datan och fokusera på de viktigaste orden i texten. Detta kan också bidra till att förbättra noggrannheten hos en textklassificeringsmodell genom att minska brus i data.
Stämma eller lemmatisera texten
Stamning och lemmatisering är vanliga tekniker för att reducera ord till sin basform. Stemming innebär att man tar bort suffixen av ord för att producera ett stam- eller rotord. Till exempel skulle ordet "hoppa" härstamma från "hoppa". Den här tekniken kan vara användbar för att minska dimensionaliteten hos data, men det kan ibland resultera i stammar som inte är verkliga ord.
Omvänt innebär lemmatisering att reducera ord till sin basform med hjälp av en ordbok eller morfologisk analys. Till exempel skulle ordet "hoppa" lemmatiseras till "hoppa", vilket är ett verkligt ord. Den här tekniken kan vara mer exakt än stemming men också dyrare beräkningsmässigt.
Både stemming och lemmatisering kan minska dimensionaliteten hos textdata och göra det lättare för en modell att analysera. Det är dock viktigt att notera att de ibland kan resultera i förlust av information, så det är viktigt att experimentera med båda teknikerna och avgöra vilken som fungerar bäst för ett visst textklassificeringsproblem.
Vi kommer att utföra dessa steg med hjälp av NLTK-biblioteket, som tillhandahåller olika textbearbetningsverktyg.
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer, WordNetLemmatizer
import string nltk.download('wordnet') stop_words = set(stopwords.words('english'))
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer() def preprocess_text(text): # Lowercase the text text = text.lower() # Remove punctuation and digits text = text.translate(str.maketrans('', '', string.punctuation + string.digits)) # Tokenize the text words = word_tokenize(text) # Remove stop words words = [word for word in words if word not in stop_words] # Stem or lemmatize the words words = [stemmer.stem(word) for word in words] # Join the words back into a string text = ' '.join(words) return textVi kan nu tillämpa denna förbearbetningsfunktion på varje artikel i våra datauppsättningar:
real_news['text'] = real_news['text'].apply(preprocess_text)
fake_news['text'] = fake_news['text'].apply(preprocess_text)3. Modellutbildning
Vi kan träna vår modell nu när vi har förbehandlat vår textdata. Vi kommer att använda en enkel påse med ord, som representerar varje artikel som en vektor av ordfrekvenser. Vi kommer att använda CountVectorizer klass från lära sig bibliotek för att konvertera den förbearbetade texten till funktionsvektorer.
CountVectorizer är en vanlig textförbehandlingsteknik i naturlig språkbehandling. Den förvandlar en samling textdokument till en matris av ordräkningar. Varje rad i matrisen representerar ett dokument och varje kolumn representerar ett ord i dokumentsamlingen.
CountVectorizer konverterar en samling textdokument till en matris av token-antal. Det fungerar genom att först tokenisera texten till ord och sedan räkna frekvensen av varje ord i varje dokument. Den resulterande matrisen kan användas som input till maskininlärningsalgoritmer för uppgifter som textklassificering.
CountVectorizer har flera parametrar som kan justeras för att anpassa textförbehandlingen. Till exempel kan parametern "stop_words" användas för att specificera en lista med ord som ska tas bort från texten innan räkning. Parametern "max_df" kan ange den maximala dokumentfrekvensen för ett ord, utöver vilken ordet anses vara ett stoppord och tas bort från texten.
En fördel med CountVectorizer är att den är enkel att använda och fungerar bra för många typer av textklassificeringsproblem. Det är också mycket effektivt när det gäller minnesanvändning, eftersom det bara lagrar frekvensräkningarna för varje ord i varje dokument. En annan fördel är att den är lätt att tolka, eftersom den resulterande matrisen direkt kan inspekteras för att förstå betydelsen av olika ord i klassificeringsprocessen.
Andra metoder för att konvertera textdata till numeriska funktioner inkluderar TF-IDF (term frequency-inverse document frequency), Word2Vec, Doc2Vec och GloVe (Global Vectors for Word Representation).
TF-IDF liknar CountVectorizer, men istället för att bara räkna frekvensen av varje ord tar den hänsyn till hur ofta ordet förekommer i hela korpusen och tilldelar en vikt till varje ord baserat på hur viktigt det är i dokumentet.
Word2Vec och Doc2Vec är metoder för att lära sig lågdimensionella vektorrepresentationer av ord och dokument som fångar de underliggande semantiska sambanden mellan dem.
GloVe är en annan metod för att lära sig vektorrepresentationer av ord som kombinerar fördelarna med TF-IDF och Word2Vec.
Varje metod har sina fördelar och nackdelar, och valet av metod beror på problemet och datauppsättningen. För denna datauppsättning använder vi CountVectorizer enligt följande:
from sklearn.feature_extraction.text import CountVectorizer
import scipy.sparse as sp
import numpy as np vectorizer = CountVectorizer()
X_real = vectorizer.fit_transform(real_news['text'])
X_fake = vectorizer.transform(fake_news['text']) X = sp.vstack([X_real, X_fake])
y = np.concatenate([np.ones(X_real.shape[0]), np.zeros(X_fake.shape[0])])
Här skapar vi först en CountVectorizer objekt och passa den till den förbehandlade texten i den riktiga nyhetsdatauppsättningen. Vi använder sedan samma vektoriserare för att transformera den förbehandlade texten i den falska nyhetsdatauppsättningen. Vi staplar sedan funktionsmatriserna för båda datamängderna vertikalt och skapar en motsvarande etikettvektor, y.
Nu när vi har våra funktions- och etikettvektorer kan vi dela upp data i tränings- och testset:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Vi kan nu träna vår modell med hjälp av en logistisk regressionsklassificerare:
from sklearn.linear_model import LogisticRegression clf = LogisticRegression(random_state=42)
clf.fit(X_train, y_train)
4. Modellutvärdering
Nu när vi har tränat vår modell kan vi utvärdera dess prestanda på testsetet. Vi kommer att använda våra utvärderingsmått för noggrannhet, precision, återkallelse och F1-poäng.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score y_pred = clf.predict(X_test) accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred) print('Accuracy:', accuracy)
print('Precision:', precision)
print('Recall:', recall)
print('F1 Score:', f1)
Utgången ska se ut så här:
Accuracy: 0.992522617676591
Precision: 0.9918478260869565
Recall: 0.9932118684430505
F1 Score: 0.9925293344993434
Som vi kan se presterar vår modell mycket bra, med en noggrannhet på över 99%.
Vår datauppsättning uppnådde en testnoggrannhet på över 99 %, vilket indikerar att modellen exakt kan klassificera nyhetsartiklar som verkliga eller falska.
Förbättra modellen
Även om vår logistiska regressionsmodell uppnådde hög noggrannhet på testsetet, finns det flera sätt vi potentiellt skulle kunna förbättra dess prestanda:
- Funktionsteknik: Istället för att använda en påse-of-word-metod kan vi använda mer avancerade textrepresentationer, som ordinbäddningar eller ämnesmodeller, som kan fånga mer nyanserade relationer mellan ord.
- Hyperparameterjustering: Vi skulle kunna ställa in hyperparametrarna för den logistiska regressionsmodellen med metoder som rutnätssökning eller randomiserad sökning för att hitta den optimala uppsättningen parametrar för vår datauppsättning.
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# Define a function to train and evaluate a model
def train_and_evaluate_model(model, X_train, y_train, X_test, y_test): # Train the model on the training data model.fit(X_train, y_train) # Predict the labels for the testing data y_pred = model.predict(X_test) # Evaluate the model accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred, average='weighted') recall = recall_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted') # Print the evaluation metrics print(f"Accuracy: {accuracy:.4f}") print(f"Precision: {precision:.4f}") print(f"Recall: {recall:.4f}") print(f"F1-score: {f1:.4f}")
# Train and evaluate a Multinomial Naive Bayes model
print("Training and evaluating Multinomial Naive Bayes model...")
nb = MultinomialNB()
train_and_evaluate_model(nb, X_train, y_train, X_test, y_test)
print() # Train and evaluate a Support Vector Machine model
print("Training and evaluating Support Vector Machine model...")
svm = SVC()
train_and_evaluate_model(svm, X_train, y_train, X_test, y_test)Och resultaten är:
Jag har lagt till ett kodavsnitt för att justera hyperparametrar med GridSearchCV. Du använder också RandomSearchCV eller BayesSearchCV för att justera hyperparametrarna.
from sklearn.model_selection import GridSearchCV # Define a list of hyperparameters to search over
hyperparameters = { 'penalty': ['l1', 'l2'], 'C': [0.1, 1, 10, 100], 'solver': ['liblinear', 'saga']
} # Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(LogisticRegression(), hyperparameters, cv=5)
grid_search.fit(X_train, y_train) # Print the best hyperparameters and test accuracy
print('Best hyperparameters:', grid_search.best_params_)
print('Test accuracy:', grid_search.score(X_test, y_test))
Att experimentera med dessa metoder kan förbättra vår modells noggrannhet ytterligare.
Sparar vår modell:
from joblib import dump dump(clf, 'model.joblib')
dump(vectorizer, 'vectorizer.joblib')
Dumpfunktionen från joblib-biblioteket kan användas för att spara clf-modellen i filen model.joblib. När modellen väl har sparats kan den laddas i andra Python-skript med hjälp av laddningsfunktionen, som visas i föregående svar.
5. Modellinstallation
Slutligen kan vi distribuera vår modell som en webbapplikation med hjälp av Flask-ramverket. Vi kommer att skapa ett enkelt webbformulär där användare kan mata in text, och modellen kommer att visa om texten sannolikt är riktiga eller falska nyheter.
from flask import Flask, request, render_template
from joblib import load
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer, WordNetLemmatizer
import string stop_words = set(stopwords.words('english'))
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer() clf = load('model.joblib')
vectorizer = load('vectorizer.joblib')
def preprocess_text(text): # Lowercase the text text = text.lower() # Remove punctuation and digits text = text.translate(str.maketrans('', '', string.punctuation + string.digits)) # Tokenize the text words = word_tokenize(text) # Remove stop words words = [word for word in words if word not in stop_words] # Stem or lemmatize the words words = [stemmer.stem(word) for word in words] # Join the words back into a string text = ' '.join(words) return text app = Flask(__name__) @app.route('/')
def home(): return render_template('home.html') @app.route('/predict', methods=['POST'])
def predict(): text = request.form['text'] preprocessed_text = preprocess_text(text) X = vectorizer.transform([preprocessed_text]) y_pred = clf.predict(X) if y_pred[0]== 1: result = 'real' else: result = 'fake' return render_template('result.html', result=result, text=text) if __name__ == '__main__': app.run(debug=True)
Vi kan spara ovanstående kod i en fil som heter `app.py.` Vi behöver också skapa två HTML-mallar, `home.html` och `result.html`, som innehåller HTML-koden för startsidan och resultatsidan, respektive.
home.html
<!DOCTYPE html>
<html>
<head> <title>Real or Fake News</title>
</head>
<body> <h1>Real or Fake News</h1> <form action="/sv/predict" method="post"> <label for="text">Enter text:</label><br> <textarea name="text" rows="10" cols="50"></textarea><br> <input type="submit" value="Submit"> </form>
</body>
</html>resultat.html
<!DOCTYPE html>
<html>
<head> <title>Real or Fake News</title>
</head>
<body> <h1>Real or Fake News</h1> <p>The text you entered:</p> <p>{{ text }}</p> <p>The model predicts that this text is:</p> <p>{{ result }}</p>
</body>
</html>
Vi kan nu köra Flask-appen med kommandot python app.py på kommandoraden. Appen bör vara tillgänglig på http://localhost:5000.
Hemsida:

Förutspå sida:
Slutsats
- Förbearbetning är ett viktigt steg i naturliga språkbearbetningsuppgifter som textklassificering, och tekniker som små bokstäver, ta bort stoppord och stemming/lemmatisering kan avsevärt förbättra modellernas prestanda.
- CountVectorizer är ett kraftfullt verktyg för att konvertera textdata till en numerisk representation som kan användas i maskininlärningsmodeller.
- Valet av en maskininlärningsalgoritm kan avsevärt påverka prestandan för en textklassificeringsuppgift. I det här projektet jämförde vi prestandan för logistisk regression och stödvektormaskiner och fann att logistisk regression hade bäst prestanda.
- Modellutvärdering är avgörande för att förstå prestandan hos en maskininlärningsmodell och identifiera områden för förbättringar. I det här projektet använde vi mätvärden som noggrannhet, precision, återkallelse och F1-poäng för att utvärdera våra modeller.
- Slutligen visar detta projekt potentialen hos maskininlärning för automatisk upptäckt av falska nyheter och dess potentiella tillämpningar inom mediebranschen och utanför.
I det här blogginlägget lärde vi oss hur man tränar en enkel logistisk regressionsmodell för att klassificera nyhetsartiklar som verkliga eller falska och hur man distribuerar modellen som en webbapplikation med hjälp av Flask-ramverket. Vi använde sklearn-biblioteket för att förbearbeta och modellera data och skapade ett enkelt webbformulär med HTML och Flask.
Datauppsättningen vi använde för detta projekt var Uppsättning av falska och riktiga nyheter från Kaggle, som innehåller 23481 riktiga nyhetsartiklar och 21417 falska nyhetsartiklar. Vi förbearbetade texten genom att ta bort stoppord, skiljetecken och siffror och använde sedan en påse med ord för att representera varje artikel som en vektor av ordfrekvenser. Vi tränade en logistisk regressionsklassificerare på dessa data och uppnådde en noggrannhet på över 99 %.
Sammantaget visar detta projekt hur maskininlärning kan användas för att tackla problemet med falska nyheter, som blir en allt viktigare fråga i dagens samhälle.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/02/tackling-fake-news-with-machine-learning/

