Kunder av alla storlekar och branscher förnyar sig på AWS genom att ingjuta maskininlärning (ML) i sina produkter och tjänster. Den senaste utvecklingen av generativa AI-modeller har ytterligare påskyndat behovet av ML-adoption inom olika branscher. Men implementering av säkerhets-, datasekretess- och styrningskontroller är fortfarande viktiga utmaningar för kunder när de implementerar ML-arbetsbelastningar i stor skala. Att ta itu med dessa utmaningar bygger ramverket och grunden för att minska risker och ansvarsfull användning av ML-drivna produkter. Även om generativ AI kan behöva ytterligare kontroller på plats, såsom att ta bort toxicitet och förhindra jailbreaking och hallucinationer, delar den samma grundläggande komponenter för säkerhet och styrning som traditionell ML.
Vi hör från kunder att de behöver specialiserad kunskap och investeringar på upp till 12 månader för att bygga ut sina skräddarsydda Amazon SageMaker ML-plattformsimplementering för att säkerställa skalbara, pålitliga, säkra och styrda ML-miljöer för deras verksamhetsgrenar (LOB) eller ML-team. Om du saknar ett ramverk för att styra ML-livscykeln i stor skala, kan du stöta på utmaningar som isolering av resurser på teamnivå, skalning av experimentresurser, operationalisering av ML-arbetsflöden, skalning av modellstyrning och hantering av säkerhet och efterlevnad av ML-arbetsbelastningar.
Att styra ML-livscykeln i stor skala är ett ramverk som hjälper dig att bygga en ML-plattform med inbäddade säkerhets- och styrningskontroller baserade på branschpraxis och företagsstandarder. Detta ramverk tar itu med utmaningar genom att tillhandahålla föreskrivande vägledning genom en modulär rammetod som utökar en AWS kontrolltorn multi-account AWS-miljö och tillvägagångssättet som diskuteras i inlägget Konfigurera säkra, välstyrda maskininlärningsmiljöer på AWS.
Den ger föreskrivande vägledning för följande ML-plattformsfunktioner:
- Grunder för flera konton, säkerhet och nätverk – Den här funktionen använder AWS Control Tower och väl utformade principer för att ställa in och driva flerkontomiljö, säkerhet och nätverkstjänster.
- Data- och styrningsstiftelser – Den här funktionen använder en datanätsarkitektur för att sätta upp och driva datasjön, central funktionslagring och datastyrningsstiftelser för att möjliggöra finkornig dataåtkomst.
- ML-plattformsdelade och styrningstjänster – Denna funktion gör det möjligt att ställa in och använda vanliga tjänster som CI/CD, AWS servicekatalog för provisioneringsmiljöer och ett centralt modellregister för modellfrämjande och härstamning.
- ML teammiljöer – Den här funktionen gör det möjligt att sätta upp och använda miljöer för ML-team för modellutveckling, testning och distribution av deras användningsfall för inbäddning av säkerhets- och styrningskontroller.
- ML-plattformens observerbarhet – Den här funktionen hjälper till med felsökning och identifiering av grundorsaken till problem i ML-modeller genom centralisering av loggar och tillhandahåller verktyg för visualisering av logganalys. Den ger också vägledning för att generera kostnads- och användningsrapporter för ML-användningsfall.
Även om detta ramverk kan ge fördelar för alla kunder, är det mest fördelaktigt för stora, mogna, reglerade eller globala företagskunder som vill skala sina ML-strategier i ett kontrollerat, kompatibelt och samordnat tillvägagångssätt över hela organisationen. Det hjälper till att möjliggöra ML-adoption samtidigt som riskerna minskar. Detta ramverk är användbart för följande kunder:
- Stora företagskunder som har många LOB:er eller avdelningar som är intresserade av att använda ML. Detta ramverk tillåter olika team att bygga och distribuera ML-modeller oberoende samtidigt som de tillhandahåller central styrning.
- Företagskunder med måttlig till hög mognad i ML. De har redan implementerat några inledande ML-modeller och försöker skala sina ML-ansträngningar. Detta ramverk kan hjälpa till att påskynda användningen av ML i hela organisationen. Dessa företag inser också behovet av styrning för att hantera saker som åtkomstkontroll, dataanvändning, modellprestanda och orättvis partiskhet.
- Företag inom reglerade branscher som finansiella tjänster, hälsovård, kemi och den privata sektorn. Dessa företag behöver stark styrning och hörbarhet för alla ML-modeller som används i deras affärsprocesser. Att anta detta ramverk kan hjälpa till att underlätta efterlevnaden samtidigt som det tillåter lokal modellutveckling.
- Globala organisationer som behöver balansera centraliserad och lokal kontroll. Detta ramverks federerade tillvägagångssätt tillåter det centrala plattformsingenjörsteamet att sätta vissa policyer och standarder på hög nivå, men ger också LOB-team flexibilitet att anpassa sig utifrån lokala behov.
I den första delen av denna serie går vi igenom referensarkitekturen för att sätta upp ML-plattformen. I ett senare inlägg kommer vi att ge föreskrivande vägledning för hur du implementerar de olika modulerna i referensarkitekturen i din organisation.
ML-plattformens funktioner är grupperade i fyra kategorier, som visas i följande figur. Dessa funktioner utgör grunden för referensarkitekturen som diskuteras senare i det här inlägget:
- Bygg ML-fundament
- Skala ML-operationer
- Observerbar ML
- Säker ML
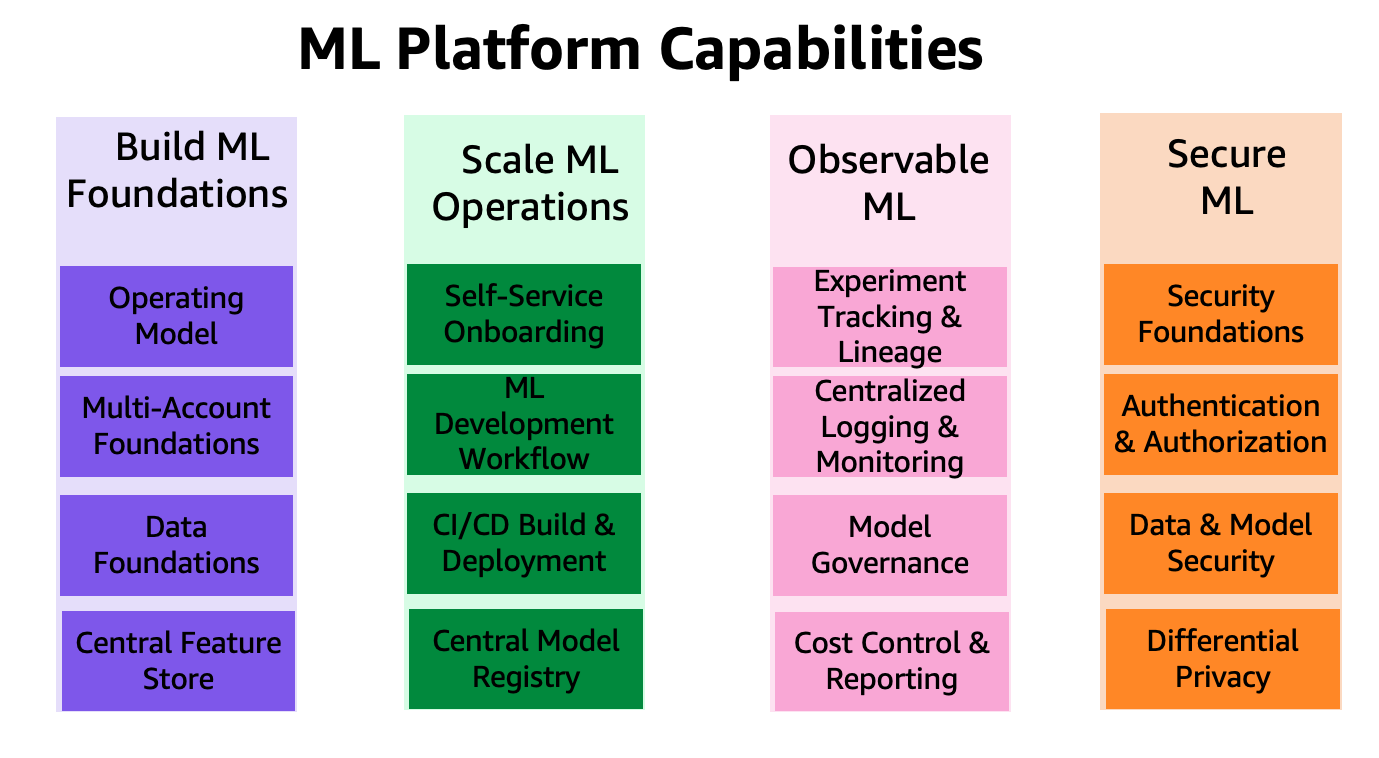
Lösningsöversikt
Ramverket för att styra ML-livscykeln i stor skala gör det möjligt för organisationer att bädda in säkerhets- och styrningskontroller under hela ML:s livscykel, vilket i sin tur hjälper organisationer att minska risker och påskynda införandet av ML i sina produkter och tjänster. Ramverket hjälper till att optimera installationen och styrningen av säkra, skalbara och pålitliga ML-miljöer som kan skalas för att stödja ett ökande antal modeller och projekt. Ramverket möjliggör följande funktioner:
- Konto- och infrastrukturförsörjning med organisationspolicykompatibla infrastrukturresurser
- Självbetjäningsdistribution av datavetenskapsmiljöer och mallar för end-to-end ML operations (MLOps) för ML-användningsfall
- Isolering av resurser på LOB-nivå eller teamnivå för efterlevnad av säkerhet och integritet
- Styrd åtkomst till produktionsklassdata för experiment och produktionsklara arbetsflöden
- Hantering och styrning av kodförråd, kodpipelines, distribuerade modeller och datafunktioner
- Ett modellregister och funktionsarkiv (lokala och centrala komponenter) för att förbättra styrningen
- Säkerhets- och styrningskontroller för end-to-end-modellutveckling och implementeringsprocessen
I det här avsnittet ger vi en översikt över föreskrivande vägledning för att hjälpa dig bygga denna ML-plattform på AWS med inbyggda säkerhets- och styrningskontroller.
Den funktionella arkitekturen associerad med ML-plattformen visas i följande diagram. Arkitekturen mappar de olika funktionerna hos ML-plattformen till AWS-konton.
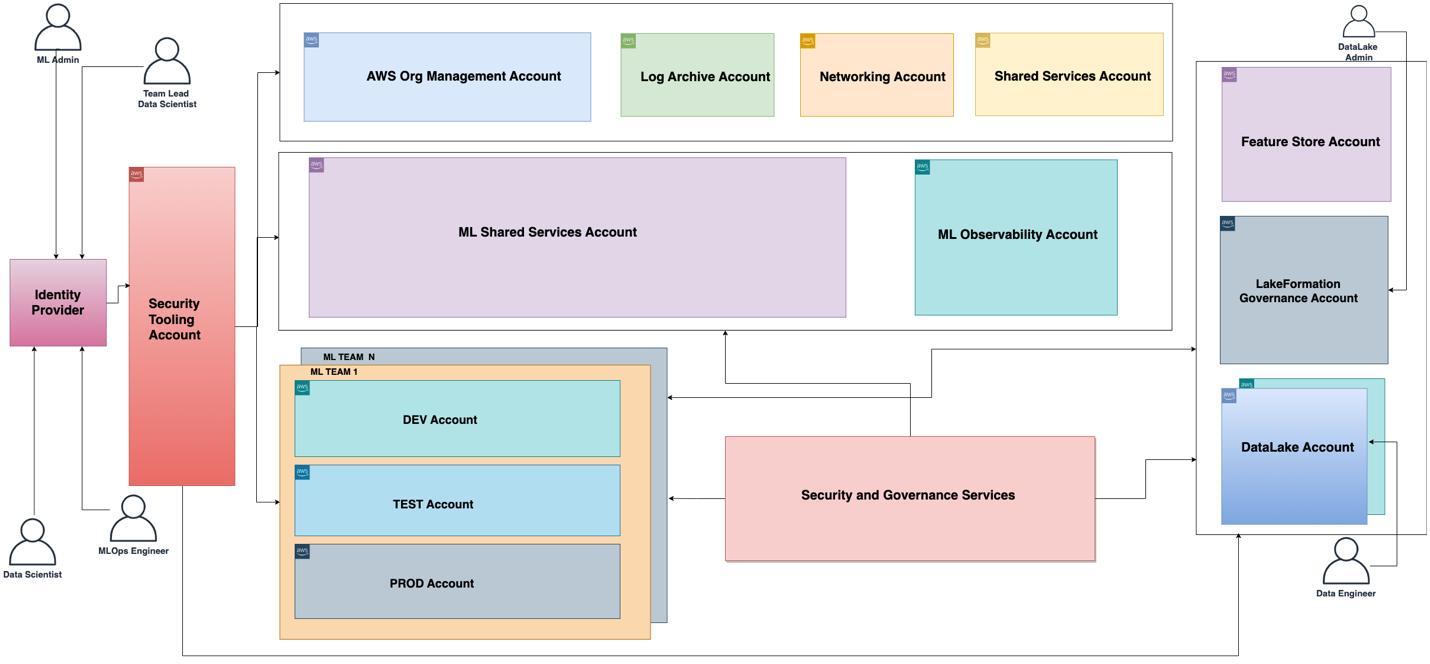
Den funktionella arkitekturen med olika möjligheter implementeras med hjälp av ett antal AWS-tjänster, bl.a AWS-organisationer, SageMaker, AWS DevOps-tjänster och en datasjö. Referensarkitekturen för ML-plattformen med olika AWS-tjänster visas i följande diagram.
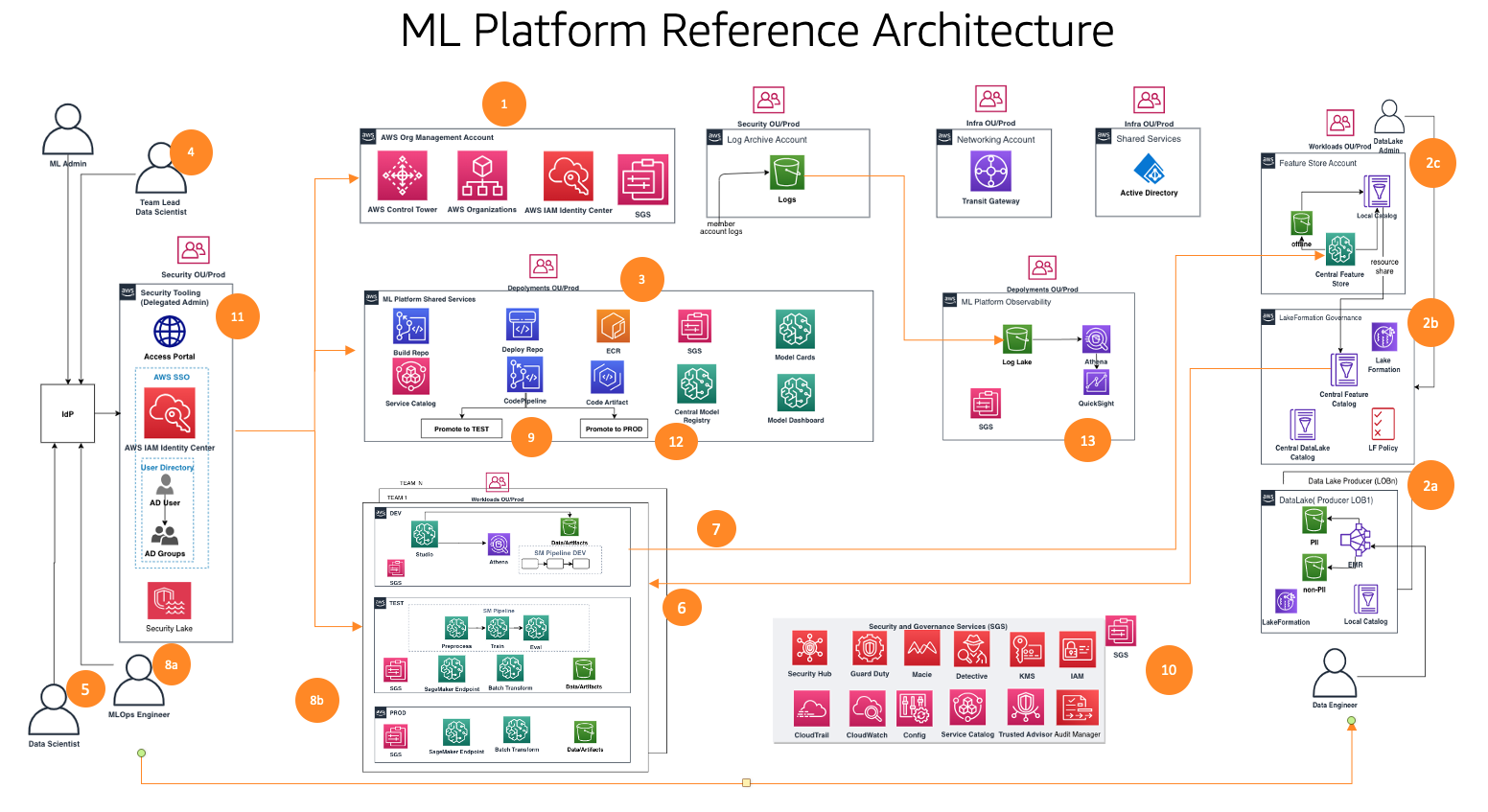
Detta ramverk tar hänsyn till flera personer och tjänster för att styra ML-livscykeln i stor skala. Vi rekommenderar följande steg för att organisera dina team och tjänster:
- Med hjälp av AWS Control Tower och automationsverktyg ställer din molnadministratör upp grunderna för flera konton som organisationer och Aws iam identitetscenter (efterträdare till AWS Single Sign-On) och säkerhets- och styrningstjänster som t.ex AWS nyckelhanteringstjänst (AWS KMS) och tjänstekatalog. Dessutom ställer administratören upp en mängd olika organisationsenheter (OU) och initiala konton för att stödja dina ML- och analysarbetsflöden.
- Datasjöadministratörer ställer in din datasjö och datakatalog och ställer in det centrala funktionslagret som arbetar med ML-plattformsadministratören.
- ML-plattformens administratör tillhandahåller ML-delade tjänster som t.ex AWS CodeCommit, AWS CodePipeline, Amazon Elastic Container Registry (Amazon ECR), ett centralt modellregister, SageMaker modellkort, SageMaker Model Dashboard, och Service Catalog-produkter för ML-team.
- ML-teamet leder federationer via IAM Identity Center, använder Service Catalog-produkter och tillhandahåller resurser i ML-teamets utvecklingsmiljö.
- Dataforskare från ML-team över olika affärsenheter ansluter sig till sitt teams utvecklingsmiljö för att bygga modellpipeline.
- Dataforskare söker och hämtar funktioner från den centrala butikskatalogen, bygger modeller genom experiment och väljer den bästa modellen för marknadsföring.
- Dataforskare skapar och delar med sig av nya funktioner i den centrala funktionsbutikskatalogen för återanvändning.
- En ML-ingenjör distribuerar modellpipelinen i ML-teamets testmiljö med hjälp av en CI/CD-process för delade tjänster.
- Efter intressentvalidering distribueras ML-modellen till teamets produktionsmiljö.
- Säkerhets- och styrningskontroller är inbäddade i varje lager av denna arkitektur med hjälp av tjänster som t.ex AWS Security Hub, Amazon Guard Duty, Amazon MacieOch mycket mer.
- Säkerhetskontroller hanteras centralt från säkerhetsverktygskontot med hjälp av Security Hub.
- ML-plattformsstyrningsfunktioner som SageMaker Model Cards och SageMaker Model Dashboard hanteras centralt från kontot för styrningstjänster.
- amazoncloudwatch och AWS CloudTrail loggar från varje medlemskonto görs tillgängliga centralt från ett observerbarhetskonto med hjälp av AWS inbyggda tjänster.
Därefter dyker vi djupt in i modulerna i referensarkitekturen för detta ramverk.
Referensarkitekturmoduler
Referensarkitekturen består av åtta moduler, var och en utformad för att lösa en specifik uppsättning problem. Tillsammans behandlar dessa moduler styrning över olika dimensioner, såsom infrastruktur, data, modell och kostnad. Varje modul erbjuder en distinkt uppsättning funktioner och samverkar med andra moduler för att tillhandahålla en integrerad end-to-end ML-plattform med inbyggda säkerhets- och styrningskontroller. I det här avsnittet presenterar vi en kort sammanfattning av varje moduls kapacitet.
Flerkontostiftelser
Den här modulen hjälper molnadministratörer att bygga en AWS Control Tower landningszon som en grundläggande ram. Detta inkluderar att bygga en struktur för flera konton, autentisering och auktorisering via IAM Identity Center, en nätverkshubb-and-spoke-design, centraliserade loggningstjänster och nya AWS-medlemskonton med standardiserade säkerhets- och styrningsbaslinjer.
Dessutom ger den här modulen bästa praxis-vägledning om organisationsenheter och kontostrukturer som är lämpliga för att stödja dina ML- och analysarbetsflöden. Molnadministratörer kommer att förstå syftet med de obligatoriska kontona och organisationsenheterna, hur man distribuerar dem och viktiga säkerhets- och efterlevnadstjänster som de bör använda för att centralt styra sina ML- och analysarbetsbelastningar.
Ett ramverk för försäljning av nya konton täcks också, som använder automatisering för att baslinjeforma nya konton när de tillhandahålls. Genom att ha en automatiserad kontoprovisioneringsprocess inrättad kan molnadministratörer ge ML- och analysteam de konton de behöver för att utföra sitt arbete snabbare, utan att göra avkall på en stark grund för styrning.
Datasjöfundament
Den här modulen hjälper datasjöadministratörer att ställa in en datasjö för att mata in data, kurera datamängder och använda AWS Lake Formation styrningsmodell för att hantera finkornig dataåtkomst över konton och användare med hjälp av en centraliserad datakatalog, dataåtkomstpolicyer och taggbaserade åtkomstkontroller. Du kan börja i det små med ett konto för din dataplattforms grunder för ett proof of concept eller några små arbetsbelastningar. För medelstor till storskalig implementering av produktionsbelastning rekommenderar vi att du använder en strategi för flera konton. I en sådan miljö kan LOB:er anta rollen som dataproducenter och datakonsumenter som använder olika AWS-konton, och datasjöstyrningen drivs från ett centralt delat AWS-konto. Dataproducenten samlar in, bearbetar och lagrar data från sin datadomän, förutom att övervaka och säkerställa kvaliteten på sina datatillgångar. Datakonsumenter konsumerar data från dataproducenten efter att den centraliserade katalogen delar den med Lake Formation. Den centraliserade katalogen lagrar och hanterar den delade datakatalogen för dataproducentkontona.
ML-plattformstjänster
Den här modulen hjälper ML-plattformsingenjörsteamet att skapa delade tjänster som används av datavetenskapsteamen på deras teamkonton. Tjänsterna inkluderar en tjänstekatalogportfölj med produkter för SageMaker-domän spridning, SageMaker domänanvändarprofil distribution, datavetenskapsmodellmallar för modellbyggande och implementering. Den här modulen har funktioner för ett centraliserat modellregister, modellkort, modellinstrumentpanel och CI/CD-pipelines som används för att orkestrera och automatisera modellutvecklings- och distributionsarbetsflöden.
Dessutom beskriver den här modulen hur man implementerar de kontroller och styrning som krävs för att möjliggöra personbaserade självbetjäningsfunktioner, vilket gör att datavetenskapsteam självständigt kan distribuera sin nödvändiga molninfrastruktur och ML-mallar.
ML användningsfallsutveckling
Den här modulen hjälper LOB:er och datavetare att komma åt sitt teams SageMaker-domän i en utvecklingsmiljö och instansiera en modellbyggande mall för att utveckla sina modeller. I den här modulen arbetar datavetare på en utvecklarkontoinstans av mallen för att interagera med data som finns på den centraliserade datasjön, återanvända och dela funktioner från en central funktionsbutik, skapa och köra ML-experiment, bygga och testa sina ML-arbetsflöden, och registrera sina modeller till ett modellregister för utvecklarkonton i deras utvecklingsmiljöer.
Funktioner som experimentspårning, modellförklaringsrapporter, data- och modellbiasövervakning samt modellregister är också implementerade i mallarna, vilket möjliggör snabb anpassning av lösningarna till datavetarnas utvecklade modeller.
ML verksamhet
Den här modulen hjälper LOB:er och ML-ingenjörer att arbeta med sina dev-instanser av modelldistributionsmallen. Efter att kandidatmodellen är registrerad och godkänd sätter de upp CI/CD-pipelines och kör ML-arbetsflöden i teamets testmiljö, som registrerar modellen i det centrala modellregistret som körs i ett konto för delade tjänster för plattformar. När en modell godkänns i det centrala modellregistret triggar detta en CI/CD-pipeline för att distribuera modellen i teamets produktionsmiljö.
Centraliserad funktionsbutik
Efter att de första modellerna har distribuerats till produktion och flera användningsfall börjar dela funktioner som skapats från samma data, blir en funktionsbutik viktig för att säkerställa samarbete mellan användningsfall och minska dubbelarbete. Den här modulen hjälper ML-plattformsingenjörsteamet att skapa en centraliserad funktionsbutik för att tillhandahålla lagring och styrning av ML-funktioner som skapats av ML-användningsfallen, vilket möjliggör återanvändning av funktioner över projekt.
Loggning och observerbarhet
Den här modulen hjälper LOBs och ML-utövare att få insyn i tillståndet för ML-arbetsbelastningar i ML-miljöer genom centralisering av loggaktivitet som CloudTrail, CloudWatch, VPC-flödesloggar och ML-arbetsbelastningsloggar. Team kan filtrera, fråga och visualisera loggar för analys, vilket också kan bidra till att förbättra säkerhetsställningen.
Kostnad och rapportering
Den här modulen hjälper olika intressenter (molnadministratör, plattformsadministratör, molnföretagskontor) att generera rapporter och instrumentpaneler för att dela upp kostnader på ML-användare, ML-team och ML-produktnivåer, och spåra användning som antal användare, instanstyper och slutpunkter.
Kunder har bett oss att ge vägledning om hur många konton som ska skapas och hur man strukturerar dessa konton. I nästa avsnitt ger vi vägledning om den kontostrukturen som referens som du kan ändra för att passa dina behov enligt dina krav på företagsstyrning.
I det här avsnittet diskuterar vi vår rekommendation för att organisera din kontostruktur. Vi delar en baslinjestruktur för referenskonton; Vi rekommenderar dock att ML- och dataadministratörer arbetar nära sin molnadministratör för att anpassa denna kontostruktur baserat på deras organisationskontroller.

Vi rekommenderar att du organiserar konton efter OU för säkerhet, infrastruktur, arbetsbelastningar och implementeringar. Dessutom, inom varje OU, organisera efter icke-produktions- och produktions-OU eftersom konton och arbetsbelastningar som distribueras under dem har olika kontroller. Därefter diskuterar vi kort dessa organisationsenheter.
Säkerhet OU
Kontona i denna OU hanteras av organisationens molnadministratör eller säkerhetsteam för att övervaka, identifiera, skydda, upptäcka och svara på säkerhetshändelser.
Infrastruktur OU
Kontona i denna OU hanteras av organisationens molnadministratör eller nätverksteam för hantering av delade resurser och nätverk för infrastruktur på företagsnivå.
Vi rekommenderar att du har följande konton under infrastrukturorganisationen:
- nätverks – Sätt upp en centraliserad nätverksinfrastruktur som t.ex AWS Transit Gateway
- Delade tjänster – Konfigurera centraliserade AD-tjänster och VPC-slutpunkter
Arbetsbelastning OU
Kontona i denna OU hanteras av organisationens plattformsteamadministratörer. Om du behöver olika kontroller implementerade för varje plattformsteam kan du kapsla andra nivåer av OU för det ändamålet, till exempel en OE för ML-arbetsbelastningar, OE för dataarbetsbelastningar och så vidare.
Vi rekommenderar följande konton under arbetsbelastningsorganisationen:
- Dev-, test- och prodkonton för ML på teamnivå – Ställ in detta baserat på dina krav på isolering av arbetsbelastning
- Data lake konton – Dela upp konton efter din datadomän
- Centralt datastyrningskonto – Centralisera dina policyer för dataåtkomst
- Central funktion butik konto – Centralisera funktioner för delning mellan team
Distributions OU
Kontona i denna OU hanteras av organisationens plattformsteamadministratörer för att distribuera arbetsbelastningar och observerbarhet.
Vi rekommenderar följande konton under implementeringsorganisationen eftersom ML-plattformsteamet kan ställa in olika uppsättningar kontroller på denna organisationsenhetsnivå för att hantera och styra implementeringar:
- ML delade tjänster står för test och prod – Värdplattform för delade tjänster CI/CD och modellregister
- ML observerbarhet står för test och prod – Värdar för CloudWatch-loggar, CloudTrail-loggar och andra loggar efter behov
Därefter diskuterar vi kortfattat organisationskontroller som måste övervägas för inbäddning i medlemskonton för övervakning av infrastrukturresurserna.
AWS miljökontroller
En kontroll är en regel på hög nivå som ger kontinuerlig styrning av din övergripande AWS-miljö. Det uttrycks i klarspråk. I detta ramverk använder vi AWS Control Tower för att implementera följande kontroller som hjälper dig att styra dina resurser och övervaka efterlevnad mellan grupper av AWS-konton:
- Förebyggande kontroller – En förebyggande kontroll säkerställer att dina konton upprätthåller efterlevnad eftersom den inte tillåter åtgärder som leder till policyöverträdelser och implementeras med hjälp av en Service Control Policy (SCP). Du kan till exempel ställa in en förebyggande kontroll som säkerställer att CloudTrail inte raderas eller stoppas i AWS-konton eller regioner.
- Detektivkontroller – En detektivkontroll upptäcker bristande efterlevnad av resurser inom dina konton, såsom policyöverträdelser, ger varningar via instrumentpanelen och implementeras med hjälp av AWS -konfigur regler. Till exempel kan du skapa en detektivkontroll för att upptäcka om offentlig läsbehörighet är aktiverad för Amazon enkel lagringstjänst (Amazon S3) hinkar i loggarkivets delade konto.
- Proaktiva kontroller – En proaktiv kontroll skannar dina resurser innan de tillhandahålls och ser till att resurserna är kompatibla med den kontrollen och implementeras med hjälp av AWS molnformation krokar. Resurser som inte är kompatibla kommer inte att tillhandahållas. Du kan till exempel ställa in en proaktiv kontroll som kontrollerar att direkt internetåtkomst inte är tillåten för en SageMaker-anteckningsbok-instans.
Interaktioner mellan ML-plattformstjänster, ML-användningsfall och ML-operationer
Olika personas, såsom chefen för datavetenskap (lead data scientist), datascientist och ML-ingenjör, driver modulerna 2–6 som visas i följande diagram för olika stadier av ML-plattformstjänster, ML-användningsfallsutveckling och ML-verksamhet tillsammans med data lake foundations och den centrala funktionsbutiken.

Följande tabell sammanfattar operationsflödesaktiviteten och inställningsflödesstegen för olika personas. När en persona initierar en ML-aktivitet som en del av operationsflödet körs tjänsterna som nämnts i stegen för installationsflödet.
| Persona | Ops Flow Activity – Antal | Ops Flow Activity – Beskrivning | Setup Flow Step – Number | Setup Flow Step – Beskrivning |
| Lead Data Science eller ML Team Lead |
1 |
Använder Service Catalog i ML-plattformstjänstkontot och distribuerar följande:
|
1-A |
|
|
1-B |
|
|||
| Datavetenskapare |
2 |
Genomför och spårar ML-experiment i SageMaker-anteckningsböcker |
2-A |
|
|
3 |
Automatiserar framgångsrika ML-experiment med SageMaker-projekt och pipelines |
3-A |
|
|
|
3-B |
Efter att SageMaker-pipelines har körts, sparas modellen i det lokala (dev) modellregistret | |||
| Lead Data Scientist eller ML Team Lead |
4 |
Godkänner modellen i det lokala (dev) modellregistret |
4-A |
Modellmetadata och modellpaket skriver från det lokala (dev) modellregistret till det centrala modellregistret |
|
5 |
Godkänner modellen i det centrala modellregistret |
5-A |
Initierar distributions-CI/CD-processen för att skapa SageMaker-slutpunkter i testmiljön | |
|
5-B |
Skriver modellinformation och metadata till ML-styrningsmodulen (modellkort, modellinstrumentpanel) i ML-plattformstjänstkontot från det lokala (dev) kontot | |||
| ML-ingenjör |
6 |
Testar och övervakar SageMaker endpoint i testmiljön efter CI/CD | . | |
|
7 |
Godkänner distribution för SageMaker-slutpunkter i prod-miljön |
7-A |
Initierar distributions-CI/CD-processen för att skapa SageMaker-slutpunkter i prod-miljön | |
|
8 |
Testar och övervakar SageMaker endpoint i testmiljön efter CI/CD | . | ||
Personas och interaktioner med olika moduler av ML-plattformen
Varje modul vänder sig till särskilda målpersoner inom specifika divisioner som använder modulen oftast, vilket ger dem primär åtkomst. Sekundär åtkomst tillåts då till andra divisioner som kräver tillfällig användning av modulerna. Modulerna är skräddarsydda för behoven hos särskilda jobbroller eller personas för att optimera funktionaliteten.
Vi diskuterar följande team:
- Central molnteknik – Det här teamet arbetar på företagsmolnnivå över alla arbetsbelastningar för att konfigurera vanliga molninfrastrukturtjänster, som att konfigurera nätverk på företagsnivå, identitet, behörigheter och kontohantering
- Dataplattformsteknik – Det här teamet hanterar företagsdatasjöar, datainsamling, datakurering och datastyrning
- ML-plattformsteknik – Det här teamet arbetar på ML-plattformsnivå över LOB:er för att tillhandahålla delade ML-infrastrukturtjänster som ML-infrastrukturförsörjning, experimentspårning, modellstyrning, implementering och observerbarhet
Följande tabell beskriver vilka divisioner som har primär och sekundär åtkomst för varje modul enligt modulens målpersonas.
| Modulnummer | Moduler | Primär tillgång | Sekundär åtkomst | Målpersonas | Antal konton |
|
1 |
Flerkontostiftelser | Central molnteknik | Individuella LOB |
|
Få |
|
2 |
Datasjöfundament | Central moln- eller dataplattformsteknik | Individuella LOB |
|
Flera olika |
|
3 |
ML-plattformstjänster | Central moln- eller ML-plattformsteknik | Individuella LOB |
|
en |
|
4 |
ML användningsfallsutveckling | Individuella LOB | Central moln- eller ML-plattformsteknik |
|
Flera olika |
|
5 |
ML verksamhet | Central moln eller ML-teknik | Individuella LOB |
|
Flera olika |
|
6 |
Centraliserad funktionsbutik | Central moln eller datateknik | Individuella LOB |
|
en |
|
7 |
Loggning och observerbarhet | Central molnteknik | Individuella LOB |
|
en |
|
8 |
Kostnad och rapportering | Individuella LOB | Central plattformsteknik |
|
en |
Slutsats
I det här inlägget introducerade vi ett ramverk för att styra ML-livscykeln i stor skala som hjälper dig att implementera väldesignade ML-arbetsbelastningar som bäddar in säkerhets- och styrningskontroller. Vi diskuterade hur detta ramverk tar ett holistiskt tillvägagångssätt för att bygga en ML-plattform med hänsyn till datastyrning, modellstyrning och kontroller på företagsnivå. Vi uppmuntrar dig att experimentera med ramverket och koncepten som introduceras i det här inlägget och dela din feedback.
Om författarna
 Ram Vittal är Principal ML Solutions Architect på AWS. Han har över 3 decennier av erfarenhet av att bygga och bygga distribuerade, hybrid- och molnapplikationer. Han brinner för att bygga säkra, skalbara, pålitliga AI/ML- och big data-lösningar för att hjälpa företagskunder med deras molnintroduktion och optimeringsresa för att förbättra deras affärsresultat. På fritiden kör han motorcykel och går med sin treåriga sheep-a-doodle!
Ram Vittal är Principal ML Solutions Architect på AWS. Han har över 3 decennier av erfarenhet av att bygga och bygga distribuerade, hybrid- och molnapplikationer. Han brinner för att bygga säkra, skalbara, pålitliga AI/ML- och big data-lösningar för att hjälpa företagskunder med deras molnintroduktion och optimeringsresa för att förbättra deras affärsresultat. På fritiden kör han motorcykel och går med sin treåriga sheep-a-doodle!
 Sovik Kumar Nath är en AI/ML-lösningsarkitekt med AWS. Han har lång erfarenhet av att designa end-to-end maskininlärning och affärsanalyslösningar inom ekonomi, drift, marknadsföring, hälsovård, supply chain management och IoT. Sovik har publicerat artiklar och har patent på ML-modellövervakning. Han har dubbla magisterexamen från University of South Florida, University of Fribourg, Schweiz, och en kandidatexamen från Indian Institute of Technology, Kharagpur. Utanför jobbet tycker Sovik om att resa, åka färja och titta på film.
Sovik Kumar Nath är en AI/ML-lösningsarkitekt med AWS. Han har lång erfarenhet av att designa end-to-end maskininlärning och affärsanalyslösningar inom ekonomi, drift, marknadsföring, hälsovård, supply chain management och IoT. Sovik har publicerat artiklar och har patent på ML-modellövervakning. Han har dubbla magisterexamen från University of South Florida, University of Fribourg, Schweiz, och en kandidatexamen från Indian Institute of Technology, Kharagpur. Utanför jobbet tycker Sovik om att resa, åka färja och titta på film.
 Maira Ladeira Tanke är Senior Data Specialist på AWS. Som teknisk ledare hjälper hon kunder att accelerera deras uppnående av affärsvärde genom framväxande teknologi och innovativa lösningar. Maira har varit på AWS sedan januari 2020. Dessförinnan arbetade hon som datavetare i flera branscher med fokus på att uppnå affärsnytta från data. På fritiden tycker Maira om att resa och umgås med sin familj på en varm plats.
Maira Ladeira Tanke är Senior Data Specialist på AWS. Som teknisk ledare hjälper hon kunder att accelerera deras uppnående av affärsvärde genom framväxande teknologi och innovativa lösningar. Maira har varit på AWS sedan januari 2020. Dessförinnan arbetade hon som datavetare i flera branscher med fokus på att uppnå affärsnytta från data. På fritiden tycker Maira om att resa och umgås med sin familj på en varm plats.
 Ryan Lempka är Senior Solutions Architect på Amazon Web Services, där han hjälper sina kunder att arbeta baklänges från affärsmål för att utveckla lösningar på AWS. Han har djup erfarenhet av affärsstrategi, IT-systemhantering och datavetenskap. Ryan är dedikerad till att vara en livslång lärande och tycker om att utmana sig själv varje dag för att lära sig något nytt.
Ryan Lempka är Senior Solutions Architect på Amazon Web Services, där han hjälper sina kunder att arbeta baklänges från affärsmål för att utveckla lösningar på AWS. Han har djup erfarenhet av affärsstrategi, IT-systemhantering och datavetenskap. Ryan är dedikerad till att vara en livslång lärande och tycker om att utmana sig själv varje dag för att lära sig något nytt.
 Sriharsh Adari är Senior Solutions Architect på Amazon Web Services (AWS), där han hjälper kunder att arbeta baklänges från affärsresultat för att utveckla innovativa lösningar på AWS. Under åren har han hjälpt flera kunder med dataplattformstransformationer över branschvertikaler. Hans kärnexpertisområde inkluderar teknologistrategi, dataanalys och datavetenskap. På fritiden tycker han om att spela sport, titta på tv-program och spela Tabla.
Sriharsh Adari är Senior Solutions Architect på Amazon Web Services (AWS), där han hjälper kunder att arbeta baklänges från affärsresultat för att utveckla innovativa lösningar på AWS. Under åren har han hjälpt flera kunder med dataplattformstransformationer över branschvertikaler. Hans kärnexpertisområde inkluderar teknologistrategi, dataanalys och datavetenskap. På fritiden tycker han om att spela sport, titta på tv-program och spela Tabla.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/governing-the-ml-lifecycle-at-scale-part-1-a-framework-for-architecting-ml-workloads-using-amazon-sagemaker/

