Customer 360 (C360) ger en komplett och enhetlig bild av en kunds interaktioner och beteende över alla kontaktpunkter och kanaler. Denna vy används för att identifiera mönster och trender i kundbeteende, vilket kan informera datadrivna beslut för att förbättra affärsresultat. Du kan till exempel använda C360 för att segmentera och skapa marknadsföringskampanjer som är mer benägna att få resonans hos specifika kundgrupper.
År 2022 beställde AWS en studie utförd av American Productivity and Quality Center (APQC) för att kvantifiera Business Value of Customer 360. Följande figur visar några av de mått som härrör från studien. Organisationer som använder C360 uppnådde 43.9 % minskning av försäljningscykelns varaktighet, 22.8 % ökning i kundlivstidsvärde, 25.3 % snabbare tid till marknaden och 19.1 % förbättring i NPS-betyg (net promoter score).

Utan C360 möter företag missade möjligheter, felaktiga rapporter och osammanhängande kundupplevelser, vilket leder till kundförlust. Att bygga en C360-lösning kan dock vara komplicerat. A Gartners marknadsundersökning fann att endast 14 % av organisationerna framgångsrikt har implementerat en C360-lösning, på grund av bristande konsensus om vad en 360-gradersvy innebär, utmaningar med datakvalitet och brist på tvärfunktionell styrningsstruktur för kunddata.
I det här inlägget diskuterar vi hur du kan använda specialbyggda AWS-tjänster för att skapa en heltäckande datastrategi för C360 för att förena och styra kunddata som hanterar dessa utmaningar. Vi strukturerar det i fem pelare som driver C360: datainsamling, sammanslagning, analys, aktivering och datastyrning, tillsammans med en lösningsarkitektur som du kan använda för din implementering.
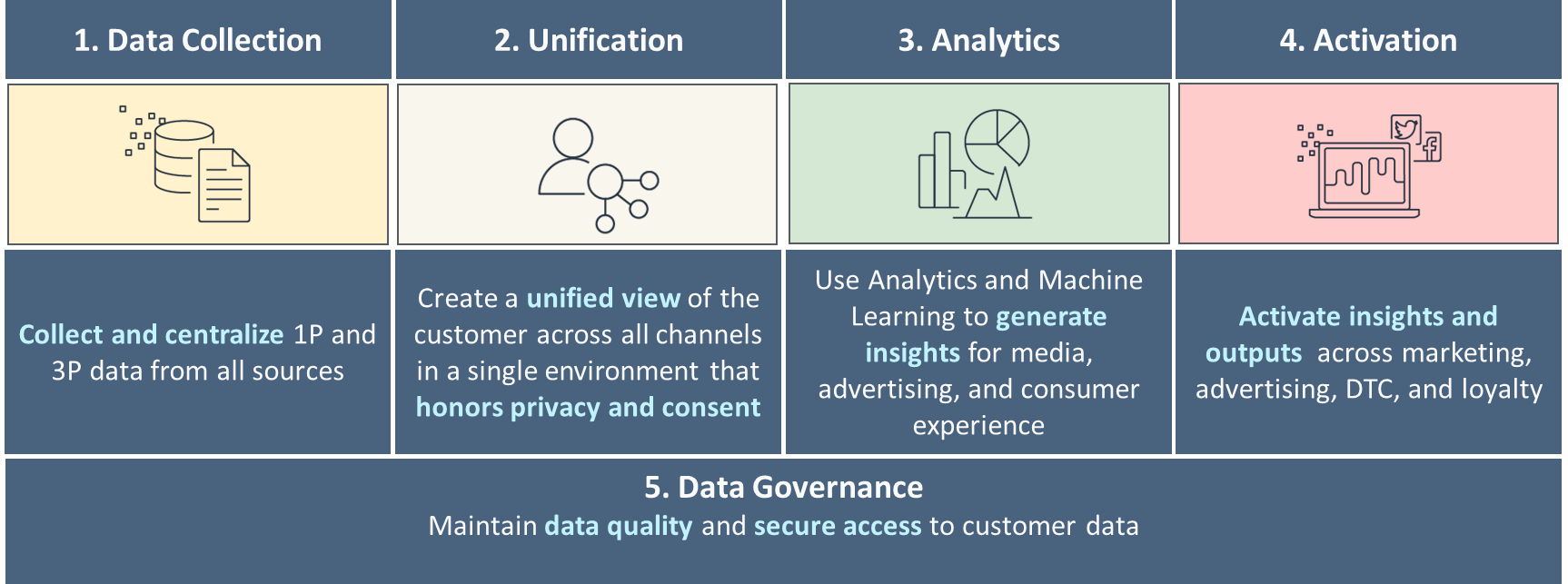
De fem pelarna i en mogen C360
När du ger dig i kast med att skapa en C360 arbetar du med flera användningsfall, typer av kunddata och användare och applikationer som kräver olika verktyg. Att bygga en C360 på rätt datauppsättningar, lägga till nya datauppsättningar över tid samtidigt som kvaliteten på data bibehålls och att hålla den säker kräver en heltäckande datastrategi för dina kunddata. Du måste också tillhandahålla verktyg som gör det enkelt för dina team att bygga produkter som utvecklar din C360.
Vi rekommenderar att du bygger din datastrategi runt fem pelare i C360, som visas i följande figur. Detta börjar med grundläggande datainsamling, förenande och länkning av data från olika kanaler relaterade till unika kunder, och går vidare mot grundläggande till avancerad analys för beslutsfattande och personligt engagemang genom olika kanaler. När du mognar i var och en av dessa pelare går du framåt mot att svara på kundsignaler i realtid.
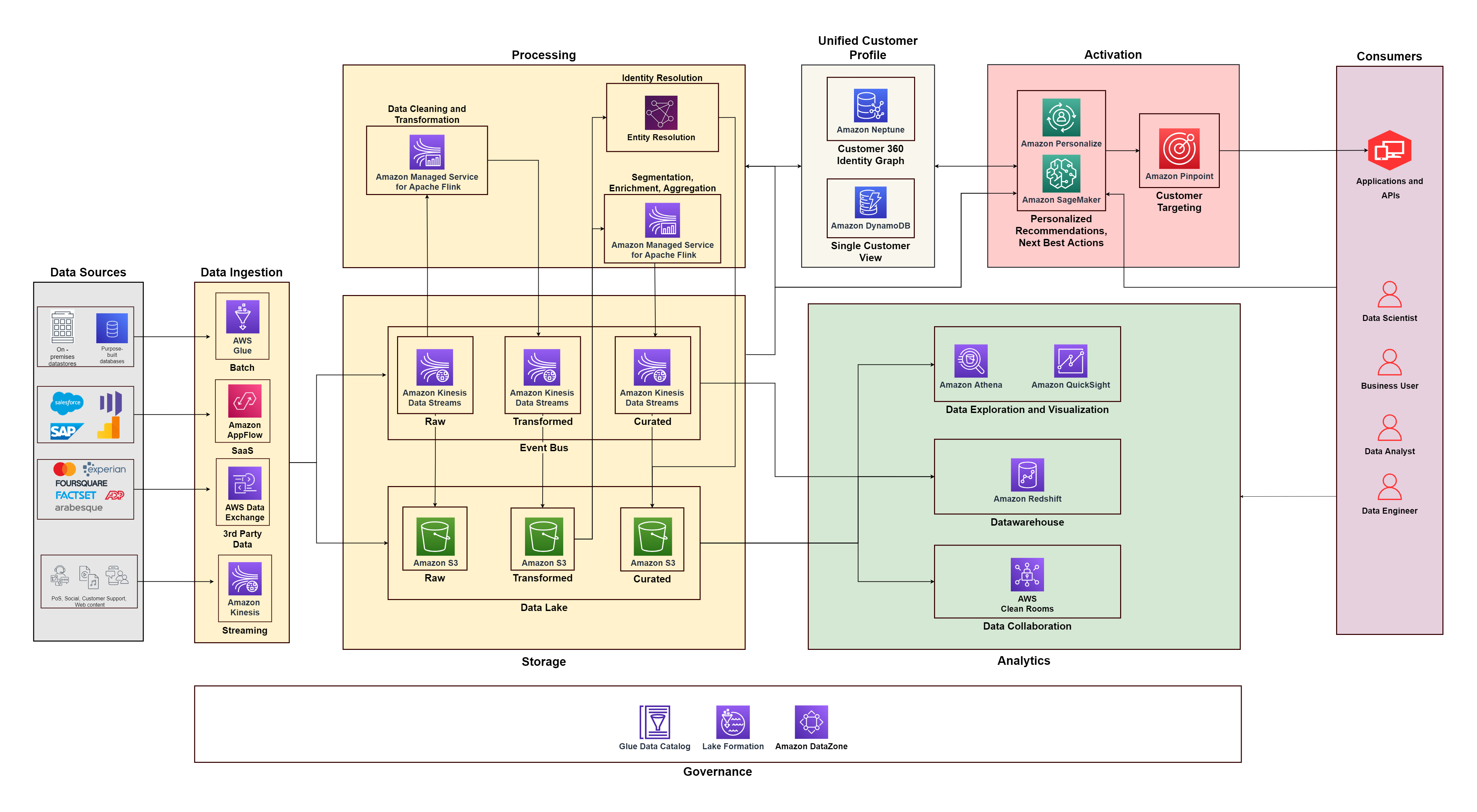
Följande diagram illustrerar den funktionella arkitekturen som kombinerar byggstenarna i en Kunddataplattform på AWS med ytterligare komponenter som används för att designa en heltäckande C360-lösning. Detta är anpassat till de fem pelarna som vi diskuterar i det här inlägget.
Pelare 1: Datainsamling
När du börjar bygga din kunddataplattform måste du samla in data från olika system och kontaktpunkter, såsom dina säljsystem, kundsupport, webb och sociala medier samt datamarknadsplatser. Tänk på datainsamlingens pelare som en kombination av intag, lagring och bearbetningsmöjligheter.
Upptagning av data
Du måste bygga inmatningspipelines baserat på faktorer som typer av datakällor (lokala datalager, filer, SaaS-applikationer, data från tredje part) och dataflöde (obegränsade strömmar eller batchdata). AWS tillhandahåller olika tjänster för att bygga pipelines för dataintag:
- AWS-lim är en serverlös dataintegrationstjänst som tar in data i partier från lokala databaser och datalager i molnet. Den ansluter till mer än 70 datakällor och hjälper dig att bygga extrahera, transformera och ladda (ETL) pipelines utan att behöva hantera pipeline-infrastruktur. AWS limdatakvalitet kontrollerar och varnar om dålig data, vilket gör det enkelt att upptäcka och åtgärda problem innan de skadar ditt företag.
- Amazon App Flow tar in data från SaaS-applikationer (Software as a Service) som Google Analytics, Salesforce, SAP och Marketo, vilket ger dig flexibiliteten att mata in data från mer än 50 SaaS-applikationer.
- AWS datautbyte gör det enkelt att hitta, prenumerera på och använda data från tredje part för analys. Du kan prenumerera på dataprodukter som hjälper till att berika kundprofiler, till exempel demografisk data, reklamdata och finansmarknadsdata.
- Amazon Kinesis tar in strömmande händelser i realtid från försäljningsställen, klickströmdata från mobilappar och webbplatser och sociala medier. Du kan också överväga att använda Amazon Managed Streaming för Apache Kafka (Amazon MSK) för att streama händelser i realtid.
Följande diagram illustrerar de olika pipelines för att mata in data från olika källsystem som använder AWS-tjänster.
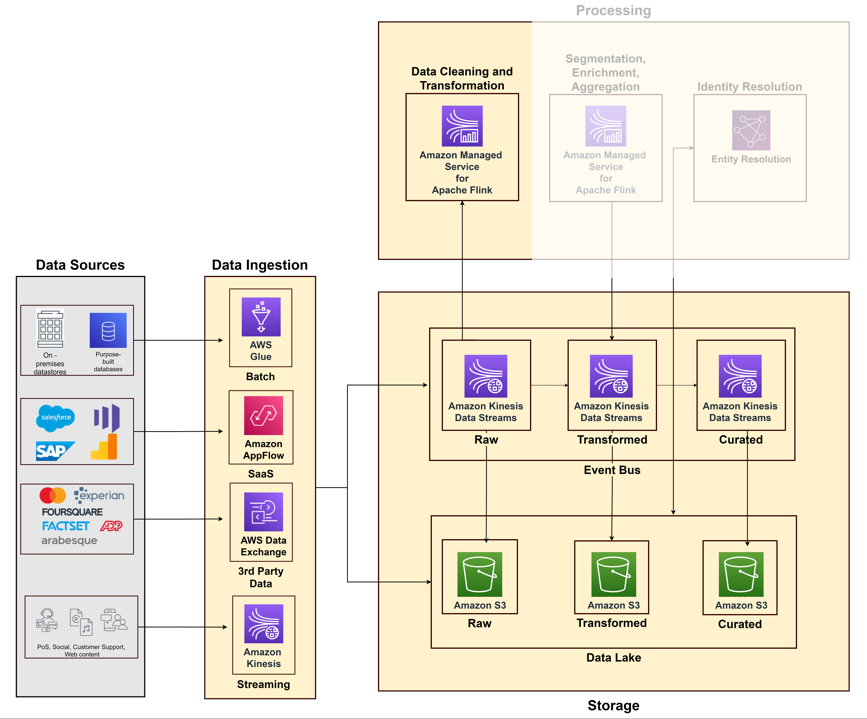
Datalagring
Strukturerad, semistrukturerad eller ostrukturerad batchdata lagras i ett objektlager eftersom dessa är kostnadseffektiva och hållbara. Amazon enkel lagringstjänst (Amazon S3) är en hanterad lagringstjänst med arkiveringsfunktioner som kan lagra petabyte med data med elva 9:or av hållbarhet. Strömmande data med låga latensbehov lagras i Amazon Kinesis dataströmmar för realtidskonsumtion. Detta möjliggör omedelbar analys och åtgärder för olika nedströmskonsumenter – som sett med Riot Games central Riot Event Bus.
Databearbetning
Rådata är ofta belamrad med dubbletter och oregelbundna format. Du måste bearbeta detta för att göra det redo för analys. Om du konsumerar batchdata och strömmande data, överväg att använda ett ramverk som kan hantera båda. Ett mönster som Kappa arkitektur ser allt som en ström, vilket förenklar bearbetningspipelines. Överväg att använda Amazon Managed Service för Apache Flink att sköta bearbetningsarbetet. Med Managed Service för Apache Flink kan du rensa och transformera strömmande data och dirigera den till lämplig destination baserat på latenskrav. Du kan också implementera batchdatabehandling med hjälp av Amazon EMR på ramverk med öppen källkod som Apache Spark med 3.5 gånger bättre prestanda än den självhanterade versionen. Arkitekturbeslutet att använda ett batch- eller strömmande bearbetningssystem kommer att bero på olika faktorer; men om du vill aktivera realtidsanalys av dina kunddata rekommenderar vi att du använder ett Kappa-arkitekturmönster.
Pelare 2: Enande
För att länka olika data som kommer från olika kontaktpunkter till en unik kund måste du bygga en identitetsbearbetningslösning som identifierar anonyma inloggningar, lagrar användbar kundinformation, länkar dem till extern data för bättre insikter och grupperar kunder i intressedomäner. Även om identitetsbearbetningslösningen hjälper till att bygga den enhetliga kundprofilen rekommenderar vi att du överväger detta som en del av dina databehandlingsmöjligheter. Följande diagram illustrerar komponenterna i en sådan lösning.
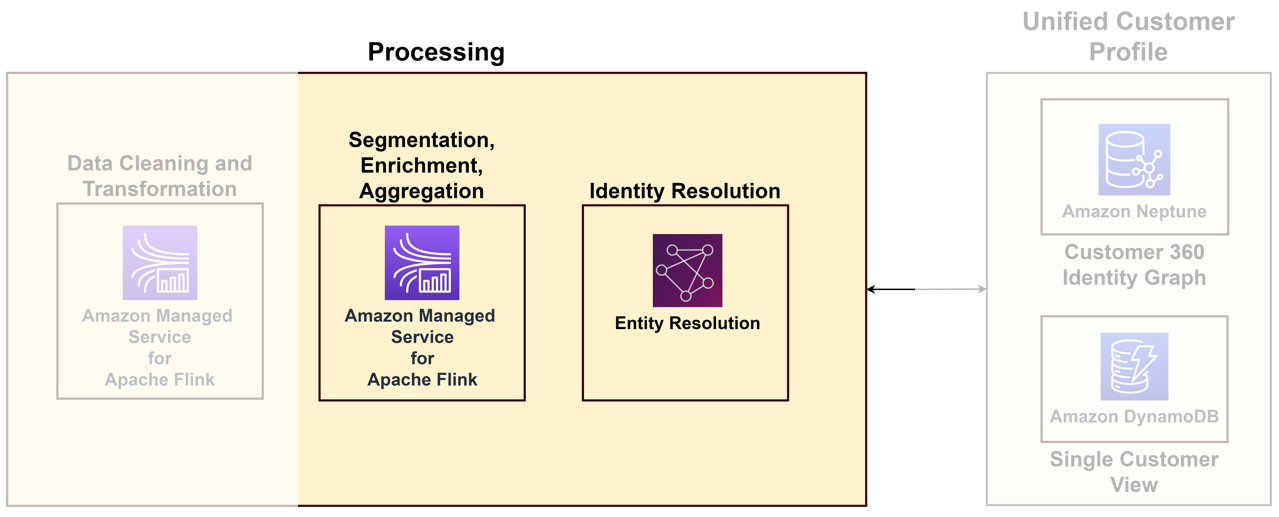
De viktigaste komponenterna är följande:
- Identitetsupplösning – Identitetsupplösning är en lösning för deduplicering, där poster matchas för att identifiera en unik kund och potentiella kunder genom att länka flera identifierare såsom cookies, enhetsidentifierare, IP-adresser, e-post-ID och interna företags-ID:n till en känd person eller anonym profil med hjälp av sekretess- kompatibla metoder. Detta kan uppnås med hjälp av AWS Entity Resolution, som gör det möjligt att använda regler och maskininlärningstekniker (ML) för att matcha register och lösa identiteter. Alternativt kan du bygga identitetsdiagram med hjälp av Amazon Neptunus för en enda enhetlig vy av dina kunder.
- Profilaggregation – När du unikt har identifierat en kund kan du bygga applikationer i Managed Service för Apache Flink för att konsolidera all deras metadata, från namn till interaktionshistorik. Sedan omvandlar du dessa data till ett kortfattat format. Istället för att visa varje transaktionsdetalj kan du erbjuda ett aggregerat utgiftsvärde och en länk till deras Customer Relationship Management (CRM)-post. För kundtjänstinteraktioner, ange ett genomsnittligt CSAT-resultat och en länk till callcentersystemet för en djupare dykning i deras kommunikationshistorik.
- Profilberikning – När du har löst en kund till en enda identitet, förbättra deras profil med hjälp av olika datakällor. Anrikning innebär vanligtvis att lägga till demografiska, beteendemässiga och geolokaliseringsdata. Du kan använda tredjepartsdataprodukter från AWS Marketplace levererade via AWS Data Exchange för att få insikter om inkomst, konsumtionsmönster, kreditriskpoäng och många fler dimensioner för att ytterligare förfina kundupplevelsen.
- Kundsegmentering – Efter att unikt identifierat och berikat en kunds profil kan du segmentera dem baserat på demografi som ålder, utgifter, inkomst och plats med hjälp av applikationer i Managed Service för Apache Flink. När du avancerar kan du införliva AI-tjänster för mer exakta inriktningstekniker.
Efter att du har gjort identitetsbearbetningen och segmenteringen behöver du en lagringskapacitet för att lagra den unika kundprofilen och tillhandahålla sök- och frågemöjligheter ovanpå den för nedströmskonsumenter att använda den berikade kunddatan.
Följande diagram illustrerar sammanslagningspelaren för en enhetlig kundprofil och en enda vy av kunden för nedströmsapplikationer.
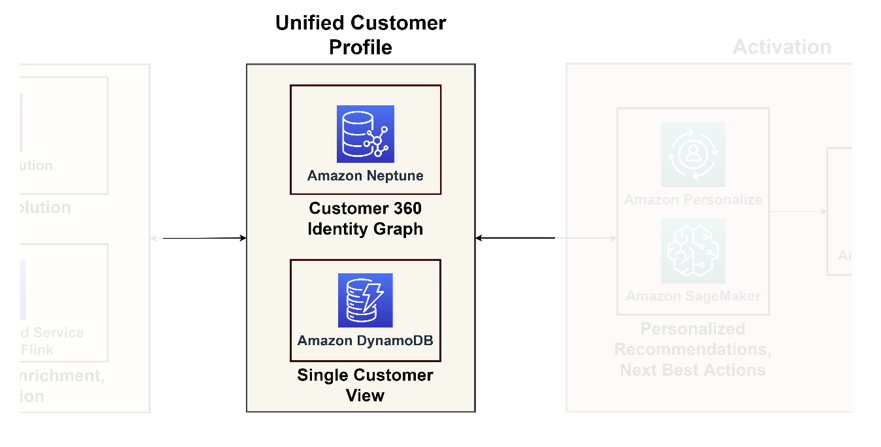
Enad kundprofil
Grafdatabaser utmärker sig när det gäller att modellera kundinteraktioner och relationer, och erbjuder en heltäckande bild av kundresan. Om du har att göra med miljarder profiler och interaktioner kan du överväga att använda Neptune, en hanterad grafdatabastjänst på AWS. Organisationer som t.ex Zeta och Activision har framgångsrikt använt Neptune för att lagra och söka efter miljarder unika identifierare per månad och miljontals frågor per sekund vid svarstid på millisekunder.
Enskild kundvy
Även om grafdatabaser ger djupgående insikter, kan de ändå vara komplexa för vanliga applikationer. Det är klokt att konsolidera dessa data till en enda kundvy, som fungerar som en primär referens för nedströmsapplikationer, allt från e-handelsplattformar till CRM-system. Denna konsoliderade syn fungerar som en länk mellan dataplattformen och kundcentrerade applikationer. För sådana ändamål rekommenderar vi att du använder Amazon DynamoDB för dess anpassningsförmåga, skalbarhet och prestanda, vilket resulterar i en uppdaterad och effektiv kunddatabas. Denna databas kommer att ta emot många skrivfrågor från aktiveringssystemen som lär sig ny information om kunderna och återkopplar dem.
Pelare 3: Analys
Analyspelaren definierar funktioner som hjälper dig att generera insikter ovanpå din kunddata. Din analysstrategi gäller de bredare organisationsbehoven, inte bara C360. Du kan använda samma funktioner för att tillhandahålla finansiell rapportering, mäta operativa resultat eller till och med tjäna pengar på datatillgångar. Strategiisera baserat på hur dina team utforskar data, kör analyser, tvistar om data för nedströmskrav och visualiserar data på olika nivåer. Planera hur ni kan göra det möjligt för era team att använda ML för att gå från beskrivande till föreskrivande analyser.
Smakämnen AWS modern dataarkitektur visar ett sätt att bygga en specialbyggd, säker och skalbar dataplattform i molnet. Lär dig av detta för att bygga frågefunktioner över din datasjö och datalagret.
Följande diagram delar upp analyskapaciteten i datautforskning, visualisering, datalagring och datasamarbete. Låt oss ta reda på vilken roll var och en av dessa komponenter spelar i samband med C360.

Datautforskning
Datautforskning hjälper till att upptäcka inkonsekvenser, extremvärden eller fel. Genom att upptäcka dessa tidigt kan dina team få renare dataintegration för C360, vilket i sin tur leder till mer exakta analyser och förutsägelser. Tänk på personas som utforskar data, deras tekniska färdigheter och tiden till insikt. Till exempel kan dataanalytiker som vet att skriva SQL direkt fråga data som finns i Amazon S3 med hjälp av Amazonas Athena. Användare som är intresserade av visuell utforskning kan göra det med hjälp av AWS Lim DataBrew. Dataforskare eller ingenjörer kan använda Amazon EMR Studio or Amazon SageMaker Studio för att utforska data från den bärbara datorn, och för en upplevelse med låg kod kan du använda Amazon SageMaker Data Wrangler. Eftersom dessa tjänster direkt frågar S3-buckets kan du utforska data när den landar i datasjön, vilket minskar tiden till insikt.
Visualisering
Att förvandla komplexa datauppsättningar till intuitiva bilder avslöjar dolda mönster i data, och är avgörande för C360-användningsfall. Med den här förmågan kan du designa rapporter för olika nivåer som tillgodoser olika behov: chefsrapporter som erbjuder strategiska översikter, ledningsrapporter som lyfter fram operativa mätvärden och detaljerade rapporter som dyker in i detaljerna. Sådan visuell tydlighet hjälper din organisation att fatta välgrundade beslut över alla nivåer, vilket centraliserar kundens perspektiv.
Följande diagram visar ett exempel på en C360-instrumentpanel byggd på Amazon QuickSight. QuickSight erbjuder skalbara, serverlösa visualiseringsmöjligheter. Du kan dra nytta av dess ML-integrationer för automatiserade insikter som prognoser och avvikelsedetektering eller naturliga språkfrågor med Amazon Q i QuickSight, direkt dataanslutning från olika källor, och betal-per-session prissättning. Med QuickSight kan du bädda in instrumentpaneler till externa webbplatser och applikationer, Och den KRYDDA motorn möjliggör snabb, interaktiv datavisualisering i stor skala. Följande skärmdump visar ett exempel på C360-instrumentpanelen byggd på QuickSight.
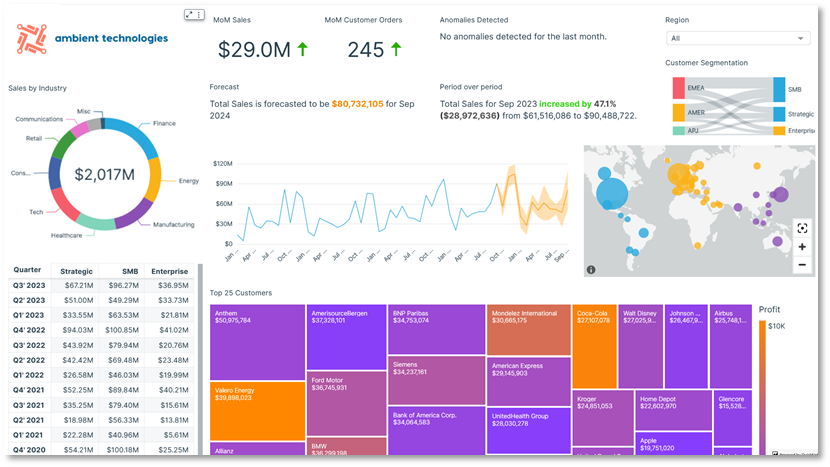
Datalager
Datalager är effektiva när det gäller att konsolidera strukturerad data från olika källor och betjäna analysfrågor från ett stort antal samtidiga användare. Datalager kan ge en enhetlig, konsekvent bild av en stor mängd kunddata för C360-användningsfall. Amazon RedShift tillgodoser detta behov genom att på ett skickligt sätt hantera stora datamängder och olika arbetsbelastningar. Det ger stark konsistens över datauppsättningar, vilket gör det möjligt för organisationer att få tillförlitliga, omfattande insikter om sina kunder, vilket är avgörande för välgrundat beslutsfattande. Amazon Redshift erbjuder realtidsinsikter och prediktiva analysfunktioner för att analysera data från terabyte till petabyte. Med Amazon Redshift ML, kan du bädda in ML ovanpå data som lagras i datalagret med minimala utvecklingskostnader. Amazon Redshift Serverlös förenklar applikationsbyggandet och gör det enkelt för företag att bädda in rika dataanalysfunktioner.
Datasamarbete
Du kan säkert samarbeta och analysera kollektiva datamängder från dina partners utan att dela eller kopiera varandras underliggande data med hjälp av AWS rena rum. Du kan sammanföra olika data från alla engagemangskanaler och partnerdatauppsättningar för att bilda en 360-graders bild av dina kunder. AWS Clean Rooms kan förbättra C360 genom att möjliggöra användningsfall som optimering av marknadsföring över kanaler, avancerad kundsegmentering och integritetskompatibel personalisering. Genom att på ett säkert sätt sammanfoga datamängder erbjuder den rikare insikter och robust datasekretess, vilket möter affärsbehov och regulatoriska standarder.
Pelare 4: Aktivering
Värdet på data minskar ju äldre den blir, vilket leder till högre alternativkostnader över tid. I en undersökning utförs av Intersystems, 75 % av de tillfrågade organisationerna anser att otidig data hämmade affärsmöjligheter. I en annan undersökning, 58% av organisationerna (av 560 svarande från HBRs rådgivande råd och läsare) uppgav att de såg en ökning i kundbehållning och lojalitet med hjälp av kundanalyser i realtid.
Du kan uppnå en mognad i C360 när du bygger förmågan att agera utifrån alla insikter som erhållits från de tidigare pelarna vi diskuterade i realtid. Till exempel, på denna mognadsnivå, kan du agera på kundsentiment baserat på det sammanhang du automatiskt härledde med en berikad kundprofil och integrerade kanaler. För detta måste du implementera föreskrivande beslutsfattande om hur du ska hantera kundens sentiment. För att göra detta i stor skala måste du använda AI/ML-tjänster för beslutsfattande. Följande diagram illustrerar arkitekturen för att aktivera insikter med ML för föreskrivande analys och AI-tjänster för inriktning och segmentering.
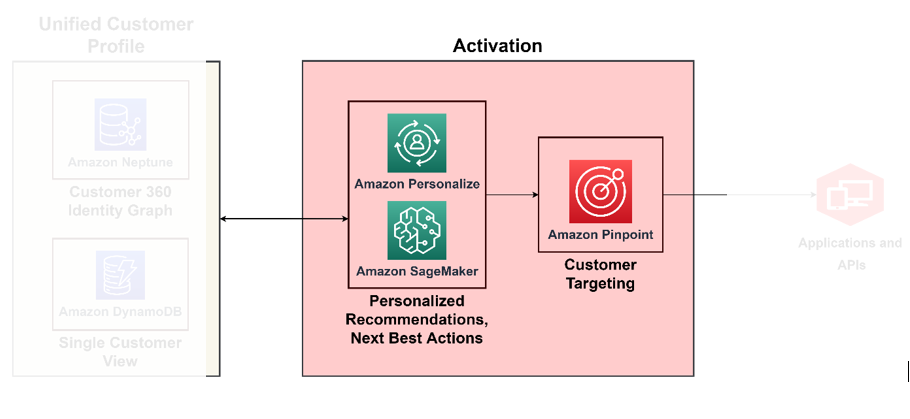
Använd ML för beslutsfattande motorn
Med ML kan du förbättra den övergripande kundupplevelsen – du kan skapa modeller för förutsägande kundbeteende, designa hyperanpassade erbjudanden och rikta in dig på rätt kund med rätt incitament. Du kan bygga dem med hjälp av Amazon SageMaker, som innehåller en svit av hanterade tjänster som är mappade till datavetenskapens livscykel, inklusive datatvist, modellträning, modellvärd, modellslutning, detektering av modelldrift och funktionslagring. SageMaker gör det möjligt för dig bygga och operationalisera dina ML-modeller, ingjuta dem tillbaka i dina applikationer för att producera rätt insikt till rätt person vid rätt tidpunkt.
Amazon Anpassa stöder kontextuella rekommendationer, genom vilka du kan förbättra rekommendationernas relevans genom att generera dem i ett sammanhang – till exempel enhetstyp, plats eller tid på dygnet. Ditt team kan komma igång utan föregående ML-erfarenhet genom att använda API:er för att bygga sofistikerade anpassningsmöjligheter med några få klick. För mer information, se Anpassa dina rekommendationer genom att marknadsföra specifika föremål med hjälp av affärsregler med Amazon Personalize.
Aktivera kanaler över marknadsföring, reklam, direkt till konsument och lojalitet
Nu när du vet vilka dina kunder är och vilka du ska nå ut till kan du bygga lösningar för att köra inriktningskampanjer i stor skala. Med Amazon precis, kan du anpassa och segmentera kommunikation för att engagera kunder över flera kanaler. Du kan till exempel använda Amazon Pinpoint för att skapa engagerande kundupplevelser genom olika kommunikationskanaler som e-post, SMS, push-meddelanden och aviseringar i appen.
Pelare 5: Datastyrning
Att etablera rätt styrning som balanserar kontroll och åtkomst ger användarna förtroende och förtroende för data. Föreställ dig att erbjuda kampanjer på produkter som en kund inte behöver, eller bombardera fel kunder med aviseringar. Dålig datakvalitet kan leda till sådana situationer och i slutändan resultera i kundförlust. Du måste bygga processer som validerar datakvalitet och vidta korrigerande åtgärder. AWS limdatakvalitet kan hjälpa dig att bygga lösningar som validerar kvaliteten på data i vila och under transport, baserat på fördefinierade regler.
För att skapa en tvärfunktionell styrningsstruktur för kunddata behöver du en förmåga att styra och dela data över din organisation. Med Amazon DataZone, administratörer och dataförvaltare kan hantera och styra åtkomst till data, och konsumenter som dataingenjörer, datavetare, produktchefer, analytiker och andra affärsanvändare kan upptäcka, använda och samarbeta med dessa data för att få insikter. Det effektiviserar dataåtkomst, låter dig hitta och använda kunddata, främjar teamsamarbete med delade datatillgångar och tillhandahåller personlig analys antingen via en webbapp eller API på en portal. AWS Lake Formation ser till att data nås på ett säkert sätt, vilket garanterar att rätt personer ser rätt data av rätt anledningar, vilket är avgörande för effektiv tvärfunktionell styrning i alla organisationer. Affärsmetadata lagras och hanteras av Amazon DataZone, som stöds av teknisk metadata och schemainformation, som är registrerad i AWS limdatakatalog. Denna tekniska metadata används också av både andra styrningstjänster som Lake Formation och Amazon DataZone, och analystjänster som Amazon Redshift, Athena och AWS Glue.

Att föra ihop allt
Med hjälp av följande diagram som referens kan du skapa projekt och team för att bygga och driva olika kapaciteter. Till exempel kan du ha ett dataintegrationsteam som fokuserar på datainsamlingens pelare – du kan sedan anpassa funktionella roller, som dataarkitekter och dataingenjörer. Du kan bygga upp dina analytiska och datavetenskapliga metoder för att fokusera på analys- respektive aktiveringspelare. Sedan kan du skapa ett specialiserat team för kundidentitetsbearbetning och för att bygga en enhetlig syn på kunden. Du kan skapa ett datastyrningsteam med dataansvariga från olika funktioner, säkerhetsadministratörer och beslutsfattare för datastyrning för att utforma och automatisera policyer.
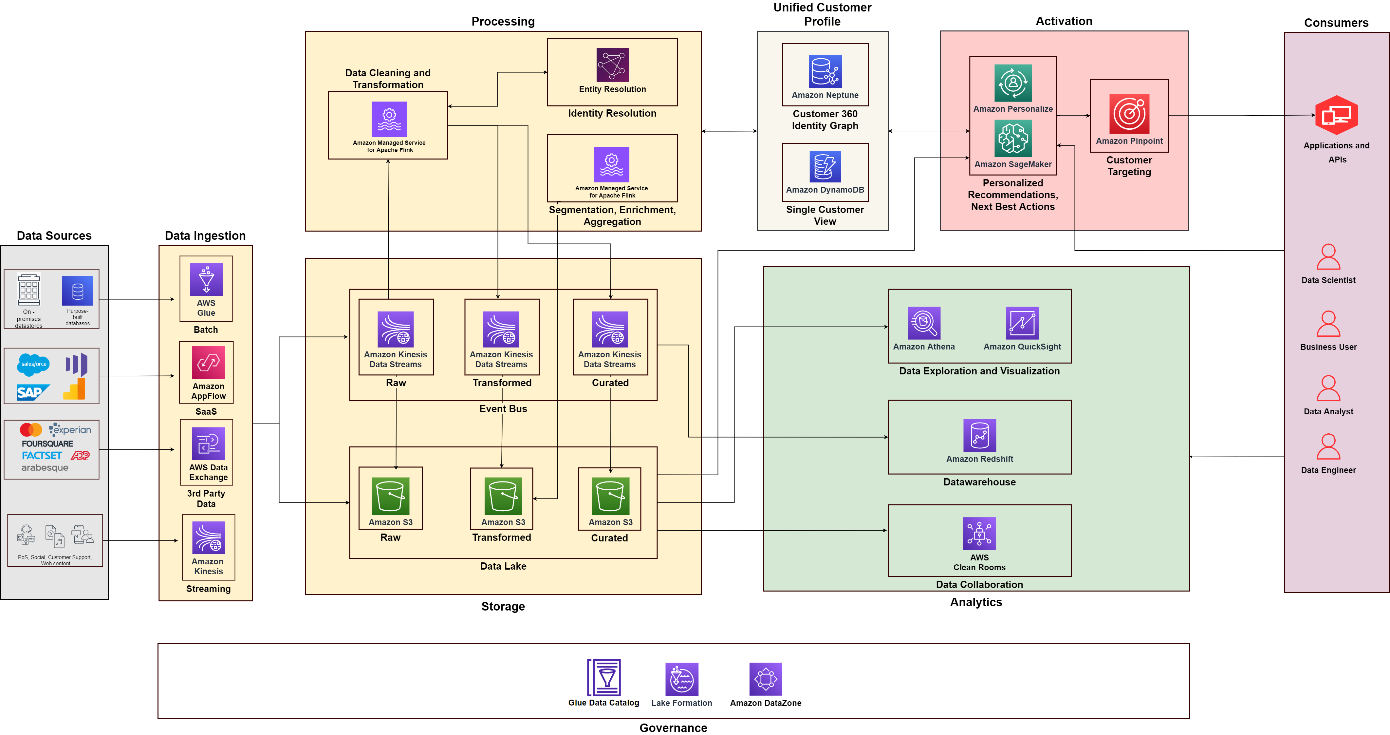
Slutsats
Att bygga en robust C360-kapacitet är grundläggande för att din organisation ska få insikter i din kundbas. AWS-databaser, analys och AI/ML-tjänster kan hjälpa till att effektivisera denna process, vilket ger skalbarhet och effektivitet. Genom att följa de fem pelarna för att vägleda ditt tänkande kan du bygga en heltäckande datastrategi som definierar C360-vyn över hela organisationen, ser till att data är korrekta och etablerar tvärfunktionell styrning av kunddata. Du kan kategorisera och prioritera de produkter och funktioner du måste bygga inom varje pelare, välja rätt verktyg för jobbet och bygga upp de färdigheter du behöver i dina team.
Besök AWS for Data Customer Stories för att lära dig hur AWS förvandlar kundresor, från världens största företag till växande startups.
Om författarna
 Ismail Makhlouf är Senior Specialist Solutions Architect för Data Analytics på AWS. Ismail fokuserar på arkitekturlösningar för organisationer över deras end-to-end dataanalysområde, inklusive batch- och realtidsströmning, big data, datalager och datasjöarbetsbelastningar. Han arbetar främst med organisationer inom detaljhandel, e-handel, FinTech, HealthTech och resor för att uppnå sina affärsmål med väl utformade dataplattformar.
Ismail Makhlouf är Senior Specialist Solutions Architect för Data Analytics på AWS. Ismail fokuserar på arkitekturlösningar för organisationer över deras end-to-end dataanalysområde, inklusive batch- och realtidsströmning, big data, datalager och datasjöarbetsbelastningar. Han arbetar främst med organisationer inom detaljhandel, e-handel, FinTech, HealthTech och resor för att uppnå sina affärsmål med väl utformade dataplattformar.
 Sandipan Bhaumik (Sandi) är Senior Analytics Specialist Solutions Architect på AWS. Han hjälper kunder att modernisera sina dataplattformar i molnet för att utföra analyser säkert i stor skala, minska driftskostnader och optimera användningen för kostnadseffektivitet och hållbarhet.
Sandipan Bhaumik (Sandi) är Senior Analytics Specialist Solutions Architect på AWS. Han hjälper kunder att modernisera sina dataplattformar i molnet för att utföra analyser säkert i stor skala, minska driftskostnader och optimera användningen för kostnadseffektivitet och hållbarhet.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/create-an-end-to-end-data-strategy-for-customer-360-on-aws/

