Organisationer behöver ofta hantera en stor mängd data som växer i en extraordinär takt. Samtidigt måste de optimera driftskostnaderna för att låsa upp värdet av denna data för snabba insikter och göra det med en konsekvent prestanda.
Med denna massiva datatillväxt kan dataspridning över dina datalager, datalager och datasjöar bli lika utmanande. Med en modern dataarkitektur på AWS kan du snabbt bygga skalbara datasjöar; använda en bred och djup samling av specialanpassade datatjänster; säkerställa efterlevnad via enhetlig dataåtkomst, säkerhet och styrning; skala dina system till en låg kostnad utan att kompromissa med prestanda; och dela data över organisationsgränser med lätthet, så att du kan fatta beslut med snabbhet och smidighet i stor skala.
Du kan ta all din data från olika silos, samla dessa data i din datasjö och utföra analyser och maskininlärning (ML) direkt ovanpå den datan. Du kan också lagra annan data i specialbyggda datalager för att analysera och få snabba insikter från både strukturerad och ostrukturerad data. Denna datarörelse kan vara inifrån-ut, utanför-in, runt omkretsen eller dela över.
Till exempel kan applikationsloggar och spår från webbapplikationer samlas in direkt i en datasjö, och en del av denna data kan flyttas ut till en logganalysbutik som Amazon OpenSearch Service för daglig analys. Vi tänker på detta koncept som ut-och in datarörelse. Den analyserade och aggregerade data som lagras i Amazon OpenSearch Service kan återigen flyttas till datasjön för att köra ML-algoritmer för nedströms konsumtion från applikationer. Vi hänvisar till detta koncept som ut-och-in datarörelse.
Låt oss titta på ett exempel på användningsfall. Exempel Corp. är ett ledande Fortune 500-företag som är specialiserat på socialt innehåll. De har hundratals applikationer som genererar data och spår på cirka 500 TB per dag och har följande kriterier:
- Ha loggar tillgängliga för snabb analys i 2 dagar
- Utöver 2 dagar, ha data tillgänglig i en lagringsnivå som kan göras tillgänglig för analys med en rimlig SLA
- Behåll data längre än 1 vecka i kylförvaring i 30 dagar (för efterlevnad, revision och annat)
I följande avsnitt diskuterar vi tre möjliga lösningar för att hantera liknande användningsfall:
- Lagring i nivå med Amazon OpenSearch Service och datalivscykelhantering
- On-demand intag av loggar med hjälp av Amazon OpenSearch Intag
- Amazon OpenSearch Service direkta frågor med Amazon Simple Storage Service (Amazon S3)
Lösning 1: Nivålagring i OpenSearch Service och datalivscykelhantering
OpenSearch Service stöder tre integrerade lagringsnivåer: varm, UltraWarm och kall lagring. Baserat på dina datalagring, frågefördröjning och budgetkrav kan du välja den bästa strategin för att balansera kostnad och prestanda. Du kan också migrera data mellan olika lagringsnivåer.
Hot storage används för indexering och uppdatering och ger den snabbaste åtkomsten till data. Varmlagring har formen av en instansbutik eller Amazon Elastic Block Store (Amazon EBS) volymer kopplade till varje nod.
UltraWarm erbjuder betydligt lägre kostnader per GiB för skrivskyddad data som du frågar mindre ofta och som inte behöver samma prestanda som varmlagring. UltraWarm-noder använder Amazon S3 med relaterade cachningslösningar för att förbättra prestandan.
Kyllagring är optimerad för att lagra sällan åtkomst eller historisk data. När du använder kylförvaring kopplar du bort dina index från UltraWarm-nivån, vilket gör dem oåtkomliga. Du kan bifoga dessa index igen på några sekunder när du behöver fråga efter data.
För mer information om datanivåer inom OpenSearch Service, se Välj rätt lagringsnivå för dina behov i Amazon OpenSearch Service.
Lösningsöversikt
Arbetsflödet för denna lösning består av följande steg:
- Inkommande data som genereras av applikationerna strömmas till en S3-datasjö.
- Data tas in i Amazon OpenSearch med hjälp av S3-SQS intag nästan i realtid genom aviseringar som ställs in på S3-hinkarna.
- Efter 2 dagar migreras heta data till UltraWarm-lagring för att stödja läsfrågor.
- Efter 5 dagar i UltraWarm migreras data till kyllagring i 21 dagar och kopplas bort från alla datorer. Data kan återkopplas till UltraWarm vid behov. Data raderas från kylförvaring efter 21 dagar.
- Dagliga index upprätthålls för enkel rollover. En Index State Management-policy (ISM) automatiserar övergången eller raderingen av index som är äldre än 2 dagar.
Följande är ett exempel på en ISM-policy som rullar över data till UltraWarm-nivån efter 2 dagar, flyttar den till kyllagring efter 5 dagar och raderar den från kyllagring efter 21 dagar:
Överväganden
UltraWarm använder sofistikerade cachningstekniker för att möjliggöra sökningar efter sällan åtkomst till data. Även om dataåtkomsten är sällsynt, måste beräkningen för UltraWarm-noder vara igång hela tiden för att göra denna åtkomst möjlig.
När du arbetar i PB-skala, för att minska effektområdet för eventuella fel, rekommenderar vi att du delar upp implementeringen i flera OpenSearch Service-domäner när du använder nivålagring.
De följande två mönstren tar bort behovet av att ha långvarig beräkning och beskriver on-demand-tekniker där data antingen hämtas vid behov eller frågas direkt var den finns.
Lösning 2: Inmatning på begäran av loggdata genom OpenSearch Intag
OpenSearch Ingestion är en helt hanterad datainsamlare som levererar logg- och spårningsdata i realtid till OpenSearch Service-domäner. OpenSearch Ingestion drivs av datainsamlaren med öppen källkod Dataförberedare. Data Prepper är en del av OpenSearch-projekt med öppen källkod.
Med OpenSearch Ingestion kan du filtrera, berika, transformera och leverera dina data för nedströmsanalys och visualisering. Du konfigurerar dina dataproducenter att skicka data till OpenSearch Ingestion. Den levererar automatiskt data till domänen eller samlingen som du anger. Du kan också konfigurera OpenSearch Ingestion för att transformera din data innan den levereras. OpenSearch Ingestion är serverlöst, så du behöver inte oroa dig för att skala din infrastruktur, driva din intagsflotta och patcha eller uppdatera programvaran.
Det finns två sätt som du kan använda Amazon S3 som källa för att bearbeta data med OpenSearch Ingestion. Det första alternativet är S3-SQS-bearbetning. Du kan använda S3-SQS-behandling när du behöver skanning i nästan realtid av filer efter att de har skrivits till S3. Det kräver en Amazon enkel kötjänst (Amazon S3) kö som tar emot S3 händelsemeddelanden. Du kan konfigurera S3-buckets för att höja en händelse när som helst ett objekt lagras eller modifieras i hinken som ska bearbetas.
Alternativt kan du använda en engångs- eller återkommande schemalagd skanning för att batchbearbeta data i en S3-hink. För att ställa in en schemalagd skanning, konfigurera din pipeline med ett schema på skanningsnivån som gäller för alla dina S3-buckets, eller på hinknivå. Du kan konfigurera schemalagda skanningar med antingen en engångsskanning eller en återkommande skanning för batchbearbetning.
För en omfattande översikt över OpenSearch Intag, se Amazon OpenSearch Intag. För mer information om Data Prepper open source-projektet, besök Dataförberedare.
Lösningsöversikt
Vi presenterar ett arkitekturmönster med följande nyckelkomponenter:
- Applikationsloggar strömmas in till datasjön, vilket hjälper till att mata in het data till OpenSearch Service i nästan realtid med hjälp av OpenSearch Ingestion S3-SQS-bearbetning.
- ISM-policyer inom OpenSearch Service hanterar indexövergångar eller borttagningar. ISM-policyer låter dig automatisera dessa periodiska, administrativa operationer genom att utlösa dem baserat på ändringar i indexåldern, indexstorleken eller antalet dokument. Du kan till exempel definiera en policy som flyttar ditt index till ett skrivskyddat läge efter 2 dagar och sedan raderar det efter en viss period på 3 dagar.
- Kalla data är tillgängliga i S3-datasjön för att kunna konsumeras på begäran i OpenSearch Service med OpenSearch Ingestion schemalagda skanningar.
Följande diagram illustrerar lösningsarkitekturen.
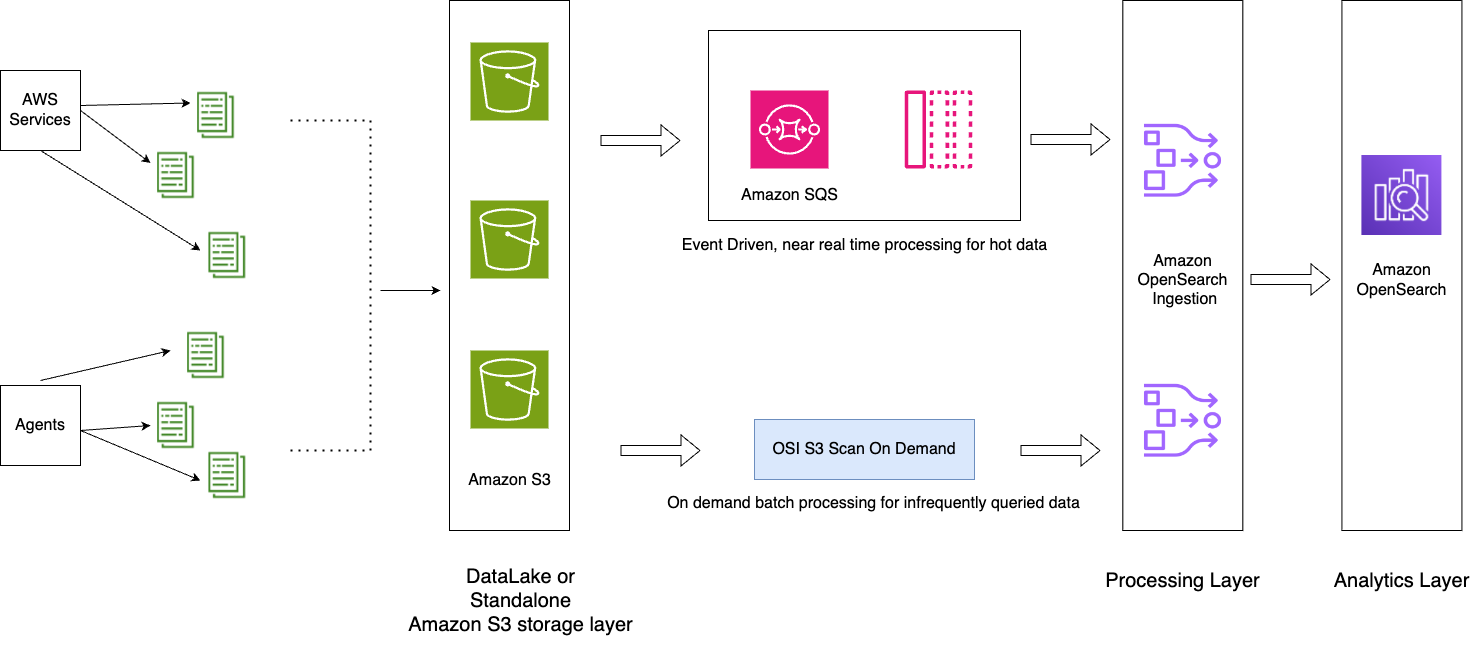
Arbetsflödet innehåller följande steg:
- Inkommande data som genereras av applikationerna strömmas till S3-datasjön.
- För den aktuella dagen matas data in i OpenSearch Service med hjälp av S3-SQS nästan realtidsintag genom aviseringar som ställs in i S3-segmenten.
- Dagliga index upprätthålls för enkel rollover. En ISM-policy automatiserar övergången eller raderingen av index som är äldre än 2 dagar.
- Om en begäran görs för analys av data efter 2 dagar och data inte finns i UltraWarm-nivån, kommer data att tas in med hjälp av engångsskanningsfunktionen i Amazon S3 mellan det specifika tidsfönstret.
Till exempel, om den nuvarande dagen är den 10 januari 2024 och du behöver data från den 6 januari 2024 vid ett specifikt intervall för analys, kan du skapa en OpenSearch Ingestion-pipeline med en Amazon S3-skanning i din YAML-konfiguration, med start_time och end_time för att ange när du vill att objekten i hinken ska skannas:
Överväganden
Dra fördel av kompression
Data i Amazon S3 kan komprimeras, vilket minskar ditt totala dataavtryck och resulterar i betydande kostnadsbesparingar. Om du till exempel genererar 15 PB rå JSON-applikationsloggar per månad kan du använda en komprimeringsmekanism som GZIP, som kan minska storleken till cirka 1 PB eller mindre, vilket resulterar i betydande kostnadsbesparingar.
Stoppa rörledningen när det är möjligt
OpenSearch Ingestion skalar automatiskt mellan lägsta och maximala OCU:er som är inställda för pipelinen. Efter att pipelinen har slutfört Amazon S3-skanningen under den angivna varaktigheten som nämns i pipelinekonfigurationen, fortsätter pipelinen att köras för kontinuerlig övervakning vid minsta OCU.
För on-demand-intag för tidigare tidsperioder där du inte förväntar dig att nya objekt ska skapas, överväg att använda pipelinemått som stöds som t.ex. recordsOut.count att skapa amazoncloudwatch larm som kan stoppa rörledningen. För en lista över mätvärden som stöds, se Övervakning av pipelinemått.
CloudWatch-larm utför en åtgärd när ett CloudWatch-mått överskrider ett angivet värde under en viss tid. Du kanske till exempel vill övervaka recordsOut.count att vara 0 i mer än 5 minuter för att initiera en begäran till stoppa rörledningen genom AWS-kommandoradsgränssnitt (AWS CLI) eller API.
Lösning 3: OpenSearch Service direkta frågor med Amazon S3
OpenSearch Service direkta frågor med Amazon S3 (förhandsgranskning) är ett nytt sätt att söka efter driftsloggar i Amazon S3- och S3-datasjöar utan att behöva växla mellan tjänster. Du kan nu analysera sällan efterfrågade data i molnobjektlager och samtidigt använda operationsanalys- och visualiseringsfunktionerna i OpenSearch Service.
OpenSearch Service erbjuder direkta frågor med Amazon S3 noll-ETL integration för att minska den operativa komplexiteten för att duplicera data eller hantera flera analysverktyg genom att göra det möjligt för dig att direkt söka efter dina operativa data, vilket minskar kostnader och tid till handling. Denna noll-ETL-integrering är konfigurerbar inom OpenSearch Service, där du kan dra fördel av olika loggtypsmallar, inklusive fördefinierade instrumentpaneler, och konfigurera dataaccelerationer skräddarsydda för den loggtypen. Mallar inkluderar VPC-flödesloggar, Elastisk belastningsbalansering loggar och NGINX-loggar, och accelerationer inkluderar överhoppningsindex, materialiserade vyer och täckta index.
Med OpenSearch Service direkta förfrågningar med Amazon S3 kan du utföra komplexa frågor som är avgörande för säkerhetsforskning och hotanalys och korrelera data över flera datakällor, vilket hjälper team att undersöka tjänstavbrott och säkerhetshändelser. När du har skapat en integration kan du börja söka efter dina data direkt från OpenSearch Dashboards eller OpenSearch API. Du kan granska anslutningar för att säkerställa att de ställs in på ett skalbart, kostnadseffektivt och säkert sätt.
Direkta frågor från OpenSearch Service till Amazon S3 använder Spark-tabeller i AWS-lim Datakatalog. Efter att tabellen har katalogiserats i din AWS Glue-metadatakatalog kan du köra frågor direkt på dina data i din S3-datasjö genom OpenSearch Dashboards.
Lösningsöversikt
Följande diagram illustrerar lösningsarkitekturen.
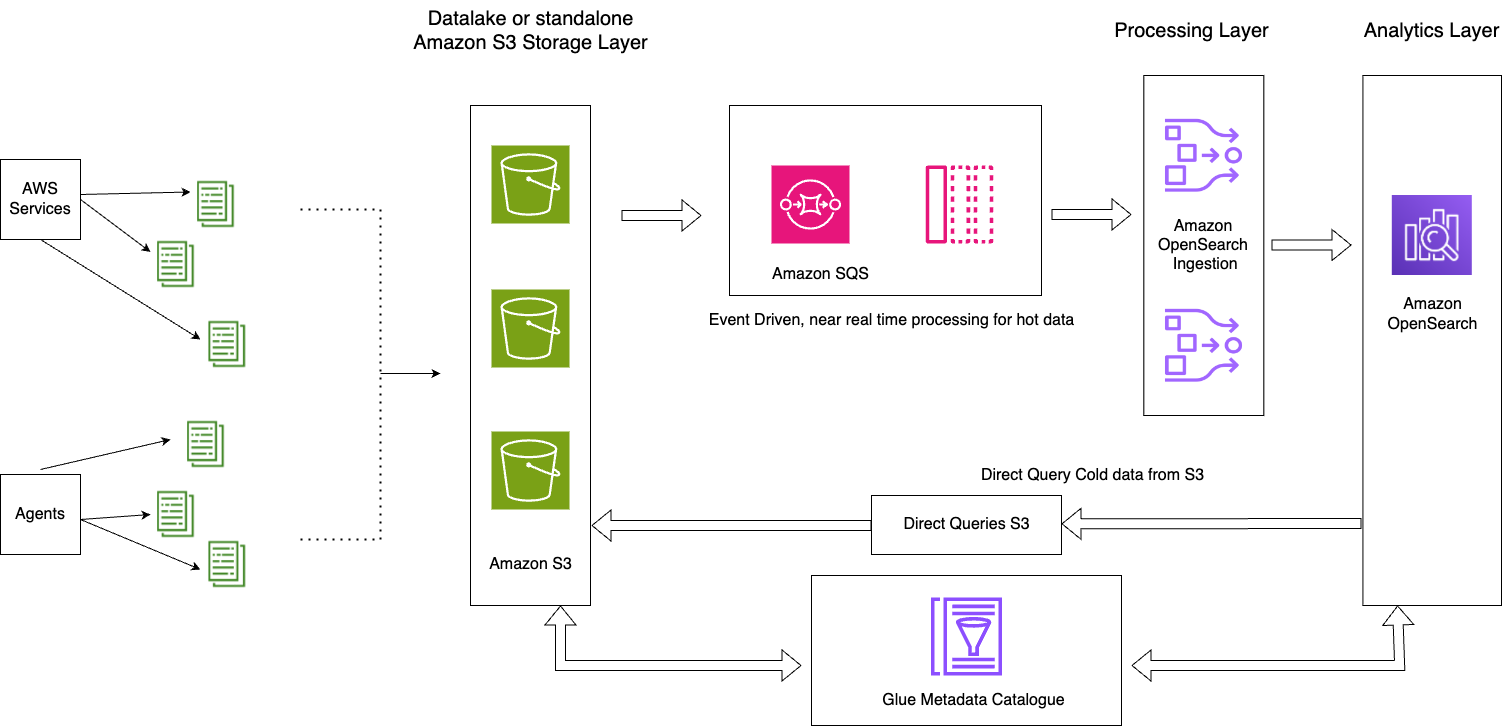
Denna lösning består av följande nyckelkomponenter:
- De heta data för den aktuella dagen strömbearbetas till OpenSearch Service-domäner genom det händelsedrivna arkitekturmönstret med OpenSearch Ingestion S3-SQS-behandlingsfunktionen
- Den heta datalivscykeln hanteras genom ISM-policyer kopplade till dagliga index
- Den kalla data finns i din Amazon S3-hink och är partitionerad och katalogiserad
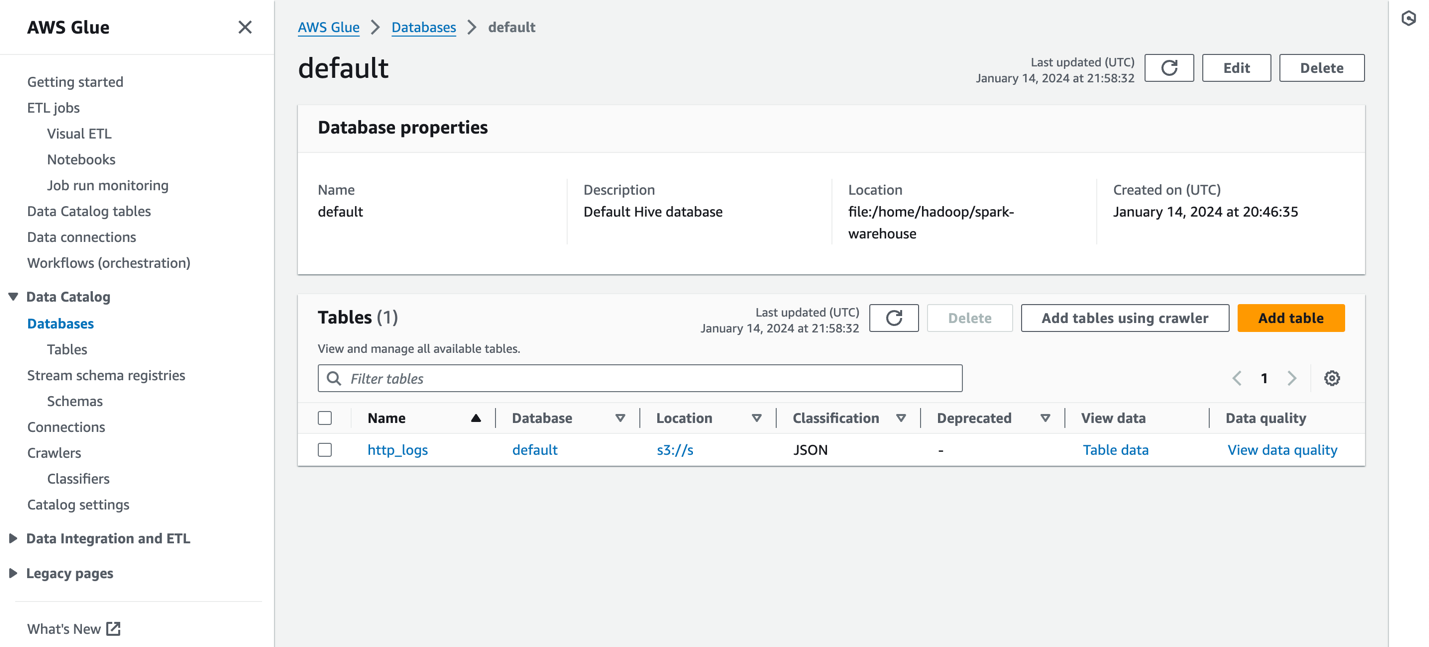
Följande skärmdump visar ett exempel http_logs tabell som är katalogiserad i AWS Glue-metadatakatalogen. För detaljerade steg, se Datakatalog och sökrobotar i AWS Glue.
Innan du skapar en datakälla bör du ha en OpenSearch Service-domän med version 2.11 eller senare och en måltabell för S3 i AWS Glue Data Catalog med lämplig AWS identitets- och åtkomsthantering (IAM) behörigheter. IAM kommer att behöva tillgång till önskade S3-hinkar och ha läs- och skrivåtkomst till AWS Glue Data Catalog. Följande är ett exempel på roll- och förtroendepolicy med lämpliga behörigheter för att komma åt AWS Glue Data Catalog via OpenSearch Service:
Följande är ett exempel på en anpassad policy med tillgång till Amazon S3 och AWS Glue:
För att skapa en ny datakälla på OpenSearch Service-konsolen, ange namnet på din nya datakälla, ange datakällans typ som Amazon S3 med AWS Glue Data Catalog, och välj IAM-rollen för din datakälla.
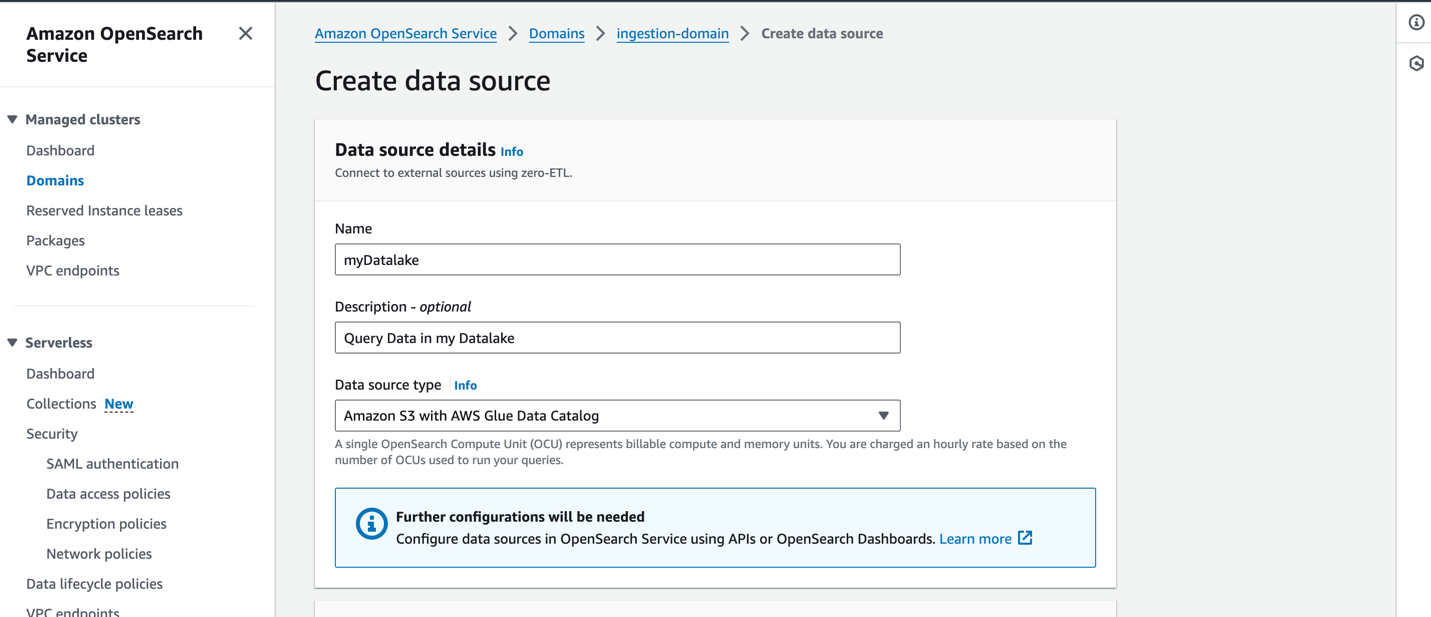
När du har skapat en datakälla kan du gå till OpenSearch-instrumentpanelen för domänen, som du använder för att konfigurera åtkomstkontroll, definiera tabeller, ställa in loggtypbaserade instrumentpaneler för populära loggtyper och fråga efter dina data.

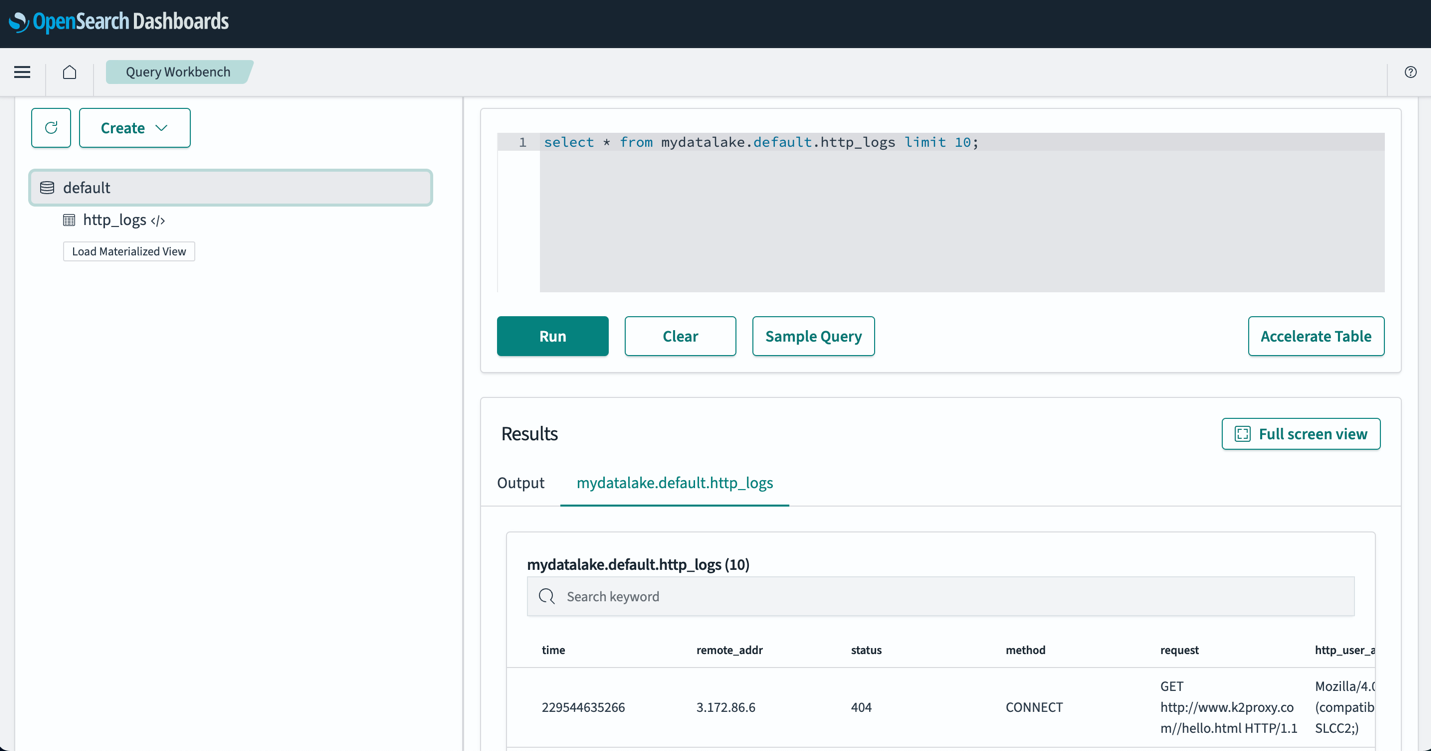
När du har ställt in dina tabeller kan du fråga efter dina data i din S3-datasjö via OpenSearch Dashboards. Du kan köra ett exempel på SQL-fråga för http_logs tabell som du skapade i AWS Glue Data Catalog-tabellerna, som visas i följande skärmdump.
Bästa praxis
Få bara in den data du behöver
Arbeta bakåt från dina affärsbehov och skapa rätt datauppsättningar du behöver. Utvärdera om du kan undvika att mata in bullriga data och bara mata in utvalda, samplade eller aggregerade data. Genom att använda dessa rensade och kurerade datauppsättningar hjälper du dig att optimera de beräknings- och lagringsresurser som behövs för att mata in dessa data.
Minska storleken på data före intag
När du designar dina pipelines för datainmatning, använd strategier som komprimering, filtrering och aggregering för att minska storleken på intagna data. Detta gör att mindre datastorlekar kan överföras över nätverket och lagras i ditt datalager.
Slutsats
I det här inlägget diskuterade vi lösningar som möjliggör petabyte-skala logganalys med OpenSearch Service i en modern dataarkitektur. Du lärde dig hur du skapar en serverlös inmatningspipeline för att leverera loggar till en OpenSearch Service-domän, hantera index genom ISM-policyer, konfigurera IAM-behörigheter för att börja använda OpenSearch Ingestion och skapa pipelinekonfigurationen för data i din datasjö. Du lärde dig också hur du ställer in och använder OpenSearch Service-direkta frågor med Amazon S3-funktionen (förhandsgranskning) för att söka efter data från din datasjö.
För att välja rätt arkitekturmönster för dina arbetsbelastningar när du använder OpenSearch Service i stor skala, överväg prestanda, latens, kostnad och datavolymtillväxt över tid för att fatta rätt beslut.
- Använd nivåbaserad lagringsarkitektur med Index State Management-policyer när du behöver snabb åtkomst till dina heta data och vill balansera kostnaden och prestanda med UltraWarm-noder för skrivskyddad data.
- Använd On Demand Ingestion av dina data i OpenSearch Service när du kan tolerera inmatningsfördröjningar för att fråga om dina data som inte finns kvar i dina heta noder. Du kan uppnå betydande kostnadsbesparingar när du använder komprimerad data i Amazon S3 och matar in data på begäran i OpenSearch Service.
- Använd Direct query med S3-funktionen när du direkt vill analysera dina driftsloggar i Amazon S3 med de rika analys- och visualiseringsfunktionerna i OpenSearch Service.
Som nästa steg, se Amazon OpenSearch Developer Guide för att utforska loggar och metriska pipelines som du kan använda för att bygga en skalbar observerbarhetslösning för dina företagsapplikationer.
Om författarna
 Jagadish Kumar (Jag) är en Senior Specialist Solutions Architect på AWS fokuserad på Amazon OpenSearch Service. Han brinner djupt för dataarkitektur och hjälper kunder att bygga analyslösningar i stor skala på AWS.
Jagadish Kumar (Jag) är en Senior Specialist Solutions Architect på AWS fokuserad på Amazon OpenSearch Service. Han brinner djupt för dataarkitektur och hjälper kunder att bygga analyslösningar i stor skala på AWS.
 Muthu Pitchaimani är en Senior Specialist Solutions Architect med Amazon OpenSearch Service. Han bygger storskaliga sökapplikationer och lösningar. Muthu är intresserad av ämnena nätverk och säkerhet och är baserad i Austin, Texas.
Muthu Pitchaimani är en Senior Specialist Solutions Architect med Amazon OpenSearch Service. Han bygger storskaliga sökapplikationer och lösningar. Muthu är intresserad av ämnena nätverk och säkerhet och är baserad i Austin, Texas.
 Sam Selvan är en Principal Specialist Solution Architect med Amazon OpenSearch Service.
Sam Selvan är en Principal Specialist Solution Architect med Amazon OpenSearch Service.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/petabyte-scale-log-analytics-with-amazon-s3-amazon-opensearch-service-and-amazon-opensearch-ingestion/

