
Beskrivning
Välkommen till vårt heltäckande dataanalys blogg som gräver djupt in i Netflix-världen. Som en av de ledande streamingplattformarna globalt har Netflix revolutionerat hur vi konsumerar underhållning. Med sitt stora bibliotek av filmer och TV-program erbjuder den ett överflöd av valmöjligheter för tittare runt om i världen.
Netflix Global Reach
Netflix har upplevt en anmärkningsvärd tillväxt och utökat sin närvaro till att bli en dominerande kraft inom streamingbranschen. Här är några anmärkningsvärda statistik som visar dess globala inverkan:
- Användarbas: I början av andra kvartalet 2022 hade Netflix samlats ungefär 222 miljoner internationella abonnenter, som spänner över 190 länder (exklusive Kina, Krim, Nordkorea, Ryssland och Syrien). Dessa imponerande siffror understryker plattformens utbredda acceptans och popularitet bland tittare över hela världen.
- Internationell expansion: Med sin tillgänglighet i över 190 länder har Netflix framgångsrikt etablerat en global närvaro. Företaget har gjort betydande ansträngningar för att lokalisera sitt innehåll genom att erbjuda undertexter och dubbning på olika språk, vilket säkerställer tillgänglighet för en mångfaldig publik.
I den här bloggen ger vi oss ut på en spännande resa för att utforska de spännande mönster, trender och insikter som är gömda i Netflix innehållslandskap. Utnyttja kraften i Python och dess dataanalys bibliotek, dyker vi in i den stora samlingen av Netflix erbjudanden för att avslöja värdefull information som belyser innehållstillägg, varaktighetsdistributioner, genrekorrelationer och till och med de vanligaste orden i titlar och beskrivningar.
Genom detaljerade kodavsnitt och visualiseringar, drar vi tillbaka lagren i Netflix innehållsekosystem för att ge ett nytt perspektiv på hur plattformen har utvecklats. Genom att analysera releasemönster, säsongstrender och publikpreferenser strävar vi efter att bättre förstå innehållsdynamiken i Netflix enorma universum.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Förberedelse av data
Datan som används i den här fallstudien kommer från Kaggle, en populär plattform för entusiaster inom datavetenskap och maskininlärning. Datauppsättningen, med titeln "Netflix filmer och TV-program,” är allmänt tillgänglig på Kaggle och ger värdefull information om filmer och TV-program på Netflix streamingplattform.
Datauppsättningen består av ett tabellformat som innehåller olika kolumner som beskriver de olika aspekterna av varje film eller TV-program. Här är en tabell som sammanfattar kolumnerna och deras beskrivningar:
| Kolumnnamn | Beskrivning |
|---|---|
| show_id | Unikt ID för varje film/tv-program |
| Typ | Identifierare – en film eller ett tv-program |
| rubricerade | Filmens/TV-programmets titel |
| direktör | Filmens regissör |
| gjutas | Skådespelare involverade i filmen/showen |
| land | Land där filmen/showen producerades |
| datum tillagt | Datum då den lades till på Netflix |
| utgivningsår | Faktiskt släppår för filmen/showen |
| betyg | TV-betyg av filmen/showen |
| varaktighet | Total varaktighet – i minuter eller antal säsonger |
I det här avsnittet kommer vi att utföra dataförberedande uppgifter på Netflix-datauppsättningen för att säkerställa dess renhet och lämplighet för analys. Vi kommer att hantera saknade värden och dubbletter och utföra datatypkonverteringar efter behov. Låt oss dyka in i koden och utforska varje steg.
Importerar bibliotek
Till att börja med importerar vi de nödvändiga biblioteken för dataanalys och visualisering. Dessa bibliotek inkluderar pandor, numpy och matplotlib. pyplot och sjöfödd. De tillhandahåller viktiga funktioner och verktyg för att manipulera och visualisera data effektivt.
# Importing necessary libraries for data analysis and visualization
import pandas as pd # pandas for data manipulation and analysis
import numpy as np # numpy for numerical operations
import matplotlib.pyplot as plt # matplotlib for data visualization
import seaborn as sns # seaborn for enhanced data visualizationLäser in datauppsättningen
Därefter laddar vi Netflix dataset med funktionen pd.read_csv() . Datauppsättningen lagras i filen 'netflix.csv'. Låt oss titta på de första fem posterna i datamängden för att förstå dess struktur.
# Loading the dataset from a CSV file
df = pd.read_csv('netflix.csv') # Displaying the first few rows of the dataset
df.head()Beskrivande statistik
Det är avgörande att förstå datasetets övergripande egenskaper genom beskrivande statistik. Vi kan få insikter i de numeriska attributen som antal, medelvärde, standardavvikelse, minimum, maximum och kvartiler.
# Computing descriptive statistics for the dataset
df.describe()Kortfattad sammanfattning
För att få en kortfattad sammanfattning av datamängden använder vi funktionen df.info(). Den ger information om antalet icke-nullvärden och datatyperna för varje kolumn. Den här sammanfattningen hjälper till att identifiera saknade värden och potentiella problem med datatyper.
# Obtaining information about the dataset
df.info()Hantera saknade värden
Saknade värden kan hindra korrekt analys. Denna datauppsättning utforskar de saknade värdena i varje kolumn med hjälp av df. isnull().sum(). Vi strävar efter att identifiera kolumnerna med saknade värden och bestämma procentandelen av saknad data i varje kolumn.
# Checking for missing values in the dataset
df.isnull().sum()För att hantera saknade värden använder vi olika strategier för olika kolumner. Låt oss gå igenom varje steg:
dubbletter
Dubbletter kan förvränga analysresultat, så det är viktigt att ta itu med dem. Vi identifierar och tar bort dubbletter av poster med df.duplicated().sum().
# Checking for duplicate rows in the dataset
df.duplicated().sum()Hantera saknade värden i specifika kolumner
För kolumnerna "regissör" och "cast" ersätter vi saknade värden med "Inga data" för att bibehålla dataintegriteten och undvika eventuella fördomar i analysen.
# Replacing missing values in the 'director' column with 'No Data'
df['director'].replace(np.nan, 'No Data', inplace=True) # Replacing missing values in the 'cast' column with 'No Data'
df['cast'].replace(np.nan, 'No Data', inplace=True)I kolumnen 'land' fyller vi i saknade värden med läget (det vanligaste värdet) för att säkerställa konsekvens och minimera dataförlust.
# Filling missing values in the 'country' column with the mode value
df['country'] = df['country'].fillna(df['country'].mode()[0])För kolumnen "betyg" fyller vi i saknade värden baserat på "typ" av programmet. Vi tilldelar läget för "betyg" för filmer och TV-program separat.
# Finding the mode rating for movies and TV shows
movie_rating = df.loc[df['type'] == 'Movie', 'rating'].mode()[0]
tv_rating = df.loc[df['type'] == 'TV Show', 'rating'].mode()[0] # Filling missing rating values based on the type of content
df['rating'] = df.apply(lambda x: movie_rating if x['type'] == 'Movie' and pd.isna(x['rating']) else tv_rating if x['type'] == 'TV Show' and pd.isna(x['rating']) else x['rating'], axis=1)För kolumnen "varaktighet" fyller vi i saknade värden baserat på "typ" av showen. Vi tilldelar läget för "varaktighet" för filmer och TV-program separat.
# Finding the mode duration for movies and TV shows
movie_duration_mode = df.loc[df['type'] == 'Movie', 'duration'].mode()[0]
tv_duration_mode = df.loc[df['type'] == 'TV Show', 'duration'].mode()[0] # Filling missing duration values based on the type of content
df['duration'] = df.apply(lambda x: movie_duration_mode if x['type'] == 'Movie' and pd.isna(x['duration']) else tv_duration_mode if x['type'] == 'TV Show' and pd.isna(x['duration']) else x['duration'], axis=1)Tappa kvarvarande saknade värden
Efter att ha hanterat saknade värden i specifika kolumner släpper vi alla återstående rader med saknade värden för att säkerställa en ren datauppsättning för analys.
# Dropping rows with missing values
df.dropna(inplace=True)Datumhantering
Vi konverterar kolumnen 'date_added' till datetime-format med pd.to_datetime() för att möjliggöra ytterligare analys baserat på datumrelaterade attribut.
# Converting the 'date_added' column to datetime format
df["date_added"] = pd.to_datetime(df['date_added'])Ytterligare datatransformationer
Vi extraherar ytterligare attribut från kolumnen 'date_added' för att förbättra våra analysmöjligheter. Vi tar bort värdena för månad och år för att analysera trender utifrån dessa tidsmässiga aspekter.
# Extracting month, month name, and year from the 'date_added' column
df['month_added'] = df['date_added'].dt.month
df['month_name_added'] = df['date_added'].dt.month_name()
df['year_added'] = df['date_added'].dt.yearDatatransformation: Skådespelare, Country, Listed In och Director
För att analysera kategoriska attribut mer effektivt, omvandlar vi dem till separata dataramar, vilket möjliggör mer lugn utforskning och analys.
För kolumnerna "cast", "country", "listed_in" och "director" delade vi upp värdena baserat på kommaavgränsaren och skapade separata rader för varje värde. Denna transformation gör det möjligt för oss att analysera data på en mer granulär nivå.
# Splitting and expanding the 'cast' column
df_cast = df['cast'].str.split(',', expand=True).stack()
df_cast = df_cast.reset_index(level=1, drop=True).to_frame('cast')
df_cast['show_id'] = df['show_id'] # Splitting and expanding the 'country' column
df_country = df['country'].str.split(',', expand=True).stack()
df_country = df_country.reset_index(level=1, drop=True).to_frame('country')
df_country['show_id'] = df['show_id'] # Splitting and expanding the 'listed_in' column
df_listed_in = df['listed_in'].str.split(',', expand=True).stack()
df_listed_in = df_listed_in.reset_index(level=1, drop=True).to_frame('listed_in')
df_listed_in['show_id'] = df['show_id'] # Splitting and expanding the 'director' column
df_director = df['director'].str.split(',', expand=True).stack()
df_director = df_director.reset_index(level=1, drop=True).to_frame('director')
df_director['show_id'] = df['show_id']Efter att ha slutfört dessa dataförberedande steg har vi en ren och transformerad datauppsättning redo för vidare analys. Dessa initiala datamanipulationer lägger grunden för att utforska Netflix-datauppsättningen och avslöja insikter i streamingplattformens datadrivna strategier.
Utforskande dataanalys
Distribution av innehållstyper
För att bestämma distributionen av innehåll i Netflix-biblioteket kan vi beräkna den procentuella fördelningen av innehållstyper (filmer och TV-program) med hjälp av följande kod:
# Calculate the percentage distribution of content types
x = df.groupby(['type'])['type'].count()
y = len(df)
r = ((x/y) * 100).round(2) # Create a DataFrame to store the percentage distribution
mf_ratio = pd.DataFrame(r)
mf_ratio.rename({'type': '%'}, axis=1, inplace=True) # Plot the 3D-effect pie chart
plt.figure(figsize=(12, 8))
colors = ['#b20710', '#221f1f']
explode = (0.1, 0)
plt.pie(mf_ratio['%'], labels=mf_ratio.index, autopct='%1.1f%%', colors=colors, explode=explode, shadow=True, startangle=90, textprops={'color': 'white'}) plt.legend(loc='upper right')
plt.title('Distribution of Content Types')
plt.show()
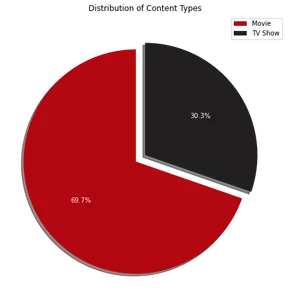
Cirkeldiagramvisualiseringen visar att cirka 70 % av innehållet på Netflix består av film, medan resterande 30 % är TV-program. Därefter, för att identifiera de 10 bästa länderna där Netflix är populärt, kan vi använda följande kod:
Topp 10 länder där Netflix är populärt
Därefter, för att identifiera de 10 bästa länderna där Netflix är populärt, kan vi använda följande kod:
# Remove white spaces from 'country' column
df_country['country'] = df_country['country'].str.rstrip() # Find value counts
country_counts = df_country['country'].value_counts() # Select the top 10 countries
top_10_countries = country_counts.head(10) # Plot the top 10 countries
plt.figure(figsize=(16, 10))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_countries) - 1)
bar_plot = sns.barplot(x=top_10_countries.index, y=top_10_countries.values, palette=colors) plt.xlabel('Country')
plt.ylabel('Number of Titles')
plt.title('Top 10 Countries Where Netflix is Popular') # Add count values on top of each bar
for index, value in enumerate(top_10_countries.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()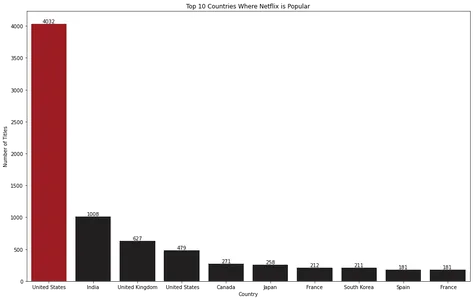
Stapeldiagramvisualiseringen avslöjar att USA är det bästa landet där Netflix är populärt.
Topp 10 skådespelare efter film/tv-program
För att identifiera de 10 bästa skådespelarna med det högsta antalet framträdanden i filmer och TV-program kan du använda följande kod:
# Count the occurrences of each actor
cast_counts = df_cast['cast'].value_counts()[1:] # Select the top 10 actors
top_10_cast = cast_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_cast) - 1)
bar_plot = sns.barplot(x=top_10_cast.index, y=top_10_cast.values, palette=colors) plt.xlabel('Actor')
plt.ylabel('Number of Appearances')
plt.title('Top 10 Actors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_cast.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()
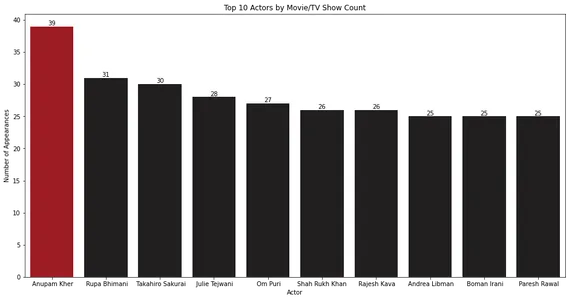
Stapeldiagrammet visar att Anupam Kher har flest framträdanden i filmer och TV-program.
Topp 10 regissörer efter film/tv-program
För att identifiera de 10 bästa regissörerna som har regisserat flest filmer eller tv-program kan du använda följande kod:
# Count the occurrences of each actor
director_counts = df_director['director'].value_counts()[1:] # Select the top 10 actors
top_10_directors = director_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_directors) - 1)
bar_plot = sns.barplot(x=top_10_directors.index, y=top_10_directors.values, palette=colors) plt.xlabel('Director')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Directors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_directors.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()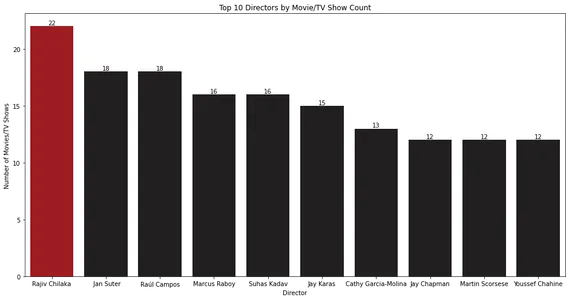
Stapeldiagrammet visar de 10 bästa regissörerna med flest filmer eller TV-program. Rajiv Chilaka verkar ha regisserat mest innehåll i Netflix-biblioteket.
Topp 10 kategorier efter film/tv-program
För att analysera distributionen av innehåll i olika kategorier kan du använda följande kod:
df_listed_in['listed_in'] = df_listed_in['listed_in'].str.strip() # Count the occurrences of each actor
listed_in_counts = df_listed_in['listed_in'].value_counts() # Select the top 10 actors
top_10_listed_in = listed_in_counts.head(10) plt.figure(figsize=(12, 8))
bar_plot = sns.barplot(x=top_10_listed_in.index, y=top_10_listed_in.values, palette=colors) # Customize the plot
plt.xlabel('Category')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Categories by Movie/TV Show Count')
plt.xticks(rotation=45) # Add count values on top of each bar
for index, value in enumerate(top_10_listed_in.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Show the plot
plt.show()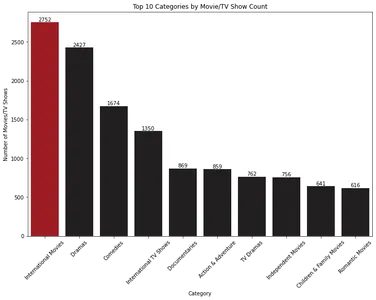
Stapeldiagrammet visar de 10 bästa kategorierna av filmer och TV-program baserat på deras antal. "Internationella filmer" är den mest dominerande kategorin, följt av "drama".
Filmer och TV-program har lagts till med tiden
För att analysera tillägget av filmer och TV-program över tid kan du använda följande kod:
# Filter the DataFrame to include only Movies and TV Shows
df_movies = df[df['type'] == 'Movie']
df_tv_shows = df[df['type'] == 'TV Show'] # Group the data by year and count the number of Movies and TV Shows # added in each year
movies_count = df_movies['year_added'].value_counts().sort_index()
tv_shows_count = df_tv_shows['year_added'].value_counts().sort_index() # Create a line chart to visualize the trends over time
plt.figure(figsize=(16, 8))
plt.plot(movies_count.index, movies_count.values, color='#b20710', label='Movies', linewidth=2)
plt.plot(tv_shows_count.index, tv_shows_count.values, color='#221f1f', label='TV Shows', linewidth=2) # Fill the area under the line charts
plt.fill_between(movies_count.index, movies_count.values, color='#b20710')
plt.fill_between(tv_shows_count.index, tv_shows_count.values, color='#221f1f') # Customize the plot
plt.xlabel('Year')
plt.ylabel('Count')
plt.title('Movies & TV Shows Added Over Time')
plt.legend() # Show the plot
plt.show()
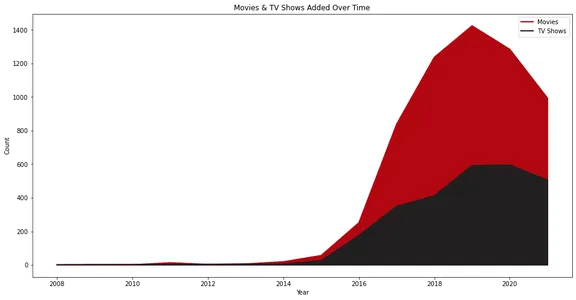
Linjediagrammet illustrerar antalet filmer och TV-program som lagts till Netflix över tiden. Den representerar visuellt tillväxten och trenderna i innehållstillägg, med separata rader för filmer och TV-program.
Netflix såg sin verkliga tillväxt från och med år 2015, och vi kan se att det lagt till fler filmer än TV-program under åren.
Det är också intressant att innehållstillägget sjönk 2020. Detta kan bero på pandemisituationen.
Därefter utforskar vi fördelningen av innehållstillägg över olika månader. Denna analys hjälper oss att identifiera mönster och förstå när Netflix introducerar nytt innehåll.
Innehåll tillagt per månad
För att undersöka detta extraherar vi månaden från kolumnen 'date_added' och räknar varje månads förekomster. Genom att visualisera dessa data som ett stapeldiagram kan vi snabbt identifiera månaderna med de högsta innehållstilläggen.
# Extract the month from the 'date_added' column
df['month_added'] = pd.to_datetime(df['date_added']).dt.month_name() # Define the order of the months
month_order = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'] # Count the number of shows added in each month
monthly_counts = df['month_added'].value_counts().loc[month_order] # Determine the maximum count
max_count = monthly_counts.max() # Set the color for the highest bar and the rest of the bars
colors = ['#b20710' if count == max_count else '#221f1f' for count in monthly_counts] # Create the bar chart
plt.figure(figsize=(16, 8))
bar_plot = sns.barplot(x=monthly_counts.index, y=monthly_counts.values, palette=colors) # Customize the plot
plt.xlabel('Month')
plt.ylabel('Count')
plt.title('Content Added by Month') # Add count values on top of each bar
for index, value in enumerate(monthly_counts.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()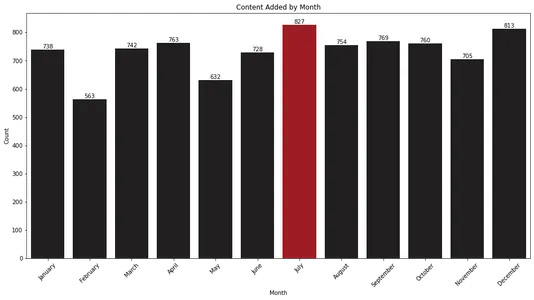
Stapeldiagrammet visar att juli och december är de månader då Netflix lägger till mest innehåll i sitt bibliotek. Denna information kan vara värdefull för tittare som vill förutse nya släpp under dessa månader.
En annan avgörande aspekt av Netflix innehållsanalys är att förstå fördelningen av betyg. Genom att undersöka antalet av varje klassificeringskategori kan vi fastställa de vanligaste typerna av innehåll på plattformen.
Fördelning av betyg
Vi börjar med att beräkna förekomsten av varje klassificeringskategori och visualiserar dem med hjälp av ett stapeldiagram. Denna visualisering ger en tydlig överblick över fördelningen av betyg.
# Count the occurrences of each rating
rating_counts = df['rating'].value_counts() # Create a bar chart to visualize the ratings
plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(rating_counts) - 1)
sns.barplot(x=rating_counts.index, y=rating_counts.values, palette=colors) # Customize the plot
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('Distribution of Ratings') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()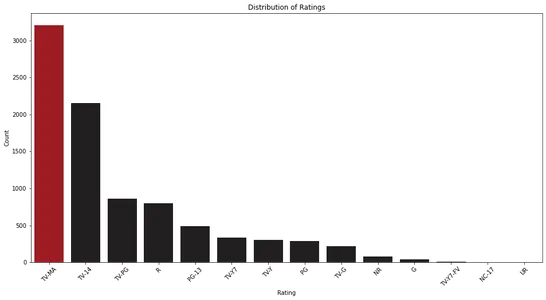
När vi analyserar stapeldiagrammet kan vi observera fördelningen av betyg på Netflix. Det hjälper oss att identifiera de vanligaste klassificeringskategorierna och deras relativa frekvens.
Genre Correlation Heatmap
Genrer spelar en viktig roll för att kategorisera och organisera innehåll på Netflix. Att analysera sambandet mellan genrer kan avslöja intressanta samband mellan olika typer av innehåll.
Vi skapar en genredata DataFrame för att undersöka genrekorrelation och fylla den med nollor. Genom att iterera över varje rad i den ursprungliga DataFrame uppdaterar vi genredata DataFrame baserat på de listade genrerna. Vi skapar sedan en korrelationsmatris med hjälp av denna genredata och visualiserar den som en värmekarta.
# Extracting unique genres from the 'listed_in' column
genres = df['listed_in'].str.split(', ', expand=True).stack().unique() # Create a new DataFrame to store the genre data
genre_data = pd.DataFrame(index=genres, columns=genres, dtype=float) # Fill the genre data DataFrame with zeros
genre_data.fillna(0, inplace=True) # Iterate over each row in the original DataFrame and update the genre data DataFrame
for _, row in df.iterrows(): listed_in = row['listed_in'].split(', ') for genre1 in listed_in: for genre2 in listed_in: genre_data.at[genre1, genre2] += 1 # Create a correlation matrix using the genre data
correlation_matrix = genre_data.corr() # Create the heatmap
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm') # Customize the plot
plt.title('Genre Correlation Heatmap')
plt.xticks(rotation=90)
plt.yticks(rotation=0) # Show the plot
plt.show()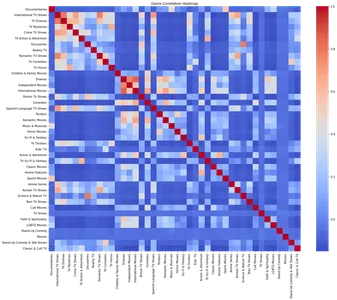
Värmekartan visar sambandet mellan olika genrer. Genom att analysera värmekartan kan vi identifiera starka positiva samband mellan specifika genrer, såsom TV-drama och internationella TV-program, romantiska TV-program och internationella TV-program.
Fördelning av filmlängder och antal avsnitt av tv-program
Att förstå varaktigheten för filmer och tv-program ger insikter om innehållets längd och hjälper tittarna att planera sin visningstid. Genom att undersöka fördelningen av filmlängder och tv-programlängder kan vi bättre förstå innehållet som är tillgängligt på Netflix.
För att uppnå detta extraherar vi filmlängderna och avsnittet av tv-program räknas från kolumnen "varaktighet". Vi plottar sedan histogram och boxplots för att visualisera fördelningen av filmlängder och TV-programlängder.
# Extract the movie lengths and TV show episode counts
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Plot the histogram
plt.figure(figsize=(10, 6))
plt.hist(movie_lengths, bins=10, color='#b20710', label='Movies')
plt.hist(tv_show_episodes, bins=10, color='#221f1f', label='TV Shows') # Customize the plot
plt.xlabel('Duration/Episode Count')
plt.ylabel('Frequency')
plt.title('Distribution of Movie Lengths and TV Show Episode Counts')
plt.legend() # Show the plot
plt.show()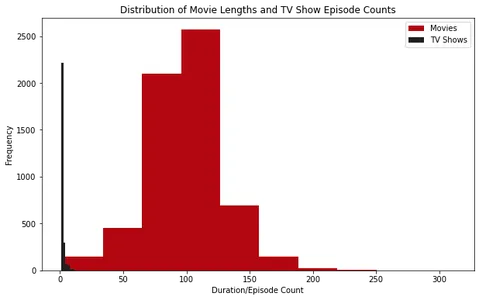
Genom att analysera histogrammen kan vi observera att de flesta filmer på Netflix har en varaktighet på cirka 100 minuter. Å andra sidan har de flesta TV-program på Netflix bara en säsong.
Dessutom, genom att undersöka boxplotterna, kan vi se att filmer som är längre än cirka 2.5 timmar anses vara extrema. För tv-program är det ovanligt att hitta de med fler än fyra säsonger.
Trenden för film-/tv-programlängder genom åren
Vi kan rita linjediagram för att förstå hur filmlängder och antalet avsnitt av TV-program har utvecklats under åren. Identifiera mönster eller förändringar i innehållets varaktighet genom att analysera dessa trender.
Vi börjar med att extrahera filmlängderna och antalet avsnitt av TV-program från kolumnen "varaktighet". Sedan skapar vi linjediagram för att visualisera förändringarna i filmlängder och tv-programavsnitt genom åren.
import seaborn as sns
import matplotlib.pyplot as plt # Extract the movie lengths and TV show episodes from the 'duration' column
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Create line plots for movie lengths and TV show episodes
plt.figure(figsize=(16, 8)) plt.subplot(2, 1, 1)
sns.lineplot(data=df_movies, x='release_year', y=movie_lengths, color=colors[0])
plt.xlabel('Release Year')
plt.ylabel('Movie Length')
plt.title('Trend of Movie Lengths Over the Years') plt.subplot(2, 1, 2)
sns.lineplot(data=df_tv_shows, x='release_year', y=tv_show_episodes,color=colors[1])
plt.xlabel('Release Year')
plt.ylabel('TV Show Episodes')
plt.title('Trend of TV Show Episodes Over the Years') # Adjust the layout and spacing
plt.tight_layout() # Show the plots
plt.show()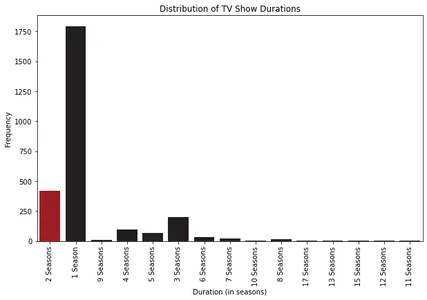
Genom att analysera linjediagrammen observerar vi spännande mönster. Vi kan se att filmens längd initialt ökade fram till omkring 1963-1964 och sedan gradvis sjönk, och stabiliserades runt i genomsnitt 100 minuter. Detta tyder på en förändring i publikpreferenser över tid.
När det gäller avsnitt av tv-program har vi märkt en konsekvent trend sedan början av 2000-talet, där de flesta tv-program på Netflix har en till tre säsonger. Detta indikerar en preferens för kortare serier eller begränsade serieformat bland tittare.
De vanligaste orden i titlar och beskrivningar
Att analysera de vanligaste orden som används i titlar och beskrivningar kan ge insikter i teman och innehållsfokus på Netflix. Vi kan generera ordmoln för att avslöja dessa mönster baserat på titlar och beskrivningar av Netflix innehåll.
from wordcloud import WordCloud # Concatenate all the titles into a single string
text = ' '.join(df['title']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show() # Concatenate all the titles into a single string
text = ' '.join(df['description']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show()
När vi undersöker ordmolnet för titlar, observerar vi att termer som "Kärlek", "Flicka", "Man", "Life" och "World" används ofta, vilket indikerar närvaron av romantik, blivande ålder och drama genrer i Netflix innehållsbibliotek.
När vi analyserar ordmolnet för beskrivningar lägger vi märke till dominerande ord som "liv", "hitta" och "familj", som föreslår teman för personliga resor, relationer och familjedynamik som är vanliga i Netflix innehåll.
Varaktighet Distribution för filmer och TV-program
Genom att analysera varaktigheten för filmer och TV-program kan vi förstå den typiska längden på innehåll som är tillgängligt på Netflix. Vi kan skapa boxplots för att visualisera dessa distributioner och identifiera extremvärden eller standardvaraktigheter.
# Extracting and converting the duration for movies
df_movies['duration'] = df_movies['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for movie duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_movies, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for Movies')
plt.show() # Extracting and converting the duration for TV shows
df_tv_shows['duration'] = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for TV show duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_tv_shows, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for TV Shows')
plt.show()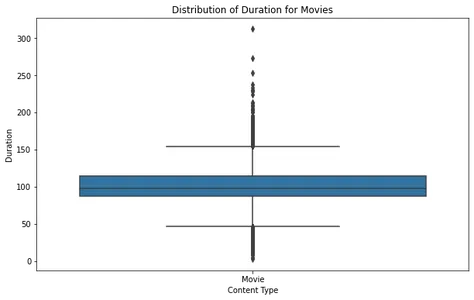
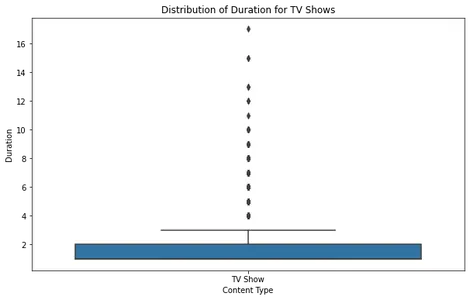
Genom att analysera filmboxens handling kan vi se att de flesta filmer faller inom ett rimligt varaktighetsområde, med få extremvärden som överstiger cirka 2.5 timmar. Detta tyder på att de flesta filmer på Netflix är designade för att passa inom en vanlig visningstid.
För tv-program avslöjar boxplotten att de flesta program har en till fyra säsonger, med väldigt få extremvärden som har längre varaktighet. Detta är i linje med de tidigare trenderna, vilket indikerar att Netflix fokuserar på kortare serieformat.
Slutsats
Med hjälp av denna artikel har vi kunnat lära oss om-
- Kvantitet: Vår analys avslöjade att Netflix hade lagt till fler filmer än TV-program, i linje med förväntningarna att filmer dominerar deras innehållsbibliotek.
- Innehållstillägg: Juli blev den månad då Netflix lägger till mest innehåll, tätt följt av december, vilket indikerar ett strategiskt tillvägagångssätt för innehållssläpp.
- Genrekorrelation: Starka positiva samband observerades mellan olika genrer, såsom TV-dramer och internationella TV-program, romantiska och internationella TV-program, och oberoende filmer och dramer. Dessa korrelationer ger insikter i tittarpreferenser och innehållssammankopplingar.
- Filmlängder: Analysen av filmens varaktighet visade på en topp runt 1960-talet, följt av en stabilisering runt 100 minuter, vilket framhävde en trend i filmlängder över tid.
- TV-programavsnitt: De flesta TV-program på Netflix har en säsong, vilket tyder på att tittarna föredrar kortare serier.
- Vanliga teman: Ord som kärlek, liv, familj och äventyr återfanns ofta i titlar och beskrivningar, och fångar återkommande teman i Netflix-innehåll.
- Betygsfördelning: Fördelningen av betyg under åren ger insikter i det föränderliga innehållslandskapet och publikens mottagande.
- Datadrivna insikter: Vår dataanalysresa visade upp kraften i data för att reda ut mysterierna i Netflix innehållslandskap, vilket gav värdefulla insikter för tittare och innehållsskapare.
- Fortsatt relevans: Allt eftersom streamingbranschen utvecklas, blir förståelsen av dessa mönster och trender allt viktigare för att navigera i det dynamiska landskapet hos Netflix och dess stora bibliotek.
- Happy Streaming: Vi hoppas att den här bloggen har varit en upplysande och underhållande resa in i Netflix-världen, och vi uppmuntrar dig att utforska de fängslande berättelserna i dess ständigt föränderliga innehållsutbud. Låt data styra dina streamingäventyr!
Officiell dokumentation och resurser
Nedan hittar du de officiella länkarna till de bibliotek som används i vår analys. Du kan hänvisa till dessa länkar för mer information om metoderna och funktionerna som tillhandahålls av dessa bibliotek:
- Pandor: https://pandas.pydata.org/
- NumPy: https://numpy.org/
- matplotlib: https://matplotlib.org/
- SciPy: https://scipy.org/
- Seaborn: https://seaborn.pydata.org/
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/06/netflix-case-study-eda-unveiling-data-driven-strategies-for-streaming/

