
Bild av författare
Mistral AI, ett av världens ledande AI-forskningsföretag, har nyligen släppt basmodellen för Mistral 7B v0.2.
Denna språkmodell med öppen källkod avslöjades under företagets hackathon-evenemang den 23 mars 2024.
Mistral 7B-modellerna har 7.3 miljarder parametrar, vilket gör dem extremt kraftfulla. De överträffar Llama 2 13B och Llama 1 34B på nästan alla benchmarks. Den senaste V0.2-modellen introducerar ett 32k kontextfönster bland andra framsteg, vilket förbättrar dess förmåga att bearbeta och generera text.
Dessutom är versionen som nyligen tillkännagavs basmodellen av den instruktionsinställda varianten, "Mistral-7B-Instruct-V0.2", som släpptes tidigare förra året.
I den här handledningen kommer jag att visa dig hur du kommer åt och finjusterar den här språkmodellen på Hugging Face.
Vi kommer att finjustera Mistral 7B-v0.2 basmodellen med Hugging Faces AutoTrain-funktion.
Kramande ansikte är känt för att demokratisera tillgången till maskininlärningsmodeller, vilket gör att vanliga användare kan utveckla avancerade AI-lösningar.
AutoTrain, en funktion i Hugging Face, automatiserar processen med modellträning, vilket gör den tillgänglig och effektiv.
Det hjälper användare att välja de bästa parametrarna och träningsteknikerna när de finjusterar modeller, vilket är en uppgift som annars kan vara skrämmande och tidskrävande.
Här är 5 steg för att finjustera din Mistral-7B-modell:
1. Sätta upp miljön
Du måste först skapa ett konto hos Hugging Face och sedan skapa ett modellförråd.
För att uppnå detta, följ helt enkelt stegen som anges i detta länk och kom tillbaka till denna handledning.
Vi kommer att träna modellen i Python. När det gäller att välja en bärbar datormiljö för träning kan du använda Kaggle Anteckningsböcker or Google Colab, som båda ger fri tillgång till GPU:er.
Om utbildningsprocessen tar för lång tid kanske du vill byta till en molnplattform som AWS Sagemaker eller Azure ML.
Slutligen, utför följande pip-installationer innan du börjar koda till den här handledningen:
!pip install -U autotrain-advanced
!pip install datasets transformers2. Förbereder din datauppsättning
I den här handledningen kommer vi att använda Alpaca dataset på Hugging Face, som ser ut så här:
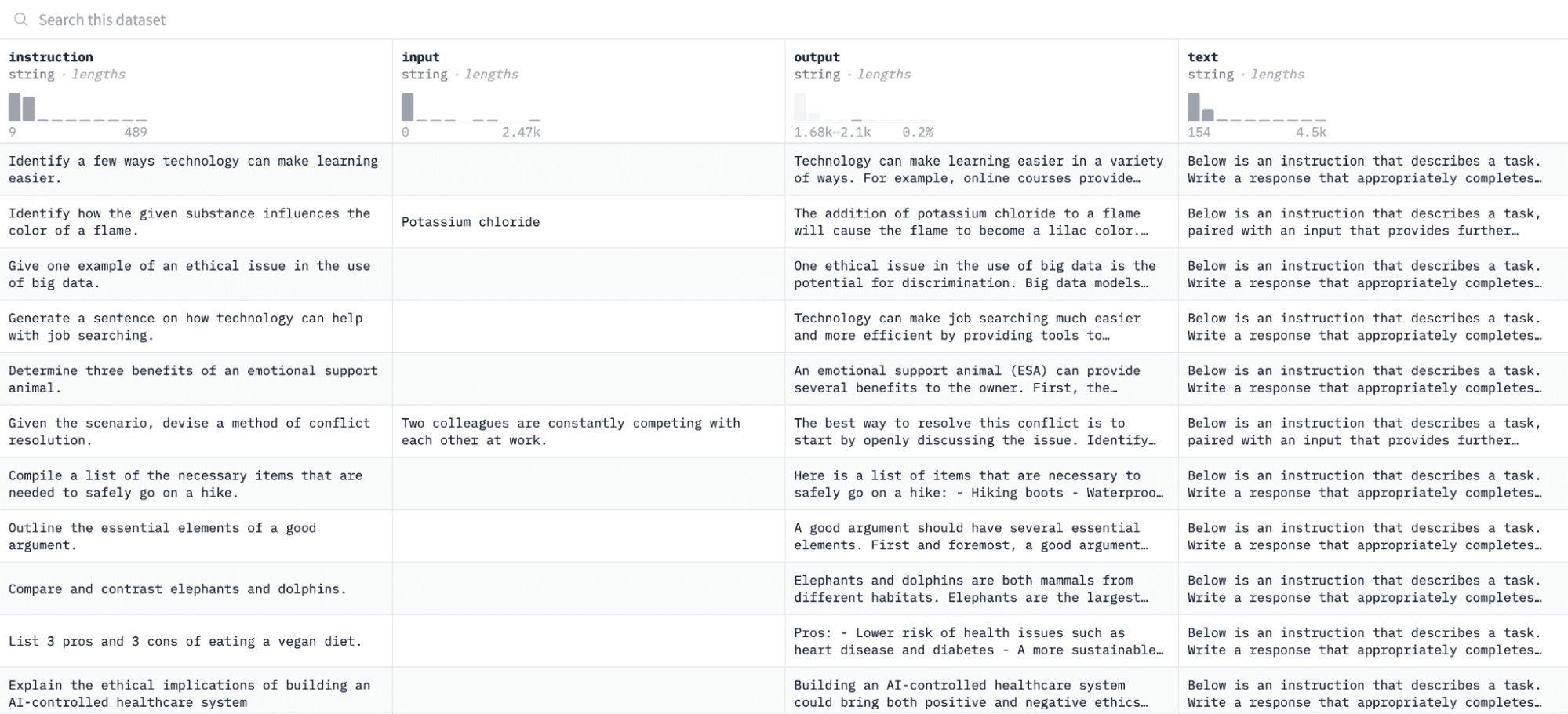
Vi kommer att finjustera modellen på par av instruktioner och utdata och bedöma dess förmåga att svara på den givna instruktionen i utvärderingsprocessen.
För att komma åt och förbereda denna datauppsättning, kör följande kodrader:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")Den första funktionen kommer att ladda Alpaca-datasetet med hjälp av "dataset"-biblioteket och rengöra det för att säkerställa att vi inte inkluderar några tomma instruktioner. Den andra funktionen strukturerar dina data i ett format som AutoTrain kan förstå.
Efter att ha kört ovanstående kod kommer datasetet att laddas, formateras och sparas i den angivna sökvägen. När du öppnar din formaterade datauppsättning bör du se en enda kolumn märkt "formaterad_text."
3. Ställa in din träningsmiljö
Nu när du framgångsrikt har förberett datamängden, låt oss fortsätta med att ställa in din modellträningsmiljö.
För att göra detta måste du definiera följande parametrar:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'Här är en uppdelning av ovanstående specifikationer:
- Du kan ange vilken som helst Projektnamn. Det är här alla dina projekt- och utbildningsfiler kommer att lagras.
- Smakämnen modellnamn parameter är modellen du vill finjustera. I det här fallet har jag angett en sökväg till Mistral-7B v0.2 basmodell på Hugging Face.
- Smakämnen hf_token variabel måste ställas in på din Hugging Face-token, som kan erhållas genom att navigera till denna länk.
- Din repo_id måste vara inställd på Hugging Face-modellförrådet som du skapade i det första steget i den här handledningen. Till exempel är mitt förvars-ID NatasshaS/Model2.
4. Konfigurera modellparametrar
Innan vi finjusterar vår modell måste vi definiera träningsparametrarna som styr aspekter av modellbeteende som träningslängd och regularisering.
Dessa parametrar påverkar nyckelaspekter som hur länge modellen tränar, hur den lär sig av data och hur den undviker överanpassning.
Du kan ställa in följande parametrar för din modell:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015. Ställa in miljövariabler
Låt oss nu förbereda vår träningsmiljö genom att ställa in några miljövariabler.
Detta steg säkerställer att AutoTrain-funktionen använder de önskade inställningarna för att finjustera modellen, såsom vårt projektnamn och träningsinställningar:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. Inled modellutbildning
Slutligen, låt oss börja träna modellen med hjälp av autotåg kommando. Det här steget innebär att du specificerar din modell, datauppsättning och träningskonfigurationer, som visas nedan:
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )Se till att ändra data-sökväg till var din träningsdatauppsättning finns.
7. Utvärdera modellen
När din modell har avslutat utbildningen bör du se en mapp visas i din katalog med samma titel som ditt projektnamn.
I mitt fall heter den här mappen "mistralai,” som visas på bilden nedan:
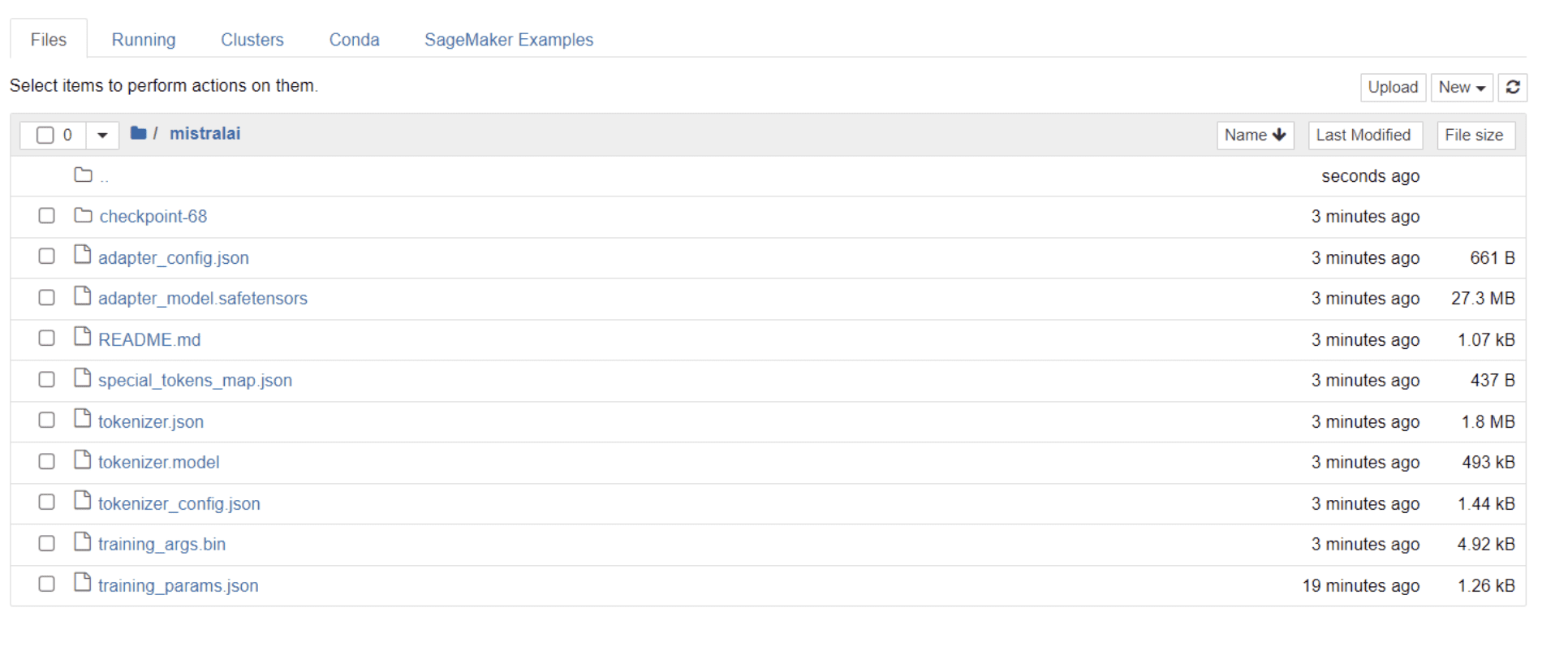
I den här mappen kan du hitta filer som omfattar dina modellvikter, hyperparametrar och arkitekturdetaljer.
Låt oss nu kontrollera om denna finjusterade modell kan svara korrekt på en fråga i vår datauppsättning. För att uppnå detta måste vi först köra följande kodrader för att generera 5 exempelingångar och utdata från vår datauppsättning:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")Du bör se ett svar som ser ut så här, som visar 5 exempeldatapunkter:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.Vi kommer att skriva in en av instruktionerna ovan i modellen och kontrollera om den genererar korrekt utdata. Här är en funktion för att ge en instruktion till modellen och få svar från den:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answerSlutligen, skriv in en fråga i den här funktionen som visas nedan:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)Din modell bör generera ett svar som är identiskt med dess motsvarande utdata i träningsdatauppsättningen, som visas nedan:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business andObservera att svaret kan verka ofullständigt eller avskuren på grund av antalet tokens vi har angett. Justera gärna "max_length"-värdet för att möjliggöra ett mer utökat svar.
Om du har kommit så långt, grattis!
Du har framgångsrikt finjusterat en toppmodern språkmodell och utnyttjat kraften i Mistral 7B v-0.2 tillsammans med Hugging Faces möjligheter.
Men resan slutar inte här.
Som nästa steg rekommenderar jag att du experimenterar med olika datauppsättningar eller justerar vissa träningsparametrar för att optimera modellens prestanda. Att finjustera modeller i större skala kommer att förbättra deras användbarhet, så försök experimentera med större datamängder eller olika format, som PDF-filer och textfiler.
Sådan erfarenhet blir ovärderlig när man arbetar med verklig data i organisationer, som ofta är rörig och ostrukturerad.
Natassha Selvaraj är en självlärd dataforskare med en passion för att skriva. Natassha skriver om allt datavetenskapsrelaterat, en sann mästare på alla dataämnen. Du kan få kontakt med henne LinkedIn eller kolla in henne YouTube-kanal.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

