Amazon Relational Database Service (Amazon RDS) för MySQL noll-ETL integration med Amazon RedShift var meddelade i förhandsvisning på AWS re:Invent 2023 för Amazon RDS för MySQL version 8.0.28 eller högre. I det här inlägget ger vi steg-för-steg-vägledning om hur du kommer igång med operationsanalyser i nästan realtid med den här funktionen. Det här inlägget är en fortsättning på noll-ETL-serien som började med Komma igång-guide för operationsanalys i nästan realtid med Amazon Aurora noll-ETL-integration med Amazon Redshift.
Utmaningar
Kunder inom olika branscher vill idag använda data till sin konkurrensfördel och öka intäkterna och kundernas engagemang genom att implementera analytiska användningsfall i nästan realtid som personaliseringsstrategier, bedrägeriupptäckt, lagerövervakning och många fler. Det finns två breda metoder för att analysera driftsdata för dessa användningsfall:
- Analysera data på plats i den operativa databasen (som läsrepliker, federerad fråga och analysacceleratorer)
- Flytta data till ett datalager som är optimerat för att köra användningsfallsspecifika frågor som ett datalager
Noll-ETL-integrationen är inriktad på att förenkla det senare tillvägagångssättet.
Processen att extrahera, transformera och ladda (ETL) har varit ett vanligt mönster för att flytta data från en operativ databas till ett analysdatalager. ELT är där den extraherade informationen laddas som den är i målet först och sedan transformeras. ETL- och ELT-pipelines kan vara dyra att bygga och komplexa att hantera. Med flera beröringspunkter kan intermittenta fel i ETL- och ELT-pipelines leda till långa förseningar, vilket lämnar datalagerapplikationer med inaktuella eller saknade data, vilket ytterligare leder till missade affärsmöjligheter.
Alternativt kan lösningar som analyserar data på plats fungera utmärkt för att accelerera frågor på en enda databas, men sådana lösningar kan inte samla data från flera operativa databaser för kunder som behöver köra enhetlig analys.
Noll-ETL
Till skillnad från de traditionella systemen där data lagras i en databas och användaren måste göra en avvägning mellan enhetlig analys och prestanda, kan dataingenjörer nu replikera data från flera RDS för MySQL-databaser till ett enda Redshift-datalager för att få holistiska insikter över många applikationer eller partitioner. Uppdateringar i transaktionsdatabaser sprids automatiskt och kontinuerligt till Amazon Redshift så att dataingenjörer har den senaste informationen i nästan realtid. Det finns ingen infrastruktur att hantera och integrationen kan automatiskt skalas upp och ner baserat på datavolymen.
På AWS har vi gjort stadiga framsteg mot att ta fram vår noll-ETL-vision till livet. Följande källor stöds för närvarande för noll-ETL-integrationer:
När du skapar en noll-ETL-integration för Amazon Redshift, fortsätter du att betala för underliggande källdatabas och målanvändning av Redshift-databas. Hänvisa till Noll-ETL integrationskostnader (förhandsgranskning) för mer information.
Med noll-ETL-integrering med Amazon Redshift, replikerar integrationen data från källdatabasen till måldatalagret. Datan blir tillgänglig i Amazon Redshift inom några sekunder, vilket gör att du kan använda analysfunktionerna i Amazon Redshift och funktioner som datadelning, autonomi för optimering av arbetsbelastning, skalning av samtidighet, maskininlärning och många fler. Du kan fortsätta med din transaktionsbearbetning på Amazon RDS eller Amazon-Aurora samtidigt som du använder Amazon Redshift för analytiska arbetsbelastningar som rapportering och instrumentpaneler.
Följande diagram illustrerar denna arkitektur.
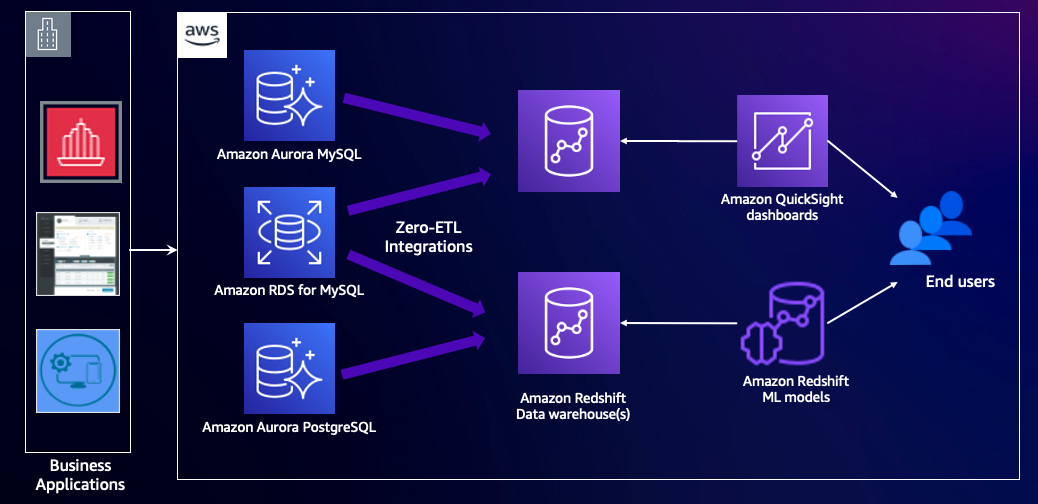
Lösningsöversikt
Låt oss överväga TICKIT, en fiktiv webbplats där användare köper och säljer biljetter online till sportevenemang, shower och konserter. Transaktionsdata från denna webbplats laddas in i en Amazon RDS för MySQL 8.0.28 (eller högre version) databas. Företagets affärsanalytiker vill generera statistik för att identifiera biljettrörelser över tid, framgångsfrekvenser för säljare och de bästsäljande evenemangen, arenor och säsonger. De skulle vilja få dessa mätvärden i nästan realtid med hjälp av en noll-ETL-integration.
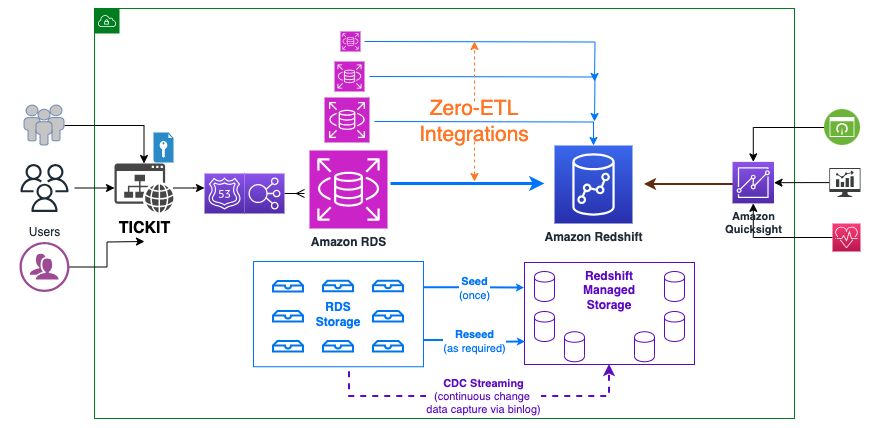
Integrationen är uppställd mellan Amazon RDS för MySQL (källa) och Amazon Redshift (destination). Transaktionsdata från källan uppdateras i nästan realtid på destinationen, som bearbetar analytiska frågor.
Du kan använda antingen det serverlösa alternativet eller ett krypterat RA3-kluster för Amazon Redshift. För det här inlägget använder vi en tillhandahållen RDS-databas och ett Redshift-förvaltat datalager.
Följande diagram illustrerar högnivåarkitekturen.
Följande är stegen som behövs för att ställa in noll-ETL-integration. Dessa steg kan göras automatiskt av noll-ETL-guiden, men du kommer att kräva en omstart om guiden ändrar inställningen för Amazon RDS eller Amazon Redshift. Du kan göra dessa steg manuellt, om det inte redan är konfigurerat, och utföra omstarterna när det passar dig. För de fullständiga kom-igång-guiderna, se Arbeta med Amazon RDS noll-ETL-integrationer med Amazon Redshift (förhandsgranskning) och Arbeta med noll-ETL-integrationer.
- Konfigurera RDS för MySQL-källan med en anpassad DB-parametergrupp.
- Konfigurera Redshift-klustret för att aktivera skiftlägeskänsliga identifierare.
- Konfigurera de nödvändiga behörigheterna.
- Skapa noll-ETL-integrationen.
- Skapa en databas från integrationen i Amazon Redshift.
Konfigurera RDS för MySQL-källan med en anpassad DB-parametergrupp
Utför följande steg för att skapa en RDS för MySQL-databas:
- På Amazon RDS-konsolen skapar du en DB-parametergrupp som heter
zero-etl-custom-pg.
Noll-ETL-integrering fungerar genom att använda binära loggar (binlogs) som genereras av MySQL-databasen. För att aktivera binlogs på Amazon RDS för MySQL måste en specifik uppsättning parametrar vara aktiverad.
- Ställ in följande binlog-klusterparameterinställningar:
binlog_format = ROWbinlog_row_image = FULLbinlog_checksum = NONE
Se dessutom till att binlog_row_value_options parametern är inte inställd på PARTIAL_JSON. Som standard är denna parameter inte inställd.
- Välja Databaser i navigeringsfönstret och välj sedan Skapa databas.
- För Motorversionväljer MySQL 8.0.28 (eller högre).

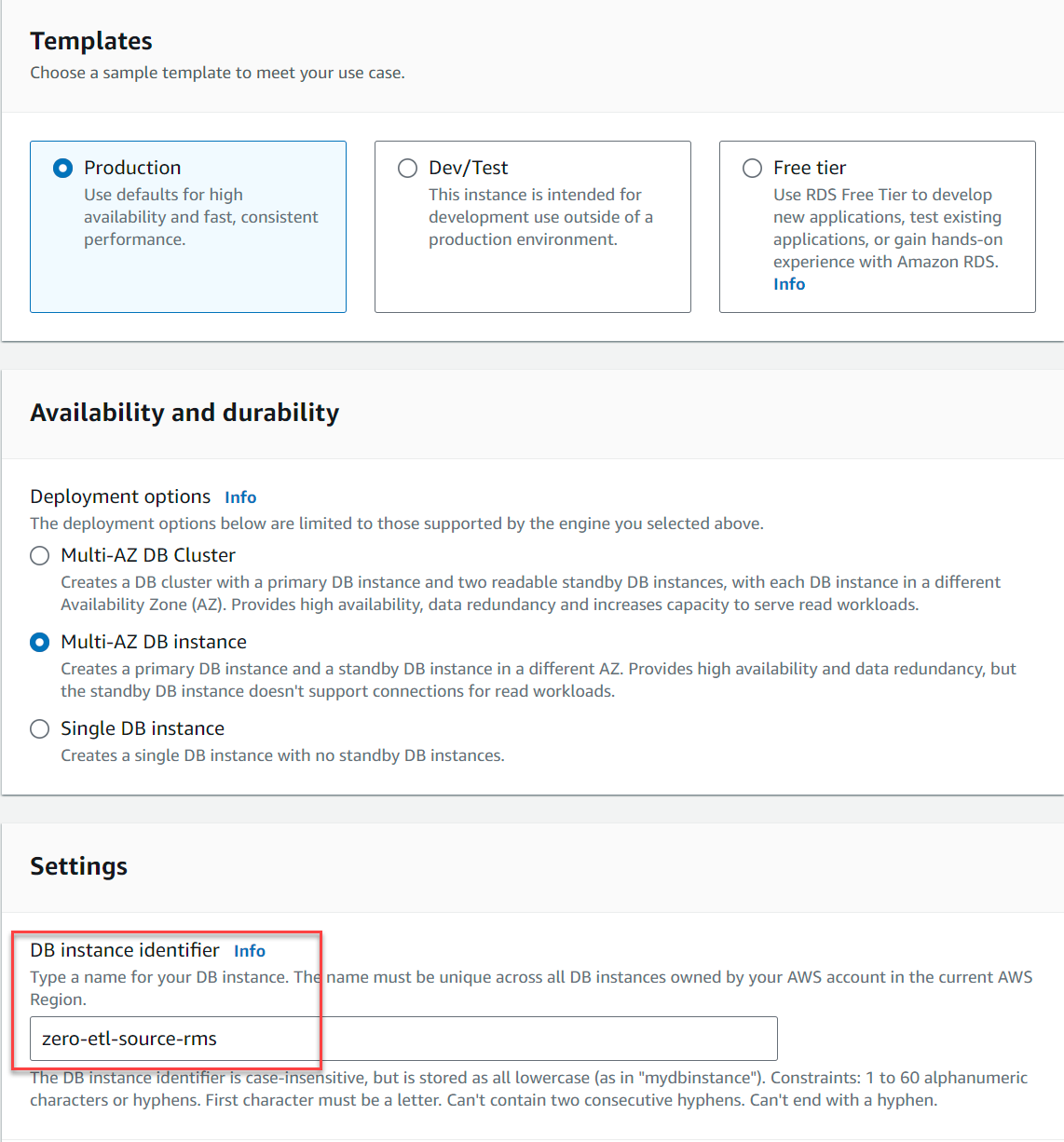
- För Mallar, Välj Produktion.
- För Tillgänglighet och hållbarhet, välj antingen Multi-AZ DB-instans or Enstaka DB-instans (Multi-AZ DB-kluster stöds inte, när detta skrivs).
- För DB-instansidentifierare, stiga på
zero-etl-source-rms.
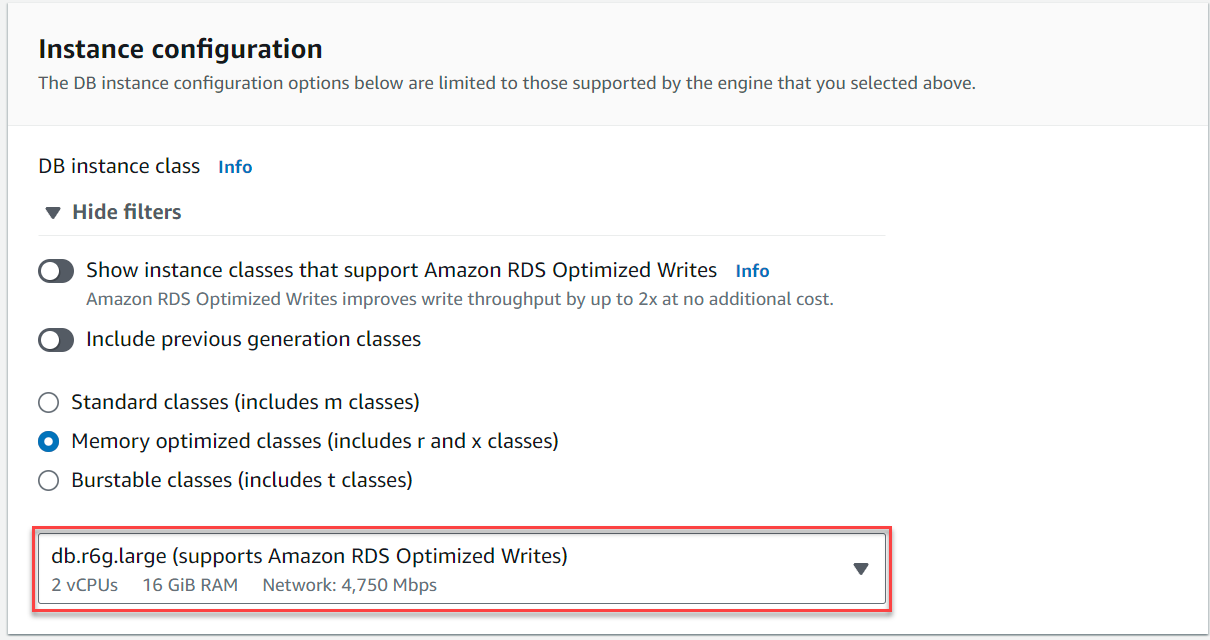
- Enligt Instanskonfiguration, Välj Minnesoptimerade klasser och välj instans
db.r6g.large, vilket borde vara tillräckligt för TICKIT användningsfall.
- Enligt Ytterligare konfiguration, För DB-klusterparametergrupp, välj parametergruppen du skapade tidigare (
zero-etl-custom-pg).
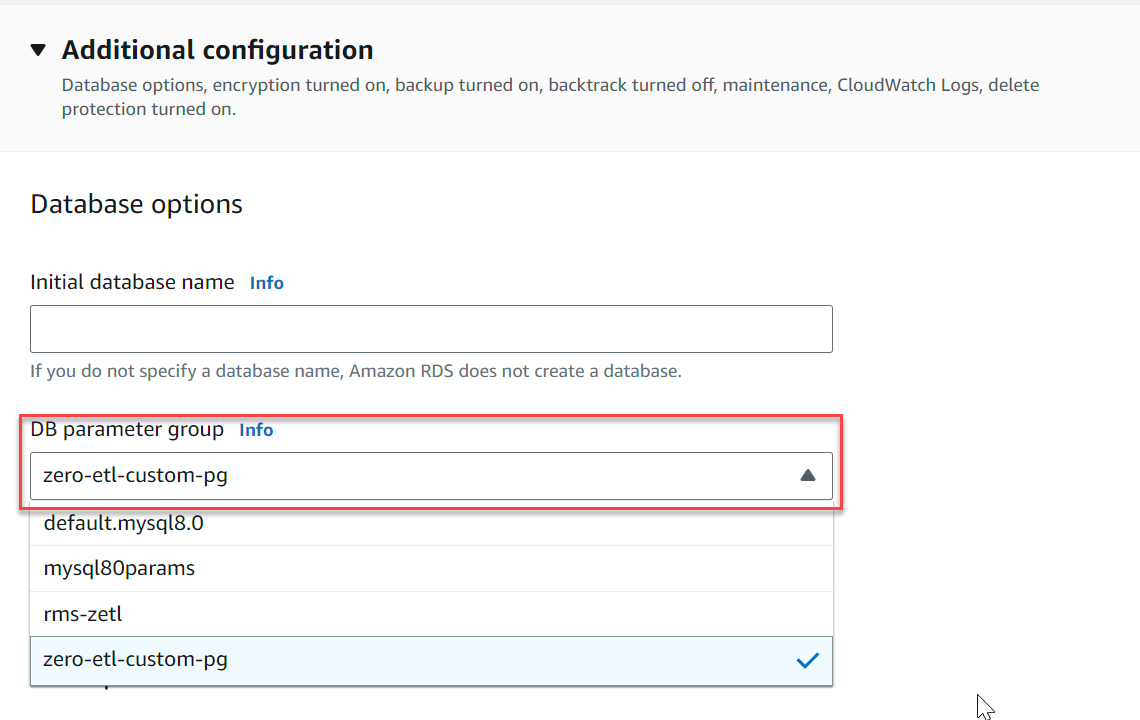
- Välja Skapa databas.
Inom ett par minuter bör det snurra upp en RDS för MySQL-databas som källan för noll-ETL-integration.
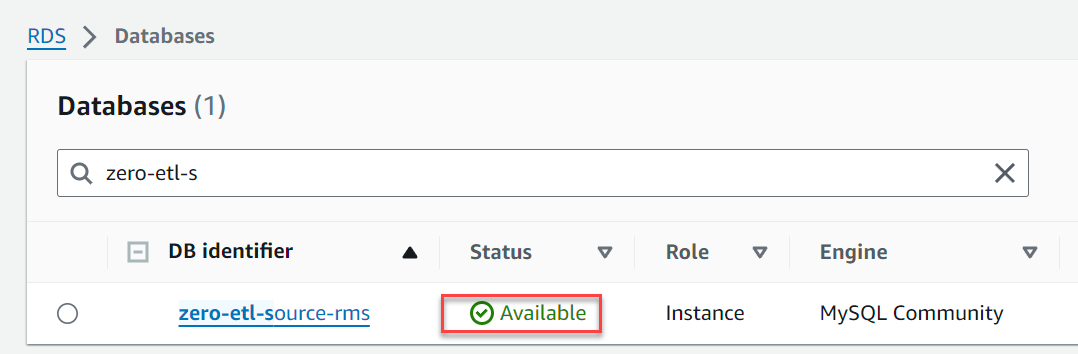
Konfigurera rödförskjutningsdestinationen
När du har skapat ditt källdatabaskluster måste du skapa och konfigurera ett måldatalager i Amazon Redshift. Datalagret måste uppfylla följande krav:
- Använda en RA3-nodtyp (
ra3.16xlarge,ra3.4xlarge, ellerra3.xlplus) Eller Amazon Redshift Serverlös - Krypterad (om du använder ett tillhandahållet kluster)
För vårt användningsfall, skapa ett Redshift-kluster genom att slutföra följande steg:
- Välj på Amazon Redshift-konsolen konfigurationer och välj sedan Arbetsbelastningshantering.
- Välj i avsnittet parametergrupp Skapa.
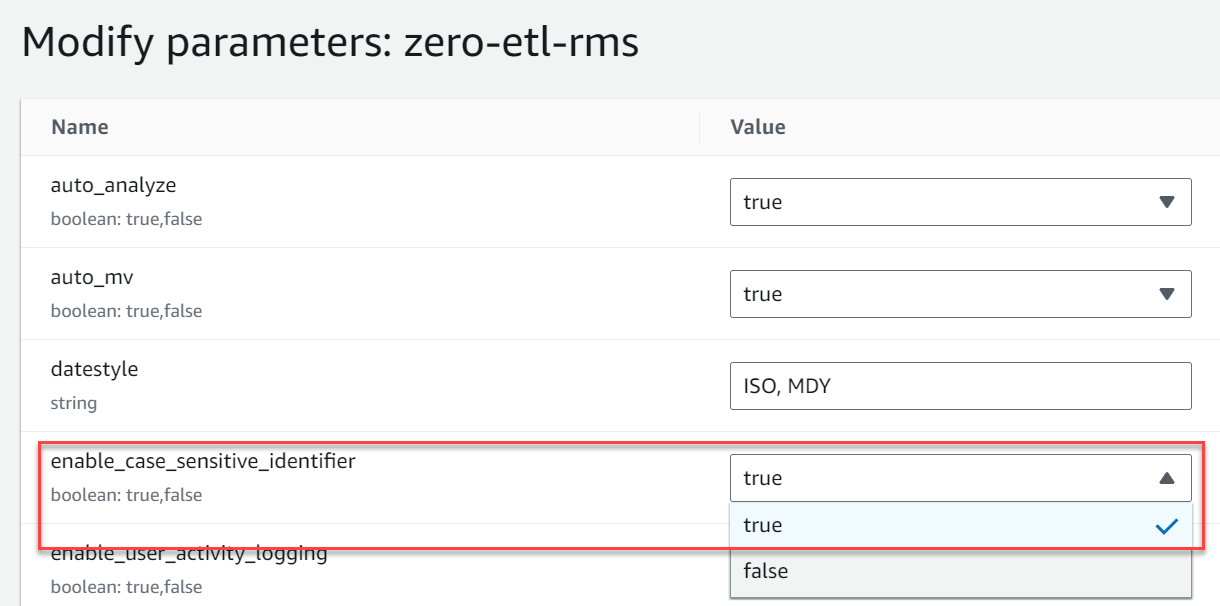
- Skapa en ny parametergrupp med namnet
zero-etl-rms. - Välja Redigera parametrar och ändra värdet på
enable_case_sensitive_identifiertillTrue. - Välja Save.
Du kan också använda AWS-kommandoradsgränssnitt (AWS CLI) kommando uppdatera-arbetsgrupp för Redshift Serverless:
- Välja Instrumentpanel för tillhandahållna kluster.
Överst i konsolfönstret ser du en Prova nya Amazon Redshift-funktioner i förhandsgranskning baner.
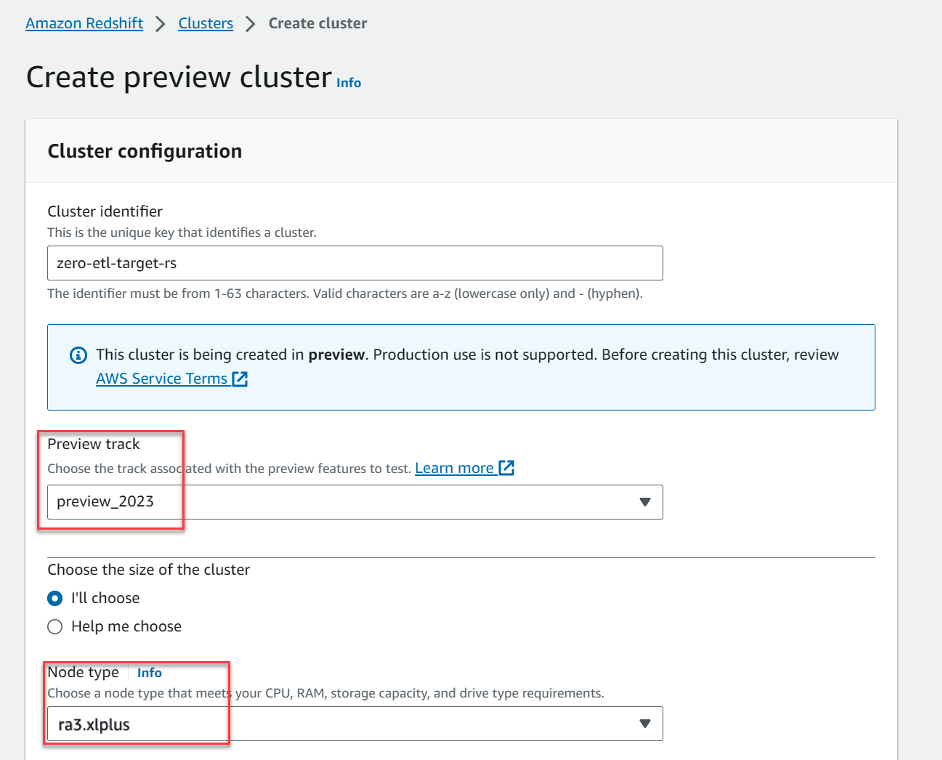
- Välja Skapa förhandsgranskningskluster.

- För Förhandsgranska spår, valde
preview_2023. - För Nodtyp, välj en av de nodtyper som stöds (för det här inlägget använder vi
ra3.xlplus).
- Enligt Ytterligare konfigurationer, bygga ut Databas konfigurationer.
- För Parametergrupperväljer
zero-etl-rms. - För kryptering, Välj Använd AWS Key Management Service.
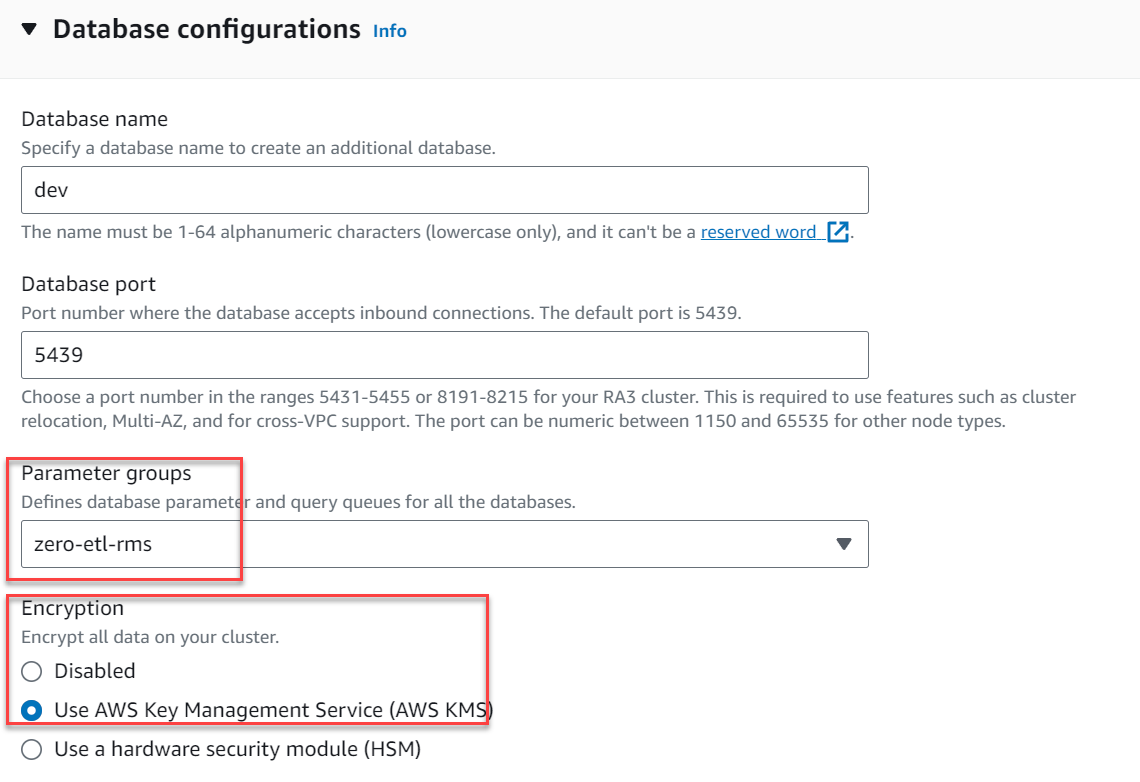
- Välja Skapa kluster.
Klustret ska bli Tillgängliga om några minuter.

- Navigera till namnområdet
zero-etl-target-rs-nsoch välj Resurspolicy fliken. - Välja Lägg till auktoriserade huvudmän.
- Ange antingen Amazon Resource Name (ARN) för AWS-användaren eller rollen, eller AWS-konto-ID (IAM-principaler) som får skapa integrationer.
Ett konto-ID lagras som ett ARN med root-användare.
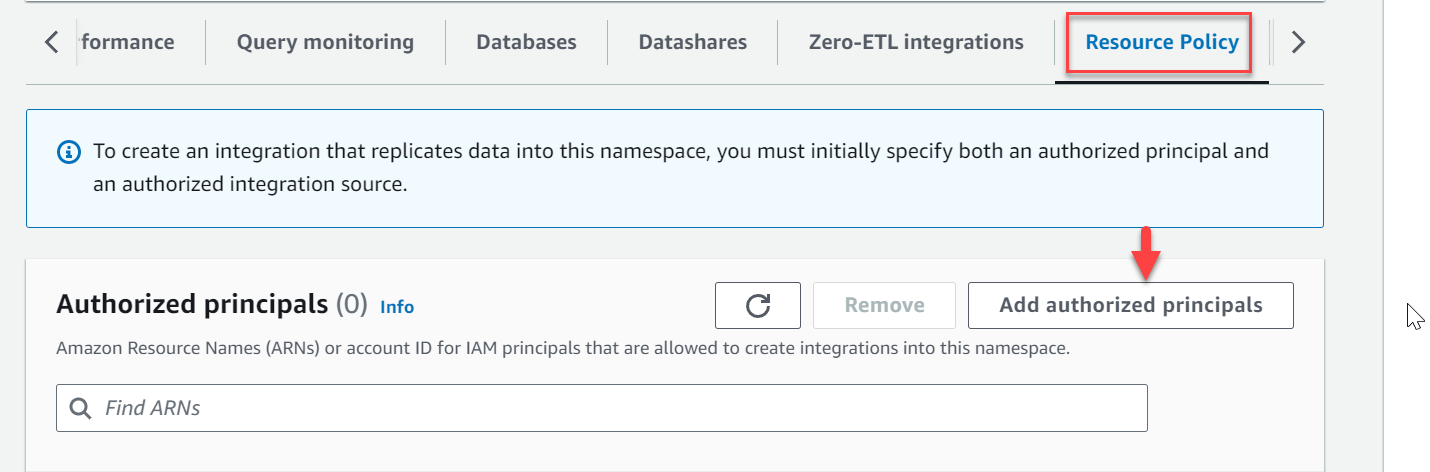
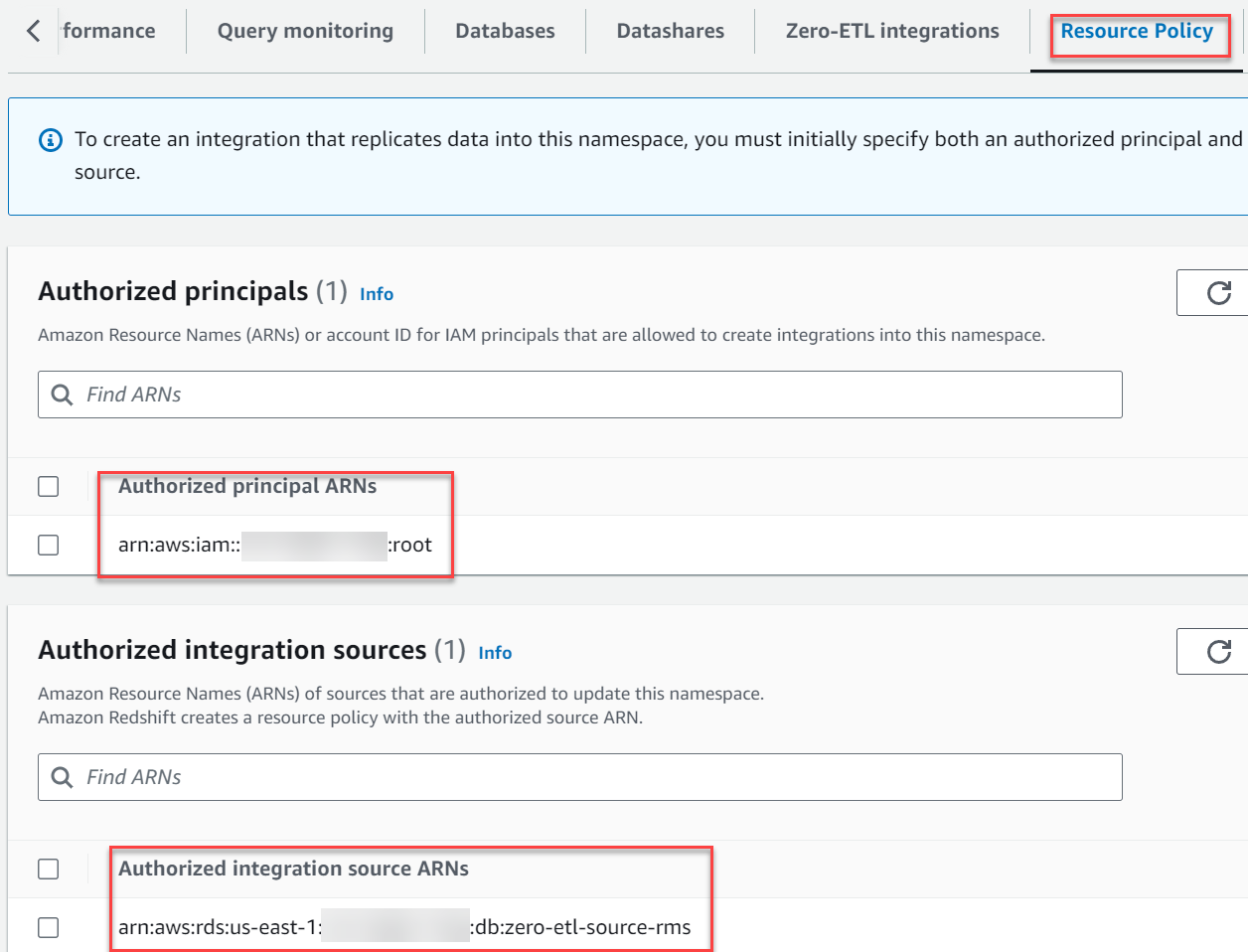
- I Auktoriserade integrationskällor avsnitt väljer Lägg till auktoriserad integrationskälla för att lägga till ARN för RDS för MySQL DB-instansen som är datakällan för noll-ETL-integreringen.
Du kan hitta detta värde genom att gå till Amazon RDS-konsolen och navigera till konfiguration fliken på zero-etl-source-rms DB-instans.

Din resurspolicy bör likna följande skärmdump.
Konfigurera nödvändiga behörigheter
För att skapa en noll-ETL-integration måste din användare eller roll ha en bifogad identitetsbaserad policy med lämpligt AWS identitets- och åtkomsthantering (IAM) behörigheter. En AWS-kontoägare kan konfigurera nödvändiga behörigheter för användare eller roller som kan skapa noll-ETL-integrationer. Exempelpolicyn tillåter den associerade huvudmannen att utföra följande åtgärder:
- Skapa noll-ETL-integrationer för käll-RDS för MySQL DB-instans.
- Visa och ta bort alla noll-ETL-integreringar.
- Skapa inkommande integrationer i måldatalagret. Denna behörighet krävs inte om samma konto äger Redshifts datalager och detta konto är en auktoriserad huvudman för det datalagret. Observera också att Amazon Redshift har ett annat ARN-format för provisionerade och serverlösa kluster:
- Förutsatt -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Server -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
- Förutsatt -
Slutför följande steg för att konfigurera behörigheterna:
- Välj på IAM-konsolen policies i navigeringsfönstret.
- Välja Skapa policy.
- Skapa en ny policy som heter
rds-integrationsmed följande JSON (ersättregionochaccount-idmed dina faktiska värden):
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"rds:CreateIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:db:source-instancename",
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeIntegration"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"rds:DeleteIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"redshift:CreateInboundIntegration"
],
"Resource": [
"arn:aws:redshift:{region}:{account-id}:cluster:namespace-uuid"
]
}]
}
- Bifoga policyn du skapade till din IAM-användar- eller rollbehörighet.
Skapa noll-ETL-integrationen
Utför följande steg för att skapa noll-ETL-integrationen:
- Välj på Amazon RDS-konsolen Noll-ETL-integrationer i navigeringsfönstret.
- Välja Skapa noll-ETL-integration.

- För Integrationsidentifierare, ange till exempel ett namn
zero-etl-demo.
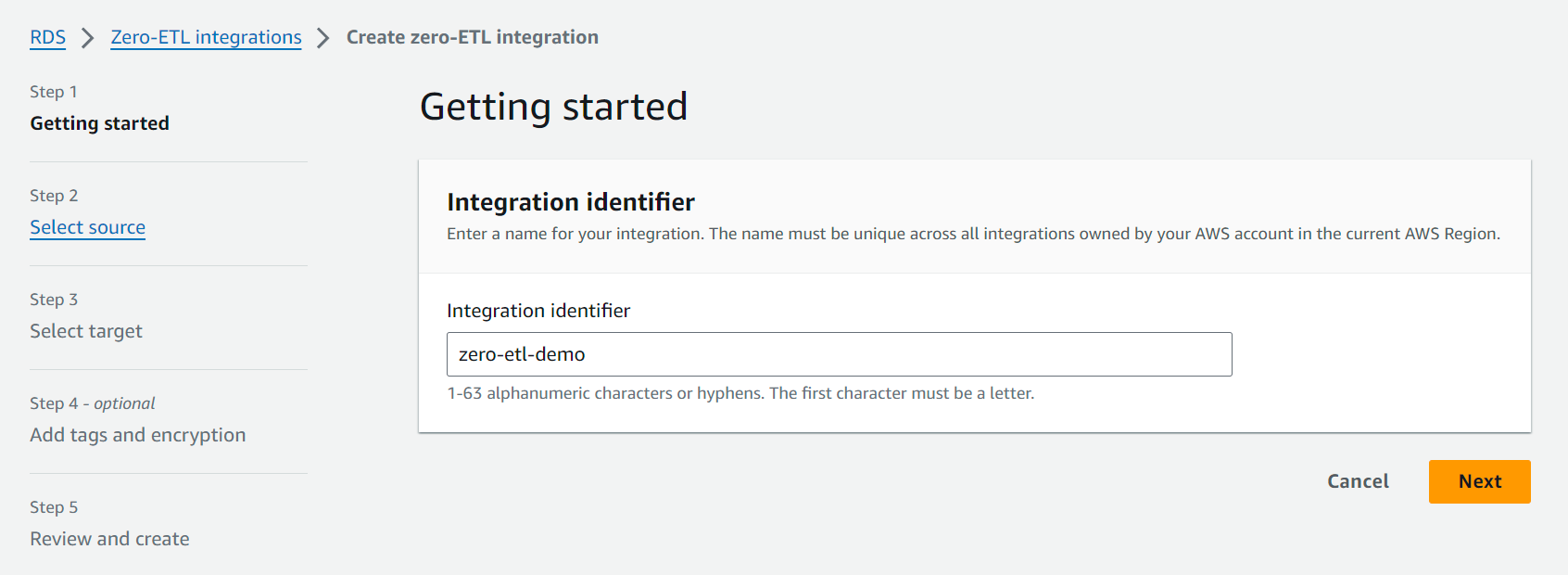
- För Källdatabasväljer Bläddra i RDS-databaser och välj källklustret
zero-etl-source-rms. - Välja Nästa.

- Enligt Målet, För Amazon Redshift datalagerväljer Bläddra i Redshifts datalager och välj Redshift data warehouse (
zero-etl-target-rs). - Välja Nästa.
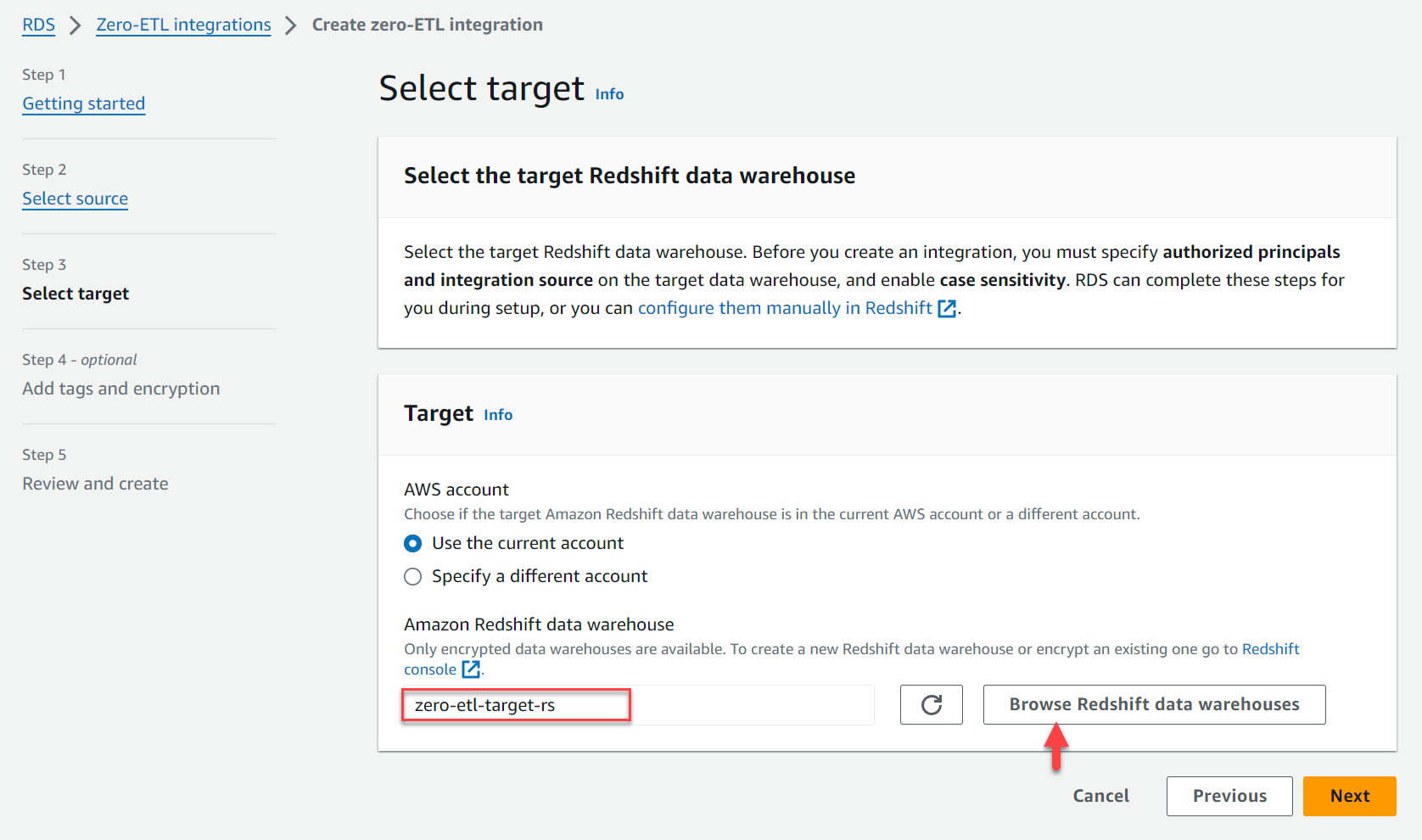
- Lägg till taggar och kryptering, om tillämpligt.
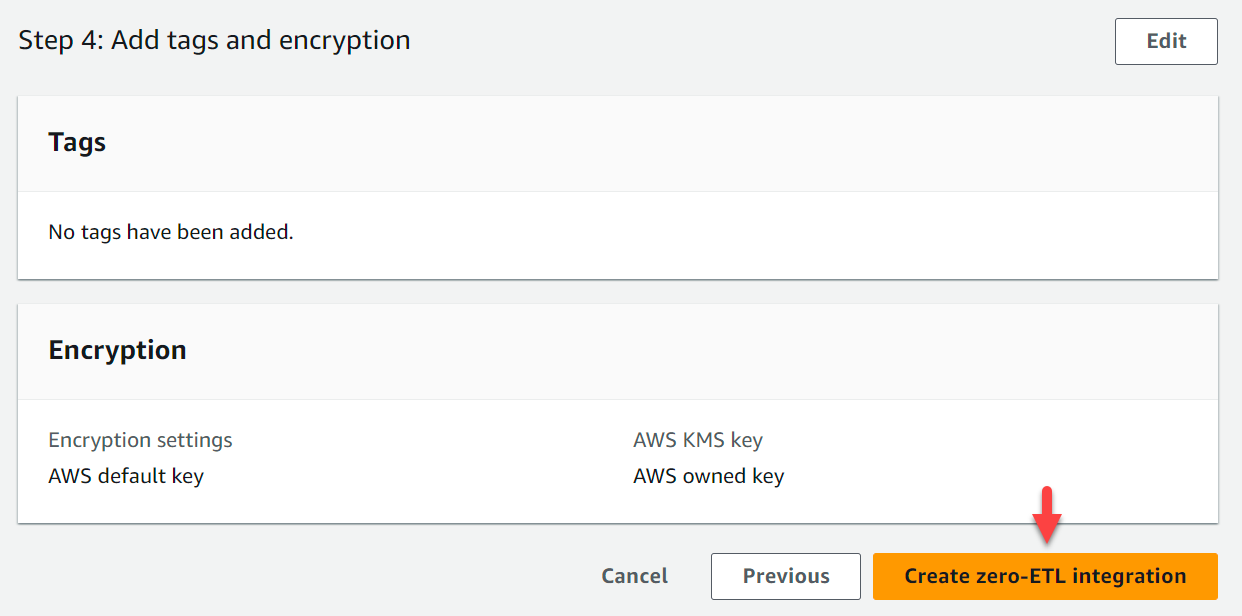
- Välja Nästa.
- Verifiera integreringsnamn, källa, mål och andra inställningar.
- Välja Skapa noll-ETL-integration.
Du kan välja integrationen för att se detaljerna och övervaka dess framsteg. Det tog cirka 30 minuter för status att ändras från Skapa till Aktiva.

Tiden kommer att variera beroende på storleken på din datauppsättning i källan.
Skapa en databas från integrationen i Amazon Redshift
För att skapa din databas från noll-ETL-integrationen, utför följande steg:
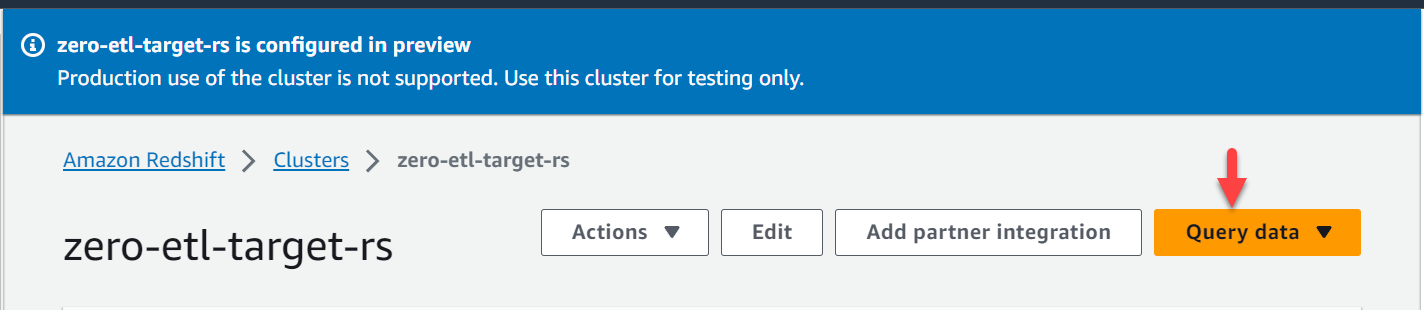
- Välj på Amazon Redshift-konsolen kluster i navigeringsfönstret.
- Öppna
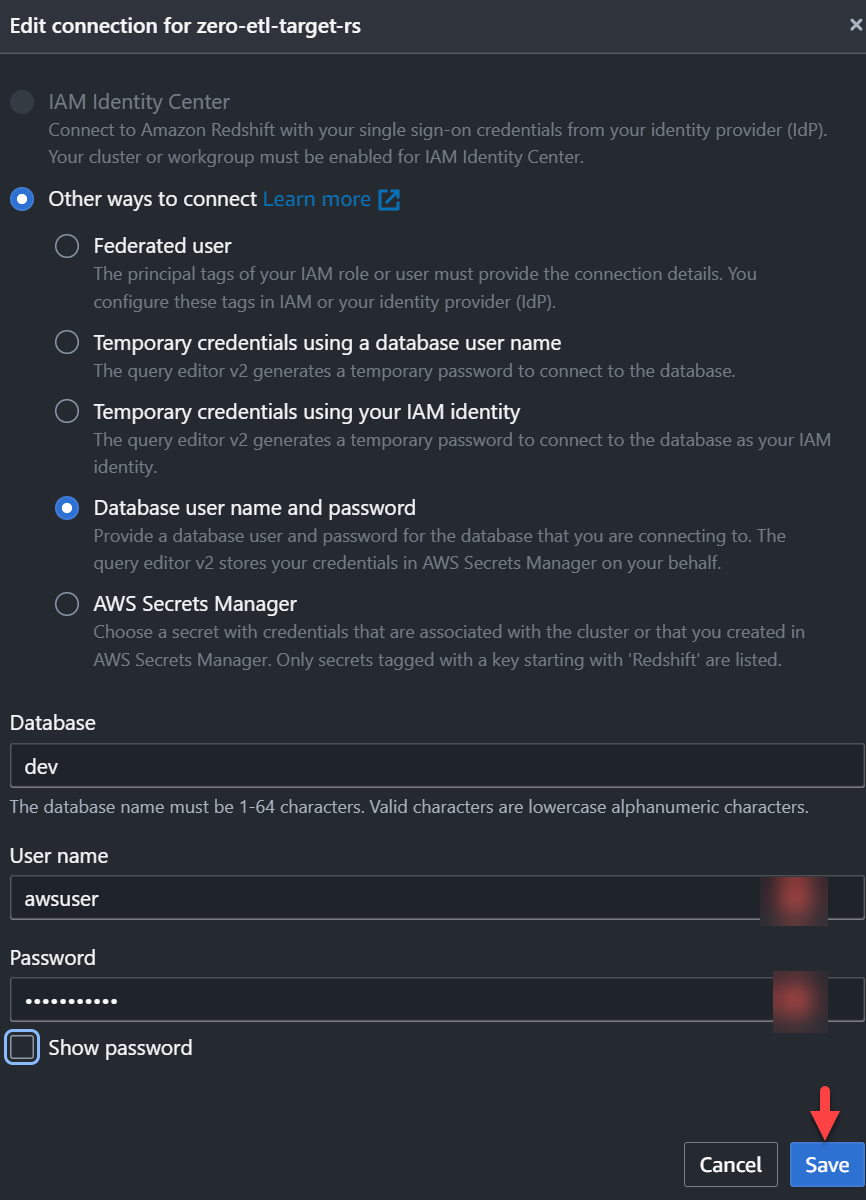
zero-etl-target-rsklunga. - Välja Fråga data för att öppna frågeredigeraren v2.
- Anslut till Redshifts datalager genom att välja Save.
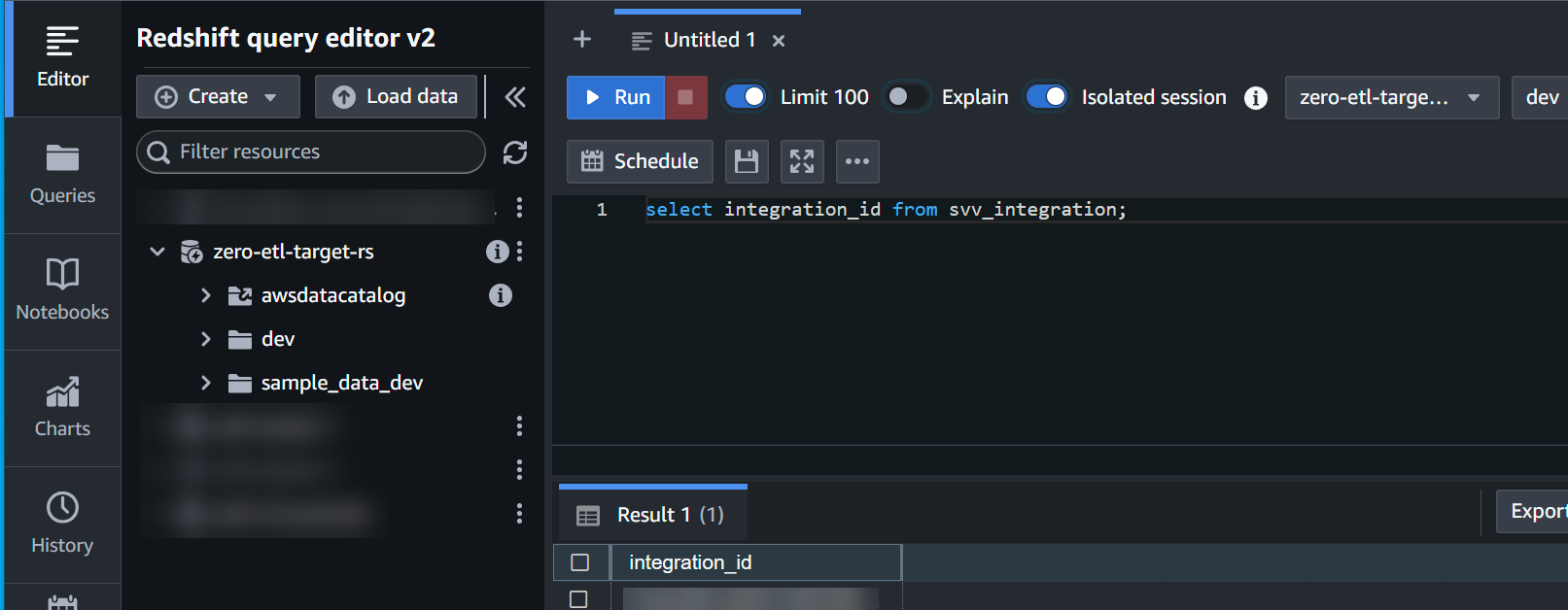
- Skaffa
integration_idfrånsvv_integrationsystemtabell:
select integration_id from svv_integration; -- copy this result, use in the next sql
- Använd
integration_idfrån föregående steg för att skapa en ny databas från integrationen:
CREATE DATABASE zetl_source FROM INTEGRATION '<result from above>';
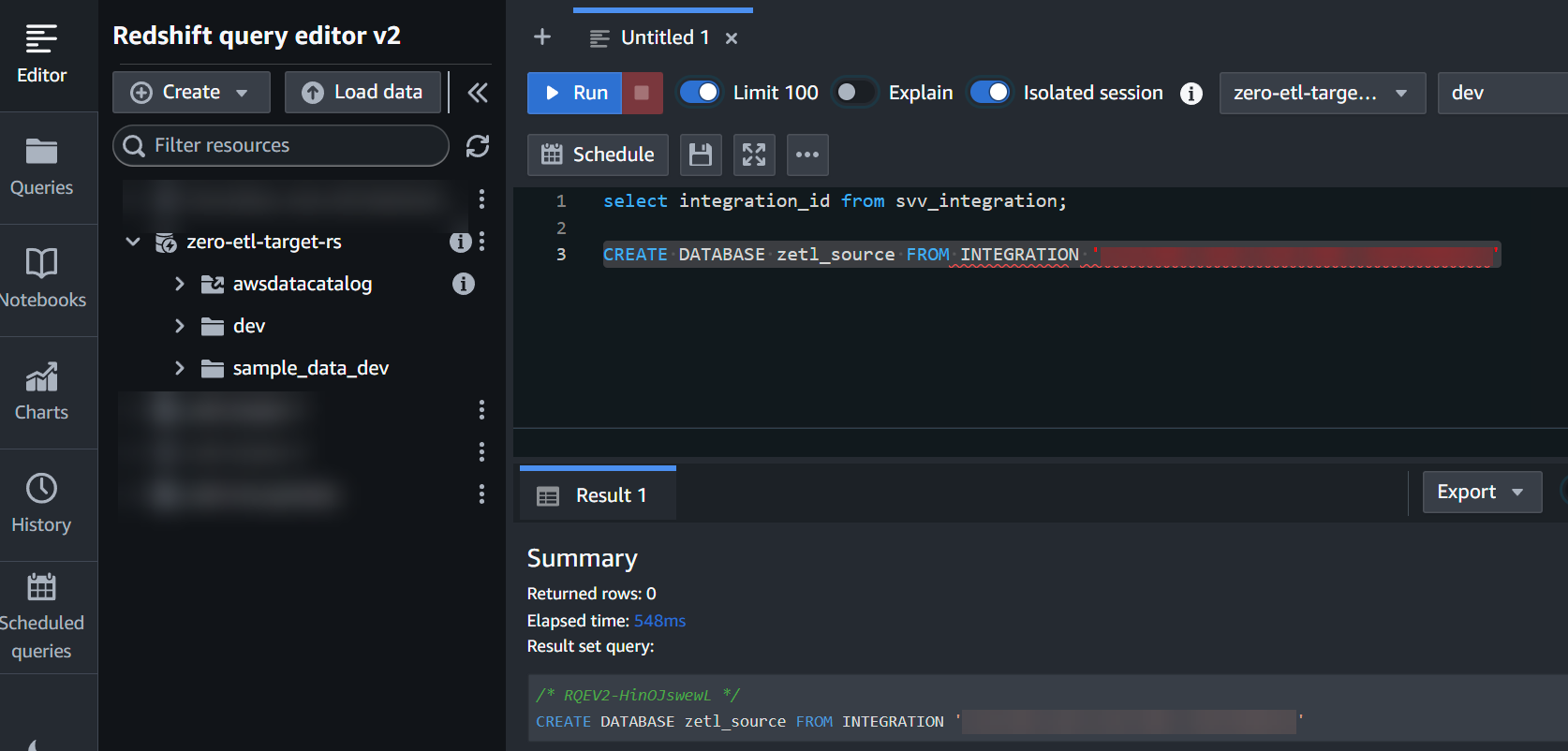
Integrationen är nu klar och en hel ögonblicksbild av källan kommer att återspegla som den är i destinationen. Pågående ändringar kommer att synkroniseras i nästan realtid.
Analysera transaktionsdata nästan i realtid
Nu kan vi köra analyser på TICKITs verksamhetsdata.
Fyll i källan TICKIT-data
För att fylla i källdata, utför följande steg:
- Kopiera CSV-indatafilerna till en lokal katalog. Följande är ett exempel på kommando:
aws s3 cp 's3://redshift-blogs/zero-etl-integration/data/tickit' . --recursive
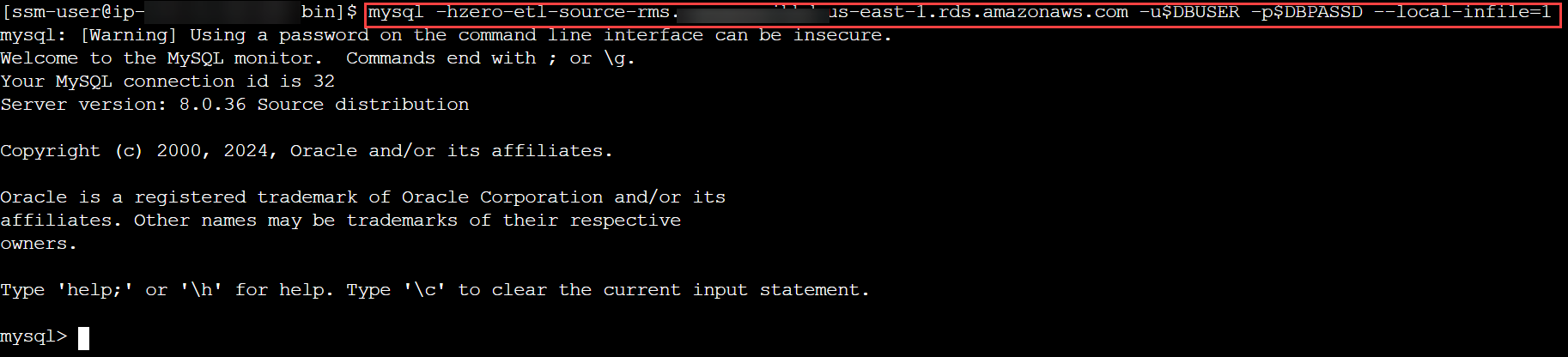
- Anslut till ditt RDS för MySQL-kluster och skapa en databas eller ett schema för TICKIT-datamodellen, verifiera att tabellerna i det schemat har en primärnyckel och initiera laddningsprocessen:
mysql -h <rds_db_instance_endpoint> -u admin -p password --local-infile=1
- Använd följande CREATE TABLE-kommandon.
- Ladda data från lokala filer med kommandot LOAD DATA.
Följande är ett exempel. Observera att indata-CSV-filen är uppdelad i flera filer. Detta kommando måste köras för varje fil om du vill ladda all data. För demoändamål bör en partiell dataladdning också fungera.

Analysera källan TICKIT-data i destinationen
På Amazon Redshift-konsolen öppnar du frågeredigeraren v2 med den databas du skapade som en del av integrationsinstallationen. Använd följande kod för att validera seed- eller CDC-aktiviteten:

Du kan nu tillämpa din affärslogik för transformationer direkt på data som har replikerats till datalagret. Du kan också använda prestandaoptimeringstekniker som att skapa en Redshift-materialiserad vy som förenar de replikerade tabellerna och andra lokala tabeller för att förbättra frågeprestanda för dina analytiska frågor.
Övervakning
Du kan fråga följande systemvyer och tabeller i Amazon Redshift för att få information om dina noll-ETL-integreringar med Amazon Redshift:
För att se integrationsrelaterade mätvärden som publicerats till amazoncloudwatch, öppna Amazon Redshift-konsolen. Välja Noll-ETL-integrationer i navigeringsfönstret och välj integrationen för att visa aktivitetsstatistik.
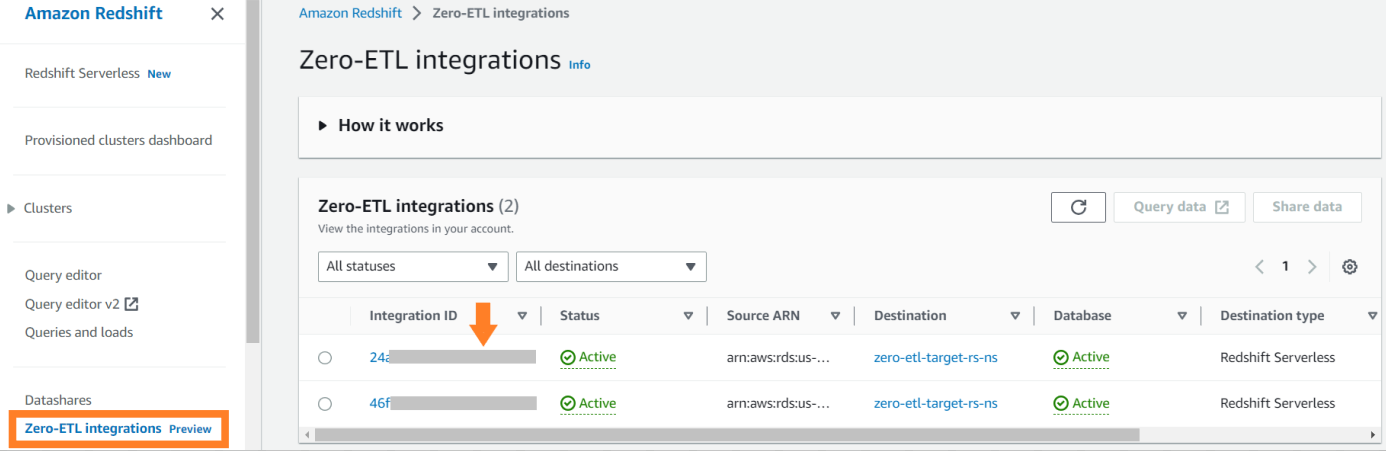
Tillgängliga mätvärden på Amazon Redshift-konsolen är integrationsstatistik och tabellstatistik, med tabellstatistik som ger information om varje tabell replikerad från Amazon RDS för MySQL till Amazon Redshift.

Integrationsmåtten innehåller tabellreplikeringsframgång och misslyckanden och fördröjningsdetaljer.
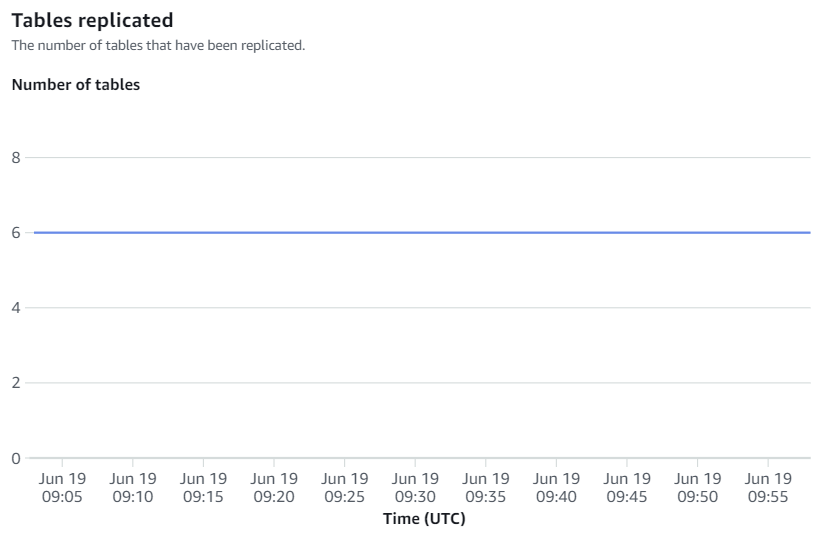
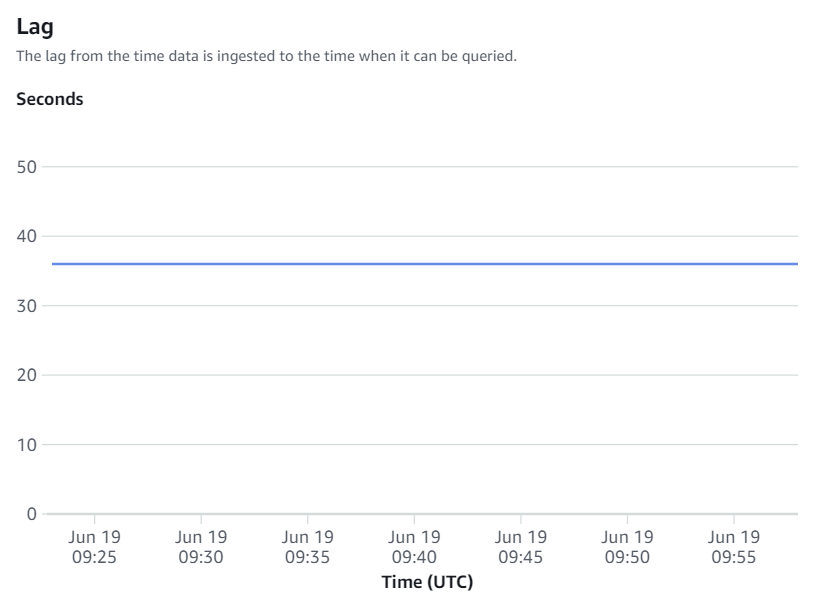
Manuell omsynkronisering
Noll-ETL-integreringen kommer automatiskt att initiera en omsynkronisering om ett tabellsynkroniseringstillstånd visas som misslyckat eller omsynkronisering krävs. Men om den automatiska omsynkroniseringen misslyckas kan du initiera en omsynkronisering på tabellnivå:
ALTER DATABASE zetl_source INTEGRATION REFRESH TABLES tbl1, tbl2;
En tabell kan gå in i ett misslyckat tillstånd av flera anledningar:
- Primärnyckeln togs bort från tabellen. I sådana fall måste du lägga till primärnyckeln igen och utföra det tidigare nämnda ALTER-kommandot.
- Ett ogiltigt värde påträffas under replikering eller en ny kolumn läggs till i tabellen med en datatyp som inte stöds. I sådana fall måste du ta bort kolumnen med datatypen som inte stöds och utföra det tidigare nämnda ALTER-kommandot.
- Ett internt fel kan i sällsynta fall orsaka tabellfel. ALTER-kommandot bör fixa det.
Städa upp
När du tar bort en noll-ETL-integrering raderas inte dina transaktionsdata från käll-RDS- eller mål-Redshift-databaserna, men Amazon RDS skickar inga nya ändringar till Amazon Redshift.
För att ta bort en noll-ETL-integrering, utför följande steg:
- Välj på Amazon RDS-konsolen Noll-ETL-integrationer i navigeringsfönstret.
- Välj den noll-ETL-integrering som du vill ta bort och välj Radera.
- För att bekräfta raderingen, välj Radera.

Slutsats
I det här inlägget visade vi dig hur du ställer in en noll-ETL-integration från Amazon RDS för MySQL till Amazon Redshift. Detta minimerar behovet av att underhålla komplexa datapipelines och möjliggör nästan realtidsanalys av transaktions- och operationsdata.
För att lära dig mer om Amazon RDS noll-ETL-integrering med Amazon Redshift, se Arbeta med Amazon RDS noll-ETL-integrationer med Amazon Redshift (förhandsgranskning).
Om författarna
 Milind Oke är en senior Redshift-specialistlösningsarkitekt som har arbetat på Amazon Web Services i tre år. Han är en AWS-certifierad innehavare av SA Associate, Security Specialty och Analytics Specialty, baserad i Queens, New York.
Milind Oke är en senior Redshift-specialistlösningsarkitekt som har arbetat på Amazon Web Services i tre år. Han är en AWS-certifierad innehavare av SA Associate, Security Specialty och Analytics Specialty, baserad i Queens, New York.
 Aditya Samant är en veteran från relationsdatabasbranschen med över 2 decennier av erfarenhet av att arbeta med kommersiella databaser och databaser med öppen källkod. Han arbetar för närvarande på Amazon Web Services som Principal Database Specialist Solutions Architect. I sin roll ägnar han tid åt att arbeta med kunder och designa skalbara, säkra och robusta molnbaserade arkitekturer. Aditya arbetar nära serviceteamen och samarbetar kring design och leverans av de nya funktionerna för Amazons hanterade databaser.
Aditya Samant är en veteran från relationsdatabasbranschen med över 2 decennier av erfarenhet av att arbeta med kommersiella databaser och databaser med öppen källkod. Han arbetar för närvarande på Amazon Web Services som Principal Database Specialist Solutions Architect. I sin roll ägnar han tid åt att arbeta med kunder och designa skalbara, säkra och robusta molnbaserade arkitekturer. Aditya arbetar nära serviceteamen och samarbetar kring design och leverans av de nya funktionerna för Amazons hanterade databaser.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/unlock-insights-on-amazon-rds-for-mysql-data-with-zero-etl-integration-to-amazon-redshift/

