Vi introducerade nyligen en ny funktion i Amazon SageMaker Python SDK som låter datavetare köra sin maskininlärningskod (ML) skapad i deras föredragna integrerade utvecklarmiljö (IDE) och bärbara datorer tillsammans med tillhörande körtidsberoenden som Amazon SageMaker utbildningsjobb med minimala kodändringar av experimenten som görs lokalt. Dataforskare utför vanligtvis flera iterationer av experiment i databearbetnings- och utbildningsmodeller medan de arbetar med ML-problem. De vill köra den här ML-koden och utföra experimentet med enkel användning och minimal kodändring. Amazon SageMaker modellutbildning hjälper datavetare att köra helt hanterade storskaliga utbildningsjobb på AWS:s datorinfrastruktur. SageMaker Training hjälper även datavetare med avancerade verktyg som t.ex Amazon SageMaker Debugger och Profiler för att felsöka och analysera deras storskaliga utbildningsjobb.
För kunder med små budgetar, små team och snäva tidslinjer, gör varje nytt koncept och kodrad som skrivs om för att köras på SageMaker dem mindre produktiva för sina kärnuppgifter, nämligen databearbetning och utbildning av ML-modeller. De vill skriva kod en gång inom ramen för deras val och kunna flytta sömlöst från att köra kod i sina bärbara eller bärbara datorer till att köra kod i skala med SageMaker-funktioner.
Med den här nya kapaciteten hos SageMaker Python SDK kan datavetare ta med sin ML-kod till SageMaker Training-plattformen på några minuter. Du behöver bara lägga till en enda rad kod till din ML-kod, och SageMaker förstår på ett intelligent sätt din kod tillsammans med datamängderna och inställningarna för arbetsytan och kör den som ett SageMaker-utbildningsjobb. Du kan sedan dra nytta av nyckelfunktionerna i SageMaker Training-plattformen, som möjligheten att enkelt skala jobb och andra associerade verktyg som Debugger och Profiler. I den här versionen kan du köra din lokala maskininlärning (ML) Python-kod som ett Amazon SageMaker-utbildningsjobb med en nod eller flera parallella jobb. Distribuerade träningsjobb (över flera noder) stöds inte av fjärrfunktioner.
I det här inlägget visar vi dig hur du använder den här nya förmågan för att köra lokal ML-kod som ett SageMaker-utbildningsjobb.
Lösningsöversikt
Du kan nu köra din ML-kod skriven i din IDE eller notebook som ett SageMaker Training-jobb genom att annotera funktionen, som fungerar som en ingångspunkt till användarens kodbas, med en enkel dekorator. Vid anrop tar denna funktion automatiskt en ögonblicksbild av alla associerade variabler, funktioner, paket, miljövariabler och andra körtidskrav från din ML-kod, serialiserar dem och skickar dem som ett SageMaker Training-jobb. Den integreras med den nyligen tillkännagivna SageMaker Python SDK-funktion för att ställa in standardvärden för parametrar. Denna förmåga förenklar SageMaker-konstruktionerna som du behöver lära dig för att kunna köra kod med SageMaker Training. Dataforskare kan skriva, felsöka och iterera sin kod i vilken IDE som helst (som t.ex. Amazon SageMaker Studio, bärbara datorer, VS-kod eller PyCharm). När du är klar kan du kommentera din Python-funktion med @remote dekoratör och kör det som ett SageMaker-jobb i stor skala.
Denna förmåga tar välbekanta Python-objekt med öppen källkod som argument och utdata. Dessutom behöver du inte förstå containerlivscykelhantering och kan helt enkelt köra dina arbetsbelastningar över olika beräkningskontexter (som en lokal IDE, Studio eller utbildningsjobb) med minimala konfigurationskostnader. För att köra vilken lokal kod som helst som ett SageMaker-utbildningsjobb, härleder den här förmågan de konfigurationer som krävs för att köra jobb, t.ex. AWS identitets- och åtkomsthantering (IAM) roll, krypteringsnyckel och nätverkskonfiguration, från Studio- eller IDE-inställningarna (som kan vara standardinställningar) och skickar dem till plattformen som standard. Du har flexibiliteten att anpassa din körtid i SageMaker-hanterade infrastruktur med den härledda konfigurationen eller åsidosätta dem på SDK-nivå genom att skicka dem som argument till dekoratören.
Den här nya förmågan hos SageMaker Python SDK omvandlar din ML-kod i en befintlig arbetsmiljö och eventuell tillhörande databearbetningskod och datauppsättningar till ett SageMaker Training-jobb. Denna funktion söker efter ML-kod insvept i en @remote decorator och automatiskt översätter det till ett jobb som körs i antingen Studio eller en lokal IDE som PyCharm.
I följande avsnitt går vi igenom funktionerna i denna nya funktion och hur man startar pythonfunktioner som SageMaker Training-jobb.
Förutsättningar
För att använda denna nya SageMaker Python SDK-kapacitet och köra koden som är kopplad till det här inlägget, behöver du följande förutsättningar:
- Ett AWS-konto som kommer att innehålla alla dina AWS-resurser
- En IAM-roll för att komma åt SageMaker
- Tillgång till Studio eller en SageMaker notebook-instans eller en IDE som PyCharm
Använd SDK från Studio och SageMaker anteckningsböcker
Du kan använda denna funktion från Studio genom att starta en anteckningsbok och slå in din kod med en @remote dekoratör inuti anteckningsboken. Du måste först importera fjärrfunktionen med följande kod:
from sagemaker.remote_function import remoteNär du använder dekorationsfunktionen kommer denna funktion automatiskt att tolka din kods funktion och köra den som ett SageMaker Training-jobb.
Du kan också använda denna funktion från en SageMaker-anteckningsbokinstans. Du måste först starta en anteckningsbokförekomst, öppna Jupyter eller Jupyter Lab på den och starta en anteckningsbok. Importera sedan fjärrfunktionen som visas i föregående kod och slå in din kod med @remote dekoratör. Vi inkluderar ett exempel på hur du använder dekorationsfunktionen och tillhörande inställningar längre fram i detta inlägg.
Använd SDK från din lokala miljö
Du kan också använda denna funktion från din lokala IDE. Som en förutsättning måste du ha AWS-kommandoradsgränssnitt (AWS CLI), SageMaker Python SDK och AWS SDK för Python (Boto3) installerad i din lokala miljö. Du måste importera dessa bibliotek i din kod, ställa in SageMaker-sessionen, ange inställningar och dekorera din funktion med @remote dekoratör. I följande exempelkod kör vi en enkel uppdelningsfunktion som ett SageMaker Training-jobb:
import boto3
import sagemaker
from sagemaker.remote_function import remote sm_session = sagemaker.Session(boto_session=boto3.session.Session(region_name="us-west-2"))
settings = dict(
sagemaker_session=sm_session,
role=<IAM_ROLE_NAME>
instance_type="ml.m5.xlarge",
)
@remote(**settings)
def divide(x, y):
return x / y
if __name__ == "__main__":
print(divide(2, 3.0))Vi kan använda en liknande metod för att köra avancerade funktioner som utbildningsjobb, som visas i nästa avsnitt.
Starta Python fungerar som SageMaker-jobb
Den nya SageMaker Python SDK-funktionen låter dig köra Python-funktioner som SageMaker Training jobb. Vilken Python-kod, ML-träningskod som helst som utvecklats av datavetare med deras föredragna lokala IDE (PyCharm, VS Code), SageMaker-anteckningsböcker eller Studio-anteckningsböcker kan lanseras som ett hanterat SageMaker-jobb.
I ML-arbetsbelastningar som använder denna funktion, serialiseras associerade datauppsättningar, beroenden och arbetsytemiljöinställningar med ML-koden och körs som ett SageMaker-jobb synkront och asynkront.
Du kan lägga till en @remote dekoratörskommentarer till valfri Python-kod inklusive en lokal ML-bearbetnings- eller utbildningsfunktion för att starta den som ett hanterat SageMaker Training-jobb, och därigenom dra fördel av skalan, prestanda och kostnadsfördelar med SageMaker. Detta kan uppnås med minimala kodändringar genom att lägga till en dekorator till Python-funktionskoden. Anropet till den dekorerade funktionen körs synkront, och funktionskörningen väntar tills SageMaker-jobbet är klart.
I följande exempel använder vi @remote decorator för att lansera SageMaker-jobb i dekoratörsläge med en ml.m5.large-instans. SageMaker använder utbildningsjobb för att lansera denna funktion som ett hanterat jobb.
from sagemaker.remote_function import remote
from numpy as np @remote(instance_type="ml.m5.large")
def matrix_multiply(a, b): return np.matmul(a, b) a = np.array([[1, 0], [0, 1]])
b = np.array([1, 2]) assert matrix_multiply(a, b) == np.array([1,2])Du kan också använda dekorationsläget för att starta SageMaker-jobb, Python-paket och beroenden. Du kan inkludera miljövariabler som VPC, subnät och säkerhetsgrupper för att starta SageMaker-utbildningsjobb i environment.yml fil. Detta gör att ML-ingenjörer och -administratörer kan konfigurera dessa miljövariabler så att datavetare kan fokusera på ML-modellbyggnad och iterera snabbare. Se följande kod:
from sagemaker.remote_function import remote @remote(instance_type="ml.g4dn.xlarge",dependencies = "./environment.yml")
def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
... <TRUCNATED>
return os.path.join(s3_output_path, model_dir), eval_resultDu kan använda RemoteExecutor för att starta Python-funktioner som SageMaker jobbar asynkront. Exekutorn pollar asynkront SageMaker Training-jobb för att uppdatera statusen för jobbet. De RemoteExecutor klass är en implementering av concurrent.futures.Executor, som används för att skicka in SageMaker Training-jobb asynkront. Se följande kod:
from sagemaker.remote_function import RemoteExecutor def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
...<TRUNCATED>
return os.path.join(s3_output_path, model_dir), eval_result with RemoteExecutor(instance_type="ml.g4dn.xlarge", dependencies = './requirements.txt') as e:
future = e.submit(train_hf_model, train_input_path,test_input_path,s3_output_path,
epochs, train_batch_size, eval_batch_size,warmup_steps,learning_rate)Anpassa runtime-miljön
Dekoratörsläge och RemoteExecutor låter dig definiera och anpassa runtime-miljöerna för SageMaker-jobbet. Körtidsberoendena, inklusive Python-paket och miljövariabler för SageMaker-jobb, kan specificeras för att anpassa körtiden. För att kunna köra lokal Python-kod som SageMaker-hanterade jobb måste Python-paketet och beroenden göras tillgängliga för SageMaker. ML-ingenjörer eller datavetenskapsadministratörer kan konfigurera nätverks- och säkerhetskonfigurationer som VPC, subnät och säkerhetsgrupper för SageMaker-jobb, så datavetare kan använda dessa centralt hanterade konfigurationer medan de startar SageMaker-jobb. Du kan använda antingen a requirements.txt fil eller en Conda environment.yaml fil.
När beroenden definieras med requirements.txt, kommer paketen att installeras med hjälp av pip under jobbkörningen. Om bilden som används för att köra jobbet kommer med Conda-miljöer kommer paket att installeras i den Conda-miljö som deklarerats att användas för jobb. Följande kod visar ett exempel requirements.txt fil:
datasets
transformers
torch
scikit-learn
s3fs==0.4.2
sagemaker>=2.148.0Du kan skicka din Conda environment.yaml fil för att skapa den Conda-miljö du vill att din kod ska köras i under träningsjobbet. Om bilden som används för att köra jobbet deklarerar en Conda-miljö att köra koden under, kommer vi att uppdatera den deklarerade Conda-miljön med den givna specifikationen. Följande kod är ett exempel på en Conda environment.yaml fil:
name: sagemaker_example
channels: - conda-forge
dependencies: - python=3.10 - pandas - pip: - sagemakerAlternativt kan du ställa in dependencies=”auto_capture” att låta SageMaker Python SDK fånga de installerade beroenden i den aktiva Conda-miljön. Du måste ha en aktiv Conda-miljö för auto_capture att jobba. Observera att det finns förutsättningar för auto_capture att jobba; vi rekommenderar att du skickar in dina beroenden som en requirement.txt or Conda environment.yml fil enligt beskrivningen i föregående avsnitt.
Mer information finns i Kör din lokala kod som ett SageMaker-utbildningsjobb.
Konfigurationer för SageMaker-jobb
Infrastrukturrelaterade inställningar kan överföras till en konfigurationsfil som administratörsanvändare kan hjälpa till att konfigurera. Du behöver bara ställa in den en gång. Infrastrukturinställningar täcker nätverkskonfigurationen, IAM-roller, Amazon enkel lagringstjänst (Amazon S3) mapp för indata, utdata och taggar. Hänvisa till Konfigurera och använda standardinställningar med SageMaker Python SDK för mer detaljer.
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
Dependencies: path/to/requirements.txt
EnvironmentVariables: {"EnvVarKey": "EnvVarValue"}
ImageUri: 366666666666.dkr.ecr.us-west-2.amazonaws.com/my-image:latest
InstanceType: ml.m5.large
RoleArn: arn:aws:iam::366666666666:role/MyRole
S3KmsKeyId: somekmskeyid
S3RootUri: s3://my-bucket/my-project
SecurityGroupIds:
- sg123
Subnets:
- subnet-1234
Tags:
- {"Key": "someTagKey", "Value": "someTagValue"}
VolumeKmsKeyId: somekmskeyidGenomförande
Modeller för djupinlärning som PyTorch eller TensorFlow kan också köras inom Studio genom att köra koden som ett träningsjobb i den bärbara datorn. För att visa upp den här funktionen i Studio kan du klona detta arkiv i din Studio och köra anteckningsboken som finns i GitHub förvaret.
Det här exemplet visar ett användningsfall för binär textklassificering från början till slut. Vi använder Hugging Face-transformatorerna och datauppsättningsbiblioteket för att finjustera en förtränad transformator på binär textklassificering. I synnerhet kommer den förtränade modellen att finjusteras med hjälp av IMDb-datauppsättning.
När du klona förvaret bör du hitta följande filer:
- config.yaml – De flesta dekorationsargumenten kan laddas ner till konfigurationsfilen för att separera de infrastrukturrelaterade inställningarna från kodbasen
- huggingface.ipynb – Den här innehåller koden för att träna en förtränad HuggingFace-modell, som kommer att finjusteras med hjälp av IMDB-datauppsättningen
- requirements.txt – Den här filen innehåller alla beroenden för att köra funktionen som kommer att användas i den här anteckningsboken för att köra koden och köra utbildningen på distans i en GPU-instans som ett träningsjobb
När du öppnar anteckningsboken blir du ombedd att ställa in anteckningsbokens miljö. Du kan välja Data Science 3.0-bilden med Python 3-kärnan och ml.m5.large som snabbstartsinstanstyp för att köra notebook-koden. Den här instanstypen är betydligt snabbare när det gäller att skapa en miljö.
Utbildningsjobbet kommer att köras i en ml.g4dn.xlarge-instans enligt definitionen i config.yaml fil:
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
# role arn is not required if in SageMaker Notebook instance or SageMaker Studio
# Uncomment the following line and replace with the right execution role if in a local IDE
# RoleArn: <IAM_ROLE_ARN>
InstanceType: ml.g4dn.xlarge
Dependencies: ./requirements.txtSmakämnen requirements.txt filberoenden för att köra funktionen för att träna Hugging Face-modellen inkluderar följande:
datasets
transformers
torch
scikit-learn
# lock s3fs to this specific version as more recent ones introduce dependency on aiobotocore, which is not compatible with botocore
s3fs==0.4.2
sagemaker>=2.148.0,<3Anteckningsboken Hugging Face visar hur man kör träningen på distans via @remote funktion, som körs synkront. Därför kommer funktionen som körs för att träna modellen att vänta tills SageMaker Training-jobbet är klart. Utbildningen kommer att köras på distans med en GPU-instans där instanstypen är definierad i den föregående konfigurationsfilen.
När du har kört träningsjobbet kan du köra resten av cellerna i anteckningsboken för att inspektera utvärderingsmåtten och klassificera texten på vår utbildade modell.
Du kan också se utbildningsjobbets status som fjärrutlöstes i GPU-instansen på SageMakers instrumentpanel genom att navigera tillbaka till SageMaker-konsolen.
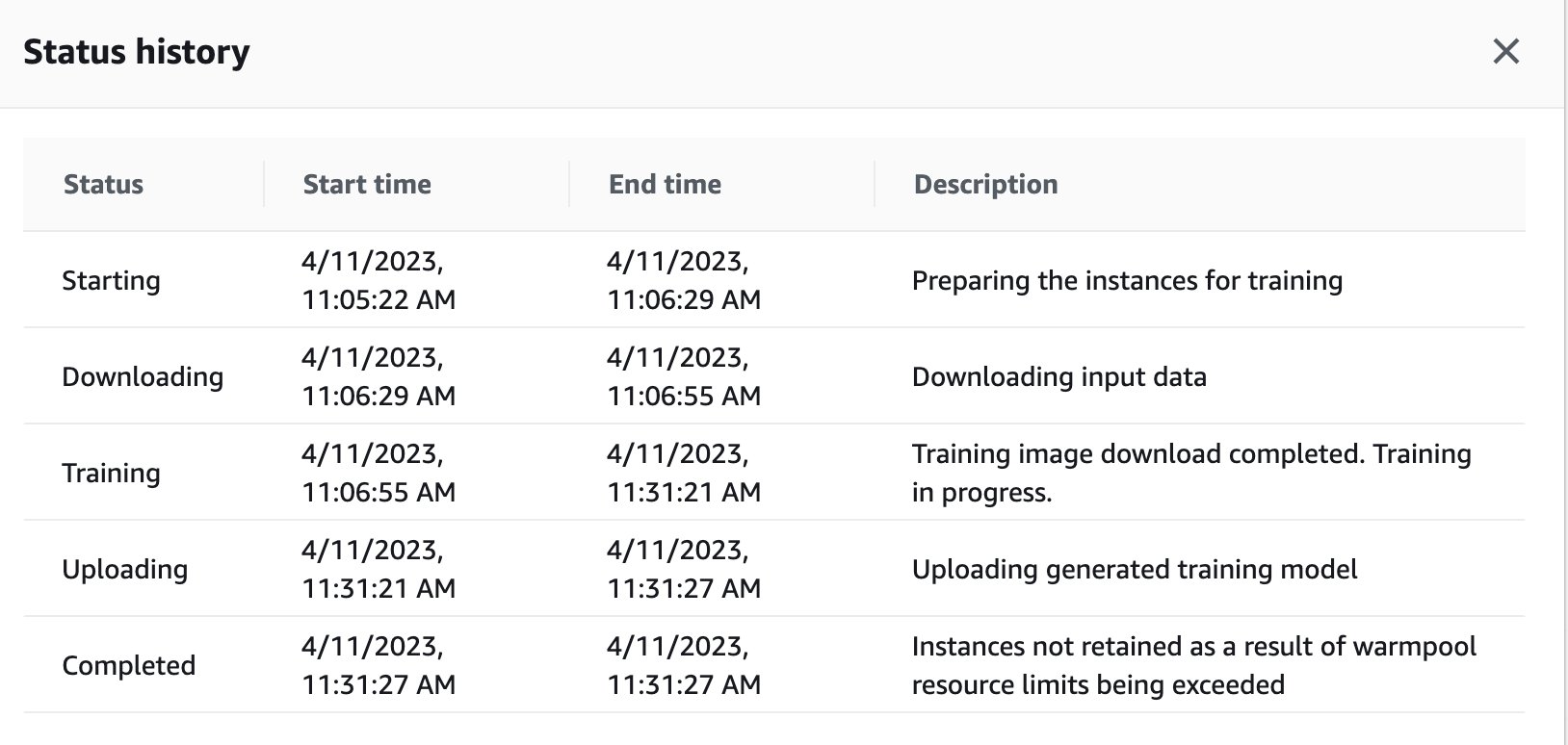
Så snart träningsjobbet är klart fortsätter det att köra instruktionerna i anteckningsboken för utvärdering och klassificering. Liknande jobb kan tränas och köras via fjärrexekveringsfunktionen inbäddad i Studio-anteckningsböcker för att utföra körningarna asynkront.
Integration med SageMaker-experiment inuti en @remote-funktion
Du kan skicka ditt experimentnamn, körnamn och andra parametrar till din fjärrfunktion för att skapa en SageMaker-experimentkörning. Följande kodexempel importerar experimentnamnet, namnet på körningen och parametrarna som ska loggas för varje körning:
from sagemaker.remote_function import remote
from sagemaker.experiments.run import Run
# Define your remote function
@remote
def train(value_1, value_2, exp_name, run_name):
...
...
#Creates the experiment
with Run( experiment_name=exp_name, run_name=run_name, sagemaker_session=sagemaker_session
) as run:
...
...
#Define values for the parameters to log
run.log_parameter("param_1", value_1)
run.log_parameter("param_2", value_2)
...
...
#Define metrics to log
run.log_metric("metric_a", 0.5)
run.log_metric("metric_b", 0.1) # Invoke your remote function
train(1.0, 2.0, "my-exp-name", "my-run-name") I det föregående exemplet, parametrarna p1 och p2 loggas över tid i en träningsslinga. Vanliga parametrar kan inkludera batchstorlek eller epoker. I exemplet, måtten A och B loggas för en löprunda över tid i en träningsslinga. Vanliga mätvärden kan vara noggrannhet eller förlust. För mer information, se Skapa ett Amazon SageMaker-experiment.
Slutsats
I det här inlägget introducerade vi en ny SageMaker Python SDK-kapacitet som gör det möjligt för datavetare att köra sin ML-kod i sin föredragna IDE som SageMaker Training-jobb. Vi diskuterade de förutsättningar som behövs för att använda denna funktion tillsammans med dess funktioner. Vi visade också hur man använder denna funktion i Studio, SageMaker notebook-instanser och din lokala IDE. Dessutom gav vi exempel på kod för att visa hur man använder denna funktion. Som nästa steg rekommenderar vi att du provar denna funktion i din IDE eller SageMaker genom att följa anvisningarna kodexempel refereras i detta inlägg.
Om författarna
 Dipankar Patro är en mjukvaruutvecklingsingenjör på AWS SageMaker, förnyar och bygger MLOps-lösningar för att hjälpa kunder att använda AI/ML-lösningar i stor skala. Han har en MS i datavetenskap och hans intresseområden är datorsäkerhet, distribuerade system och AI/ML.
Dipankar Patro är en mjukvaruutvecklingsingenjör på AWS SageMaker, förnyar och bygger MLOps-lösningar för att hjälpa kunder att använda AI/ML-lösningar i stor skala. Han har en MS i datavetenskap och hans intresseområden är datorsäkerhet, distribuerade system och AI/ML.
 Farooq Sabir är Senior Artificiell Intelligens och Machine Learning Specialist Solutions Architect på AWS. Han har doktorsexamen och MS-examen i elektroteknik från University of Texas i Austin och en MS i datavetenskap från Georgia Institute of Technology. Han har över 15 års arbetslivserfarenhet och gillar även att undervisa och mentor studenter. På AWS hjälper han kunder att formulera och lösa sina affärsproblem inom datavetenskap, maskininlärning, datorseende, artificiell intelligens, numerisk optimering och relaterade domäner. Baserad i Dallas, Texas, älskar han och hans familj att resa och åka på långa vägresor.
Farooq Sabir är Senior Artificiell Intelligens och Machine Learning Specialist Solutions Architect på AWS. Han har doktorsexamen och MS-examen i elektroteknik från University of Texas i Austin och en MS i datavetenskap från Georgia Institute of Technology. Han har över 15 års arbetslivserfarenhet och gillar även att undervisa och mentor studenter. På AWS hjälper han kunder att formulera och lösa sina affärsproblem inom datavetenskap, maskininlärning, datorseende, artificiell intelligens, numerisk optimering och relaterade domäner. Baserad i Dallas, Texas, älskar han och hans familj att resa och åka på långa vägresor.
 Manoj Ravi är senior produktchef för Amazon SageMaker. Han brinner för att bygga nästa generations AI-produkter och arbetar med mjukvara och verktyg för att göra storskalig maskininlärning enklare för kunderna. Han har en MBA från Haas School of Business och en magisterexamen i Information Systems Management från Carnegie Mellon University. På fritiden tycker Manoj om att spela tennis och ägna sig åt landskapsfotografering.
Manoj Ravi är senior produktchef för Amazon SageMaker. Han brinner för att bygga nästa generations AI-produkter och arbetar med mjukvara och verktyg för att göra storskalig maskininlärning enklare för kunderna. Han har en MBA från Haas School of Business och en magisterexamen i Information Systems Management från Carnegie Mellon University. På fritiden tycker Manoj om att spela tennis och ägna sig åt landskapsfotografering.
 Shikhar Kwatra är en AI/ML Specialist Solutions Architect på Amazon Web Services och arbetar med en ledande global systemintegratör. Han har förtjänat titeln som en av de yngsta indiska mästeruppfinnarna med över 500 patent inom AI/ML och IoT-domänerna. Shikhar hjälper till med att utforma, bygga och underhålla kostnadseffektiva, skalbara molnmiljöer för organisationen och stödjer GSI-partnern i att bygga strategiska industrilösningar på AWS. Shikhar tycker om att spela gitarr, komponera musik och träna mindfulness på sin fritid.
Shikhar Kwatra är en AI/ML Specialist Solutions Architect på Amazon Web Services och arbetar med en ledande global systemintegratör. Han har förtjänat titeln som en av de yngsta indiska mästeruppfinnarna med över 500 patent inom AI/ML och IoT-domänerna. Shikhar hjälper till med att utforma, bygga och underhålla kostnadseffektiva, skalbara molnmiljöer för organisationen och stödjer GSI-partnern i att bygga strategiska industrilösningar på AWS. Shikhar tycker om att spela gitarr, komponera musik och träna mindfulness på sin fritid.
 Vikram Elango är Sr. AI/ML Specialist Solutions Architect vid AWS, baserad i Virginia, USA. Han är för närvarande fokuserad på generativ AI, LLM, prompt ingenjörskonst, optimering av stora modellinferenser och skalning av ML mellan företag. Vikram hjälper finans- och försäkringsbranschens kunder med design och tankeledarskap att bygga och distribuera maskininlärningsapplikationer i stor skala. På fritiden tycker han om att resa, vandra, laga mat och campa.
Vikram Elango är Sr. AI/ML Specialist Solutions Architect vid AWS, baserad i Virginia, USA. Han är för närvarande fokuserad på generativ AI, LLM, prompt ingenjörskonst, optimering av stora modellinferenser och skalning av ML mellan företag. Vikram hjälper finans- och försäkringsbranschens kunder med design och tankeledarskap att bygga och distribuera maskininlärningsapplikationer i stor skala. På fritiden tycker han om att resa, vandra, laga mat och campa.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/run-your-local-machine-learning-code-as-amazon-sagemaker-training-jobs-with-minimal-code-changes/

