Beskrivning
Området artificiell intelligens har sett anmärkningsvärda framsteg de senaste åren, särskilt när det gäller stora språkmodeller. LLM:er kan generera människoliknande text, sammanfatta dokument och skriva programvarukod. Mistral-7B är en av de senaste stora språkmodellerna som stöder engelsk text- och kodgenereringsförmåga, och den kan användas för olika uppgifter som t.ex. textöversikt, klassificering, textkomplettering och kodkomplettering.

Det som utmärker Mistral-7B-Instruct är dess förmåga att leverera fantastisk prestanda trots färre parametrar, vilket gör den till en högpresterande och kostnadseffektiv lösning. Modellen blev nyligen populär efter att benchmarkresultat visade att den inte bara överträffar alla 7B-modeller på MT-Bench utan också konkurrerar positivt med 13B-chattmodeller. I den här bloggen kommer vi att utforska funktionerna och funktionerna hos Mistral 7B, inklusive dess användningsfall, prestanda och en praktisk guide för att finjustera modellen.
Inlärningsmål
- Förstå hur stora språkmodeller och Mistral 7B fungerar
- Arkitektur av Mistral 7B och riktmärken
- Användningsfall av Mistral 7B och hur den fungerar
- Djupdyka in i kod för slutledning och finjustering
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Vad är stora språkmodeller?
Stora språkmodeller' arkitektur bildas med transformatorer, som använder uppmärksamhetsmekanismer för att fånga långväga beroenden i data, där flera lager av transformatorblock innehåller multi-head självuppmärksamhet och feed-forward neurala nätverk. Dessa modeller är förtränade på textdata och lär sig att förutsäga nästa ord i en sekvens, och på så sätt fånga mönstren i språk. Förträningsvikterna kan finjusteras på specifika uppgifter. Vi kommer specifikt att titta på arkitekturen för Mistral 7B LLM, och vad som gör att den sticker ut.
Mistral 7B arkitektur
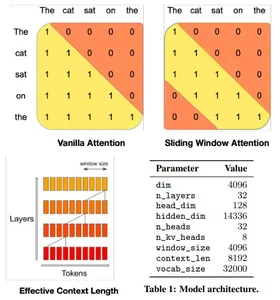
Mistral 7B-modellens transformatorarkitektur balanserar effektivt hög prestanda med minnesanvändning, genom att använda uppmärksamhetsmekanismer och cachingstrategier för att överträffa större modeller i hastighet och kvalitet. Den använder 4096-fönster Sliding Window Attention (SWA), som maximerar uppmärksamheten över längre sekvenser genom att tillåta varje token att ta hand om en undergrupp av prekursor-tokens, vilket optimerar uppmärksamheten över längre sekvenser.
Ett givet dolt lager kan komma åt tokens från indatalager på avstånd som bestäms av fönsterstorleken och lagerdjupet. Modellen integrerar modifieringar av Flash Attention och xFormers, vilket fördubblar hastigheten jämfört med traditionella uppmärksamhetsmekanismer. Dessutom bibehåller en Rolling Buffer Cache-mekanism en fast cachestorlek för effektiv minnesanvändning.
Mistral 7B i Google Colab
Låt oss djupdyka i koden och titta på slutsatser med Mistral 7B-modellen i Google Colab. Vi kommer att använda gratisversionen med en enda T4 GPU och ladda modellen från Kramar ansikte.
1. Installera och importera ctransformers-biblioteket i Colab.
#intsall ctransformers
pip install ctransformers[cuda] #import
from ctransformers import AutoModelForCausalLM2. Initiera modellobjektet från Hugging Face och ställ in nödvändiga parametrar. Vi kommer att använda en annan version av modellen eftersom originalmodellen från Mistral AI kan ha problem med att ladda hela modellen i minnet på Google Colab.
#load the model from huggingface with 50 gpu layers
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF", model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf", model_type = "mistral", gpu_layers = 50)3. Definiera en funktion för att skriva ut resultaten vertikalt i Google Colab. Det här steget kan hoppas över eller ändras om det körs i en annan miljö.
#function to print the model output in colab in a readable manner
def colab_print(text, max_width = 120): words = text.split() line = "" for word in words: if len(line) + len(word) + 1 > max_width: print(line) line = "" line += word + " " print (line)4. Generera text med hjälp av modellen och se resultatet. Ändra parametrarna för att ändra kvaliteten på den genererade texten.
#generate text
colab_print(llm('''Give me a well-written paragraph in 5 sentences about a Senior Data Scientist (name - Suvojit) who writes blogs on LLMs on Analytics Vidhya. He studied Masters in AIML in BITS Pilani and works at AZ Company, with a total of 4 years of experience. Start the sentence with - Suvojit is a''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modellsvar: Suvojit är en Senior Data Scientist som har arbetat i 4 år på AZ-företaget som en del av deras team med fokus på design, implementering och förbättring av prediktiva modeller för konsumentbeteende i deras kunders varumärken och affärslinjer med hjälp av tekniker för maskininlärning med begränsad minne. Han skriver om LLM på Analytics Vidhya som hjälper honom att hålla sig uppdaterad med de senaste trenderna inom datavetenskap. Han har en magisterexamen i AIML från BITS Pilani, där han studerade maskininlärningsalgoritmer och deras tillämpningar. Suvojit brinner för att använda sin kunskap om datavetenskap för att hjälpa företag att fatta bättre beslut och förbättra sina resultat.
Användningsfall
Låt oss titta på några av användningsfallen för Mistral 7B mer detaljerat.
Översättning
Mistral 7B stöder flera språk för översättning. Låt oss titta på engelska till franska och spanska översättningar och kontrollera riktigheten.
#translate English to French
colab_print(llm('''Translate this text from English to French: "Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modellsvar: Översättningen skulle vara: "Suvojit est un scientifique des données sénior qui écrit des blogues sur Analytics Vidhya."
#tranlsate English to Spanish
colab_print(llm('''Translate this text from English to Spanish: "Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modellsvar: Översättningen skulle vara: "Suvojit es un Senior Data Científico que escribe blogs and Analytics Vidhya."
Sammanfattning
Använd Mistral 7B för att sammanfatta dokument till en kortare version med hjälp av lämpliga sammanfattningsinstruktioner.
#Define the prompt with instructions
prompt = '''[INST] You are a helpful code assistant. Your task is to summarize text into exactly two short sentences: Transformers have revolutionized the field of large language models with their ability to capture long-range dependencies and intricate patterns in text. Originating from the paper "Attention Is All You Need" by Vaswani et al. in 2017, transformers introduced the self-attention mechanism, which weighs input tokens differently based on their relevance to a given token. This mechanism enables transformers to process
information more flexibly than traditional RNNs or LSTMs. Consequently, models like GPT, BERT, and their subsequent iterations have been built on the transformer architecture, leading to breakthroughs in numerous natural language processing tasks. Their parallel processing capabilities further make them conducive to training on vast amounts of data. However, as these models grow in size, concerns about their environmental impact and computational demands also emerge. Despite these challenges, the transformative power of transformers in language models remains undeniable. Just summarize the text in exactly 2 short sentences without explanations:
[/INST]''' #Summarize
colab_print(llm(prompt, max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modellsvar: Transformatorer har revolutionerat stora språkmodeller genom att fånga långväga beroenden och intrikata mönster, introducerat en självuppmärksamhetsmekanism som gör att de bearbetar information flexibelt och efterföljande implementeringar inkluderar genombrott som GPT och BERT. Men när dessa modeller växer i storlek oro över deras miljöpåverkan och beräkningskrav uppstår, trots dessa utmaningar förblir de onekligen transformerande i språkmodellering.
Anpassade instruktioner
Vi kan använda taggen [INST] för att ändra användarinmatningen för att få ett speciellt svar från modellen. Till exempel kan vi generera en JSON baserat på textbeskrivning.
prompt = '''[INST] You are a helpful code assistant. Your task is to generate a valid JSON object based on the given information: My name is Suvojit Hore, working in company AB and my address is AZ Street NY. Just generate the JSON object without explanations:
[/INST] ''' colab_print(llm(prompt, max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modellsvar: “`json { “name”: “Suvojit Hore”, “company”: “AB”, “address”: “AZ Street NY” } “`
Finjustera Mistral 7B
Låt oss titta på hur vi kan finjustera modellen med en enda GPU på Google Colab. Vi kommer att använda en datauppsättning som konverterar beskrivningar på få ord om bilder till detaljerad och mycket beskrivande text. Dessa resultat kan användas i Midjourney för att generera den specifika bilden. Målet är att utbilda LLM att fungera som en snabb ingenjör för bildgenerering.
Ställ in miljön och importera nödvändiga bibliotek i Google Colab:
# Install the necessary libraries
!pip install pandas autotrain-advanced -q
!autotrain setup --update-torch
!pip install -q peft accelerate bitsandbytes safetensors #import the necesary libraries
import pandas as pd
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import transformers
from huggingface_hub import notebook_loginLogga in på Hugging Face från en webbläsare och kopiera åtkomsttoken. Använd denna token för att logga in på Hugging Face i anteckningsboken.
notebook_login()
Ladda upp datauppsättningen till Colab-sessionslagring. Vi kommer att använda datauppsättningen Midjourney.
df = pd.read_csv("prompt_engineering.csv")
df.head(5)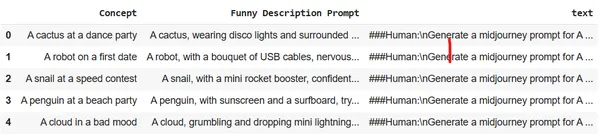
Träna modellen med hjälp av Autotrain med lämpliga parametrar. Ändra kommandot nedan för att köra det för ditt eget Huggin Face-repo och användaråtkomsttoken.
!autotrain llm --train --project_name mistral-7b-sh-finetuned --model username/Mistral-7B-Instruct-v0.1-sharded --token hf_yiguyfTFtufTFYUTUfuytfuys --data_path . --use_peft --use_int4 --learning_rate 2e-4 --train_batch_size 12 --num_train_epochs 3 --trainer sft --target_modules q_proj,v_proj --push_to_hub --repo_id username/mistral-7b-sh-finetunedLåt oss nu använda den finjusterade modellen för att köra inferensmotorn och generera några detaljerade beskrivningar av bilderna.
#adapter and model
adapters_name = "suvz47/mistral-7b-sh-finetuned"
model_name = "bn22/Mistral-7B-Instruct-v0.1-sharded" device = "cuda" #set the config
bnb_config = transformers.BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16
) #initialize the model
model = AutoModelForCausalLM.from_pretrained( model_name, load_in_4bit=True, torch_dtype=torch.bfloat16, quantization_config=bnb_config, device_map='auto'
)Ladda den finjusterade modellen och tokenizern.
#load the model and tokenizer
model = PeftModel.from_pretrained(model, adapters_name) tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.bos_token_id = 1 stop_token_ids = [0]Skapa en detaljerad och beskrivande Midjourney-prompt med bara några få ord.
#prompt
text = "[INST] generate a midjourney prompt in less than 20 words for A computer with an emotional chip [/INST]" #encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('nn')
print(decoded[0])Modellsvar: När datorn med ett känslochip börjar bearbeta sina känslor, börjar den ifrågasätta dess existens och syfte, vilket leder till en resa av självupptäckt och självförbättring.
#prompt
text = "[INST] generate a midjourney prompt in less than 20 words for A rainbow chasing its colors [/INST]" #encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('nn')
print(decoded[0])Modellsvar: En regnbåge som jagar färger befinner sig i en öken där himlen är ett hav av oändligt blått, och regnbågens färger är utspridda i sanden.
Slutsats
Mistral 7B har visat sig vara ett betydande framsteg inom området för stora språkmodeller. Dess effektiva arkitektur, i kombination med dess överlägsna prestanda, visar på dess potential att vara en bas för olika NLP-uppgifter i framtiden. Den här bloggen ger insikter i modellens arkitektur, dess tillämpning och hur man kan utnyttja dess kraft för specifika uppgifter som översättning, sammanfattning och finjustering för andra applikationer. Med rätt vägledning och experimenterande kunde Mistral 7B omdefiniera gränserna för vad som är möjligt med LLM.
Key Takeaways
- Mistral-7B-Instruct utmärker sig i prestanda trots färre parametrar.
- Den använder Sliding Window Attention för långsekvensoptimering.
- Funktioner som Flash Attention och xFormers fördubblar hastigheten.
- Rolling Buffer Cache säkerställer effektiv minneshantering.
- Mångsidig: Hanterar översättning, sammanfattning, strukturerad datagenerering, textgenerering och textkomplettering.
- Uppmaning att lägga till anpassade instruktioner kan hjälpa modellen att förstå frågan bättre och utföra flera komplexa språkuppgifter.
- Finjustera Mistral 7B för specifika språkuppgifter som att agera som en snabb ingenjör.
Vanliga frågor
A. Mistral-7B är designad för effektivitet och prestanda. Även om den har färre parametrar än vissa andra modeller, gör dess arkitektoniska framsteg, såsom Sliding Window Attention, att den kan leverera enastående resultat, till och med överträffa större modeller i specifika uppgifter.
S. Ja, Mistral-7B kan finjusteras för olika uppgifter. Guiden ger ett exempel på att finjustera modellen för att konvertera korta textbeskrivningar till detaljerade uppmaningar för bildgenerering.
S. Sliding Window Attention (SWA) gör att modellen kan hantera längre sekvenser effektivt. Med en fönsterstorlek på 4096 optimerar SWA uppmärksamhetsoperationer, vilket gör att Mistral-7B kan behandla långa texter utan att kompromissa med hastighet eller noggrannhet.
S. Ja, när du kör Mistral-7B-inferenser rekommenderar vi att du använder ctransformers-biblioteket, särskilt när du arbetar inom Google Colab. Du kan också ladda modellen från Hugging Face för extra bekvämlighet
S. Det är viktigt att skapa detaljerade instruktioner i inmatningsprompten. Mistral-7B:s mångsidighet gör det möjligt för den att förstå och följa dessa detaljerade instruktioner, vilket säkerställer korrekta och önskade utdata. Korrekt snabb konstruktion kan avsevärt förbättra modellens prestanda.
Referensprojekt
- Miniatyrbild – genererad med stabil diffusion
- Arkitektur – Papper
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/11/from-gpt-to-mistral-7b-the-exciting-leap-forward-in-ai-conversations/

