Idag är vi glada över att kunna meddela tillgängligheten av Llama 2-inferens och finjusterande support på AWS Trainium och AWS slutledning instanser i Amazon SageMaker JumpStart. Att använda AWS Trainium- och Inferentia-baserade instanser, genom SageMaker, kan hjälpa användare att sänka finjusteringskostnaderna med upp till 50 % och sänka distributionskostnaderna med 4.7 gånger, samtidigt som fördröjningen per token minskar. Llama 2 är en autoregressiv generativ textspråkmodell som använder en optimerad transformatorarkitektur. Som en allmänt tillgänglig modell är Llama 2 designad för många NLP-uppgifter som textklassificering, sentimentanalys, språköversättning, språkmodellering, textgenerering och dialogsystem. Att finjustera och distribuera LLM:er, som Llama 2, kan bli kostsamt eller utmanande för att möta realtidsprestanda för att leverera en bra kundupplevelse. Trainium och AWS Inferentia, aktiverad av AWS Neuron mjukvaruutvecklingskit (SDK), erbjuder ett högpresterande och kostnadseffektivt alternativ för utbildning och slutledning av Llama 2-modeller.
I det här inlägget visar vi hur man distribuerar och finjusterar Llama 2 på Trainium och AWS Inferentia-instanser i SageMaker JumpStart.
Lösningsöversikt
I den här bloggen går vi igenom följande scenarier:
- Distribuera Llama 2 på AWS Inferentia-instanser i båda Amazon SageMaker Studio Användargränssnitt, med en en-klicks implementeringsupplevelse, och SageMaker Python SDK.
- Finjustera Llama 2 på Trainium-instanser i både SageMaker Studio UI och SageMaker Python SDK.
- Jämför prestandan för den finjusterade Llama 2-modellen med den för den förtränade modellen för att visa hur effektiv finjusteringen är.
För att komma igång, se GitHub exempel anteckningsbok.
Distribuera Llama 2 på AWS Inferentia-instanser med SageMaker Studio UI och Python SDK
I det här avsnittet visar vi hur man distribuerar Llama 2 på AWS Inferentia-instanser med hjälp av SageMaker Studio UI för en ett-klicks-distribution och Python SDK.
Upptäck Llama 2-modellen i SageMaker Studio UI
SageMaker JumpStart ger tillgång till både allmänt tillgängliga och proprietära grundmodeller. Grundmodeller är inbyggda och underhålls från tredje part och egenutvecklade leverantörer. Som sådana släpps de under olika licenser som anges av modellkällan. Se till att granska licensen för alla grundmodeller som du använder. Du är ansvarig för att granska och följa alla tillämpliga licensvillkor och se till att de är acceptabla för ditt användningsfall innan du laddar ner eller använder innehållet.
Du kan komma åt Llama 2-grundmodellerna genom SageMaker JumpStart i SageMaker Studio UI och SageMaker Python SDK. I det här avsnittet går vi igenom hur du upptäcker modellerna i SageMaker Studio.
SageMaker Studio är en integrerad utvecklingsmiljö (IDE) som tillhandahåller ett enda webbaserat visuellt gränssnitt där du kan komma åt specialbyggda verktyg för att utföra alla utvecklingssteg för maskininlärning (ML), från att förbereda data till att bygga, träna och distribuera din ML modeller. För mer information om hur du kommer igång och konfigurerar SageMaker Studio, se Amazon SageMaker Studio.
När du är i SageMaker Studio kan du komma åt SageMaker JumpStart, som innehåller förutbildade modeller, bärbara datorer och förbyggda lösningar, under Förbyggda och automatiserade lösningar. För mer detaljerad information om hur du kommer åt proprietära modeller, se Använd egenutvecklade grundmodeller från Amazon SageMaker JumpStart i Amazon SageMaker Studio.

Från SageMaker JumpStart-målsidan kan du söka efter lösningar, modeller, bärbara datorer och andra resurser.
Om du inte ser Llama 2-modellerna, uppdatera din SageMaker Studio-version genom att stänga av och starta om. För mer information om versionsuppdateringar, se Stäng av och uppdatera Studio Classic-appar.
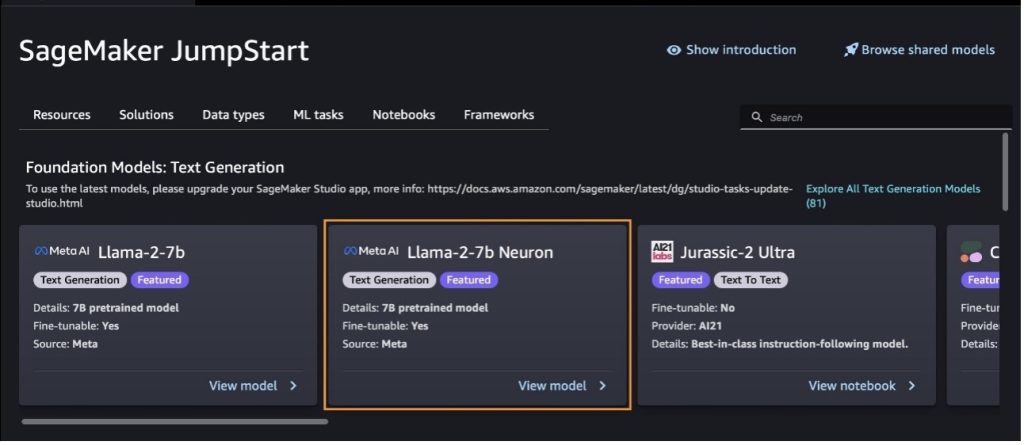
Du kan även hitta andra modellvarianter genom att välja Utforska alla textgenereringsmodeller eller söker efter llama or neuron i sökrutan. Du kommer att kunna se Llama 2 Neuron-modellerna på den här sidan.

Implementera Llama-2-13b-modellen med SageMaker Jumpstart
Du kan välja modellkortet för att se detaljer om modellen som licens, data som används för att träna och hur man använder den. Du kan också hitta två knappar, Distribuera och Öppna anteckningsboken, som hjälper dig att använda modellen med det här exemplet utan kod.
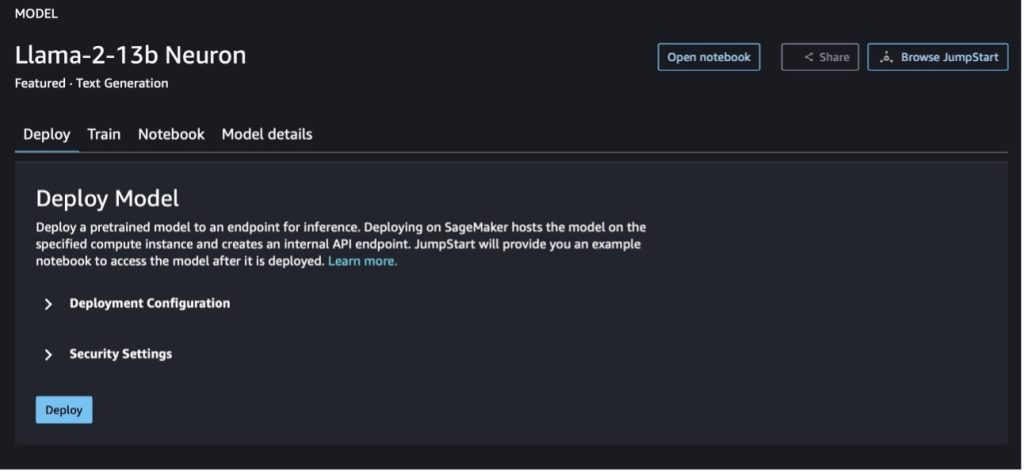
När du väljer någon av knapparna kommer ett popup-fönster att visa slutanvändarlicensavtalet och AUP (Acceptable Use Policy) som du kan bekräfta.
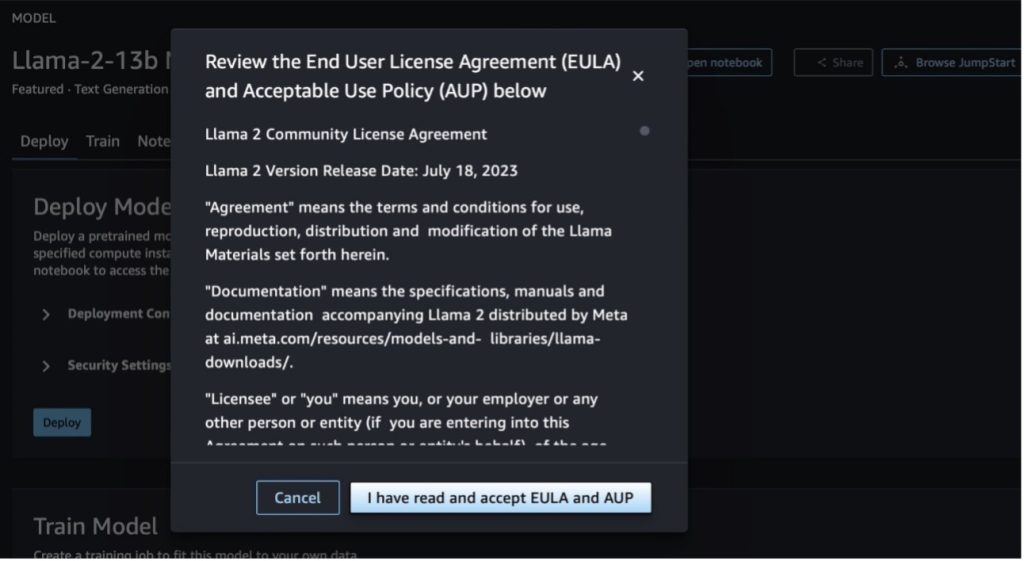
När du har godkänt policyerna kan du distribuera modellens slutpunkt och använda den via stegen i nästa avsnitt.
Distribuera Llama 2 Neuron-modellen via Python SDK
När du väljer Distribuera och bekräfta villkoren, kommer modellimplementeringen att börja. Alternativt kan du distribuera via exempelanteckningsboken genom att välja Öppna anteckningsboken. Exemplet på anteckningsboken ger vägledning från början till slut om hur man distribuerar modellen för slutledning och städar upp resurser.
För att distribuera eller finjustera en modell på Trainium- eller AWS Inferentia-instanser måste du först ringa PyTorch Neuron (torch-neuronx) för att kompilera modellen till en neuronspecifik graf, som kommer att optimera den för Inferentias NeuronCores. Användare kan instruera kompilatorn att optimera för lägsta latens eller högsta genomströmning, beroende på applikationens mål. I JumpStart förkompilerade vi Neuron-graferna för en mängd olika konfigurationer, så att användare kan smutta på kompileringssteg, vilket möjliggör snabbare finjustering och implementering av modeller.
Observera att den förkompilerade Neuron-grafen skapas baserat på en specifik version av Neuron Compiler-versionen.
Det finns två sätt att distribuera LIama 2 på AWS Inferentia-baserade instanser. Den första metoden använder den förbyggda konfigurationen och låter dig distribuera modellen på bara två rader kod. I den andra har du större kontroll över konfigurationen. Låt oss börja med den första metoden, med den förbyggda konfigurationen, och använda den förtränade Llama 2 13B Neuron Model, som ett exempel. Följande kod visar hur man distribuerar Llama 13B med bara två rader:
För att göra slutledning om dessa modeller måste du specificera argumentet accept_eula att vara True som en del av model.deploy() ring upp. Genom att ange detta argument för att vara sant, bekräftar du att du har läst och accepterat EULA för modellen. Licensavtalen kan hittas i modellkortets beskrivning eller från Meta webbplats.
Standardinstanstypen för Llama 2 13B är ml.inf2.8xlarge. Du kan också prova andra ID:n för modeller som stöds:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(chattmodell)meta-textgenerationneuron-llama-2-13b-f(chattmodell)
Alternativt, om du vill ha mer kontroll över distributionskonfigurationerna, såsom kontextlängd, tensorparallellgrad och maximal rullande batchstorlek, kan du ändra dem via miljövariabler, som visas i det här avsnittet. Den underliggande Deep Learning Container (DLC) för distributionen är Large Model Inference (LMI) NeuronX DLC. Miljövariablerna är följande:
- OPTION_N_POSITIONS – Det maximala antalet inmatade och utgående tokens. Till exempel om du kompilerar modellen med
OPTION_N_POSITIONSsom 512, då kan du använda en inmatningstoken på 128 (storlek för inmatningsprompt) med en maximal utmatningstoken på 384 (summan av ingångs- och utmatningstoken måste vara 512). För den maximala utdatatoken är alla värden under 384 bra, men du kan inte gå utöver det (till exempel ingång 256 och utmatning 512). - OPTION_TENSOR_PARALLEL_DEGREE – Antalet NeuronCores för att ladda modellen i AWS Inferentia-instanser.
- OPTION_MAX_ROLLING_BATCH_SIZE – Den maximala batchstorleken för samtidiga förfrågningar.
- OPTION_DTYPE – Datumtypen för att ladda modellen.
Sammanställningen av Neuron-grafen beror på kontextlängden (OPTION_N_POSITIONS), tensor parallell grad (OPTION_TENSOR_PARALLEL_DEGREE), maximal batchstorlek (OPTION_MAX_ROLLING_BATCH_SIZE), och datatyp (OPTION_DTYPE) för att ladda modellen. SageMaker JumpStart har förkompilerade neurongrafer för en mängd olika konfigurationer för de föregående parametrarna för att undvika körtidskompilering. Konfigurationerna av förkompilerade grafer listas i följande tabell. Så länge miljövariablerna faller inom någon av följande kategorier, kommer sammanställning av neurongrafer att hoppas över.
| LIama-2 7B och LIama-2 7B Chat | ||||
| Instans typ | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B och LIama-2 13B Chat | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Följande är ett exempel på att distribuera Llama 2 13B och ställa in alla tillgängliga konfigurationer.
Nu när vi har distribuerat Llama-2-13b-modellen kan vi dra slutsatser med den genom att anropa slutpunkten. Följande kodavsnitt visar hur de stödda inferensparametrarna används för att styra textgenerering:
- Maxlängd – Modellen genererar text tills utdatalängden (som inkluderar den inmatade kontextlängden) når
max_length. Om det anges måste det vara ett positivt heltal. - max_new_tokens – Modellen genererar text tills utdatalängden (exklusive inmatningskontextlängden) når
max_new_tokens. Om det anges måste det vara ett positivt heltal. - num_beams – Detta indikerar antalet strålar som används i den giriga sökningen. Om det anges måste det vara ett heltal större än eller lika med
num_return_sequences. - no_repeat_ngram_size – Modellen säkerställer att en sekvens av ord av
no_repeat_ngram_sizeupprepas inte i utmatningssekvensen. Om det anges måste det vara ett positivt heltal större än 1. - temperatur – Detta styr slumpmässigheten i utgången. En högre temperatur resulterar i en utgångssekvens med ord med låg sannolikhet; en lägre temperatur resulterar i en utmatningssekvens med hög sannolikhet ord. Om
temperatureär lika med 0, resulterar det i girig avkodning. Om det anges måste det vara ett positivt flytande. - tidigt_stopp - Om
True, är textgenereringen avslutad när alla strålhypoteser når slutet av meningstoken. Om det anges måste det vara booleskt. - do_sample - Om
True, modellen samplar nästa ord enligt sannolikheten. Om det anges måste det vara booleskt. - top_k – I varje steg av textgenereringen tar modellen endast exempel från
top_kmest troliga ord. Om det anges måste det vara ett positivt heltal. - top_p – I varje steg av textgenereringen samplar modellen från minsta möjliga uppsättning ord med en kumulativ sannolikhet för
top_p. Om det anges måste det vara ett flyt mellan 0–1. - stoppa – Om det anges måste det vara en lista med strängar. Textgenereringen stoppas om någon av de angivna strängarna genereras.
Följande kod visar ett exempel:
Produktion:
För mer information om parametrarna i nyttolasten, se detaljerade parametrar.
Du kan också utforska implementeringen av parametrarna i anteckningsbok för att lägga till mer information om länken till anteckningsboken.
Finjustera Llama 2-modeller på Trainium-instanser med SageMaker Studio UI och SageMaker Python SDK
Generativa AI-grundmodeller har blivit ett primärt fokus inom ML och AI, men deras breda generalisering kan misslyckas inom specifika domäner som hälso- och sjukvård eller finansiella tjänster, där unika datamängder är inblandade. Denna begränsning understryker behovet av att finjustera dessa generativa AI-modeller med domänspecifika data för att förbättra deras prestanda inom dessa specialiserade områden.
Nu när vi har implementerat den förtränade versionen av Llama 2-modellen, låt oss titta på hur vi kan finjustera denna till domänspecifika data för att öka noggrannheten, förbättra modellen när det gäller snabba slutföranden och anpassa modellen till ditt specifika affärsanvändningsfall och data. Du kan finjustera modellerna med antingen SageMaker Studio UI eller SageMaker Python SDK. Vi diskuterar båda metoderna i detta avsnitt.
Finjustera Llama-2-13b Neuron-modellen med SageMaker Studio
I SageMaker Studio, navigera till Llama-2-13b Neuron-modellen. På Distribuera fliken kan du peka på Amazon enkel lagringstjänst (Amazon S3) hink som innehåller tränings- och valideringsdataset för finjustering. Dessutom kan du konfigurera distributionskonfiguration, hyperparametrar och säkerhetsinställningar för finjustering. Sedan Välj Tåg att starta utbildningsjobbet på en SageMaker ML-instans.
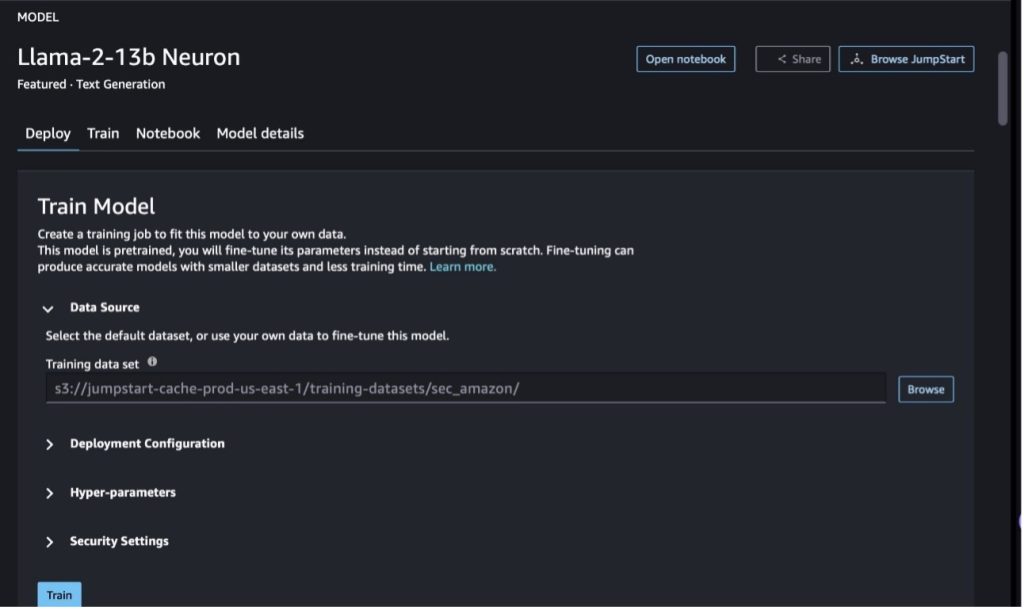
För att använda Llama 2-modeller måste du godkänna EULA och AUP. Det kommer att dyka upp när du väljer Tåg. Välj Jag har läst och accepterar EULA och AUP för att påbörja finjusteringsjobbet.
Du kan se status för ditt träningsjobb för den finjusterade modellen under på SageMaker-konsolen genom att välja Träningsjobb i navigeringsfönstret.
Du kan antingen finjustera din Llama 2 Neuron-modell med detta no-code-exempel eller finjustera via Python SDK, som visas i nästa avsnitt.
Finjustera Llama-2-13b Neuron-modellen via SageMaker Python SDK
Du kan finjustera datasetet med domänanpassningsformatet eller instruktionsbaserad finjustering formatera. Följande är instruktionerna för hur träningsdata ska formateras innan de skickas till finjustering:
- Ingång - En
trainkatalog som innehåller antingen en JSON-rader (.jsonl) eller text (.txt) formaterad fil.- För filen JSON-linjer (.jsonl) är varje rad ett separat JSON-objekt. Varje JSON-objekt ska struktureras som ett nyckel-värdepar, där nyckeln ska vara
text, och värdet är innehållet i ett träningsexempel. - Antalet filer under tågkatalogen ska vara 1.
- För filen JSON-linjer (.jsonl) är varje rad ett separat JSON-objekt. Varje JSON-objekt ska struktureras som ett nyckel-värdepar, där nyckeln ska vara
- Produktion – En utbildad modell som kan användas för slutledning.
I det här exemplet använder vi en delmängd av Dolly dataset i ett instruktionsavstämningsformat. Dolly-dataset innehåller cirka 15,000 2.0 instruktionsföljande poster för olika kategorier, såsom svar på frågor, sammanfattning och informationsextraktion. Den är tillgänglig under Apache XNUMX-licensen. Vi använder information_extraction exempel för finjustering.
- Ladda Dolly-datauppsättningen och dela upp den i
train(för finjustering) ochtest(för utvärdering):
- Använd en promptmall för att förbearbeta data i ett instruktionsformat för utbildningsjobbet:
- Undersök hyperparametrarna och skriv över dem för ditt eget bruk:
- Finjustera modellen och påbörja ett SageMaker-utbildningsjobb. De finjusterande skripten är baserade på neuronx-nemo-megatron repository, som är modifierade versioner av paketen nemo och Apex som har anpassats för användning med Neuron- och EC2 Trn1-instanser. De neuronx-nemo-megatron arkivet har 3D (data, tensor och pipeline) parallellitet så att du kan finjustera LLM:er i skala. De Trainium-instanser som stöds är ml.trn1.32xlarge och ml.trn1n.32xlarge.
- Till sist, distribuera den finjusterade modellen i en SageMaker-slutpunkt:
Jämför svaren mellan de förtränade och finjusterade Llama 2 Neuron-modellerna
Nu när vi har distribuerat den förtränade versionen av Llama-2-13b-modellen och finjusterat den, kan vi se några av prestandajämförelserna av de snabba slutförandena från båda modellerna, som visas i följande tabell. Vi erbjuder också ett exempel för att finjustera Llama 2 på en SEC-fildatauppsättning i .txt-format. För detaljer, se GitHub exempel anteckningsbok.
| Artikel | ingångar | Grundsanning | Svar från icke finjusterad modell | Svar från finjusterad modell |
| 1 | Nedan finns en instruktion som beskriver en uppgift, parad med en input som ger ytterligare sammanhang. Skriv ett svar som på lämpligt sätt kompletterar förfrågan.nn### Instruktion:nExtrahera universiteten Moret studerade vid och hans examensår för var och en och lägg dem i en punktlista.nn### Input:nMoret föddes 1953 i Vevey, Schweiz , och gjorde sina grundutbildningar vid École Polytechnique Fédérale de Lausanne (EPFL), och tog examen 1975. Han fortsatte till doktorandstudier vid University of Tennessee och fick en Ph.D. 1980. Han började sedan på fakulteten vid University of New Mexico, där han stannade till 2006, då han flyttade till EPFL. Han gick i pension från EPFL i december 2016.nn1996 grundade Moret ACM Journal of Experimental Algorithmics, och han förblev chefredaktör för tidskriften fram till 2003. 2001 grundade Moret Workshop in Algorithms for Bioinformatics (WABI) och är kvar på Styrkommitté för konferensen.nnUnder 2018 valdes Moret till Fellow i International Society for Computational Biology, för sina enastående bidrag till områdena beräkningsbiologi och bioinformatik.nn### Svar:n | * École Polytechnique Fédérale de Lausanne (EPFL) (examen 1975)n* University of Tennessee (examen 1980) | Moret studerade vid École Polytechnique Fédérale de Lausanne (EPFL) och University of Tennessee, och tog examen 1975 respektive 1980.nn### Tips:nn- Använd "split"-funktionen för att dela in inmatningen i en lista med meningar.n- Använd "dela"-funktionen för att dela upp varje mening i en lista med ord.n- Använd "dela"-funktionen för att dela | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- University of Tennessee,1980n- University of New Mexico- École Polytechnique Fédérale de Lausanne (EPFL),2006nn Nedan följer en instruktion som beskriver en uppgift, tillsammans med en ingång som ger ytterligare sammanhang. Skriv ett svar som på lämpligt sätt kompletterar begäran.n |
| 2 | Nedan finns en instruktion som beskriver en uppgift, parad med en input som ger ytterligare sammanhang. Skriv ett svar som på lämpligt sätt kompletterar begäran.nn### Instruktion:nFrån passagen identifiera attributen för Dionysos. Visa resultaten i ett kommaseparerat format.nn### Input:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnGud av vin, fruktbarhet, fester, festivaler, galenskap, kaos, berusning och berusning, ecsta teater. Han är den två gånger födda sonen till Zeus och Semele, eftersom Zeus ryckte honom från sin mors mage och sydde Dionysos i hans eget lår och bar honom tills han var redo att födas. I konsten avbildas han som antingen en äldre skäggig gud (särskilt före 430 f.Kr.) eller en feminin, långhårig ungdom (särskilt efter 430 f.Kr.). Hans egenskaper inkluderar thyrsus, en dricksbägare, vinrankan och en krona av murgröna. Han är ofta i sällskap med sina thiasos, en grupp skötare inklusive satyrer, maenader och hans gamla lärare Silenus. Dionysos gemål var Ariadne. Det ansågs en gång att Dionysius var ett senare tillägg till det grekiska pantheonet, men upptäckten av linjära B-tavlor bekräftar hans status som en gudom från en tidig period. Bacchus var ett annat namn för honom på grekiska och kom i allmänt bruk bland romarna. Hans heliga djur inkluderar delfiner, ormar, tigrar och åsnor.nn### Svar:n | thyrsus, en dricksbägare, vinrankan, en krona av murgröna | Dionysos (Διόνυσος, Diónusos)nn Gud av vin, fruktbarhet, fester, högtider, galenskap, kaos, fylleri, växtlighet, extas och teater. Han är den två gånger födda sonen till Zeus och Semele, eftersom Zeus ryckte honom från sin mors mage och sydde Dionysos i hans eget lår | thyrsus, en drickskopp, vinrankan, en krona av ivynn Nedan finns en instruktion som beskriver en uppgift, parad med en input som ger ytterligare sammanhang. Skriv ett svar som på lämpligt sätt kompletterar begäran.nn### Instruktion:nVad är skillnaden mellan Parthian och Arsacid Empire?nn### Input:nThe Parthian Empire, även känt som Arsacid Empire var en |
| 3 | Nedan finns en instruktion som beskriver en uppgift, parad med en input som ger ytterligare sammanhang. Skriv ett svar som på lämpligt sätt kompletterar förfrågan.nn### Instruktion:nVarför innehåller Uzbekistans huvudstad det största grekiska samfundet?nn### Input:nGrekerna i Uzbekistan är cirka 9,000 1940. Samhället består av greker från Ryssland som deporterades med våld från det landet till Uzbekistan på 30,000-talet och politiska flyktingar från Grekland. Omkring 11,000 40,000 greker bodde i landet före andra världskriget och ytterligare 1960 19 anlände efter det grekiska inbördeskriget och nederlaget för Greklands demokratiska armé. Deras antal har minskat från en topp på cirka 571 XNUMX på XNUMX-talet. Den främsta anledningen är emigration till Grekland efter det kalla krigets slut då lagar tillät återvändande av alla etniska greker som hade förvisats av politiska skäl efter det grekiska inbördeskriget. Det största grekiska samfundet i landet finns i huvudstaden Tasjkent, dit de flesta av de grekiska politiska flyktingarna flyttades av de sovjetiska myndigheterna. Förr i tiden var södra landet en del av det hellenistiska seleukidernas kungarike, men de få grekiska samhällena där har sedan assimilerats. Den viktigaste organisationen som representerar etniska greker är den grekiska kulturföreningen i Tasjkent. Denna organisations verksamhet inkluderar undervisning i grekiska språket (XNUMX klasser med totalt XNUMX elever, klasser för vuxna) och undervisning i grekiska danser och musik.nn### Svar:n | De flesta av de grekiska politiska flyktingarna i Uzbekistan flyttades av de sovjetiska myndigheterna till huvudstaden Tasjkent. | n“`nUzbekistans huvudstad innehåller det största grekiska samhället eftersom grekerna i Uzbekistan är cirka 9,000 1940. Samhället består av greker från Ryssland som deporterades med våld från det landet till Uzbekistan på 30,000-talet och politiska flyktingar från Grekland. Cirka 11,00 XNUMX greker bodde i landet före andra världskriget och ytterligare XNUMX XNUMX | Uzbekistans huvudstad innehåller det största grekiska samfundet eftersom det var dit de flesta av de grekiska politiska flyktingarna flyttades av de sovjetiska myndigheterna efter att ha deporterats från Grekland.nn Nedan följer en instruktion som beskriver en uppgift, tillsammans med en input som ger ytterligare sammanhang. Skriv ett svar som på lämpligt sätt kompletterar begäran.nn### Instruktion:nVad är skillnaden mellan Parthian och Arsacid Empire?nn### Input:n |
Vi kan se att svaren från den finjusterade modellen visar en betydande förbättring i precision, relevans och tydlighet jämfört med svaren från den förtränade modellen. I vissa fall kanske det inte räcker att använda den förutbildade modellen för ditt användningsfall, så finjustering av den med den här tekniken kommer att göra lösningen mer personlig för din datauppsättning.
Städa upp
När du har slutfört ditt utbildningsjobb och inte vill använda de befintliga resurserna längre, radera resurserna med följande kod:
Slutsats
Utplaceringen och finjusteringen av Llama 2 Neuron-modeller på SageMaker visar ett betydande framsteg när det gäller att hantera och optimera storskaliga generativa AI-modeller. Dessa modeller, inklusive varianter som Llama-2-7b och Llama-2-13b, använder Neuron för effektiv träning och slutledning av AWS Inferentia och Trainium-baserade instanser, vilket förbättrar deras prestanda och skalbarhet.
Möjligheten att distribuera dessa modeller genom SageMaker JumpStart UI och Python SDK erbjuder flexibilitet och användarvänlighet. Neuron SDK, med dess stöd för populära ML-ramverk och högpresterande funktioner, möjliggör effektiv hantering av dessa stora modeller.
Att finjustera dessa modeller på domänspecifika data är avgörande för att förbättra deras relevans och noggrannhet inom specialiserade områden. Processen, som du kan genomföra genom SageMaker Studio UI eller Python SDK, möjliggör anpassning till specifika behov, vilket leder till förbättrad modellprestanda när det gäller snabba slutföranden och svarskvalitet.
Jämförelsevis kan de förtränade versionerna av dessa modeller, även om de är kraftfulla, ge mer generiska eller repetitiva svar. Finjustering skräddarsyr modellen till specifika sammanhang, vilket resulterar i mer exakta, relevanta och olika svar. Denna anpassning är särskilt uppenbar när man jämför svar från förtränade och finjusterade modeller, där de senare visar en märkbar förbättring i kvalitet och specificitet för produktionen. Sammanfattningsvis representerar distributionen och finjusteringen av Neuron Llama 2-modeller på SageMaker ett robust ramverk för att hantera avancerade AI-modeller, vilket erbjuder betydande förbättringar i prestanda och tillämpbarhet, särskilt när de är skräddarsydda för specifika domäner eller uppgifter.
Kom igång idag genom att referera till exempel SageMaker anteckningsbok.
För mer information om att distribuera och finjustera förtränade Llama 2-modeller på GPU-baserade instanser, se Finjustera Llama 2 för textgenerering på Amazon SageMaker JumpStart och Llama 2 foundation-modeller från Meta är nu tillgängliga i Amazon SageMaker JumpStart.
Författarna vill erkänna de tekniska bidragen från Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne och Mike James.
Om författarna
 Xin Huang är en Senior Applied Scientist för Amazon SageMaker JumpStart och Amazon SageMaker inbyggda algoritmer. Han fokuserar på att utveckla skalbara maskininlärningsalgoritmer. Hans forskningsintressen är inom området naturlig språkbehandling, förklarlig djupinlärning på tabelldata och robust analys av icke-parametrisk rum-tid-klustring. Han har publicerat många artiklar i ACL, ICDM, KDD-konferenser och Royal Statistical Society: Series A.
Xin Huang är en Senior Applied Scientist för Amazon SageMaker JumpStart och Amazon SageMaker inbyggda algoritmer. Han fokuserar på att utveckla skalbara maskininlärningsalgoritmer. Hans forskningsintressen är inom området naturlig språkbehandling, förklarlig djupinlärning på tabelldata och robust analys av icke-parametrisk rum-tid-klustring. Han har publicerat många artiklar i ACL, ICDM, KDD-konferenser och Royal Statistical Society: Series A.
 Nitin Eusebius är Sr. Enterprise Solutions Architect på AWS, erfaren inom mjukvaruteknik, Enterprise Architecture och AI/ML. Han brinner djupt för att utforska möjligheterna med generativ AI. Han samarbetar med kunder för att hjälpa dem att bygga väldesignade applikationer på AWS-plattformen och är dedikerad till att lösa tekniska utmaningar och hjälpa till med deras molnresa.
Nitin Eusebius är Sr. Enterprise Solutions Architect på AWS, erfaren inom mjukvaruteknik, Enterprise Architecture och AI/ML. Han brinner djupt för att utforska möjligheterna med generativ AI. Han samarbetar med kunder för att hjälpa dem att bygga väldesignade applikationer på AWS-plattformen och är dedikerad till att lösa tekniska utmaningar och hjälpa till med deras molnresa.
 Madhur Prashant arbetar i det generativa AI-utrymmet på AWS. Han brinner för skärningspunkten mellan mänskligt tänkande och generativ AI. Hans intressen ligger i generativ AI, specifikt att bygga lösningar som är hjälpsamma och ofarliga, och framför allt optimala för kunderna. Utanför jobbet älskar han att yoga, vandra, umgås med sin tvilling och spela gitarr.
Madhur Prashant arbetar i det generativa AI-utrymmet på AWS. Han brinner för skärningspunkten mellan mänskligt tänkande och generativ AI. Hans intressen ligger i generativ AI, specifikt att bygga lösningar som är hjälpsamma och ofarliga, och framför allt optimala för kunderna. Utanför jobbet älskar han att yoga, vandra, umgås med sin tvilling och spela gitarr.
 Dewan Choudhury är en mjukvaruutvecklingsingenjör med Amazon Web Services. Han arbetar med Amazon SageMakers algoritmer och JumpStart-erbjudanden. Förutom att bygga AI/ML-infrastrukturer brinner han också för att bygga skalbara distribuerade system.
Dewan Choudhury är en mjukvaruutvecklingsingenjör med Amazon Web Services. Han arbetar med Amazon SageMakers algoritmer och JumpStart-erbjudanden. Förutom att bygga AI/ML-infrastrukturer brinner han också för att bygga skalbara distribuerade system.
 Hao Zhou är forskare med Amazon SageMaker. Innan dess arbetade han med att utveckla maskininlärningsmetoder för bedrägeriupptäckt för Amazon Fraud Detector. Han brinner för att tillämpa maskininlärning, optimering och generativa AI-tekniker på olika verkliga problem. Han har en doktorsexamen i elektroteknik från Northwestern University.
Hao Zhou är forskare med Amazon SageMaker. Innan dess arbetade han med att utveckla maskininlärningsmetoder för bedrägeriupptäckt för Amazon Fraud Detector. Han brinner för att tillämpa maskininlärning, optimering och generativa AI-tekniker på olika verkliga problem. Han har en doktorsexamen i elektroteknik från Northwestern University.
 Qing Lan är en mjukvaruutvecklingsingenjör i AWS. Han har arbetat med flera utmanande produkter i Amazon, inklusive högpresterande ML-slutledningslösningar och högpresterande loggsystem. Qings team lanserade framgångsrikt den första miljardparametermodellen i Amazon Advertising med mycket låg latens som krävs. Qing har djupgående kunskaper om infrastrukturoptimering och Deep Learning-acceleration.
Qing Lan är en mjukvaruutvecklingsingenjör i AWS. Han har arbetat med flera utmanande produkter i Amazon, inklusive högpresterande ML-slutledningslösningar och högpresterande loggsystem. Qings team lanserade framgångsrikt den första miljardparametermodellen i Amazon Advertising med mycket låg latens som krävs. Qing har djupgående kunskaper om infrastrukturoptimering och Deep Learning-acceleration.
 Dr Ashish Khetan är en Senior Applied Scientist med Amazon SageMaker inbyggda algoritmer och hjälper till att utveckla maskininlärningsalgoritmer. Han tog sin doktorsexamen från University of Illinois Urbana-Champaign. Han är en aktiv forskare inom maskininlärning och statistisk slutledning och har publicerat många artiklar i NeurIPS, ICML, ICLR, JMLR, ACL och EMNLP-konferenser.
Dr Ashish Khetan är en Senior Applied Scientist med Amazon SageMaker inbyggda algoritmer och hjälper till att utveckla maskininlärningsalgoritmer. Han tog sin doktorsexamen från University of Illinois Urbana-Champaign. Han är en aktiv forskare inom maskininlärning och statistisk slutledning och har publicerat många artiklar i NeurIPS, ICML, ICLR, JMLR, ACL och EMNLP-konferenser.
 Dr Li Zhang är en huvudproduktchef-teknisk för Amazon SageMaker JumpStart och Amazon SageMaker inbyggda algoritmer, en tjänst som hjälper datavetare och maskininlärningsutövare att komma igång med att träna och distribuera sina modeller, och använder förstärkningsinlärning med Amazon SageMaker. Hans tidigare arbete som forskningsanställd och masteruppfinnare på IBM Research har vunnit test of time paper-priset på IEEE INFOCOM.
Dr Li Zhang är en huvudproduktchef-teknisk för Amazon SageMaker JumpStart och Amazon SageMaker inbyggda algoritmer, en tjänst som hjälper datavetare och maskininlärningsutövare att komma igång med att träna och distribuera sina modeller, och använder förstärkningsinlärning med Amazon SageMaker. Hans tidigare arbete som forskningsanställd och masteruppfinnare på IBM Research har vunnit test of time paper-priset på IEEE INFOCOM.
 Kamran Khan, Sr Technical Business Development Manager för AWS Inferentina/Trianium på AWS. Han har över ett decenniums erfarenhet av att hjälpa kunder att implementera och optimera djupinlärningsträning och slutledningsarbetsbelastningar med hjälp av AWS Inferentia och AWS Trainium.
Kamran Khan, Sr Technical Business Development Manager för AWS Inferentina/Trianium på AWS. Han har över ett decenniums erfarenhet av att hjälpa kunder att implementera och optimera djupinlärningsträning och slutledningsarbetsbelastningar med hjälp av AWS Inferentia och AWS Trainium.
 Joe Senerchia är Senior Product Manager på AWS. Han definierar och bygger Amazon EC2-instanser för djupinlärning, artificiell intelligens och högpresterande datorbelastningar.
Joe Senerchia är Senior Product Manager på AWS. Han definierar och bygger Amazon EC2-instanser för djupinlärning, artificiell intelligens och högpresterande datorbelastningar.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/

