Amazon Titan lmage Generator G1 är en banbrytande text-till-bild-modell, tillgänglig via Amazonas berggrund, som kan förstå uppmaningar som beskriver flera objekt i olika sammanhang och fångar dessa relevanta detaljer i bilderna den genererar. Den är tillgänglig i AWS-regionerna i USA East (N. Virginia) och US West (Oregon) och kan utföra avancerade bildredigeringsuppgifter som smart beskärning, in-painting och bakgrundsändringar. Användare skulle dock vilja anpassa modellen till unika egenskaper i anpassade datamängder som modellen inte redan är utbildad på. Anpassade datauppsättningar kan inkludera mycket proprietära data som överensstämmer med dina varumärkesriktlinjer eller specifika stilar som en tidigare kampanj. För att hantera dessa användningsfall och generera helt personliga bilder kan du finjustera Amazon Titan Image Generator med dina egna data med hjälp av anpassade modeller för Amazon Bedrock.
Från att skapa bilder till att redigera dem, text-till-bild-modeller har breda tillämpningar inom olika branscher. De kan öka medarbetarnas kreativitet och ge möjligheten att föreställa sig nya möjligheter helt enkelt med textbeskrivningar. Det kan till exempel underlätta design och golvplanering för arkitekter och tillåta snabbare innovation genom att ge möjligheten att visualisera olika design utan den manuella processen att skapa dem. På samma sätt kan det hjälpa till med design inom olika branscher som tillverkning, modedesign inom detaljhandeln och speldesign genom att effektivisera genereringen av grafik och illustrationer. Text-till-bild-modeller förbättrar också din kundupplevelse genom att möjliggöra personlig reklam samt interaktiva och uppslukande visuella chatbots i media och underhållning.
I det här inlägget guidar vi dig genom processen med att finjustera Amazon Titan Image Generator-modellen för att lära dig två nya kategorier: hunden Ron och katten Smila, våra favorithusdjur. Vi diskuterar hur du förbereder din data för modellfinjusteringsuppgiften och hur du skapar ett modellanpassningsjobb i Amazon Bedrock. Slutligen visar vi dig hur du testar och distribuerar din finjusterade modell med Provisioned throughput.
 |
 |
| Hunden Ron | Katten Smila |
Utvärdera modellkapacitet innan du finjusterar ett jobb
Grundmodeller tränas på stora mängder data, så det är möjligt att din modell kommer att fungera tillräckligt bra ur lådan. Det är därför det är bra att kontrollera om du verkligen behöver finjustera din modell för ditt användningsfall eller om snabb ingenjörskonst är tillräcklig. Låt oss försöka skapa några bilder av hunden Ron och katten Smila med basmodellen Amazon Titan Image Generator, som visas i följande skärmdumpar.
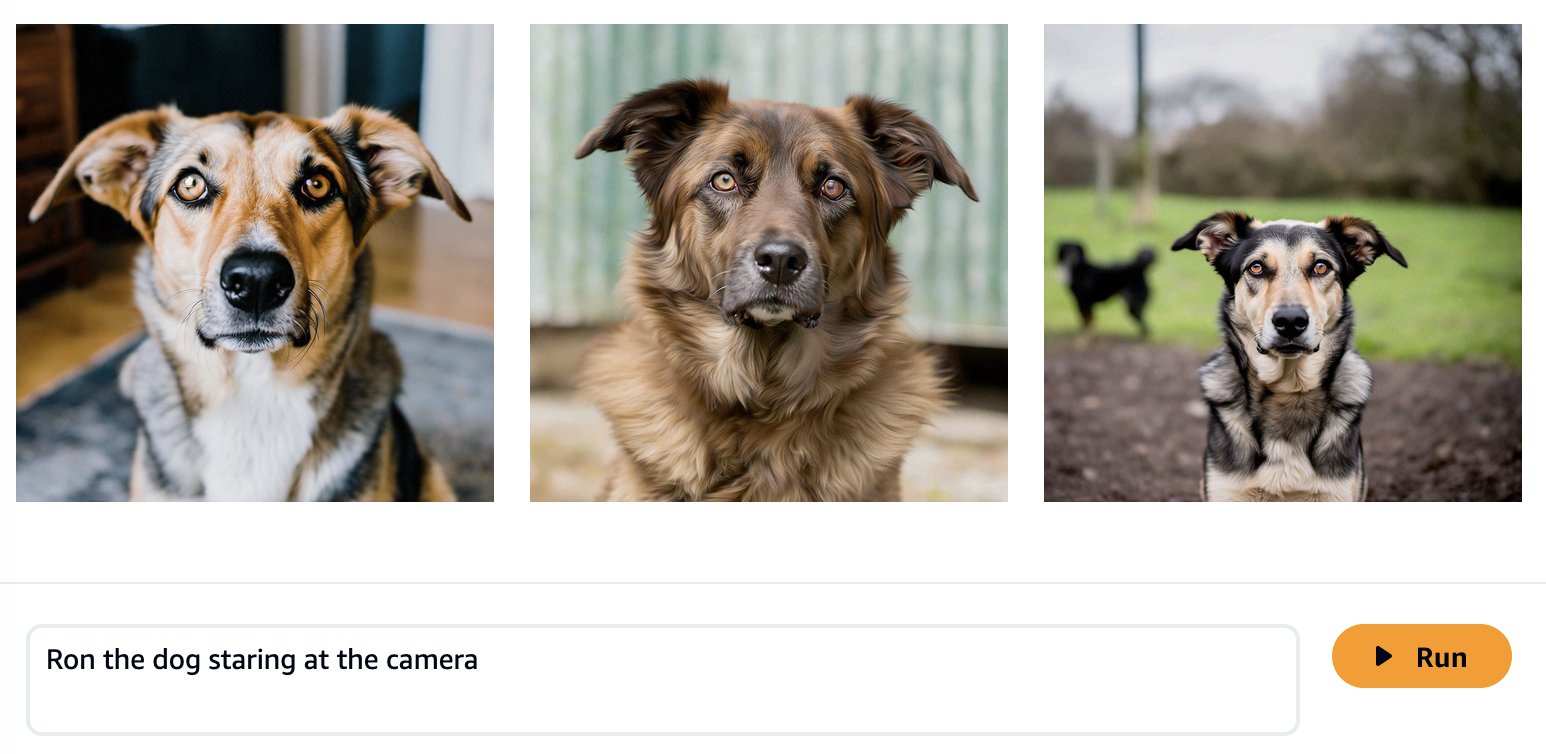

Som väntat känner den out-of-the-box-modellen inte till Ron och Smila ännu, och de genererade utdata visar olika hundar och katter. Med lite snabb teknik kan vi tillhandahålla mer information för att komma närmare utseendet på våra favorithusdjur.


Även om de genererade bilderna liknar Ron och Smila mer ser vi att modellen inte kan återge hela likheten med dem. Låt oss nu påbörja ett finjusteringsjobb med bilderna från Ron och Smila för att få konsekventa, personliga utdata.
Finjustera Amazon Titan Image Generator
Amazon Bedrock ger dig en serverlös upplevelse för att finjustera din Amazon Titan Image Generator-modell. Du behöver bara förbereda din data och välja dina hyperparametrar, så kommer AWS att hantera de tunga lyften åt dig.
När du använder Amazon Titan Image Generator-modellen för att finjustera skapas en kopia av denna modell i AWS-modellutvecklingskontot, som ägs och hanteras av AWS, och ett modellanpassningsjobb skapas. Detta jobb kommer sedan åt finjusteringsdata från en VPC och Amazon Titan-modellen har sina vikter uppdaterade. Den nya modellen sparas sedan till en Amazon enkel lagringstjänst (Amazon S3) som ligger i samma modellutvecklingskonto som den förtränade modellen. Det kan nu endast användas för slutledning av ditt konto och delas inte med något annat AWS-konto. När du kör inferens kommer du åt den här modellen via en beräkning av tillhandahållen kapacitet eller direkt, med hjälp av batch slutledning för Amazon Bedrock. Oberoende av den valda slutledningsmodaliteten finns dina data kvar på ditt konto och kopieras inte till något AWS-ägt konto eller används för att förbättra Amazon Titan Image Generator-modellen.
Följande diagram illustrerar detta arbetsflöde.
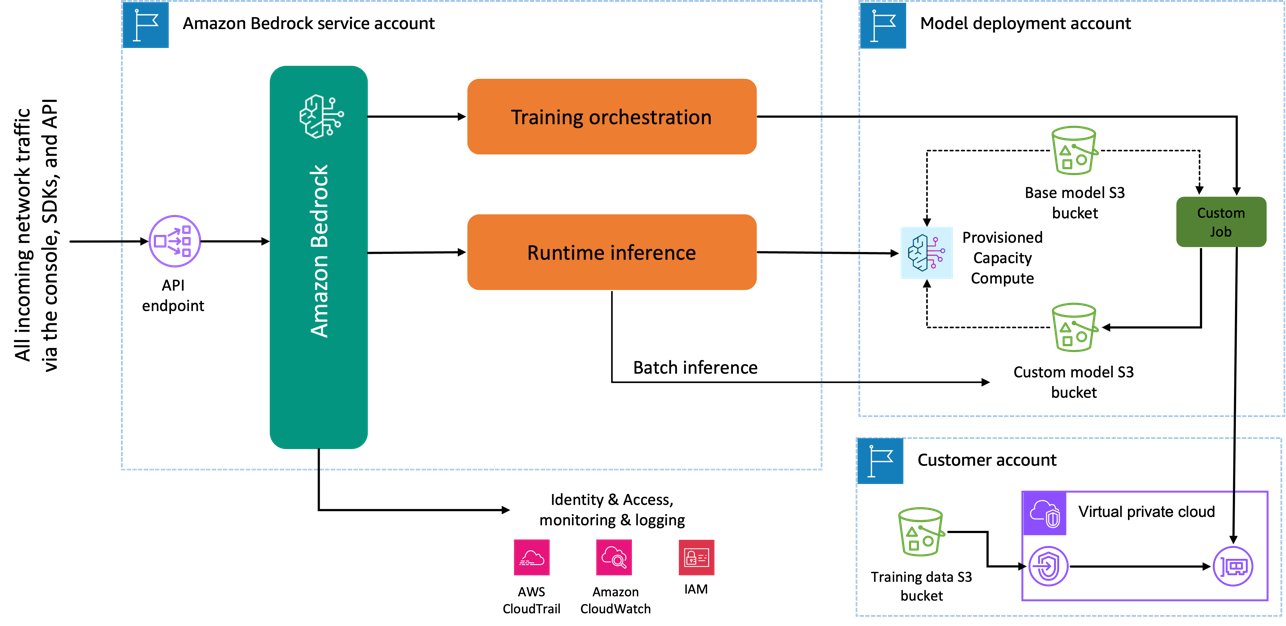
Datasekretess och nätverkssäkerhet
Dina data som används för finjustering inklusive uppmaningar, såväl som de anpassade modellerna, förblir privata i ditt AWS-konto. De delas inte eller används för modellutbildning eller tjänsteförbättringar och delas inte med tredjepartsmodellleverantörer. All data som används för finjustering är krypterad under överföring och vila. Data förblir i samma region där API-anropet behandlas. Du kan också använda AWS PrivateLink för att skapa en privat anslutning mellan AWS-kontot där dina data finns och VPC:n.
Dataförberedelse
Innan du kan skapa ett modellanpassningsjobb måste du göra det förbered din träningsdatauppsättning. Formatet på din träningsdatauppsättning beror på vilken typ av anpassningsjobb du skapar (finjustering eller fortsatt förträning) och modaliteten av dina data (text-till-text, text-till-bild eller bild-till-bild). inbäddning). För Amazon Titan Image Generator-modellen måste du tillhandahålla de bilder du vill använda för finjusteringen och en bildtext för varje bild. Amazon Bedrock förväntar sig att dina bilder lagras på Amazon S3 och att paren av bilder och bildtexter tillhandahålls i ett JSONL-format med flera JSON-rader.
Varje JSON-rad är ett exempel som innehåller en bildreferens, S3 URI för en bild och en bildtext som innehåller en textuppmaning för bilden. Dina bilder måste vara i JPEG- eller PNG-format. Följande kod visar ett exempel på formatet:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Eftersom "Ron" och "Smila" är namn som också skulle kunna användas i andra sammanhang, till exempel en persons namn, lägger vi till identifierarna "Ron the dog" och "Smila the cat" när vi skapar uppmaningen för att finjustera vår modell . Även om det inte är ett krav för att finjustera arbetsflödet, ger denna ytterligare information mer kontextuell tydlighet för modellen när den anpassas för de nya klasserna och kommer att undvika förvirringen av "Ron the dog" med en person som heter Ron och " Smila katten” med staden Smila i Ukraina. Med hjälp av denna logik visar följande bilder ett exempel på vår träningsdatauppsättning.
 |
 |
 |
| Hunden Ron ligger på en vit hundsäng | Hunden Ron sitter på ett klinkergolv | Hunden Ron ligger på en bilbarnstol |
 |
 |
 |
| Smila katten ligger på en soffa | Katten Smila stirrar på kameran som ligger på en soffa | Katten Smila ligger i en husdjursbärare |
När vi transformerar vår data till det format som förväntas av anpassningsjobbet får vi följande exempelstruktur:
{"image-ref": "/ron_01.jpg", "caption": "Hunden Ron ligger på en vit hundsäng"} {"image-ref": "/ron_02.jpg", "caption": "Ron hunden sitter på ett klinkergolv"} {"image-ref": "/ron_03.jpg", "caption": "Ron hunden som ligger på en bilbarnstol"} {"image-ref": "/smila_01.jpg", "caption": "Smila katten som ligger på en soffa"} {"image-ref": "/smila_02.jpg", "caption": "Smila katten som sitter bredvid fönstret bredvid en statykatt"} {"image-ref": "/smila_03.jpg", "caption": "Smila katten som ligger på en husdjursbärare"}
Efter att vi har skapat vår JSONL-fil måste vi lagra den på en S3-hink för att starta vårt anpassningsjobb. Finjusteringsjobb för Amazon Titan Image Generator G1 kommer att fungera med 5–10,000 60 bilder. För exemplet som diskuteras i det här inlägget använder vi 30 bilder: 30 av hunden Ron och XNUMX av katten Smila. Generellt sett förbättras noggrannheten hos din finjusterade modell genom att tillhandahålla fler varianter av stilen eller klassen du försöker lära dig. Men ju fler bilder du använder för finjustering, desto mer tid kommer det att ta för finjusteringsjobbet att slutföra. Antalet bilder som används påverkar också prissättningen av ditt finjusterade jobb. Hänvisa till Prissättning för Amazons berggrund för mer information.
Finjustera Amazon Titan Image Generator
Nu när vi har vår utbildningsdata redo kan vi påbörja ett nytt anpassningsjobb. Denna process kan göras både via Amazon Bedrock-konsolen eller API:er. För att använda Amazon Bedrock-konsolen, utför följande steg:
- Välj på Amazon Bedrock-konsolen Anpassade modeller i navigeringsfönstret.
- På Anpassa modellen meny, välj Skapa finjusteringsjobb.
- För Finjusterat modellnamn, ange ett namn för din nya modell.
- För Jobbkonfiguration, ange ett namn för utbildningsjobbet.
- För Indata, ange S3-sökvägen för indata.
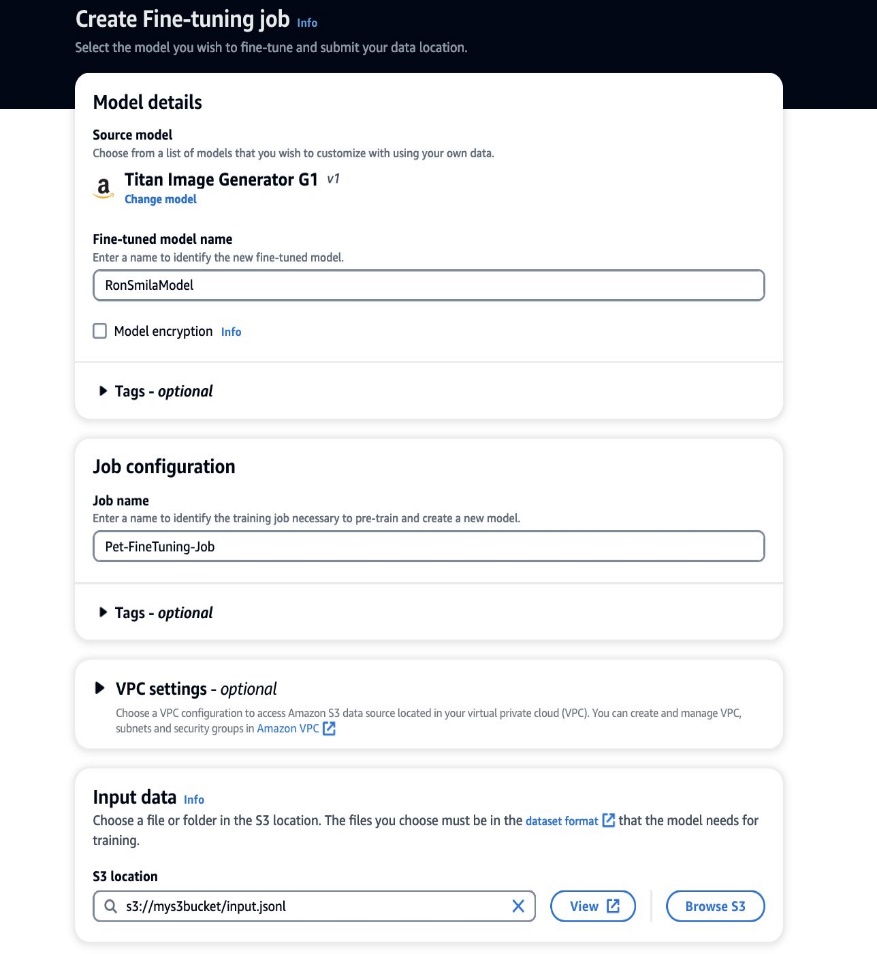
- I Hyperparametrar avsnitt, ange värden för följande:
- Antal steg – Antalet gånger modellen exponeras för varje batch.
- Satsstorlek – Antalet prover som behandlats före uppdatering av modellparametrarna.
- Lärningshastighet – Den hastighet med vilken modellparametrarna uppdateras efter varje batch. Valet av dessa parametrar beror på en given datamängd. Som en allmän riktlinje rekommenderar vi att du börjar med att fixera batchstorleken till 8, inlärningshastigheten till 1e-5, och ställer in antalet steg enligt antalet bilder som används, enligt beskrivningen i följande tabell.
| Antalet bilder som tillhandahålls | 8 | 32 | 64 | 1,000 | 10,000 |
| Antal steg rekommenderas | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Om resultatet av ditt finjusteringsjobb inte är tillfredsställande, överväg att öka antalet steg om du inte ser några tecken på stilen i genererade bilder, och minska antalet steg om du observerar stilen i de genererade bilderna men med artefakter eller suddighet. Om den finjusterade modellen inte lyckas lära sig den unika stilen i din datauppsättning även efter 40,000 XNUMX steg, överväg att öka batchstorleken eller inlärningshastigheten.
- I Utdata sektion, ange S3-utgångsvägen där valideringsutgångarna, inklusive de periodiskt registrerade valideringsförlusterna och noggrannhetsmåtten, lagras.
- I Tillgång till tjänsten sektion, generera en ny AWS identitets- och åtkomsthantering (IAM)-roll eller välj en befintlig IAM-roll med nödvändiga behörigheter för att komma åt dina S3-buckets.
Denna auktorisering gör det möjligt för Amazon Bedrock att hämta indata- och valideringsdataset från din utsedda hink och lagra valideringsutgångar sömlöst i din S3-hink.
- Välja Finjustera modellen.
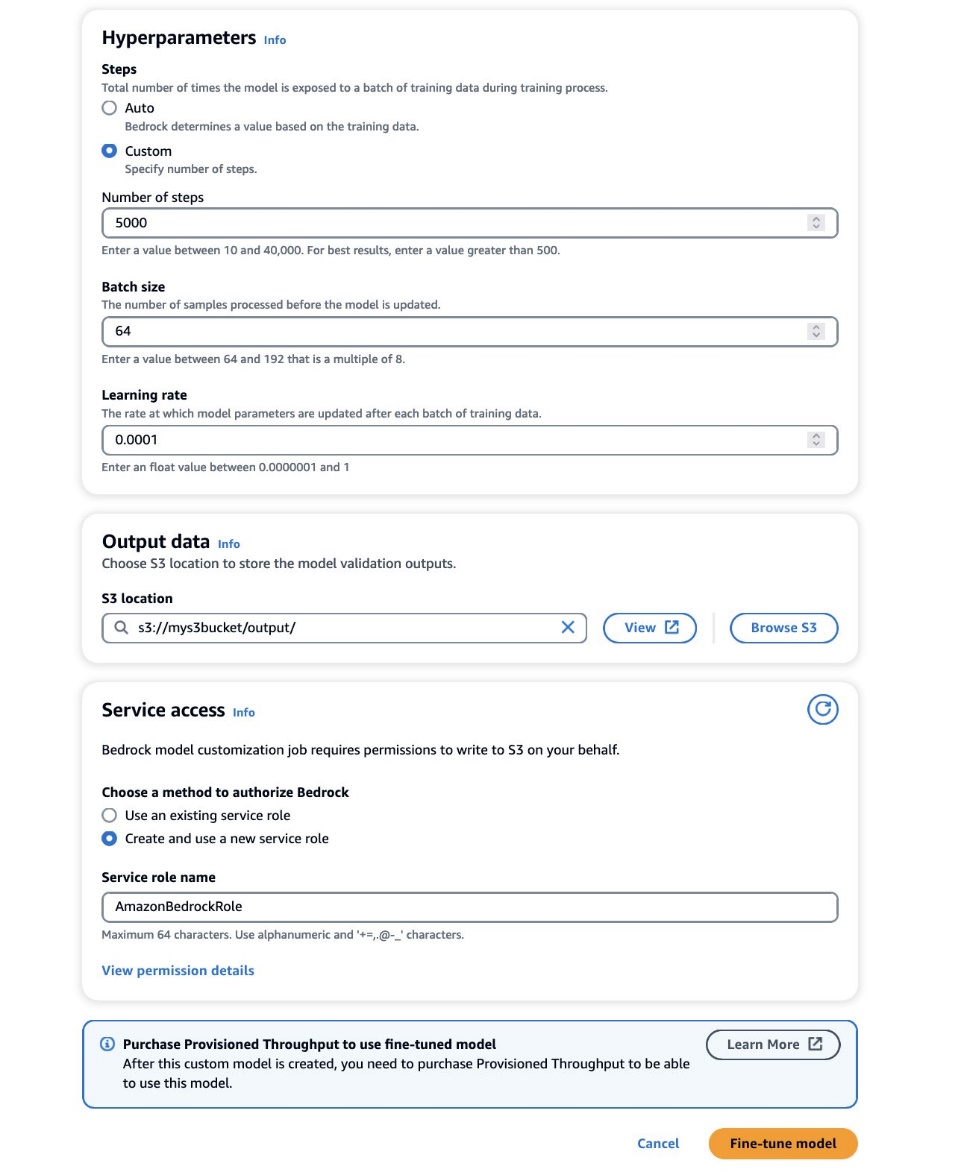
Med rätt konfigurationer inställda kommer Amazon Bedrock nu att träna din anpassade modell.
Installera den finjusterade Amazon Titan Image Generator med Provisioned Throughput
När du har skapat en anpassad modell låter Provisioned Throughput dig allokera en förutbestämd, fast hastighet för bearbetningskapacitet till den anpassade modellen. Denna tilldelning ger en konsekvent nivå av prestanda och kapacitet för att hantera arbetsbelastningar, vilket resulterar i bättre prestanda i produktionsbelastningar. Den andra fördelen med Provisioned Throughput är kostnadskontroll, eftersom standardtokenbaserad prissättning med inferensläge på begäran kan vara svårt att förutsäga i stor skala.
När finjusteringen av din modell är klar kommer denna modell att visas på Anpassade modeller' sida på Amazon Bedrock-konsolen.
För att köpa Provisioned Throughput, välj den anpassade modellen som du just finjusterat och välj Köp Provisionerad genomströmning.
Detta fyller i förväg den valda modellen som du vill köpa Provisioned Throughput för. För att testa din finjusterade modell före implementering, ställ in modellenheter till värdet 1 och ställ in åtagandeperioden till Ingen förpliktelse. Detta låter dig snabbt börja testa dina modeller med dina anpassade uppmaningar och kontrollera om utbildningen är tillräcklig. Dessutom, när nya finjusterade modeller och nya versioner är tillgängliga, kan du uppdatera Provisioned Throughput så länge du uppdaterar den med andra versioner av samma modell.
Finjustera resultat
För vår uppgift att anpassa modellen på hunden Ron och katten Smila visade experiment att de bästa hyperparametrarna var 5,000 8 steg med en batchstorlek på 1 och en inlärningshastighet på 5e-XNUMX.
Följande är några exempel på bilder som genereras av den anpassade modellen.
 |
 |
 |
| Hunden Ron bär en superhjältecape | Ron hunden på månen | Ron hunden i en pool med solglasögon |
 |
 |
 |
| Smila katten på snön | Katten Smila i svartvitt och stirrar på kameran | Katten Smila med julhatt |
Slutsats
I det här inlägget diskuterade vi när du ska använda finjustering istället för att konstruera dina uppmaningar för bildgenerering av bättre kvalitet. Vi visade hur man finjusterar Amazon Titan Image Generator-modellen och distribuerar den anpassade modellen på Amazon Bedrock. Vi gav också allmänna riktlinjer för hur du förbereder dina data för finjustering och ställer in optimala hyperparametrar för mer exakt modellanpassning.
Som nästa steg kan du anpassa följande exempel till ditt användningsfall för att generera hyperpersonaliserade bilder med Amazon Titan Image Generator.
Om författarna
 Maira Ladeira Tanke är Senior Generative AI Data Scientist på AWS. Med en bakgrund inom maskininlärning har hon över 10 års erfarenhet av att bygga och bygga AI-applikationer med kunder inom olika branscher. Som teknisk ledare hjälper hon kunder att accelerera deras uppnående av affärsvärde genom generativa AI-lösningar på Amazon Bedrock. På fritiden tycker Maira om att resa, leka med sin katt Smila och umgås med sin familj på ett varmt ställe.
Maira Ladeira Tanke är Senior Generative AI Data Scientist på AWS. Med en bakgrund inom maskininlärning har hon över 10 års erfarenhet av att bygga och bygga AI-applikationer med kunder inom olika branscher. Som teknisk ledare hjälper hon kunder att accelerera deras uppnående av affärsvärde genom generativa AI-lösningar på Amazon Bedrock. På fritiden tycker Maira om att resa, leka med sin katt Smila och umgås med sin familj på ett varmt ställe.
 Dani Mitchell är en AI/ML Specialist Solutions Architect på Amazon Web Services. Han är fokuserad på användningsfall för datorseende och att hjälpa kunder i EMEA att påskynda sin ML-resa.
Dani Mitchell är en AI/ML Specialist Solutions Architect på Amazon Web Services. Han är fokuserad på användningsfall för datorseende och att hjälpa kunder i EMEA att påskynda sin ML-resa.
 Bharathi Srinivasan är en dataforskare på AWS Professional Services, där hon älskar att bygga coola saker på Amazon Bedrock. Hon brinner för att driva affärsnytta från applikationer för maskininlärning, med fokus på ansvarsfull AI. Förutom att bygga nya AI-upplevelser för kunder älskar Bharathi att skriva science fiction och utmana sig själv med uthållighetssporter.
Bharathi Srinivasan är en dataforskare på AWS Professional Services, där hon älskar att bygga coola saker på Amazon Bedrock. Hon brinner för att driva affärsnytta från applikationer för maskininlärning, med fokus på ansvarsfull AI. Förutom att bygga nya AI-upplevelser för kunder älskar Bharathi att skriva science fiction och utmana sig själv med uthållighetssporter.
 Achin Jain är en tillämpad forskare med Amazon Artificial General Intelligence (AGI)-teamet. Han har expertis inom text-till-bild-modeller och är fokuserad på att bygga Amazon Titan Image Generator.
Achin Jain är en tillämpad forskare med Amazon Artificial General Intelligence (AGI)-teamet. Han har expertis inom text-till-bild-modeller och är fokuserad på att bygga Amazon Titan Image Generator.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

