Det här inlägget är skrivet tillsammans med Chaoyang He, Al Nevarez och Salman Avestimehr från FedML.
Många organisationer implementerar maskininlärning (ML) för att förbättra deras affärsbeslutsfattande genom automatisering och användning av stora distribuerade datauppsättningar. Med ökad tillgång till data har ML potentialen att ge oöverträffade affärsinsikter och möjligheter. Däremot utgör delning av rå, icke-sanerad känslig information på olika platser betydande säkerhets- och integritetsrisker, särskilt i reglerade branscher som sjukvård.
För att lösa detta problem är federated learning (FL) en decentraliserad och kollaborativ ML-utbildningsteknik som erbjuder datasekretess samtidigt som noggrannhet och trohet bibehålls. Till skillnad från traditionell ML-träning sker FL-träning inom en isolerad klientplats med hjälp av en oberoende säker session. Klienten delar bara sina utdatamodellparametrar med en centraliserad server, känd som träningskoordinatorn eller aggregeringsservern, och inte den faktiska data som används för att träna modellen. Detta tillvägagångssätt lindrar många problem med datasekretess samtidigt som det möjliggör effektivt samarbete kring modellträning.
Även om FL är ett steg mot att uppnå bättre datasekretess och säkerhet, är det inte en garanterad lösning. Osäkra nätverk som saknar åtkomstkontroll och kryptering kan fortfarande exponera känslig information för angripare. Dessutom kan lokalt tränad information avslöja privat data om den rekonstrueras genom en slutledningsattack. För att mildra dessa risker använder FL-modellen personliga träningsalgoritmer och effektiv maskering och parametrisering innan information delas med träningskoordinatorn. Starka nätverkskontroller på lokala och centraliserade platser kan ytterligare minska slutlednings- och exfiltreringsrisker.
I det här inlägget delar vi en FL-metod med hjälp av FedML, Amazon Elastic Kubernetes-tjänst (Amazon EKS), och Amazon SageMaker för att förbättra patientresultaten samtidigt som man tar itu med datasekretess och säkerhetsproblem.
Behovet av federerat lärande inom vården
Sjukvården är starkt beroende av distribuerade datakällor för att göra korrekta förutsägelser och bedömningar om patientvård. Att begränsa de tillgängliga datakällorna för att skydda integriteten påverkar resultatet negativt och i slutändan kvaliteten på patientvården. Därför skapar ML utmaningar för AWS-kunder som behöver säkerställa integritet och säkerhet över distribuerade enheter utan att kompromissa med patienternas resultat.
Sjukvårdsorganisationer måste navigera efter strikta efterlevnadsregler, såsom Health Insurance Portability and Accountability Act (HIPAA) i USA, samtidigt som de implementerar FL-lösningar. Att säkerställa datasekretess, säkerhet och efterlevnad blir ännu viktigare inom hälso- och sjukvården, vilket kräver robust kryptering, åtkomstkontroller, granskningsmekanismer och säkra kommunikationsprotokoll. Dessutom innehåller sjukvårdsdatauppsättningar ofta komplexa och heterogena datatyper, vilket gör datastandardisering och interoperabilitet till en utmaning i FL-miljöer.
Använda fallöversikt
Användningsfallet som beskrivs i det här inlägget är hjärtsjukdomsdata i olika organisationer, på vilka en ML-modell kommer att köra klassificeringsalgoritmer för att förutsäga hjärtsjukdom hos patienten. Eftersom denna data finns över organisationer använder vi federerad inlärning för att sammanställa resultaten.
Smakämnen Uppsättning av hjärtsjukdomar från University of California Irvines Machine Learning Repository är en mycket använd datauppsättning för kardiovaskulär forskning och prediktiv modellering. Den består av 303 prover, som var och en representerar en patient, och innehåller en kombination av kliniska och demografiska attribut, såväl som närvaro eller frånvaro av hjärtsjukdom.
Denna multivariata datauppsättning har 76 attribut i patientinformationen, av vilka 14 attribut är vanligast för att utveckla och utvärdera ML-algoritmer för att förutsäga förekomsten av hjärtsjukdom baserat på de givna attributen.
FedML ramverk
Det finns ett brett urval av FL-ramverk, men vi bestämde oss för att använda FedML ramverk för detta användningsfall eftersom det är öppen källkod och stöder flera FL-paradigm. FedML tillhandahåller ett populärt bibliotek med öppen källkod, MLOps-plattform och applikationsekosystem för FL. Dessa underlättar utveckling och driftsättning av FL-lösningar. Den tillhandahåller en omfattande uppsättning verktyg, bibliotek och algoritmer som gör det möjligt för forskare och praktiker att implementera och experimentera med FL-algoritmer i en distribuerad miljö. FedML tar itu med utmaningarna med datasekretess, kommunikation och modellaggregering i FL, och erbjuder ett användarvänligt gränssnitt och anpassningsbara komponenter. Med sitt fokus på samarbete och kunskapsdelning strävar FedML efter att påskynda införandet av FL och driva innovation inom detta framväxande område. FedML-ramverket är modellagnostiskt, inklusive nyligen tillagt stöd för stora språkmodeller (LLM). För mer information, se Släpp FedLLM: Bygg dina egna stora språkmodeller på proprietära data med hjälp av FedML-plattformen.
FedML bläckfisk
Systemhierarki och heterogenitet är en nyckelutmaning i verkliga FL-användningsfall, där olika datasilos kan ha olika infrastruktur med CPU och GPU:er. I sådana scenarier kan du använda FedML bläckfisk.
FedML Octopus är den industriella plattformen för cross-silo FL för cross-organisation och cross-account utbildning. Tillsammans med FedML MLOps gör det det möjligt för utvecklare eller organisationer att bedriva öppet samarbete från var som helst i vilken skala som helst på ett säkert sätt. FedML Octopus kör ett distribuerat träningsparadigm inuti varje datasilo och använder synkrona eller asynkrona träningar.
FedML MLOps
FedML MLOps möjliggör lokal utveckling av kod som senare kan distribueras var som helst med FedML-ramverk. Innan du påbörjar utbildningen måste du skapa ett FedML-konto, samt skapa och ladda upp server- och klientpaketen i FedML Octopus. För mer information, se steg och Vi introducerar FedML Octopus: skala federerad inlärning till produktion med förenklade MLOps.
Lösningsöversikt
Vi distribuerar FedML i flera EKS-kluster integrerade med SageMaker för experimentspårning. Vi använder Amazon EKS Blueprints för Terraform att distribuera den nödvändiga infrastrukturen. EKS Blueprints hjälper till att komponera kompletta EKS-kluster som är helt bootstrappade med den operativa programvara som behövs för att distribuera och driva arbetsbelastningar. Med EKS Blueprints beskrivs konfigurationen för det önskade tillståndet i EKS-miljön, såsom kontrollplanet, arbetarnoder och Kubernetes-tillägg, som en infrastruktur som kod (IaC) blueprint. När en ritning har konfigurerats kan den användas för att skapa konsekventa miljöer över flera AWS-konton och regioner med hjälp av kontinuerlig distributionsautomatisering.
Innehållet som delas i det här inlägget återspeglar verkliga situationer och upplevelser, men det är viktigt att notera att användningen av dessa situationer på olika platser kan variera. Även om vi använder ett enda AWS-konto med separata VPC:er är det viktigt att förstå att individuella omständigheter och konfigurationer kan skilja sig åt. Därför bör den tillhandahållna informationen användas som en allmän vägledning och kan kräva anpassning utifrån specifika krav och lokala förhållanden.
Följande diagram illustrerar vår lösningsarkitektur.
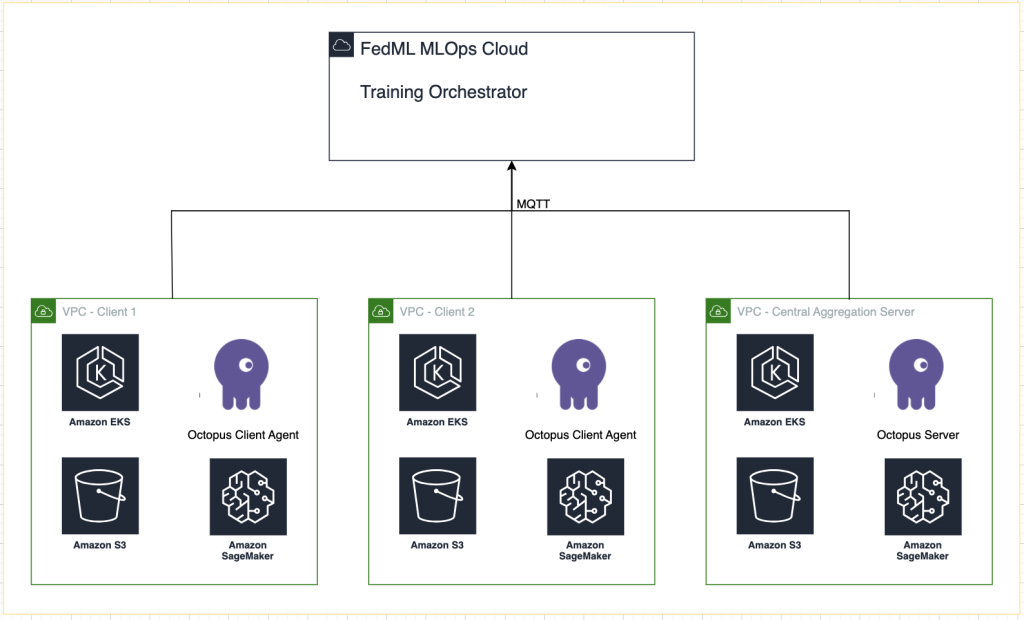
Förutom spårningen som tillhandahålls av FedML MLOps för varje träningskörning använder vi Amazon SageMaker-experiment för att spåra prestanda för varje kundmodell och den centraliserade (aggregator)modellen.
SageMaker Experiments är en funktion hos SageMaker som låter dig skapa, hantera, analysera och jämföra dina ML-experiment. Genom att registrera experimentdetaljer, parametrar och resultat kan forskare återge och validera sitt arbete korrekt. Det möjliggör effektiv jämförelse och analys av olika tillvägagångssätt, vilket leder till välgrundat beslutsfattande. Dessutom underlättar spårningsexperiment iterativ förbättring genom att ge insikter i modellernas utveckling och göra det möjligt för forskare att lära av tidigare iterationer, vilket i slutändan påskyndar utvecklingen av mer effektiva lösningar.
Vi skickar följande till SageMaker Experiments för varje körning:
- Modellutvärderingsmått – Träningsförlust och Area Under the Curve (AUC)
- Hyperparametrar – Epok, inlärningshastighet, batchstorlek, optimerare och viktminskning
Förutsättningar
För att följa detta inlägg bör du ha följande förutsättningar:
Distribuera lösningen
Till att börja, klona arkivet som är värd för exempelkoden lokalt:
Distribuera sedan use case-infrastrukturen med följande kommandon:
Terraform-mallen kan ta 20–30 minuter att distribuera helt. När den har distribuerats följer du stegen i nästa avsnitt för att köra FL-applikationen.
Skapa ett MLOps-distributionspaket
Som en del av FedML-dokumentationen måste vi skapa klient- och serverpaketen, som MLOps-plattformen kommer att distribuera till servern och klienterna för att börja träna.
För att skapa dessa paket, kör följande skript som finns i rotkatalogen:
Detta kommer att skapa respektive paket i följande katalog i projektets rotkatalog:
Ladda upp paketen till FedML MLOps-plattformen
Utför följande steg för att ladda upp paketen:
- Välj i FedML-gränssnittet Mina applikationer i navigeringsfönstret.
- Välja Ny ansökan.
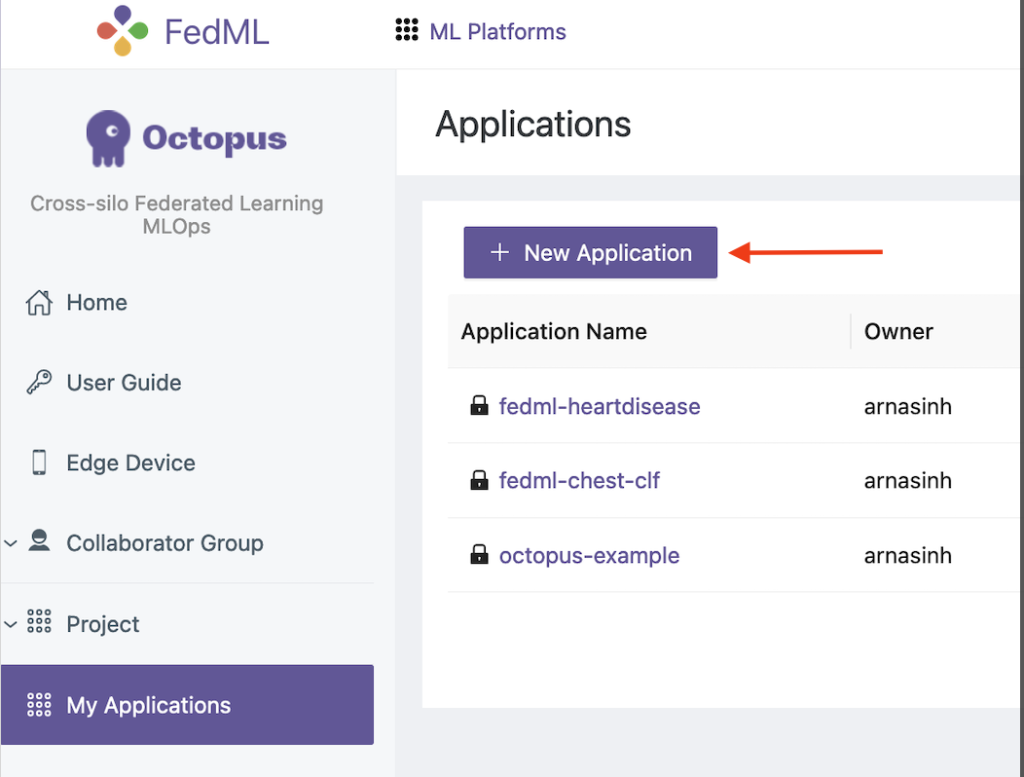
- Ladda upp klient- och serverpaketen från din arbetsstation.
- Du kan också justera hyperparametrarna eller skapa nya.

Utlösa federerad utbildning
Utför följande steg för att köra federerad utbildning:
- Välj i FedML-gränssnittet Projektlista i navigeringsfönstret.
- Välja Skapa ett nytt projekt.
- Ange ett gruppnamn och ett projektnamn och välj sedan OK.

- Välj det nyskapade projektet och välj Skapa ny körning för att utlösa ett träningslopp.
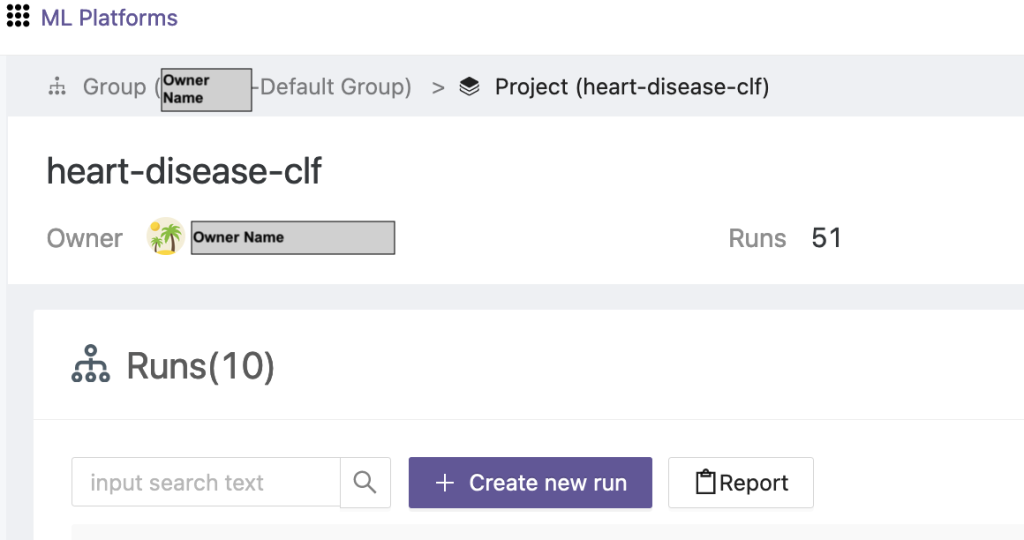
- Välj edge-klientenheterna och den centrala aggregatorservern för denna träningskörning.
- Välj programmet som du skapade i de föregående stegen.

- Uppdatera någon av hyperparametrarna eller använd standardinställningarna.
- Välja Start att börja träna.

- Välj Utbildningsstatus och vänta på att träningskörningen ska slutföras. Du kan också navigera till de tillgängliga flikarna.
- När utbildningen är klar, välj Systemkrav fliken för att se träningstidslängderna på dina edge-servrar och aggregeringshändelser.
Visa resultat och experimentdetaljer
När utbildningen är klar kan du se resultaten med FedML och SageMaker.
På FedML UI, på Modeller fliken kan du se aggregator och kundmodell. Du kan också ladda ner dessa modeller från webbplatsen.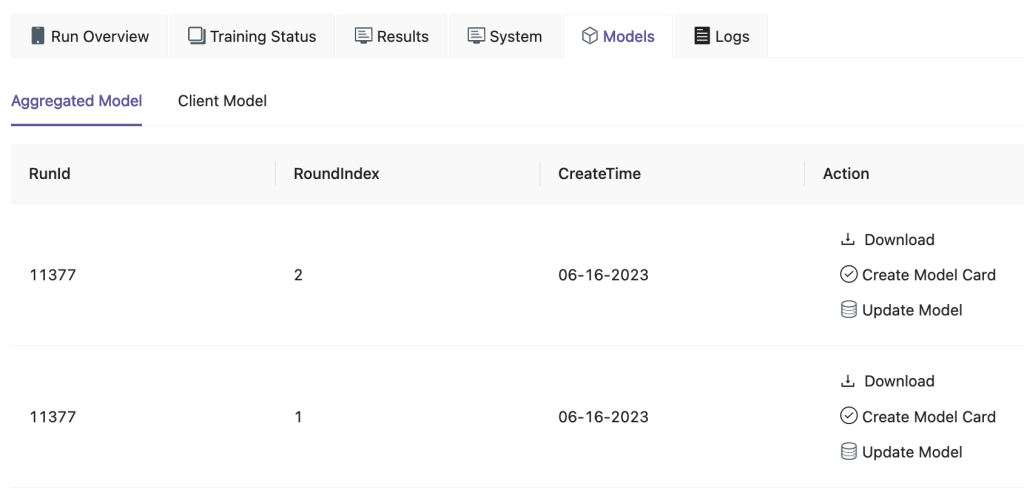
Du kan också logga in på Amazon SageMaker Studio Och välj Experiment i navigeringsfönstret.
Följande skärmdump visar de loggade experimenten.
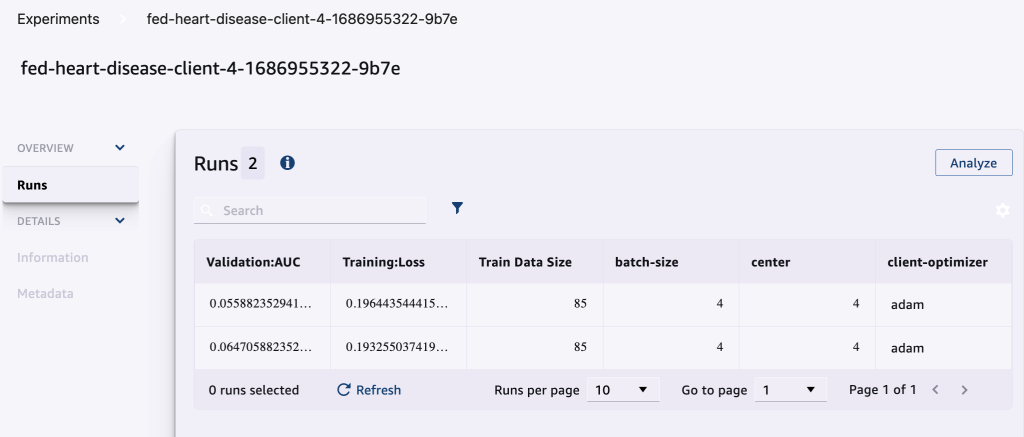
Experimentets spårningskod
I det här avsnittet utforskar vi koden som integrerar SageMaker-experimentspårning med FL-ramträningen.
Öppna följande mapp i en valfri redigerare för att se redigeringarna av koden för att injicera SageMaker experimentspårningskod som en del av utbildningen:
För att spåra träningen, vi skapa ett SageMaker-experiment med parametrar och mätvärden loggade med hjälp av log_parameter och log_metric kommando som beskrivs i följande kodexempel.
En post i config/fedml_config.yaml fil deklarerar experimentprefixet, som hänvisas till i koden för att skapa unika experimentnamn: sm_experiment_name: "fed-heart-disease". Du kan uppdatera detta till valfritt värde.
Se till exempel följande kod för heart_disease_trainer.py, som används av varje klient för att träna modellen på sin egen datauppsättning:
För varje klientkörning spåras experimentdetaljerna med hjälp av följande kod i heart_disease_trainer.py:
På samma sätt kan du använda koden i heart_disease_aggregator.py att köra ett test på lokal data efter uppdatering av modellvikterna. Detaljerna loggas efter varje kommunikationskörning med klienterna.
Städa upp
När du är klar med lösningen, se till att rensa upp de resurser som används för att säkerställa ett effektivt resursutnyttjande och kostnadshantering, och undvika onödiga utgifter och resursslöseri. Aktiv städning av miljön, som att ta bort oanvända instanser, stoppa onödiga tjänster och ta bort tillfällig data, bidrar till en ren och organiserad infrastruktur. Du kan använda följande kod för att rensa upp dina resurser:
Sammanfattning
Genom att använda Amazon EKS som infrastruktur och FedML som ramverk för FL kan vi tillhandahålla en skalbar och hanterad miljö för utbildning och driftsättning av delade modeller samtidigt som dataintegriteten respekteras. Med den decentraliserade karaktären hos FL kan organisationer samarbeta säkert, låsa upp potentialen hos distribuerad data och förbättra ML-modeller utan att kompromissa med datasekretessen.
Som alltid välkomnar AWS din feedback. Lämna dina tankar och frågor i kommentarsfältet.
Om författarna
 Randy DeFauw är Senior Principal Solutions Architect på AWS. Han har en MSEE från University of Michigan, där han arbetade med datorseende för autonoma fordon. Han har också en MBA från Colorado State University. Randy har haft en mängd olika positioner inom teknikområdet, allt från mjukvaruteknik till produkthantering. Han gick in i big data-utrymmet 2013 och fortsätter att utforska det området. Han arbetar aktivt med projekt inom ML-området och har presenterat på ett flertal konferenser, inklusive Strata och GlueCon.
Randy DeFauw är Senior Principal Solutions Architect på AWS. Han har en MSEE från University of Michigan, där han arbetade med datorseende för autonoma fordon. Han har också en MBA från Colorado State University. Randy har haft en mängd olika positioner inom teknikområdet, allt från mjukvaruteknik till produkthantering. Han gick in i big data-utrymmet 2013 och fortsätter att utforska det området. Han arbetar aktivt med projekt inom ML-området och har presenterat på ett flertal konferenser, inklusive Strata och GlueCon.
 Arnab Sinha är en Senior Solutions Architect för AWS, som fungerar som Field CTO för att hjälpa organisationer att designa och bygga skalbara lösningar som stödjer affärsresultat över datacentermigreringar, digital transformation och applikationsmodernisering, big data och maskininlärning. Han har stöttat kunder inom en mängd olika branscher, inklusive energi, detaljhandel, tillverkning, hälsovård och biovetenskap. Arnab innehar alla AWS-certifieringar, inklusive ML Specialty Certification. Innan han började på AWS var Arnab teknikledare och hade tidigare arkitekt- och ingenjörsledarroller.
Arnab Sinha är en Senior Solutions Architect för AWS, som fungerar som Field CTO för att hjälpa organisationer att designa och bygga skalbara lösningar som stödjer affärsresultat över datacentermigreringar, digital transformation och applikationsmodernisering, big data och maskininlärning. Han har stöttat kunder inom en mängd olika branscher, inklusive energi, detaljhandel, tillverkning, hälsovård och biovetenskap. Arnab innehar alla AWS-certifieringar, inklusive ML Specialty Certification. Innan han började på AWS var Arnab teknikledare och hade tidigare arkitekt- och ingenjörsledarroller.
 Prachi Kulkarni är Senior Solutions Architect på AWS. Hennes specialisering är maskininlärning och hon arbetar aktivt med att designa lösningar med hjälp av olika AWS ML-, big data- och analyserbjudanden. Prachi har erfarenhet inom flera områden, inklusive hälsovård, förmåner, detaljhandel och utbildning, och har arbetat i en rad olika positioner inom produktutveckling och arkitektur, management och kundframgång.
Prachi Kulkarni är Senior Solutions Architect på AWS. Hennes specialisering är maskininlärning och hon arbetar aktivt med att designa lösningar med hjälp av olika AWS ML-, big data- och analyserbjudanden. Prachi har erfarenhet inom flera områden, inklusive hälsovård, förmåner, detaljhandel och utbildning, och har arbetat i en rad olika positioner inom produktutveckling och arkitektur, management och kundframgång.
 Tamer Sherif är en Principal Solutions Architect på AWS, med en mångsidig bakgrund inom teknik- och företagskonsulttjänster, som spänner över 17 år som Solutions Architect. Med fokus på infrastruktur täcker Tamers expertis ett brett spektrum av industrivertikaler, inklusive kommersiell, hälsovård, bilindustri, offentlig sektor, tillverkning, olja och gas, mediatjänster och mer. Hans kompetens sträcker sig till olika domäner, såsom molnarkitektur, edge computing, nätverk, lagring, virtualisering, affärsproduktivitet och tekniskt ledarskap.
Tamer Sherif är en Principal Solutions Architect på AWS, med en mångsidig bakgrund inom teknik- och företagskonsulttjänster, som spänner över 17 år som Solutions Architect. Med fokus på infrastruktur täcker Tamers expertis ett brett spektrum av industrivertikaler, inklusive kommersiell, hälsovård, bilindustri, offentlig sektor, tillverkning, olja och gas, mediatjänster och mer. Hans kompetens sträcker sig till olika domäner, såsom molnarkitektur, edge computing, nätverk, lagring, virtualisering, affärsproduktivitet och tekniskt ledarskap.
 Hans Nesbitt är Senior Solutions Architect på AWS baserad i södra Kalifornien. Han arbetar med kunder över hela västra USA för att skapa mycket skalbara, flexibla och motståndskraftiga molnarkitekturer. På fritiden tycker han om att umgås med sin familj, laga mat och spela gitarr.
Hans Nesbitt är Senior Solutions Architect på AWS baserad i södra Kalifornien. Han arbetar med kunder över hela västra USA för att skapa mycket skalbara, flexibla och motståndskraftiga molnarkitekturer. På fritiden tycker han om att umgås med sin familj, laga mat och spela gitarr.
 Chaoyang He är medgrundare och CTO för FedML, Inc., en startup som driver en gemenskapsbyggande öppen och samarbetande AI från var som helst i vilken skala som helst. Hans forskning fokuserar på distribuerade och federerade maskininlärningsalgoritmer, system och applikationer. Han tog sin doktorsexamen i datavetenskap från University of Southern California.
Chaoyang He är medgrundare och CTO för FedML, Inc., en startup som driver en gemenskapsbyggande öppen och samarbetande AI från var som helst i vilken skala som helst. Hans forskning fokuserar på distribuerade och federerade maskininlärningsalgoritmer, system och applikationer. Han tog sin doktorsexamen i datavetenskap från University of Southern California.
 Al Nevarez är Director of Product Management på FedML. Innan FedML var han gruppproduktchef på Google och senior manager för datavetenskap på LinkedIn. Han har flera dataproduktrelaterade patent och han studerade teknik vid Stanford University.
Al Nevarez är Director of Product Management på FedML. Innan FedML var han gruppproduktchef på Google och senior manager för datavetenskap på LinkedIn. Han har flera dataproduktrelaterade patent och han studerade teknik vid Stanford University.
 Salman Avestimehr är medgrundare och VD för FedML. Han har varit dekanusprofessor vid USC, direktör för USC-Amazon Center on Trustworthy AI och Amazon Scholar i Alexa AI. Han är expert på federerad och decentraliserad maskininlärning, informationsteori, säkerhet och integritet. Han är fellow i IEEE och tog sin doktorsexamen i EECS från UC Berkeley.
Salman Avestimehr är medgrundare och VD för FedML. Han har varit dekanusprofessor vid USC, direktör för USC-Amazon Center on Trustworthy AI och Amazon Scholar i Alexa AI. Han är expert på federerad och decentraliserad maskininlärning, informationsteori, säkerhet och integritet. Han är fellow i IEEE och tog sin doktorsexamen i EECS från UC Berkeley.
 Samir Ladd är en skicklig företagsteknolog med AWS som arbetar nära kundernas chefer på C-nivå. Som en före detta C-suite-chef som har drivit transformationer över flera Fortune 100-företag delar Samir med sig av sina ovärderliga erfarenheter för att hjälpa sina kunder att lyckas med sin egen transformationsresa.
Samir Ladd är en skicklig företagsteknolog med AWS som arbetar nära kundernas chefer på C-nivå. Som en före detta C-suite-chef som har drivit transformationer över flera Fortune 100-företag delar Samir med sig av sina ovärderliga erfarenheter för att hjälpa sina kunder att lyckas med sin egen transformationsresa.
 Stephen Kraemer är styrelse- och CxO-rådgivare och tidigare chef på AWS. Stephen förespråkar kultur och ledarskap som grunden för framgång. Han bekänner sig till säkerhet och innovation som drivkrafterna bakom molntransformation, vilket möjliggör mycket konkurrenskraftiga, datadrivna organisationer.
Stephen Kraemer är styrelse- och CxO-rådgivare och tidigare chef på AWS. Stephen förespråkar kultur och ledarskap som grunden för framgång. Han bekänner sig till säkerhet och innovation som drivkrafterna bakom molntransformation, vilket möjliggör mycket konkurrenskraftiga, datadrivna organisationer.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/federated-learning-on-aws-using-fedml-amazon-eks-and-amazon-sagemaker/

