Den snabba introduktionen av smarta telefoner och andra mobila plattformar har genererat en enorm mängd bilddata. Enligt Gartner, utgör ostrukturerad data nu 80–90 % av all ny företagsdata, men bara 18 % av organisationerna utnyttjar denna data. Detta beror främst på bristen på expertis och den stora mängd tid och ansträngning som krävs för att sålla igenom all information för att identifiera kvalitetsdata och användbara insikter.
Innan du kan använda bilddata för märkning, utbildning eller slutledning måste den först rengöras (deduplicera, släppa skadade bilder eller extremvärden, och så vidare), analyseras (som gruppbilder baserat på vissa attribut), standardiseras (ändra storlek, ändra orientering, standardisera belysning och färg, och så vidare), och utökas för bättre resultat för märkning, träning eller slutledning (förbättra kontrasten, sudda ut vissa irrelevanta objekt, uppskala och så vidare).
Idag är vi glada att kunna meddela att med Amazon SageMaker Data Wrangler, kan du utföra bilddataförberedelse för maskininlärning (ML) med lite eller ingen kod.
Data Wrangler minskar tiden det tar att aggregera och förbereda data för ML från veckor till minuter. Med Data Wrangler kan du förenkla processen för dataförberedelse och funktionsutveckling och slutföra varje steg i dataförberedelsens arbetsflöde (inklusive dataurval, rensning, utforskning, visualisering och bearbetning i skala) från ett enda visuellt gränssnitt.
Data Wranglers bilddataförberedande funktion tillgodoser dina behov via ett visuellt användargränssnitt för förhandsgranskning, import, transformation och export av bilder. Du kan bläddra, importera och transformera bilddata precis som hur du använder Data Wrangler för tabelldata. I det här inlägget visar vi ett exempel på hur man använder den här funktionen.
Lösningsöversikt
För det här inlägget fokuserar vi på Data Wrangler-komponenten för bildbehandling, som vi använder för att hjälpa en bildklassificeringsmodell att upptäcka krascher med bilder av bättre kvalitet. Vi använder följande tjänster:
Följande diagram illustrerar lösningsarkitekturen.

Data Wrangler är en SageMaker-funktion tillgänglig i Studio. Du kan följa introduktionsprocessen för Studio för att snurra upp Studio-miljön och anteckningsböckerna. Även om du kan välja mellan några få autentiseringsmetoder, är det enklaste sättet att skapa en Studio-domän att följa Snabbstartinstruktioner. Snabbstarten använder samma standardinställningar som standardinställningarna i Studio. Du kan också välja att ombord använda Aws iam identitetscenter (efterträdare till AWS Single Sign-On) för autentisering (se Ombord på Amazon SageMaker Domain med IAM Identity Center).
För detta användningsfall använder vi CCTV-filmdata från olyckor och icke-olyckor tillgängliga från Kaggle. Datauppsättningen innehåller ramar tagna från YouTube-videor av olyckor och icke-olyckor. Bilderna är uppdelade i tåg-, test- och valideringsmappar.
Förutsättningar
Som en förutsättning, ladda ner exempeluppsättning och ladda upp den till en Amazon enkel lagringstjänst (Amazon S3) hink. Vi använder denna datauppsättning för bildbehandling och därefter för att träna en anpassad modell.
Bearbeta bilder med Data Wrangler
Starta din Studio-miljö och skapa en ny Data Wrangler-flöde kallas car_crash_detection_data.flow. Låt oss nu importera datasetet till Data Wrangler från S3-bucketen där datamängden laddades upp. Data Wrangler låter dig importera datamängder från olika datakällor, inklusive bilder.
Data Wrangler stöder en mängd olika inbyggda transformationer för bildbehandling, inklusive följande:
- Oskärpa bild – Data Wrangler stöder olika tekniker från ett bildbibliotek med öppen källkod (Gaussian, Average, Median, Motion och mer) för att göra bilder suddiga. För detaljer om varje teknik, se augmenters.blur.
- Korrupt bild – Data Wrangler stöder också olika korruptionstekniker (Gaussiskt brus, Impulsbrus, Speckle-brus och mer). För detaljer om varje teknik, se augmenters.imgcorruptlike.
- Förbättra bildkontrasten – Du kan använda olika kontrastförbättringstekniker (Gamma-kontrast, Sigmoid-kontrast, Log-kontrast, Linjär kontrast, Histogram-utjämning och mer). För mer information, se augmenters.contrast.
- Ändra storlek på bilden – Data Wrangler stöder olika storleksändringstekniker (beskärning, utfyllnad, miniatyrbilder och mer). För mer information, se augmenters.size.
I det här inlägget lyfter vi fram en delmängd av dessa funktioner genom följande steg:
- Ladda upp bilder från S3-källan och förhandsgranska bilden.
- Skapa snabba bildtransformationer med hjälp av de inbyggda transformatorerna.
- Skriv anpassad kod som att hitta extremvärden eller använda Sök exempelutdrag funktion.
- Exportera den slutgiltiga rensade datan till en annan S3-hink.
- Kombinera bilder från olika Amazon S3-källor till ett Data Wrangler-flöde.
- Skapa ett jobb för att utlösa Data Wrangler-flödet.
Låt oss titta på varje steg i detalj.
Ladda upp bilder från källbucket S3 och förhandsgranska bilden
För att ladda upp alla bilder under en mapp, utför följande steg:
- Välj mappen S3 som innehåller bilderna.
- För Filtypväljer Bild.
- Välja Importera kapslade kataloger.
- Välja Importera.

Du kan förhandsgranska bilderna som du laddar upp genom att vrida på Förhandsvisning alternativet på. Observera att Date Wrangler endast importerar 100 slumpmässiga bilder för den interaktiva dataförberedelsen.

Förhandsgranskningsfunktionen låter dig visa bilder och förhandsgranska kvaliteten på importerade bilder.

För det här inlägget laddar vi in bilderna från både accident och non-accident mappar. Vi skapar en uppsättning transformationer för var och en: ett flöde för att korrumpera bilder, ändra storlek och ta bort extremvärden, och ett annat flöde för att förbättra bildkontrasten, ändra storlek och ta bort extremvärden.
Förvandla bilder med inbyggda transformationer
Bilddatatransformation är mycket viktig för att reglera ditt modellnätverk och öka storleken på din träningsuppsättning. Dessa transformationer kan ändra bildernas pixelvärden men ändå behålla nästan all information i bilden, så att en människa knappast kunde se om den var förstärkt eller inte. Detta tvingar modellen att vara mer flexibel med det stora utbudet av objekt i bilden, vad gäller position, orientering, storlek, färg och så vidare. Modeller tränade med dataökning generaliserar vanligtvis bättre.
Data Wrangler erbjuder inbyggda och anpassade transformationer för att förbättra kvaliteten på bilder för märkning, utbildning eller slutledning. Vi använder några av dessa transformationer för att förbättra bilddatauppsättningen som matas till modellen för maskininlärning.
Korrupta bilder
Den första inbyggda transformationen vi använder är Korrupta bilder.
Vi lägger till ett steg med Korruption satt till Impulsljud och ställ in vår svårighetsgrad.

Att korrumpera en bild eller skapa någon form av brus hjälper till att göra en modell mer robust. Modellen kan förutsäga med större noggrannhet även om den får en skadad bild eftersom den tränats med korrupta och icke-korrupta bilder.
Förbättra kontrasten
Vi lägger också till en transformation för att förbättra Gamma-kontrasten.

Ändra storlek på bilder
Vi kan använda en inbyggd transformation för att ändra storlek på alla bilder för att lägga till symmetri. Data Wrangler erbjuder flera storleksändringsalternativ, som visas i följande skärmdump.

Följande exempel visar bilder före storleksändring: 720 x 1280.

Följande bilder har ändrats till 620 x 1180.

Lägg till en anpassad transformation för att upptäcka och ta bort avvikande bilder
Med bildförberedelse i Data Wrangler kan vi även anropa en annan slutpunkt för en annan modell. Du kan hitta några exempelskript med boilerplate-kod i Sök exempel på utdrag sektion.

För vårt exempel skapar vi en ny transformation för att ta bort extremvärden. Observera att denna kod endast är till för demonstrationssyfte. Du kan behöva ändra koden för att passa alla behov av produktionsbelastning.
Detta är ett anpassat utdrag skrivet i PySpark. Innan vi kör det här steget måste vi ha en bildinbäddningsmodell mobile-net (till exempel, jumpstart-dft-mobilenet-v2-100-224-featurevector-4). Efter att slutpunkten har distribuerats kan vi anropa en JumpStart-modellslutpunkt.
JumpStart-modeller löser vanliga ML-uppgifter som bildklassificering, objektdetektering, textklassificering, meningsparklassificering och frågesvar, och är tillgängliga för att snabbt skapa och distribuera modeller.
För att lära dig hur du skapar en bildinbäddningsmodell i JumpStart, se GitHub repo. Stegen att följa liknar skapa en bildklassificeringsmodell med Jumpstart. Se följande kod:
Följande skärmdumpar visar ett exempel på vår anpassade transformation.


Detta identifierar avvikelsen. Låt oss sedan filtrera bort extremvärdet. Du kan använda följande kodavsnitt i slutet av den anpassade transformationen:
Välja Förhandsvisning och Lägg till för att spara ändringarna.
Exportera den slutgiltiga rensade datan till en annan S3-hink
Efter att ha lagt till alla transformationer, låt oss definiera destinationen i Amazon S3.

Ange platsen för din S3-skopa.

Kombinera bilder från olika Amazon S3-källor till ett Data Wrangler-flöde
I de föregående avsnitten bearbetade vi bilder av olyckor. Vi kan implementera ett liknande flöde för alla andra bilder (i vårt fall, icke-olycksbilder). Välja Importera och följ samma steg för att skapa ett andra flöde.

Nu kan vi se flödena för varje datamängd.

Skapa ett jobb för att köra det automatiserade flödet
När vi skapar ett jobb skalar vi receptet till hela datamängden, som kan vara tusentals eller miljoner bilder. Du kan också schemalägga att flödet körs regelbundet och du kan parametrisera indatakällan för att skala bearbetningen. För detaljer om jobbschemaläggning och ingångsparameterisering, se Skapa ett schema för att automatiskt bearbeta nya data.
Välja Skapa jobb att köra ett jobb för flödet från början till slut.
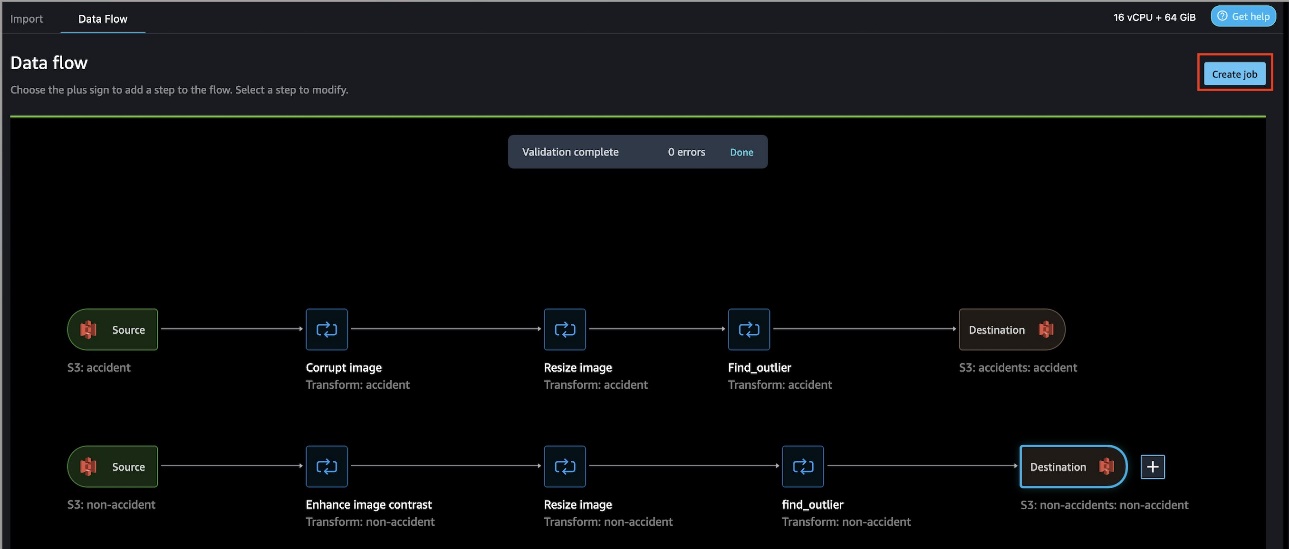
Ange detaljer om jobbet och välj båda datamängderna.

Grattis! Du har framgångsrikt skapat ett jobb för att bearbeta bilder med Data Wrangler.
Modellutbildning och distribution
JumpStart tillhandahåller ett klick, end-to-end-lösningar för många vanliga ML-användningsfall. Vi kan använda bilderna förberedda med Data Wrangler när vi skapar en snabb bildklassificeringsmodell i JumpStart. För instruktioner, se Kör bildklassificering med Amazon SageMaker JumpStart.
Städa upp
När du inte använder Data Wrangler är det viktigt att stänga av instansen som den körs på för att undvika extra avgifter.
Data Wrangler sparar automatiskt ditt dataflöde var 60:e sekund. För att undvika att förlora arbete, spara ditt dataflöde innan du stänger av Data Wrangler.
- För att spara ditt dataflöde i Studio, välj FilOch välj sedan Spara data Wrangler Flow.
- För att stänga av Data Wrangler-instansen, i Studio, välj Löpande instanser och kärnor.
- Enligt KÖR APPAR, välj avstängningsikonen bredvid
sagemaker-data-wrangler-1.0app. - Välja Stäng av allt att bekräfta.
Data Wrangler körs på en ml.m5.4xlarge instans. Denna instans försvinner från KÖRINSTANSER när du stänger av Data Wrangler-appen.
- Stäng av JumpStart-slutpunkten som du skapade för inbäddningen av avvikande transformationsbild.
När du har stängt av Data Wrangler-appen måste den startas om nästa gång du öppnar en Data Wrangler-flödesfil. Detta kan ta några minuter.
Slutsats
I det här inlägget demonstrerade vi användning av bilddataförberedelse för ML på Data Wrangler. För att komma igång med Data Wrangler, se Förbered ML-data med Amazon SageMaker Data Wrangler, och kolla in den senaste informationen om Data Wrangler produktsida.
Om författarna
 Deepmala Agarwal arbetar som AWS Data Specialist Solutions Architect. Hon brinner för att hjälpa kunder att bygga ut skalbara, distribuerade och datadrivna lösningar på AWS. När Deepmala inte är på jobbet gillar Deepmala att umgås med familjen, promenera, lyssna på musik, titta på film och laga mat!
Deepmala Agarwal arbetar som AWS Data Specialist Solutions Architect. Hon brinner för att hjälpa kunder att bygga ut skalbara, distribuerade och datadrivna lösningar på AWS. När Deepmala inte är på jobbet gillar Deepmala att umgås med familjen, promenera, lyssna på musik, titta på film och laga mat!
 Meenakshisundaram Thandavarayan arbetar för AWS som AI/ML-specialist. Han har en passion för att designa, skapa och främja människocentrerade data- och analysupplevelser. Meena fokuserar på att utveckla hållbara system som levererar mätbara konkurrensfördelar för strategiska kunder till AWS. Meena är en koppling, designtänkare och strävar efter att driva företag till nya sätt att arbeta genom innovation, inkubation och demokratisering.
Meenakshisundaram Thandavarayan arbetar för AWS som AI/ML-specialist. Han har en passion för att designa, skapa och främja människocentrerade data- och analysupplevelser. Meena fokuserar på att utveckla hållbara system som levererar mätbara konkurrensfördelar för strategiska kunder till AWS. Meena är en koppling, designtänkare och strävar efter att driva företag till nya sätt att arbeta genom innovation, inkubation och demokratisering.
 Lu Huang är Senior Product Manager på Data Wrangler. Hon brinner för AI, maskininlärning och big data.
Lu Huang är Senior Product Manager på Data Wrangler. Hon brinner för AI, maskininlärning och big data.
 Nikita Ivkin är en Senior Applied Scientist på Amazon SageMaker Data Wrangler med intressen för maskininlärning och datarensningsalgoritmer.
Nikita Ivkin är en Senior Applied Scientist på Amazon SageMaker Data Wrangler med intressen för maskininlärning och datarensningsalgoritmer.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/prepare-image-data-with-amazon-sagemaker-data-wrangler/

