Generativa språkmodeller har visat sig vara anmärkningsvärt skickliga på att lösa logiska och analytiska NLP-uppgifter (natural language processing). Vidare kan användningen av snabb ingenjörskonst kan märkbart förbättra deras prestanda. Till exempel, tankekedja (CoT) är känt för att förbättra en modells kapacitet för komplexa flerstegsproblem. För att ytterligare öka noggrannheten i uppgifter som involverar resonemang, a självständighet man har föreslagit tillvägagångssätt, som ersätter girig med stokastisk avkodning under språkgenerering.
Amazonas berggrund är en helt hanterad tjänst som erbjuder ett urval av högpresterande grundmodeller från ledande AI-företag och Amazon via ett enda API, tillsammans med en bred uppsättning möjligheter att bygga generativ AI applikationer med säkerhet, integritet och ansvarsfull AI. Med parti slutledning API kan du använda Amazon Bedrock för att köra inferens med grundmodeller i partier och få svar mer effektivt. Det här inlägget visar hur man implementerar självkonsekvensuppmaning via batch-inferens på Amazon Bedrock för att förbättra modellens prestanda på aritmetiska och flervalsresonemangsuppgifter.
Översikt över lösningen
Språkmodellers självständighet är beroende av genereringen av flera svar som aggregeras till ett slutgiltigt svar. I motsats till engenerationsmetoder som CoT, skapar självkonsekvensprov-och-marginaliseringsproceduren en rad modellkompletteringar som leder till en mer konsekvent lösning. Generering av olika svar för en given prompt är möjlig på grund av användningen av en stokastisk snarare än girig avkodningsstrategi.
Följande figur visar hur självständighet skiljer sig från girig CoT genom att den genererar en mångfald av resonemangsvägar och aggregerar dem för att producera det slutliga svaret.

Avkodningsstrategier för textgenerering
Text som genereras av språkmodeller med enbart avkodare utvecklas ord för ord, och den efterföljande symbolen förutsägs utifrån det föregående sammanhanget. För en given prompt beräknar modellen en sannolikhetsfördelning som indikerar sannolikheten för att varje token dyker upp nästa i sekvensen. Avkodning innebär att översätta dessa sannolikhetsfördelningar till faktisk text. Textgenerering förmedlas av en uppsättning av inferensparametrar som ofta är hyperparametrar för själva avkodningsmetoden. Ett exempel är temperatur, som modulerar sannolikhetsfördelningen för nästa token och påverkar slumpmässigheten i modellens utdata.
Girig avkodning är en deterministisk avkodningsstrategi som vid varje steg väljer den token med högst sannolikhet. Även om det är enkelt och effektivt, riskerar tillvägagångssättet att hamna i repetitiva mönster, eftersom det bortser från det bredare sannolikhetsutrymmet. Att ställa in temperaturparametern till 0 vid slutledningstidpunkten är i huvudsak detsamma som att implementera girig avkodning.
provtagning introducerar stokasticitet i avkodningsprocessen genom att slumpmässigt välja varje efterföljande token baserat på den förutsagda sannolikhetsfördelningen. Denna slumpmässighet resulterar i större outputvariabilitet. Stokastisk avkodning visar sig vara skickligare på att fånga mångfalden av potentiella utdata och ger ofta mer fantasifulla svar. Högre temperaturvärden introducerar fler fluktuationer och ökar kreativiteten i modellens respons.
Uppmaningstekniker: CoT och självständighet
Resonemangsförmågan hos språkmodeller kan utökas genom snabb ingenjörskonst. I synnerhet har CoT visat sig framkalla resonemang i komplexa NLP-uppgifter. Ett sätt att implementera en nollskott CoT är via snabb förstärkning med instruktionen att "tänka steg för steg." En annan är att exponera modellen för exemplar av mellanliggande resonemangssteg in uppmaning till få skott mode. Båda scenarierna använder vanligtvis girig avkodning. CoT leder till betydande prestandavinster jämfört med enkel instruktion som uppmanar till aritmetiska, sunt förnuft och symboliska resonemangsuppgifter.
Självkonsekvent maning bygger på antagandet att införande av mångfald i resonemangsprocessen kan vara fördelaktigt för att hjälpa modeller att konvergera till det korrekta svaret. Tekniken använder stokastisk avkodning för att uppnå detta mål i tre steg:
- Uppmana språkmodellen med CoT-exemplar för att få fram resonemang.
- Ersätt girig avkodning med en samplingsstrategi för att generera en mångsidig uppsättning resonemangsvägar.
- Aggregera resultaten för att hitta det mest konsekventa svaret i svarsuppsättningen.
Självkonsekvens har visat sig överträffa CoT-uppmaning på populära aritmetiska och sunt förnuftsresonemang. En begränsning av metoden är dess större beräkningskostnad.
Det här inlägget visar hur självkonsistensförmaning förbättrar prestandan för generativa språkmodeller på två NLP-resonemangsuppgifter: aritmetisk problemlösning och flervalsdomänspecifikt frågesvar. Vi demonstrerar tillvägagångssättet med hjälp av batch-inferens på Amazon Bedrock:
- Vi kommer åt Amazon Bedrock Python SDK i JupyterLab på en Amazon SageMaker anteckningsbok instans.
- För aritmetiska resonemang frågar vi Sammanhängande kommando på GSM8K-datauppsättningen av matematikproblem i grundskolan.
- För flervalsresonemang frågar vi AI21 Labs Jurassic-2 Mid på ett litet urval av frågor från AWS Certified Solutions Architect – Associate-examen.
Förutsättningar
Denna genomgång förutsätter följande förutsättningar:

Den uppskattade kostnaden för att köra koden som visas i det här inlägget är 100 USD, förutsatt att du kör självkonsistensfråga en gång med 30 resonemangsvägar med ett värde för den temperaturbaserade provtagningen.
Datauppsättning för att undersöka aritmetiska resonemangsmöjligheter
GSM8K är en datauppsättning av mänskliga sammansatta matematikproblem i grundskolan med en hög språklig mångfald. Varje problem tar 2–8 steg att lösa och kräver att man utför en sekvens av elementära beräkningar med grundläggande aritmetiska operationer. Dessa data används vanligtvis för att jämföra flerstegs aritmetiska resonemangsförmåga hos generativa språkmodeller. De GSM8K tågset omfattar 7,473 XNUMX poster. Följande är ett exempel:
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
Ställ in för att köra batch-inferens med Amazon Bedrock
Batch-inferens låter dig köra flera slutledningsanrop till Amazon Bedrock asynkront och förbättra prestandan för modellinferens på stora datamängder. Tjänsten är i förhandsvisning när detta skrivs och endast tillgänglig via API:et. Hänvisa till Kör batch slutledning för att komma åt batch-inferens-API:er via anpassade SDK:er.
När du har laddat ner och packat upp Python SDK i en SageMaker-anteckningsbok-instans kan du installera den genom att köra följande kod i en Jupyter-anteckningsbokcell:
Formatera och ladda upp indata till Amazon S3
Indata för batch-inferens måste förberedas i JSONL-format med recordId och modelInput nycklar. Den senare bör matcha kroppsfältet för modellen som ska anropas på Amazon Bedrock. I synnerhet vissa inferensparametrar som stöds för Cohere Command är temperature för slumpen, max_tokens för utmatningslängd, och num_generations för att generera flera svar, som alla skickas tillsammans med prompt as modelInput:
Se Inferensparametrar för grundmodeller för mer information, inklusive andra modellleverantörer.
Våra experiment med aritmetiska resonemang utförs i inställningen få skott utan att anpassa eller finjustera Cohere Command. Vi använder samma uppsättning av åtta få-shot exemplar från kedjan-of-thought (Tabell 20) och självständighet (Tabell 17) papper. Uppmaningar skapas genom att sammanfoga exemplen med varje fråga från GSM8K-tågsetet.
Vi sätter max_tokens till 512 och num_generations till 5, det högsta tillåtna av Cohere Command. För girig avkodning ställer vi in temperature till 0 och för självständighet kör vi tre experiment vid temperaturerna 0.5, 0.7 och 1. Varje inställning ger olika indata enligt respektive temperaturvärden. Data formateras som JSONL och lagras i Amazon S3.
Skapa och kör batch slutledningsjobb i Amazon Bedrock
Att skapa jobb för batch slutledningar kräver en Amazon Bedrock-klient. Vi specificerar S3-inmatnings- och utmatningsvägarna och ger varje anropsjobb ett unikt namn:
Jobb är skapas genom att skicka IAM-rollen, modell-ID, jobbnamn och in-/utgångskonfiguration som parametrar till Amazon Bedrock API:
notering, övervakningoch stoppa batch slutledningsjobb stöds av deras respektive API-anrop. Vid skapande visas jobb först som Submitted, då som InProgress, och slutligen som Stopped, Failed, eller Completed.
Om jobben slutförs framgångsrikt kan det genererade innehållet hämtas från Amazon S3 med hjälp av dess unika utdataplats.
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
Självkonsistens förbättrar modellens noggrannhet på aritmetiska uppgifter
Cohere Commands självständighetsfråga överträffar en girig CoT-baslinje när det gäller noggrannhet på GSM8K-datauppsättningen. För självständighet provar vi 30 oberoende resonemangsvägar vid tre olika temperaturer, med topP och topK inställd på deras ursprungliga värden. Slutliga lösningar aggregeras genom att välja den mest konsekventa förekomsten via majoritetsomröstning. Om det blir lika, väljer vi slumpmässigt ett av majoritetens svar. Vi beräknar noggrannhets- och standardavvikelsevärden i genomsnitt över 100 körningar.
Följande figur visar noggrannheten på GSM8K-datauppsättningen från Cohere Command med girig CoT (blå) och självkonsistens vid temperaturvärdena 0.5 (gul), 0.7 (grön) och 1.0 (orange) som en funktion av antalet samplade resonemangsvägar.
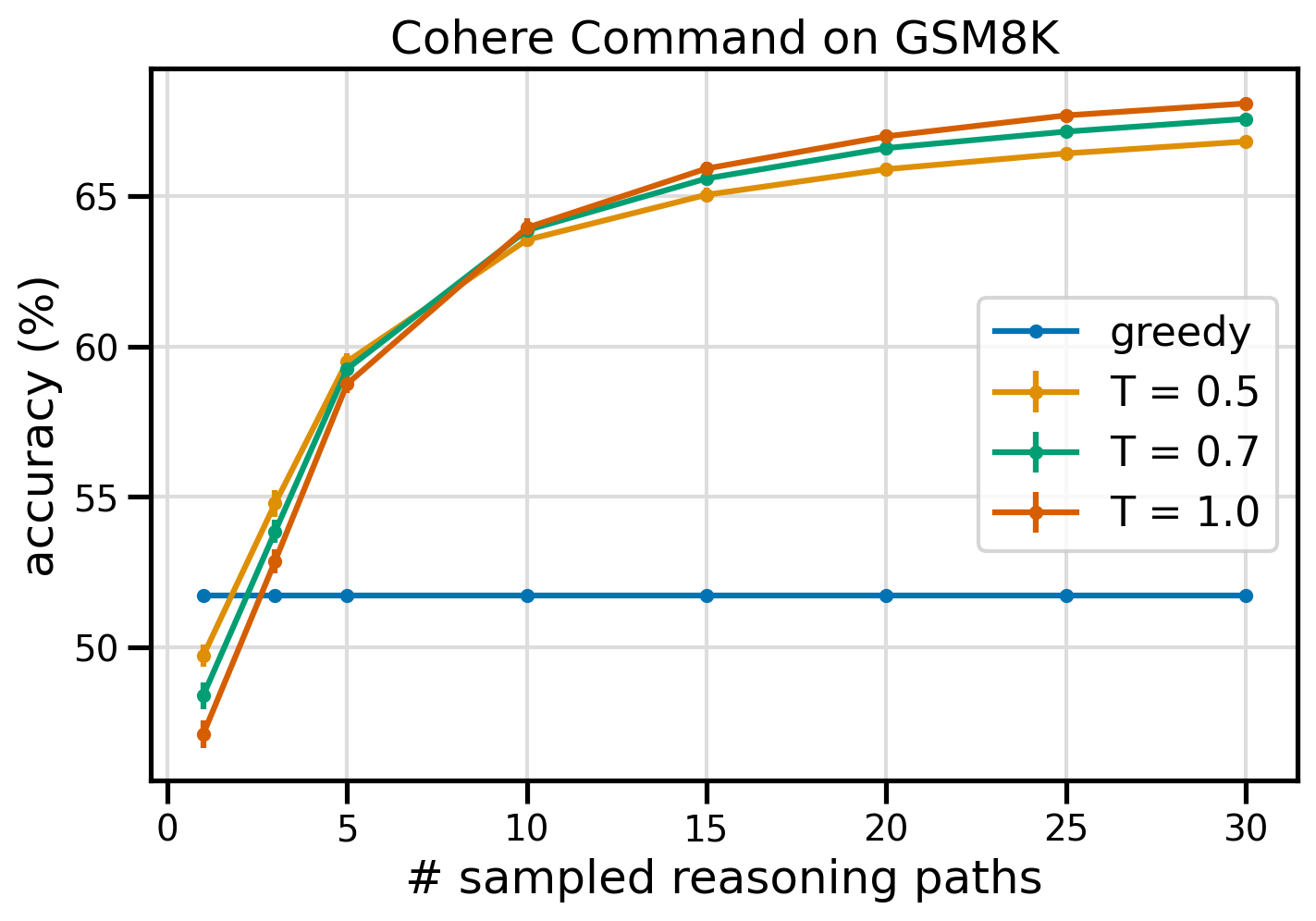
Den föregående figuren visar att självkonsistens förbättrar aritmetisk noggrannhet jämfört med giriga CoT när antalet samplade vägar är så lågt som tre. Prestanda ökar konsekvent med ytterligare resonemangsvägar, vilket bekräftar vikten av att införa mångfald i tankegenereringen. Cohere Command löser GSM8K frågeuppsättningen med 51.7 % noggrannhet när du uppmanas med CoT kontra 68 % med 30 självständiga resonemangsvägar vid T=1.0. Alla tre undersökta temperaturvärden ger liknande resultat, med lägre temperaturer som är jämförelsevis mer presterande vid mindre samplade vägar.
Praktiska överväganden om effektivitet och kostnad
Självständighet begränsas av den ökade svarstiden och kostnaden som uppstår när flera utdata genereras per prompt. Som en praktisk illustration, batch slutledning för girig generering med Cohere Command på 7,473 8 GSM20K-skivor avslutades på mindre än 5.5 minuter. Jobbet tog 630,000 miljoner tokens som input och genererade XNUMX XNUMX output-tokens. För närvarande Amazon Bedrock slutledningspriser, var den totala kostnaden runt $9.50.
För självständighet med Cohere Command använder vi inferensparameter num_generations för att skapa flera kompletteringar per prompt. När detta skrivs tillåter Amazon Bedrock maximalt fem generationer och tre samtidigt Submitted batch slutledningsjobb. Jobben fortsätter till InProgress status sekventiellt, därför kräver sampling av fler än fem vägar flera anrop.
Följande figur visar körtiderna för Cohere Command på GSM8K-datauppsättningen. Total körtid visas på x-axeln och körtid per samplade resonemangsbana på y-axeln. Girig generation går på kortast tid men medför en högre tidskostnad per provad väg.

Girig generation slutförs på mindre än 20 minuter för hela GSM8K-setet och provar en unik resonemangsväg. Självkonsekvens med fem prover kräver cirka 50 % längre tid att slutföra och kostar cirka 14.50 USD, men ger fem vägar (över 500 %) under den tiden. Den totala körtiden och kostnaderna ökar stegvis för varje extra fem samplade vägar. En kostnads-nyttoanalys tyder på att 1–2 batch slutledningsjobb med 5–10 provade vägar är den rekommenderade inställningen för praktisk implementering av självkonsistens. Detta uppnår förbättrad modellprestanda samtidigt som kostnader och fördröjning hålls i schack.
Självkonsistens förbättrar modellens prestanda bortom aritmetiska resonemang
En avgörande fråga för att bevisa lämpligheten av självkonsekvensuppmaning är om metoden lyckas över ytterligare NLP-uppgifter och språkmodeller. Som en förlängning av ett Amazon-relaterat användningsfall utför vi en liten analys av exempelfrågor från AWS Solutions Architect Associate-certifiering. Detta är ett flervalsprov om AWS-teknik och tjänster som kräver domänkunskap och förmåga att resonera och välja mellan flera alternativ.
Vi förbereder ett dataset från SAA-CO01 och SAA-CO03 provfrågor. Av de 20 tillgängliga frågorna använder vi de fyra första som exemplar av få skott och uppmanar modellen att svara på de återstående 4. Den här gången kör vi slutledning med AI16 Labs Jurassic-21 Mid-modell och genererar maximalt 2 resonemangsvägar vid temperatur 10. Resultaten visar att självständighet förbättrar prestandan: även om giriga CoT ger 0.7 korrekta svar, lyckas självkonsekvens på ytterligare två.
Följande tabell visar noggrannhetsresultaten för 5 och 10 provade banor, i genomsnitt över 100 körningar.
| . | Girig avkodning | T = 0.7 |
| # provade sökvägar: 5 | 68.6 | 74.1 0.7 ± |
| # provade sökvägar: 10 | 68.6 | 78.9 ± 0.3 |
I följande tabell presenterar vi två tentamensfrågor som besvaras felaktigt av giriga CoT medan självkonsekvensen lyckas, och i varje enskilt fall lyfter vi fram de korrekta (gröna) eller felaktiga (röda) resonemangsspåren som fick modellen att producera korrekta eller felaktiga svar. Även om inte alla samplade vägar som genereras av självkonsekvens är korrekta, konvergerar majoriteten på det sanna svaret när antalet samplade vägar ökar. Vi observerar att 5–10 vägar vanligtvis räcker för att förbättra de giriga resultaten, med minskande avkastning i termer av effektivitet över dessa värden.
| Fråga |
En webbapplikation låter kunder ladda upp beställningar till en S3-hink. De resulterande Amazon S3-händelserna utlöser en Lambda-funktion som infogar ett meddelande i en SQS-kö. En enda EC2-instans läser meddelanden från kön, bearbetar dem och lagrar dem i en DynamoDB-tabell partitionerad med unikt order-ID. Nästa månad förväntas trafiken öka med en faktor 10 och en Solutions Architect ser över arkitekturen för eventuella skalningsproblem. Vilken komponent är mest sannolikt att behöva omarkitektur för att kunna skalas för att rymma den nya trafiken? A. Lambdafunktion |
En applikation som körs på AWS använder en Amazon Aurora Multi-AZ DB-klusterdistribution för sin databas. Vid utvärdering av prestandamått upptäckte en lösningsarkitekt att databasläsningarna orsakar hög I/O och lägger till latens till skrivförfrågningarna mot databasen. Vad ska lösningsarkitekten göra för att skilja läsbegäran från skrivbegäran? A. Aktivera genomläsningscache i Aurora-databasen. |
| Rätt svar | C – En enskild EC2-instans kommer inte att skalas och är en enda felpunkt i arkitekturen. En mycket bättre lösning skulle vara att ha EC2-instanser i en Auto Scaling-grupp över 2 tillgänglighetszoner som läser meddelanden från kön. De andra svaren är alla hanterade tjänster som kan konfigureras för att skalas eller kommer att skalas automatiskt. | C – Aurora-repliker ger ett sätt att avlasta lästrafik. Aurora Replicas delar samma underliggande lagring som huvuddatabasen, så eftersläpningstiden är i allmänhet mycket låg. Aurora Replicas har sina egna ändpunkter, så applikationen måste konfigureras för att dirigera lästrafik till de nya ändpunkterna. |
| Girig avkodning | Det är kanske inte möjligt att skala EC2-instansen direkt, eftersom det kanske inte går att ändra storlek på instansen. Det är kanske inte tillräckligt att skala lambdafunktionen, eftersom Lambda-funktioner har en 6 GB minnesallokeringsgräns. Det är kanske inte tillräckligt att skala SQS-kön, eftersom SQS har en gräns på 10,000 XNUMX meddelanden. DynamoDB-tabeller kan skalas genom att tillhandahålla fler kapacitetsenheter. Det rätta svaret är D. | Ändra programmet för att läsa från Multi-AZ standby-instansen (alternativ B) är det bästa tillvägagångssättet. Standby-instansen replikeras asynkront från den primära instansen, så läsoperationer kommer inte att störa skrivoperationer. Aktivera genomläsningscache (alternativ A) eller Att skapa en Aurora-replika (alternativ C) kommer inte att lösa problemet med I/O-striden. Att skapa en andra Aurora-databas och länka den som en läsreplika (alternativ D) kommer inte heller att lösa problemet med I/O-striden. Rätt svar är B. |
| Provväg #1 | Att skala EC2-instansen till 10 gånger dess nuvarande storlek kanske inte är genomförbart, vare sig ur ett kostnads- eller prestandaperspektiv. Det skulle kräva en större instans, vilket kan bli dyrt. Ett mer kostnadseffektivt tillvägagångssätt kan vara att använda en svärm av mindre instanser (t.ex. Auto Scaling Group) för att dela belastningen. I det här fallet skulle EC2-instansen troligen behöva omarbetas. Rätt svar är C. | Att modifiera applikationen för att använda lämpliga slutpunkter är inte en praktisk lösning eftersom det skulle kräva ändringar av applikationskoden. Rätt svar är C: Skapa en Aurora-replika och modifiera applikationen för att använda lämpliga slutpunkter. |
| Provväg #2 | Att skala en enskild EC2-instans är svårare och mer problematiskt än att skala de andra tjänstekomponenterna. Amazon SQS, Lambda och DynamoDB kan alla skalas automatiskt för att klara den ökade belastningen. Rätt svar är C. |
(C) Skapa en Aurora-replika och modifiera applikationen för att använda lämpliga slutpunkter. Genom att konfigurera en Aurora Replica kan du separera lästrafik från skrivtrafik. Aurora-replikerna använder olika slutpunkts-URL:er, så att du kan dirigera lästrafik till repliken istället för den primära databasen. Repliken kan behandla läsbegäranden parallellt med skrivbegäranden till den primära databasen, vilket minskar I/O och latens. |
Städa upp
Att köra batch-inferens i Amazon Bedrock är föremål för avgifter enligt Amazon Bedrock-prissättning. När du har slutfört genomgången, radera din SageMaker-anteckningsbok-instans och ta bort all data från dina S3-hinkar för att undvika framtida avgifter.
Överväganden
Även om den demonstrerade lösningen visar förbättrad prestanda för språkmodeller när du uppmanas med självständighet, är det viktigt att notera att genomgången inte är produktionsklar. Innan du distribuerar till produktion bör du anpassa detta proof of concept till din egen implementering, med tanke på följande krav:
- Åtkomstbegränsning till API:er och databaser för att förhindra obehörig användning.
- Efterlevnad av bästa praxis för AWS-säkerhet angående IAM-rollåtkomst och säkerhetsgrupper.
- Validering och sanering av användarinmatning för att förhindra snabba injektionsattacker.
- Övervakning och loggning av utlösta processer för att möjliggöra testning och revision.
Slutsats
Det här inlägget visar att uppmaning om självständighet förbättrar prestandan hos generativa språkmodeller i komplexa NLP-uppgifter som kräver aritmetiska och logiska flervalsfärdigheter. Självkonsistens använder temperaturbaserad stokastisk avkodning för att generera olika resonemangsvägar. Detta ökar modellens förmåga att få fram olika och användbara tankar för att komma fram till korrekta svar.
Med Amazon Bedrock batch-inferens, uppmanas språkmodellen Cohere Command att generera självständiga svar på en uppsättning aritmetiska problem. Noggrannheten förbättras från 51.7 % med girig avkodning till 68 % med självkonsistenssampling 30 resonemangsvägar vid T=1.0. Sampling av fem vägar ökar redan precisionen med 7.5 procentenheter. Tillvägagångssättet kan överföras till andra språkmodeller och resonemangsuppgifter, vilket visas av resultaten från AI21 Labs Jurassic-2 Mid-modellen på en AWS-certifieringsexamen. I en liten frågeuppsättning ökar självkonsekvens med fem samplade vägar noggrannheten med 5 procentenheter jämfört med giriga CoT.
Vi uppmuntrar dig att implementera självkonsekvensuppmaning för förbättrad prestanda i dina egna applikationer med generativa språkmodeller. Lära sig mer om Sammanhängande kommando och AI21 Labs Jurassic modeller tillgängliga på Amazon Bedrock. För mer information om batch slutledning, se Kör batch slutledning.
Tack
Författaren tackar tekniska granskare Amin Tajgardoon och Patrick McSweeney för användbar feedback.
Om författaren

Lucía Santamaría är en Sr. Applied Scientist vid Amazons ML University, där hon fokuserar på att höja nivån på ML-kompetens i hela företaget genom praktisk utbildning. Lucía har en doktorsexamen i astrofysik och brinner för att demokratisera tillgången till teknisk kunskap och verktyg.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/enhance-performance-of-generative-language-models-with-self-consistency-prompting-on-amazon-bedrock/

