Många organisationer runt om i världen förlitar sig på användningen av fysiska tillgångar, såsom fordon, för att leverera en tjänst till sina slutkunder. Genom att spåra dessa tillgångar i realtid och lagra resultaten kan tillgångsägare få värdefulla insikter om hur deras tillgångar används för att kontinuerligt leverera affärsförbättringar och planera för framtida förändringar. Till exempel kan ett leveransföretag som driver en fordonsflotta behöva ta reda på effekterna av lokala policyändringar utanför deras kontroll, såsom den aviserade utvidgningen av en Zon med ultralåga utsläpp (ULEZ). Genom att kombinera historiska fordonslokaliseringsdata med information från andra källor kan företaget ta fram empiriska tillvägagångssätt för bättre beslutsfattande. Till exempel kan företagets inköpsteam använda denna information för att fatta beslut om vilka fordon som ska prioriteras för utbyte innan policyändringar träder i kraft.
Utvecklare kan använda stödet i Amazon platstjänst för publicera enhetspositionsuppdateringar till Amazon EventBridge att bygga en nästan realtidsdatapipeline som lagrar platser för spårade tillgångar i Amazon enkel lagringstjänst (Amazon S3). Dessutom kan du använda AWS Lambda för att berika inkommande platsdata med data från andra källor, såsom en Amazon DynamoDB tabell med information om fordonsunderhåll. Då kan en dataanalytiker använda geospatiala frågemöjligheter of Amazonas Athena för att få insikter, såsom antalet dagar deras fordon har körts inom de föreslagna gränserna för en utökad ULEZ. Eftersom fordon som inte uppfyller ULEZs utsläppsstandarder utsätts för en daglig avgift för att köra inom zonen, kan du använda platsdata, tillsammans med underhållsdata som fordonets ålder, nuvarande körsträcka och aktuella utsläppsstandarder för att uppskatta mängden företaget skulle behöva spendera på dagliga avgifter.
Det här inlägget visar hur du kan använda Amazon Location, EventBridge, Lambda, Amazon Data Firehose, och Amazon S3 för att bygga en platsmedveten datapipeline och använda dessa data för att skapa meningsfulla insikter med AWS-lim och Athena.
Översikt över lösningen
Detta är en helt serverlös lösning för platsbaserad tillgångshantering. Lösningen består av följande gränssnitt:
- IoT eller mobilapplikation – En mobilapplikation eller en Internet of Things (IoT)-enhet tillåter spårning av ett företagsfordon medan det används och överför sin nuvarande plats säkert till dataintagslagret i AWS. Intagsmetoden omfattas inte av detta inlägg. Istället simulerar en Lambda-funktion i vår lösning exempel på fordonsresor och uppdaterar direkt Amazon Location tracker-objekt med randomiserade platser.
- Dataanalys – Affärsanalytiker samlar in operativa insikter från flera datakällor, inklusive platsdata som samlas in från fordonen. Dataanalytiker letar efter svar på frågor som, "Hur lång tid har ett givet fordon historiskt tillbringat i en föreslagen zon och hur mycket skulle avgifterna ha kostat om policyn varit på plats under de senaste 12 månaderna?"
Följande diagram illustrerar lösningsarkitekturen.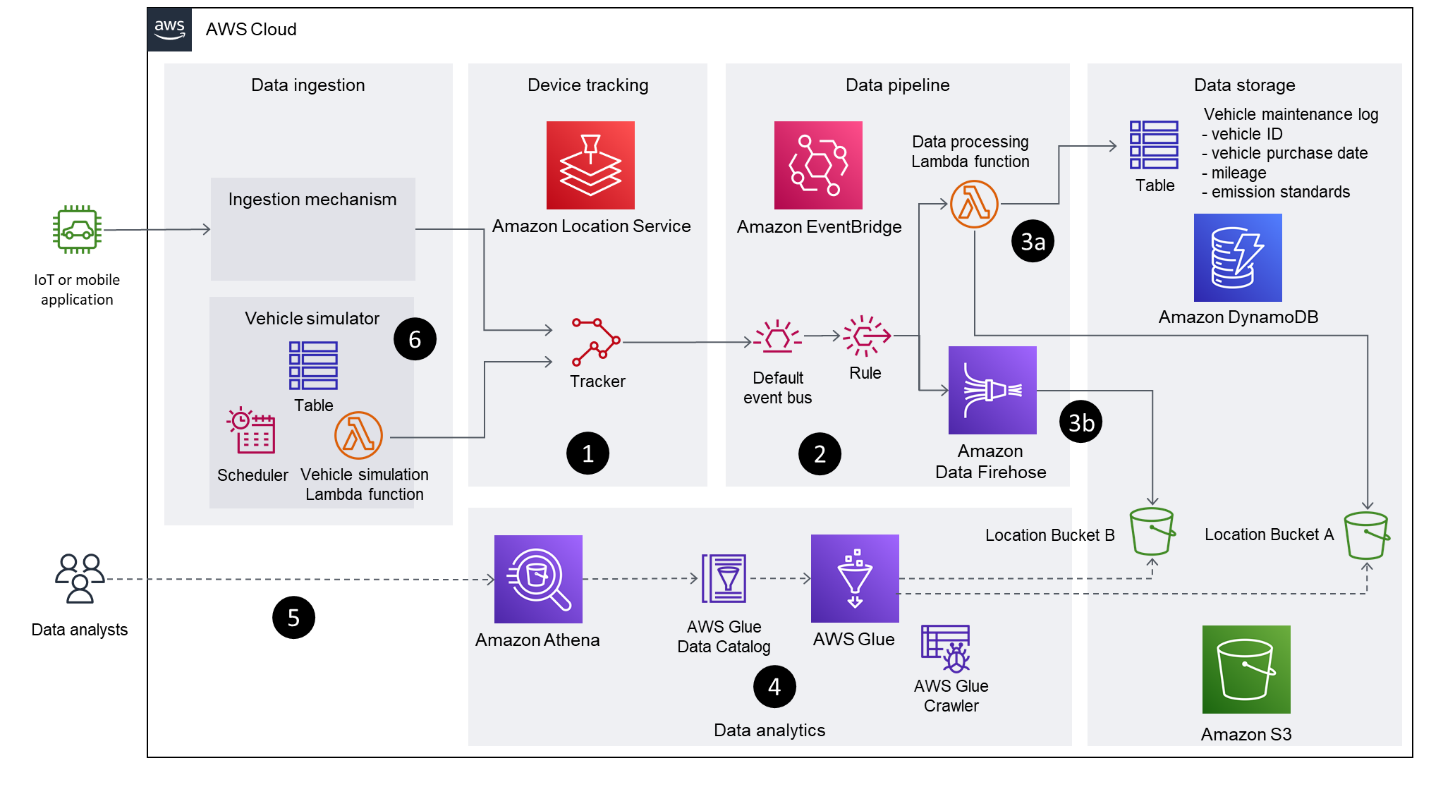
Arbetsflödet består av följande nyckelsteg:
- Spårningsfunktionen för Amazon Location används för att spåra fordonet. Genom att använda EventBridge-integration publiceras filtrerade positionsuppdateringar till en EventBridge-händelsebuss. Denna lösning använder avståndsbaserad filtrering för att minska kostnader och jitter. Avståndsbaserad filtrering ignorerar platsuppdateringar där enheter har rört sig mindre än 30 meter (98.4 fot).
- Amazon Location enhetspositionshändelser anländer till EventBridge
defaultbuss medsource: ["aws.geo"]ochdetail-type: ["Location Device Position Event"]. En regel skapas för att vidarebefordra dessa händelser till två nedströmsmål: en Lambda-funktion och en Firehose-leveransström. - Två olika mönster, baserade på varje mål, beskrivs i det här inlägget för att visa olika metoder för att överföra data till en S3-hink:
- Lambdafunktion – Det första tillvägagångssättet använder en Lambda-funktion för att visa hur du kan använda kod i datapipeline för att direkt transformera inkommande platsdata. Du kan modifiera Lambdafunktionen för att hämta ytterligare fordonsinformation från ett separat datalager (till exempel en DynamoDB-tabell eller ett Customer Relationship Management-system) för att berika data, innan du lagrar resultaten i en S3-hink. I denna modell anropas Lambda-funktionen för varje inkommande händelse.
- Leveransström för brandslang – Den andra metoden använder en Firehose-leveransström för att buffra och batcha de inkommande positionsuppdateringarna, innan de lagras i en S3-hink utan modifiering. Den här metoden använder GZIP-komprimering för att optimera lagringsförbrukning och frågeprestanda. Du kan också använda datatransformation funktion i Data Firehose för att anropa en Lambda-funktion för att utföra datatransformation i batcher.
- AWS Glue genomsöker båda S3-hinkvägarna, fyller i AWS Glue-databastabellerna baserat på de härledda schemana och gör data tillgänglig för andra analysapplikationer via AWS Glue Data Catalog.
- Athena används för att köra geospatiala frågor på platsdata som lagras i S3-hinkarna. Datakatalogen tillhandahåller metadata som gör att analysapplikationer som använder Athena kan hitta, läsa och bearbeta platsdata som lagras i Amazon S3.
- Denna lösning innehåller en Lambda-funktion som kontinuerligt uppdaterar Amazon Location tracker med simulerad platsdata från fiktiva resor. Lambdafunktionen utlöses med jämna mellanrum med hjälp av en schemalagd EventBridge-regel.
Du kan testa den här lösningen själv med hjälp av AWS Samples GitHub repository. Förvaret innehåller AWS serverlös applikationsmodell (AWS SAM) mall och lambdakod krävs för att testa denna lösning. Se instruktionerna i README fil för steg för hur man tillhandahåller och avvecklar denna lösning.
Visuella layouter i vissa skärmdumpar i det här inlägget kan se annorlunda ut än de på din AWS Management Console.
Datagenerering
I det här avsnittet diskuterar vi stegen för att manuellt eller automatiskt generera resedata.
Generera resedata manuellt
Du kan manuellt uppdatera enhetspositioner med hjälp av AWS-kommandoradsgränssnitt (AWS CLI) kommando aws location batch-update-device-position. Ersätt tracker-name, device-id, Positionoch SampleTime värden med dina egna, och se till att successiva uppdateringar är mer än 30 meter från varandra för att placera ett evenemang på default EventBridge event buss:
Generera resedata automatiskt med simulatorn
Den tillhandahållna AWS molnformation mallen distribuerar en EventBridge-schemalagd regel och en tillhörande Lambda-funktion som simulerar spårningsuppdateringar från fordon. Den här regeln är aktiverad som standard och körs med en frekvens som anges av SimulationIntervalMinutes CloudFormation-parameter. Datagenereringens Lambda-funktion uppdaterar Amazon Location tracker med en slumpmässig positionsförskjutning från fordonens basplatser.
Fordonsnamn och basplatser lagras i fordon.json fil. Ett fordons startposition återställs varje dag, och basplatser har valts ut för att ge dem möjlighet att glida in och ut ur ULEZ en viss dag för att ge en realistisk resesimulering.
Du kan inaktivera regeln tillfälligt genom att navigera till de schemalagda regeldetaljerna på EventBridge-konsolen. Alternativt kan du ändra parametern State: ENABLED till State: DISABLED för den schemalagda regelresursen GenerateDevicePositionsScheduleRule i mall.yml fil. Bygg om och distribuera om AWS SAM-mallen för att denna ändring ska träda i kraft.
Platsdatapipeline närmar sig
Konfigurationerna som beskrivs i det här avsnittet distribueras automatiskt av den medföljande AWS SAM-mallen. Informationen i detta avsnitt tillhandahålls för att beskriva de relevanta delarna av lösningen.
Amazon Location enhetspositionshändelser
Amazon Location skickar händelser för uppdatering av enhetsposition till EventBridge i följande format:
Du kan valfritt ange en ingångsomvandling för att ändra formatet och innehållet i enhetens positionshändelsedata innan den når målet.
Databerikning med Lambda
Dataanrikning i detta mönster underlättas genom anropet av en lambdafunktion. I det här exemplet kallar vi denna funktion ProcessDevicePosition, och använd en Python-körtid. En anpassad transformation tillämpas i EventBridge-måldefinitionen för att ta emot händelsedata i följande format:
Du kan tillämpa ytterligare omvandlingar, såsom refaktorering av Latitude och Longitude data i separata nyckel-värdepar om detta krävs av nedströms affärslogik som bearbetar händelserna.
Följande kod visar Python-applikationslogiken som körs av ProcessDevicePosition Lambdafunktion. Felhanteringen har hoppats över i detta kodavsnitt för korthetens skull. Hela koden finns tillgänglig i GitHub repo.
Den föregående koden skapar ett S3-objekt för varje enhetspositionshändelse som tas emot av EventBridge. Koden använder DeviceId som ett prefix för att skriva objekten till hinken.
Du kan lägga till ytterligare logik till den föregående Lambda-funktionskoden för att berika händelsedata med andra källor. Exemplet i GitHub repo demonstrerar berikande av händelsen med data från en DynamoDB fordonsunderhållstabell.
Förutom förutsättningen AWS identitets- och åtkomsthantering (IAM)-behörigheter som tillhandahålls av rollen AWSBasicLambdaExecutionRole, den ProcessDevicePosition funktionen kräver behörighet för att utföra S3 put_object åtgärd och alla andra åtgärder som krävs av databerikningslogiken. IAM-behörigheter som krävs av lösningen dokumenteras i mall.yml fil.
Datapipeline med Amazon Data Firehose
Utför följande steg för att skapa din Firehose-leveransström:
- På Amazon Data Firehose-konsolen väljer du Eldslang strömmar i navigeringsfönstret.
- Välja Skapa Firehose-ström.
- För Källa, välj som Direkt PUT.
- För Destinationväljer Amazon S3.
- För Brandslangströms namn, ange ett namn (för det här inlägget,
ProcessDevicePositionFirehose).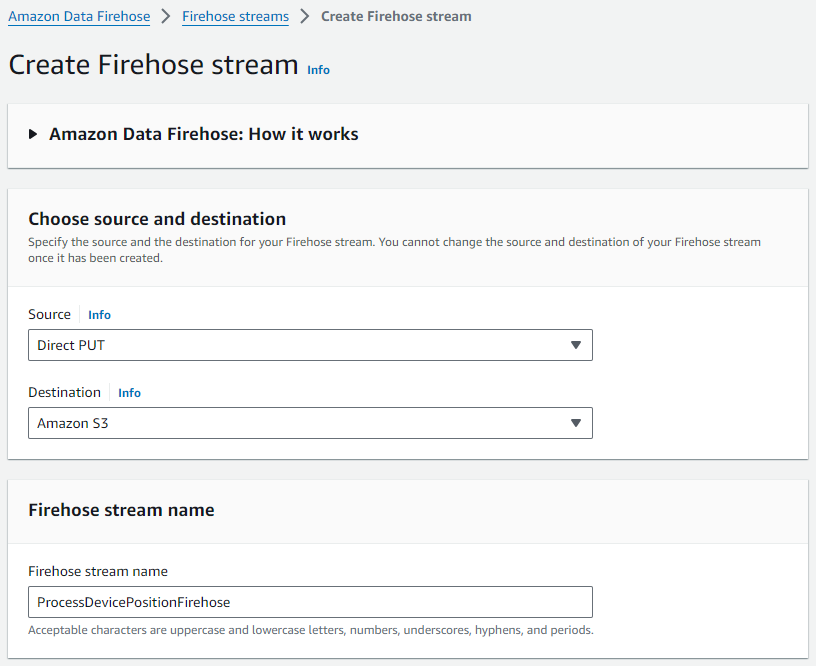
- Konfigurera destinationsinställningarna med detaljer om S3-skopan där platsdata lagras, tillsammans med partitioneringsstrategin:
- Använda och för att bestämma segmentets och objektets prefix.
- Använda
DeviceIdsom ett extra prefix för att skriva objekten till hinken.
- aktivera Dynamisk partitionering och Ny radavgränsare för att se till att partitioneringen är automatisk baserad på
DeviceId, och att nya radavgränsare läggs till mellan poster i objekt som levereras till Amazon S3.
Dessa krävs av AWS Glue för att senare genomsöka data och för att Athena ska känna igen enskilda poster.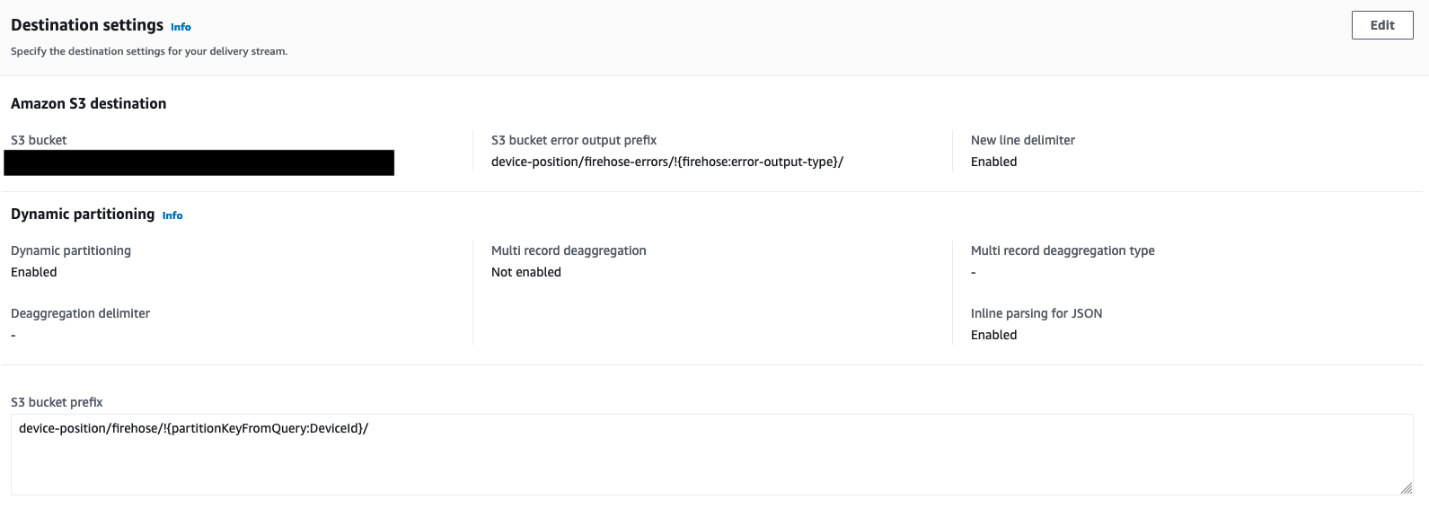
Skapa en EventBridge-regel och bifoga mål
EventBridge-regeln ProcessDevicePosition definierar två mål: den ProcessDevicePosition Lambdafunktion och ProcessDevicePositionFirehose leveransström. Utför följande steg för att skapa regeln och bifoga mål:
- Skapa en ny regel på EventBridge-konsolen.
- För Namn , ange ett namn (för det här inlägget,
ProcessDevicePosition). - För Event buss¸ välja standard.
- För RegeltypVälj Regel med ett händelsemönster.
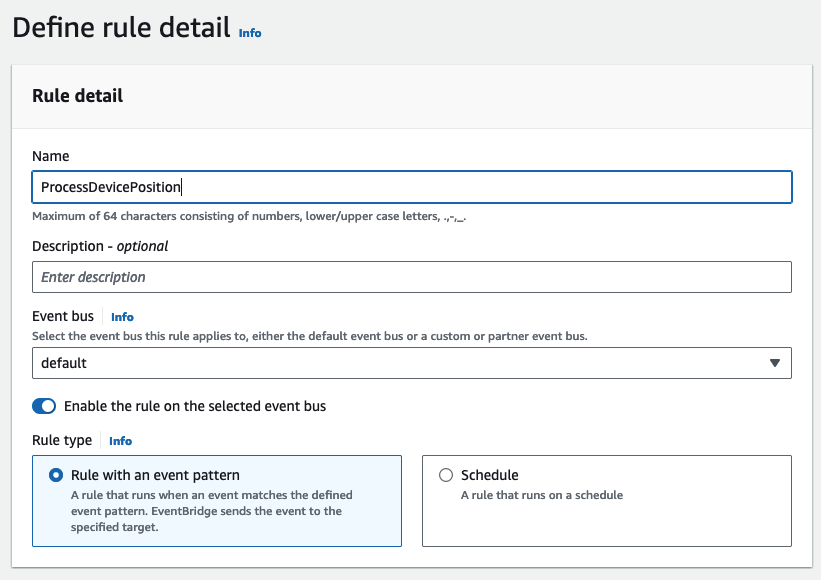
- För Händelse källa, Välj AWS-evenemang eller EventBridge-partnerevenemang.
- För Metod, Välj Använd mönsterform.
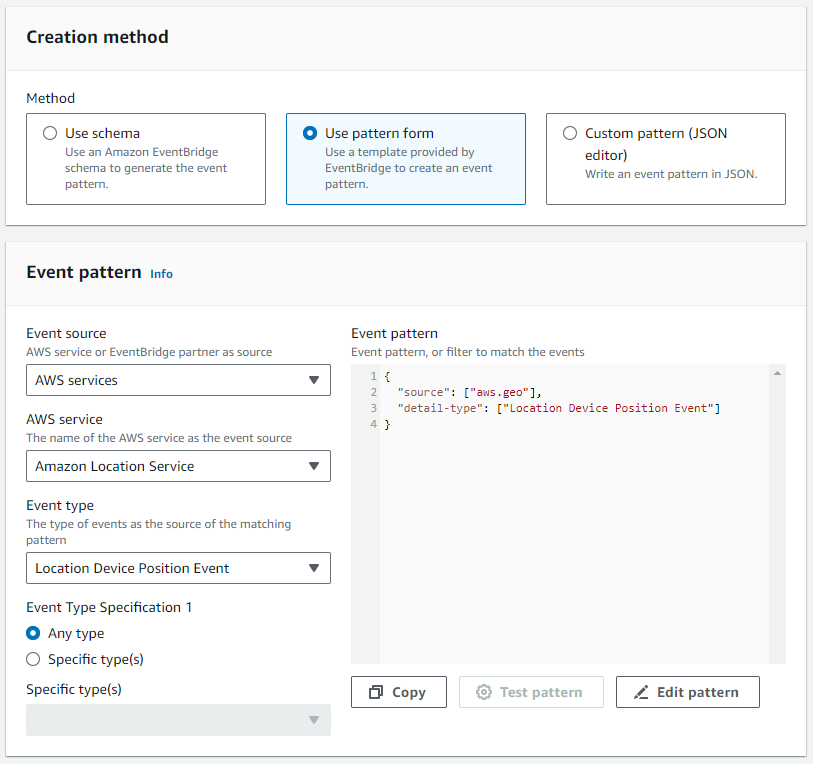
- I Händelsemönster avsnitt, ange AWS-tjänster som källa, Amazon platstjänst som den specifika tjänsten, och Plats Enhetspositionshändelse som händelsetyp.
- För Mål 1, fäst
ProcessDevicePositionLambda fungerar som mål.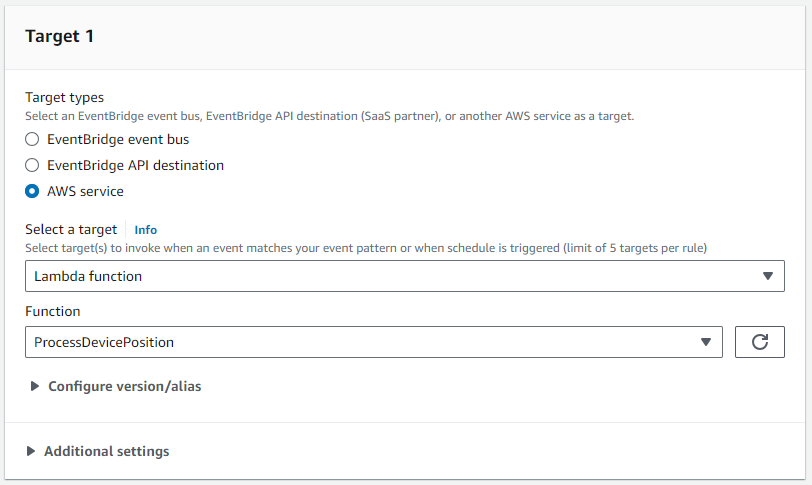
- Vi använder Ingångstransformator för att skräddarsy evenemanget som är engagerat i S3-hinken.
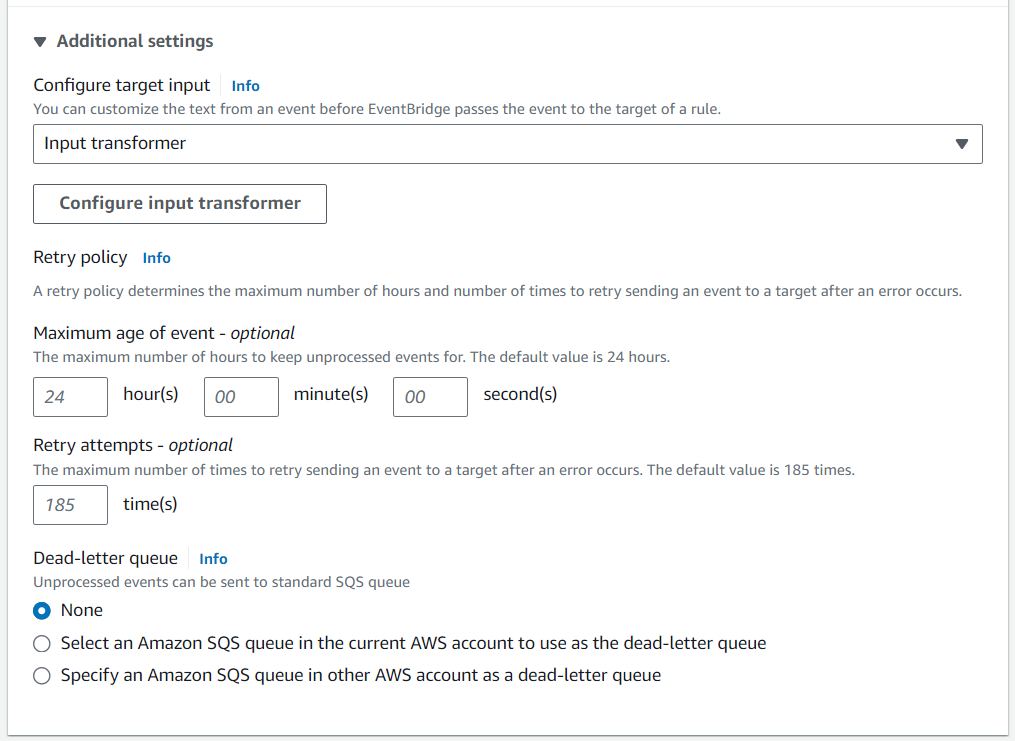
- Inställd Karta över inmatningsvägar och Inmatningsmall för att organisera nyttolasten i önskat format.
- Följande kod är kartan för inmatningsvägar:
- Följande kod är inmatningsmallen:
- För Mål 2, Välj den
ProcessDevicePositionFirehoseleveransström som mål.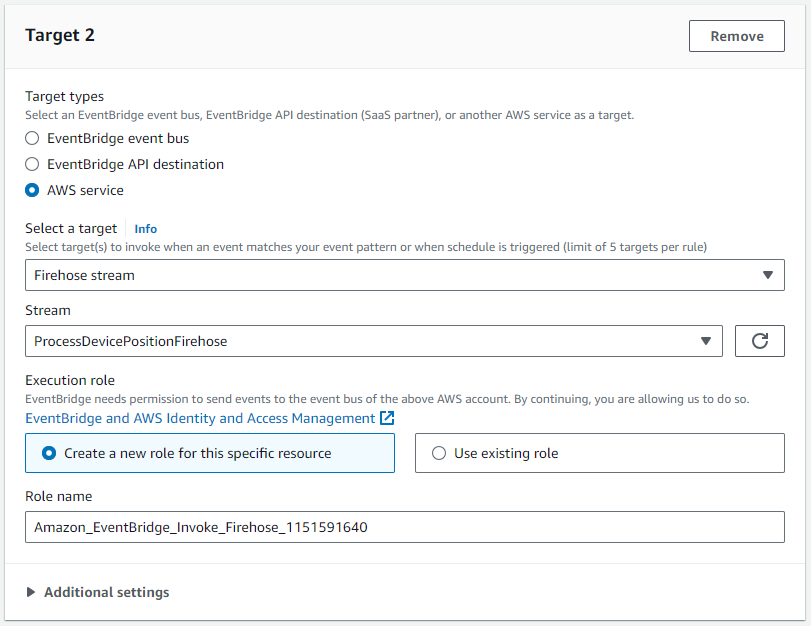
Detta mål kräver en IAM-roll som tillåter att en eller flera poster kan skrivas till Firehose-leveransströmmen:
Genomsök och katalogisera data med AWS Glue
När tillräckligt med data har genererats, slutför följande steg:
- Välj på AWS Lim-konsolen crawlers i navigeringsfönstret.
- Välj sökrobotarna som har skapats,
location-analytics-glue-crawler-lambdaochlocation-analytics-glue-crawler-firehose. - Välja Körning.
Sökrobotarna kommer automatiskt att klassificera data i JSON-format, gruppera posterna i tabeller och partitioner och överföra tillhörande metadata till AWS Glue Data Catalog.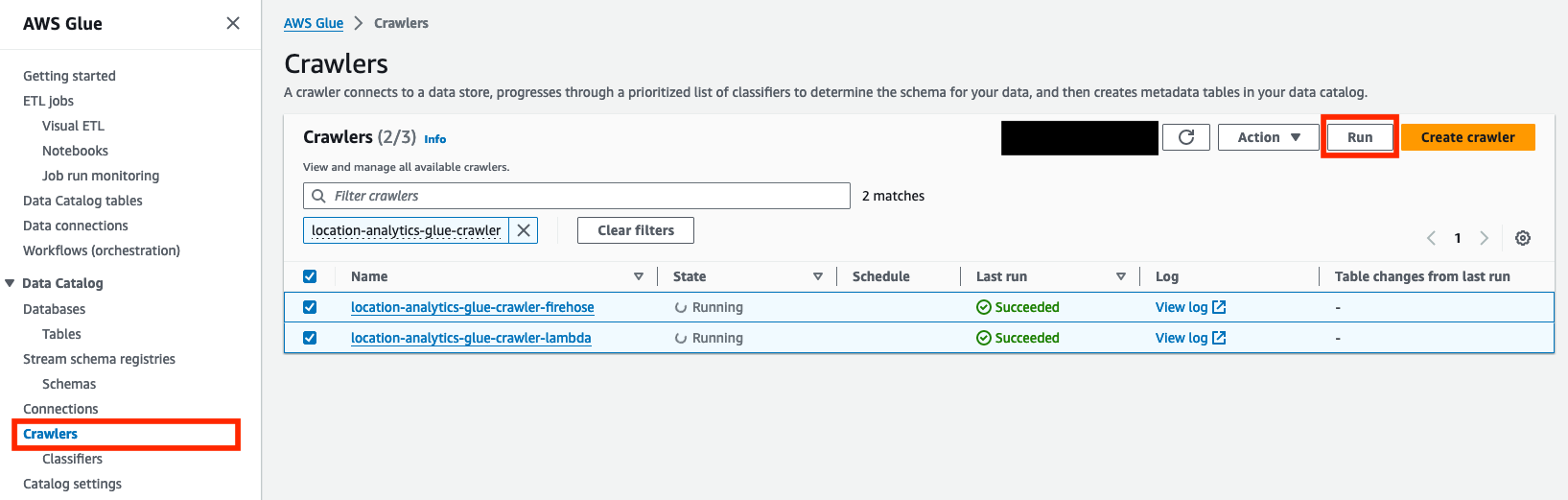
- När Sista körningen status för båda sökrobotarna visas som Lyckades, bekräfta att två tabeller (
lambdaochfirehose) har skapats på Bord sida.
Lösningen partitionerar inkommande platsdata baserat på deviceid fält. Så länge det inte finns några nya enheter eller schemaändringar behöver sökrobotarna därför inte köras igen. Men om nya enheter läggs till, eller ett annat fält används för partitionering, måste sökrobotarna köras igen.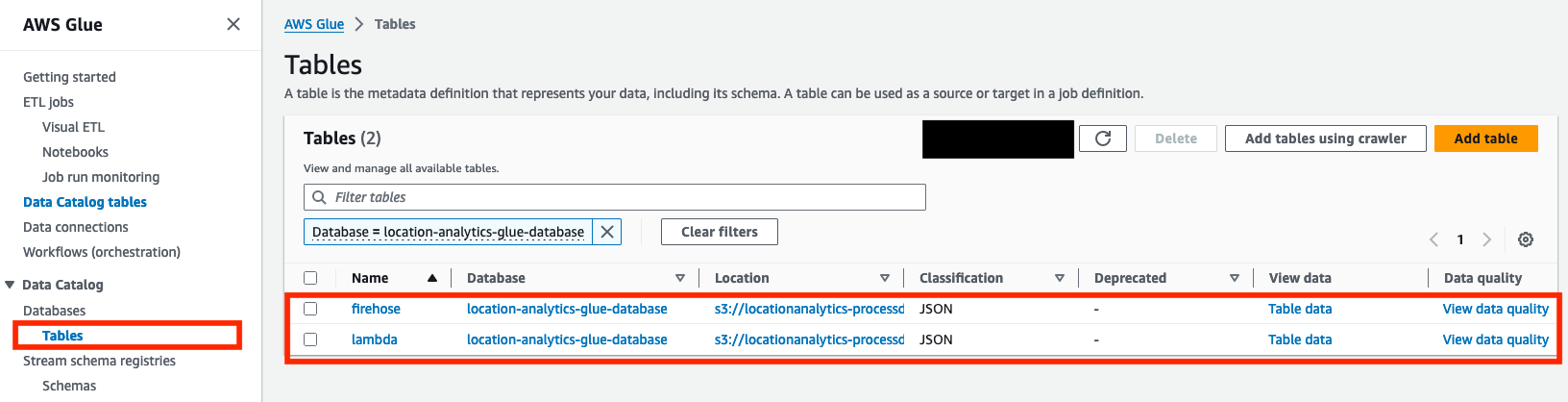
Du är nu redo att fråga tabellerna med Athena.
Fråga efter data med Athena
Athena är en serverlös, interaktiv analystjänst byggd för att analysera ostrukturerad, semistrukturerad och strukturerad data där den finns. Om det här är första gången du använder Athena-konsolen, Följ instruktionerna för att ställa in en frågeresultatplats i Amazon S3. Utför följande steg för att fråga om data med Athena:
- Öppna frågeredigeraren på Athena-konsolen.
- För Datakällaväljer
AwsDataCatalog. - För Databasväljer
location-analytics-glue-database. - Välj på alternativmenyn (tre vertikala punkter). Förhandsgranskningstabell för att fråga innehållet i båda tabellerna.
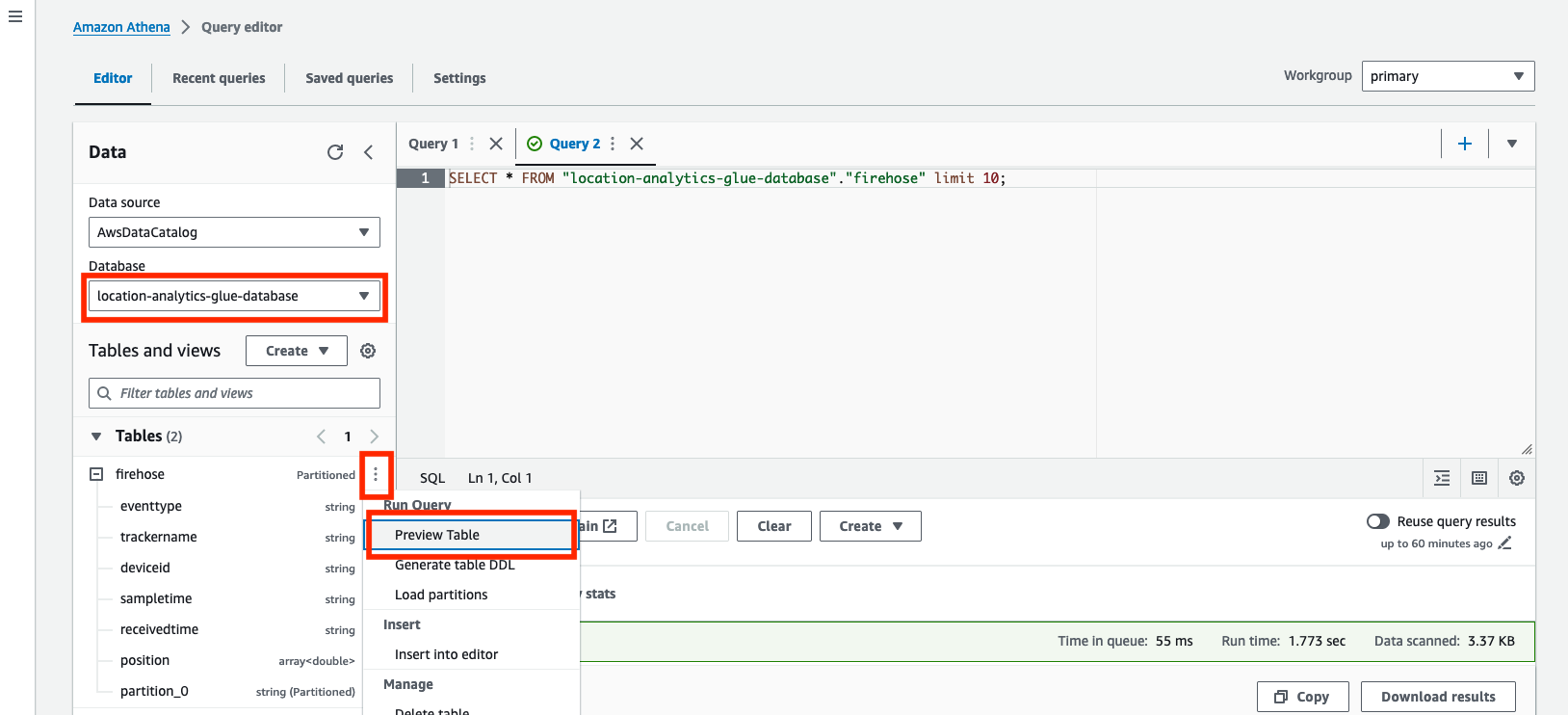
Frågan visar 10 exempel på positionsposter som för närvarande är lagrade i tabellen. Följande skärmdump är ett exempel från förhandsgranskning av firehose tabell. De firehose Tabell lagrar rå, omodifierad data från Amazon Location tracker.
Du kan nu experimentera med geospatiala frågor GeoJSON-fil för London ULEZ-expansionen 2021 är en del av arkivet och har redan konverterats till en fråga som är kompatibel med båda Athena-tabellerna.
- Kopiera och klistra in innehållet från 1-firehose-athena-ulez-2021-create-view.sql fil som finns i
examples/firehosemappen till frågeredigeraren.
Denna fråga använder ST_Within geospatial funktion för att bestämma om en registrerad position är inom eller utanför ULEZ-zonen definierad av polygonen. En ny syn kallas ulezvehicleanalysis_firehose skapas med en ny kolumn, insidezone, som fångar om den registrerade positionen finns inom zonen.
En enkel Python verktyg tillhandahålls, som konverterar polygonfunktionerna som finns i den nedladdade GeoJSON-filen till ST_Polygon strängar baserade på välkänt textformat som kan användas direkt i en Athena-fråga.
- Välja Förhandsvisning på
ulezvehicleanalysis_firehoseför att utforska dess innehåll.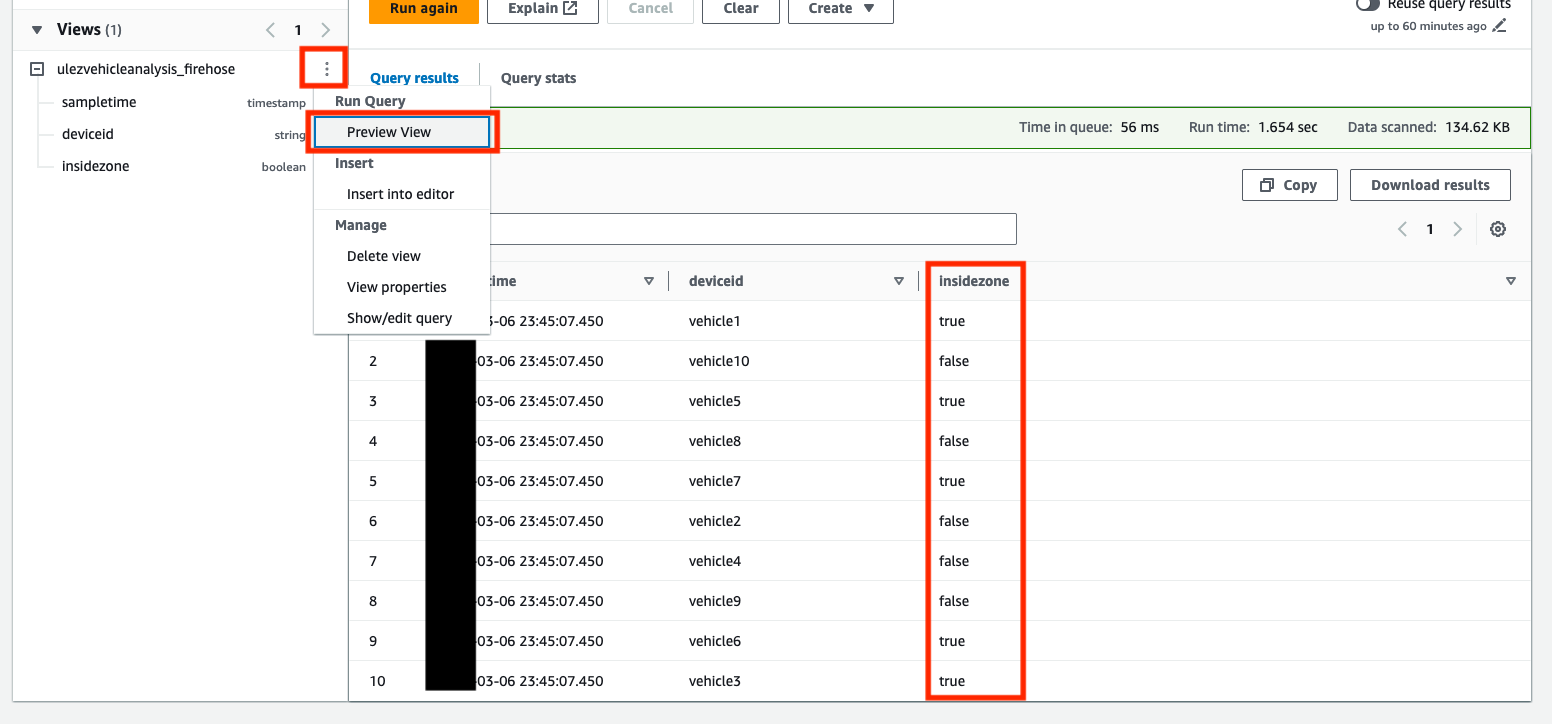
Du kan nu köra frågor mot denna vy för att få övergripande insikter.
- Kopiera och klistra in innehållet från 2-firehose-athena-ulez-2021-query-days-in-zone.sql fil som finns i
examples/firehosemappen till frågeredigeraren.
Denna fråga fastställer det totala antalet dagar varje fordon har kört in i ULEZ och vad de förväntade totala avgifterna skulle vara. Frågan har parametrerats med hjälp av ? platshållartecken. Parameteriserade frågor låter dig köra samma fråga igen med olika parametervärden.
- Ange det dagliga avgiftsbeloppet för Parameter 1, kör sedan frågan.
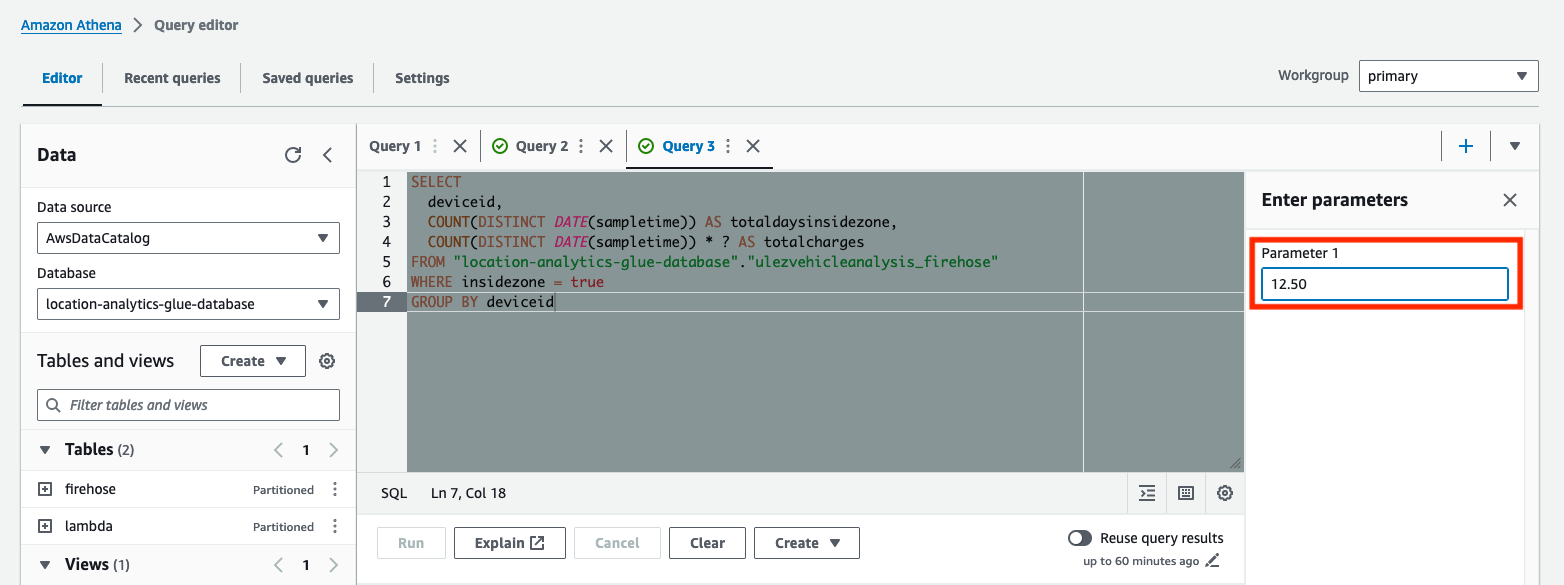
Resultaten visar varje fordon, det totala antalet dagar som spenderats i den föreslagna ULEZ och de totala avgifterna baserat på den dagliga avgiften du angett.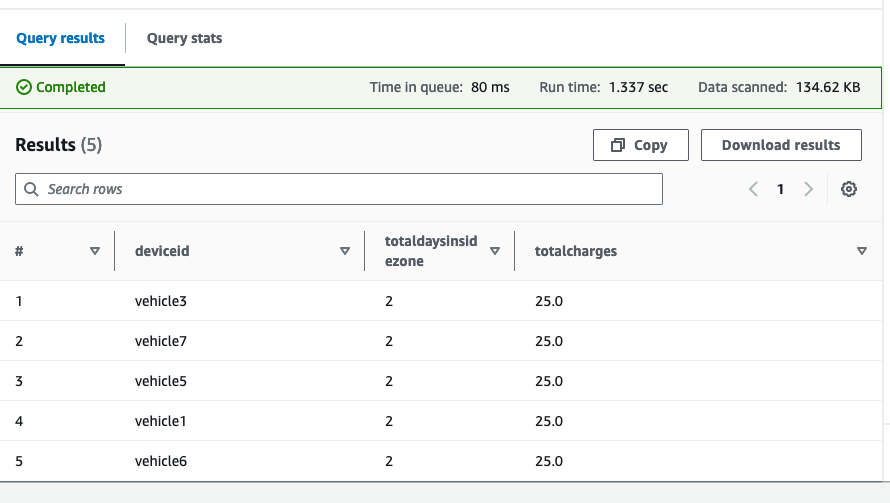
Du kan upprepa denna övning med hjälp av lambda tabell. Data i lambda Tabellen utökas med ytterligare fordonsdetaljer som finns i DynamoDB-tabellen för fordonsunderhåll när den bearbetas av Lambda-funktionen. Lösningen stöder följande fält:
MeetsEmissionStandards(Boolesk)Mileage(Siffra)PurchaseDate(Sträng, inYYYY-MM-DDformatera)
Du kan också berika den nya datan när den kommer.
- På DynamoDB-konsolen, hitta fordonsunderhållstabellen under Bord. Tabellnamnet tillhandahålls som utdata
VehicleMaintenanceDynamoTablei den distribuerade CloudFormation-stacken. - Välja Utforska bordsartiklar för att se innehållet i tabellen.
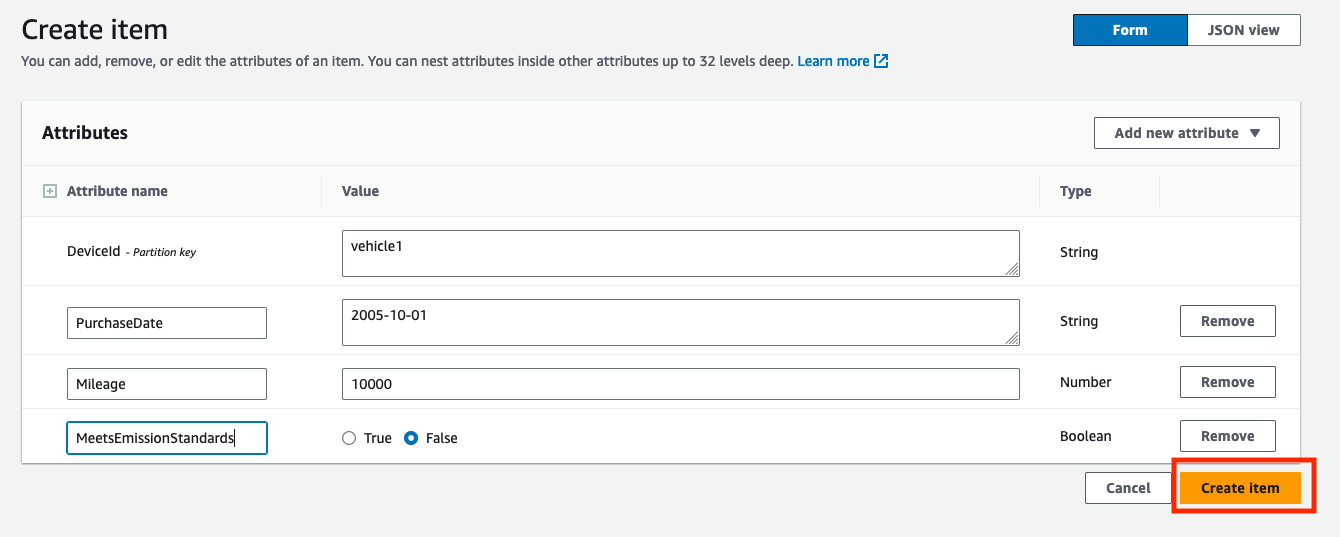
- Välja Skapa objekt för att skapa ett nytt rekord för ett fordon.

- ange
DeviceId(somvehicle1som en sträng),PurchaseDate(som2005-10-01som en sträng),Mileage(som10000som ett nummer), ochMeetsEmissionStandards(med ett värde somFalsesom boolesk). - Välja Skapa objekt för att skapa posten.
- Duplicera den nyskapade posten med ytterligare poster för andra fordon (t.ex. för
vehicle2orvehicle3), ändra värdena för attributen något varje gång. - Kör igen
location-analytics-glue-crawler-lambdaAWS Glue crawler efter att ny data har genererats för att bekräfta att uppdateringen av schemat med nya fält är registrerad. - Kopiera och klistra in innehållet från 1-lambda-athena-ulez-2021-create-view.sql fil som finns i
examples/lambdamappen till frågeredigeraren. - Förhandsgranska
ulezvehicleanalysis_lambdavisa för att bekräfta att de nya kolumnerna har skapats.
Om fel som t.ex Column 'mileage' cannot be resolved visas, databerikningen äger inte rum eller så har AWS Glue-sökroboten ännu inte upptäckt uppdateringar av schemat.
Om Alternativ för förhandsgranska tabell returnerar endast resultat från innan du skapade poster i DynamoDB-tabellen, returnerar frågeresultaten i fallande ordning med sampletime (till exempel, order by sampletime desc limit 100;).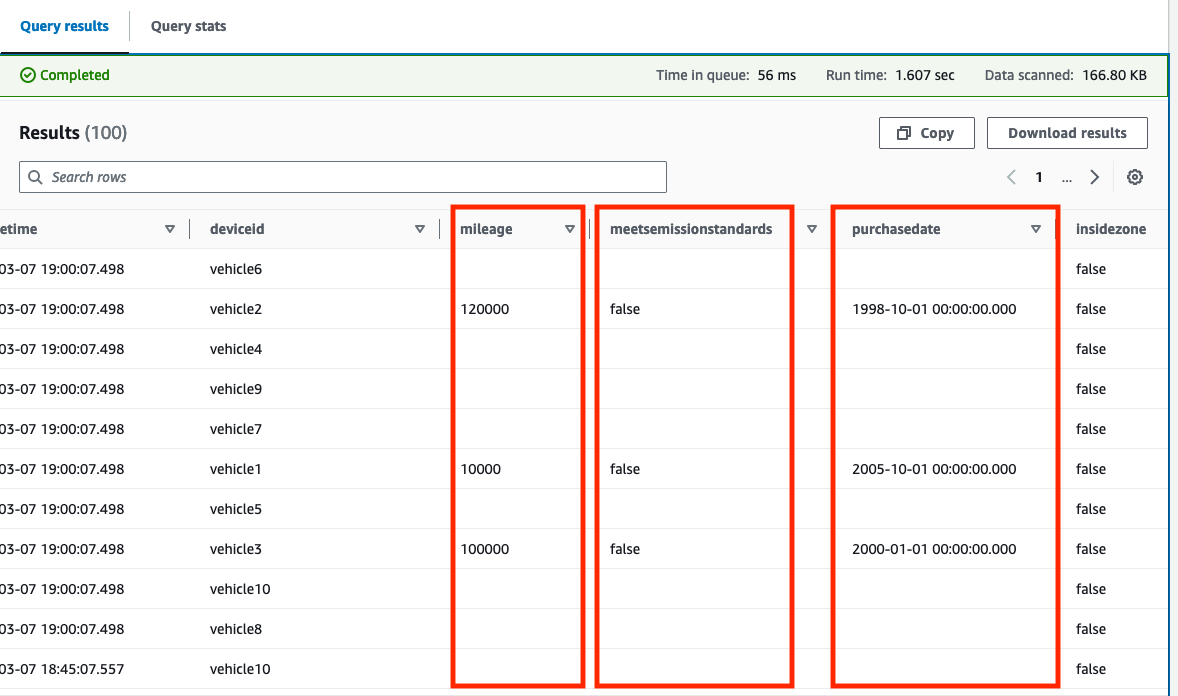
Nu fokuserar vi på de fordon som för närvarande inte uppfyller utsläppsnormerna och beställer fordonen i fallande ordning baserat på körsträcka per år (beräknat med den senaste körsträckan/åldern på fordonet i år).
- Kopiera och klistra in innehållet från 2-lambda-athena-ulez-2021-query-days-in-zone.sql fil som finns i
examples/lambdamappen till frågeredigeraren.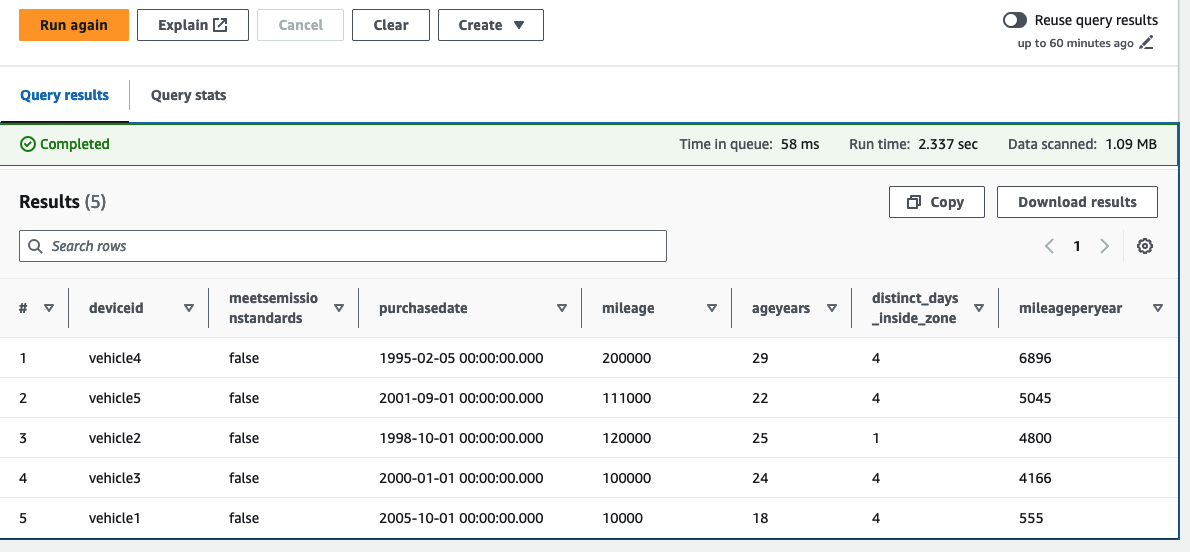
I det här exemplet kan vi se att fem av vår fordonsflotta har rapporterats som inte uppfyller utsläppsnormerna. Vi kan också se de fordon som har ackumulerat höga körsträcka per år och antalet dagar tillbringade i den föreslagna ULEZ. Flottans operatör kan nu besluta att prioritera dessa fordon för utbyte. Eftersom platsdata är berikat med de mest uppdaterade fordonsunderhållsdata vid den tidpunkt den tas in, kan du vidareutveckla dessa frågor så att de körs över ett definierat tidsfönster. Du kan till exempel ta hänsyn till förändringar i körsträcka under det senaste året.
På grund av databerikningens dynamiska natur kommer all ny data som överförs till Amazon S3, tillsammans med frågeresultaten, att ändras när och när poster uppdateras i DynamoDB-fordonsunderhållstabellen.
Städa upp
Se instruktionerna i README fil för att rensa upp resurserna som tillhandahålls för den här lösningen.
Slutsats
Det här inlägget demonstrerade hur du kan använda Amazon Location, EventBridge, Lambda, Amazon Data Firehose och Amazon S3 för att bygga en platsmedveten datapipeline och använda insamlade enhetspositionsdata för att skapa analytiska insikter med AWS Glue och Athena. Genom att spåra dessa tillgångar i realtid och lagra resultaten kan företag få värdefulla insikter om hur effektivt deras flottor utnyttjas och bättre reagera på förändringar i framtiden. Du kan nu utforska hur du utökar denna exempelkod med din egen enhetsspårningsdata och analyskrav.
Om författarna
 Alan Peaty är Senior Partner Solutions Architect på AWS. Alan hjälper Global Systems Integrators (GSI) och Global Independent Software Vendors (GISVs) att lösa komplexa kundutmaningar med hjälp av AWS-tjänster. Innan han började på AWS arbetade Alan som arkitekt på systemintegratörer för att översätta affärskrav till tekniska lösningar. Utanför jobbet är Alan en IoT-entusiast och en ivrig löpare som älskar att åka de leriga stigarna på den engelska landsbygden.
Alan Peaty är Senior Partner Solutions Architect på AWS. Alan hjälper Global Systems Integrators (GSI) och Global Independent Software Vendors (GISVs) att lösa komplexa kundutmaningar med hjälp av AWS-tjänster. Innan han började på AWS arbetade Alan som arkitekt på systemintegratörer för att översätta affärskrav till tekniska lösningar. Utanför jobbet är Alan en IoT-entusiast och en ivrig löpare som älskar att åka de leriga stigarna på den engelska landsbygden.
 Parag Srivastava är en lösningsarkitekt på AWS och hjälper företagskunder med framgångsrik molnadoption och migrering. Under sin yrkeskarriär har han varit mycket involverad i komplexa digitala transformationsprojekt. Han brinner också för att bygga innovativa lösningar kring geospatiala aspekter av adresser.
Parag Srivastava är en lösningsarkitekt på AWS och hjälper företagskunder med framgångsrik molnadoption och migrering. Under sin yrkeskarriär har han varit mycket involverad i komplexa digitala transformationsprojekt. Han brinner också för att bygga innovativa lösningar kring geospatiala aspekter av adresser.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/gain-insights-from-historical-location-data-using-amazon-location-service-and-aws-analytics-services/

