Beskrivning
One-Class Support Vector Machine (SVM) är en variant av den traditionella SVM. Den är speciellt anpassad för att upptäcka anomalier. Dess primära syfte är att lokalisera instanser som avviker särskilt från standarden. Till skillnad från konventionella Maskininlärning modeller fokuserade på binär eller multiklassklassificering, en-klass SVM specialiserar sig på avviker- eller nyhetsdetektering inom datamängder. I den här artikeln kommer du att lära dig hur One-Class Support Vector Machine (SVM) skiljer sig från traditionell SVM. Du får också lära dig hur OC-SVM fungerar och hur man implementerar det. Du kommer också att lära dig om dess hyperparametrar.
Inlärningsmål
- För att förstå anomalier
- Lär dig mer om One-class SVM
- Förstå hur det skiljer sig från traditionell Support Vector Machine (SVM)
- Hyperparametrar för OC-SVM i Sklearn
- Hur man upptäcker anomalier med OC-SVM
- Använd fall av enklass SVM
Innehållsförteckning
Förstå anomalier
Anomalier är observationer eller fall som avviker avsevärt från en datauppsättnings normala beteende. Dessa avvikelser kan visa sig i olika former, såsom extremvärden, brus, fel eller oväntade mönster. Anomalier är ofta fascinerande eftersom de kan representera värdefulla insikter. De kan ge insikter som att identifiera bedrägliga transaktioner, upptäcka utrustningsfel eller avslöja nya fenomen. Avvikande och nyhetsdetektering identifierar anomalier och onormala eller ovanliga observationer.
Läs också: En komplett guide om anomalidetektering
En klass SVM
Introduktion till stöd för vektormaskiner (SVM)
Support Vector Machines (SVM) är en populär övervakad inlärningsalgoritm för klassificerings- och regressionsuppgifter. SVM:er fungerar genom att hitta det optimala hyperplanet som separerar olika klasser i funktionsutrymme samtidigt som marginalen mellan dem maximeras. Detta hyperplan är baserat på en delmängd av träningsdatapunkter som kallas stödvektorer.
Enklass SVM vs traditionell SVM
- Enklassiga SVM:er representerar en variant av den traditionella SVM-algoritmen som främst används för avvikande och nyhetsdetekteringsuppgifter. Till skillnad från traditionella SVM, som hanterar binära klassificeringsuppgifter, tränar One-Class SVM exklusivt på datapunkter från en enda klass, känd som målklassen. En-klass SVM syftar till att lära sig en gräns- eller beslutsfunktion som kapslar in målklassen i funktionsutrymme, och effektivt modellerar det normala beteendet hos datan.
- Traditionella SVM syftar till att hitta en beslutsgräns som maximerar marginalen mellan olika klasser, vilket möjliggör optimal klassificering av nya datapunkter. Å andra sidan försöker One-Class SVM hitta en gräns som kapslar in målklassen samtidigt som risken för att inkludera extremvärden eller nya instanser utanför denna gräns minimeras.
- Traditionella SVM kräver märkta data med instanser från flera klasser, vilket gör dem lämpliga för övervakade klassificeringsuppgifter. Däremot tillåter en One-Class SVM tillämpning i scenarier där endast data från målklassen är tillgänglig, vilket gör den väl lämpad för oövervakad anomalidetektering och nyhetsdetekteringsuppgifter.
Läs mer: Enklassificering med stödvektormaskiner
De skiljer sig båda åt i sina formuleringar med mjuka marginaler och hur de använder dem:
(Mjuk marginal i SVM används för att tillåta en viss grad av felklassificering)
En-klass SVM syftar till att upptäcka ett hyperplan med maximal marginal inom funktionsutrymmet genom att separera den mappade datan från ursprunget. På en datauppsättning Dn = {x1, . . . , xn} med xi ∈ X (xi är en egenskap) och n dimensioner:
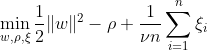
Denna ekvation representerar den primära problemformuleringen för OC-SVM, där w är det separerande hyperplanet, ρ är offset från origo och ξi är slackvariabler. De tillåter en mjuk marginal men straffar överträdelser ξi. En hyperparameter ν ∈ (0, 1] styr effekten av slack-variabeln och bör justeras efter behov. Målet är att minimera normen för w samtidigt som man straffar avvikelser från marginalen. Dessutom tillåter detta en bråkdel av data att falla inom marginalen eller på fel sida av hyperplanet.
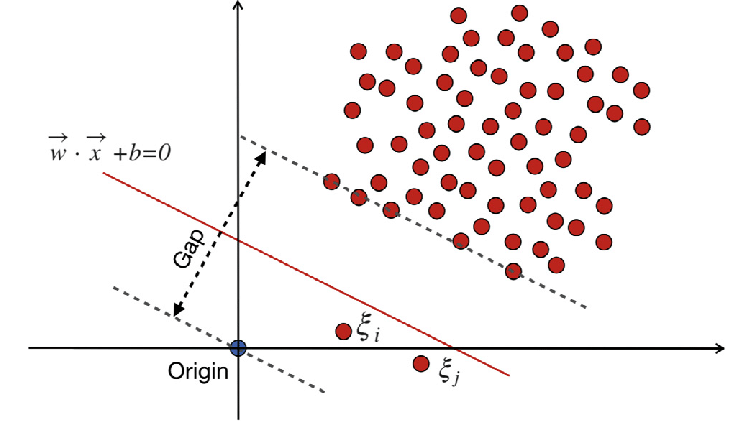
WX + b =0 är beslutsgränsen, och slackvariablerna straffar avvikelser.
Traditional-Support Vector Machines (SVM)
Traditional-Support Vector Machines (SVM) använder den mjuka marginalformuleringen för felklassificeringsfel. Eller så använder de datapunkter som faller inom marginalen eller på fel sida av beslutsgränsen.
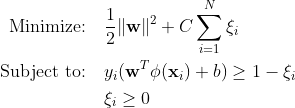
Var:
w är viktvektorn.
b är biastermen.
ξi är slackvariabler som möjliggör optimering av mjuka marginaler.
C är regulariseringsparametern som styr avvägningen mellan att maximera marginalen och minimera klassificeringsfelet.
ϕ(xi) representerar särdragsmappningsfunktionen.
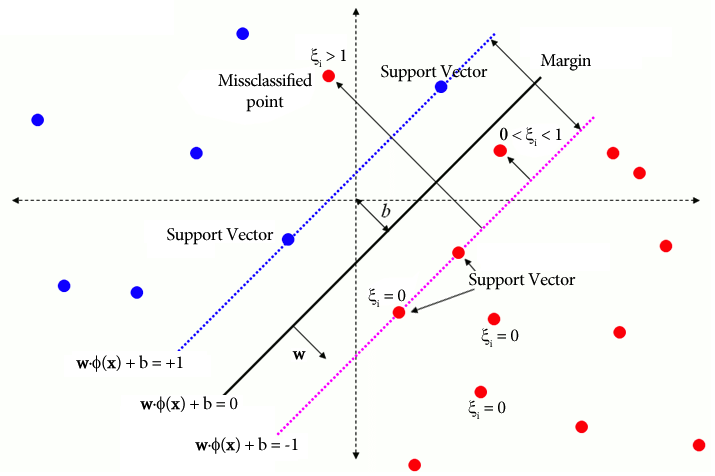
I traditionell SVM innehåller en övervakad inlärningsmetod som förlitar sig på klassetiketter för separation slackvariabler för att tillåta en viss nivå av felklassificering. SVM:s primära mål är att separera datapunkter av distinkta klasser med hjälp av beslutsgränsen WX + b = 0. Värdet på slackvariabler varierar beroende på placeringen av datapunkter: de sätts till 0 om datapunkterna är placerade utanför marginalerna. Om datapunkten finns inom marginalen sträcker sig slackvariablerna mellan 0 och 1, och sträcker sig bortom den motsatta marginalen om den är större än 1.
Både traditionella SVM och One-Class SVM med mjuka marginaler syftar till att minimera normen för viktvektorn. Ändå skiljer de sig åt i sina mål och hur de hanterar felklassificeringsfel eller avvikelser från beslutsgränsen. Traditionella SVM:er optimerar klassificeringsnoggrannheten för att undvika överanpassning, medan One-Class SVM:er fokuserar på att modellera målklassen och kontrollera andelen avvikelser eller nya instanser.
Läs också: AZ-guiden för att stödja Vector Machine
Viktiga hyperparametrar i enklass SVM
- nu: Detta är en avgörande hyperparameter i One-Class SVM, som styr andelen tillåtna extremvärden. Den sätter en övre gräns för andelen träningsfel och en nedre gräns för andelen stödvektorer. Det varierar vanligtvis mellan 0 och 1, där lägre värden innebär en strängare marginal och kan fånga färre extremvärden, medan högre värden är mer tillåtande. Standardvärdet är 0.5.
- kernel: Kärnfunktionen bestämmer vilken typ av beslutsgräns SVM använder. Vanliga val inkluderar 'linjär', 'rbf' (gaussisk radiell basfunktion), 'poly' (polynom) och 'sigmoid.' 'rbf'-kärnan används ofta eftersom den effektivt kan fånga komplexa icke-linjära relationer.
- gamma: Detta är en parameter för icke-linjära hyperplan. Den definierar hur mycket inflytande ett enskilt träningsexempel har. Ju större gammavärde, desto närmare måste andra exempel vara för att påverkas. Den här parametern är specifik för RBF-kärnan och är vanligtvis inställd på 'auto', som är standard på 1 / n_features.
- kärnparametrar (grad, coef0): Dessa parametrar är för polynom- och sigmoidkärnor. 'grad' är graden av polynomkärnfunktionen, och 'coef0' är den oberoende termen i kärnfunktionen. Justering av dessa parametrar kan vara nödvändigt för att uppnå optimal prestanda.
- till mig: Detta är stoppkriteriet. Algoritmen stannar när dualitetsgapet är mindre än toleransen. Det är en parameter som styr toleransen för stoppkriteriet.
Arbetsprincip för enklass SVM
Kärnfunktioner i One-Class SVM
Kärnfunktioner spelar en avgörande roll i One-Class SVM genom att tillåta algoritmen att fungera i högre dimensionella funktionsutrymmen utan att explicit beräkna transformationerna. I One-Class SVM, som i traditionella SVM, används kärnfunktioner för att mäta likheten mellan par av datapunkter i inmatningsutrymmet. Vanliga kärnfunktioner som används i One-Class SVM inkluderar Gaussian (RBF), polynomial och sigmoid kärnor. Dessa kärnor mappar det ursprungliga inmatningsutrymmet till ett högre dimensionellt utrymme, där datapunkter blir linjärt separerbara eller uppvisar mer distinkta mönster, vilket underlättar inlärning. Genom att välja en lämplig kärnfunktion och justera dess parametrar kan One-Class SVM effektivt fånga komplexa relationer och icke-linjära strukturer i data, vilket förbättrar dess förmåga att upptäcka anomalier eller extremvärden.
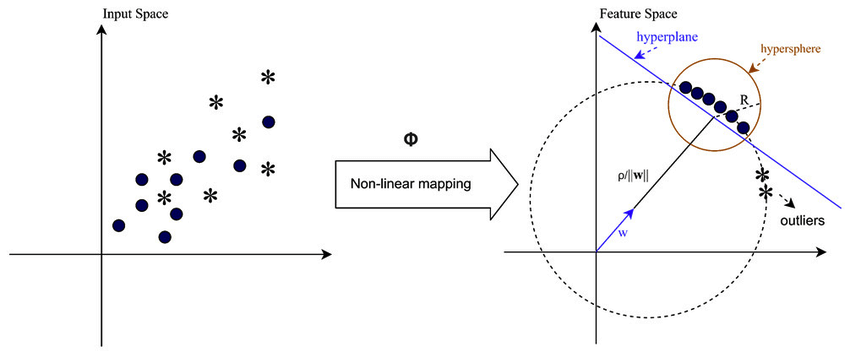
I fall där data inte är linjärt separerbara, till exempel när man hanterar komplexa eller överlappande mönster, kan Support Vector Machines (SVM) använda en kärna för radial basisfunktion (RBF) för att effektivt separera extremvärden från resten av data. RBF-kärnan omvandlar indata till ett högre dimensionellt funktionsutrymme som kan separeras bättre.
Marginal och stödvektorer
Konceptet med marginal- och stödvektorer i One-Class SVM liknar det i traditionella SVM. Marginalen avser området mellan beslutsgränsen (hyperplan) och de närmaste datapunkterna från varje klass. I One-Class SVM representerar marginalen den region där de flesta datapunkter som tillhör målklassen ligger. Maximering av marginalen är avgörande för One-Class SVM eftersom det hjälper till att generalisera nya datapunkter väl och förbättrar modellens robusthet. Stödvektorer är de datapunkter som ligger på eller inom marginalen och bidrar till att definiera beslutsgränsen.
I One-Class SVM är stödvektorer datapunkterna från målklassen närmast beslutsgränsen. Dessa stödvektorer spelar en betydande roll vid bestämning av formen och orienteringen av beslutsgränsen och, således, i den övergripande prestandan för One-Class SVM-modellen. Genom att identifiera stödvektorerna lär One-Class SVM effektivt representationen av målklassen i funktionsutrymmet och konstruerar en beslutsgräns som kapslar in de flesta datapunkterna samtidigt som risken för att inkludera extremvärden eller nya instanser minimeras.
Hur kan anomalier upptäckas med enklass SVM?
Upptäcka anomalier med hjälp av enklass SVM (Support Vector Machine) genom både nyhetsdetektering och avvikande detekteringstekniker:
Outlier Detektion
Det handlar om att identifiera observationer i träningsdatan som väsentligt avviker från resten, ofta kallade outliers. Uppskattare för avvikande upptäckt sträva efter att passa de områden där träningsdatan är mest koncentrerad, utan hänsyn till dessa avvikande observationer.
from sklearn.svm import OneClassSVM
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from sklearn.inspection import DecisionBoundaryDisplay
# Load data
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
# Define estimators (One-Class SVM)
estimators_hard_margin = {
"Hard Margin OCSVM": OneClassSVM(nu=0.01, gamma=0.35), # Very small nu for hard margin
}
estimators_soft_margin = {
"Soft Margin OCSVM": OneClassSVM(nu=0.25, gamma=0.35), # Nu between 0 and 1 for soft margin
}
# Plotting setup
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
colors = ["tab:blue", "tab:orange", "tab:red"]
legend_lines = []
# Hard Margin OCSVM
ax = axs[0]
for color, (name, estimator) in zip(colors, estimators_hard_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Hard Margin Outlier detection (wine recognition)",
)
# Soft Margin OCSVM
ax = axs[1]
legend_lines = []
for color, (name, estimator) in zip(colors, estimators_soft_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Soft Margin Outlier detection (wine recognition)",
)
plt.tight_layout()
plt.show()
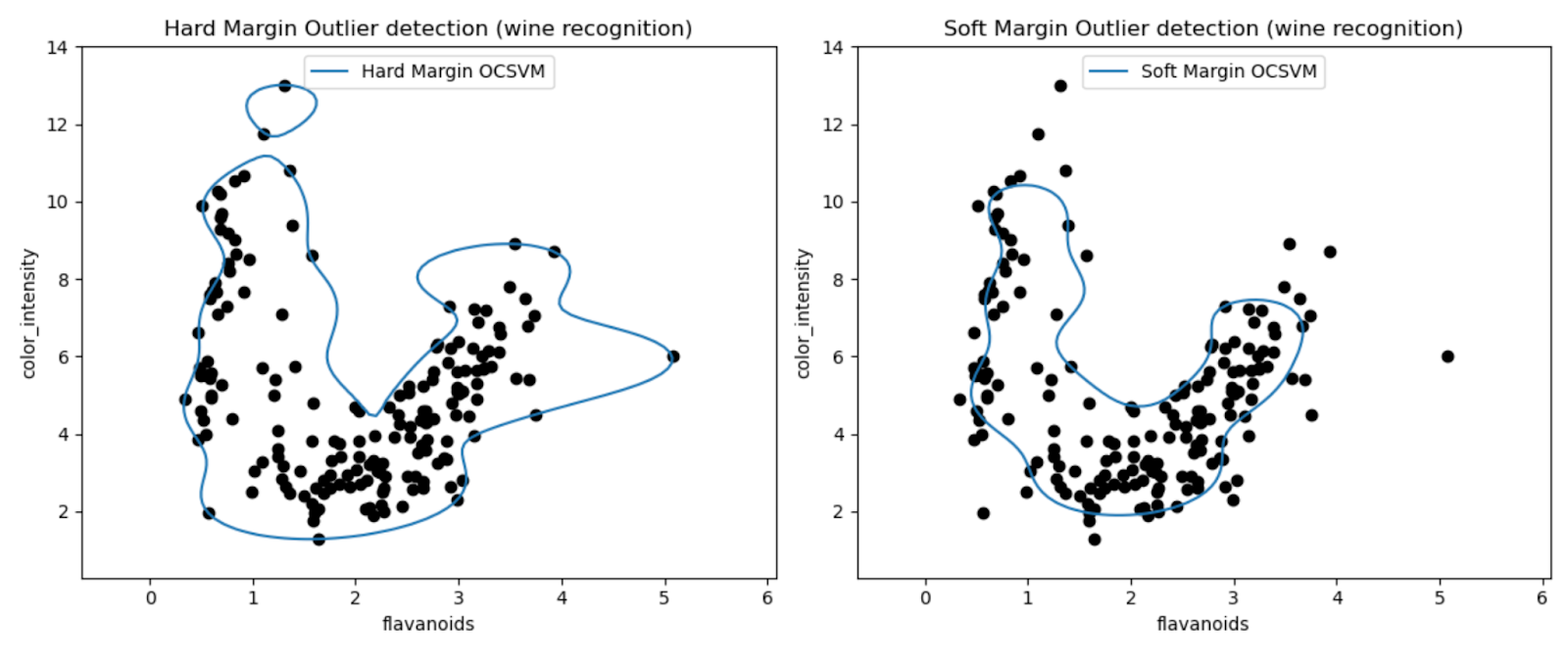
Plotterna tillåter oss att visuellt inspektera prestandan hos One-Class SVM-modellerna när det gäller att upptäcka extremvärden i Wine-datasetet.
Genom att jämföra resultaten av hårdmarginal och mjuk marginal One-Class SVM-modeller kan vi observera hur valet av marginalinställning (nu-parameter) påverkar avvikelsedetektering.
Den hårda marginalmodellen med ett mycket litet nuvärde (0.01) resulterar sannolikt i en mer konservativ beslutsgräns. Den lindar tätt runt majoriteten av datapunkterna och klassificerar potentiellt färre punkter som extremvärden.
Omvänt resulterar den mjuka marginalmodellen med ett större nuvärde (0.35) sannolikt i en mer flexibel beslutsgräns. Detta möjliggör en bredare marginal och potentiellt fånga fler extremvärden.
Nyhetsdetektering
Å andra sidan tillämpar vi det när träningsdata är fria från extremvärden, och målet är att avgöra om en ny observation är sällsynt, dvs mycket annorlunda än kända observationer. Denna senaste observation här kallas en nyhet.
import numpy as np
from sklearn import svm
# Generate train data
np.random.seed(30)
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
import matplotlib.font_manager
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, ax = plt.subplots()
# generate grid for the boundary display
xx, yy = np.meshgrid(np.linspace(-5, 5, 10), np.linspace(-5, 5, 10))
X = np.concatenate([xx.reshape(-1, 1), yy.reshape(-1, 1)], axis=1)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
cmap="PuBu",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
levels=[0, 10000],
colors="palevioletred",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contour",
ax=ax,
levels=[0],
colors="darkred",
linewidths=2,
)
s = 40
b1 = ax.scatter(X_train[:, 0], X_train[:, 1], c="white", s=s, edgecolors="k")
b2 = ax.scatter(X_test[:, 0], X_test[:, 1], c="blueviolet", s=s, edgecolors="k")
c = ax.scatter(X_outliers[:, 0], X_outliers[:, 1], c="gold", s=s, edgecolors="k")
plt.legend(
[mlines.Line2D([], [], color="darkred"), b1, b2, c],
[
"learned frontier",
"training observations",
"new regular observations",
"new abnormal observations",
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11),
)
ax.set(
xlabel=(
f"error train: {n_error_train}/200 ; errors novel regular: {n_error_test}/40 ;"
f" errors novel abnormal: {n_error_outliers}/40"
),
title="Novelty Detection",
xlim=(-5, 5),
ylim=(-5, 5),
)
plt.show()

- Generera en syntetisk datauppsättning med två kluster av datapunkter. Gör detta genom att generera dem med en normalfördelning runt två olika centra: (2, 2) och (-2, -2) för tåg- och testdata. Generera slumpmässigt tjugo datapunkter likformigt inom ett kvadratiskt område som sträcker sig från -4 till 4 längs båda dimensionerna. Dessa datapunkter representerar onormala observationer eller extremvärden som väsentligt avviker från det normala beteendet som observerats i tåg- och testdata.
- Den inlärda gränsen hänvisar till den beslutsgräns som lärts av En-klass SVM-modellen. Denna gräns separerar områdena i funktionsutrymmet där modellen anser att datapunkter är normala från extremvärdena.
- Färggradienten från blått till vitt i konturerna representerar de varierande graderna av tillförlitlighet eller säkerhet som One-Class SVM-modellen tilldelar olika regioner i funktionsutrymmet, med mörkare nyanser som indikerar högre tilltro till att klassificera datapunkter som "normala". Mörkblått indikerar regioner med en stark indikation på att vara "normala" enligt modellens beslutsfunktion. När färgen blir ljusare i konturen är modellen mindre säker på att klassificera datapunkter som "normala".
- Handlingen representerar visuellt hur En-klass SVM-modellen kan skilja mellan regelbundna och onormala observationer. Den inlärda beslutsgränsen separerar regionerna för normala och onormala observationer. En-klass SVM för nyhetsdetektion bevisar sin effektivitet när det gäller att identifiera onormala observationer i en given datamängd.
För nu=0.5:
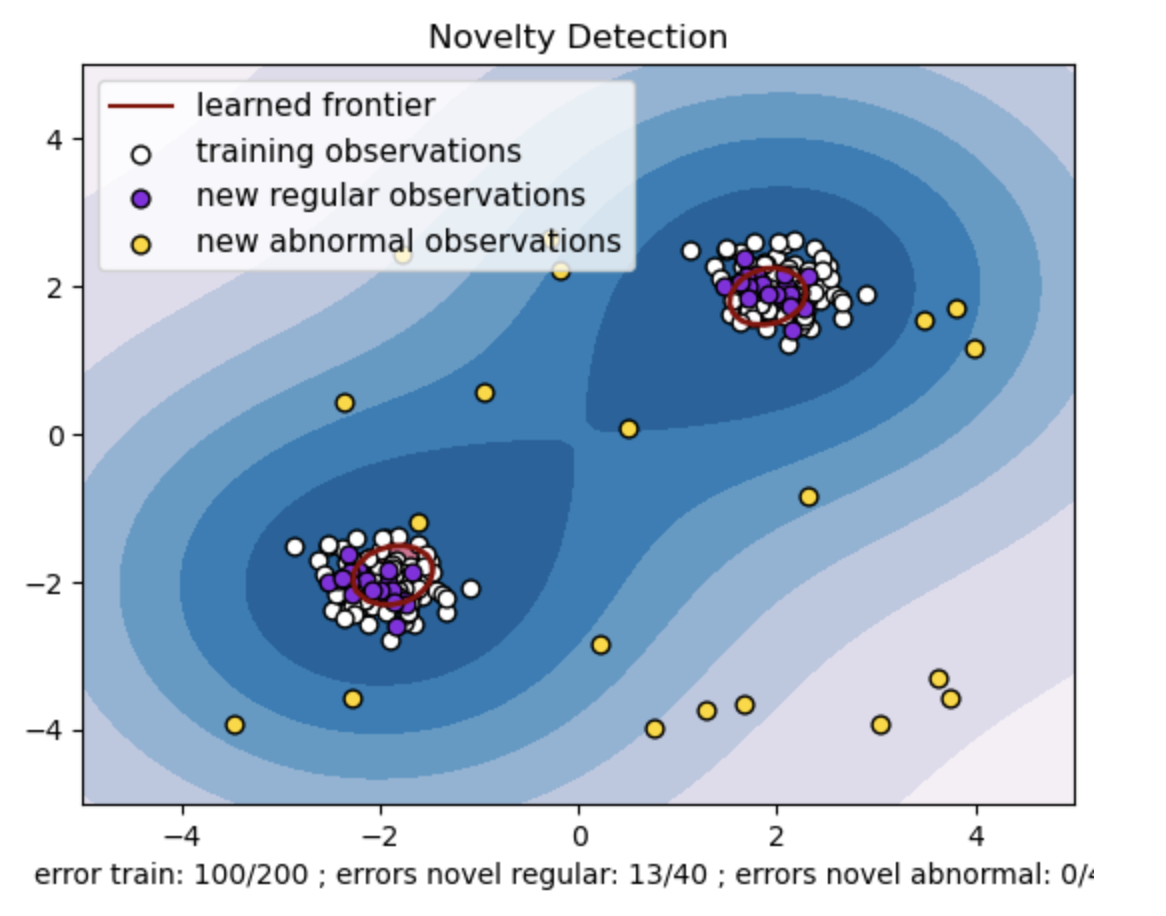
"nu"-värdet i One-class SVM spelar en avgörande roll för att kontrollera andelen av extremvärden som tolereras av modellen. Det påverkar direkt modellens förmåga att identifiera anomalier och påverkar därmed förutsägelsen. Vi kan se att modellen tillåter att 100 träningspoäng felklassificeras. Ett lägre värde på nu innebär en striktare begränsning av den tillåtna andelen av extremvärden. Valet av nu påverkar modellens prestanda när det gäller att upptäcka anomalier. Det kräver också noggrann justering baserat på applikationens specifika krav och datasetets egenskaper.
För gamma=0.5 och nu=0.5
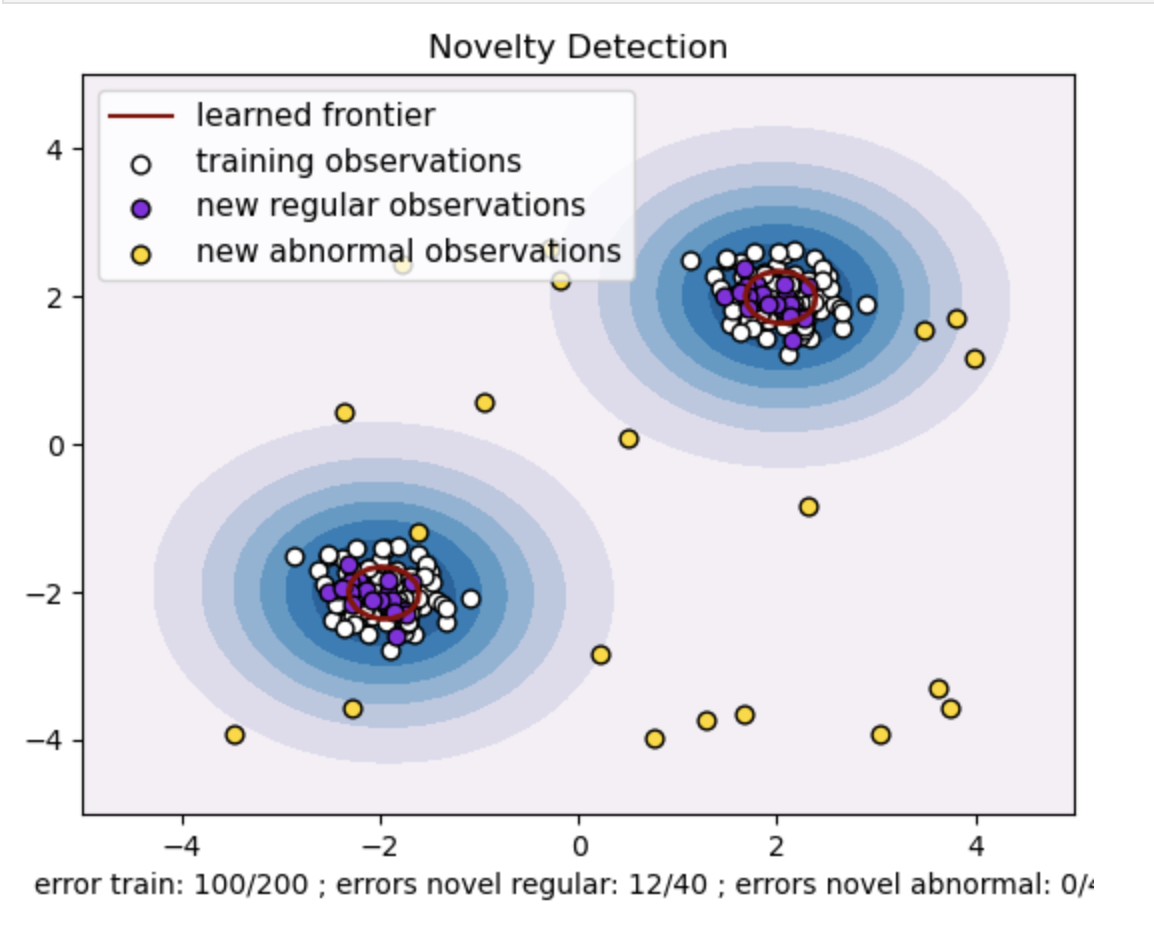
I en-klass SVM representerar gamma-hyperparametern kärnkoefficienten för 'rbf'-kärnan. Denna hyperparameter påverkar formen på beslutsgränsen och påverkar följaktligen modellens prediktiva prestanda.
När gamma är hög begränsar ett enskilt träningsexempel dess inflytande till sin omedelbara närhet. Detta skapar en mer lokaliserad beslutsgräns. Därför måste datapunkter vara närmare stödvektorerna för att tillhöra samma klass.
Slutsats
Att använda One-Class SVM för avvikelsedetektering, användning av outlier- och nyhetsdetektion erbjuder en robust lösning över olika domäner. Detta hjälper i scenarier där märkta anomalidata är knappa eller otillgängliga. Detta gör det särskilt värdefullt i verkliga tillämpningar där anomalier är sällsynta och utmanande att uttryckligen definiera. Dess användningsfall sträcker sig till olika domäner, såsom cybersäkerhet och feldiagnos, där anomalier får konsekvenser. Men medan One-Class SVM erbjuder många fördelar, är det nödvändigt att ställa in hyperparametrarna enligt data för att få bättre resultat, vilket ibland kan vara tråkigt.
Vanliga frågor
A. En-klass SVM konstruerar ett hyperplan (eller en hypersfär i högre dimensioner) som kapslar in de normala datapunkterna. Detta hyperplan är placerat för att maximera marginalen mellan normaldata och beslutsgränsen. Datapunkter klassificeras som normala (innanför gränsen) eller anomalier (utanför gränsen) under testning eller slutledning.
A. Enklass SVM är fördelaktigt eftersom det inte kräver märkta data för anomalier under träning. Den kan lära sig av en datauppsättning som bara innehåller vanliga instanser, vilket gör den lämplig för scenarier där anomalier är sällsynta och utmanande att få tag på märkta exempel för träning.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2024/03/one-class-svm-for-anomaly-detection/

