Stora språkmodeller (LLM) tränas i allmänhet på stora allmänt tillgängliga datauppsättningar som är domänagnostiska. Till exempel, Metas lama modeller tränas på datamängder som t.ex CommonCrawl, C4, Wikipedia och ArXiv. Dessa datauppsättningar omfattar ett brett spektrum av ämnen och domäner. Även om de resulterande modellerna ger fantastiskt bra resultat för allmänna uppgifter, såsom textgenerering och enhetsigenkänning, finns det bevis på att modeller som tränats med domänspecifika datauppsättningar ytterligare kan förbättra LLM-prestanda. Till exempel träningsdata som används för BloombergGPT är 51 % domänspecifika dokument, inklusive finansiella nyheter, registreringar och annat finansiellt material. Den resulterande LLM överträffar LLM:er utbildade på icke-domänspecifika datauppsättningar när de testas på ekonomispecifika uppgifter. Författarna till BloombergGPT drog slutsatsen att deras modell överträffar alla andra modeller som testats för fyra av de fem ekonomiska uppgifterna. Modellen gav ännu bättre prestanda när den testades för Bloombergs interna finansiella uppgifter med bred marginal — så mycket som 60 poäng bättre (av 100). Även om du kan lära dig mer om de omfattande utvärderingsresultaten i papper, följande prov hämtat från BloombergGPT papper kan ge dig en glimt av fördelen med att utbilda LLM med hjälp av finansiella domänspecifika data. Som visas i exemplet gav BloombergGPT-modellen korrekta svar medan andra icke-domänspecifika modeller kämpade:
Det här inlägget ger en guide till utbildning av LLM:er specifikt för den finansiella domänen. Vi täcker följande nyckelområden:
- Datainsamling och förberedelse – Vägledning om inköp och sammanställning av relevant finansiell data för effektiv modellutbildning
- Kontinuerlig förträning kontra finjustering – När du ska använda varje teknik för att optimera din LLM:s prestanda
- Effektiv kontinuerlig förträning – Strategier för att effektivisera den kontinuerliga förutbildningsprocessen, vilket sparar tid och resurser
Det här inlägget sammanför expertis från forskarteamet för tillämpad vetenskap inom Amazon Finance Technology och AWS Worldwide Specialist-teamet för den globala finansiella industrin. En del av innehållet är baserat på papperet Effektiv kontinuerlig förutbildning för att bygga domänspecifika stora språkmodeller.
Samla in och förbereda ekonomidata
Kontinuerlig förutbildning för domänen kräver en storskalig domänspecifik datauppsättning av hög kvalitet. Följande är huvudstegen för domändatauppsättning:
- Identifiera datakällor – Potentiella datakällor för domänkorpus inkluderar öppen webb, Wikipedia, böcker, sociala medier och interna dokument.
- Domändatafilter – Eftersom det slutliga målet är att kurera domänkorpus, kan du behöva tillämpa ytterligare steg för att filtrera bort prover som är irrelevanta för måldomänen. Detta minskar värdelös korpus för kontinuerlig förträning och minskar utbildningskostnaderna.
- förbehandling – Du kan överväga en serie förbearbetningssteg för att förbättra datakvaliteten och utbildningseffektiviteten. Till exempel kan vissa datakällor innehålla ett ganska stort antal bullriga tokens; deduplicering anses vara ett användbart steg för att förbättra datakvaliteten och minska utbildningskostnaderna.
För att utveckla finansiella LLM:er kan du använda två viktiga datakällor: News CommonCrawl och SEC-anmälningar. En SEC-anmälan är ett finansiellt utlåtande eller annat formellt dokument som skickas till US Securities and Exchange Commission (SEC). Börsnoterade företag är skyldiga att lämna in olika dokument regelbundet. Detta skapar ett stort antal dokument genom åren. News CommonCrawl är en datauppsättning som släpptes av CommonCrawl 2016. Den innehåller nyhetsartiklar från nyhetssajter över hela världen.
Nyheter CommonCrawl är tillgänglig på Amazon enkel lagringstjänst (Amazon S3) i commoncrawl hink kl crawl-data/CC-NEWS/. Du kan få listor över filer med hjälp av AWS-kommandoradsgränssnitt (AWS CLI) och följande kommando:
In Effektiv kontinuerlig förutbildning för att bygga domänspecifika stora språkmodeller, använder författarna en URL- och nyckelordsbaserad metod för att filtrera finansiella nyhetsartiklar från generiska nyheter. Specifikt upprätthåller författarna en lista över viktiga finansiella nyhetskanaler och en uppsättning nyckelord relaterade till finansiella nyheter. Vi identifierar en artikel som finansnyheter om den antingen kommer från finansiella nyhetsbyråer eller om några sökord dyker upp i webbadressen. Detta enkla men effektiva tillvägagångssätt gör att du kan identifiera finansiella nyheter från inte bara finansiella nyhetsbyråer utan även finanssektioner av generiska nyhetskanaler.
SEC-anmälningar är tillgängliga online via SEC:s EDGAR-databas (Electronic Data Gathering, Analysis and Retrieval), som ger öppen dataåtkomst. Du kan skrapa arkiven från EDGAR direkt, eller använda API:er i Amazon SageMaker med några rader kod, för vilken tidsperiod som helst och för ett stort antal tickers (dvs. den SEC-tilldelade identifieraren). För att lära dig mer, se SEC-arkivering.
Följande tabell sammanfattar de viktigaste detaljerna för båda datakällorna.
| . | Företagsnyheter CommonCrawl | SEC-arkivering |
| Rapportering | 2016-2022 | 1993-2022 |
| Storlek | 25.8 miljarder ord | 5.1 miljarder ord |
Författarna går igenom några extra förbearbetningssteg innan data matas in i en träningsalgoritm. Först observerar vi att SEC-anmälningar innehåller bullrig text på grund av borttagningen av tabeller och figurer, så författarna tar bort korta meningar som anses vara tabell- eller figuretiketter. För det andra använder vi en lokalitetskänslig hashalgoritm för att deduplicera de nya artiklarna och arkiven. För SEC-anmälningar deduplicerar vi på sektionsnivå istället för dokumentnivå. Slutligen sammanfogar vi dokument till en lång sträng, tokeniserar den och delar upp tokeniseringen i bitar med maximal inmatningslängd som stöds av modellen som ska tränas. Detta förbättrar genomströmningen av kontinuerlig förträning och minskar utbildningskostnaderna.
Kontinuerlig förträning kontra finjustering
De flesta tillgängliga LLM är generella och saknar domänspecifika förmågor. Domän LLM har visat betydande prestanda inom medicinska, finansiella eller vetenskapliga domäner. För att en LLM ska skaffa sig domänspecifik kunskap finns det fyra metoder: träning från grunden, kontinuerlig förträning, instruktionsfinjustering av domänuppgifter och Retrieval Augmented Generation (RAG).
I traditionella modeller används finjustering vanligtvis för att skapa uppgiftsspecifika modeller för en domän. Detta innebär att underhålla flera modeller för flera uppgifter som enhetsextraktion, avsiktsklassificering, sentimentanalys eller svar på frågor. Med tillkomsten av LLM har behovet av att upprätthålla separata modeller blivit föråldrat genom att använda tekniker som inlärning i sammanhanget eller uppmaning. Detta sparar ansträngningen som krävs för att underhålla en hög med modeller för relaterade men distinkta uppgifter.
Intuitivt kan du träna LLM:er från grunden med domänspecifika data. Även om det mesta av arbetet med att skapa domän-LLM har fokuserat på utbildning från grunden, är det oöverkomligt dyrt. Till exempel kostar GPT-4-modellen över $ 100 miljoner att träna. Dessa modeller är utbildade på en blandning av öppna domändata och domändata. Kontinuerlig förträning kan hjälpa modeller att skaffa sig domänspecifik kunskap utan att ta på sig kostnaden för förträning från början eftersom du förtränar en befintlig öppen domän LLM på endast domändata.
Med instruktionsfinjustering av en uppgift kan du inte få modellen att förvärva domänkunskap eftersom LLM endast förvärvar domäninformation som finns i instruktionsfinjusteringsdatauppsättningen. Om inte en mycket stor datamängd för instruktionsfinjustering används räcker det inte att skaffa domänkunskap. Att köpa instruktionsuppsättningar av hög kvalitet är vanligtvis utmanande och är anledningen till att använda LLM:er i första hand. Dessutom kan finjustering av instruktioner för en uppgift påverka prestanda för andra uppgifter (som ses i detta papper). Men finjustering av instruktionen är mer kostnadseffektiv än något av förträningsalternativen.
Följande figur jämför traditionell uppgiftsspecifik finjustering. vs in-context learning paradigm med LLMs.
 RAG är det mest effektiva sättet att vägleda en LLM för att generera svar på en domän. Även om den kan vägleda en modell att generera svar genom att tillhandahålla fakta från domänen som hjälpinformation, förvärvar den inte det domänspecifika språket eftersom LLM fortfarande förlitar sig på icke-domänspråksstil för att generera svaren.
RAG är det mest effektiva sättet att vägleda en LLM för att generera svar på en domän. Även om den kan vägleda en modell att generera svar genom att tillhandahålla fakta från domänen som hjälpinformation, förvärvar den inte det domänspecifika språket eftersom LLM fortfarande förlitar sig på icke-domänspråksstil för att generera svaren.
Kontinuerlig förträning är ett mellanting mellan förträning och instruktionsfinjustering vad gäller kostnad samtidigt som det är ett starkt alternativ till att få domänspecifik kunskap och stil. Den kan tillhandahålla en allmän modell över vilken ytterligare instruktionsfinjustering på begränsade instruktionsdata kan utföras. Kontinuerlig förträning kan vara en kostnadseffektiv strategi för specialiserade domäner där uppsättningen av nedströmsuppgifter är stor eller okända och märkta instruktionsjusteringsdata är begränsade. I andra scenarier kan instruktionsfinjustering eller RAG vara lämpligare.
För att lära dig mer om finjustering, RAG och modellträning, se Finjustera en grundmodell, Retrieval Augmented Generation (RAG)och Träna en modell med Amazon SageMaker, respektive. För detta inlägg fokuserar vi på effektiv kontinuerlig förträning.
Metodik för effektiv kontinuerlig förträning
Kontinuerlig förträning består av följande metodik:
- Domain-Adaptive Continual Pre-training (DACP) – I tidningen Effektiv kontinuerlig förutbildning för att bygga domänspecifika stora språkmodeller, förtränar författarna kontinuerligt Pythia-språkmodellsviten på den finansiella korpusen för att anpassa den till finansdomänen. Målet är att skapa finansiella LLM:er genom att mata in data från hela den finansiella domänen till en modell med öppen källkod. Eftersom utbildningskorpusen innehåller alla kurerade datamängder i domänen bör den resulterande modellen skaffa sig ekonomispecifik kunskap och därigenom bli en mångsidig modell för olika ekonomiska uppgifter. Detta resulterar i FinPythia-modeller.
- Task-Adaptive Continual Pre-training (TACP) – Författarna förtränar modellerna vidare på märkta och omärkta uppgiftsdata för att skräddarsy dem för specifika uppgifter. Under vissa omständigheter kan utvecklare föredra modeller som ger bättre prestanda för en grupp av uppgifter inom domänen snarare än en domängenerisk modell. TACP är utformad som kontinuerlig förträning som syftar till att förbättra prestanda på riktade uppgifter, utan krav på märkta data. Specifikt förtränar författarna kontinuerligt de öppna källkodsmodellerna på uppgiftstoken (utan etiketter). Den primära begränsningen av TACP ligger i att konstruera uppgiftsspecifika LLM:er istället för grundläggande LLM:er, på grund av den enda användningen av omärkta uppgiftsdata för utbildning. Även om DACP använder en mycket större korpus, är det oöverkomligt dyrt. För att balansera dessa begränsningar föreslår författarna två tillvägagångssätt som syftar till att bygga domänspecifika grund LLM:er samtidigt som de bevarar överlägsen prestanda för måluppgifter:
- Effektiv uppgiftsliknande DACP (ETS-DACP) – Författarna föreslår att man väljer en delmängd av finansiell korpus som är mycket lik uppgiftsdata med hjälp av inbäddningslikhet. Denna delmängd används för kontinuerlig förträning för att göra den mer effektiv. Specifikt förtränar författarna kontinuerligt den öppna källkodsläran på en liten korpus extraherad från den finansiella korpusen som ligger nära måluppgifterna i distributionen. Detta kan bidra till att förbättra uppgiftsprestanda eftersom vi använder modellen för distribution av uppgiftstokens trots att märkta data inte krävs.
- Effektiv uppgifts-agnostisk DACP (ETA-DACP) – Författarna föreslår att man använder mått som förvirring och entropi av tokentyp som inte kräver uppgiftsdata för att välja prover från finansiell korpus för effektiv kontinuerlig förträning. Detta tillvägagångssätt är utformat för att hantera scenarier där uppgiftsdata inte är tillgänglig eller mer mångsidiga domänmodeller för den bredare domänen föredras. Författarna antar två dimensioner för att välja dataprover som är viktiga för att få domäninformation från en delmängd av domändata före utbildning: nyhet och mångfald. Nyhet, mätt med den förvirring som registrerats av målmodellen, hänvisar till den information som inte sågs av LLM tidigare. Data med hög nyhet indikerar ny kunskap för LLM, och sådan data ses som svårare att lära sig. Detta uppdaterar generiska LLM:er med intensiv domänkunskap under kontinuerlig förutbildning. Mångfald, å andra sidan, fångar mångfalden av distributioner av tokentyper i domänkorpusen, vilket har dokumenterats som ett användbart inslag i forskningen om läroplansinlärning om språkmodellering.
Följande figur jämför ett exempel på ETS-DACP (vänster) mot ETA-DACP (höger).

Vi använder två samplingsscheman för att aktivt välja datapunkter från kurerad finansiell korpus: hård sampling och mjuk sampling. Det förra görs genom att först rangordna den finansiella korpusen efter motsvarande mätvärden och sedan välja topp-k-proverna, där k är förutbestämt enligt utbildningsbudgeten. För de senare tilldelar författarna provtagningsvikter för varje datapunkt enligt de metriska värdena, och sedan slumpmässigt ta k datapunkter för att möta träningsbudgeten.
Resultat och analys
Författarna utvärderar de resulterande finansiella LLM:erna på en rad finansiella uppgifter för att undersöka effektiviteten av kontinuerlig förträning:
- Finansiell fras Bank – En sentimentklassificeringsuppgift på finansiella nyheter.
- FiQA SA – En aspektbaserad sentimentklassificeringsuppgift baserad på finansiella nyheter och rubriker.
- Headline – En binär klassificeringsuppgift om huruvida en rubrik på en finansiell enhet innehåller viss information.
- NER – En finansiell namngiven enhetsutvinningsuppgift baserad på kreditriskbedömningsdelen av SEC-rapporter. Ord i denna uppgift är kommenterade med PER, LOC, ORG och MISC.
Eftersom finansiella LLM är instruktion finjusterade, utvärderar författarna modeller i en 5-shot-inställning för varje uppgift för robusthetens skull. I genomsnitt överträffar FinPythia 6.9B Pythia 6.9B med 10 % över fyra uppgifter, vilket visar effektiviteten av domänspecifik kontinuerlig förträning. För 1B-modellen är förbättringen mindre djupgående, men prestandan förbättras fortfarande med 2 % i genomsnitt.
Följande figur illustrerar prestandaskillnaden före och efter DACP på båda modellerna.

Följande figur visar två kvalitativa exempel genererade av Pythia 6.9B och FinPythia 6.9B. För två finansrelaterade frågor om en investerarförvaltare och en finansiell term, förstår Pythia 6.9B inte termen eller känner igen namnet, medan FinPythia 6.9B genererar detaljerade svar korrekt. De kvalitativa exemplen visar att kontinuerlig förutbildning gör det möjligt för LLM:erna att skaffa sig domänkunskap under processen.

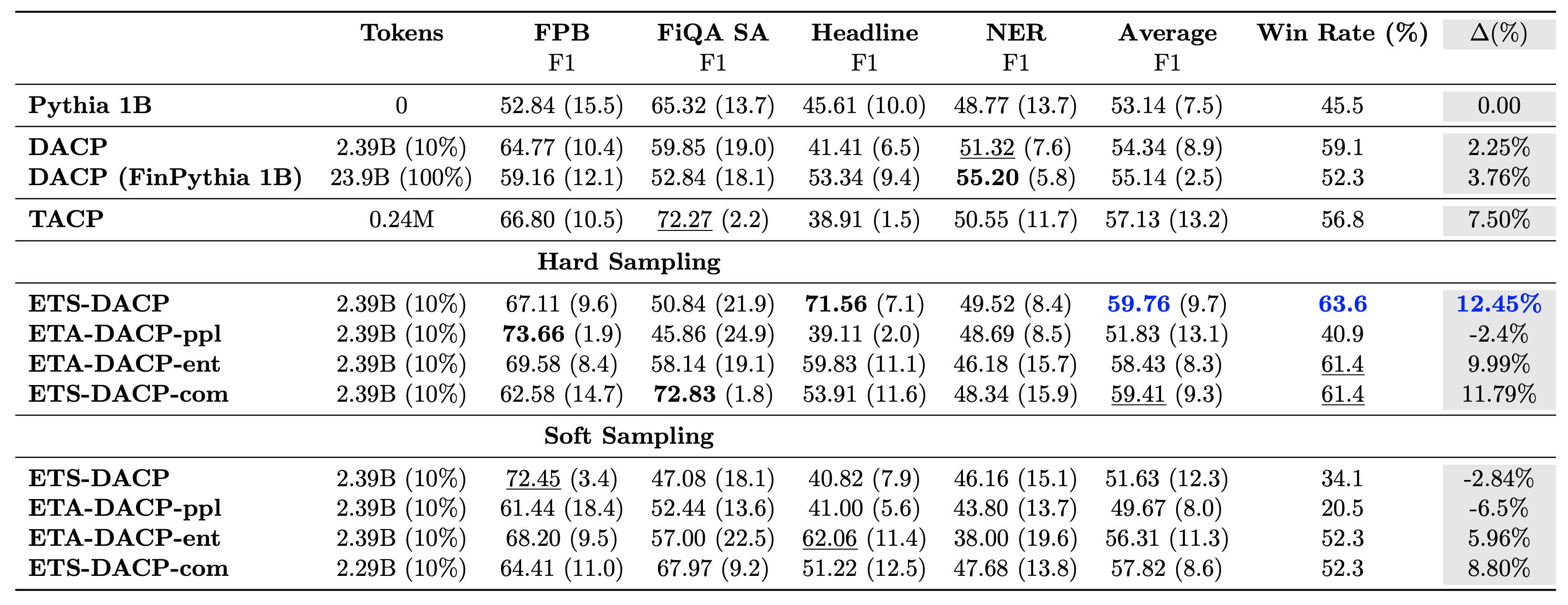
Följande tabell jämför olika effektiva metoder för kontinuerlig förträning. ETA-DACP-ppl är ETA-DACP baserad på förvirring (nyhet), och ETA-DACP-ent är baserad på entropi (diversitet). ETS-DACP-com liknar DACP med dataurval genom att medelvärde för alla tre mätvärdena. Följande är några tips från resultaten:
- Dataurvalsmetoder är effektiva – De överträffar standard kontinuerlig förträning med bara 10 % av träningsdata. Effektiv kontinuerlig förträning inklusive Task-Similar DACP (ETS-DACP), Task-Agnostic DACP baserad på entropi (ESA-DACP-ent) och Task-Similar DACP baserad på alla tre mätvärdena (ETS-DACP-com) överträffar standard DACP i genomsnitt trots att de är utbildade på endast 10% av finansiell korpus.
- Uppgiftsmedvetet dataurval fungerar bäst i linje med forskning om små språkmodeller – ETS-DACP registrerar den bästa genomsnittliga prestandan bland alla metoder och, baserat på alla tre mätvärden, registrerar den näst bästa uppgiftsprestanda. Detta tyder på att användning av omärkta uppgiftsdata fortfarande är ett effektivt tillvägagångssätt för att förbättra uppgiftsprestanda när det gäller LLM:er.
- Uppgifts-agnostisk dataurval är nära tvåa – ESA-DACP-ent följer prestandan för den uppgiftsmedvetna dataurvalsmetoden, vilket antyder att vi fortfarande kan öka uppgiftens prestanda genom att aktivt välja högkvalitativa prover som inte är knutna till specifika uppgifter. Detta banar väg för att bygga finansiella LLM:er för hela domänen samtidigt som man uppnår överlägsen uppgiftsprestanda.
En kritisk fråga när det gäller kontinuerlig förträning är om det påverkar prestationen negativt på uppgifter utanför domänen. Författarna utvärderar också den ständigt förtränade modellen på fyra allmänt använda generiska uppgifter: ARC, MMLU, TruthQA och HellaSwag, som mäter förmågan att svara på frågor, resonera och slutföra. Författarna finner att kontinuerlig förträning inte negativt påverkar prestanda utanför domänen. För mer information, se Effektiv kontinuerlig förutbildning för att bygga domänspecifika stora språkmodeller.
Slutsats
Det här inlägget erbjöd insikter i datainsamling och kontinuerliga förträningsstrategier för utbildning av LLM:er för finansiell domän. Du kan börja träna dina egna LLM:er för ekonomiska uppgifter med hjälp av Amazon SageMaker utbildning or Amazonas berggrund i dag.
Om författarna
 Yong Xie är en tillämpad vetenskapsman inom Amazon FinTech. Han fokuserar på att utveckla stora språkmodeller och Generativa AI-applikationer för finans.
Yong Xie är en tillämpad vetenskapsman inom Amazon FinTech. Han fokuserar på att utveckla stora språkmodeller och Generativa AI-applikationer för finans.
 Karan Aggarwal är en Senior Applied Scientist med Amazon FinTech med fokus på Generativ AI för ekonomibruk. Karan har lång erfarenhet av tidsserieanalys och NLP, med särskilt intresse av att lära av begränsad märkt data
Karan Aggarwal är en Senior Applied Scientist med Amazon FinTech med fokus på Generativ AI för ekonomibruk. Karan har lång erfarenhet av tidsserieanalys och NLP, med särskilt intresse av att lära av begränsad märkt data
 Aitzaz Ahmad är en tillämpad vetenskapschef på Amazon där han leder ett team av forskare som bygger olika tillämpningar av maskininlärning och generativ AI inom finans. Hans forskningsintressen är NLP, Generative AI och LLM Agents. Han doktorerade i elektroteknik från Texas A&M University.
Aitzaz Ahmad är en tillämpad vetenskapschef på Amazon där han leder ett team av forskare som bygger olika tillämpningar av maskininlärning och generativ AI inom finans. Hans forskningsintressen är NLP, Generative AI och LLM Agents. Han doktorerade i elektroteknik från Texas A&M University.
 Qingwei Li är en maskininlärningsspecialist på Amazon Web Services. Han fick sin Ph.D. i Operations Research efter att han bröt sin rådgivares forskningsanslagskonto och misslyckades med att leverera Nobelpriset han lovade. För närvarande hjälper han kunder inom finansiella tjänster att bygga maskininlärningslösningar på AWS.
Qingwei Li är en maskininlärningsspecialist på Amazon Web Services. Han fick sin Ph.D. i Operations Research efter att han bröt sin rådgivares forskningsanslagskonto och misslyckades med att leverera Nobelpriset han lovade. För närvarande hjälper han kunder inom finansiella tjänster att bygga maskininlärningslösningar på AWS.
 Raghvender Arni leder Customer Acceleration Team (CAT) inom AWS Industries. CAT är ett globalt tvärfunktionellt team av kundinriktade molnarkitekter, mjukvaruingenjörer, datavetare och AI/ML-experter och designers som driver innovation via avancerad prototyping och driver molndriftsexcellens via specialiserad teknisk expertis.
Raghvender Arni leder Customer Acceleration Team (CAT) inom AWS Industries. CAT är ett globalt tvärfunktionellt team av kundinriktade molnarkitekter, mjukvaruingenjörer, datavetare och AI/ML-experter och designers som driver innovation via avancerad prototyping och driver molndriftsexcellens via specialiserad teknisk expertis.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

