
Beskrivning
ChatGPT är en kraftfull språkmodell utvecklad av OpenAI som har tagit världen med storm med sin förmåga att förstå och konversationsmässigt svara på mänsklig input. En av de mest spännande funktionerna i ChatGPT är dess förmåga att generera kodsnuttar på olika programmeringsspråk, bl.a. Python, Java, JavaScript och C++. Denna funktion har gjort ChatGPT ett populärt val bland utvecklare som snabbt vill göra prototyper eller lösa ett problem utan att behöva skriva hela kodbasen själva. Den här artikeln kommer att utforska hur ChatGPTs kodtolkare för avancerad dataanalys för dataforskare. Vidare kommer vi att titta på hur det fungerar och kan användas för att generera maskininlärningskod. Vi kommer också att diskutera några fördelar och begränsningar med att använda ChatGPT.
Inlärningsmål
- Förstå hur ChatGPTs avancerade dataanalys fungerar och hur den kan användas för att generera maskininlärningskod.
- Lär dig hur du använder ChatGPTs avancerade dataanalys för att generera kodavsnitt för datavetare som använder Python.
- Förstå fördelarna och begränsningarna med ChatGPTs avancerade dataanalys för att generera maskininlärningskod.
- Lär dig hur du designar och implementerar maskininlärningsmodeller med ChatGPTs avancerade dataanalys.
- Förstå hur man förbearbetar data för maskininlärning, inklusive hantering av saknade värden, "kodning av kategoriska variabler, normalisering av data och skalning av numeriska funktioner."kodning av kategoriska variabler, normalisering av data och skalning av numeriska funktioner.
- Lär dig hur du delar upp data i tränings- och testset och utvärderar prestandan för maskininlärningsmodeller med hjälp av mätvärden som noggrannhet, precision, återkallelse, F1-poäng, medelkvadratfel, genomsnittligt absolut fel, R-kvadratvärde, etc.
Genom att bemästra dessa inlärningsmål bör man förstå hur man använder ChatGPTs avancerade dataanalys för att generera maskininlärningskod och implementera olika maskininlärningsalgoritmer. De bör också kunna tillämpa dessa färdigheter på verkliga problem och datauppsättningar, och demonstrera sin skicklighet i att använda ChatGPTs avancerade dataanalys för maskininlärningsuppgifter.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Hur fungerar ChatGPTs avancerade dataanalys?
ChatGPTs avancerade dataanalys är baserad på en djupt lärande modell som kallas en transformator, tränad på en stor korpus av textdata. Transformatorn använder självuppmärksamhetsmekanismer för att förstå sammanhanget och förhållandet mellan olika delar av inmatningstexten. När en användare matar in en prompt eller ett kodavsnitt genererar ChatGPTs modell ett svar baserat på de mönster och strukturer som den har lärt sig från träningsdata.
Den avancerade dataanalysen i ChatGPT kan generera kodavsnitt genom att utnyttja den stora mängden onlinekod. ChatGPT:s modell kan lära sig olika programmeringsspråks syntax, semantik och idiom genom att analysera arkiv med öppen källkod och andra kodkällor. ChatGPT:s modell kan dra nytta av denna kunskap när en användare begär en bit kod för att generera ett relevant och fungerande kodavsnitt.
Generera maskininlärningskod med ChatGPT
Maskininlärning är en av de mest lovande tillämpningarna av ChatGPTs avancerade dataanalys. Med framväxten av tillämpningar för djupinlärning och maskininlärning har de blivit allt viktigare områden för forskning och utveckling. Att designa och implementera dessa modeller kan dock vara komplext och tidskrävande och kräver expertis inom linjär algebra, kalkyl, sannolikhetsteori och datavetenskap.
ChatGPT:s avancerade dataanalys kan hjälpa till att förenkla denna process genom att generera maskininlärningskodavsnitt som användare kan integrera i sina projekt. En användare kan till exempel be ChatGPT att generera ett kodavsnitt med hjälp av en linjär regressionsteknik för att förutsäga huspriser i Kalifornien baserat på en träningsdatauppsättning som tillhandahålls som indata i .csv-format. ChatGPTs modell kan generera ett kodavsnitt som inkluderar nödvändiga importer, dataförbehandlingssteg, modellarkitektur och utbildningsprocedurer baserat på användarens input.
Ladda upp datauppsättningen till kodtolken i ChatGPT och ange prompten nedan.
frågar:
Utföra linjär regression använda sklearn på ovanstående dataset och visa alla steg med Python-kod. Prediktionsvariabeln från data är median_house_value.

Svar:
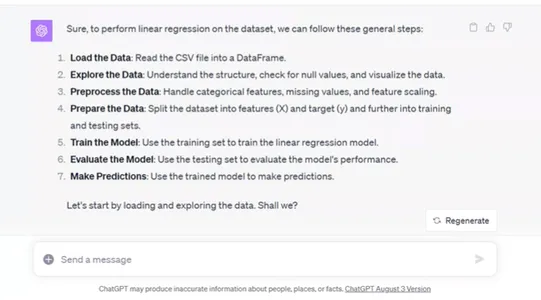
Stegen för linjär regression med hjälp av lära sig i datasetet "housing.csv", med "median_house_value" som målvariabel, är följande:
- Datautforskning: Ladda datauppsättningen och undersök snabbt dess struktur.
- Dataförbehandling: Hantera saknade värden, koda kategoriska variabler (om några) och skala numeriska funktioner.
- Dela upp data: Dela upp data i tränings- och testset.
- Modellutbildning: Träna en regressionsmodell på träningssetet.
- Utvärdering: Utvärdera den tränade modellen på testsetet.
- Modelltolkning: Analysera vikten av varje funktion i förutsägelsen.
Laddar datauppsättningen och utforskar dess struktur:
# Load the dataset
data = pd.read_csv('/mnt/data/housing.csv')
# Display the first few rows of the dataset to understand its structure
data.head()
#import csv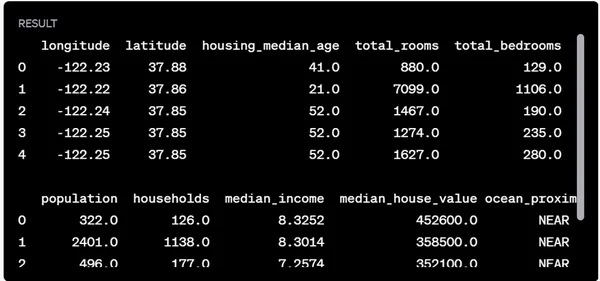
Datauppsättningen innehåller följande kolumner:
- longitud: Platsens longitud
- latitud: Platsens latitud
- boende_median_ålder: Medianåldern för bostäderna i området
- totalt_rum: Totalt antal rum i området
- total_bedrooms: Totalt antal sovrum i området
- befolkning: Områdets befolkning
- hushåll: Antal hushåll i området
- median_inkomst: Medianinkomsten för människorna i området
- median_house_value: Medianhusvärde i området (vår målvariabel)
- ocean_proximity: Närhet till havet (kategorisk variabel)
Låt oss sedan fortsätta med dataförbehandling:
Dataförbehandling:
- Kontrollera om det saknas värden och hantera dem.
- Koda den kategoriska variabeln ocean_proximity.
- Skala numeriska funktioner för att standardisera dem.
Söker efter saknade värden i datamängden:
# Check for missing values in each column
missing_values = data.isnull().sum()
missing_values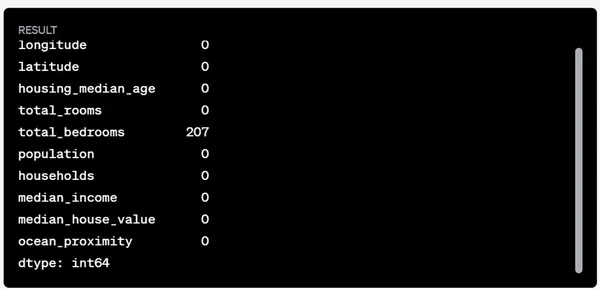
Det ser ut som totalt_sovrum kolumnen saknar 207 värden. En vanlig strategi för att hantera saknade värden för numeriska kolumner är att ersätta dem med medianvärdet för den kolumnen. Låt oss fylla i de saknade värdena totalt_sovrum med dess medianvärde.
Efter det kommer vi att koda ocean_proximity kategorisk variabel med en-hot-kodning och skala de numeriska funktionerna.
Förbehandlingssteg:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Fill missing values in total_bedrooms with its median value
data['total_bedrooms'].fillna(data['total_bedrooms'].median(), inplace=True)
# Define columns for preprocessing
numerical_features = ['longitude', 'latitude', 'housing_median_age', 'total_rooms',
'total_bedrooms', 'population', 'households', 'median_income']
categorical_feature = ['ocean_proximity']
# Create a column transformer for preprocessing
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numerical_features),
('cat', OneHotEncoder(), categorical_feature)
])
# Apply the transformations to the data (excluding the target variable)
X = data.drop('median_house_value', axis=1)
y = data['median_house_value']
X_transformed = preprocessor.fit_transform(X)
# Checking the transformed data's shape and first few rows to ensure preprocessing was successful
X_transformed.shape, X_transformed[:5]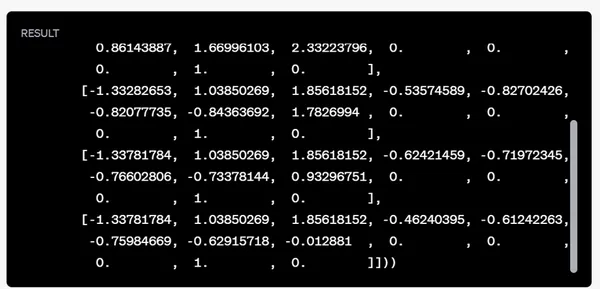
Förbehandlingsstegen var framgångsrika:
- Kontrollera om det saknas värden och hantera dem.
- Koda den kategoriska variabeln ocean_proximity.
- Skala numeriska funktioner för att standardisera dem.
Den transformerade datamängden har 20,640 13 prover och XNUMX funktioner.
Dela upp data:
Därefter delar vi upp data i tränings- och testset. Detta gör att vi kan träna vår modell på en delmängd och
Testa dess prestanda på en annan osynlig delmängd. Vanligtvis är ett vanligt delat förhållande 80:20 eller 70:30 för träning och testning. För den här övningen använder vi en 80:20-delning.
Låt oss dela upp data.
from sklearn.model_selection
import train_test_split
# Splitting the data into training and test sets (80% training, 20% testing)
X_train, X_test, y_train, y_test = train_test_split(X_transformed, y, test_size=0.2,
random_state=42)
X_train.shape, X_test.shape
Data har framgångsrikt delats upp i tränings- och testset:
- Träningsset: 16,512 prover
- Testset: 4,128 prover
Modellutbildning:
Därefter tränar vi en regressionsmodell med hjälp av träningsdata. För den här demonstrationen använder vi en enkel
linjär regressionsmodell. Vid behov kan mer komplexa modeller eller ensemblemetoder utforskas senare.
Träna den linjära regressionsmodellen:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Initialize the Linear Regression model
model = LinearRegression()
# Train the model on the training data
model.fit(X_train, y_train)
# Predict on the training data to check in-sample performance
train_predictions = model.predict(X_train)
train_mse = mean_squared_error(y_train, train_predictions)
train_rmse = train_mse**0.5
train_rmse
Rotmedelkvadratfelet (RMSE) för förutsägelserna på träningsdata är ungefär $68,433.94 XNUMX.
RMSE ger oss en uppfattning om den genomsnittliga storleken på prediktionsfelen. I detta sammanhang är vår modells förutsägelser i genomsnitt cirka 68,433.94 XNUMX USD från de faktiska husvärdena i träningsuppsättningen.
Utvärdering:
Vi kommer att förutsäga testdata och beräkna RMSE för dessa förutsägelser för att utvärdera modellens generaliseringsförmåga.
Låt oss utvärdera modellen på testsetet.
# Predict on the test data
test_predictions = model.predict(X_test)
# Compute the RMSE for the test predictions
test_mse = mean_squared_error(y_test, test_predictions)
test_rmse = test_mse**0.5
test_rmse
Rotmedelkvadratfelet (RMSE) för förutsägelserna på testdata är ungefär $70,060.52 XNUMX.
Test-RMSE är något högre än tränings-RMSE, vilket förväntas eftersom modellen inte tränades på testdata. Värdena är dock relativt nära, vilket tyder på att modellen inte överanpassar träningsdata för mycket.
Modelltolkning:
För att förstå modellen bättre kan vi titta på koefficienterna för varje funktion. Dessa koefficienter indikerar vikten och inverkan av varje funktion på målvariabeln, median_house_value.
Låt oss ta en titt på funktionskoefficienterna.
# Extract feature names after one-hot encoding
feature_names = numerical_features + list(preprocessor.named_transformers_['cat'].categories_[0])
# Retrieve the coefficients from the model
coefficients = model.coef_
# Create a DataFrame to display the feature coefficients
feature_importance = pd.DataFrame({
'Feature': feature_names,
'Coefficient': coefficients
}).sort_values(by='Coefficient', ascending=False)
feature_importance
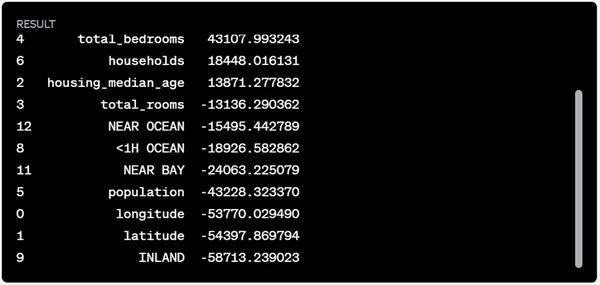
Här är tolkningarna av funktionskoefficienterna:
- Positiva koefficienter indikerar att när egenskapsvärdet ökar, ökar också det förutsagda median_house_value.
- Negativa koefficienter indikerar att när egenskapsvärdet ökar, minskar det förutsagda median_house_value.
Till exempel:
- ISLAND har den högsta positiva koefficienten, vilket tyder på att hus på öar har ett högre förutsagt värde än andra platser.
- median_income har också en betydande positiv effekt på det prognostiserade husvärdet.
- Å andra sidan har INLAND den mest negativa effekten, vilket indikerar att hus som ligger i inlandet tenderar att ha ett lägre prognostiserat värde.
- Geografiska egenskaper som longitud och latitud spelar också en roll för att bestämma husvärden, där båda har negativa koefficienter i denna modell.
Även om dessa koefficienter ger insikter i sambanden mellan funktioner och målvariabeln, innebär de inte nödvändigtvis orsakssamband. Externa faktorer och interaktioner mellan funktioner kan också påverka husvärden.
Fördelar med att använda ChatGPT för maskininlärningskodgenerering

Det finns flera fördelar med att använda ChatGPTs avancerade dataanalys för att generera maskininlärningskod:
- Tidsbesparingar: Att designa och implementera en maskininlärningsmodell kan ta mycket tid, särskilt för nybörjare. ChatGPTs avancerade dataanalys kan spara mycket tid för användare genom att generera fungerande kodavsnitt som de kan använda som utgångspunkt för sina projekt.
- Förbättrad produktivitet: Med ChatGPTs avancerade dataanalys kan användare fokusera på högnivåkoncepten i deras maskininlärningsprojekt, såsom dataförbearbetning, funktionsteknik och modellutvärdering, utan att fastna i detaljerna för att implementera modellarkitekturen.
- Tillgänglighet: ChatGPTs avancerade dataanalys gör maskininlärning mer tillgänglig för människor som kanske inte har en stark bakgrund inom datavetenskap eller programmering. Användare kan beskriva sina önskemål och ChatGPT genererar den nödvändiga koden.
- Anpassning: ChatGPTs avancerade dataanalys tillåter användare att anpassa den genererade koden för att passa deras behov. Användare kan ändra hyperparametrarna, justera modellarkitekturen eller lägga till ytterligare funktionalitet till kodavsnittet.
Begränsningar för att använda ChatGPT för maskininlärningskodgenerering
ChatGPT:s kodtolkare är ett kraftfullt verktyg för att generera maskininlärningskod, men det finns några begränsningar att tänka på:
- Kvaliteten på den genererade koden: Även om ChatGPTs avancerade dataanalys kan generera fungerande kodavsnitt, kan kodens kvalitet variera beroende på uppgiftens komplexitet och träningsdatans kvalitet. Användare kan behöva rensa upp koden, fixa buggar eller optimera prestanda innan de kan användas i produktionen.
- Brist på domänkunskap: ChatGPT:s modell kanske inte alltid förstår nyanserna i en viss domän eller applikationsområde. Användare kan behöva tillhandahålla ytterligare sammanhang eller vägledning för att hjälpa ChatGPT att generera kod som uppfyller deras krav.
- Beroende på träningsdata: ChatGPT:s avancerade dataanalys bygger i hög grad på kvaliteten och mångfalden av träningsdata som den har utsatts för. Om träningsdatan är partisk eller ofullständig kan den genererade koden återspegla dessa brister.
- Etiska betänkligheter: Etiska farhågor finns kring att använda AI-genererad kod i kritiska applikationer, som sjukvård eller finans. Användare måste noggrant utvärdera den genererade koden och se till att den uppfyller de standarder och föreskrifter som krävs.
Slutsats
ChatGPTs avancerade dataanalys är ett kraftfullt verktyg för att generera kodavsnitt. Med sin förmåga att förstå naturliga språkuppmaningar och generera arbetskod, har ChatGPT potentialen att demokratisera tillgången till maskininlärningsteknologi och påskynda innovation inom området. Användare måste dock vara medvetna om teknikens begränsningar och noggrant utvärdera den genererade koden innan den används i produktionen. När funktionerna i ChatGPT fortsätter att utvecklas kan vi förvänta oss att se ännu fler spännande tillämpningar av denna teknik.
Key Takeaways
- ChatGPTs avancerade dataanalys är baserad på en djupinlärningsmodell som kallas en transformator, tränad på en stor korpus av textdata.
- Avancerad dataanalys kan generera kodavsnitt i olika programmeringsspråk, inklusive Python, Java, JavaScript och C++, genom att utnyttja den stora mängden onlinekod.
- ChatGPTs avancerade dataanalys kan generera kodavsnitt för maskininlärning för linjär regression, logistisk regression, beslutsträd, slumpmässig skog, stödvektormaskiner, neurala nätverk och djupinlärning.
- För att använda ChatGPTs avancerade dataanalys för maskininlärning kan användare tillhandahålla en uppmaning eller kodavsnitt och begära en specifik uppgift, som att generera ett kodavsnitt för en linjär regressionsmodell med hjälp av en viss datamängd.
- ChatGPT:s modell kan generera kodavsnitt som inkluderar nödvändiga importer, dataförbehandlingssteg, modellarkitektur och utbildningsprocedurer.
- ChatGPTs avancerade dataanalys kan hjälpa till att förenkla design och implementering av maskininlärningsmodeller, vilket gör det enklare för utvecklare och datavetare att prototyper eller lösa ett problem snabbt.
- Det finns dock också begränsningar för att använda ChatGPTs avancerade dataanalys, såsom potentialen för genererad kod att innehålla fel eller brist på anpassningsalternativ.
- Sammantaget är ChatGPTs avancerade dataanalys ett kraftfullt verktyg som kan hjälpa till att effektivisera utvecklingsprocessen för utvecklare och datavetare, särskilt när de genererar maskininlärningskodavsnitt.
Vanliga frågor
S: Gå till ChatGPT-webbplatsen och börja skriva in dina kodningsfrågor eller uppmaningar. Systemet kommer sedan att svara baserat på sin förståelse av din fråga. Du kan också hänvisa till handledningar och dokumentation online för att hjälpa dig komma igång.
S: ChatGPTs kodtolkare stöder flera populära programmeringsspråk, inklusive Python, Java, JavaScript och C++. Den kan också generera kodavsnitt på andra språk, även om kvaliteten på utdata kan variera beroende på kodens komplexitet och tillgängligheten av exempel i träningsdata.
S: Ja, ChatGPTs kodtolkare kan hantera komplexa kodningsuppgifter, inklusive maskininlärningsalgoritmer, dataanalys och webbutveckling. Kvaliteten på den genererade koden kan dock bero på uppgiftens komplexitet och storleken på den utbildningsdatauppsättning som är tillgänglig för modellen.
S: Ja, koden som genereras av ChatGPT:s kodtolk är gratis att använda enligt villkoren i MIT-licensen. Detta innebär att du kan modifiera, distribuera och använda koden för kommersiella ändamål utan att betala royalties eller skaffa tillstånd från författaren.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/11/chatgpts-code-interpreter-gpt-4-advanced-data-analysis-for-data-scientists/

