del 1 i denna tvådelade serie beskrev hur man bygger en pseudonymiseringstjänst som omvandlar dataattribut i ren text till en pseudonym eller vice versa. En centraliserad pseudonymiseringstjänst tillhandahåller en unik och universellt erkänd arkitektur för att generera pseudonymer. Följaktligen kan en organisation uppnå en standardprocess för att hantera känslig data på alla plattformar. Dessutom tar detta bort all komplexitet och expertis som behövs för att förstå och implementera olika efterlevnadskrav från utvecklingsteam och analytiska användare, vilket gör att de kan fokusera på sina affärsresultat.
Att följa ett frikopplat tjänstebaserat tillvägagångssätt innebär att du som organisation är opartisk mot användningen av någon specifik teknik för att lösa dina affärsproblem. Oavsett vilken teknik som föredras av enskilda team kan de ringa pseudonymiseringstjänsten för att pseudonymisera känslig data.
I det här inlägget fokuserar vi på vanliga extrahera, transformera och ladda (ETL) konsumtionsmönster som kan använda pseudonymiseringstjänsten. Vi diskuterar hur du använder pseudonymiseringstjänsten i dina ETL-jobb på Amazon EMR (använder sig av Amazon EMR på EC2) för streaming och batchanvändning. Dessutom kan du hitta en Amazonas Athena och AWS-lim baserat konsumtionsmönster i GitHub repo av lösningen.
Lösningsöversikt
Följande diagram beskriver lösningsarkitekturen.

Kontot till höger är värd för pseudonymiseringstjänsten, som du kan distribuera med hjälp av instruktionerna i del 1 av den här serien.
Kontot till vänster är det som du konfigurerade som en del av det här inlägget, som representerar ETL-plattformen baserad på Amazon EMR med hjälp av pseudonymiseringstjänsten.
Du kan distribuera pseudonymiseringstjänsten och ETL-plattformen på samma konto.
Amazon EMR ger dig möjlighet att skapa, driva och skala ramverk för big data som Apache Spark snabbt och kostnadseffektivt.
I den här lösningen visar vi hur man konsumerar pseudonymiseringstjänsten på Amazon EMR med Apache Spark för batch- och streaminganvändningsfall. Batchapplikationen läser data från en Amazon enkel lagringstjänst (Amazon S3) hink, och streamingapplikationen förbrukar poster från Amazon Kinesis dataströmmar.
PySpark-kod som används i batch- och streamingjobb
Båda applikationerna använder en gemensam verktygsfunktion som gör HTTP POST-anrop mot API-gatewayen som är länkad till pseudonymiseringen AWS Lambda fungera. REST API-anrop görs per Spark-partition med hjälp av Spark RDD mapPartitioner fungera. POST-begäran innehåller listan med unika värden för en given indatakolumn. POST-begäransvaret innehåller motsvarande pseudonymiserade värden. Koden byter ut de känsliga värdena med de pseudonymiserade för en given datamängd. Resultatet sparas till Amazon S3 och AWS-lim Datakatalog, med Apache Iceberg tabellformat.
Iceberg är ett öppet tabellformat som stöder ACID-transaktioner, schemautveckling och tidsresefrågor. Du kan använda dessa funktioner för att implementera rätt att bli bortglömd (eller dataradering) lösningar som använder SQL-satser eller programmeringsgränssnitt. Iceberg stöds av Amazon EMR från och med version 6.5.0, AWS Glue och Athena. Batch- och streamingmönster använder Iceberg som målformat. För en översikt över hur man bygger en ACID-kompatibel datasjö med Iceberg, se Bygg en högpresterande, ACID-kompatibel, utvecklande datasjö med Apache Iceberg på Amazon EMR.
Förutsättningar
Du måste ha följande förutsättningar:
- An AWS-konto.
- An AWS identitets- och åtkomsthantering (IAM)-rektor med privilegier att distribuera AWS molnformation stack och relaterade resurser.
- Smakämnen AWS-kommandoradsgränssnitt (AWS CLI) installerad på utvecklings- eller distributionsmaskinen som du kommer att använda för att köra de medföljande skripten.
- En S3-bucket i samma konto och AWS-region där lösningen ska distribueras.
- Python3 installerat på den lokala dator där kommandona körs.
- PyYAML installeras med hjälp av pip.
- En bash-terminal för att köra bash-skript som distribuerar CloudFormation-stackar.
- En extra S3-hink som innehåller indatadataset i Parquet-filer (endast för batchapplikationer). Kopiera exempeluppsättning till S3-skopan.
- En kopia av senaste kodarkivet i den lokala maskinen med hjälp av
git cloneeller nedladdningsalternativet.
Öppna en ny bash-terminal och navigera till rotmappen för det klonade förvaret.
Källkoden för de föreslagna mönstren finns i det klonade förvaret. Den använder följande parametrar:
- ARTEFACT_S3_BUCKET – S3-hinken där infrastrukturkoden kommer att lagras. Hinken måste skapas på samma konto och region där lösningen finns.
- AWS_REGION – Regionen där lösningen kommer att användas.
- AWS_PROFILE – Den namngivna profilen som kommer att tillämpas på AWS CLI kommando. Detta bör innehålla referenser för en IAM-principal med behörighet att distribuera CloudFormation-stacken med relaterade resurser.
- SUBNET_ID – Subnät-ID där EMR-klustret kommer att snurras upp. Subnätet finns redan och för demonstrationsändamål använder vi standardsubnäts-ID för standard-VPC.
- EP_URL – Slutpunkts-URL för pseudonymiseringstjänsten. Hämta detta från lösningen som distribueras som del 1 av den här serien.
- API_SECRET - En Amazon API Gateway nyckel som kommer att lagras i AWS Secrets Manager. API-nyckeln genereras från implementeringen som visas i del 1 av den här serien.
- S3_INPUT_PATH – S3-URI:n som pekar på mappen som innehåller indatadataset som parkettfiler.
- KINESIS_DATA_STREAM_NAME - Kinesis dataströmsnamn som distribueras med CloudFormation-stacken.
- SATSSTORLEK - Antalet poster som ska skickas till dataströmmen per batch.
- THREADS_NUM - Antalet parallella trådar som används i den lokala maskinen för att ladda upp data till dataströmmen. Fler trådar motsvarar en högre meddelandevolym.
- EMR_CLUSTER_ID – EMR-kluster-ID där koden kommer att köras (EMR-klustret skapades av CloudFormation-stacken).
- STACK_NAME – Namnet på CloudFormation-stacken, som tilldelas i distributionsskriptet.
Steg för batchdistribution
Som beskrivs i förutsättningarna, innan du distribuerar lösningen, ladda upp Parquet-filerna för testdatauppsättning till Amazon S3. Ange sedan S3-sökvägen till mappen som innehåller filerna som parameter <S3_INPUT_PATH>.
Vi skapar lösningsresurserna via AWS CloudFormation. Du kan distribuera lösningen genom att köra deploy_1.sh script, som finns inuti deployment_scripts mapp.
När installationsförutsättningarna har uppfyllts anger du följande kommando för att distribuera lösningen:
sh ./deployment_scripts/deploy_1.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>
-i <S3_INPUT_PATH>Utdata ska se ut som följande skärmdump.

De nödvändiga parametrarna för rengöringskommandot skrivs ut i slutet av körningen av deploy_1.sh manus. Se till att anteckna dessa värden.
Testa satslösningen
I CloudFormation-mallen som distribueras med hjälp av deploy_1.sh script, EMR-steget som innehåller Spark-batchapplikation läggs till i slutet av EMR-klusterinställningen.
För att verifiera resultaten, kontrollera S3-bucket som identifierats i CloudFormations stack-utgångar med variabeln SparkOutputLocation.

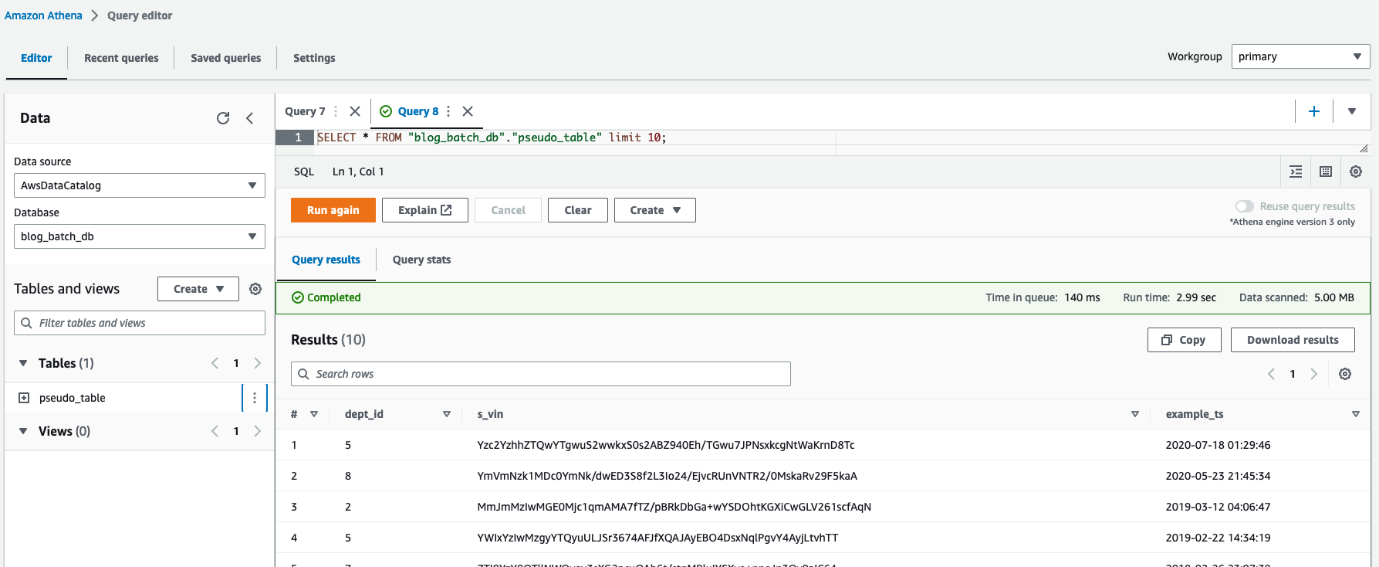
Du kan också använda Athena för att fråga i tabellen pseudo_table i databasen blog_batch_db.
Rensa upp batchresurser
För att förstöra resurserna som skapats som en del av denna övning,
i en bash-terminal, navigera till rotmappen för det klonade förvaret. Ange rengöringskommandot som visas som utdata från den tidigare körningen deploy_1.sh manus:
sh ./deployment_scripts/cleanup_1.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>Utdata ska se ut som följande skärmdump.

Implementeringssteg för streaming
Vi skapar lösningsresurserna via AWS CloudFormation. Du kan distribuera lösningen genom att köra deploy_2.sh script, som finns inuti deployment_scripts mapp. CloudFormations stackmallen för detta mönster finns tillgänglig i GitHub repo.
När installationsförutsättningarna har uppfyllts anger du följande kommando för att distribuera lösningen:
sh deployment_scripts/deploy_2.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>Utdata ska se ut som följande skärmdump.
De nödvändiga parametrarna för rengöringskommandot skrivs ut i slutet av utmatningen av deploy_2.sh manus. Se till att spara dessa värden för att använda senare.
Testa streaminglösningen
I CloudFormation-mallen som distribueras med hjälp av deploy_2.sh script, EMR-steget som innehåller Spark streaming-applikation läggs till i slutet av EMR-klusterinställningen. För att testa end-to-end-pipelinen måste du skicka poster till den distribuerade Kinesis-dataströmmen. Med följande kommandon i en bash-terminal kan du aktivera en Kinesis-producent som kontinuerligt lägger poster i strömmen, tills processen stoppas manuellt. Du kan styra producentens meddelandevolym genom att ändra BATCH_SIZE och THREADS_NUM variabler.


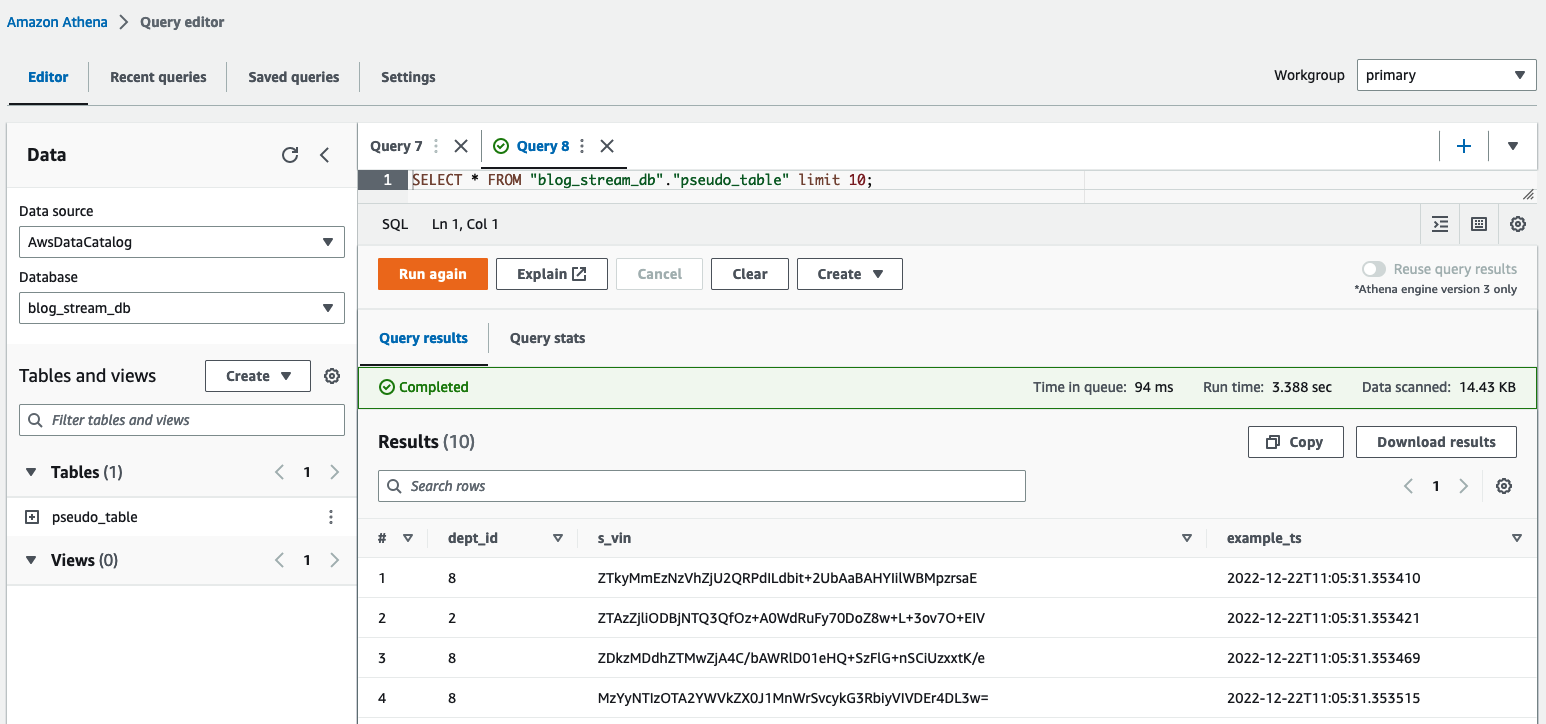
I Athenas frågeredigerare kontrollerar du resultaten genom att fråga table pseudo_table i databasen blog_stream_db.
Rensa upp streamingresurser
För att förstöra resurserna som skapats som en del av den här övningen, utför följande steg:
- Stoppa Python Kinesis-producenten som lanserades i en bash-terminal i föregående avsnitt.
- Ange följande kommando:
sh ./deployment_scripts/cleanup_2.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>Utdata ska se ut som följande skärmdump.

Prestanda detaljer
Användningsfall kan skilja sig åt i krav med avseende på datastorlek, beräkningskapacitet och kostnad. Vi har tillhandahållit några benchmarking och faktorer som kan påverka prestanda; Vi rekommenderar dock starkt att du validerar lösningen i lägre miljöer för att se om den uppfyller dina specifika krav.
Du kan påverka prestandan för den föreslagna lösningen (som syftar till att pseudonymisera en datauppsättning med Amazon EMR) genom det maximala antalet parallella samtal till pseudonymiseringstjänsten och nyttolaststorleken för varje samtal. När det gäller parallella samtal är faktorer att ta hänsyn till GetSecretValue samtalsgräns från Secrets Manager (10.000 1,000 per sekund, hård gräns) och Lambdas standard samtidighetsparallellism (XNUMX XNUMX som standard; kan ökas med kvotbegäran). Du kan styra den maximala parallelliteten genom att justera antalet executorer, antalet partitioner som utgör datamängden och klusterkonfigurationen (antal och typ av noder). När det gäller nyttolaststorleken för varje samtal är faktorer att ta hänsyn till API Gateway maximal nyttolaststorlek (6 MB) och lambdafunktionens maximala körtid (15 minuter). Du kan styra nyttolaststorleken och lambdafunktionens körtid genom att justera batchstorleksvärdet, vilket är en parameter i PySpark-skriptet som bestämmer antalet objekt som ska pseudonymiseras per varje API-anrop. För att fånga inverkan av alla dessa faktorer och bedöma prestandan för konsumtionsmönstren med Amazon EMR, har vi utformat och övervakat följande scenarier.
Prestanda för batchförbrukningsmönster
För att bedöma prestandan för batchkonsumtionsmönstret körde vi pseudonymiseringsapplikationen med tre indatauppsättningar bestående av 1, 10 och 100 parkettfiler på 97.7 MB vardera. Vi genererade indatafilerna med hjälp av dataset_generator.py skript.
Klusterkapacitetsnoderna var 1 primär (m5.4xlarge) och 15 kärnor (m5d.8xlarge). Denna klusterkonfiguration förblev densamma för alla tre scenarierna, och den gjorde det möjligt för Spark-applikationen att använda upp till 100 exekutorer. De batch_size, som också var samma för de tre scenarierna, sattes till 900 VIN per API-anrop, och den maximala VIN-storleken var 5 byte.
Följande tabell samlar informationen om de tre scenarierna.
| Utförande ID | fördelning | Datauppsättningsstorlek | Antal exekutörer | Kärnor per utförare | Exekutorminne | Runtime |
| A | 800 | 9.53 GB | 100 | 4 | 4 GiB | 11 minuter, 10 sekunder |
| B | 80 | 0.95 GB | 10 | 4 | 4 GiB | 8 minuter, 36 sekunder |
| C | 8 | 0.09 GB | 1 | 4 | 4 GiB | 7 minuter, 56 sekunder |
Som vi kan se kan vi kontrollera den övergripande körtiden genom att korrekt parallellisera samtalen till vår pseudonymiseringstjänst.
I följande exempel analyserar vi tre viktiga Lambda-mått för pseudonymiseringstjänsten: Invocations, ConcurrentExecutionsoch Duration.
Följande graf visar Invocations metrisk, med statistiken SUM i orange och RUNNING SUM i blått.

Genom att beräkna skillnaden mellan start- och slutpunkten för de kumulativa anropen kan vi extrahera hur många anrop som gjordes under varje körning.
| Kör ID | Datauppsättningsstorlek | Totala åkallanden |
| A | 9.53 GB | 1.467.000 - 0 = 1.467.000 |
| B | 0.95 GB | 1.467.000 - 1.616.500 = 149.500 |
| C | 0.09 GB | 1.616.500 - 1.631.000 = 14.500 |
Som väntat ökar antalet anrop proportionellt med 10 med datauppsättningens storlek.
Följande graf visar totalen ConcurrentExecutions metrisk, med statistiken MAX i blått.
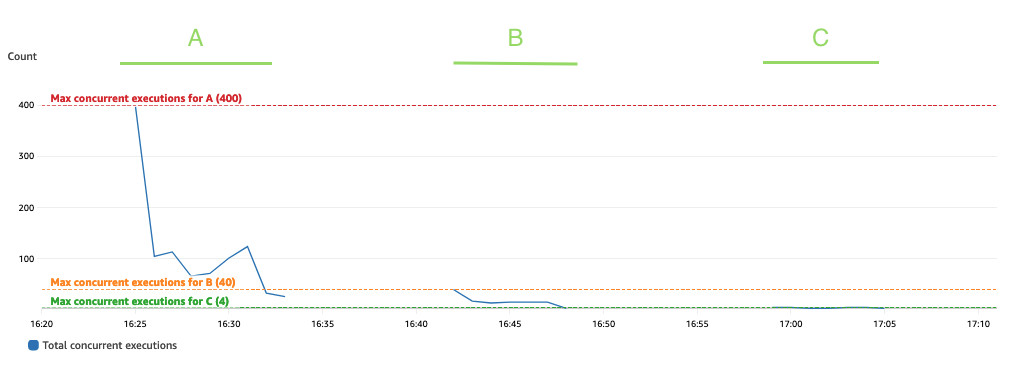
Applikationen är utformad så att det maximala antalet samtidiga körningar av lambda-funktioner ges av mängden Spark-uppgifter (Spark datasetpartitioner), som kan bearbetas parallellt. Detta antal kan beräknas som MIN (exekutorer x executor_cores, Spark-datauppsättningspartitioner).
I testet kör A behandlade 800 partitioner, med 100 exekutorer med fyra kärnor vardera. Detta gör att 400 uppgifter bearbetas parallellt så att lambdafunktionens samtidiga körningar inte kan vara över 400. Samma logik tillämpades för körningarna B och C. Vi kan se detta återspeglas i föregående graf, där mängden samtidiga körningar aldrig överstiger 400, 40 och 4 värden.
För att undvika strypning, se till att mängden Spark-uppgifter som kan bearbetas parallellt inte överstiger lambdafunktionens samtidighetsgräns. Om så är fallet bör du antingen öka Lambda-funktionens samtidighetsgräns (om du vill behålla prestanda) eller minska antingen mängden partitioner eller antalet tillgängliga executorer (som påverkar applikationens prestanda).
Följande graf visar Lambda Duration metrisk, med statistiken AVG i orange och MAX i grönt.
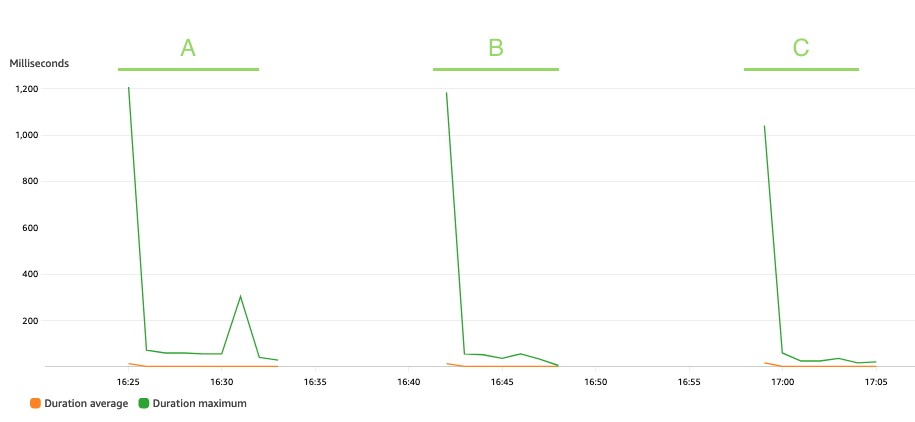
Som förväntat påverkar inte datauppsättningens storlek varaktigheten av körningen av pseudonymiseringsfunktionen, som, bortsett från några inledande anrop som står inför kallstarter, förblir konstant till ett genomsnitt på 3 millisekunder under de tre scenarierna. Detta eftersom det maximala antalet poster som ingår i varje pseudonymiseringsanrop är konstant (batch_size värde).
Lambda faktureras baserat på antalet anrop och den tid det tar för din kod att köra (varaktighet). Du kan använda den genomsnittliga varaktigheten och anropsmåtten för att uppskatta kostnaden för pseudonymiseringstjänsten.
Strömmande konsumtionsmönsterprestanda
För att bedöma prestandan för streamingkonsumtionsmönstret körde vi producer.py skript, som definierar en Kinesis-dataproducent som skickar poster i batcher till Kinesis-dataströmmen.
Streamingapplikationen lämnades igång i 15 minuter och den konfigurerades med en batch_interval på 1 minut, vilket är det tidsintervall med vilket strömmande data kommer att delas upp i batcher. Följande tabell sammanfattar de relevanta faktorerna.
| fördelning | Klusterkapacitetsnoder | Antal exekutörer | Exekutors minne | Batchfönster | Satsstorlek | VIN-storlek |
| 17 |
1 primär (m5.xlarge), 3 kärnor (m5.2xlarge) |
6 | 9 GiB | 60 sekunder | 900 VIN/API-anrop. | 5 byte / VIN |
Följande diagram visar Kinesis Data Streams-mått PutRecords (i blått) och GetRecords (i orange) aggregerat med 1-minutersperiod och med hjälp av statistiken SUM. Den första grafen visar måtten i byte, som toppar 6.8 MB per minut. Den andra grafen visar mätvärdet i rekordantal med en topp på 85,000 XNUMX poster per minut.
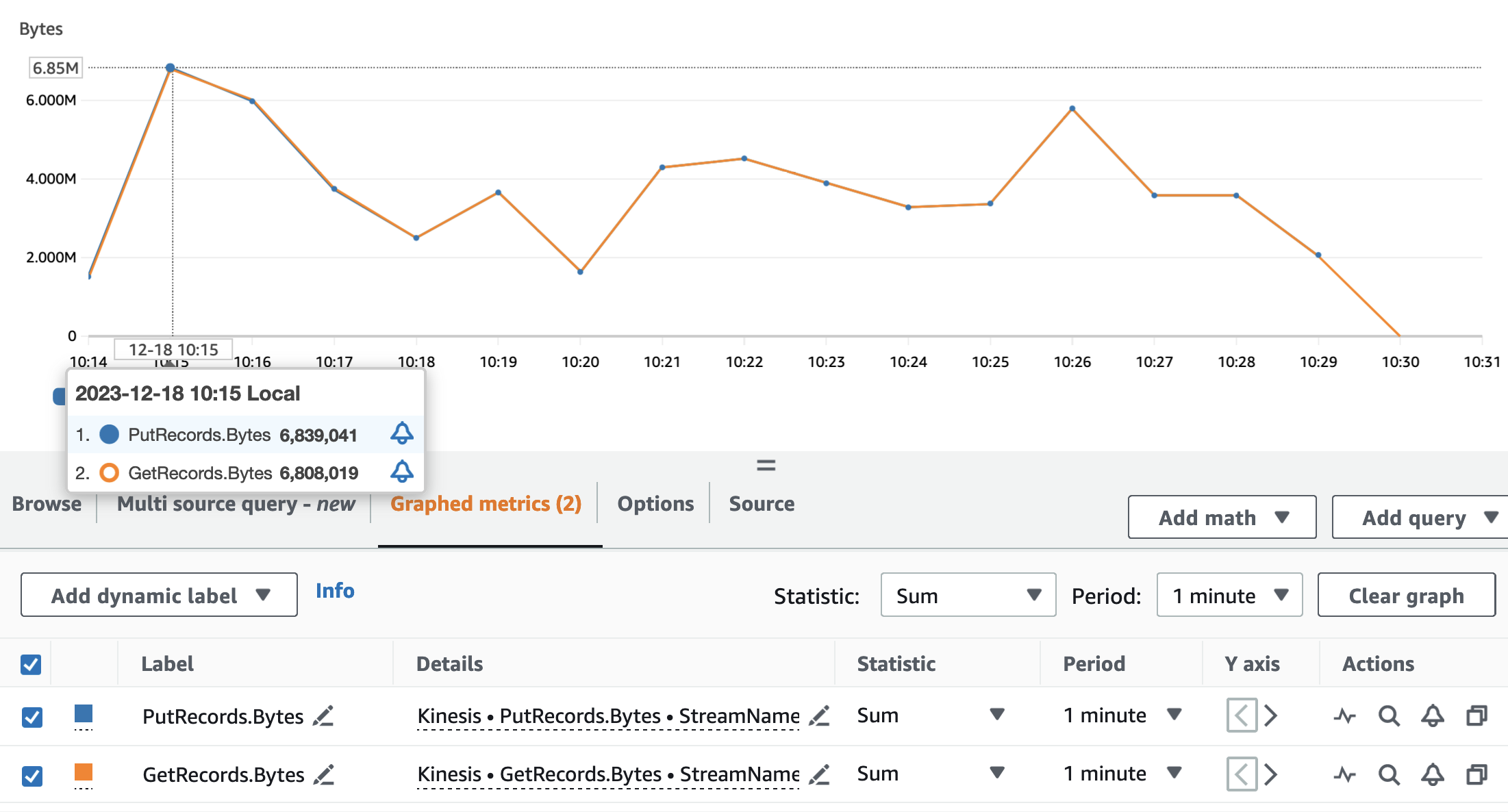

Vi kan se att måtten GetRecords och PutRecords har överlappande värden för nästan hela programmets körning. Det betyder att streamingapplikationen kunde hänga med i strömmen.
Därefter analyserar vi relevant Lambda-mått för pseudonymiseringstjänsten: Invocations, ConcurrentExecutionsoch Duration.
Följande graf visar Invocations metrisk, med statistiken SUM (i orange) och RUNNING SUM i blått.
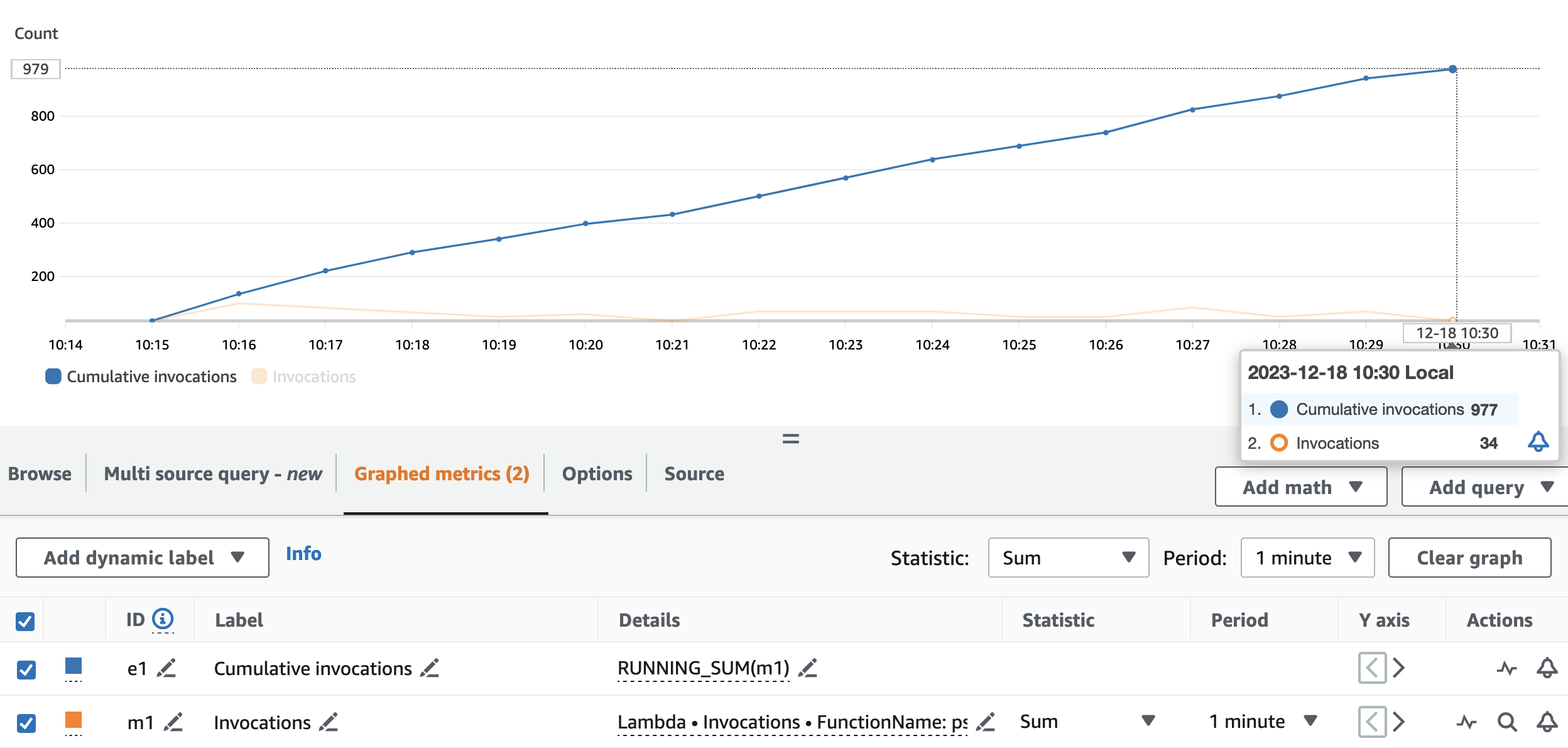
Genom att beräkna skillnaden mellan start- och slutpunkten för de kumulativa anropen kan vi extrahera hur många anrop som gjordes under körningen. Mer specifikt, på 15 minuter, anropade streamingapplikationen pseudonymiserings-API:et 977 gånger, vilket är cirka 65 samtal per minut.
Följande graf visar totalen ConcurrentExecutions metrisk, med statistiken MAX i blått.
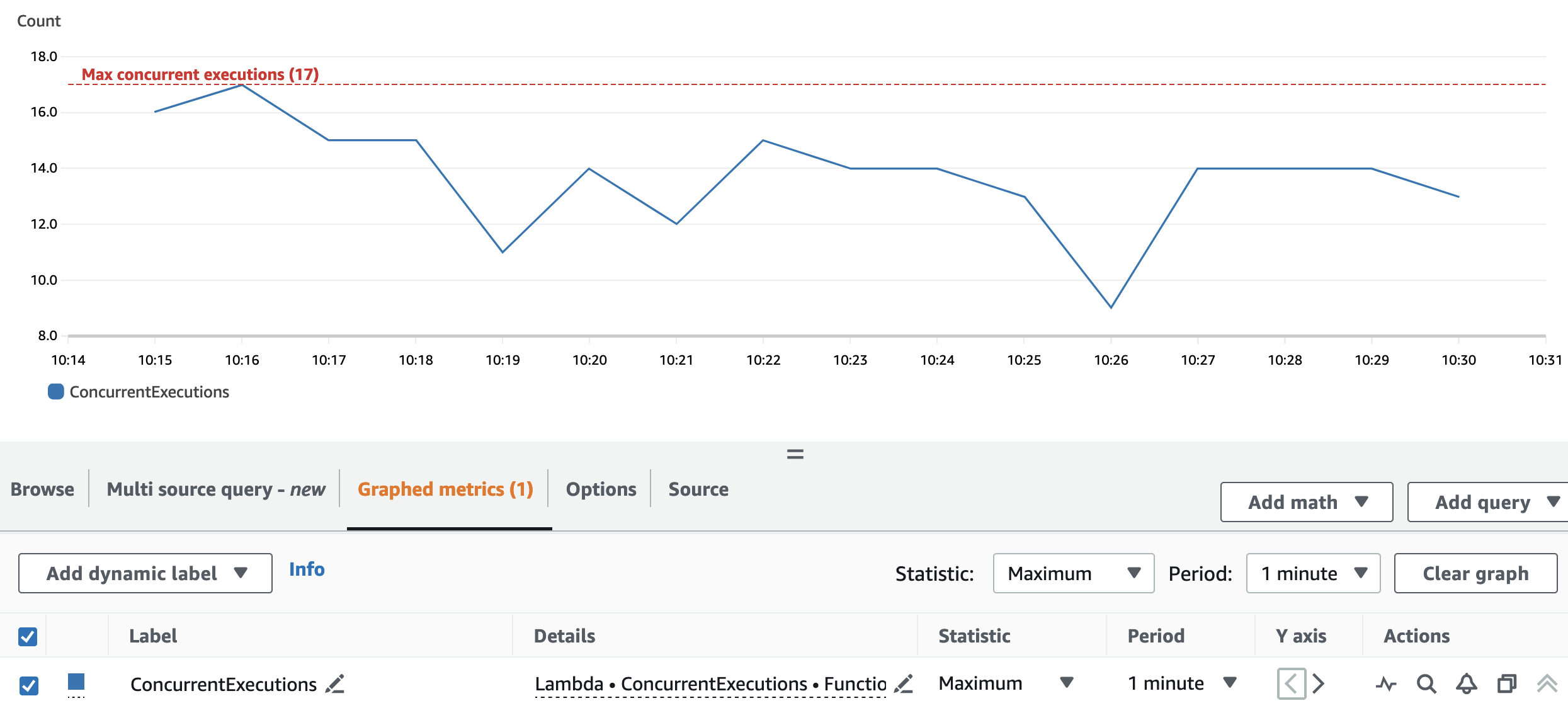
Ompartitionen och klusterkonfigurationen gör att applikationen kan behandla alla Spark RDD-partitioner parallellt. Som ett resultat är de samtidiga körningarna av Lambda-funktionen alltid lika med eller under repartitionsnumret, vilket är 17.
För att undvika strypning, se till att mängden Spark-uppgifter som kan bearbetas parallellt inte överstiger lambdafunktionens samtidighetsgräns. För denna aspekt gäller samma förslag som för batchanvändningsfallet.
Följande graf visar Lambda Duration metrisk, med statistiken AVG i blått och MAX i orange.
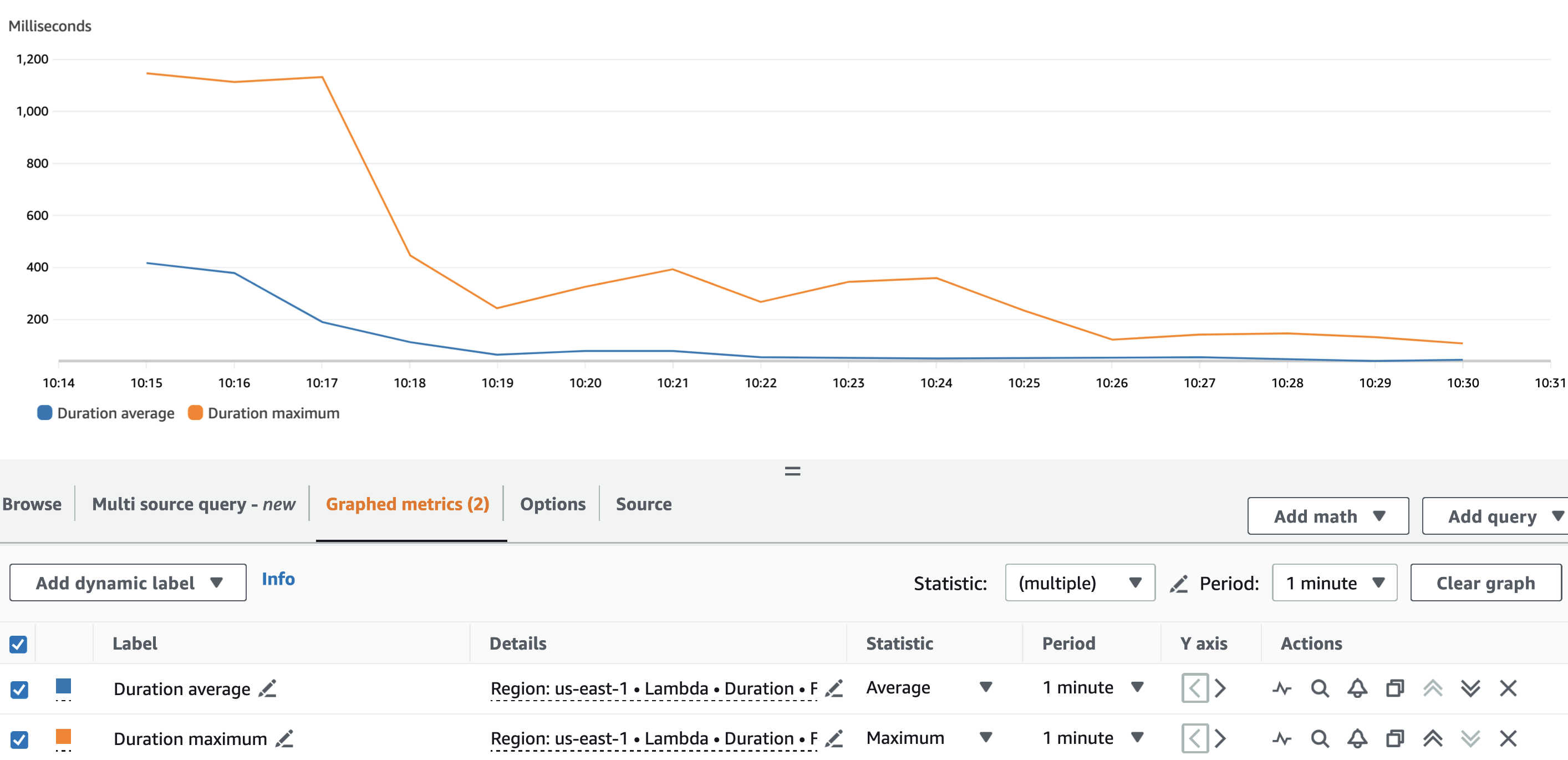
Som väntat, förutom Lambdafunktionens kallstart, var pseudonymiseringsfunktionens genomsnittliga varaktighet mer eller mindre konstant under hela körningen. Detta eftersom batch_size värde, som definierar antalet VIN att pseudonymisera per samtal, sattes till och förblev konstant på 900.
Intagshastigheten för Kinesis-dataströmmen och konsumtionshastigheten för vår streamingapplikation är faktorer som påverkar antalet API-anrop som görs mot pseudonymiseringstjänsten och därmed den relaterade kostnaden.
Följande graf visar Lambda Invocations metrisk, med statistiken SUM i orange och Kinesis dataströmmar GetRecords.Records metrisk, med statistiken SUM i blått. Vi kan se att det finns korrelation mellan mängden poster som hämtas från strömmen per minut och mängden lambdafunktionsanrop, vilket påverkar kostnaden för strömningskörningen.

Utöver batch_interval, kan vi styra streamingapplikationens konsumtionshastighet med hjälp av Spark-strömningsegenskaper tycka om spark.streaming.receiver.maxRate och spark.streaming.blockInterval. För mer information, se Spark Streaming + Kinesis Integration och Programmeringsguide för Spark Streaming.
Slutsats
Det kan vara svårt att navigera genom reglerna och förordningarna i dataskyddslagar. Pseudonymisering av PII-attribut är en av många punkter att ta hänsyn till när du hanterar känslig data.
I denna tvådelade serie utforskade vi hur du kan bygga och konsumera en pseudonymiseringstjänst med hjälp av olika AWS-tjänster med funktioner som hjälper dig att bygga en robust dataplattform. I del 1, byggde vi grunden genom att visa hur man bygger en pseudonymiseringstjänst. I det här inlägget visade vi upp de olika mönstren för att konsumera pseudonymiseringstjänsten på ett kostnadseffektivt och effektivt sätt. Kolla in GitHub förvar för ytterligare konsumtionsmönster.
Om författarna
 Edvin Hallvaxhiu är en Senior Global Security Architect med AWS Professional Services och brinner för cybersäkerhet och automation. Han hjälper kunder att bygga säkra och kompatibla lösningar i molnet. Utanför jobbet gillar han att resa och sporta.
Edvin Hallvaxhiu är en Senior Global Security Architect med AWS Professional Services och brinner för cybersäkerhet och automation. Han hjälper kunder att bygga säkra och kompatibla lösningar i molnet. Utanför jobbet gillar han att resa och sporta.
 Rahul Shaurya är en huvudsaklig Big Data Architect med AWS Professional Services. Han hjälper och arbetar nära kunder som bygger dataplattformar och analytiska applikationer på AWS. Utanför jobbet älskar Rahul att ta långa promenader med sin hund Barney.
Rahul Shaurya är en huvudsaklig Big Data Architect med AWS Professional Services. Han hjälper och arbetar nära kunder som bygger dataplattformar och analytiska applikationer på AWS. Utanför jobbet älskar Rahul att ta långa promenader med sin hund Barney.
 Andrea Montanari är Senior Big Data Architect med AWS Professional Services. Han stödjer aktivt kunder och partners i att bygga analytiska lösningar i stor skala på AWS.
Andrea Montanari är Senior Big Data Architect med AWS Professional Services. Han stödjer aktivt kunder och partners i att bygga analytiska lösningar i stor skala på AWS.
 María Guerra är en Big Data Architect med AWS Professional Services. Maria har en bakgrund inom dataanalys och maskinteknik. Hon hjälper kunder att utforma och utveckla datarelaterade arbetsbelastningar i molnet.
María Guerra är en Big Data Architect med AWS Professional Services. Maria har en bakgrund inom dataanalys och maskinteknik. Hon hjälper kunder att utforma och utveckla datarelaterade arbetsbelastningar i molnet.
 Pushpraj Singh är Senior Data Architect med AWS Professional Services. Han brinner för data- och DevOps-teknik. Han hjälper kunder att bygga datadrivna applikationer i stor skala.
Pushpraj Singh är Senior Data Architect med AWS Professional Services. Han brinner för data- och DevOps-teknik. Han hjälper kunder att bygga datadrivna applikationer i stor skala.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/build-a-pseudonymization-service-on-aws-to-protect-sensitive-data-part-2/

