För att bygga en generativ AI-applikation är det absolut nödvändigt att berika de stora språkmodellerna (LLM) med ny data. Det är här tekniken Retrieval Augmented Generation (RAG) kommer in. RAG är en maskininlärningsarkitektur (ML) som använder externa dokument (som Wikipedia) för att utöka sin kunskap och uppnå toppmoderna resultat på kunskapsintensiva uppgifter . För att inta dessa externa datakällor har Vector-databaser utvecklats, som kan lagra vektorinbäddningar av datakällan och möjliggöra likhetssökningar.
I det här inlägget visar vi hur man bygger en RAG-extrakt, transformerar och laddar (ETL) intagspipeline för att mata in stora mängder data till en Amazon OpenSearch Service kluster och användning Amazon Relational Database Service (Amazon RDS) för PostgreSQL med tillägget pgvector som ett vektordatalager. Varje tjänst implementerar k-närmaste granne (k-NN) eller ungefärliga närmaste granne (ANN) algoritmer och avståndsmått för att beräkna likhet. Vi introducerar integrationen av Stråle in i RAG-mekanismen för kontextuell dokumenthämtning. Ray är ett distribuerat datorbibliotek med öppen källkod, Python, allmänt ändamål. Det tillåter distribuerad databehandling för att generera och lagra inbäddningar för en stor mängd data, parallellt över flera GPU:er. Vi använder ett Ray-kluster med dessa GPU:er för att köra parallell intagning och fråga för varje tjänst.
I det här experimentet försöker vi analysera följande aspekter för OpenSearch Service och tillägget pgvector på Amazon RDS:
- Som en vektorbutik, möjligheten att skala och hantera en stor datamängd med tiotals miljoner poster för RAG
- Möjliga flaskhalsar i intag pipeline för RAG
- Hur man uppnår optimal prestanda i inmatnings- och frågehämtningstider för OpenSearch Service och Amazon RDS
För att förstå mer om vektordatalagrar och deras roll i att bygga generativa AI-applikationer, se Rollen för vektordatalager i generativa AI-applikationer.
Översikt över OpenSearch Service
OpenSearch Service är en hanterad tjänst för säker analys, sökning och indexering av affärs- och verksamhetsdata. OpenSearch Service stöder petabyte-skala data med möjligheten att skapa flera index på text och vektordata. Med optimerad konfiguration siktar den på hög återkallelse för frågorna. OpenSearch Service stöder ANN såväl som exakt k-NN-sökning. OpenSearch Service stöder ett urval av algoritmer från NMSLIB, FAISSoch Lucene bibliotek för att driva k-NN-sökningen. Vi skapade ANN-indexet för OpenSearch med algoritmen Hierarchical Navigable Small World (HNSW) eftersom det anses vara en bättre sökmetod för stora datamängder. För mer information om val av indexalgoritm, se Välj k-NN-algoritmen för ditt användningsfall i miljardskala med OpenSearch.
Översikt över Amazon RDS för PostgreSQL med pgvector
Tillägget pgvector lägger till en vektorlikhetssökning med öppen källkod till PostgreSQL. Genom att använda tillägget pgvector kan PostgreSQL utföra likhetssökningar på vektorinbäddningar, vilket ger företag en snabb och skicklig lösning. pgvector tillhandahåller två typer av vektorlikhetssökningar: exakt närmaste granne, vilket resulterar med 100 % återkallelse, och ungefärlig närmaste granne (ANN), som ger bättre prestanda än exakt sökning med en avvägning vid återkallelse. För sökningar över ett index kan du välja hur många centra som ska användas i sökningen, med fler centra som ger bättre minne med en avvägning av prestanda.
Lösningsöversikt
Följande diagram illustrerar lösningsarkitekturen.

Låt oss titta på nyckelkomponenterna mer i detalj.
dataset
Vi använder OSCAR-data som vår korpus och SQUAD-datauppsättningen för att ge exempel på frågor. Dessa datamängder konverteras först till Parquet-filer. Sedan använder vi ett Ray-kluster för att konvertera Parkettdata till inbäddningar. De skapade inbäddningarna matas in till OpenSearch Service och Amazon RDS med pgvector.
OSCAR (Open Super-large Crawled Aggregated corpus) är en enorm flerspråkig korpus som erhålls genom språkklassificering och filtrering av Vanlig genomsökning korpus med hjälp av ogolikt arkitektur. Data distribueras efter språk i både original och deduplicerad form. Oscar Corpus datauppsättning är cirka 609 miljoner poster och tar upp cirka 4.5 TB som råa JSONL-filer. JSONL-filerna konverteras sedan till parkettformat, vilket minimerar den totala storleken till 1.8 TB. Vi skalade ner datasetet ytterligare till 25 miljoner poster för att spara tid under intag.
SQuAD (Stanford Question Answering Dataset) är en datauppsättning för läsförståelse som består av frågor som ställs av publikarbetare på en uppsättning Wikipedia-artiklar, där svaret på varje fråga är ett textsegment, eller span, från motsvarande läspassage, annars kan frågan vara obesvarbar. Vi använder TRUPP, licensierad som CC-BY-SA 4.0, för att ge exempel på frågor. Den har cirka 100,000 50,000 frågor med över XNUMX XNUMX obesvarade frågor skrivna av folkmassaarbetare för att se ut som svarbara.
Strålkluster för intag och skapande av vektorinbäddningar
I våra tester fann vi att GPU:erna har störst inverkan på prestanda när man skapar inbäddningarna. Därför bestämde vi oss för att använda ett Ray-kluster för att konvertera vår råtext och skapa inbäddningarna. Stråle är ett unified compute-ramverk med öppen källkod som gör det möjligt för ML-ingenjörer och Python-utvecklare att skala Python-applikationer och accelerera ML-arbetsbelastningar. Vårt kluster bestod av 5 g4dn.12xlarge Amazon Elastic Compute Cloud (Amazon EC2) instanser. Varje instans konfigurerades med 4 NVIDIA T4 Tensor Core GPU:er, 48 vCPU och 192 GiB minne. För våra textposter slutade vi med att vi delade var och en i 1,000 100 bitar med en överlappning på 200 bitar. Detta bryter ut till cirka XNUMX per rekord. För modellen som användes för att skapa inbäddningar, slog vi oss till all-mpnet-base-v2 för att skapa ett 768-dimensionellt vektorrum.
Infrastrukturinstallation
Vi använde följande RDS-instanstyper och OpenSearch-tjänstklusterkonfigurationer för att konfigurera vår infrastruktur.
Följande egenskaper är våra RDS-instanstyper:
- Instanstyp: db.r7g.12xlarge
- Tilldelad lagring: 20 TB
- Multi-AZ: Sant
- Lagring krypterad: Sant
- Aktivera prestandainsikter: sant
- Performance Insight retention: 7 dagar
- Lagringstyp: gp3
- Avsatt IOPS: 64,000 XNUMX
- Indextyp: IVF
- Antal listor: 5,000 XNUMX
- Avståndsfunktion: L2
Följande är våra OpenSearch Service-klusteregenskaper:
- Version: 2.5
- Datanoder: 10
- Datanodinstanstyp: r6g.4xlarge
- Primära noder: 3
- Typ av primär nodinstans: r6g.xlarge
- Index: HNSW-motor:
nmslib - Uppdateringsintervall: 30 sekunder
ef_construction: 256- m: 16
- Avståndsfunktion: L2
Vi använde stora konfigurationer för både OpenSearch Service-klustret och RDS-instanser för att undvika prestandaflaskhalsar.
Vi distribuerar lösningen med en AWS Cloud Development Kit (AWS CDK) stapel, som beskrivs i följande avsnitt.
Distribuera AWS CDK-stacken
AWS CDK-stacken låter oss välja OpenSearch Service eller Amazon RDS för inmatning av data.
Förhandskrav
Innan du fortsätter med installationen, under cdk, bin, src.tc, ändra de booleska värdena för Amazon RDS och OpenSearch Service till antingen sant eller falskt beroende på dina önskemål.
Du behöver också en tjänstekopplad AWS identitets- och åtkomsthantering (IAM) roll för OpenSearch Service-domänen. För mer information, se Amazon OpenSearch Service Construct Library. Du kan också köra följande kommando för att skapa rollen:
Denna AWS CDK-stack kommer att distribuera följande infrastruktur:
- En VPC
- En hoppvärd (inuti VPC)
- Ett OpenSearch Service-kluster (om du använder OpenSearch-tjänsten för inmatning)
- En RDS-instans (om du använder Amazon RDS för intag)
- An AWS systemchef dokument för distribution av Ray-klustret
- An Amazon enkel lagringstjänst (Amazon S3) skopa
- An AWS-lim jobb för att konvertera OSCAR-datauppsättningen JSONL-filer till Parkett-filer
- amazoncloudwatch instrumentpaneler
Ladda ner data
Kör följande kommandon från hoppvärden:
Innan du klona git-repo, se till att du har en Hugging Face-profil och tillgång till OSCAR-datakorpusen. Du måste använda användarnamnet och lösenordet för att klona OSCAR-data:
Konvertera JSONL-filer till Parkett
AWS CDK-stacken skapade AWS Glue ETL-jobbet oscar-jsonl-parquet för att konvertera OSCAR-data från JSONL till parkettformat.
När du kör oscar-jsonl-parquet jobb ska filerna i parkettformat finnas tillgängliga under parkettmappen i S3-hinken.
Ladda ner frågorna
Ladda ner frågedata från din hoppvärd och ladda upp den till din S3-bucket:
Ställ in Ray-klustret
Som en del av AWS CDK-stackdistributionen skapade vi ett System Manager-dokument som heter CreateRayCluster.
Utför följande steg för att köra dokumentet:
- På System Manager-konsolen, under Dokument välj i navigeringsfönstret Ägs av mig.
- Öppna
CreateRayClusterdokument. - Välja Körning.
Kommandosidan kör kommer att ha standardvärdena ifyllda för klustret.
Standardkonfigurationen kräver 5 g4dn.12xlarge. Se till att ditt konto har gränser för att stödja detta. Den relevanta servicegränsen är Running On-Demand G- och VT-instanser. Standard för detta är 64, men denna konfiguration kräver 240 processorer.
- När du har granskat klusterkonfigurationen väljer du hoppvärden som mål för körkommandot.
Detta kommando kommer att utföra följande steg:
- Kopiera Ray-klusterfilerna
- Ställ in Ray-klustret
- Ställ in OpenSearch Service-index
- Ställ in RDS-tabellerna
Du kan övervaka utmatningen av kommandona på Systems Manager-konsolen. Denna process tar 10–15 minuter för den första lanseringen.
Kör förtäring
Från hoppvärden, anslut till Ray-klustret:
Första gången du ansluter till värden installerar du kraven. Dessa filer bör redan finnas på huvudnoden.
För någon av intagsmetoderna, om du får ett fel som följande, är det relaterat till utgångna autentiseringsuppgifter. Den aktuella lösningen (när detta skrivs) är att placera autentiseringsfiler i Ray-huvudnoden. För att undvika säkerhetsrisker, använd inte IAM-användare för autentisering när du utvecklar specialbyggd programvara eller arbetar med riktig data. Använd istället federation med en identitetsleverantör som t.ex AWS IAM Identity Center (efterträdare till AWS Single Sign-On).
Vanligtvis lagras referenserna i filen ~/.aws/credentials på Linux- och macOS-system, och %USERPROFILE%.awscredentials på Windows, men dessa är kortsiktiga referenser med en sessionstoken. Du kan inte heller åsidosätta standardinloggningsfilen, så du måste skapa långsiktiga autentiseringsuppgifter utan sessionstoken med en ny IAM-användare.
För att skapa långsiktiga autentiseringsuppgifter måste du generera en AWS-åtkomstnyckel och AWS-hemlig åtkomstnyckel. Du kan göra det från IAM-konsolen. För instruktioner, se Autentisera med IAM-användaruppgifter.
När du har skapat nycklarna ansluter du till hoppvärden med hjälp av Sessionshanteraren, en funktion hos System Manager, och kör följande kommando:
Nu kan du köra inmatningsstegen igen.
Ta in data i OpenSearch Service
Om du använder OpenSearch-tjänsten, kör följande skript för att mata in filerna:
När det är klart kör du skriptet som kör simulerade frågor:
Mata in data i Amazon RDS
Om du använder Amazon RDS, kör följande skript för att mata in filerna:
När det är klart, se till att köra ett helt vakuum på RDS-instansen.
Kör sedan följande skript för att köra simulerade frågor:
Ställ in Ray-instrumentpanelen
Innan du ställer in Ray-instrumentpanelen bör du installera AWS-kommandoradsgränssnitt (AWS CLI) på din lokala dator. För instruktioner, se Installera eller uppdatera den senaste versionen av AWS CLI.
Utför följande steg för att konfigurera instrumentpanelen:
- installera Session Manager-plugin för AWS CLI.
- I Isengard-kontot kopierar du de tillfälliga referenserna för bash/zsh och kör i din lokala terminal.
- Skapa en session.sh-fil på din maskin och kopiera följande innehåll till filen:
- Ändra katalogen till där filen session.sh är lagrad.
- Kör kommandot
Chmod +xför att ge körbar behörighet till filen. - Kör följande kommando:
Till exempel:
Du kommer att se ett meddelande som följande:
Öppna en ny flik i din webbläsare och ange localhost:8265.
Du kommer att se Ray-instrumentpanelen och statistik över jobben och klustret som körs. Du kan spåra mätvärden härifrån.
Du kan till exempel använda Ray-instrumentpanelen för att observera belastningen på klustret. Som visas i följande skärmdump, under intag, körs GPU:erna nästan 100 % utnyttjande.
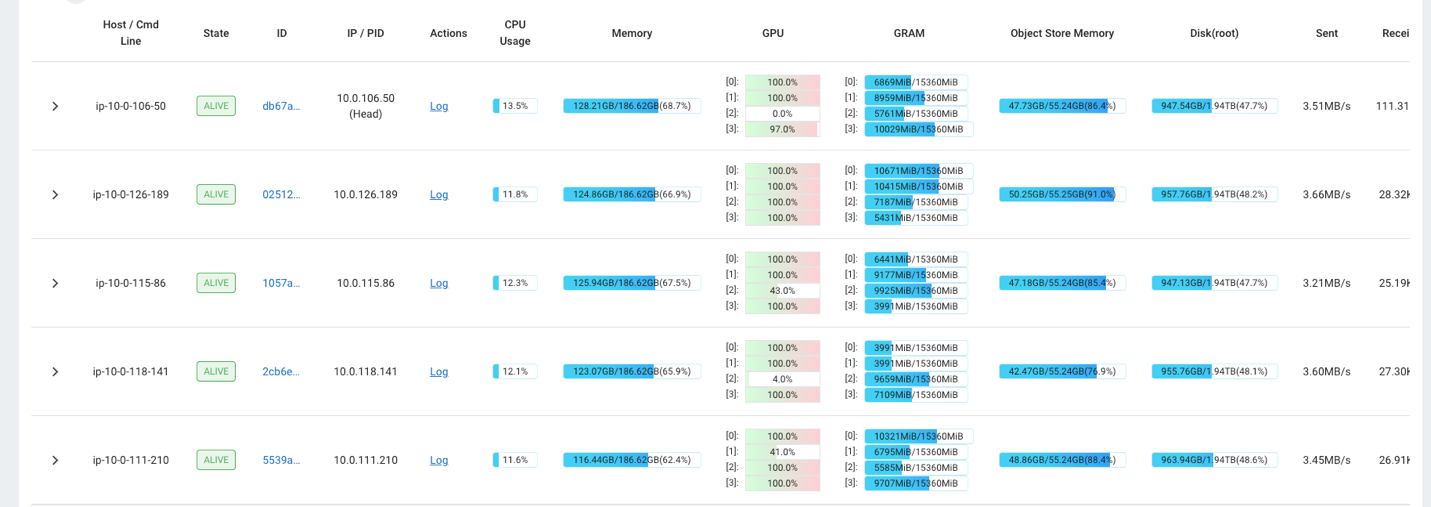
Du kan också använda RAG_Benchmarks CloudWatch-instrumentpanelen för att se intagsfrekvensen och svarstider för frågor.
Lösningens töjbarhet
Du kan utöka den här lösningen till att ansluta andra AWS eller tredjeparts vektorbutiker. För varje nytt vektorlager måste du skapa skript för att konfigurera datalagret såväl som för inmatning av data. Resten av rörledningen kan återanvändas vid behov.
Slutsats
I det här inlägget delade vi en ETL-pipeline som du kan använda för att lägga vektoriserad RAG-data i både OpenSearch Service och Amazon RDS med tillägget pgvector som vektordatalager. Lösningen använde ett Ray-kluster för att tillhandahålla den nödvändiga parallelliteten för att få in en stor datakorpus. Du kan använda denna metod för att integrera valfri vektordatabas för att bygga RAG-pipelines.
Om författarna
 Randy DeFauw är Senior Principal Solutions Architect på AWS. Han har en MSEE från University of Michigan, där han arbetade med datorseende för autonoma fordon. Han har också en MBA från Colorado State University. Randy har haft en mängd olika positioner inom teknikområdet, allt från mjukvaruteknik till produkthantering. Han gick in i big data-utrymmet 2013 och fortsätter att utforska det området. Han arbetar aktivt med projekt inom ML-området och har presenterat på ett flertal konferenser, inklusive Strata och GlueCon.
Randy DeFauw är Senior Principal Solutions Architect på AWS. Han har en MSEE från University of Michigan, där han arbetade med datorseende för autonoma fordon. Han har också en MBA från Colorado State University. Randy har haft en mängd olika positioner inom teknikområdet, allt från mjukvaruteknik till produkthantering. Han gick in i big data-utrymmet 2013 och fortsätter att utforska det området. Han arbetar aktivt med projekt inom ML-området och har presenterat på ett flertal konferenser, inklusive Strata och GlueCon.
 David Christian är en Principal Solutions Architect baserad i södra Kalifornien. Han har sin kandidatexamen i informationssäkerhet och en passion för automation. Hans fokusområden är DevOps kultur och transformation, infrastruktur som kod och resiliens. Innan han började på AWS hade han roller inom säkerhet, DevOps och systemteknik, där han hanterade storskaliga privata och offentliga molnmiljöer.
David Christian är en Principal Solutions Architect baserad i södra Kalifornien. Han har sin kandidatexamen i informationssäkerhet och en passion för automation. Hans fokusområden är DevOps kultur och transformation, infrastruktur som kod och resiliens. Innan han började på AWS hade han roller inom säkerhet, DevOps och systemteknik, där han hanterade storskaliga privata och offentliga molnmiljöer.
 Prachi Kulkarni är Senior Solutions Architect på AWS. Hennes specialisering är maskininlärning och hon arbetar aktivt med att designa lösningar med hjälp av olika AWS ML-, big data- och analyserbjudanden. Prachi har erfarenhet inom flera områden, inklusive hälsovård, förmåner, detaljhandel och utbildning, och har arbetat i en rad olika positioner inom produktutveckling och arkitektur, management och kundframgång.
Prachi Kulkarni är Senior Solutions Architect på AWS. Hennes specialisering är maskininlärning och hon arbetar aktivt med att designa lösningar med hjälp av olika AWS ML-, big data- och analyserbjudanden. Prachi har erfarenhet inom flera områden, inklusive hälsovård, förmåner, detaljhandel och utbildning, och har arbetat i en rad olika positioner inom produktutveckling och arkitektur, management och kundframgång.
 Richa Gupta är lösningsarkitekt på AWS. Hon brinner för att designa helhetslösningar för kunder. Hennes specialisering är maskininlärning och hur det kan användas för att bygga nya lösningar som leder till operationell excellens och driver affärsintäkter. Innan hon började på AWS arbetade hon i egenskap av mjukvaruingenjör och lösningsarkitekt och byggde lösningar för stora telekomoperatörer. Utanför jobbet gillar hon att utforska nya platser och älskar äventyrliga aktiviteter.
Richa Gupta är lösningsarkitekt på AWS. Hon brinner för att designa helhetslösningar för kunder. Hennes specialisering är maskininlärning och hur det kan användas för att bygga nya lösningar som leder till operationell excellens och driver affärsintäkter. Innan hon började på AWS arbetade hon i egenskap av mjukvaruingenjör och lösningsarkitekt och byggde lösningar för stora telekomoperatörer. Utanför jobbet gillar hon att utforska nya platser och älskar äventyrliga aktiviteter.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

