It took me a long time to realise that search is the biggest problem in NLP. Just look at Google, Amazon and Bing. These are multi-billion dollar businesses possible only due to their powerful search engines.
My initial thoughts on search were centered around unsupervised ML, but I participated in Microsoft Hackathon 2018 for Bing and came to know the various ways a search engine can be made with deep learning.
The following topics will be covered in this article:
Do you find this in-depth technical education about NLP applications to be useful? Subscribe below to be updated when we release new relevant content.
Classical search engines
The process of search can be broken down into 4 steps:
- Query autocompletion — Suggest query based on first characters typed
- Query filtering — Token removal, stemming and lowering
- Query augmentation — Adding synonyms and acronym contraction/expansion
- Document scoring — Score(document | query) as per scoring mechanism which is mostly BM25
Now without spending time on explaining these steps, I will start discussing the shortcomings of a classical search engine such as Lucene which is the most popular search engine.
Problem 1: Token matching
Imagine I am interested in finding the best book on Backpropagation. As per the user reviews, Deep Learning by Ian Goodfellow et al. is considered to be the best on the topic and others surrounding it. But there is a complete mismatch of words between the Query: Backpropagation and Document title: Deep learning. These are the results of amazon.com. The deep learning book isn’t there!

Result for query ‘Backpropagation’
Although if I search for deep learning, I get the book at the top.

Result for query ‘deep learning’
This is the problem of hard token matching.
Problem 2: Contextualisation
The above example works with query deep learning. What if I like reading books with practical examples instead of just reading the theory. This brings us to the topic of contextual search. In that case, these books were perfect for me. Isn’t it?

A practical book for learning ‘neural network’

Another practical book for learning ‘neural network’
And why thy hell I see books on NLP (Neuro-linguistic programming) when I search NLP! Contextual search can solve this — If the search engine knows that I buy books on computer science, it would have shown me books on natural language processing instead.

And I get these when I search GAN. Again an issue of non-personalisation.

Problem 3: Query misunderstanding
Query: x’s influence on y First scholarly article result: a’s influence on x
i.e Rather than finding Bernhard’s influence on academic, the first paper is about Herbart’s influence on Bernhard.

Searched on 14 Nov 2019
Because the token match engine doesn’t regard for the sequence of words, it can throw wrong results. 😞
Although, Google’s similar query suggestion is better!

Searched on 14 Nov 2019
Problem 4: Image search
Last but not the least, the only way we can search for images by text is by generating metadata of all the images with descriptions or tags — which is practically impossible.
What is the effect on our metric?
Because of this, our metric gets affected adversely.
Hard token match → LESS RECALL
Absence of context → LESS PRECISION
Deep learning for search 🔥
Now that you have understood the problems associated with just token matching, we can discuss how to do search using deep learning. My thoughts are based on the book Deep learning for search by Tommaso Teofili.
Solution 1: Synonym generation
The problem of token match can be solved by augmenting the words with synonym words through a custom dictionary in Elasticsearch. For this, I have to manually figure out the words which require synonyms and then find their synonyms too. This is easy to start with but difficult to maintain. Instead, we can leverage deep learning over here! First we find the POS(Part of speech) using a library like Spacy and get synonyms for words which have POS(Part of speech) as noun, verb or adjective. We have to keep a cutoff of cosine similarity for selecting similar words to avoid adding too many or irrelevant synonyms.
Having synonym augmentation can help us improve recall but can also decrease precision 😅
Caution ❌
Over here we need to be careful of not augmenting certain words. Surprisingly the nearest words for ‘good’ as per word2vec are ‘bad’ and ‘poor’. This can alter the results in certain cases. 😅
You can try out on https://projector.tensorflow.org
The nearest word for ‘amazing’ as per word2vec is ‘spider’ which might be coming from The Amazing Spider-Man movie. This can lead to some surprising results
Solution 2: Query autocompletion
Why not help the user complete the query right when he is typing such that the completed query will not throw empty result! Elasticsearch also has query autocompletion feature but it is a finite automata. If you type a character sequence which was not seen in the index, it will not show results. While in the case of a language model(LM), the generation is not finite. (Although LM generation might fail for longer queries if the model is trained for shorter sequences.)
Ability to autocomplete queries such that the result is not empty can dramatically alter the user experience and avoid churnout☺️
Trick: Remove those queries from training which return empty results since there is no point of suggesting queries which will lead to no result.
Solution 3: Alternate query generation
If we have a log of queries from user sessions, we can train a generative model to generate (next query | current query). The hypothesis being that all the queries in a session are similar to each other. The logs can be like this.
- Artificial intelligence
- Tensorflow
- Neural networks
- …
Training data (x, y) (Artificial intelligence, Tensorflow) (Tensorflow, Neural networks)
Query generation can help us suggest relevant queries by understanding the buying intent of user.
Solution 4: Using word and document embeddings
Once we have the query entered by the user, instead of representing it in one-hot or TF-IDF normalised form, we can vectorise words, sentences and documents using some approaches.
- Simple embedding average
- Weighted embedding average by multiplying with IDF values
- Sentence embedding using a model like infersent, USE(Universal sentence encoder), sentence-bert
- seq2seq autoencoder
This can help us represent all the tokens in a semantic and compressed form of a vector of fixed size irrespective of the vocabulary size. This requires a one-time heavy overhead of vectorising using the model but all the searches later will be vector search in n-dimension. The current state of the art in vector search is&nb
sp;milvus. For approximate nearest neighbour you can use flann and annoy.
Solution 5: Contextualisation
Factors to be considered by the search engine for contextualisation/personalisation
- User history — Interests from his past search and if he searched the same in past what did he click
- User geography — Searching word ‘president’ gives me ‘Ram Nath Kovind’ → the current president of India
- Temporal changes in information — The result of query ‘president’ will change with time
User history can be used by encoding each click as a fixed vector and generate score(document | history+query)
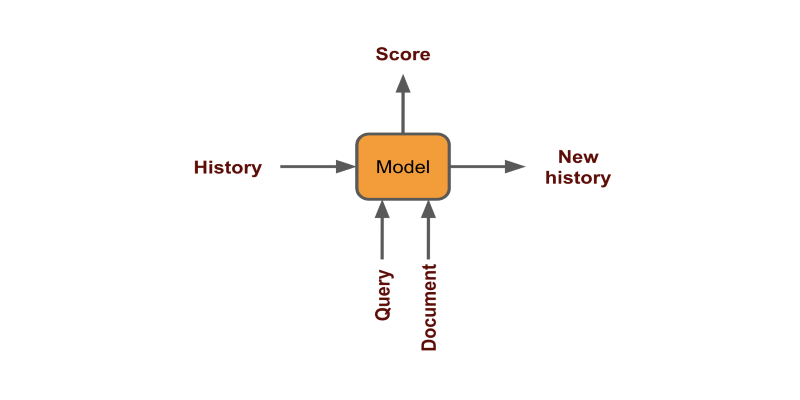
Geography and temporal can be taken care either by filtering or adding them as features while training the model.
Personalisation allows us to serve human-level suggestions to the user which can help us improve the conversion.
Solution 6: Learning to rank
Because of the flaws of token matching in TF-IDF scheme, we actually need a layer which can re-rank the results. The scheme has high bias for rare words and also doesn’t account for conversion possibility of an article. If we have a log of user queries and what they clicked from the search results, we can train the model to rank documents. The data will look like this. (x, y) (Artificial intelligence, book 2 title) (Tensorflow, book 1 title) (Neural networks, book 4 title) Next time we want to show results, we first get the top x results from a cheap process of token match through TF-IDF/BM25, mostly through Elasticsearch, and then generate a score for all pairs. (x, y)
- (query, title 1) → score 1
- (query, title 2) → score 2
- …
Then we sort the titles by the score and show top results. You can find an implementation of this using BERT in my github.

BERT with NSP head
We can define the learning to rank problem as BERT NextSentencePrediction problem — aka entailment problem.
Solution 7: Ensemble
In most cases, it’s advantageous to leverage both the approaches. The book mentions that using a combined score of wordvector and BM25 works best.

From ‘Deep learning for search’
Ensemble allows us to exploit best of both the approaches-hard token match + semantics.
Solution 8: Multilingual search
Approach 1

In certain cases when the application is across the geography, the language of user can be different from the document. Such a search is not possible with classical search approach as tokens of different languages cannot match. This requires the help of machine translation with deep learning.
- Detect the language of user query (ex. French)
- Translate query to all languages for which we have the documents (French to English, German and Spanish)
- Search documents
- Translate all top-scoring documents to user’s language (English, German and Spanish to French)
Approach 2
Instead we can use a multilingual sentence encoder to represent text from any language to similar vectors. Let’s explore this approach in detail.
Multilingual Universal Sentence Encoder
I am taking these components for doing the POC:
- Model — Multilingual Universal Sentence Encoder
- Vector search — FAISS
- Data — Quora question pair from kaggle
You can read more about USE in this paper. It supports 16 languages.
STEP 1. LOAD DATA
Let’s first read the data. Because the quora dataset is huge and takes a lot of time, we will take only 1% of the data. This will take around 3 minutes for encoding and indexing. It will have 4000 questions.
df = pd.read_csv('quora-question-pairs/train.csv')
df = df.sample(frac=0.01, random_state=1)
df.dropna(inplace=True)
questions = df.question1.values
STEP 2. CREATE ENCODER
Let’s make encoder classes that load the model and have an encode method. I have created classes for different models which you can use. All models work with English and only USE multilingual works with other languages.
USE encodes text in a fixed vector of size 512.
I am using TFHub for USE and Flair for BERT for loading the models.
class TFEncoder(metaclass=ABCMeta): """Base encoder to be used for all encoders.""" def __init__(self, model_path:str): self.model = hub.load(model_path) @abstractmethod def encode(self, text:list): """Encodes text. Text: should be a list of strings to encode """ class USE(TFEncoder): """Universal sentence encoder""" def __init__(self, model_path): super().__init__(model_path) def encode(self, text): return self.model(text).numpy() class USEQA(TFEncoder): """Universal sentence encoder trained on Question Answer pairs""" def __init__(self, model_path): super().__init__(model_path) def encode(self, text): return self.model.signatures['question_encoder'](tf.constant(s))['outputs'].numpy() class BERT(): """BERT models""" def __init__(self, model_name, layers="-2", pooling_operation="mean"): self.embeddings = BertEmbeddings(model_name, layers=layers, pooling_operation=pooling_operation) self.document_embeddings = DocumentPoolEmbeddings([self.embeddings], fine_tune_mode='nonlinear') def encode(self, text): sentence = Sentence(text) self.document_embeddings.embed(sentence) return sentence.embedding.detach().numpy().reshape(1, -1) model_path = "https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3" encoder = USE(model_path)
STEP 3. CREATE INDEXER
Now we will create FAISS indexer class which will store all embeddings efficiently for fast vector search.
class FAISS: def __init__(self, dimensions:int): self.dimensions = dimensions self.index = faiss.IndexFlatL2(dimensions) self.vectors = {} self.counter = 0 def add(self, text:str, v:list): self.index.add(v) self.vectors[self.counter] = (text, v) self.counter += 1 def search(self, v:list, k:int=10): distance, item_index = self.index.search(v, k) for dist, i in zip(distance[0], item_index[0]): if i==-1: break else: print(f'{self.vectors[i][0]}, %.2f'%dist)
STEP 4. ENCODE AND INDEX
Let’s create embeddings for all the questions and store them in FAISS. We define a search method which shows us the top k similar results given a query.
d = encoder.encode(['hello']).shape[-1] # get dimension of emb index = FAISS(d) #index all questions for q in tqdm(questions): emb = encoder.encode([q]) index.add(q, emb) # embed and search a question def search(s, k=10): emb = encoder.encode([s]) index.search(emb, k)
STEP 5. SEARCH
Below we can see the results of the model. We first write a question in English and it gives expected results. Then we convert the query to other languages using google translate and the results are great again. Even though I have made a spelling mistake of writing ‘loose’ instead of ‘lose’, the model understands it as it works on the subword level and is contextual.

As you can see, the results are so impressive that the model is worth putting in production.
You can find the complete code in my colab notebook. You can download data from here.
In order to make better models, you need to tune the language model for your data using transfer learning. You can read more on it in my last article.
And here you can read more about different models for encoding text for semantic search.
Conclusion
You might already know that recently Google pushed BERT based implementation in production for enhancing their search results. It seems that semantic search is on a rise and will become common in the industry as we get more understanding of leveraging deep learning for search.
This article was originally published on Medium (part 1 and part 2) and re-published to TOPBOTS with permission from the author.
Enjoy this article? Sign up for more AI and NLP updates.
We’ll let you know when we release more in-depth technical education.

