Создание платформы операций машинного обучения (MLOps) в быстро развивающейся среде искусственного интеллекта (ИИ) и машинного обучения (ML) для организаций имеет важное значение для плавного преодоления разрыва между экспериментами в области науки о данных и их развертыванием, одновременно удовлетворяя требованиям, касающимся производительности модели. безопасность и соблюдение требований.
Для выполнения нормативных и нормативных требований ключевыми требованиями при разработке такой платформы являются:
- Дрейф адресных данных
- Мониторинг производительности модели
- Упрощение автоматического переобучения модели
- Предоставить процесс утверждения модели
- Храните модели в безопасной среде
В этом посте мы покажем, как создать платформу MLOps для удовлетворения этих потребностей, используя комбинацию сервисов AWS и сторонних наборов инструментов. Решение предполагает настройку нескольких сред с автоматическим переобучением модели, пакетным выводом и мониторингом с помощью Монитор моделей Amazon SageMaker, версия модели с Реестр моделей SageMakerи конвейер CI/CD для облегчения продвижения кода и конвейеров машинного обучения в разных средах с помощью Создатель мудреца Амазонки, Amazon EventBridge, Amazon Простая служба уведомлений (Амазон С3), ХашиКорп Терраформ, GitHubи Дженкинс CI/CD. Мы создаем модель для прогнозирования тяжести (доброкачественная или злокачественная) маммографического образования, обученную с помощью Алгоритм XGBoost используя общедоступные UCI Маммография Масса набор данных и разверните его с помощью платформы MLOps. Полная инструкция с кодом доступна в Репозиторий GitHub.
Обзор решения
На следующей диаграмме архитектуры показан обзор инфраструктуры MLOps со следующими ключевыми компонентами:
- Стратегия с несколькими аккаунтами – Две разные среды (dev и prod) настраиваются в двух разных учетных записях AWS в соответствии с рекомендациями AWS Well-Architected, а третья учетная запись настраивается в центральном реестре моделей:
- Среда разработки – Где Домен Amazon SageMaker Studio настроен для разработки моделей, обучения моделей и тестирования конвейеров машинного обучения (обучение и вывод) до того, как модель будет готова к использованию в более высоких средах.
- Рабочая среда – Где конвейеры машинного обучения от разработки продвигаются в качестве первого шага, а также планируются и контролируются с течением времени.
- Центральный реестр моделей – Реестр моделей Amazon SageMaker настраивается в отдельной учетной записи AWS для отслеживания версий модели, созданных в средах разработки и рабочей среды.
- CI/CD и контроль версий – Развертывание конвейеров машинного обучения в средах осуществляется посредством CI/CD, настроенного с помощью Jenkins, а контроль версий осуществляется через GitHub. Изменения кода, объединенные с соответствующей веткой git среды, запускают рабочий процесс CI/CD для внесения соответствующих изменений в данную целевую среду.
- Пакетные прогнозы с мониторингом модели – Конвейер вывода, построенный с Конвейеры Amazon SageMaker запускается по расписанию для создания прогнозов вместе с мониторингом модели с помощью SageMaker Model Monitor для обнаружения отклонения данных.
- Автоматизированный механизм переобучения – Конвейер обучения, построенный с помощью SageMaker Pipelines, запускается всякий раз, когда в конвейере вывода обнаруживается отклонение данных. После обучения модель регистрируется в центральном реестре моделей для утверждения утверждающим лицом. После утверждения обновленная версия модели используется для создания прогнозов через конвейер вывода.
- Инфраструктура как код – Инфраструктура как код (IaC), созданная с использованием ХашиКорп Терраформ, поддерживает планирование конвейера вывода с помощью EventBridge, запуск конвейера поездов на основе Правило EventBridge и отправка уведомлений с помощью Amazon Простая служба уведомлений (Амазон соцсети) Темы.
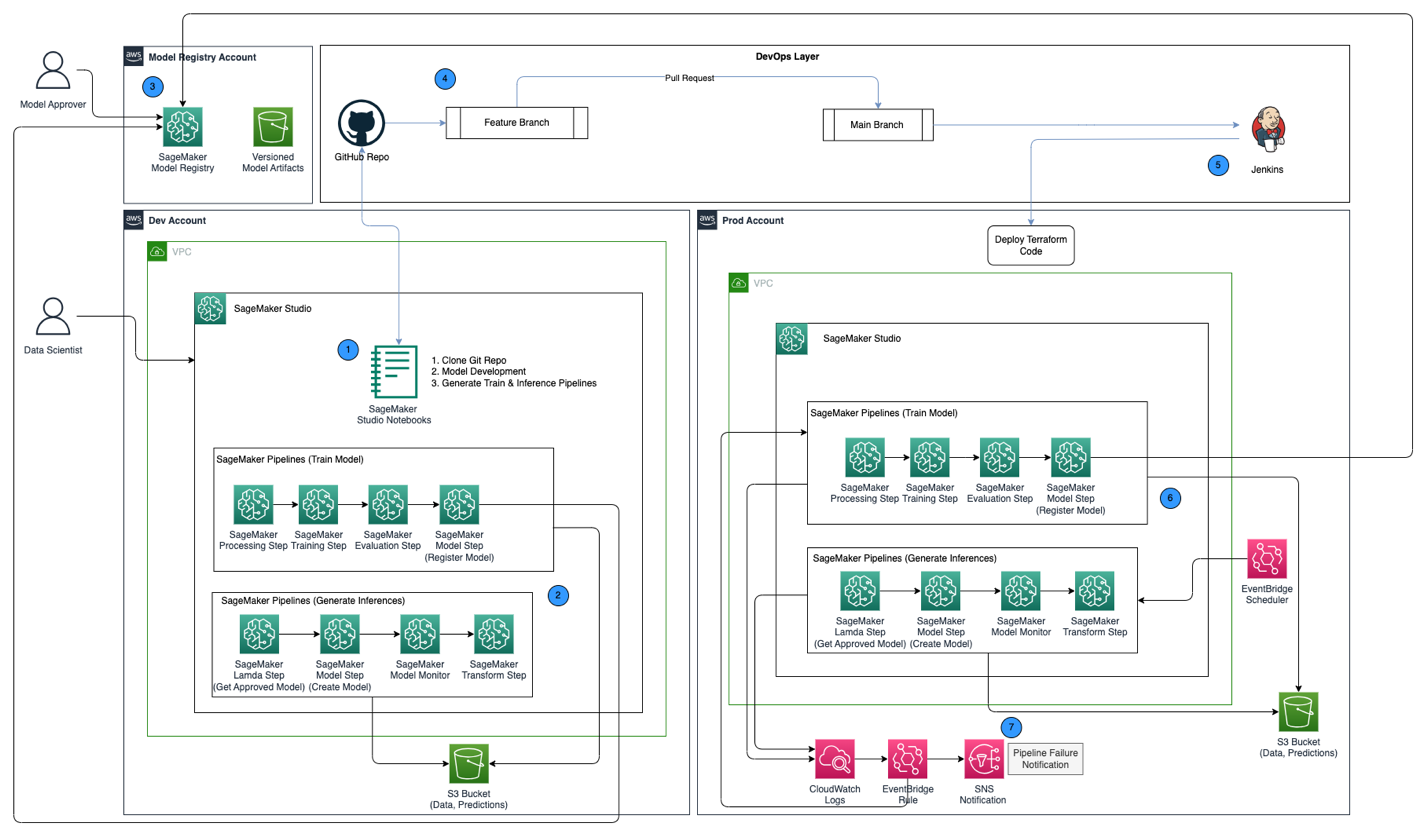
Рабочий процесс MLOps включает в себя следующие шаги:
- Получите доступ к домену SageMaker Studio в учетной записи разработчика, клонируйте репозиторий GitHub, пройдите процесс разработки модели, используя предоставленный образец модели, и сгенерируйте конвейеры обучения и вывода.
- Запустите конвейер обучения в учетной записи разработчика, который генерирует артефакты модели для версии обученной модели и регистрирует модель в реестре моделей SageMaker в центральной учетной записи реестра моделей.
- Утвердите модель в реестре моделей SageMaker в учетной записи центрального реестра моделей.
- Отправьте код (конвейеры обучения и вывода, а также код Terraform IaC для создания расписания EventBridge, правила EventBridge и темы SNS) в ветку функций репозитория GitHub. Создайте запрос на включение, чтобы объединить код с основной веткой репозитория GitHub.
- Запустите конвейер Jenkins CI/CD, который настроен с помощью репозитория GitHub. Конвейер CI/CD развертывает код в учетной записи prod для создания конвейеров обучения и вывода вместе с кодом Terraform для подготовки расписания EventBridge, правила EventBridge и темы SNS.
- Конвейер вывода планируется запускать ежедневно, тогда как конвейер поездов настроен на запуск всякий раз, когда обнаруживается отклонение данных из конвейера вывода.
- Уведомления отправляются через тему SNS при возникновении сбоя в поезде или конвейере вывода.
Предпосылки
Для этого решения у вас должны быть следующие предпосылки:
- Три учетные записи AWS (учетные записи разработчиков, продуктов и центрального реестра моделей)
- Домен SageMaker Studio, настроенный в каждой из трех учетных записей AWS (см. На борту Amazon SageMaker Studio или посмотрите видео Быстрое подключение к Amazon SageMaker Studio инструкции по настройке)
- Jenkins (мы используем Jenkins 2.401.1) с правами администратора, установленный на AWS.
- Terraform версии 1.5.5 или более поздней версии, установленной на сервере Jenkins.
Для этого поста мы работаем в us-east-1 Регион для развертывания решения.
Предоставление ключей KMS в учетных записях разработчиков и продуктов.
Наш первый шаг — создать Служба управления ключами AWS (AWS KMS) в учетных записях разработчиков и продуктов.
Создайте ключ KMS в учетной записи разработчика и предоставьте доступ к учетной записи prod.
Выполните следующие шаги, чтобы создать ключ KMS в учетной записи разработчика:
- В консоли AWS KMS выберите Ключи, управляемые клиентом в навигационной панели.
- Выберите Создать ключ.
- Что касается Тип ключа, наведите на симметричный.
- Что касается Использование ключа, наведите на Зашифровать и расшифровать.
- Выберите Следующая.
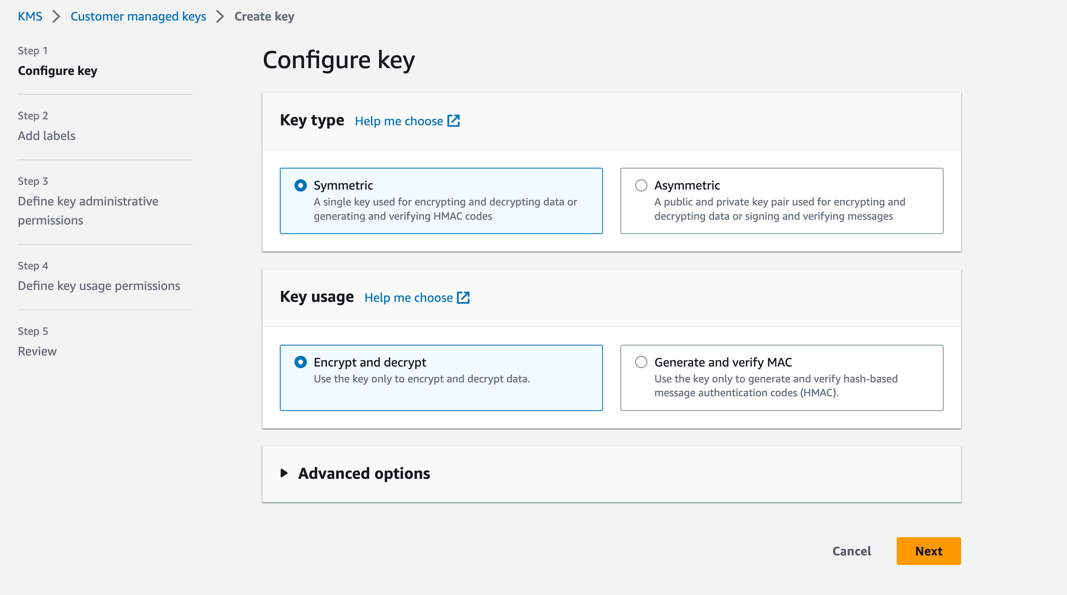
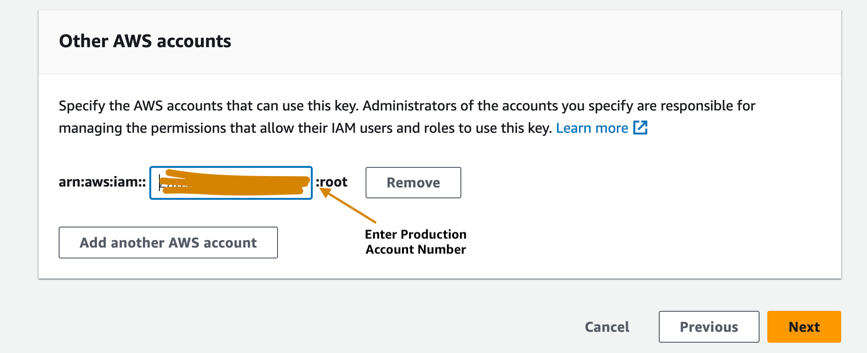
- Введите номер рабочей учетной записи, чтобы предоставить рабочей учетной записи доступ к ключу KMS, предоставленному в учетной записи разработчика. Это обязательный шаг, поскольку при первом обучении модели в учетной записи разработчика артефакты модели шифруются с помощью ключа KMS перед записью в корзину S3 в учетной записи центрального реестра модели. Рабочей учетной записи необходим доступ к ключу KMS для расшифровки артефактов модели и запуска конвейера вывода.
- Выберите Следующая и завершите создание ключа.
После предоставления ключа он должен появиться на консоли AWS KMS.
Создайте ключ KMS в учетной записи prod.
Выполните те же действия, что и в предыдущем разделе, чтобы создать ключ KMS, управляемый клиентом, в рабочей учетной записи. Вы можете пропустить этот шаг, чтобы поделиться ключом KMS с другой учетной записью.
Настройте корзину S3 артефактов модели в учетной записи центрального реестра моделей.
Создайте корзину S3 по вашему выбору с помощью строки sagemaker в соглашении об именах как часть имени корзины в учетной записи центрального реестра модели и обновите политику корзины в корзине S3, чтобы предоставить разрешения как учетным записям разработчиков, так и учетным записям prod на чтение и запись артефактов модели в корзину S3.
Следующий код представляет собой политику корзины, которая будет обновлена в корзине S3:
Настройте роли IAM в своих учетных записях AWS
Следующим шагом является настройка Управление идентификацией и доступом AWS (IAM) роли в ваших учетных записях AWS с разрешениями для AWS Lambda, SageMaker и Дженкинс.
Роль выполнения лямбда
Создавать Роли выполнения Lambda в учетных записях dev и prod, которые будут использоваться функцией Lambda, запускаемой как часть Шаг SageMaker Pipelines Lambda. Этот шаг будет выполняться из конвейера вывода для получения последней утвержденной модели, с использованием которой генерируются выводы. Создайте роли IAM в учетных записях разработчиков и продуктов, используя соглашение об именах. arn:aws:iam::<account-id>:role/lambda-sagemaker-role и прикрепите следующие политики IAM:
- Политика 1 – Создайте встроенную политику с именем
cross-account-model-registry-access, который предоставляет доступ к пакету модели, настроенному в реестре модели в центральной учетной записи: - Политика 2 - Прикреплять AmazonSageMakerFullAccess, который является Политика, управляемая AWS который предоставляет полный доступ к SageMaker. Он также обеспечивает выборочный доступ к сопутствующим услугам, таким как Автоматическое масштабирование приложений AWS, Амазон S3, Реестр Amazon Elastic Container (Amazon ECR) и Журналы Amazon CloudWatch.
- Политика 3 - Прикреплять AWSLambda_FullAccess, которая представляет собой политику, управляемую AWS, которая предоставляет полный доступ к Lambda, функциям консоли Lambda и другим связанным сервисам AWS.
- Политика 4 – Используйте следующую политику доверия IAM для роли IAM:
Исполнительная роль SageMaker
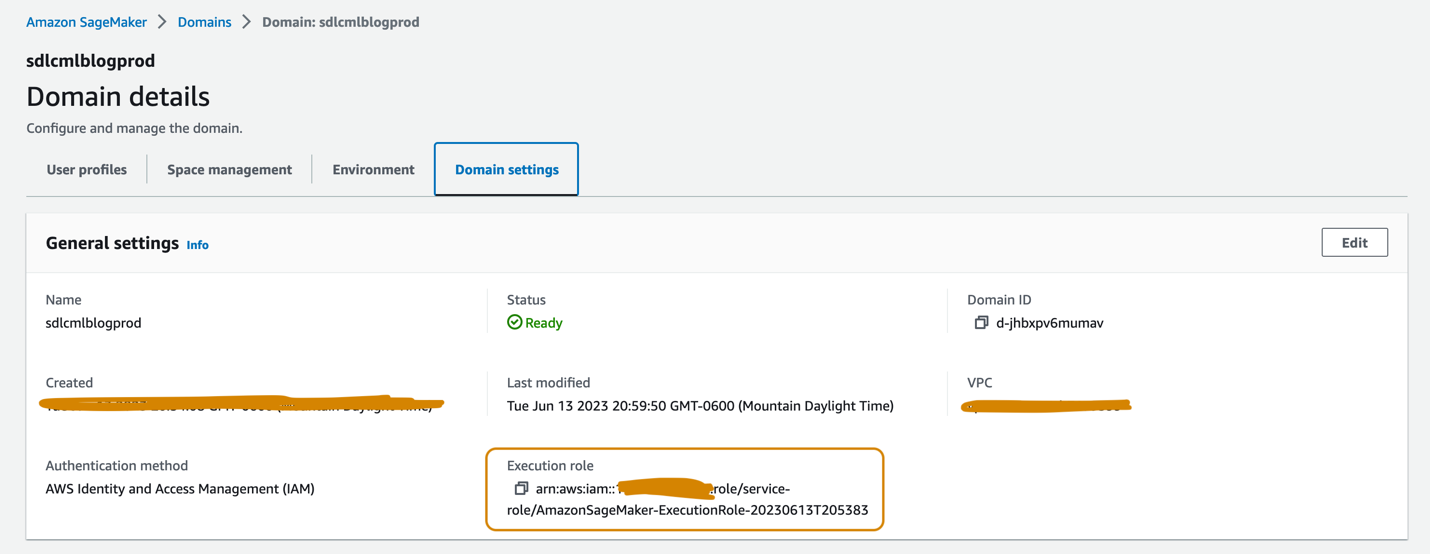
Домены SageMaker Studio, настроенные в учетных записях dev и prod, должны иметь связанную с ними роль исполнения, которую можно найти на странице настройки домена на странице сведений о домене, как показано на следующем снимке экрана. Эта роль используется для запуска заданий обучения, обработки и т. д. в домене SageMaker Studio.
Добавьте следующие политики к роли выполнения SageMaker в обеих учетных записях:
- Политика 1 – Создайте встроенную политику с именем
cross-account-model-artifacts-s3-bucket-access, который предоставляет доступ к корзине S3 в учетной записи центрального реестра модели, в которой хранятся артефакты модели: - Политика 2 – Создайте встроенную политику с именем
cross-account-model-registry-access, который предоставляет доступ к пакету модели в реестре моделей в учетной записи центрального реестра моделей: - Политика 3 – Создайте встроенную политику с именем
kms-key-access-policy, который предоставляет доступ к ключу KMS, созданному на предыдущем шаге. Укажите идентификатор учетной записи, в которой создается политика, и идентификатор ключа KMS, созданный в этой учетной записи. - Политика 4 - Прикреплять AmazonSageMakerFullAccess, который является Политика, управляемая AWS который предоставляет полный доступ к SageMaker и выборочный доступ к соответствующим службам.
- Политика 5 - Прикреплять AWSLambda_FullAccess, которая представляет собой политику, управляемую AWS, которая предоставляет полный доступ к Lambda, функциям консоли Lambda и другим связанным сервисам AWS.
- Политика 6 - Прикреплять CloudWatchEventsFullAccess, которая представляет собой политику, управляемую AWS, которая предоставляет полный доступ к CloudWatch Events.
- Политика 7 – Добавьте следующую политику доверия IAM для роли IAM выполнения SageMaker:
- Политика 8 (относится к роли выполнения SageMaker в учетной записи prod) – Создайте встроенную политику с именем
cross-account-kms-key-access-policy, который предоставляет доступ к ключу KMS, созданному в учетной записи разработчика. Это необходимо, чтобы конвейер вывода мог считывать артефакты модели, хранящиеся в учетной записи центрального реестра модели, где артефакты модели шифруются с помощью ключа KMS из учетной записи разработчика, когда первая версия модели создается из учетной записи разработчика.
Роль Дженкинса для нескольких аккаунтов
Настройте роль IAM под названием cross-account-jenkins-role в рабочей учетной записи, которую Дженкинс возьмет на себя для развертывания конвейеров машинного обучения и соответствующей инфраструктуры в рабочей учетной записи.
Добавьте в роль следующие управляемые политики IAM:
CloudWatchFullAccessAmazonS3FullAccessAmazonSNSFullAccessAmazonSageMakerFullAccessAmazonEventBridgeFullAccessAWSLambda_FullAccess
Обновите доверительные отношения для роли, чтобы предоставить разрешения учетной записи AWS, на которой размещен сервер Jenkins:
Обновление разрешений для роли IAM, связанной с сервером Jenkins.
Предполагая, что Jenkins настроен на AWS, обновите роль IAM, связанную с Jenkins, добавив следующие политики, которые предоставят Jenkins доступ для развертывания ресурсов в учетной записи prod:
- Политика 1 – Создайте следующую встроенную политику с именем
assume-production-role-policy: - Политика 2 – Прикрепите
CloudWatchFullAccessуправляемая политика IAM.
Настройте группу пакетов модели в учетной записи центрального реестра моделей.
В домене SageMaker Studio в учетной записи центрального реестра модели создайте группу пакетов модели с именем mammo-severity-model-package используя следующий фрагмент кода (который можно запустить с помощью блокнота Jupyter):
Настройте доступ к пакету модели для ролей IAM в учетных записях dev и prod.
Предоставьте доступ к ролям выполнения SageMaker, созданным в учетных записях dev и prod, чтобы вы могли регистрировать версии модели в пакете модели. mammo-severity-model-package в центральном реестре моделей из обеих учетных записей. Из домена SageMaker Studio в учетной записи центрального реестра модели запустите следующий код в блокноте Jupyter:
Настройка Дженкинса
В этом разделе мы настраиваем Jenkins для создания конвейеров ML и соответствующей инфраструктуры Terraform в учетной записи prod через конвейер Jenkins CI/CD.
- В консоли CloudWatch создайте группу журналов с именем
jenkins-logвнутри учетной записи prod, в которую Jenkins будет отправлять журналы из конвейера CI/CD. Группа журналов должна быть создана в том же регионе, где настроен сервер Jenkins.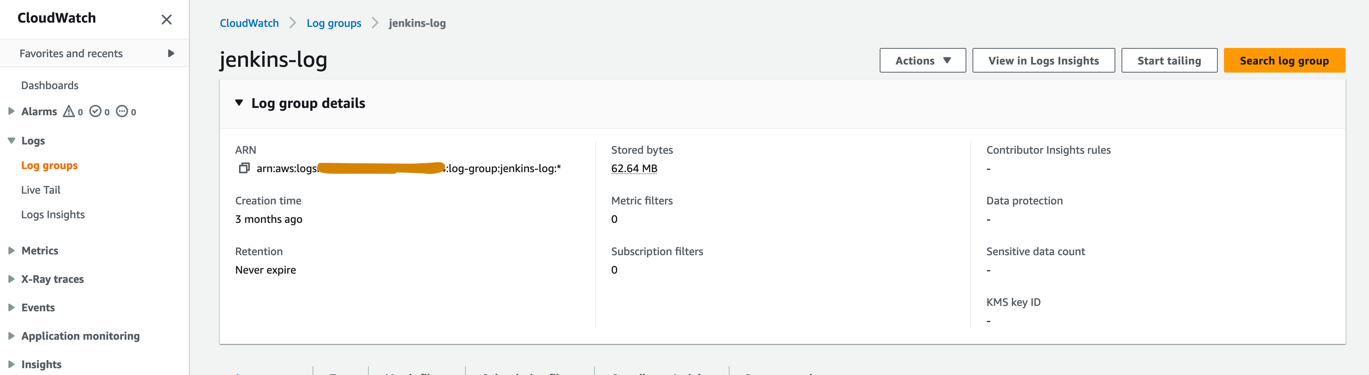
- Установите следующие плагины на вашем сервере Jenkins:
- Настройте учетные данные AWS в Jenkins, используя роль IAM для нескольких учетных записей (
cross-account-jenkins-role), предоставленный в учетной записи prod.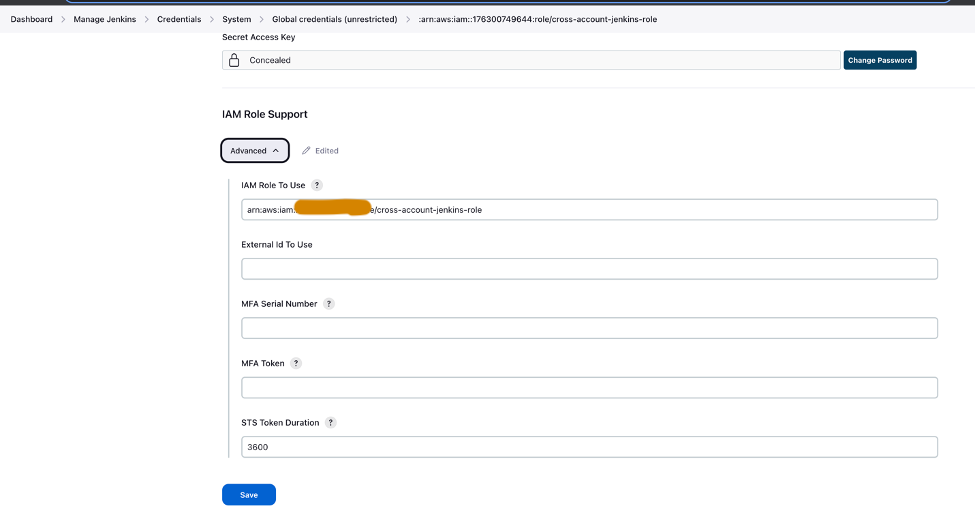
- Что касается Конфигурация системы, выберите AWS.

- Укажите учетные данные и группу журналов CloudWatch, которую вы создали ранее.

- Настройте учетные данные GitHub в Jenkins.
- Создайте новый проект в Jenkins.
- Введите название проекта и выберите Трубопровод.
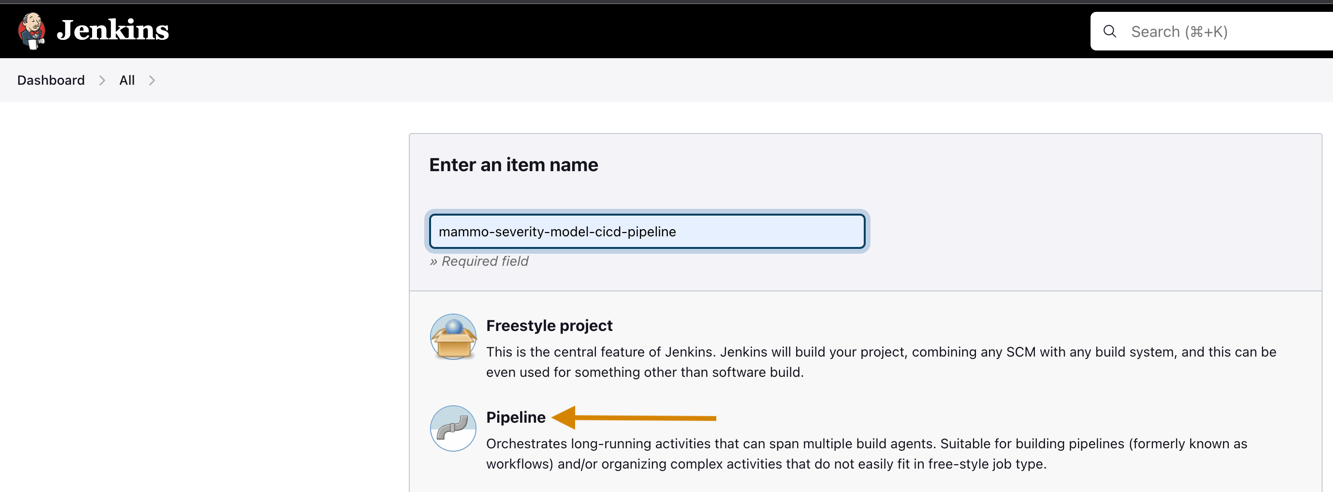
- На Общие вкладка, выберите Проект GitHub и войдите в развилку Репозиторий GitHub URL.
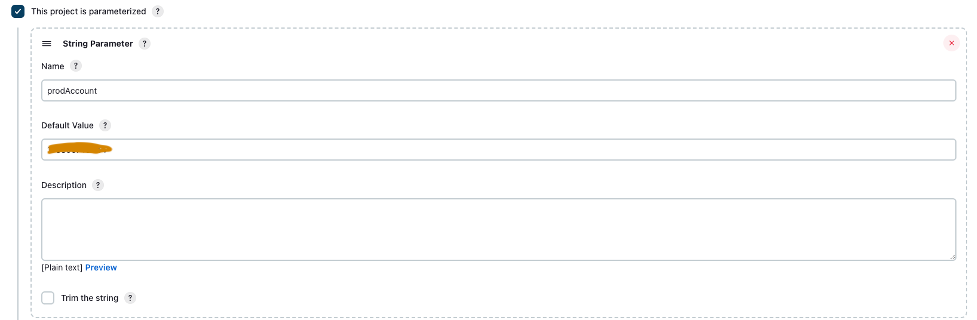
- Выберите Этот проект параметризован.
- На Добавить параметр Меню, выберите Строковый параметр.

- Что касается Имя, войти
prodAccount. - Что касается Значение по умолчанию, введите идентификатор рабочей учетной записи.
- Под Расширенные параметры проекта, Для Определение, наведите на Скрипт пайплайна от SCM.
- Что касается SCM, выберите идти.
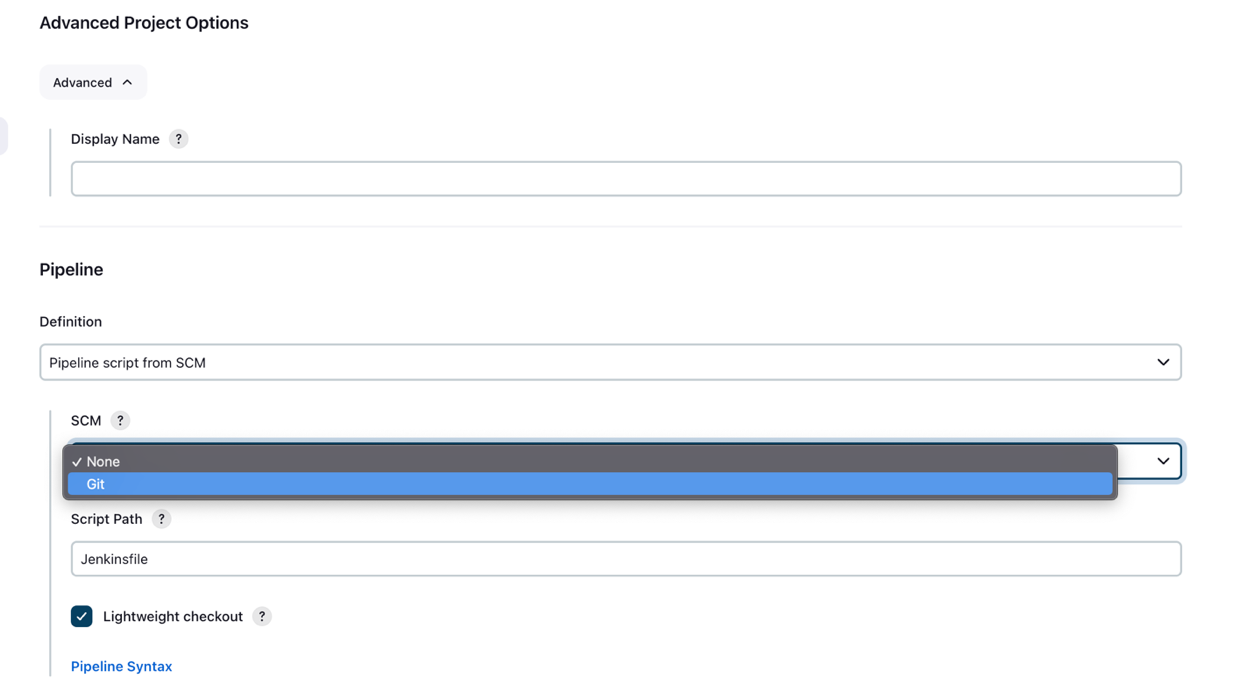
- Что касается URL-адрес репозитория, войдите в раздвоение Репозиторий GitHub URL.
- Что касается Полномочия, введите учетные данные GitHub, сохраненные в Jenkins.
- Enter
mainв Филиалы для строительства раздел, на основании которого будет запускаться конвейер CI/CD.
- Что касается Путь сценария, войти
Jenkinsfile. - Выберите Сохранить.
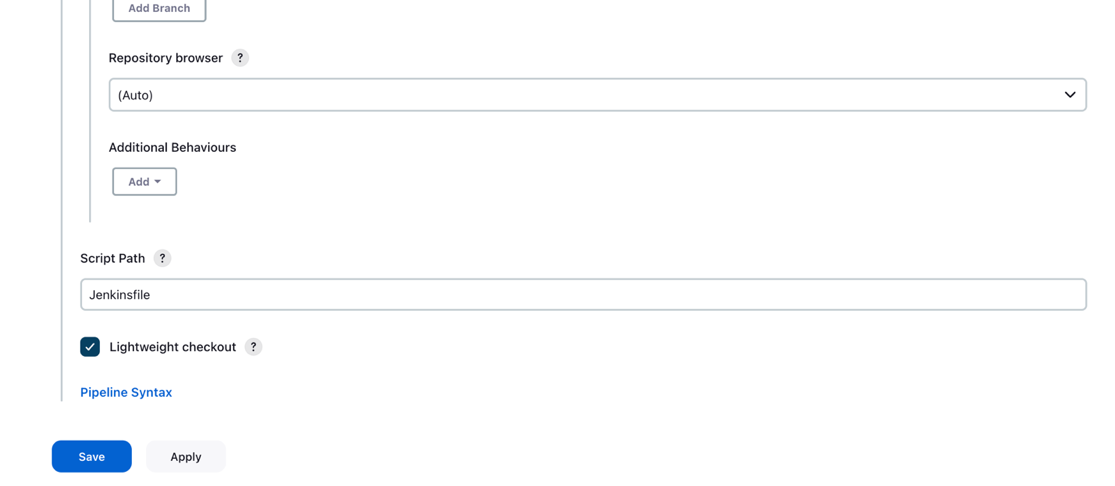
Конвейер Jenkins должен быть создан и виден на вашей информационной панели.
Предоставление сегментов S3, сбор и подготовка данных
Выполните следующие шаги, чтобы настроить сегменты и данные S3:
- Создайте корзину S3 по вашему выбору с помощью строки
sagemakerв соглашении об именах как часть имени сегмента в учетных записях разработчиков и продуктов для хранения наборов данных и артефактов модели. - Настройте корзину S3 для поддержания состояния Terraform в учетной записи продукта.
- Загрузите и сохраните общедоступный UCI Маммография Масса набор данных в корзину S3, созданную ранее в учетной записи разработчика.
- Форкнуть и клонировать Репозиторий GitHub в домене SageMaker Studio в учетной записи разработчика. Репо имеет следующую структуру папок:
- /environments — скрипт конфигурации для среды prod.
- /mlops-инфра – Код для развертывания сервисов AWS с использованием кода Terraform.
- /трубопроводы – Код для компонентов пайплайна SageMaker
- Дженкинсфайл – Скрипт для развертывания через конвейер Jenkins CI/CD.
- setup.py – Необходимо установить необходимые модули Python и создать команду run-pipeline.
- маммография-тяжесть-modeling.ipynb – Позволяет создавать и запускать рабочий процесс ML
- Создайте папку data в папке клонированного репозитория GitHub и сохраните копию общедоступной папки. UCI Маммография Масса набор данных.
- Следуйте блокноту Jupyter
mammography-severity-modeling.ipynb. - Запустите следующий код в блокноте, чтобы предварительно обработать набор данных и загрузить его в корзину S3 в учетной записи разработчика:
Код сгенерирует следующие наборы данных:
-
- данные/mammo-train-dataset-part1.csv – Будет использоваться для обучения первой версии модели.
- данные/mammo-train-dataset-part2.csv – Будет использоваться для обучения второй версии модели вместе с набором данных mammo-train-dataset-part1.csv.
- данные/mammo-batch-dataset.csv – Будет использоваться для формирования выводов.
- данные/mammo-batch-dataset-outliers.csv – В набор данных будут внесены выбросы, чтобы вывести из строя конвейер вывода. Это позволит нам протестировать шаблон, чтобы запустить автоматическое переобучение модели.
- Загрузите набор данных
mammo-train-dataset-part1.csvпод приставкойmammography-severity-model/train-datasetи загрузите наборы данныхmammo-batch-dataset.csvиmammo-batch-dataset-outliers.csvк префиксуmammography-severity-model/batch-datasetкорзины S3, созданной в учетной записи разработчика: - Загрузите наборы данных
mammo-train-dataset-part1.csvиmammo-train-dataset-part2.csvпод приставкойmammography-severity-model/train-datasetв корзину S3, созданную в учетной записи prod, через консоль Amazon S3.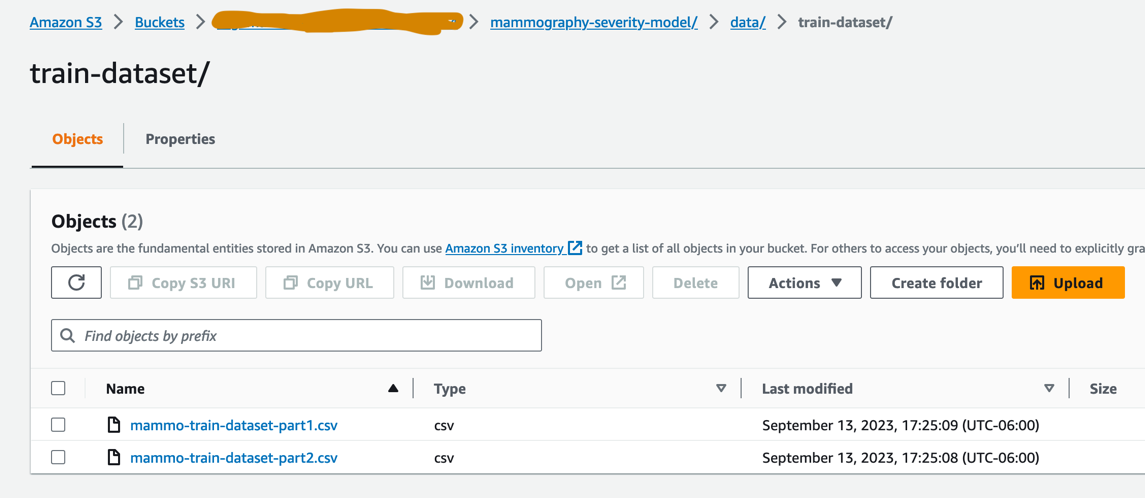
- Загрузите наборы данных
mammo-batch-dataset.csvиmammo-batch-dataset-outliers.csvк префиксуmammography-severity-model/batch-datasetкорзины S3 в учетной записи prod.
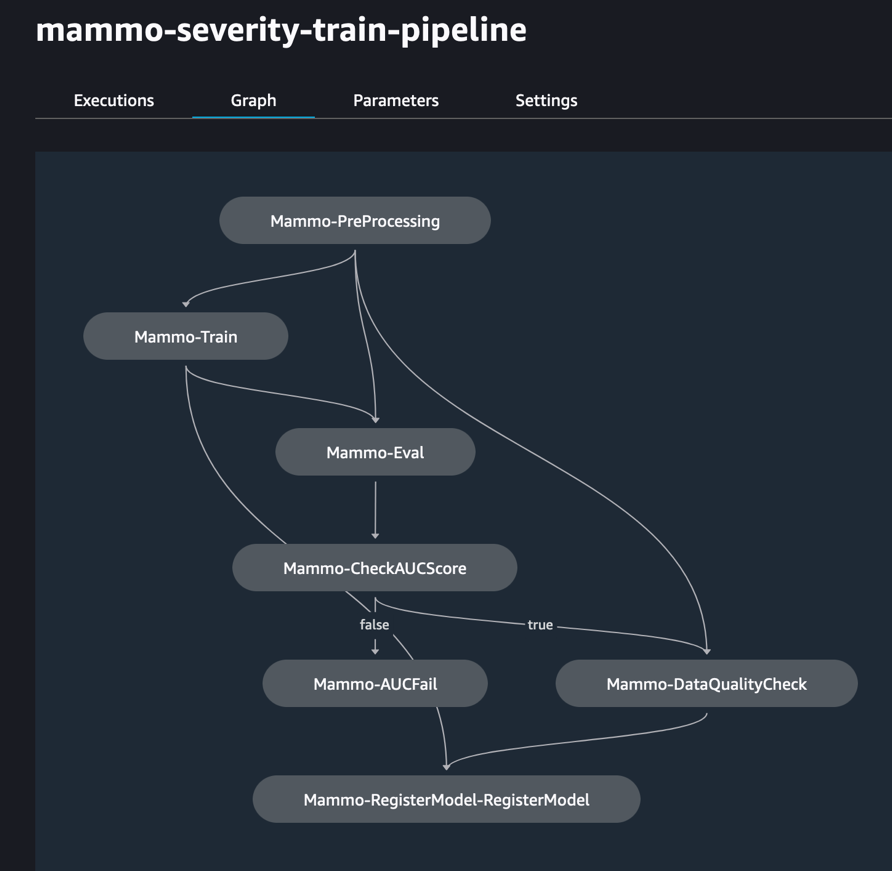
Запустить железнодорожный конвейер
Под <project-name>/pipelines/train, вы можете увидеть следующие скрипты Python:
- скрипты/raw_preprocess.py – Интегрируется с SageMaker Processing для разработки функций.
- скрипты/evaluate_model.py – В данном случае позволяет рассчитывать метрики модели.
auc_score - train_pipeline.py – Содержит код для конвейера обучения модели.
Выполните следующие шаги:
- Загрузите сценарии в Amazon S3:
- Получите экземпляр конвейера поезда:
- Отправьте конвейер поезда и запустите его:
На следующем рисунке показан успешный запуск конвейера обучения. На последнем этапе конвейера модель регистрируется в учетной записи центрального реестра моделей.

Утвердите модель в центральном реестре моделей.
Войдите в учетную запись центрального реестра моделей и получите доступ к реестру моделей SageMaker в домене SageMaker Studio. Измените статус версии модели на «Утверждено».
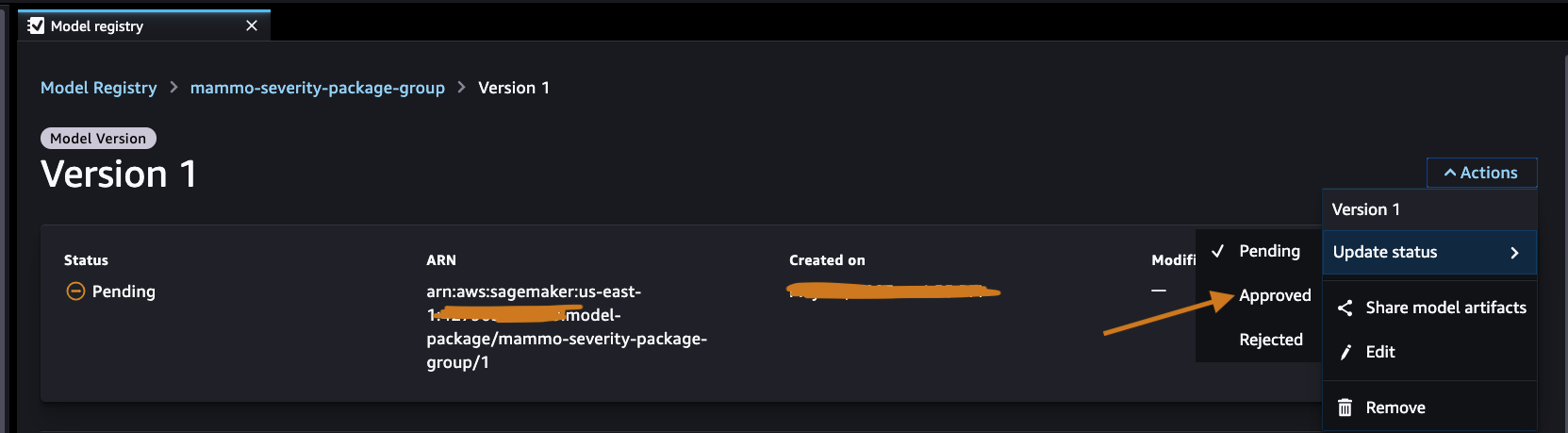
После утверждения статус должен быть изменен в версии модели.
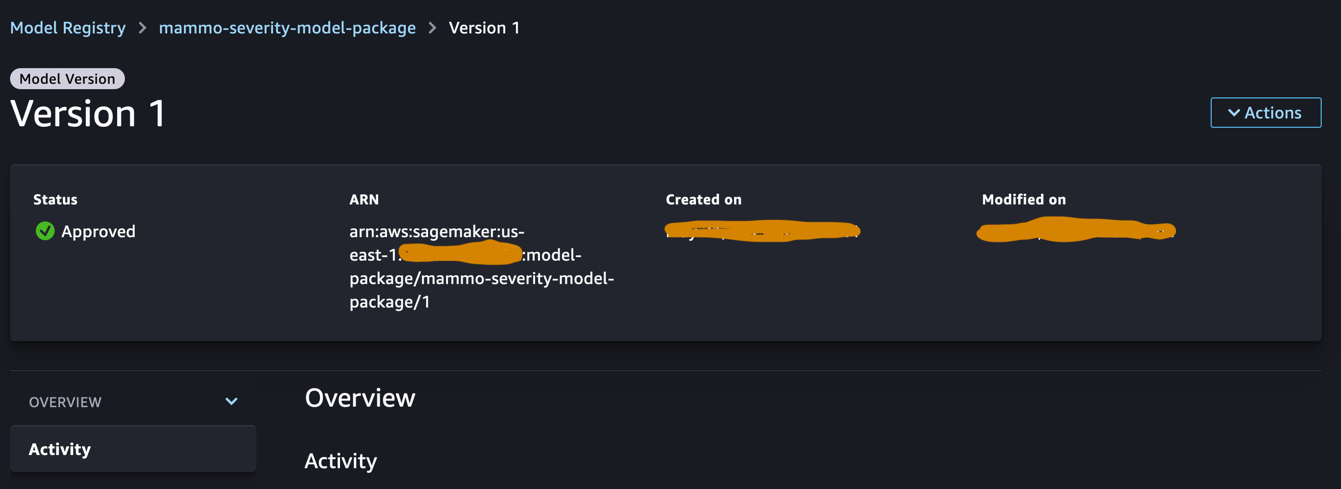
Запустите конвейер вывода (необязательно)
Этот шаг не является обязательным, но вы все равно можете запустить конвейер вывода для создания прогнозов в учетной записи разработчика.
Под <project-name>/pipelines/inference, вы можете увидеть следующие скрипты Python:
- скрипты/lambda_helper.py – Извлекает последнюю утвержденную версию модели из учетной записи центрального реестра моделей с помощью шага SageMaker Pipelines Lambda.
- inference_pipeline.py – Содержит код для конвейера вывода модели.
Выполните следующие шаги:
- Загрузите скрипт в корзину S3:
- Получите экземпляр конвейера вывода, используя обычный пакетный набор данных:
- Отправьте конвейер вывода и запустите его:
На следующем рисунке показан успешный запуск конвейера вывода. Последний шаг конвейера генерирует прогнозы и сохраняет их в корзине S3. Мы используем Мониторбачтрансформстепп для мониторинга входных данных в задание пакетного преобразования. Если есть какие-либо выбросы, конвейер вывода переходит в состояние сбоя.
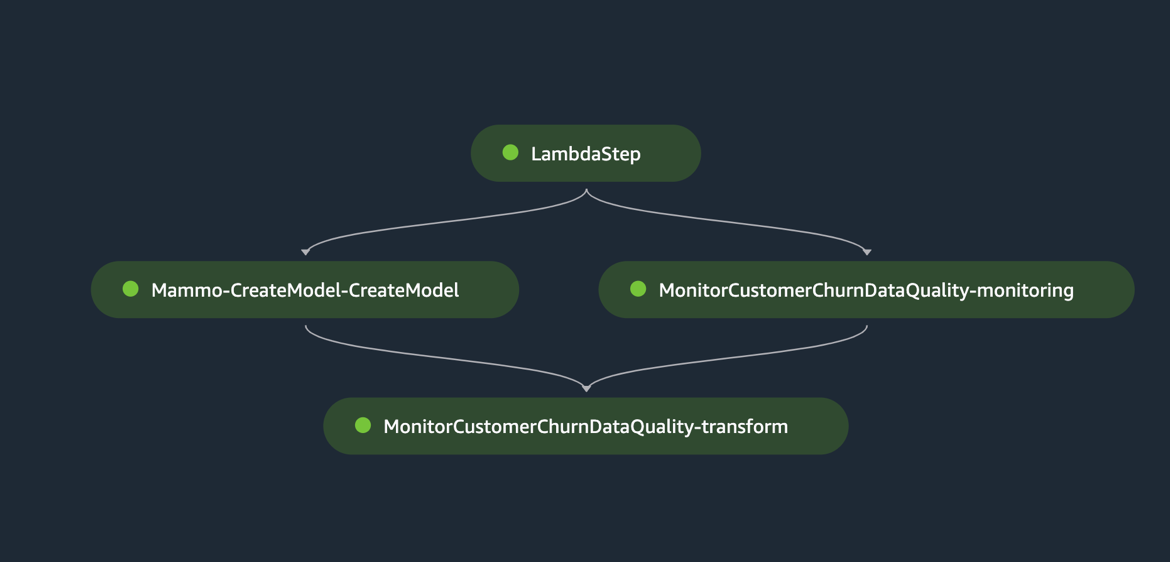
Запустите конвейер Jenkins
Ассоциация environment/ Папка в репозитории GitHub содержит сценарий конфигурации для учетной записи prod. Выполните следующие шаги, чтобы запустить конвейер Jenkins:
- Обновите скрипт конфигурации
prod.tfvars.jsonна основе ресурсов, созданных на предыдущих шагах: - После обновления поместите код в разветвленный репозиторий GitHub и объедините его с основной веткой.
- Перейдите в пользовательский интерфейс Jenkins, выберите Сборка с параметрамии запустите конвейер CI/CD, созданный на предыдущих шагах.

Когда сборка будет завершена и успешна, вы сможете войти в учетную запись prod и просмотреть конвейеры обучения и вывода в домене SageMaker Studio.
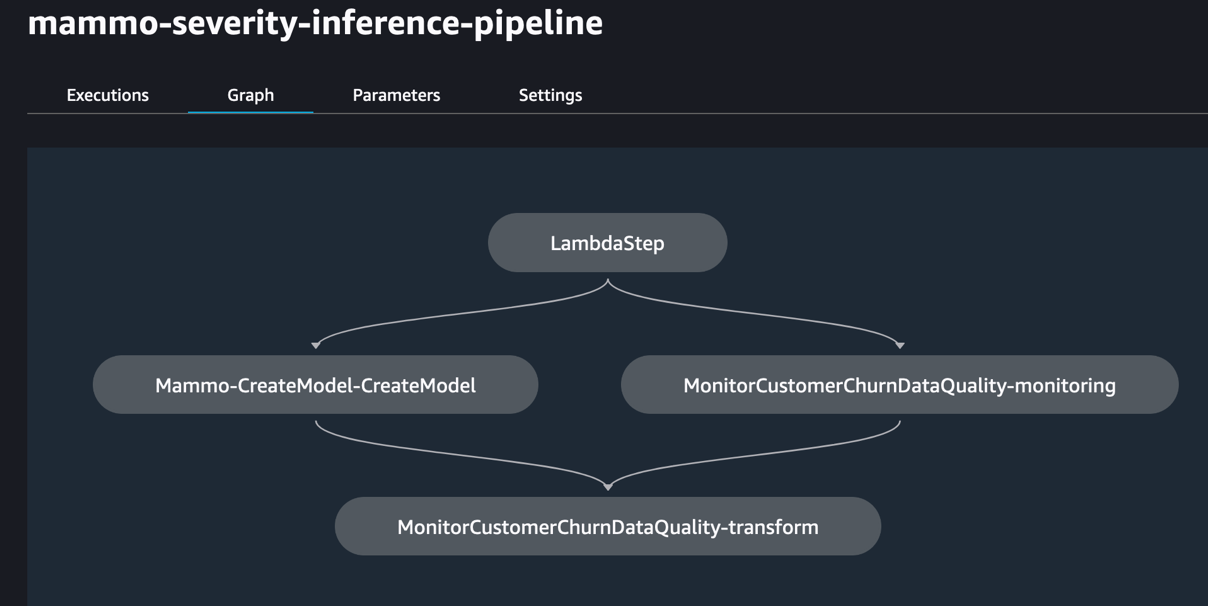
Кроме того, вы увидите три правила EventBridge на консоли EventBridge в учетной записи prod:
- Запланируйте конвейер вывода
- Отправить уведомление о сбое в трубопроводе поезда
- Если конвейер вывода не может запустить конвейер поезда, отправьте уведомление.

Наконец, вы увидите тему уведомлений SNS на консоли Amazon SNS, которая отправляет уведомления по электронной почте. Вы получите электронное письмо с просьбой подтвердить принятие этих уведомлений по электронной почте.

Протестируйте конвейер вывода, используя пакетный набор данных без выбросов.
Чтобы проверить, работает ли конвейер вывода в учетной записи продукта должным образом, мы можем войти в учетную запись продукта и запустить конвейер вывода, используя пакетный набор данных без выбросов.
Запустите конвейер через консоль SageMaker Pipelines в домене SageMaker Studio учетной записи prod, где transform_input будет URI S3 набора данных без выбросов (s3://<s3-bucket-in-prod-account>/mammography-severity-model/data/mammo-batch-dataset.csv).
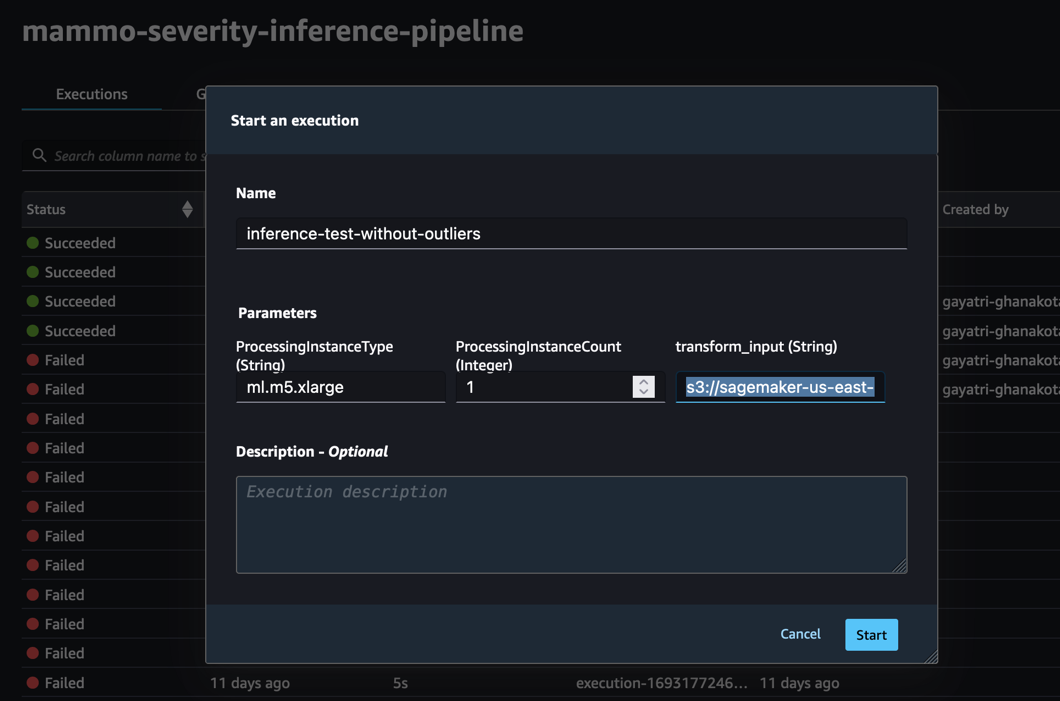
Конвейер вывода завершается успешно и записывает прогнозы обратно в корзину S3.
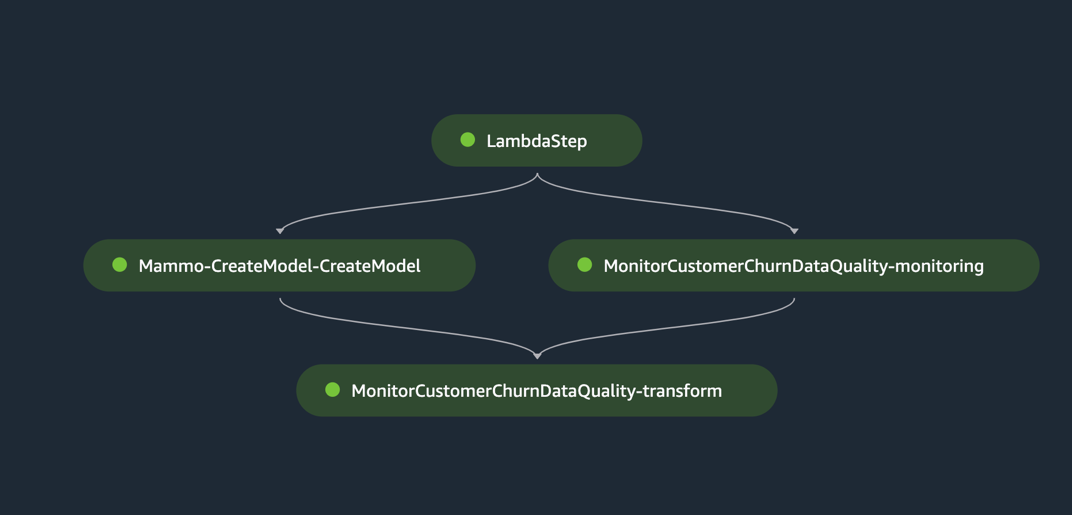
Протестируйте конвейер вывода, используя пакетный набор данных с выбросами.
Вы можете запустить конвейер вывода, используя пакетный набор данных с выбросами, чтобы проверить, работает ли механизм автоматического переобучения должным образом.
Запустите конвейер через консоль SageMaker Pipelines в домене SageMaker Studio учетной записи prod, где transform_input будет URI S3 набора данных с выбросами (s3://<s3-bucket-in-prod-account>/mammography-severity-model/data/mammo-batch-dataset-outliers.csv).

Конвейер вывода завершается сбоем, как и ожидалось, что активирует правило EventBridge, которое, в свою очередь, запускает конвейер поезда.
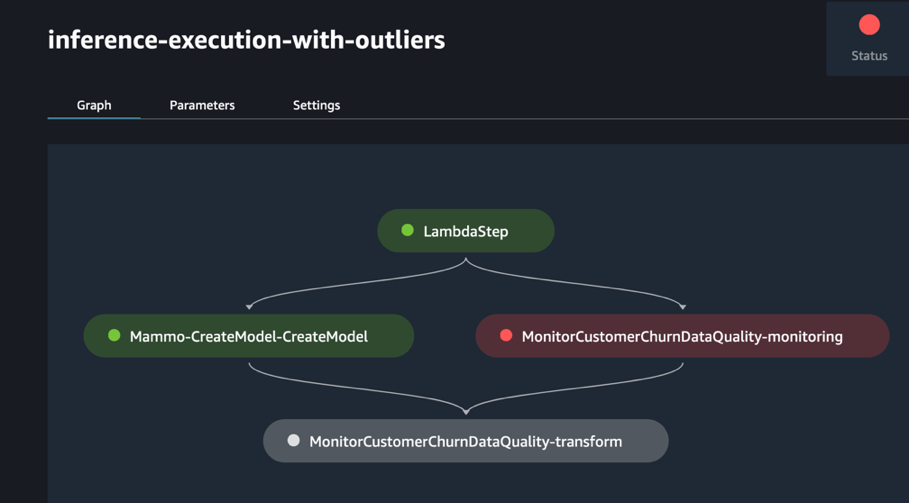
Через несколько секунд вы должны увидеть новый запуск конвейера поездов на консоли SageMaker Pipelines, который собирает два разных набора данных поездов (mammo-train-dataset-part1.csv и mammo-train-dataset-part2.csv) загружен в корзину S3 для повторного обучения модели.

Вы также увидите уведомление, отправленное на адрес электронной почты, подписанный на тему SNS.
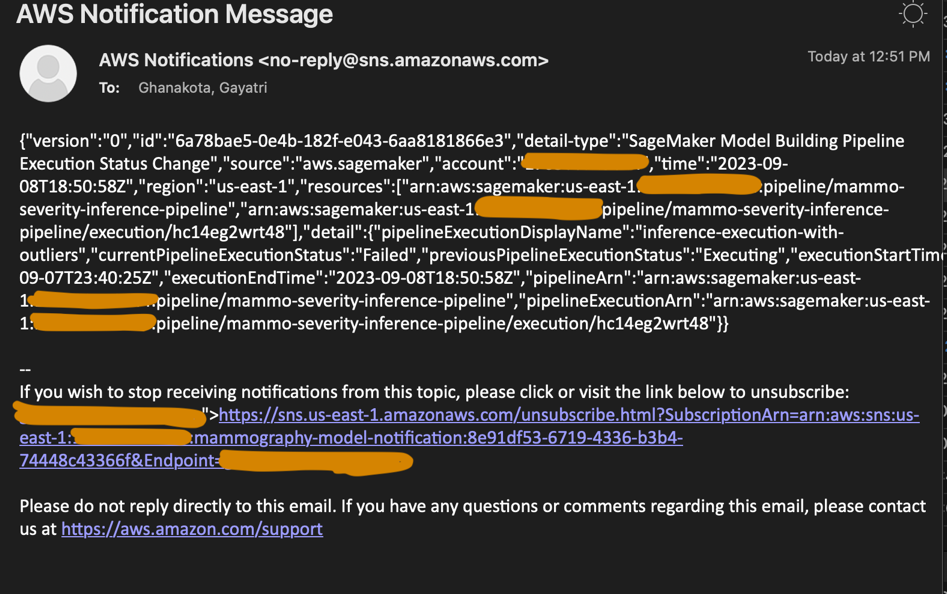
Чтобы использовать обновленную версию модели, войдите в учетную запись центрального реестра модели и подтвердите версию модели, которая будет выбрана во время следующего запуска конвейера вывода, запускаемого с помощью запланированного правила EventBridge.
Хотя конвейеры обучения и вывода используют статический URL-адрес набора данных, вы можете передать URL-адрес набора данных в конвейеры обучения и вывода в качестве динамических переменных, чтобы использовать обновленные наборы данных для повторного обучения модели и создания прогнозов в реальном сценарии.
Убирать
Чтобы избежать дополнительных расходов в будущем, выполните следующие действия:
- Удалите домен SageMaker Studio из всех учетных записей AWS.
- Удалите все ресурсы, созданные вне SageMaker, включая сегменты S3, роли IAM, правила EventBridge и тему SNS, настроенную через Terraform в учетной записи prod.
- Удалите конвейеры SageMaker, созданные между учетными записями, с помощью команды Интерфейс командной строки AWS (Интерфейс командной строки AWS).
Заключение
Организациям часто необходимо использовать общекорпоративные наборы инструментов, чтобы обеспечить совместную работу между различными функциональными областями и командами. Такое сотрудничество гарантирует, что ваша платформа MLOps сможет адаптироваться к меняющимся потребностям бизнеса, и ускоряет внедрение машинного обучения в командах. В этом посте объясняется, как создать платформу MLOps в конфигурации с несколькими средами, чтобы обеспечить автоматическое переобучение модели, пакетный вывод и мониторинг с помощью Amazon SageMaker Model Monitor, управление версиями модели с помощью SageMaker Model Registry, а также продвижение кода и конвейеров машинного обучения в разных средах с помощью Конвейер CI/CD. Мы продемонстрировали это решение, используя комбинацию сервисов AWS и сторонних наборов инструментов. Инструкции по реализации этого решения см. Репозиторий GitHub. Вы также можете расширить это решение, добавив свои собственные источники данных и платформы моделирования.
Об авторах
 Гаятри Ганакота — старший инженер по машинному обучению в AWS Professional Services. Она увлечена разработкой, развертыванием и объяснением решений AI/ML в различных областях. До этой должности она руководила несколькими инициативами в качестве специалиста по данным и инженера по машинному обучению в ведущих мировых компаниях в сфере финансов и розничной торговли. Она имеет степень магистра компьютерных наук, специализирующуюся на науке о данных, полученную в Колорадском университете в Боулдере.
Гаятри Ганакота — старший инженер по машинному обучению в AWS Professional Services. Она увлечена разработкой, развертыванием и объяснением решений AI/ML в различных областях. До этой должности она руководила несколькими инициативами в качестве специалиста по данным и инженера по машинному обучению в ведущих мировых компаниях в сфере финансов и розничной торговли. Она имеет степень магистра компьютерных наук, специализирующуюся на науке о данных, полученную в Колорадском университете в Боулдере.
 Сунита Коппар — старший архитектор озера данных в AWS Professional Services. Она с энтузиазмом занимается решением проблем клиентов, обрабатывая большие данные и предоставляя долгосрочные масштабируемые решения. До этой должности она разрабатывала продукты в сфере Интернета, телекоммуникаций и автомобилестроения, а также была клиентом AWS. Она имеет степень магистра в области науки о данных Калифорнийского университета в Риверсайде.
Сунита Коппар — старший архитектор озера данных в AWS Professional Services. Она с энтузиазмом занимается решением проблем клиентов, обрабатывая большие данные и предоставляя долгосрочные масштабируемые решения. До этой должности она разрабатывала продукты в сфере Интернета, телекоммуникаций и автомобилестроения, а также была клиентом AWS. Она имеет степень магистра в области науки о данных Калифорнийского университета в Риверсайде.
 Сасвата Дэш — консультант DevOps в AWS Professional Services. Она работала с клиентами в сфере здравоохранения и биологических наук, авиации и производства. Она увлечена всем, что связано с автоматизацией, и имеет обширный опыт проектирования и создания корпоративных клиентских решений в AWS. Вне работы она занимается фотографией и ловлей восходов солнца.
Сасвата Дэш — консультант DevOps в AWS Professional Services. Она работала с клиентами в сфере здравоохранения и биологических наук, авиации и производства. Она увлечена всем, что связано с автоматизацией, и имеет обширный опыт проектирования и создания корпоративных клиентских решений в AWS. Вне работы она занимается фотографией и ловлей восходов солнца.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/promote-pipelines-in-a-multi-environment-setup-using-amazon-sagemaker-model-registry-hashicorp-terraform-github-and-jenkins-ci-cd/

