Введение
Точная настройка обработка естественного языка (НЛП) Модель влечет за собой изменение гиперпараметров и архитектуры модели и, как правило, настройку набора данных для повышения производительности модели при выполнении определенной задачи. Этого можно добиться, регулируя скорость обучения, количество слоев в модели, размер внедрений и различные другие параметры. Точная настройка — это трудоемкая процедура, требующая четкого понимания модели и задачи. В этой статье мы рассмотрим, как точно настроить модель обнимающего лица.

Цели обучения
- Поймите структуру модели T5, включая Трансформеры и внимание к себе.
- Научитесь оптимизировать гиперпараметры для повышения производительности модели.
- Подготовка основных текстовых данных, включая токенизацию и форматирование.
- Знать, как адаптировать предварительно обученные модели к конкретным задачам.
- Научитесь очищать, разделять и создавать наборы данных для обучения.
- Получите опыт обучения и оценки моделей с использованием таких показателей, как потери и точность.
- Изучите реальные применения точно настроенной модели для генерации ответов или ответов.
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
Об обнимающихся моделях лица
Обнимая лицо — это фирма, предоставляющая платформу для обучения и развертывания моделей обработки естественного языка (НЛП). На платформе размещена библиотека моделей, подходящая для различных задач НЛП, в том числе языковой перевод, генерация текстаи вопросы-ответы. Эти модели проходят обучение на обширных наборах данных и предназначены для достижения успеха в широком спектре действий по обработке естественного языка (НЛП).
Платформа Hugging Face также включает в себя инструменты для точной настройки предварительно обученных моделей на конкретных наборах данных, которые могут помочь адаптировать алгоритмы к конкретным областям или языкам. Платформа также имеет API-интерфейсы для доступа и использования предварительно обученных моделей в приложениях и инструменты для создания индивидуальных моделей и их доставки в облако.
Использование библиотеки Hugging Face для задач обработки естественного языка (NLP) имеет различные преимущества:
- Широкий выбор моделей: В библиотеке Hugging Face доступен значительный спектр предварительно обученных моделей НЛП, включая модели, обученные таким задачам, как языковой перевод, ответы на вопросы и категоризация текста. Это позволяет легко выбрать модель, которая точно соответствует вашим требованиям.
- Совместимость между платформами: Библиотека Hugging Face совместима со стандартными глубокое обучение такие системы, как TensorFlow, PyTorchи Keras, что упрощает интеграцию в существующий рабочий процесс.
- Простая тонкая настройка: Библиотека Hugging Face содержит инструменты для тонкой настройки предварительно обученных моделей в вашем наборе данных, что позволяет сэкономить время и усилия по сравнению с обучением модели с нуля.
- Активное сообщество: Библиотека Hugging Face имеет обширное и активное сообщество пользователей, а это значит, что вы можете получить помощь и поддержку и внести свой вклад в развитие библиотеки.
- Хорошо документированы: Библиотека Hugging Face содержит обширную документацию, благодаря которой ее можно легко запустить и научиться эффективно использовать.
Импортировать необходимые библиотеки
Импорт необходимых библиотек аналогичен созданию набора инструментов для конкретного программирования и анализа данных. Эти библиотеки, которые часто представляют собой предварительно написанные коллекции кода, предлагают широкий спектр функций и инструментов, которые помогают ускорить разработку. Разработчики и специалисты по обработке данных могут получить доступ к новым возможностям, повысить производительность и использовать существующие решения, импортировав соответствующие библиотеки.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split import torch from transformers import T5Tokenizer
from transformers import T5ForConditionalGeneration, AdamW import pytorch_lightning as pl
from pytorch_lightning.callbacks import ModelCheckpoint pl.seed_everything(100) import warnings
warnings.filterwarnings("ignore")
Импортировать набор данных
Импорт набора данных — это важный начальный шаг в проектах, управляемых данными.
df = pd.read_csv("/kaggle/input/queestion-answer-dataset-qa/train.csv")
df.columns
df = df[['context','question', 'text']]
print("Number of records: ", df.shape[0])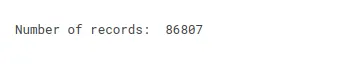
Постановка задачи
«Создать модель, способную генерировать ответы на основе контекста и вопросов».
Например,
Контекст = «Кластеризация групп похожих случаев, например, может
найти похожих пациентов или использовать для сегментации клиентов в
банковская сфера. Метод ассоциации используется для поиска предметов или событий.
которые часто встречаются одновременно, например, продуктовые товары, которые конкретный покупатель обычно покупает вместе. Обнаружение аномалий используется для обнаружения аномальных
и необычные случаи; например, мошенничество с кредитными картами
обнаружение».
Вопрос = «Каков пример обнаружения аномалий?»
Ответ = ?????????????????????????????????
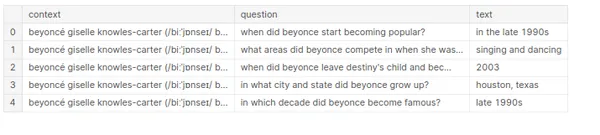
df["context"] = df["context"].str.lower()
df["question"] = df["question"].str.lower()
df["text"] = df["text"].str.lower() df.head()
Инициализировать параметры
- длина ввода: Во время обучения мы ссылаемся на количество входных токенов (например, слов или символов) в одном примере, введенных в модель, как входную длину. Если вы обучаете языковую модель прогнозированию следующего слова в предложении, входная длина будет равна количеству слов во фразе.
- Выходная длина: Ожидается, что во время обучения модель сгенерирует определенное количество выходных токенов, таких как слова или символы, в одной выборке. Выходная длина соответствует количеству слов, предсказанных моделью в предложении.
- Размер обучающей партии: Во время обучения модель обрабатывает сразу несколько выборок. Если вы установите размер обучающего пакета равным 32, модель одновременно обрабатывает 32 экземпляра, например 32 фразы, прежде чем обновлять веса модели.
- Проверка размера пакета: Подобно размеру обучающего пакета, этот параметр указывает количество экземпляров, которые модель обрабатывает на этапе проверки. Другими словами, он представляет собой объем данных, которые обрабатывает модель при ее тестировании на резервном наборе данных.
- Эпохи: Эпоха — это один проход по всему набору обучающих данных. Таким образом, если набор обучающих данных содержит 1000 экземпляров, а размер обучающего пакета равен 32, для одной эпохи потребуется 32 шага обучения. Если модель обучена в течение десяти эпох, она обработает десять тысяч экземпляров (10 * 1000 = десять тысяч).
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') INPUT_MAX_LEN = 512 # Input length
OUT_MAX_LEN = 128 # Output Length
TRAIN_BATCH_SIZE = 8 # Training Batch Size
VALID_BATCH_SIZE = 2 # Validation Batch Size
EPOCHS = 5 # Number of IterationТрансформатор Т5
Ассоциация Модель Т5 основан на архитектуре Transformer — нейронной сети, предназначенной для эффективной обработки последовательных входных данных. Он состоит из кодера и декодера, которые включают в себя последовательность взаимосвязанных «уровней».
Уровни кодера и декодера содержат различные механизмы «внимания» и сети «упреждающей связи». Механизмы внимания позволяют модели фокусироваться на различных разделах входной последовательности в другое время. В то же время сети прямого распространения изменяют входные данные, используя набор весов и смещений.
Модель T5 также использует «самообслуживание», которое позволяет каждому элементу входной последовательности обращать внимание на каждый другой элемент. Это позволяет модели распознавать связи между словами и фразами во входных данных, что имеет решающее значение для многих приложений НЛП.
Помимо кодера и декодера, модель T5 содержит «голову языковой модели», которая предсказывает следующее слово в последовательности на основе предыдущих слов. Это имеет решающее значение для работ по переводу и созданию текста, где модель должна обеспечивать целостный и естественно звучащий результат.
Модель T5 представляет собой большую и сложную нейронную сеть, предназначенную для высокоэффективной и точной обработки последовательного ввода. Он прошел обширное обучение работе с разнообразными наборами текстовых данных и может профессионально выполнять широкий спектр задач по обработке естественного языка.
T5Токенайзер
T5Tokenizer используется для преобразования текста в список токенов, каждый из которых представляет одно слово или знак препинания. Токенизатор дополнительно вставляет во входной текст уникальные токены, чтобы обозначить начало и конец текста и различать различные фразы.
T5Tokenizer использует комбинацию токенизации на уровне символов и слов, а также стратегию токенизации на уровне подслов, сравнимую с токенизатором SentencePiece. Он преобразует входной текст в подсловы на основе частоты каждого символа или последовательности символов в обучающих данных. Это помогает токенизатору справляться с терминами, выходящим за пределы словарного запаса (OOV), которые не встречаются в обучающих данных, но появляются в тестовых данных.
T5Tokenizer дополнительно вставляет в текст уникальные токены для обозначения начала и конца предложений и их разделения. Он добавляет токены s > и / s >, например, для обозначения начала и конца фразы, и Pad > для обозначения заполнения.
MODEL_NAME = "t5-base" tokenizer = T5Tokenizer.from_pretrained(MODEL_NAME, model_max_length= INPUT_MAX_LEN)
print("eos_token: {} and id: {}".format(tokenizer.eos_token, tokenizer.eos_token_id)) # End of token (eos_token)
print("unk_token: {} and id: {}".format(tokenizer.unk_token, tokenizer.eos_token_id)) # Unknown token (unk_token)
print("pad_token: {} and id: {}".format(tokenizer.pad_token, tokenizer.eos_token_id)) # Pad token (pad_token)

Подготовка набора данных
При работе с PyTorch вы обычно готовите данные для использования с моделью, используя класс набора данных. Класс набора данных отвечает за загрузку данных с диска и выполнение необходимых процедур подготовки, таких как токенизация и нумерация. Класс также должен реализовать функцию getitem, которая используется для получения одного элемента из набора данных по индексу.
Метод init заполняет набор данных текстовым списком, списком меток и токенизатором. Функция len возвращает количество выборок в наборе данных. Функция get item возвращает один элемент из набора данных по индексу. Он принимает индексный идентификатор и выводит токенизированные входные данные и метки.
Также принято включать различные этапы предварительной обработки, такие как заполнение и усечение токенизированных входных данных. Вы также можете превратить метки в тензоры.
class T5Dataset: def __init__(self, context, question, target): self.context = context self.question = question self.target = target self.tokenizer = tokenizer self.input_max_len = INPUT_MAX_LEN self.out_max_len = OUT_MAX_LEN def __len__(self): return len(self.context) def __getitem__(self, item): context = str(self.context[item]) context = " ".join(context.split()) question = str(self.question[item]) question = " ".join(question.split()) target = str(self.target[item]) target = " ".join(target.split()) inputs_encoding = self.tokenizer( context, question, add_special_tokens=True, max_length=self.input_max_len, padding = 'max_length', truncation='only_first', return_attention_mask=True, return_tensors="pt" ) output_encoding = self.tokenizer( target, None, add_special_tokens=True, max_length=self.out_max_len, padding = 'max_length', truncation= True, return_attention_mask=True, return_tensors="pt" ) inputs_ids = inputs_encoding["input_ids"].flatten() attention_mask = inputs_encoding["attention_mask"].flatten() labels = output_encoding["input_ids"] labels[labels == 0] = -100 # As per T5 Documentation labels = labels.flatten() out = { "context": context, "question": question, "answer": target, "inputs_ids": inputs_ids, "attention_mask": attention_mask, "targets": labels } return out Загрузчик данных
Класс DataLoader загружает данные параллельно и в пакетном режиме, что позволяет работать с большими наборами данных, которые в противном случае были бы слишком велики для хранения в памяти. Объединение класса DataLoader с классом набора данных, содержащим загружаемые данные.
Загрузчик данных отвечает за перебор набора данных и возврат пакета данных в модель для обучения или оценки во время обучения модели преобразователя. Класс DataLoader предлагает различные параметры для управления загрузкой и предварительной обработкой данных, включая размер пакета, количество рабочих потоков и необходимость перемешивания данных перед каждой эпохой.
class T5DatasetModule(pl.LightningDataModule): def __init__(self, df_train, df_valid): super().__init__() self.df_train = df_train self.df_valid = df_valid self.tokenizer = tokenizer self.input_max_len = INPUT_MAX_LEN self.out_max_len = OUT_MAX_LEN def setup(self, stage=None): self.train_dataset = T5Dataset( context=self.df_train.context.values, question=self.df_train.question.values, target=self.df_train.text.values ) self.valid_dataset = T5Dataset( context=self.df_valid.context.values, question=self.df_valid.question.values, target=self.df_valid.text.values ) def train_dataloader(self): return torch.utils.data.DataLoader( self.train_dataset, batch_size= TRAIN_BATCH_SIZE, shuffle=True, num_workers=4 ) def val_dataloader(self): return torch.utils.data.DataLoader( self.valid_dataset, batch_size= VALID_BATCH_SIZE, num_workers=1 )Построение модели
Создавая модель трансформера в PyTorch, вы обычно начинаете с создания нового класса, производного от факела. nn.Модуль. Этот класс описывает архитектуру модели, включая уровни и функцию пересылки. Функция init класса определяет архитектуру модели, часто создавая экземпляры различных уровней модели и присваивая их в качестве атрибутов класса.
Прямой метод отвечает за передачу данных через модель в прямом направлении. Этот метод принимает входные данные и применяет слои модели для создания выходных данных. Прямой метод должен реализовывать логику модели, например, передавать входные данные через последовательность слоев и возвращать результат.
Функция init класса создает слой внедрения, слой преобразователя и полностью связанный слой и назначает их как атрибуты класса. Прямой метод принимает входящие данные x, обрабатывает их через заданные этапы и возвращает результат. При обучении модели трансформатора процесс обучения обычно включает два этапа: обучение и проверку.
Метод Training_step определяет обоснование выполнения одного шага обучения, который обычно включает в себя:
- прямой проход по модели
- расчет потерь
- вычисление градиентов
- Обновление параметров модели
Метод val_step, как и метод Training_step, используется для оценки модели в наборе проверки. Обычно оно включает в себя:
- прямой проход по модели
- вычисление показателей оценки
class T5Model(pl.LightningModule): def __init__(self): super().__init__() self.model = T5ForConditionalGeneration.from_pretrained(MODEL_NAME, return_dict=True) def forward(self, input_ids, attention_mask, labels=None): output = self.model( input_ids=input_ids, attention_mask=attention_mask, labels=labels ) return output.loss, output.logits def training_step(self, batch, batch_idx): input_ids = batch["inputs_ids"] attention_mask = batch["attention_mask"] labels= batch["targets"] loss, outputs = self(input_ids, attention_mask, labels) self.log("train_loss", loss, prog_bar=True, logger=True) return loss def validation_step(self, batch, batch_idx): input_ids = batch["inputs_ids"] attention_mask = batch["attention_mask"] labels= batch["targets"] loss, outputs = self(input_ids, attention_mask, labels) self.log("val_loss", loss, prog_bar=True, logger=True) return loss def configure_optimizers(self): return AdamW(self.parameters(), lr=0.0001)
Модельное обучение
Пакетное перебор набора данных, отправка входных данных через модель и изменение параметров модели на основе рассчитанных градиентов и набора критериев оптимизации обычно используются для обучения модели преобразователя.
def run(): df_train, df_valid = train_test_split( df[0:10000], test_size=0.2, random_state=101 ) df_train = df_train.fillna("none") df_valid = df_valid.fillna("none") df_train['context'] = df_train['context'].apply(lambda x: " ".join(x.split())) df_valid['context'] = df_valid['context'].apply(lambda x: " ".join(x.split())) df_train['text'] = df_train['text'].apply(lambda x: " ".join(x.split())) df_valid['text'] = df_valid['text'].apply(lambda x: " ".join(x.split())) df_train['question'] = df_train['question'].apply(lambda x: " ".join(x.split())) df_valid['question'] = df_valid['question'].apply(lambda x: " ".join(x.split())) df_train = df_train.reset_index(drop=True) df_valid = df_valid.reset_index(drop=True) dataModule = T5DatasetModule(df_train, df_valid) dataModule.setup() device = DEVICE models = T5Model() models.to(device) checkpoint_callback = ModelCheckpoint( dirpath="/kaggle/working", filename="best_checkpoint", save_top_k=2, verbose=True, monitor="val_loss", mode="min" ) trainer = pl.Trainer( callbacks = checkpoint_callback, max_epochs= EPOCHS, gpus=1, accelerator="gpu" ) trainer.fit(models, dataModule) run()Прогнозирование модели
Чтобы делать прогнозы с помощью точно настроенной модели НЛП, такой как T5, с использованием новых входных данных, вы можете выполнить следующие шаги:
- Предварительная обработка нового ввода: Токенизируйте и предварительно обработайте новый входной текст, чтобы он соответствовал предварительной обработке, которую вы применили к своим обучающим данным. Убедитесь, что он имеет правильный формат, ожидаемый моделью.
- Используйте точно настроенную модель для вывода: Загрузите свою настроенную модель T5, которую вы ранее обучили или загрузили из контрольной точки.
- Генерировать прогнозы: Передайте предварительно обработанные новые входные данные в модель для прогнозирования. В случае Т5 вы можете использовать метод генерации для генерации ответов.
train_model = T5Model.load_from_checkpoint("/kaggle/working/best_checkpoint-v1.ckpt") train_model.freeze() def generate_question(context, question): inputs_encoding = tokenizer( context, question, add_special_tokens=True, max_length= INPUT_MAX_LEN, padding = 'max_length', truncation='only_first', return_attention_mask=True, return_tensors="pt" ) generate_ids = train_model.model.generate( input_ids = inputs_encoding["input_ids"], attention_mask = inputs_encoding["attention_mask"], max_length = INPUT_MAX_LEN, num_beams = 4, num_return_sequences = 1, no_repeat_ngram_size=2, early_stopping=True, ) preds = [ tokenizer.decode(gen_id, skip_special_tokens=True, clean_up_tokenization_spaces=True) for gen_id in generate_ids ] return "".join(preds)Прогноз
давайте сгенерируем прогноз, используя точно настроенную модель T5 с новыми входными данными:
context = «Кластеризация групп похожих дел, например,
можно найти похожих пациентов или использовать для сегментации клиентов в
банковская сфера. Использование техники ассоциаций для поиска предметов или событий, которые
часто встречаются вместе, например, продуктовые товары, которые обычно покупаются вместе.
конкретным заказчиком. Использование обнаружения аномалий для обнаружения аномалий
и необычные случаи, например, обнаружение мошенничества с кредитными картами».
que = «Каков пример обнаружения аномалий?»
print(generate_question(context, que))

context = "Classification is used when your target is categorical, while regression is used when your target variable
is continuous. Both classification and regression belong to the category of supervised machine learning algorithms." que = "When is classification used?" print(generate_question(context, que))

Заключение
В этой статье мы отправились в путь по тонкой настройке модели обработки естественного языка (NLP), в частности модели T5, для задачи ответа на вопросы. На протяжении всего этого процесса мы углубились в различные аспекты разработки и внедрения моделей НЛП.
Программа вебинара:
- Изучена структура кодера-декодера и механизмы самообслуживания, лежащие в основе его возможностей.
- Искусство настройки гиперпараметров — важный навык для оптимизации производительности модели.
- Экспериментирование со скоростью обучения, размерами пакетов и размерами модели позволило нам эффективно настроить модель.
- Опыт токенизации, заполнения и преобразования необработанных текстовых данных в подходящий формат для ввода модели.
- Углубился в тонкую настройку, включая загрузку предварительно обученных весов, изменение слоев модели и адаптацию их к конкретным задачам.
- Научились очищать и структурировать данные, разбивая их на обучающие и проверочные наборы.
- Продемонстрировано, как он может генерировать ответы или ответы на основе входного контекста и вопросов, продемонстрировав его реальную полезность.
Часто задаваемые вопросы
Ответ: Точная настройка в НЛП включает в себя изменение гиперпараметров и архитектуры предварительно обученной модели для оптимизации ее производительности для конкретной задачи или набора данных.
Ответ: Архитектура Transformer представляет собой архитектуру нейронной сети. Он превосходно справляется с обработкой последовательных данных и является основой для таких моделей, как T5. Он использует механизмы самообслуживания для понимания контекста.
Ответ: В задачах последовательности в последовательности в НЛП мы используем структуру кодер-декодер. Кодер обрабатывает входные данные, а декодер генерирует выходные данные.
Ответ: Да, вы можете применять точно настроенные модели к различным реальным задачам НЛП, включая генерацию текста, перевод и ответы на вопросы.
Ответ: Для начала вы можете изучить такие библиотеки, как Hugging Face. Эти библиотеки предлагают предварительно обученные модели и инструменты для точной настройки наборов данных. Изучение основ НЛП и концепций глубокого обучения также имеет решающее значение.
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2023/10/hugging-face-fine-tuning-tutorial/

