Astăzi, clienții din toate industriile – fie că este vorba de servicii financiare, asistență medicală și științe ale vieții, călătorii și ospitalitate, mass-media și divertisment, telecomunicații, software ca serviciu (SaaS) și chiar furnizori de modele proprietare – folosesc modele lingvistice mari (LLM) pentru construiți aplicații precum chatbot-uri cu întrebări și răspunsuri (QnA), motoare de căutare și baze de cunoștințe. Aceste AI generativă aplicațiile nu sunt folosite doar pentru a automatiza procesele de afaceri existente, dar au și capacitatea de a transforma experiența clienților care folosesc aceste aplicații. Având în vedere progresele realizate cu LLM-uri precum Mixtral-8x7B Instruct, derivat din arhitecturi precum cel amestec de experți (MoE), clienții caută în permanență modalități de a îmbunătăți performanța și acuratețea aplicațiilor AI generative, permițându-le în același timp să utilizeze eficient o gamă mai largă de modele cu sursă închisă și deschisă.
Un număr de tehnici sunt de obicei utilizate pentru a îmbunătăți acuratețea și performanța rezultatelor unui LLM, cum ar fi reglarea fină cu reglaj fin eficient al parametrilor (PEFT), învățare prin consolidare din feedbackul uman (RLHF), și performanță distilare a cunoștințelor. Cu toate acestea, atunci când construiți aplicații AI generative, puteți utiliza o soluție alternativă care permite încorporarea dinamică a cunoștințelor externe și vă permite să controlați informațiile utilizate pentru generare fără a fi nevoie să vă ajustați modelul de bază existent. Aici intervine Retrieval Augmented Generation (RAG), în special pentru aplicațiile AI generative, spre deosebire de alternativele de reglare fină mai scumpe și mai robuste pe care le-am discutat. Dacă implementați aplicații RAG complexe în sarcinile dvs. zilnice, este posibil să întâmpinați provocări comune cu sistemele dvs. RAG, cum ar fi recuperarea incorectă, creșterea dimensiunii și complexității documentelor și depășirea contextului, care pot avea un impact semnificativ asupra calității și fiabilității răspunsurilor generate. .
Această postare discută despre modelele RAG pentru a îmbunătăți acuratețea răspunsului folosind LangChain și instrumente cum ar fi retriever-ul părinte, pe lângă tehnici precum compresia contextuală, pentru a le permite dezvoltatorilor să îmbunătățească aplicațiile AI generative existente.
Prezentare generală a soluțiilor
În această postare, demonstrăm utilizarea generării de text Mixtral-8x7B Instruct combinată cu modelul de încorporare BGE Large En pentru a construi eficient un sistem RAG QnA pe un notebook Amazon SageMaker utilizând instrumentul de recuperare a documentelor părinte și tehnica de compresie contextuală. Următoarea diagramă ilustrează arhitectura acestei soluții.
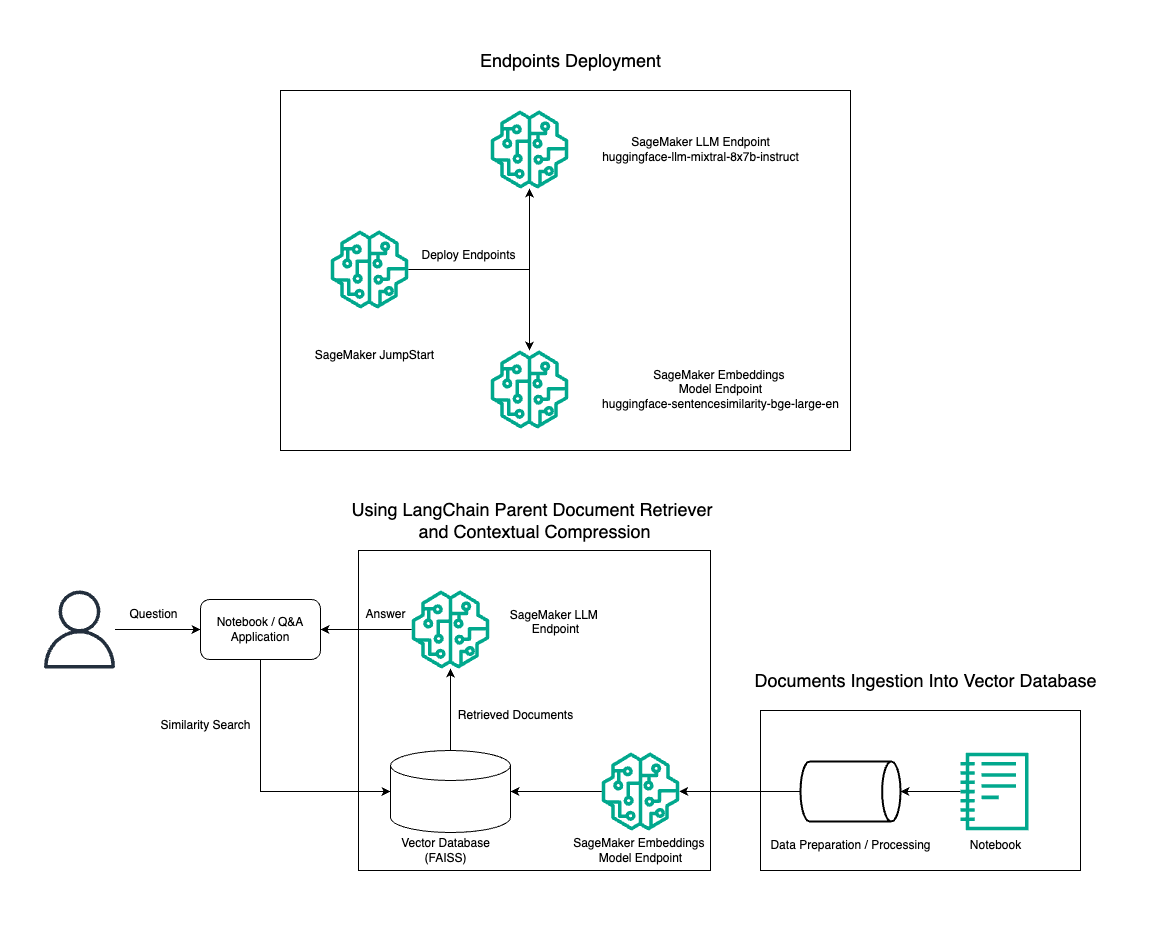
Puteți implementa această soluție cu doar câteva clicuri folosind Amazon SageMaker JumpStart, o platformă complet gestionată care oferă modele de bază de ultimă generație pentru diverse cazuri de utilizare, cum ar fi scrierea de conținut, generarea de cod, răspunsul la întrebări, redactarea, rezumarea, clasificarea și recuperarea informațiilor. Acesta oferă o colecție de modele pre-instruite pe care le puteți implementa rapid și cu ușurință, accelerând dezvoltarea și implementarea aplicațiilor de învățare automată (ML). Una dintre componentele cheie ale SageMaker JumpStart este Model Hub, care oferă un catalog vast de modele pre-antrenate, cum ar fi Mixtral-8x7B, pentru o varietate de sarcini.
Mixtral-8x7B folosește o arhitectură MoE. Această arhitectură permite diferitelor părți ale unei rețele neuronale să se specializeze în diferite sarcini, împărțind efectiv volumul de muncă între mai mulți experți. Această abordare permite instruirea și implementarea eficientă a modelelor mai mari în comparație cu arhitecturile tradiționale.
Unul dintre principalele avantaje ale arhitecturii MoE este scalabilitatea sa. Distribuind volumul de lucru între mai mulți experți, modelele MoE pot fi instruite pe seturi de date mai mari și pot obține performanțe mai bune decât modelele tradiționale de aceeași dimensiune. În plus, modelele MoE pot fi mai eficiente în timpul inferenței, deoarece doar un subset de experți trebuie activat pentru o anumită intrare.
Pentru mai multe informații despre Mixtral-8x7B Instruct on AWS, consultați Mixtral-8x7B este acum disponibil în Amazon SageMaker JumpStart. Modelul Mixtral-8x7B este disponibil sub licența Apache 2.0 permisivă, pentru utilizare fără restricții.
În această postare, discutăm despre cum puteți utiliza LangChain pentru a crea aplicații RAG eficiente și mai eficiente. LangChain este o bibliotecă open source Python concepută pentru a construi aplicații cu LLM-uri. Oferă un cadru modular și flexibil pentru combinarea LLM-urilor cu alte componente, cum ar fi baze de cunoștințe, sisteme de recuperare și alte instrumente AI, pentru a crea aplicații puternice și personalizabile.
Ne parcurgem construirea unei conducte RAG pe SageMaker cu Mixtral-8x7B. Folosim modelul de generare de text Mixtral-8x7B Instruct cu modelul de încorporare BGE Large En pentru a crea un sistem QnA eficient folosind RAG pe un notebook SageMaker. Folosim o instanță ml.t3.medium pentru a demonstra implementarea LLM-urilor prin SageMaker JumpStart, care poate fi accesată printr-un punct final API generat de SageMaker. Această configurație permite explorarea, experimentarea și optimizarea tehnicilor avansate RAG cu LangChain. De asemenea, ilustrăm integrarea magazinului FAISS Embedding în fluxul de lucru RAG, evidențiind rolul său în stocarea și recuperarea înglobărilor pentru a îmbunătăți performanța sistemului.
Efectuăm o scurtă prezentare a caietului SageMaker. Pentru instrucțiuni mai detaliate și pas cu pas, consultați Modele RAG avansate cu Mixtral pe SageMaker Jumpstart GitHub repo.
Nevoia de modele RAG avansate
Modelele RAG avansate sunt esențiale pentru a îmbunătăți capacitățile actuale ale LLM-urilor în procesarea, înțelegerea și generarea de text asemănător omului. Pe măsură ce dimensiunea și complexitatea documentelor cresc, reprezentarea mai multor fațete ale documentului într-o singură încorporare poate duce la o pierdere a specificității. Deși este esențial să surprindeți esența generală a unui document, este la fel de important să recunoașteți și să reprezentați subcontextele variate din interior. Aceasta este o provocare cu care vă confruntați adesea atunci când lucrați cu documente mai mari. O altă provocare cu RAG este că, odată cu extragerea, nu știți despre interogările specifice cu care sistemul dvs. de stocare a documentelor le va trata la ingerare. Acest lucru ar putea duce la ca informațiile cele mai relevante pentru o interogare să fie îngropate sub text (debordare de context). Pentru a atenua eșecul și a îmbunătăți arhitectura RAG existentă, puteți utiliza modele RAG avansate (recuperare document părinte și compresie contextuală) pentru a reduce erorile de recuperare, pentru a îmbunătăți calitatea răspunsurilor și pentru a permite gestionarea întrebărilor complexe.
Cu tehnicile discutate în această postare, puteți aborda provocările cheie asociate cu regăsirea și integrarea cunoștințelor externe, permițând aplicației dvs. să ofere răspunsuri mai precise și mai conștiente de context.
În secțiunile următoare, vom explora cum recuperatorii de documente părinte și compresie contextuală vă poate ajuta să rezolvați unele dintre problemele pe care le-am discutat.
Recuperare document părinte
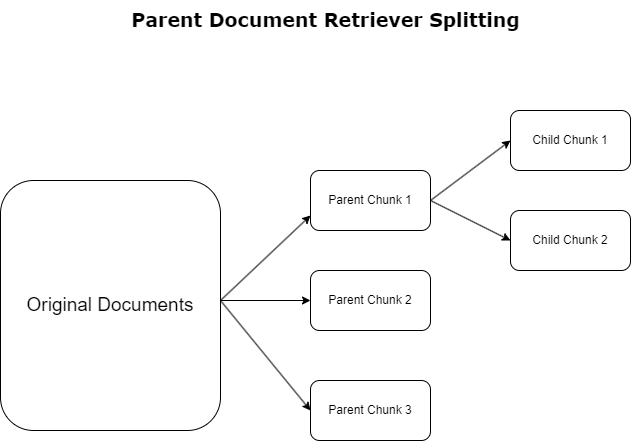
În secțiunea anterioară, am evidențiat provocările pe care le întâmpină aplicațiile RAG atunci când se ocupă de documente extinse. Pentru a aborda aceste provocări, recuperatorii de documente părinte clasifică și desemnează documentele primite ca documentele părintelui. Aceste documente sunt recunoscute pentru natura lor cuprinzătoare, dar nu sunt utilizate direct în forma lor originală pentru încorporare. În loc să comprima un întreg document într-o singură încorporare, recuperatorii de documente părinte disecă aceste documente părinte în documentele copilului. Fiecare document copil surprinde aspecte sau subiecte distincte din documentul părinte mai larg. În urma identificării acestor segmente copil, fiecăruia sunt atribuite înglobări individuale, surprinzând esența lor tematică specifică (vezi diagrama următoare). În timpul preluării, documentul părinte este invocat. Această tehnică oferă capabilități de căutare țintite, dar cu o gamă largă, oferind LLM o perspectivă mai largă. Recuperările documentelor părinte oferă LLM-urilor un dublu avantaj: specificitatea înglobărilor documentelor copil pentru regăsirea informațiilor precise și relevante, împreună cu invocarea documentelor părinte pentru generarea de răspunsuri, care îmbogățește rezultatele LLM cu un context stratificat și aprofundat.
Compresie contextuală
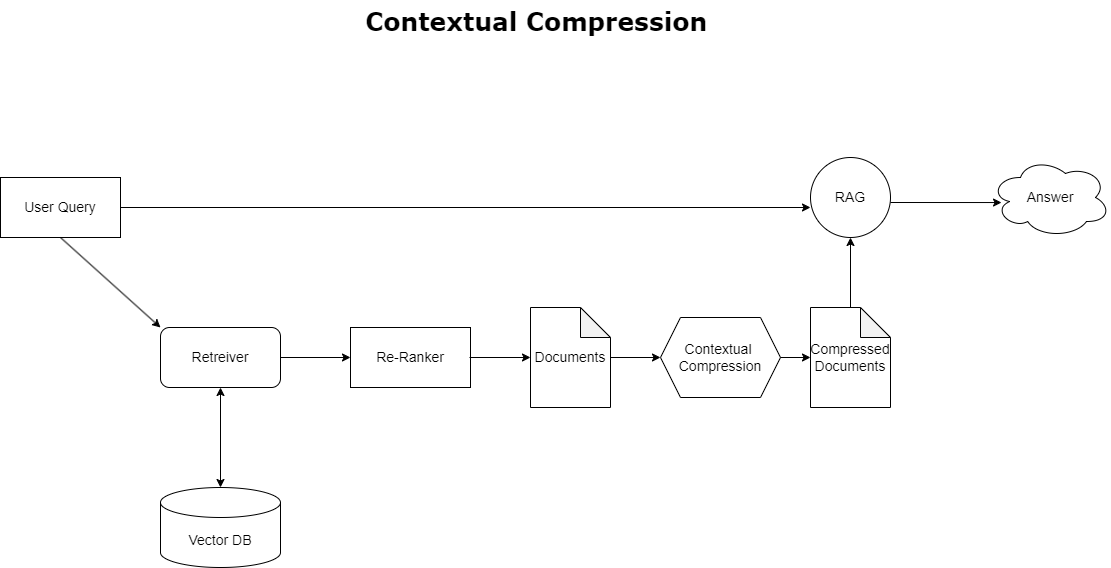
Pentru a aborda problema depășirii contextului discutată mai devreme, puteți utiliza compresie contextuală pentru a comprima și filtra documentele preluate în conformitate cu contextul interogării, astfel încât doar informațiile pertinente sunt păstrate și procesate. Acest lucru se realizează printr-o combinație de un retriever de bază pentru preluarea documentelor inițiale și un compresor de documente pentru rafinarea acestor documente prin reducerea conținutului lor sau excluzându-le în întregime pe baza relevanței, așa cum este ilustrat în diagrama următoare. Această abordare simplificată, facilitată de retriever-ul de compresie contextuală, îmbunătățește foarte mult eficiența aplicației RAG, oferind o metodă de extragere și utilizare numai a ceea ce este esențial dintr-o masă de informații. Acesta abordează problema supraîncărcării de informații și a procesării irelevante de date, ceea ce duce la o calitate îmbunătățită a răspunsului, operațiuni LLM mai rentabile și un proces general de recuperare mai fluid. În esență, este un filtru care adaptează informațiile la interogarea la îndemână, făcându-l un instrument foarte necesar pentru dezvoltatorii care doresc să-și optimizeze aplicațiile RAG pentru o performanță mai bună și satisfacție a utilizatorilor.
Cerințe preliminare
Dacă sunteți nou la SageMaker, consultați Ghid de dezvoltare Amazon SageMaker.
Înainte de a începe cu soluția, creați un cont AWS. Când creați un cont AWS, obțineți o identitate de conectare unică (SSO) care are acces complet la toate serviciile și resursele AWS din cont. Această identitate se numește cont AWS utilizator root.
Conectarea la Consola de administrare AWS utilizarea adresei de e-mail și a parolei pe care le-ați folosit pentru a crea contul vă oferă acces complet la toate resursele AWS din contul dvs. Vă recomandăm insistent să nu utilizați utilizatorul root pentru sarcinile de zi cu zi, chiar și pentru cele administrative.
În schimb, respectați cele mai bune practici de securitate in Gestionarea identității și accesului AWS (IAM) și creați un utilizator și un grup administrativ. Apoi blocați în siguranță acreditările utilizatorului root și folosiți-le pentru a efectua doar câteva sarcini de gestionare a contului și a serviciilor.
Modelul Mixtral-8x7b necesită o instanță ml.g5.48xlarge. SageMaker JumpStart oferă o modalitate simplificată de a accesa și de a implementa peste 100 de modele diferite de fundație open source și terță parte. Pentru a lansați un punct final pentru a găzdui Mixtral-8x7B de la SageMaker JumpStart, poate fi necesar să solicitați o creștere a cotei de serviciu pentru a accesa o instanță ml.g5.48xlarge pentru utilizarea punctului final. Puteți solicitați creșteri ale cotei de servicii prin consola, Interfața liniei de comandă AWS (AWS CLI) sau API pentru a permite accesul la acele resurse suplimentare.
Configurați o instanță de notebook SageMaker și instalați dependențe
Pentru a începe, creați o instanță de blocnotes SageMaker și instalați dependențele necesare. Consultați GitHub repo pentru a asigura o instalare de succes. După ce ați configurat instanța de notebook, puteți implementa modelul.
De asemenea, puteți rula notebook-ul local în mediul de dezvoltare integrat (IDE) preferat. Asigurați-vă că aveți instalat laboratorul de notebook Jupyter.
Implementați modelul
Implementați modelul Mixtral-8X7B Instruct LLM pe SageMaker JumpStart:
Implementați modelul de încorporare BGE Large En pe SageMaker JumpStart:
Configurați LangChain
După ce ați importat toate bibliotecile necesare și ați implementat modelul Mixtral-8x7B și modelul de înglobare BGE Large En, acum puteți configura LangChain. Pentru instrucțiuni pas cu pas, consultați GitHub repo.
Pregătirea datelor
În această postare, folosim câțiva ani de Scrisori către acționari ale Amazon ca corpus text pentru a realiza QnA. Pentru pași mai detaliați pentru pregătirea datelor, consultați GitHub repo.
Răspuns la întrebare
Odată ce datele sunt pregătite, puteți utiliza wrapper-ul oferit de LangChain, care se înfășoară în jurul magazinului de vectori și preia intrare pentru LLM. Acest înveliș efectuează următorii pași:
- Luați întrebarea de intrare.
- Creați o încorporare a întrebării.
- Preluați documentele relevante.
- Încorporați documentele și întrebarea într-un prompt.
- Invocați modelul cu prompt și generați răspunsul într-o manieră lizibilă.
Acum că magazinul de vectori este la locul lui, puteți începe să puneți întrebări:
Lanț obișnuit de retriever
În scenariul precedent, am explorat modalitatea rapidă și simplă de a obține un răspuns conștient de context la întrebarea dvs. Acum să ne uităm la o opțiune mai personalizabilă cu ajutorul RetrievalQA, unde puteți personaliza modul în care documentele preluate ar trebui să fie adăugate la prompt folosind parametrul chain_type. De asemenea, pentru a controla câte documente relevante ar trebui recuperate, puteți modifica parametrul k din următorul cod pentru a vedea diferite rezultate. În multe scenarii, ați putea dori să știți ce documente sursă a folosit LLM pentru a genera răspunsul. Puteți obține acele documente în ieșire folosind return_source_documents, care returnează documentele care sunt adăugate în contextul promptului LLM. RetrievalQA vă permite, de asemenea, să furnizați un șablon de prompt personalizat care poate fi specific modelului.
Să punem o întrebare:
Lanțul de recuperare a documentelor părinte
Să ne uităm la o opțiune RAG mai avansată cu ajutorul lui ParentDocumentRetriever. Când lucrați cu preluarea documentelor, este posibil să întâlniți un compromis între stocarea unor bucăți mici de document pentru încorporare precise și documente mai mari pentru a păstra mai mult context. Recuperarea documentului părinte atinge acest echilibru prin împărțirea și stocarea unor bucăți mici de date.
Noi folosim a parent_splitter pentru a împărți documentele originale în bucăți mai mari numite documente părinte și a child_splitter pentru a crea documente copil mai mici din documentele originale:
Documentele copil sunt apoi indexate într-un magazin de vectori folosind înglobări. Acest lucru permite regăsirea eficientă a documentelor copilului relevante pe baza similitudinii. Pentru a prelua informații relevante, recuperatorul documentului părinte preia mai întâi documentele secundare din depozitul de vectori. Apoi caută ID-urile părintelui pentru acele documente copil și returnează documentele părinte mai mari corespunzătoare.
Să punem o întrebare:
Lanț de compresie contextuală
Să ne uităm la o altă opțiune avansată RAG numită compresie contextuală. O provocare legată de regăsire este că, de obicei, nu cunoaștem întrebările specifice cu care se va confrunta sistemul dvs. de stocare a documentelor atunci când ingerați date în sistem. Aceasta înseamnă că informațiile cele mai relevante pentru o interogare pot fi îngropate într-un document cu mult text irelevant. Trecerea acelui document complet prin aplicația dvs. poate duce la apeluri LLM mai scumpe și răspunsuri mai slabe.
Retriever-ul de compresie contextuală abordează provocarea de a prelua informații relevante dintr-un sistem de stocare a documentelor, unde datele pertinente pot fi îngropate în documente care conțin mult text. Prin comprimarea și filtrarea documentelor preluate pe baza contextului de interogare dat, sunt returnate doar cele mai relevante informații.
Pentru a utiliza recuperatorul de compresie contextuală, veți avea nevoie de:
- Un retriever de bază – Acesta este retrieverul inițial care preia documentele din sistemul de stocare pe baza interogării
- Un compresor de documente – Această componentă preia documentele preluate inițial și le scurtează prin reducerea conținutului documentelor individuale sau eliminarea totală a documentelor irelevante, folosind contextul de interogare pentru a determina relevanța
Adăugarea compresiei contextuale cu un extractor de lanț LLM
În primul rând, înfășurați-vă retriever-ul de bază cu a ContextualCompressionRetriever. Veți adăuga un LLMChainExtractor, care va itera peste documentele returnate inițial și va extrage din fiecare doar conținutul care este relevant pentru interogare.
Inițializați lanțul folosind ContextualCompressionRetriever cu o LLMChainExtractor și transmiteți promptul prin intermediul chain_type_kwargs a susținut.
Să punem o întrebare:
Filtrați documentele cu un filtru LLM în lanț
LLMChainFilter este un compresor puțin mai simplu, dar mai robust, care utilizează un lanț LLM pentru a decide care dintre documentele preluate inițial să filtreze și pe care să le returneze, fără a manipula conținutul documentului:
Inițializați lanțul folosind ContextualCompressionRetriever cu o LLMChainFilter și transmiteți promptul prin intermediul chain_type_kwargs a susținut.
Să punem o întrebare:
Comparați rezultatele
Următorul tabel compară rezultatele de la diferite interogări în funcție de tehnică.
| Metoda de măsurare | Interogarea 1 | Interogarea 2 | Comparaţie |
| Cum a evoluat AWS? | De ce are succes Amazon? | ||
| Ieșire obișnuită în lanț Retriever | AWS (Amazon Web Services) a evoluat de la o investiție inițial neprofitabilă la o afacere anuală de 85 de miliarde de dolari cu o rentabilitate puternică, oferind o gamă largă de servicii și caracteristici și devenind o parte semnificativă a portofoliului Amazon. În ciuda faptului că s-a confruntat cu scepticismul și vânturile în contra pe termen scurt, AWS a continuat să inoveze, să atragă noi clienți și să migreze clienții activi, oferind beneficii precum agilitate, inovație, eficiență a costurilor și securitate. AWS și-a extins, de asemenea, investițiile pe termen lung, inclusiv dezvoltarea de cipuri, pentru a oferi noi capabilități și a schimba ceea ce este posibil pentru clienții săi. | Amazon are succes datorită inovației sale continue și extinderii în noi domenii, cum ar fi serviciile de infrastructură tehnologică, dispozitivele digitale de citire, asistenții personali bazați pe voce și noile modele de afaceri, cum ar fi piața terță parte. Capacitatea sa de a extinde operațiunile rapid, așa cum se vede în expansiunea rapidă a rețelelor de servicii și transport, contribuie, de asemenea, la succesul său. În plus, concentrarea Amazon pe optimizare și creșterea eficienței în procesele sale a dus la îmbunătățiri ale productivității și reduceri de costuri. Exemplul Amazon Business evidențiază capacitatea companiei de a-și valorifica punctele forte în comerțul electronic și logistica în diferite sectoare. | Pe baza răspunsurilor din lanțul obișnuit de retriever, observăm că, deși oferă răspunsuri lungi, suferă de un debordare a contextului și nu menționează detalii semnificative din corpus în ceea ce privește răspunsul la interogarea furnizată. Lanțul obișnuit de recuperare nu este capabil să surprindă nuanțele cu profunzime sau perspectivă contextuală, potențial lipsind aspectele critice ale documentului. |
| Ieșire Parent Document Retriever | AWS (Amazon Web Services) a început cu o lansare inițială fără caracteristici a serviciului Elastic Compute Cloud (EC2) în 2006, oferind o singură dimensiune a instanței, într-un singur centru de date, într-o regiune a lumii, cu doar instanțe de sistem de operare Linux , și fără multe caracteristici cheie, cum ar fi monitorizarea, echilibrarea sarcinii, scalarea automată sau stocarea persistentă. Cu toate acestea, succesul AWS le-a permis să repete și să adauge rapid capabilitățile lipsă, extinzându-se în cele din urmă pentru a oferi diverse arome, dimensiuni și optimizări de calcul, stocare și rețea, precum și dezvoltarea propriilor cipuri (Graviton) pentru a împinge prețul și performanța mai departe. . Procesul iterativ de inovare al AWS a necesitat investiții semnificative în resurse financiare și umane de peste 20 de ani, adesea cu mult înainte de momentul plății, pentru a satisface nevoile clienților și pentru a îmbunătăți experiențele clienților pe termen lung, loialitatea și randamentul pentru acționari. | Amazon are succes datorită capacității sale de a inova în mod constant, de a se adapta la condițiile în schimbare ale pieței și de a satisface nevoile clienților din diverse segmente de piață. Acest lucru este evident în succesul Amazon Business, care a crescut pentru a genera vânzări brute anuale de aproximativ 35 de miliarde de dolari, oferind selecție, valoare și comoditate clienților de afaceri. Investițiile Amazon în comerțul electronic și capabilitățile logistice au permis, de asemenea, crearea de servicii precum Buy with Prime, care îi ajută pe comercianții cu site-uri web direct către consumatori să conducă conversia de la vizualizări la achiziții. | Recuperarea documentului părinte aprofundează specificul strategiei de creștere a AWS, inclusiv procesul iterativ de adăugare de noi funcții bazate pe feedback-ul clienților și călătoria detaliată de la o lansare inițială fără caracteristici la o poziție dominantă pe piață, oferind în același timp un răspuns bogat în context. . Răspunsurile acoperă o gamă largă de aspecte, de la inovații tehnice și strategia de piață până la eficiența organizațională și concentrarea către clienți, oferind o viziune holistică a factorilor care contribuie la succes, împreună cu exemple. Acest lucru poate fi atribuit capacităților de căutare țintite, dar ample, ale retriever-ului de document părinte. |
| Extractor de lanț LLM: Ieșire de compresie contextuală | AWS a evoluat pornind ca un mic proiect în interiorul Amazon, necesitând investiții de capital semnificative și confruntându-se cu scepticismul atât din interiorul, cât și din exteriorul companiei. Cu toate acestea, AWS a avut un avans față de potențialii concurenți și a crezut în valoarea pe care o poate aduce clienților și Amazon. AWS și-a luat angajamentul pe termen lung de a continua investițiile, rezultând peste 3,300 de noi funcții și servicii lansate în 2022. AWS a transformat modul în care clienții își gestionează infrastructura tehnologică și a devenit o afacere cu o rată anuală de venituri de 85 de miliarde de dolari, cu o rentabilitate puternică. De asemenea, AWS și-a îmbunătățit continuu ofertele, cum ar fi îmbunătățirea EC2 cu funcții și servicii suplimentare după lansarea sa inițială. | Pe baza contextului oferit, succesul Amazon poate fi atribuit expansiunii sale strategice de la o platformă de vânzare de cărți la o piață globală cu un ecosistem vibrant de vânzători terți, investiții timpurii în AWS, inovație în introducerea Kindle și Alexa și creștere substanțială. în venituri anuale din 2019 până în 2022. Această creștere a dus la extinderea amprentei centrului de livrare, crearea unei rețele de transport pe ultimul kilometru și construirea unei noi rețele de centre de sortare, care au fost optimizate pentru reducerea productivității și a costurilor. | Extractorul cu lanț LLM menține un echilibru între acoperirea cuprinzătoare a punctelor cheie și evitarea adâncimii inutile. Se adaptează dinamic la contextul interogării, astfel încât rezultatul este direct relevant și cuprinzător. |
| LLM Chain Filter: Ieșire de compresie contextuală | AWS (Amazon Web Services) a evoluat prin lansarea inițială fără funcții, dar repetarea rapidă pe baza feedback-ului clienților pentru a adăuga capabilitățile necesare. Această abordare a permis AWS să lanseze EC2 în 2006 cu funcții limitate și apoi să adauge continuu noi funcționalități, cum ar fi dimensiuni suplimentare ale instanțelor, centre de date, regiuni, opțiuni ale sistemului de operare, instrumente de monitorizare, echilibrare a încărcăturii, scalare automată și stocare persistentă. De-a lungul timpului, AWS s-a transformat dintr-un serviciu fără caracteristici într-o afacere de mai multe miliarde de dolari, concentrându-se pe nevoile clienților, agilitate, inovație, eficiență a costurilor și securitate. AWS are acum o rată anuală a veniturilor de 85 de miliarde de dolari și oferă peste 3,300 de funcții și servicii noi în fiecare an, oferind o gamă largă de clienți, de la start-up-uri la companii multinaționale și organizații din sectorul public. | Amazon are succes datorită modelelor sale de afaceri inovatoare, progreselor tehnologice continue și schimbărilor strategice organizaționale. Compania a perturbat constant industriile tradiționale prin introducerea de noi idei, cum ar fi o platformă de comerț electronic pentru diverse produse și servicii, o piață terță parte, servicii de infrastructură cloud (AWS), e-readerul Kindle și asistentul personal bazat pe voce Alexa. . În plus, Amazon a făcut modificări structurale pentru a-și îmbunătăți eficiența, cum ar fi reorganizarea rețelei sale de servicii de livrare din SUA pentru a reduce costurile și timpii de livrare, contribuind și mai mult la succesul său. | Similar cu extractorul de lanț LLM, filtrul de lanț LLM se asigură că, deși punctele cheie sunt acoperite, rezultatul este eficient pentru clienții care caută răspunsuri concise și contextuale. |
Comparând aceste tehnici diferite, putem observa că în contexte precum detalierea tranziției AWS de la un serviciu simplu la o entitate complexă, de mai multe miliarde de dolari sau explicarea succeselor strategice ale Amazon, lanțului obișnuit de retriever îi lipsește precizia oferită de tehnicile mai sofisticate, conducând la informații mai puțin țintite. Deși foarte puține diferențe sunt vizibile între tehnicile avansate discutate, acestea sunt cu mult mai informative decât lanțurile obișnuite de retriever.
Pentru clienții din industrii precum asistența medicală, telecomunicațiile și serviciile financiare care doresc să implementeze RAG în aplicațiile lor, limitările lanțului obișnuit de retriever în furnizarea de precizie, evitarea redundanței și comprimarea eficientă a informațiilor îl fac mai puțin potrivit pentru îndeplinirea acestor nevoi în comparație. la tehnicile mai avansate de recuperare a documentelor părinte și de compresie contextuală. Aceste tehnici sunt capabile să distileze cantități mari de informații în informații concentrate și de impact de care aveți nevoie, ajutând în același timp la îmbunătățirea raportului preț-performanță.
A curăța
Când ați terminat de rulat blocnotesul, ștergeți resursele pe care le-ați creat pentru a evita acumularea de taxe pentru resursele utilizate:
Concluzie
În această postare, am prezentat o soluție care vă permite să implementați tehnicile de recuperare a documentelor părinte și lanțul de compresie contextuală pentru a îmbunătăți capacitatea LLM-urilor de a procesa și genera informații. Am testat aceste tehnici avansate RAG cu modelele Mixtral-8x7B Instruct și BGE Large En disponibile cu SageMaker JumpStart. De asemenea, am explorat utilizarea stocării persistente pentru înglobare și bucăți de documente și integrarea cu depozitele de date ale întreprinderii.
Tehnicile pe care le-am efectuat nu numai că rafinează modul în care modelele LLM accesează și încorporează cunoștințele externe, ci și îmbunătățesc semnificativ calitatea, relevanța și eficiența rezultatelor lor. Combinând recuperarea din corpuri mari de text cu capabilitățile de generare a limbajului, aceste tehnici avansate RAG permit LLM-urilor să producă răspunsuri mai factice, coerente și mai adecvate contextului, îmbunătățindu-și performanța în diferite sarcini de procesare a limbajului natural.
SageMaker JumpStart este în centrul acestei soluții. Cu SageMaker JumpStart, obțineți acces la o gamă largă de modele cu sursă deschisă și închisă, simplificând procesul de începere cu ML și permițând experimentarea și implementarea rapidă. Pentru a începe implementarea acestei soluții, navigați la blocnotesul din GitHub repo.
Despre Autori
 Niithiyn Vijeaswaran este arhitect de soluții la AWS. Domeniul său de interes este AI generativ și AWS AI Accelerators. Deține o diplomă de licență în Informatică și Bioinformatică. Niithiyn lucrează îndeaproape cu echipa Generative AI GTM pentru a permite clienților AWS pe mai multe fronturi și pentru a accelera adoptarea AI generativă. Este un fan pasionat al lui Dallas Mavericks și îi place să colecteze pantofi sport.
Niithiyn Vijeaswaran este arhitect de soluții la AWS. Domeniul său de interes este AI generativ și AWS AI Accelerators. Deține o diplomă de licență în Informatică și Bioinformatică. Niithiyn lucrează îndeaproape cu echipa Generative AI GTM pentru a permite clienților AWS pe mai multe fronturi și pentru a accelera adoptarea AI generativă. Este un fan pasionat al lui Dallas Mavericks și îi place să colecteze pantofi sport.
 Sebastian Bustillo este arhitect de soluții la AWS. El se concentrează pe tehnologiile AI/ML cu o pasiune profundă pentru AI generativă și acceleratoare de calcul. La AWS, el îi ajută pe clienți să deblocheze valoarea afacerii prin IA generativă. Când nu este la serviciu, îi place să facă o ceașcă perfectă de cafea de specialitate și să exploreze lumea împreună cu soția sa.
Sebastian Bustillo este arhitect de soluții la AWS. El se concentrează pe tehnologiile AI/ML cu o pasiune profundă pentru AI generativă și acceleratoare de calcul. La AWS, el îi ajută pe clienți să deblocheze valoarea afacerii prin IA generativă. Când nu este la serviciu, îi place să facă o ceașcă perfectă de cafea de specialitate și să exploreze lumea împreună cu soția sa.
 Armando Diaz este arhitect de soluții la AWS. El se concentrează pe AI generativ, AI/ML și Data Analytics. La AWS, Armando ajută clienții să integreze în sistemele lor capabilități generative de IA de ultimă oră, încurajând inovația și avantajul competitiv. Când nu este la serviciu, îi place să petreacă timpul cu soția și familia sa, să facă drumeții și să călătorească prin lume.
Armando Diaz este arhitect de soluții la AWS. El se concentrează pe AI generativ, AI/ML și Data Analytics. La AWS, Armando ajută clienții să integreze în sistemele lor capabilități generative de IA de ultimă oră, încurajând inovația și avantajul competitiv. Când nu este la serviciu, îi place să petreacă timpul cu soția și familia sa, să facă drumeții și să călătorească prin lume.
 Dr. Farooq Sabir este arhitect senior de soluții specializat în inteligență artificială și învățare automată la AWS. El deține diplome de doctorat și master în inginerie electrică de la Universitatea din Texas din Austin și un master în informatică de la Georgia Institute of Technology. Are peste 15 ani de experiență în muncă și, de asemenea, îi place să predea și să îndrume studenții. La AWS, el îi ajută pe clienți să-și formuleze și să-și rezolve problemele de afaceri în știința datelor, învățarea automată, viziunea computerizată, inteligența artificială, optimizarea numerică și domeniile conexe. Cu sediul în Dallas, Texas, lui și familia lui le place să călătorească și să plece în călătorii lungi.
Dr. Farooq Sabir este arhitect senior de soluții specializat în inteligență artificială și învățare automată la AWS. El deține diplome de doctorat și master în inginerie electrică de la Universitatea din Texas din Austin și un master în informatică de la Georgia Institute of Technology. Are peste 15 ani de experiență în muncă și, de asemenea, îi place să predea și să îndrume studenții. La AWS, el îi ajută pe clienți să-și formuleze și să-și rezolve problemele de afaceri în știința datelor, învățarea automată, viziunea computerizată, inteligența artificială, optimizarea numerică și domeniile conexe. Cu sediul în Dallas, Texas, lui și familia lui le place să călătorească și să plece în călătorii lungi.
 Marco Punio este un arhitect de soluții axat pe strategia generativă de inteligență artificială, soluții aplicate de inteligență artificială și care efectuează cercetări pentru a ajuta clienții să se extindă pe AWS. Marco este un consilier digital nativ în cloud cu experiență în FinTech, Healthcare & Life Sciences, Software-as-a-service și, cel mai recent, în industriile de telecomunicații. Este un tehnolog calificat cu o pasiune pentru învățarea automată, inteligența artificială și fuziuni și achiziții. Marco are sediul în Seattle, WA și îi place să scrie, să citească, să facă exerciții și să creeze aplicații în timpul liber.
Marco Punio este un arhitect de soluții axat pe strategia generativă de inteligență artificială, soluții aplicate de inteligență artificială și care efectuează cercetări pentru a ajuta clienții să se extindă pe AWS. Marco este un consilier digital nativ în cloud cu experiență în FinTech, Healthcare & Life Sciences, Software-as-a-service și, cel mai recent, în industriile de telecomunicații. Este un tehnolog calificat cu o pasiune pentru învățarea automată, inteligența artificială și fuziuni și achiziții. Marco are sediul în Seattle, WA și îi place să scrie, să citească, să facă exerciții și să creeze aplicații în timpul liber.
 AJ Dhimine este arhitect de soluții la AWS. El este specializat în IA generativă, calcul fără server și analiza datelor. El este un membru/mentor activ în comunitatea de domeniu tehnic de învățare automată și a publicat mai multe lucrări științifice pe diverse subiecte AI/ML. Lucrează cu clienți, de la start-up-uri la întreprinderi, pentru a dezvolta AWSome soluții AI generative. Este deosebit de pasionat de utilizarea modelelor de limbaj mari pentru analiza avansată a datelor și de explorarea aplicațiilor practice care abordează provocările din lumea reală. În afara serviciului, lui AJ îi place să călătorească și se află în prezent în 53 de țări cu scopul de a vizita fiecare țară din lume.
AJ Dhimine este arhitect de soluții la AWS. El este specializat în IA generativă, calcul fără server și analiza datelor. El este un membru/mentor activ în comunitatea de domeniu tehnic de învățare automată și a publicat mai multe lucrări științifice pe diverse subiecte AI/ML. Lucrează cu clienți, de la start-up-uri la întreprinderi, pentru a dezvolta AWSome soluții AI generative. Este deosebit de pasionat de utilizarea modelelor de limbaj mari pentru analiza avansată a datelor și de explorarea aplicațiilor practice care abordează provocările din lumea reală. În afara serviciului, lui AJ îi place să călătorească și se află în prezent în 53 de țări cu scopul de a vizita fiecare țară din lume.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

