À medida que as empresas recolhem quantidades crescentes de dados de diversas fontes, a estrutura e a organização desses dados necessitam muitas vezes de mudar ao longo do tempo para satisfazer as necessidades analíticas em evolução. No entanto, alterar partições de esquema e tabela em data lakes tradicionais pode ser uma tarefa demorada e perturbadora, exigindo renomeação ou recriação de tabelas inteiras e reprocessamento de grandes conjuntos de dados. Isso dificulta a agilidade e o tempo para obter insights.
A evolução do esquema permite adicionar, excluir, renomear ou modificar colunas sem a necessidade de reescrever os dados existentes. Isto é fundamental para que empresas em rápida evolução aumentem as estruturas de dados para suportar novos casos de uso. Por exemplo, uma empresa de comércio eletrônico pode adicionar novos atributos demográficos de clientes ou sinalizadores de status de pedidos para enriquecer as análises. Iceberg Apache gerencia essas alterações de esquema de maneira compatível com versões anteriores por meio de sua arquitetura inovadora de evolução de tabela de metadados.
Da mesma forma, a evolução da partição permite adicionar, eliminar ou dividir partições sem problemas. Por exemplo, um mercado de comércio eletrônico pode inicialmente particionar os dados dos pedidos por dia. À medida que os pedidos se acumulam e a consulta por dia se torna ineficiente, eles podem ser divididos em partições diárias e de ID do cliente. O particionamento de tabelas organiza grandes conjuntos de dados de forma mais eficiente para desempenho de consulta. O Iceberg oferece às empresas a flexibilidade para ajustar partições de forma incremental, em vez de exigir procedimentos tediosos de reconstrução. Novas partições podem ser adicionadas de maneira totalmente compatível, sem tempo de inatividade ou necessidade de reescrever arquivos de dados existentes.
Esta postagem demonstra como você pode aproveitar o Iceberg, Serviço de armazenamento simples da Amazon (Amazon S3), Cola AWS, Formação AWS Lake e Gerenciamento de acesso e identidade da AWS (IAM) para implementar um data lake transacional que suporte uma evolução contínua. Ao permitir ajustes fáceis de esquema e partição à medida que os insights de dados evoluem, você pode se beneficiar da flexibilidade preparada para o futuro necessária para o sucesso dos negócios.
Visão geral da solução
Para nosso exemplo de caso de uso, uma grande empresa fictícia de comércio eletrônico processa milhares de pedidos todos os dias. Quando os pedidos são recebidos, atualizados, cancelados, enviados, entregues ou devolvidos, as alterações são feitas no sistema local e essas alterações precisam ser replicadas em um data lake S3 para que os analistas de dados possam executar consultas por meio de Amazona atena. As alterações também podem conter atualizações de esquema. Devido aos requisitos de segurança de diferentes organizações, elas precisam gerenciar o controle de acesso refinado para os analistas por meio do Lake Formation.
O diagrama a seguir ilustra a arquitetura da solução.
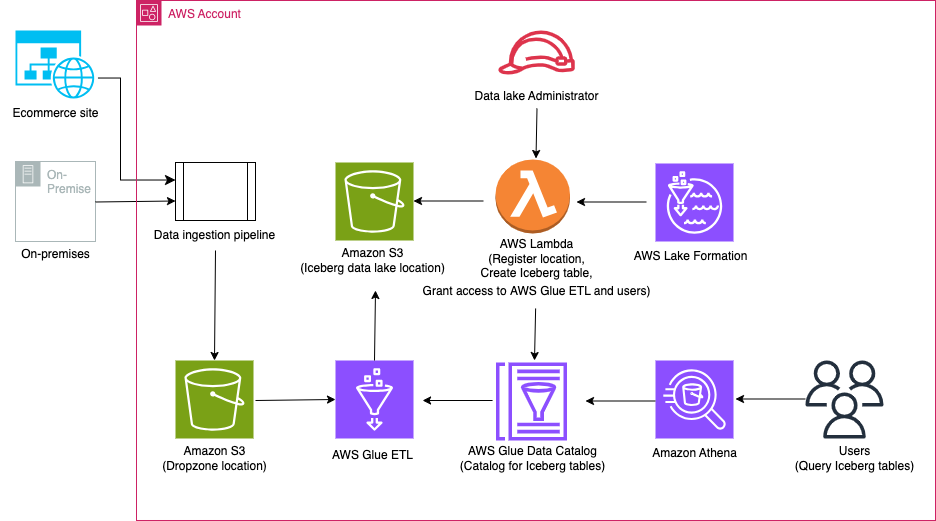
O fluxo de trabalho da solução inclui as seguintes etapas principais:
- Ingerir dados locais em um local Dropzone usando um pipeline de ingestão de dados.
- Mescle os dados do local Dropzone no Iceberg usando AWS Glue.
- Consulte os dados usando o Athena.
Pré-requisitos
Para este passo a passo, você deve ter os seguintes pré-requisitos:
Configure a infraestrutura com AWS CloudFormation
Para criar sua infraestrutura com um Formação da Nuvem AWS modelo, conclua as seguintes etapas:
- Faça login como administrador em sua conta AWS.
- Abra o console do AWS CloudFormation.
- Escolha Pilha de Lançamento:

- Escolha Nome da pilha, insira um nome (para esta postagem, icebergdemo1).
- Escolha Próximo.
- Forneça informações para os seguintes parâmetros:
DatalakeUserNameDatalakeUserPasswordDatabaseNameTableNameDatabaseLFTagKeyDatabaseLFTagValueTableLFTagKeyTableLFTagValue
- Escolha Próximo.
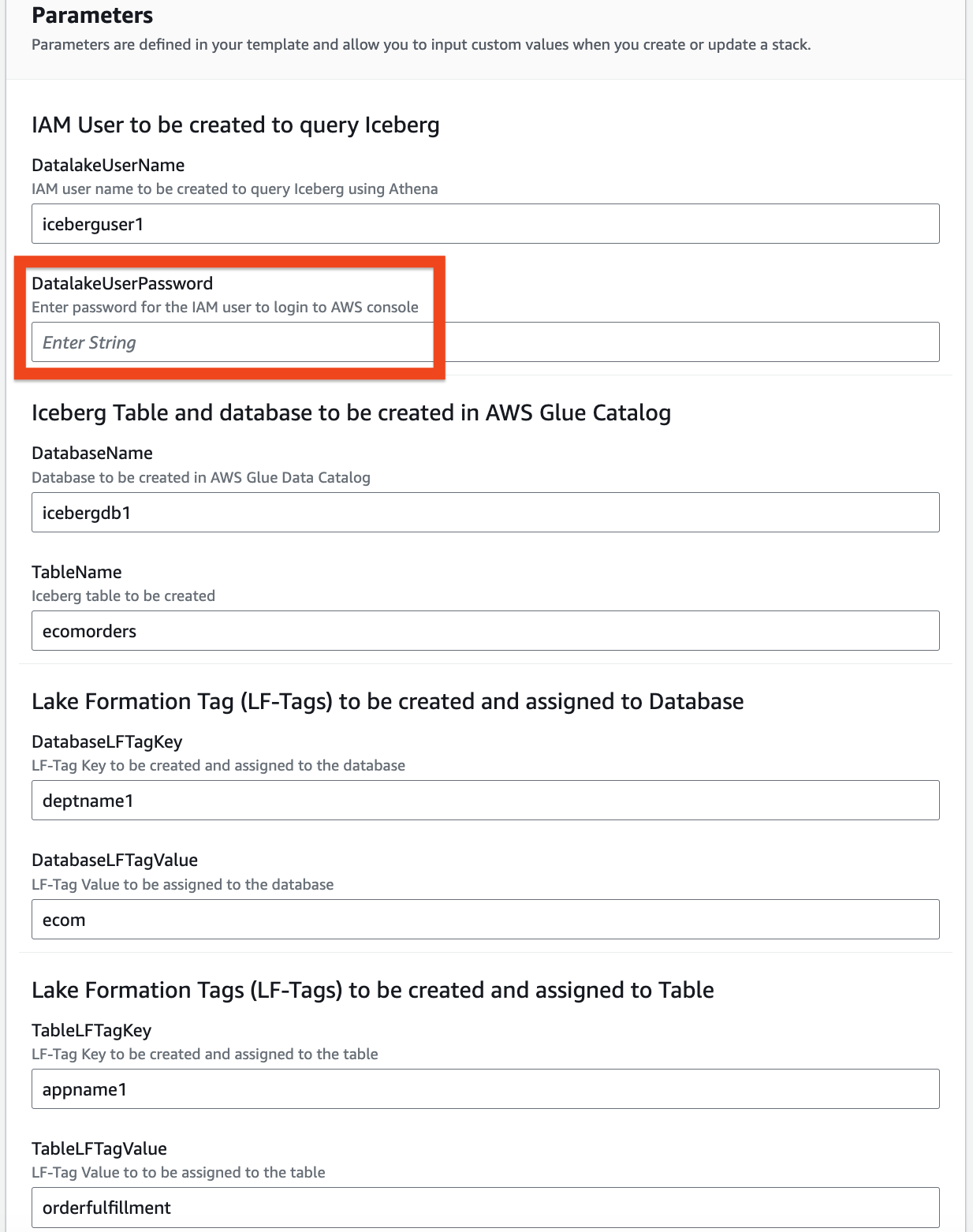
- Escolha Próximo novamente.
- No Avaliações seção, revise os valores inseridos.
- Selecionar Eu reconheço que o AWS CloudFormation pode criar recursos IAM com nomes personalizados e escolha Submeter.
Em alguns minutos, o status da pilha mudará para CREATE_COMPLETE.
Você pode ir para o Guia Saídas da pilha para ver todos os recursos provisionados. Os recursos são prefixados com o nome da pilha que você forneceu (para esta postagem, icebergdemo1).
Crie uma tabela Iceberg usando Lambda e conceda acesso usando Lake Formation
Para criar uma tabela Iceberg e conceder acesso a ela, conclua as seguintes etapas:
- Navegue até a Recursos guia da pilha CloudFormation icebergdemo1 e pesquise o ID lógico denominado
LambdaFunctionIceberg. - Escolha o hiperlink do ID físico associado.
Você é redirecionado para a função Lambda icebergdemo1-Lambda-Create-Iceberg-and-Grant-access.
- No Configuração guia, escolha Variáveis ambientais no painel esquerdo.

- No Code guia, você pode inspecionar o código da função.
A função usa o SDK da AWS para Python (Boto3) APIs para provisionar os recursos. Ele assume a função de administrador do data lake provisionado para executar as seguintes tarefas:
- Conceda DATA_LOCATION_ACCESS acesso à função de administrador do data lake no local registrado do data lake
- Crie Tags de formação de lago (LF-Tags)
- Crie um banco de dados no AWS Glue Data Catalog usando o AWS Glue CREATE_DATABASE API
- Atribuir LF-Tags ao banco de dados
- Conceda acesso DESCRIBE no banco de dados usando tags LF ao usuário IAM do data lake e à função AWS Glue ETL IAM
- Crie uma tabela Iceberg usando o AWS Glue criar a tabela API:
- Atribuir LF-Tags à mesa
- Conceda tags LF DESCRIBE e SELECT na tabela Iceberg para o usuário IAM do data lake
- Conceda acesso ALL, DESCRIBE, SELECT, INSERT, DELETE e ALTER nas tags LF da tabela Iceberg para a função AWS Glue ETL IAM
- No Test guia, escolha Test para executar a função.

Quando a função for concluída, você verá a mensagem “Executando função: bem-sucedida”.
Lake Formation ajuda você a gerenciar centralmente, proteger e compartilhar dados globalmente para análise e aprendizado de máquina. Com o Lake Formation, você pode gerenciar o controle de acesso refinado para os dados do data lake no Amazon S3 e seus metadados no Data Catalog.
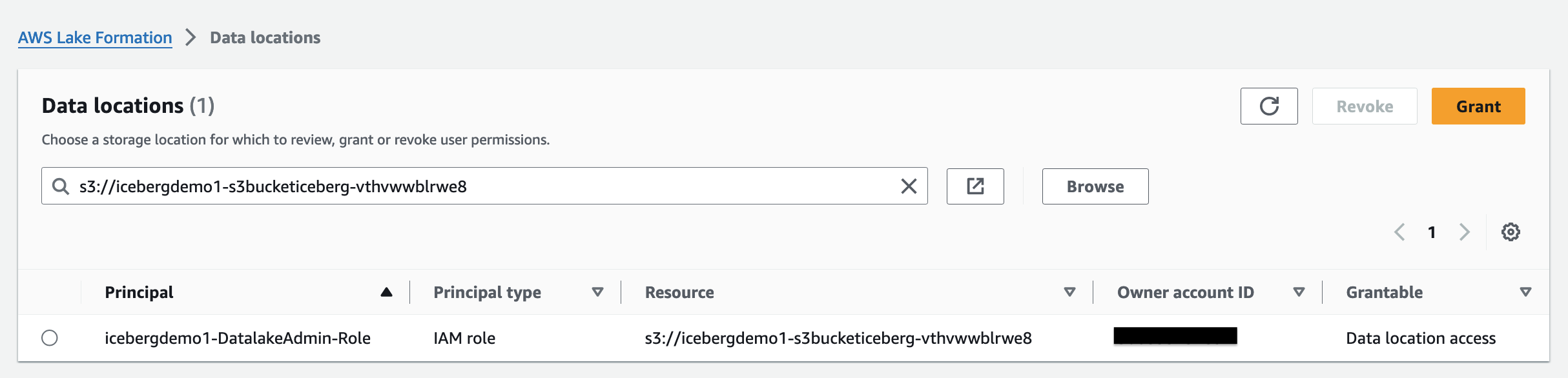
Para adicionar um local do Amazon S3 como armazenamento Iceberg em seu data lake, cadastre o local com formação de lago. Você pode então usar permissões do Lake Formation para controle de acesso refinado aos objetos do Data Catalog que apontam para esse local e para os dados subjacentes no local.
A pilha do CloudFormation registrou a localização do data lake.

Permissões de localização de dados no Lake Formation permitem que os principais criem e alterem recursos do Data Catalog que apontam para os locais registrados designados do Amazon S3. As permissões de localização de dados funcionam além do Lake Formation permissões de dados para proteger informações em seu data lake.
Controle de acesso baseado em tag Lake Formation (LF-TBAC) é uma estratégia de autorização que define permissões com base em atributos. Em Lake Formation, esses atributos são chamados de LF-Tags. Você pode anexar tags LF a recursos do Data Catalog, entidades principais do Lake Formation e colunas de tabela. Você pode atribuir e revogar permissões em recursos do Lake Formation usando essas LF-Tags. O Lake Formation permite operações nesses recursos quando a tag do principal corresponde à tag do recurso.
Verifique a tabela Iceberg no console do Lake Formation
Para verificar a tabela Iceberg, execute as seguintes etapas:
- No console do Lake Formation, escolha Bases de dados no painel de navegação.
- Abra a página de detalhes de
icebergdb1.
Você pode ver as LF-Tags do banco de dados associado.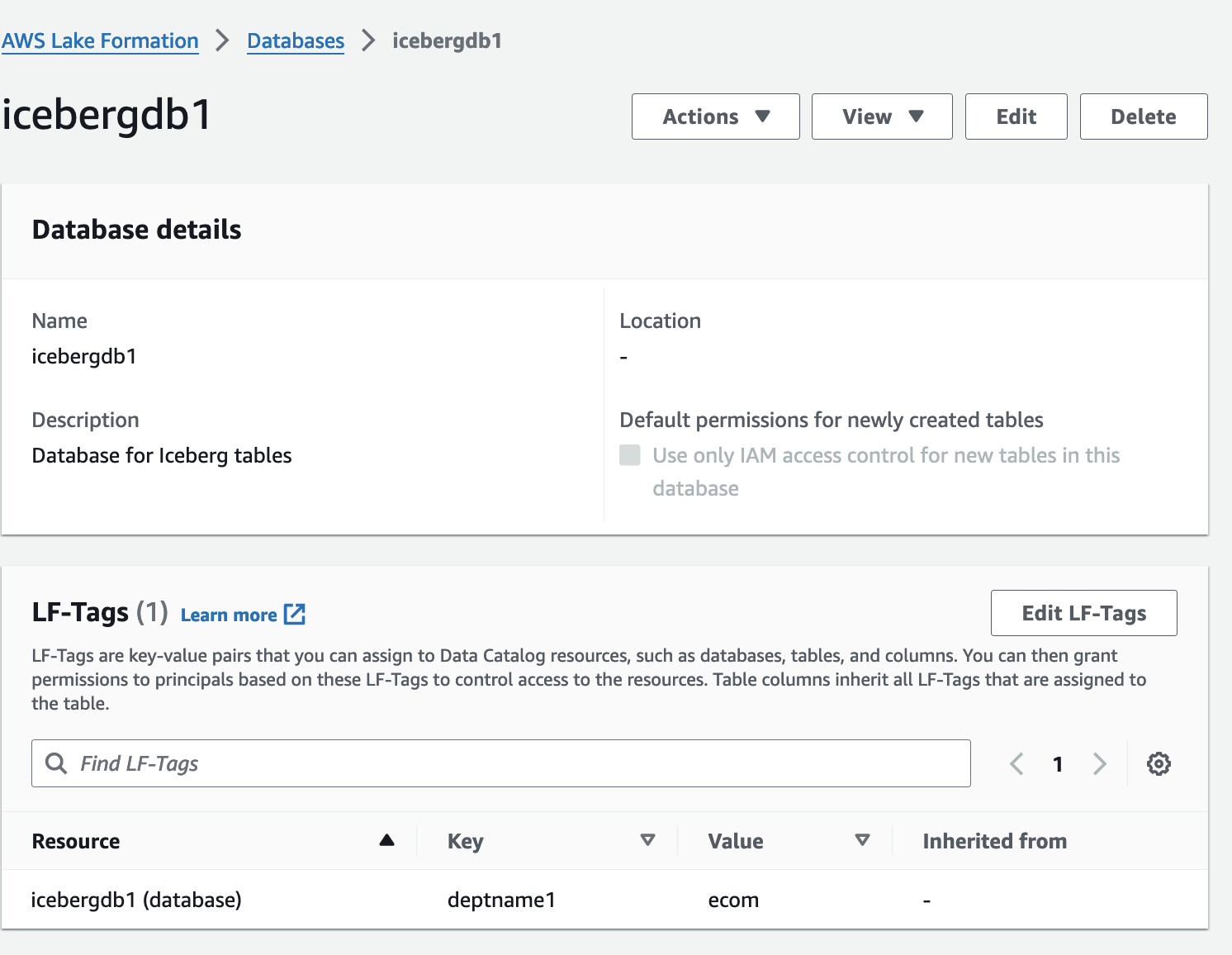
- Escolha Tabelas no painel de navegação.
- Abra a página de detalhes de
ecomorders.
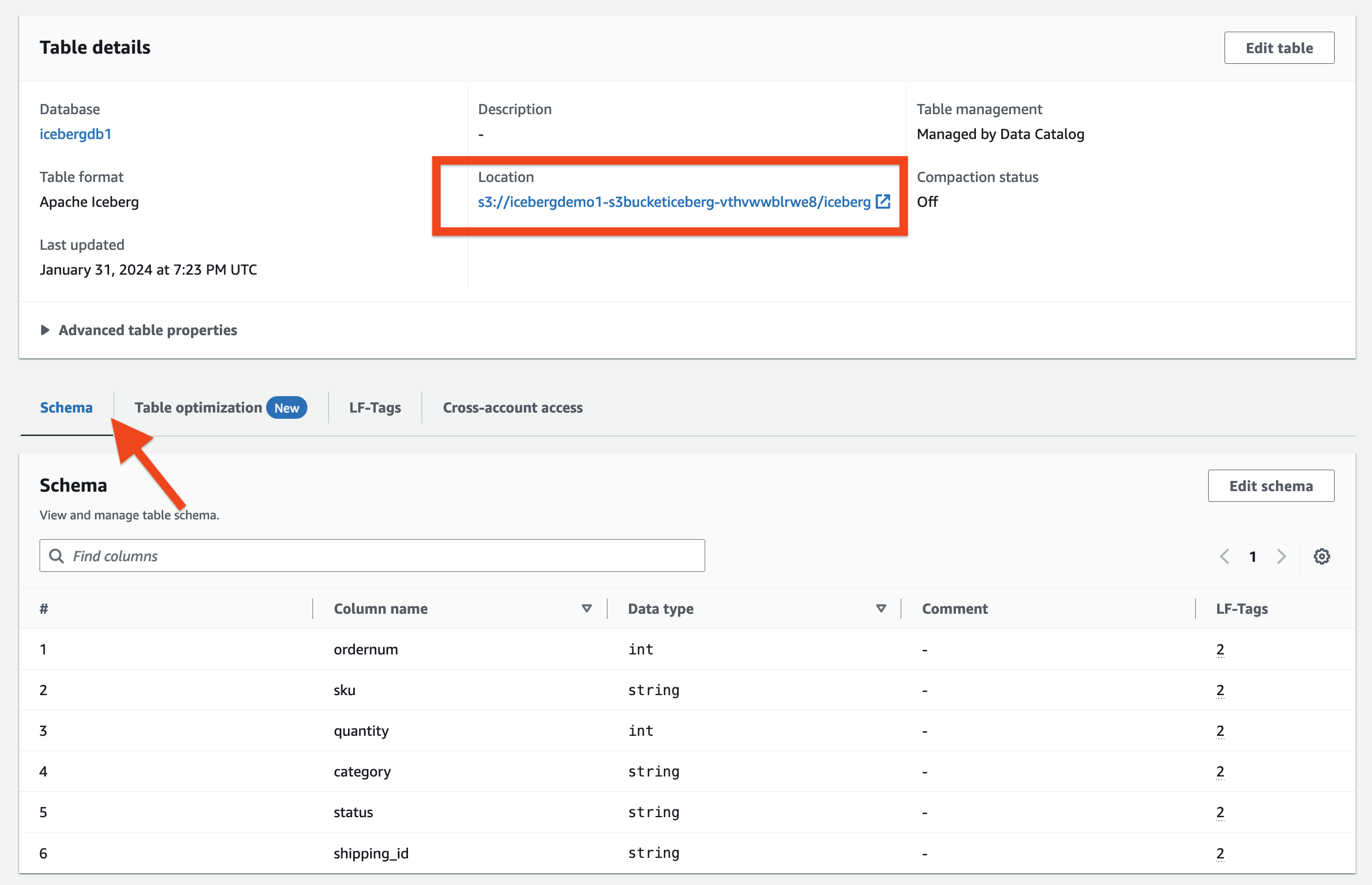
No Detalhes da mesa seção, você pode observar o seguinte:
- Formato de tabela mostra como Iceberg Apache
- Gerenciamento de tabela mostra como Gerenciado pelo Catálogo de Dados
- Localização lista a localização do data lake da tabela Iceberg
No Tags LF seção, você pode ver a tabela associada LF-Tags.
No Detalhes da mesa seção, expandir Propriedades avançadas da tabela para visualizar o seguinte:
metadata_locationaponta para a localização do arquivo de metadados da tabela Icebergtable_typemostra comoICEBERG
No Esquema guia, você pode visualizar as colunas definidas na tabela Iceberg.
Integre o Iceberg ao catálogo de dados do AWS Glue e ao Amazon S3
O Iceberg rastreia arquivos de dados individuais em uma tabela em vez de diretórios. Quando há um commit explícito na tabela, o Iceberg cria arquivos de dados e os adiciona à tabela. Iceberg mantém o estado da tabela em arquivos de metadados. Qualquer alteração no estado da tabela cria um novo arquivo de metadados que substitui atomicamente os metadados mais antigos. Os arquivos de metadados rastreiam o esquema da tabela, a configuração de particionamento e outras propriedades.
O Iceberg exige que os sistemas de arquivos que suportam as operações sejam compatíveis com armazenamentos de objetos como o Amazon S3.
Iceberg cria instantâneos para o conteúdo da tabela. Cada instantâneo é um conjunto completo de arquivos de dados na tabela em um determinado momento. Os arquivos de dados em instantâneos são armazenados em um ou mais arquivos de manifesto que contêm uma linha para cada arquivo de dados na tabela, seus dados de partição e suas métricas.
O diagrama a seguir ilustra essa hierarquia.
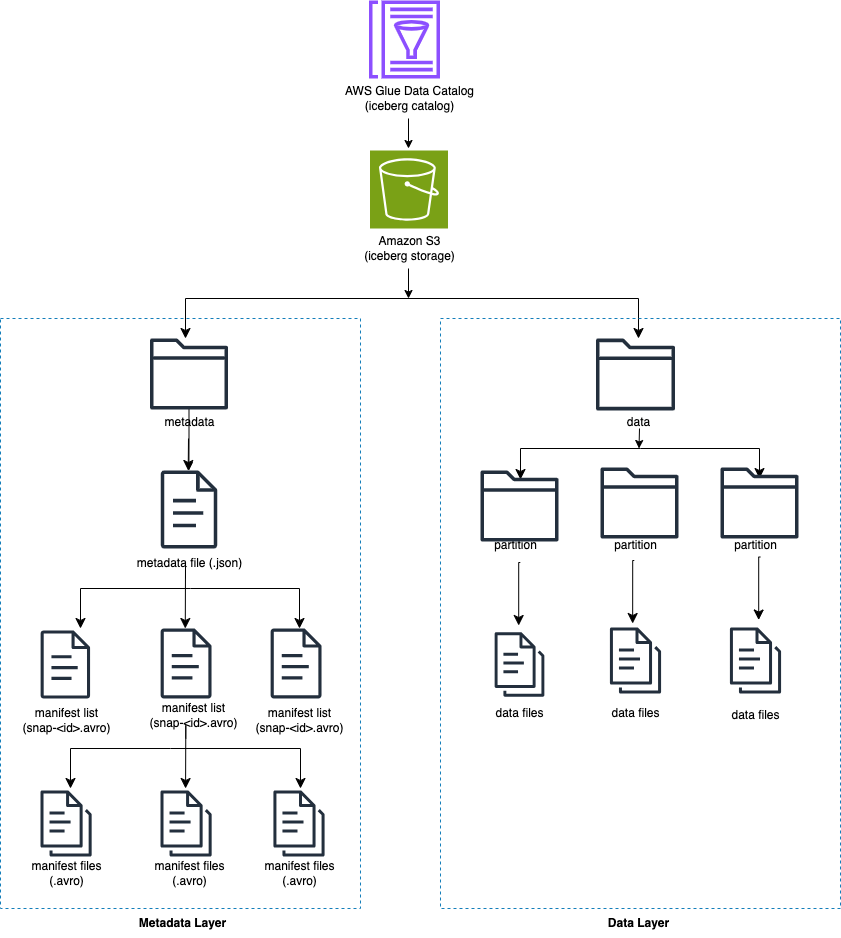
Quando você cria uma tabela Iceberg, ela cria primeiro a pasta de metadados e um arquivo de metadados na pasta de metadados. A pasta de dados é criada quando você carrega dados na tabela Iceberg.

Conteúdo do arquivo de metadados Iceberg
O arquivo de metadados Iceberg contém muitas informações, incluindo o seguinte:
- versão de formato –Versão da mesa Iceberg
- Localização – Localização da tabela no Amazon S3
- Esquemas – Nome e tipo de dados de todas as colunas da tabela
- especificações de partição – Colunas particionadas
- ordens de classificação – Ordem de classificação das colunas
- Propriedades – Propriedades da tabela
- ID do instantâneo atual – Instantâneo atual
- árbitros – Referências de tabelas
- snapshots – Lista de instantâneos, cada um contendo as seguintes informações:
- número sequencial – Número sequencial de instantâneos em ordem cronológica (o número mais alto representa o instantâneo atual, 1 para o primeiro instantâneo)
- ID do instantâneo – ID do instantâneo
- carimbo de data/hora-ms – Carimbo de data e hora em que o snapshot foi confirmado
- resumo – Resumo das alterações comprometidas
- lista de manifestos – Lista de manifestos; este nome de arquivo começa com snap-< snapshot-id >
- ID do esquema – Número de sequência do esquema em ordem cronológica (o número mais alto representa o esquema atual)
- log de instantâneo – Lista de instantâneos em ordem cronológica
- log de metadados – Lista de arquivos de metadados em ordem cronológica
O arquivo de metadados contém todas as alterações históricas nos dados e esquema da tabela. A revisão direta do conteúdo do arquivo metarquivo pode ser uma tarefa demorada. Felizmente, você pode consultar o Metadados do iceberg usando Athena.
Estrutura Iceberg no AWS Glue
O AWS Glue 4.0 oferece suporte a tabelas Iceberg registradas no Lake Formation. Nos trabalhos de ETL do AWS Glue, você precisa do código a seguir para habilitar a estrutura Iceberg:
Para acesso de leitura/gravação aos dados subjacentes, além das permissões do Lake Formation, a função AWS Glue IAM para executar os trabalhos de ETL do AWS Glue foi concedida formação de lago: GetDataAccess Permissão IAM. Com essa permissão, Lake Formation concede a solicitação de credenciais temporárias para acessar os dados.
A pilha do CloudFormation provisionou os quatro trabalhos de ETL do AWS Glue para você. O nome de cada trabalho começa com o nome da pilha (icebergdemo1). Conclua as etapas a seguir para visualizar as tarefas:
- Faça login como administrador em sua conta AWS.
- No console AWS Glue, escolha Trabalhos de ETL no painel de navegação.
- Procure empregos com
icebergdemo1no nome.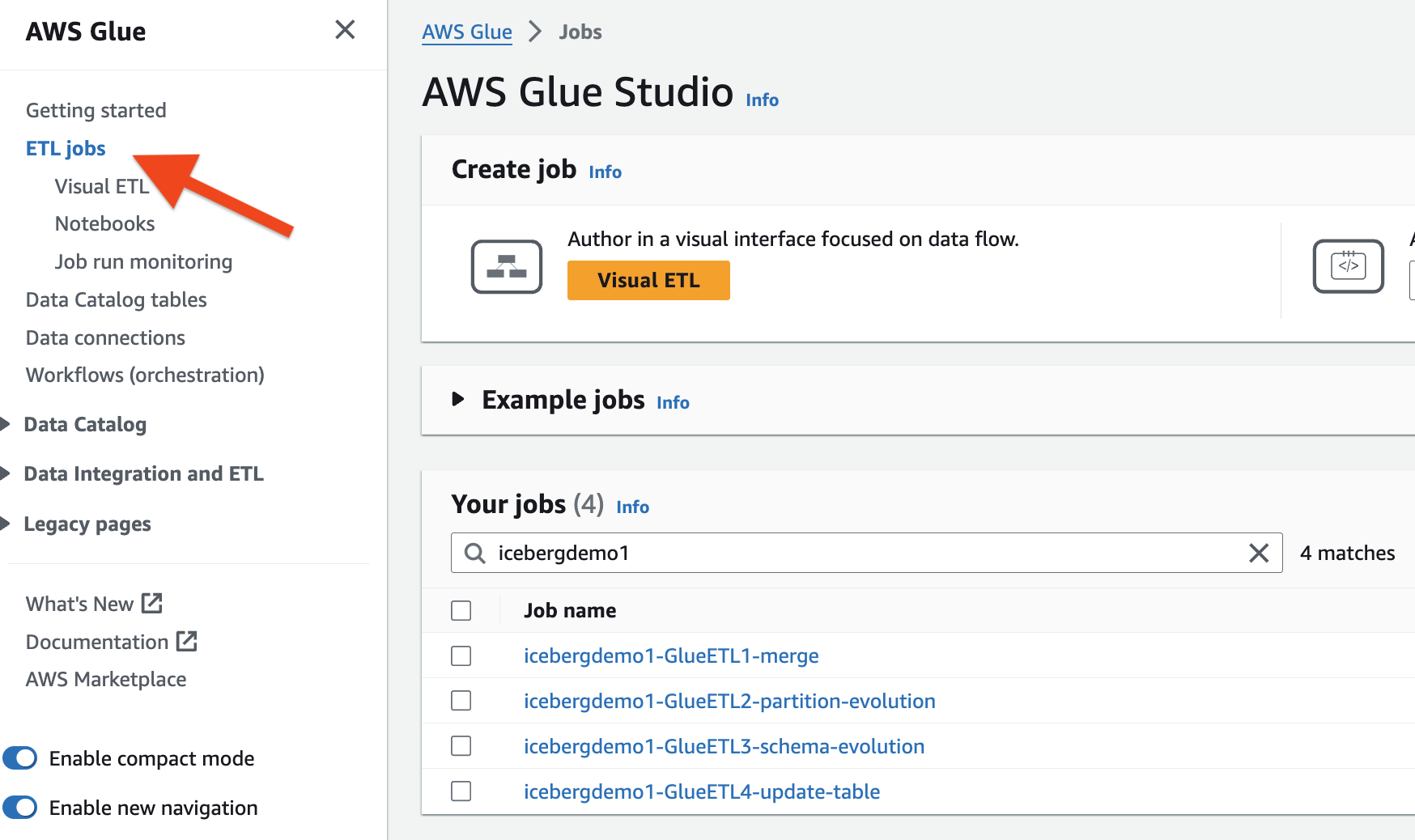
Mesclar dados do Dropzone na tabela Iceberg
Para nosso caso de uso, a empresa ingere dados de pedidos de comércio eletrônico diariamente de seu local local para um local Amazon S3 Dropzone. A pilha do CloudFormation carregou três arquivos com pedidos de amostra durante 3 dias, conforme mostrado nas figuras a seguir. Você vê os dados no local Dropzone s3://icebergdemo1-s3bucketdropzone-kunftrcblhsk/data.
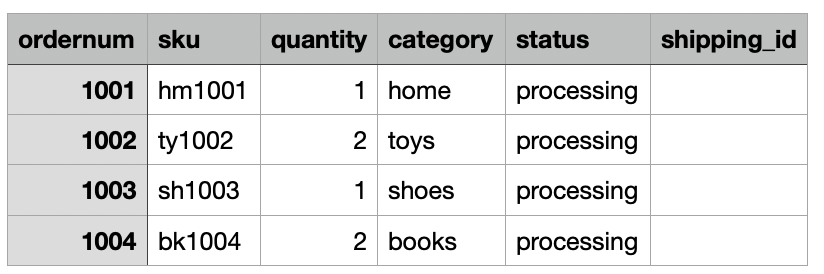


O trabalho de ETL do AWS Glue icebergdemo1-GlueETL1-merge será executado diariamente para mesclar os dados na tabela Iceberg. Possui a seguinte lógica para adicionar ou atualizar os dados no Iceberg:
- Crie um Spark DataFrame a partir dos dados de entrada:
- Para um novo pedido, adicione-o à tabela
- Se a tabela tiver uma ordem correspondente, atualize o status e
shipping_id:
Conclua as etapas a seguir para executar o trabalho de mesclagem do AWS Glue:
- No console AWS Glue, escolha Trabalhos de ETL no painel de navegação.
- Selecione o trabalho ETL
icebergdemo1-GlueETL1-merge. - No Opções menu suspenso, escolha Execute com parâmetros.
- No Executar parâmetros página, vá para Parâmetros de trabalho.
- Para o
--dropzone_pathparâmetro, forneça a localização S3 dos dados de entrada (icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge1). - Execute o trabalho para adicionar todos os pedidos: 1001, 1002, 1003 e 1004.
- Para o
--dropzone_path parameter, altere o local do S3 paraicebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge2. - Execute a tarefa novamente para adicionar os pedidos 2001 e 2002 e atualizar os pedidos 1001, 1002 e 1003.
- Para o
--dropzone_pathparâmetro, altere a localização do S3 paraicebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge3. - Execute a tarefa novamente para adicionar o pedido 3001 e atualizar os pedidos 1001, 1003, 2001 e 2002.
Vá para a pasta de dados da tabela para ver os arquivos de dados escritos pelo Iceberg quando você mesclou os dados na tabela usando o trabalho Glue ETL icebergdemo1-GlueETL1-merge.

Consultar Iceberg usando Athena
A pilha do CloudFormation criou o usuário IAM iceberguser1, que tem acesso de leitura na tabela Iceberg usando LF-Tags. Para consultar o Iceberg usando o Athena por meio deste usuário, conclua as seguintes etapas:
- Entrar como
iceberguser1ao Console de gerenciamento da AWS. - No console Athena, escolha Grupos de Trabalho no painel de navegação.
- Localize o grupo de trabalho provisionado pelo CloudFormation (
icebergdemo1-workgroup) - Verifique a versão 3 do mecanismo Athena.
O mecanismo Athena versão 3 suporta Formatos de arquivo iceberg, incluindo Parquet, ORC e Avro.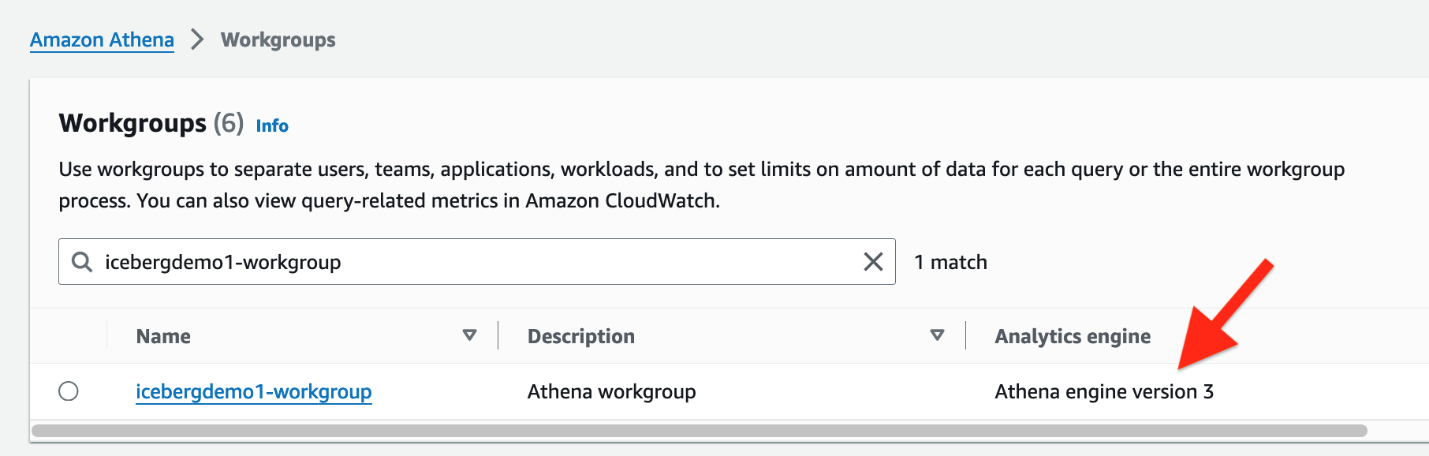
- Acesse o editor de consultas do Athena.
- Escolha o grupo de trabalho icebergdemo1-workgroup no menu suspenso.
- Escolha banco de dados, escolha
icebergdb1. Você verá a mesaecomorders. - Execute a seguinte consulta para ver os dados na tabela Iceberg:
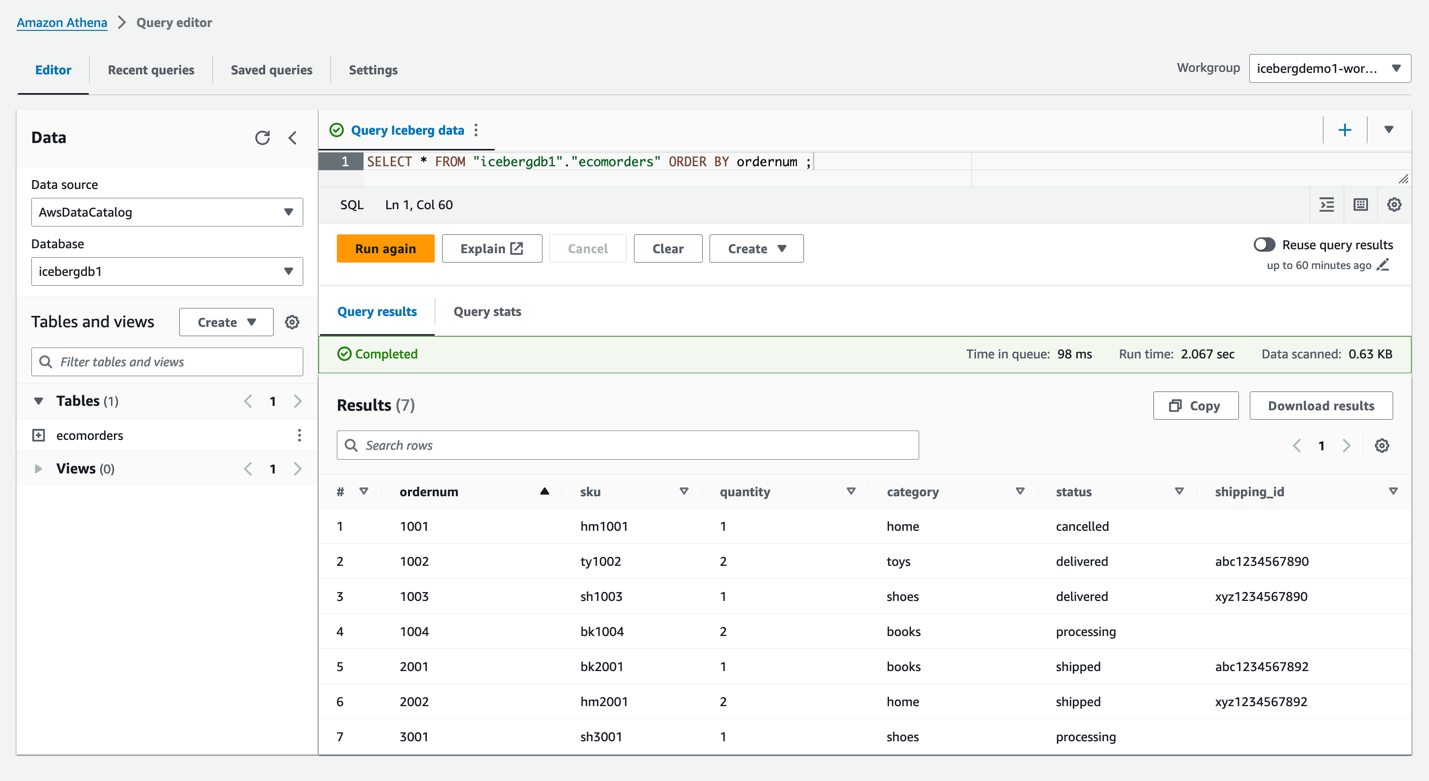
- Execute a seguinte consulta para ver as partições atuais da tabela:
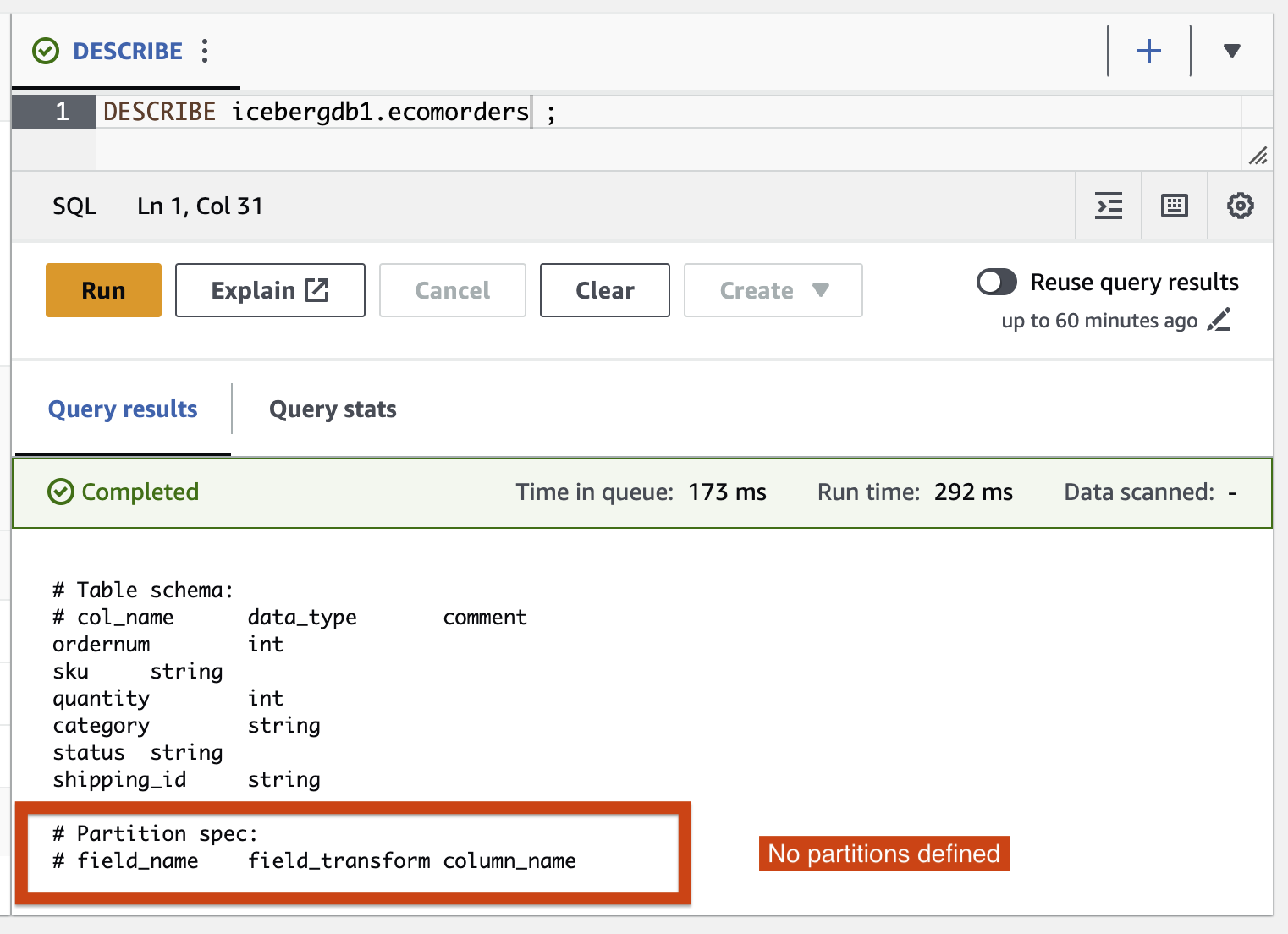
Especificação de partição descreve como a tabela é particionada. Neste exemplo, não há campos particionados porque você não definiu nenhuma partição na tabela.
Evolução da partição do iceberg
Talvez seja necessário alterar sua estrutura de partição; por exemplo, devido a mudanças de tendências de padrões de consulta comuns em análises downstream. Uma mudança na estrutura de partição de tabelas tradicionais é uma operação significativa que requer uma cópia completa dos dados.
Iceberg torna isso simples. Quando você altera a estrutura da partição no Iceberg, não é necessário reescrever os arquivos de dados. Os dados antigos gravados com partições anteriores permanecem inalterados. Novos dados são gravados usando as novas especificações em um novo layout. Os metadados de cada uma das versões da partição são mantidos separadamente.
Vamos adicionar a categoria do campo de partição à tabela Iceberg usando o trabalho AWS Glue ETL icebergdemo1-GlueETL2-partition-evolution:
No console do AWS Glue, execute o trabalho ETL icebergdemo1-GlueETL2-partition-evolution. Quando o trabalho for concluído, você poderá consultar partições usando o Athena.
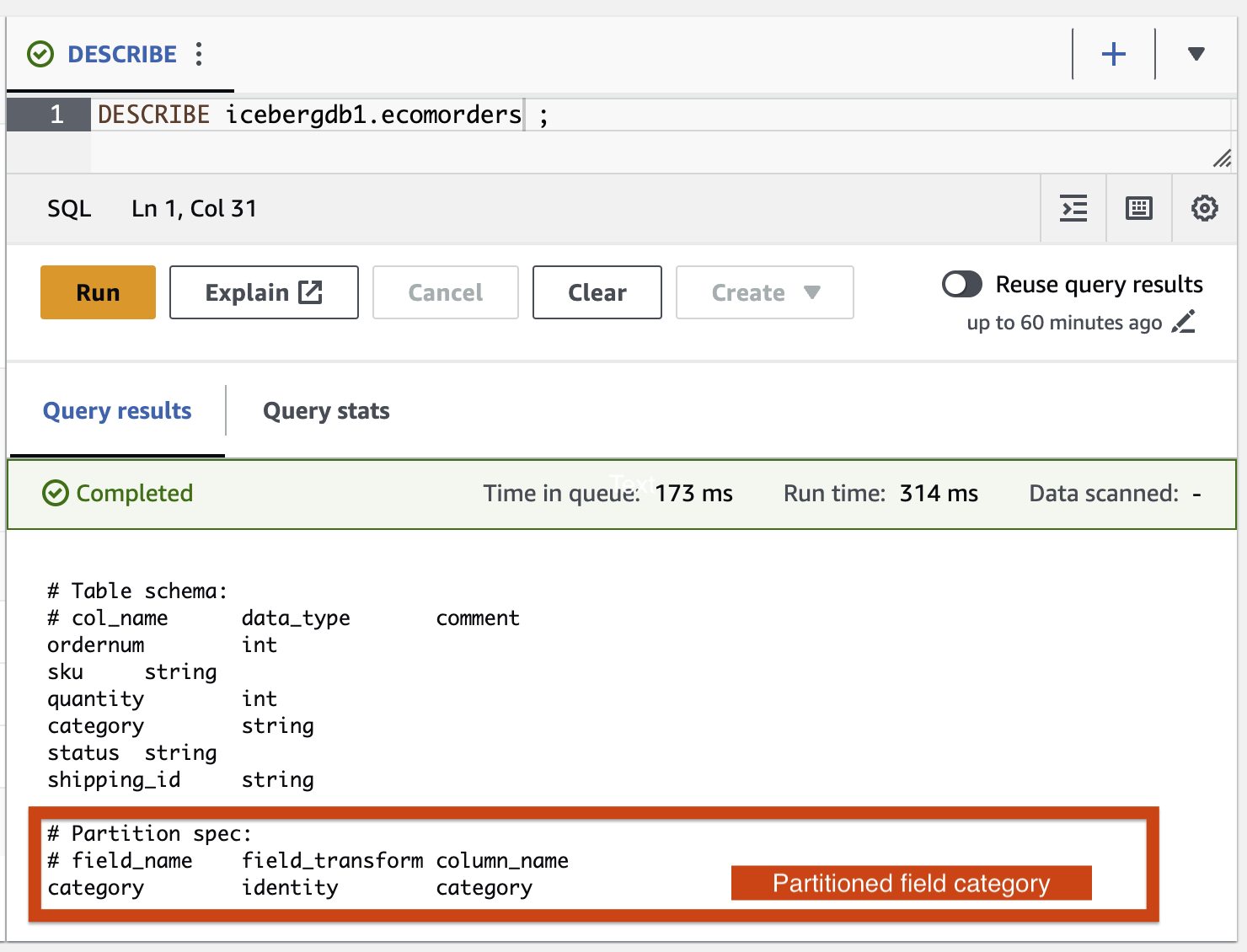
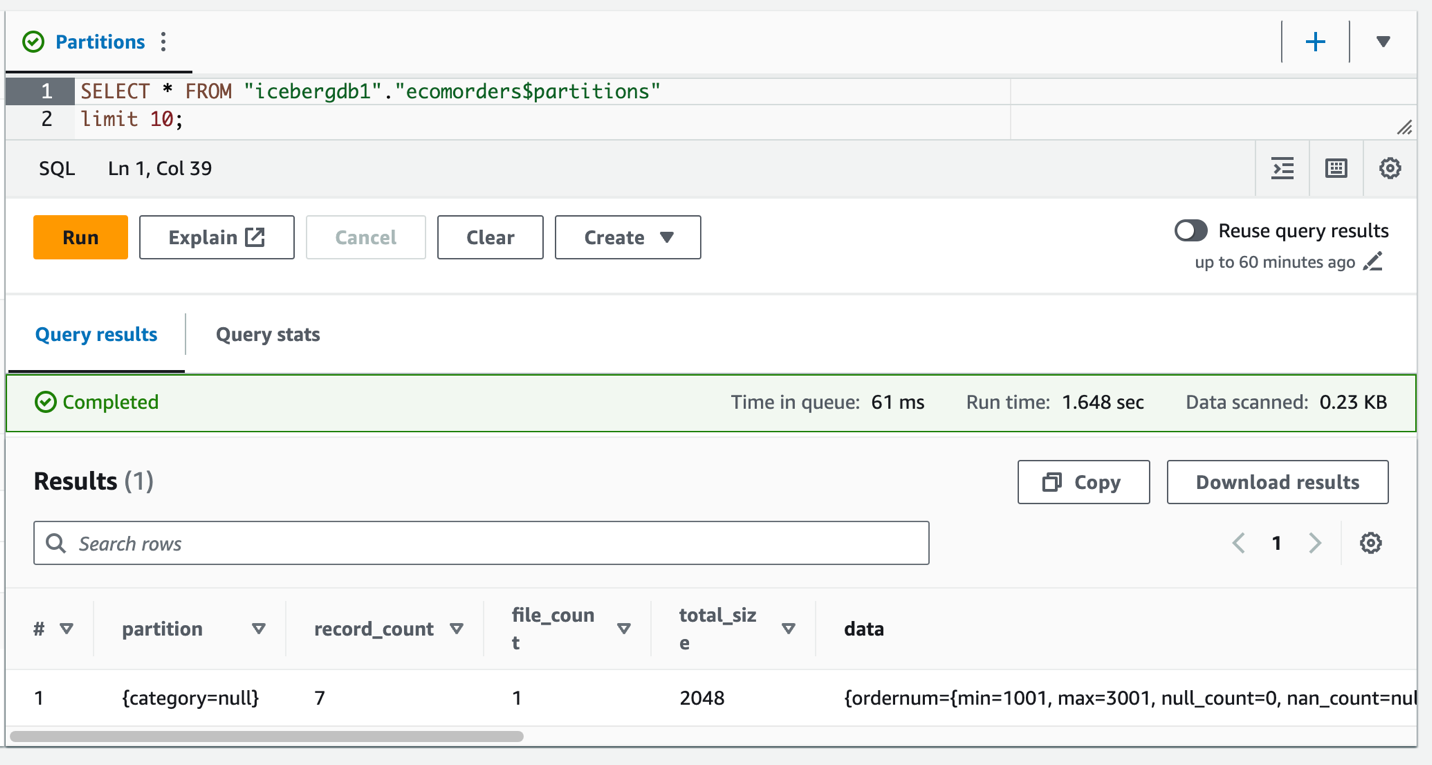
Você pode ver a categoria do campo de partição, mas os valores da partição são nulos. Não há novos arquivos de dados na pasta de dados, porque a evolução da partição é uma operação de metadados e não reescreve arquivos de dados. Ao adicionar ou atualizar dados, você verá os valores de partição correspondentes preenchidos.
Evolução do esquema Iceberg
Iceberg oferece suporte à evolução de tabelas no local. Você pode evoluir um esquema de tabela assim como SQL. As atualizações do esquema Iceberg são alterações de metadados, portanto, nenhum arquivo de dados precisa ser reescrito para realizar a evolução do esquema.
Para explorar a evolução do esquema Iceberg, execute o trabalho ETL icebergdemo1-GlueETL3-schema-evolution por meio do console do AWS Glue. O trabalho executa as seguintes instruções SparkSQL:
No editor de consultas do Athena, execute a seguinte consulta:

Você pode verificar as alterações de esquema na tabela Iceberg:
- Uma nova coluna foi adicionada chamada
shipping_carrier - A coluna
shipping_idfoi renomeado paratracking_number - O tipo de dados da coluna
ordernummudou de int para bigint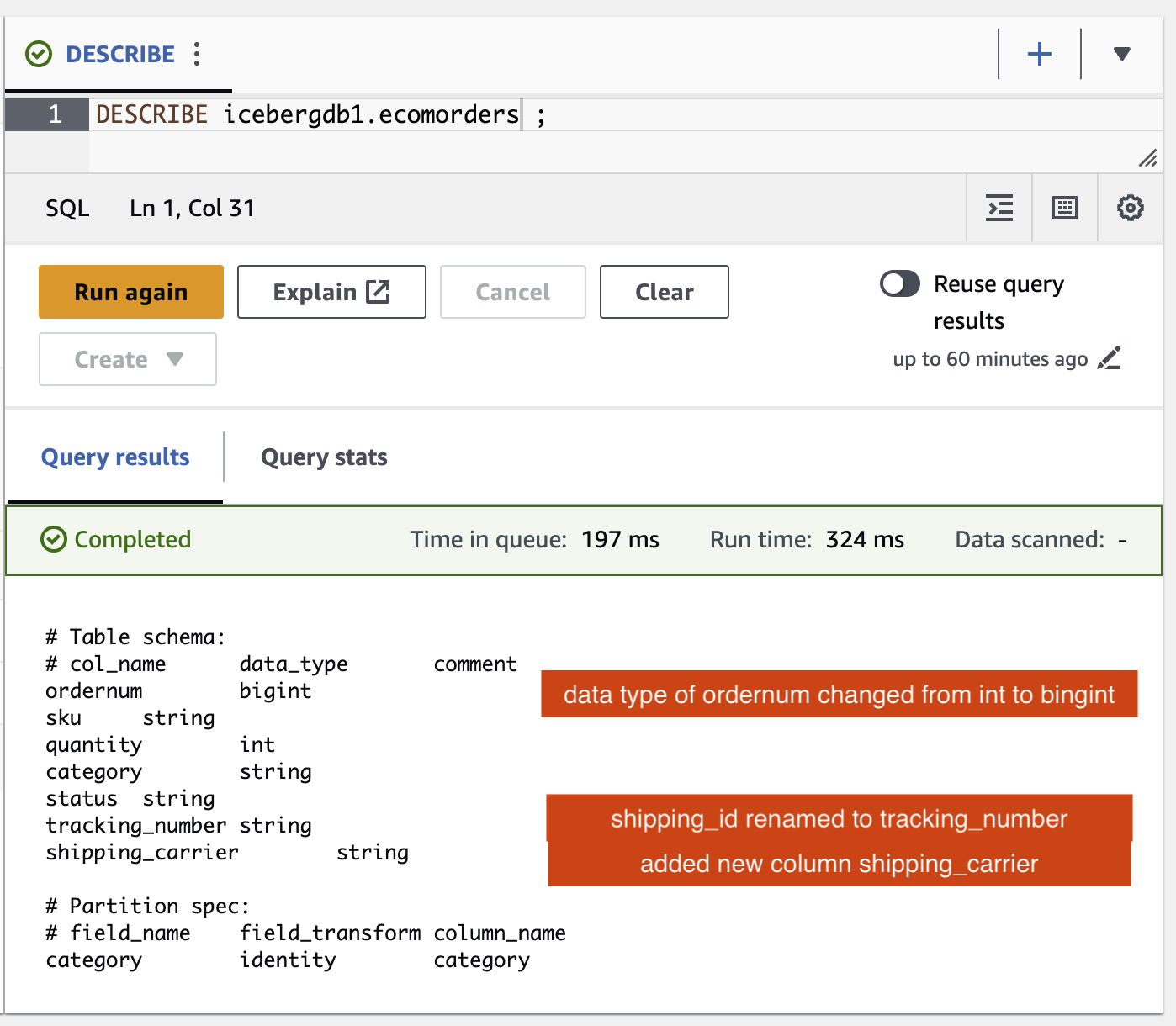
Atualização posicional
Os dados em tracking_number contém a transportadora concatenada com o número de rastreamento. Vamos supor que queremos dividir esses dados para manter a transportadora no shipping_carrier campo e o número de rastreamento no tracking_number campo.
No console do AWS Glue, execute o trabalho ETL icebergdemo1-GlueETL4-update-table. O trabalho executa a seguinte instrução SparkSQL para atualizar a tabela:
Consulte a tabela Iceberg para verificar os dados atualizados sobre tracking_number e shipping_carrier.
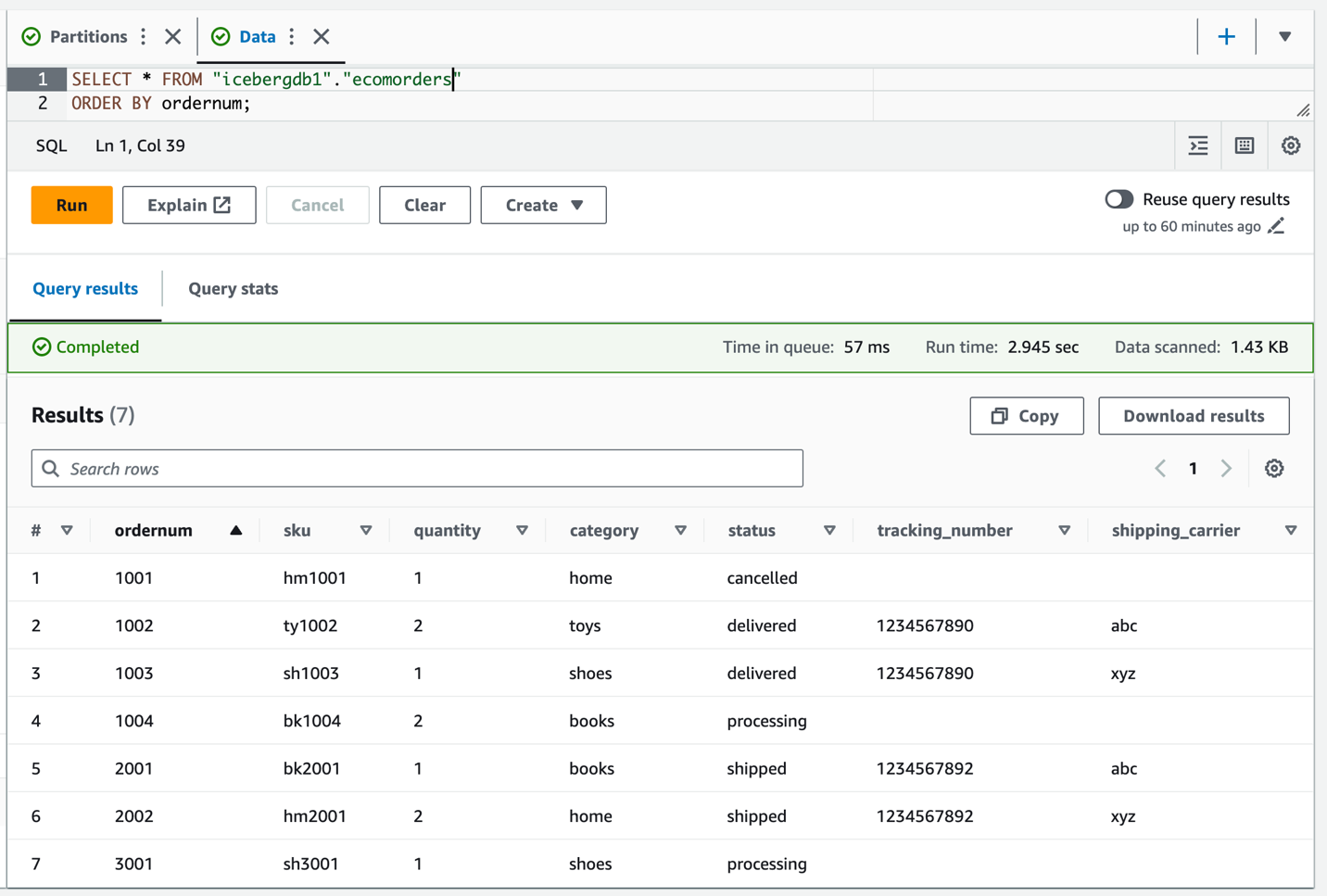
Agora que os dados foram atualizados na tabela, você deverá ver os valores de partição preenchidos para categoria:

limpar
Para evitar cobranças futuras, limpe os recursos que você criou:
- No console do Lambda, abra a página de detalhes da função
icebergdemo1-Lambda-Create-Iceberg-and-Grant-access. - No Variáveis ambientais seção, escolha a chave
Task_To_Performe atualize o valor paraCLEANUP. - Execute a função, que elimina o banco de dados, a tabela e suas tags LF associadas.
- No console do AWS CloudFormation, exclua a pilha icebergdemo1.
Conclusão
Nesta postagem, você criou uma tabela Iceberg usando a API AWS Glue e usou o Lake Formation para controlar o acesso à tabela Iceberg em um data lake transacional. Com os trabalhos de ETL do AWS Glue, você mesclou dados na tabela Iceberg e executou a evolução do esquema e da partição sem reescrever ou recriar a tabela Iceberg. Com o Athena, você consultou os dados e metadados do Iceberg.
Com base nos conceitos e demonstrações desta postagem, agora você pode construir um data lake transacional em uma empresa usando Iceberg, AWS Glue, Lake Formation e Amazon S3.
Sobre o autor
 Satya Adimula é arquiteto de dados sênior na AWS e mora em Boston. Com mais de duas décadas de experiência em dados e análises, Satya ajuda as organizações a obter insights de negócios a partir de seus dados em grande escala.
Satya Adimula é arquiteto de dados sênior na AWS e mora em Boston. Com mais de duas décadas de experiência em dados e análises, Satya ajuda as organizações a obter insights de negócios a partir de seus dados em grande escala.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/use-aws-glue-etl-to-perform-merge-partition-evolution-and-schema-evolution-on-apache-iceberg/

