Houve um enorme progresso no campo da aprendizagem profunda distribuída para grandes modelos de linguagem (LLMs), especialmente após o lançamento do ChatGPT em dezembro de 2022. Os LLMs continuam a crescer em tamanho com bilhões ou até trilhões de parâmetros, e muitas vezes não o farão. cabe em um único dispositivo acelerador, como GPU ou até mesmo em um único nó, como ml.p5.32xlarge devido a limitações de memória. Os clientes que treinam LLMs geralmente precisam distribuir sua carga de trabalho entre centenas ou até milhares de GPUs. Permitir a formação a esta escala continua a ser um desafio na formação distribuída, e a formação eficiente num sistema tão grande é outro problema igualmente importante. Nos últimos anos, a comunidade de treinamento distribuído introduziu o paralelismo 3D (paralelismo de dados, paralelismo de pipeline e paralelismo de tensor) e outras técnicas (como paralelismo de sequência e paralelismo especializado) para enfrentar esses desafios.
Em dezembro de 2023, a Amazon anunciou o lançamento do Biblioteca paralela do modelo SageMaker 2.0 (SMP), que alcança eficiência de última geração no treinamento de grandes modelos, juntamente com o Biblioteca de paralelismo de dados distribuídos SageMaker (SMDDP). Esta versão é uma atualização significativa do 1.x: SMP agora está integrado ao PyTorch de código aberto Dados totalmente fragmentados em paralelo (FSDP), que permite usar uma interface familiar ao treinar modelos grandes e é compatível com Motor Transformador (TE), desbloqueando técnicas de paralelismo de tensores junto com FSDP pela primeira vez. Para saber mais sobre o lançamento, consulte A biblioteca paralela do modelo Amazon SageMaker agora acelera as cargas de trabalho PyTorch FSDP em até 20%.
Nesta postagem, exploramos os benefícios de desempenho de Amazon Sage Maker (incluindo SMP e SMDDP) e como você pode usar a biblioteca para treinar modelos grandes com eficiência no SageMaker. Demonstramos o desempenho do SageMaker com benchmarks em clusters ml.p4d.24xlarge de até 128 instâncias e precisão mista de FSDP com bfloat16 para o modelo Llama 2. Começamos com uma demonstração de eficiências de escalonamento quase linear para o SageMaker, seguida pela análise das contribuições de cada recurso para um rendimento ideal e terminamos com um treinamento eficiente com vários comprimentos de sequência de até 32,768 por meio de paralelismo de tensor.
Dimensionamento quase linear com SageMaker
Para reduzir o tempo geral de treinamento para modelos LLM, preservar o alto rendimento ao escalar para grandes clusters (milhares de GPUs) é crucial, dada a sobrecarga de comunicação entre nós. Nesta postagem, demonstramos eficiências de escalonamento robusto e quase linear (variando o número de GPUs para um tamanho total fixo de problema) em instâncias p4d que invocam SMP e SMDDP.
Nesta seção, demonstramos o desempenho de escalonamento quase linear do SMP. Aqui treinamos modelos Llama 2 de vários tamanhos (parâmetros 7B, 13B e 70B) usando um comprimento de sequência fixo de 4,096, o backend SMDDP para comunicação coletiva, habilitado para TE, um tamanho de lote global de 4 milhões, com 16 a 128 nós p4d . A tabela a seguir resume nossa configuração ideal e desempenho de treinamento (modelo TFLOPs por segundo).
| Tamanho do modelo | Número de nós | TFLOP* | sdp* | tp* | desembarcar* | Eficiência de dimensionamento |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*No tamanho do modelo, comprimento de sequência e número de nós fornecidos, mostramos o rendimento e as configurações globalmente ideais após explorar várias combinações de sdp, tp e descarregamento de ativação.
A tabela anterior resume os números de rendimento ideais sujeitos ao grau de paralelo de dados fragmentados (sdp) (normalmente usando fragmentação híbrida FSDP em vez de fragmentação completa, com mais detalhes na próxima seção), grau de paralelo de tensor (tp) e alterações de valor de descarregamento de ativação, demonstrando uma escala quase linear para SMP junto com SMDDP. Por exemplo, dado o tamanho 2B do modelo Llama 7 e o comprimento de sequência 4,096, no geral ele atinge eficiências de escalonamento de 97.0%, 91.6% e 84.1% (em relação a 16 nós) em 32, 64 e 128 nós, respectivamente. As eficiências de escala são estáveis em diferentes tamanhos de modelo e aumentam ligeiramente à medida que o tamanho do modelo aumenta.
SMP e SMDDP também demonstram eficiências de escala semelhantes para outros comprimentos de sequência, como 2,048 e 8,192.
Desempenho da biblioteca paralela do modelo SageMaker 2.0: Llama 2 70B
Os tamanhos dos modelos continuaram a crescer nos últimos anos, juntamente com atualizações frequentes de desempenho de última geração na comunidade LLM. Nesta seção, ilustramos o desempenho no SageMaker para o modelo Llama 2 usando um tamanho de modelo fixo de 70B, comprimento de sequência de 4,096 e um tamanho de lote global de 4 milhões. Para comparar com a configuração e a taxa de transferência globalmente ideais da tabela anterior (com back-end SMDDP, normalmente fragmentação híbrida FSDP e TE), a tabela a seguir se estende a outras taxas de transferência ideais (potencialmente com paralelismo de tensor) com especificações extras no back-end distribuído (NCCL e SMDDP) , estratégias de fragmentação FSDP (fragmentação completa e fragmentação híbrida) e habilitação de TE ou não (padrão).
| Tamanho do modelo | Número de nós | TFLOPS | Configuração de TFLOPs #3 | Melhoria dos TFLOPs em relação à linha de base | ||||||||
| . | . | Fragmentação completa NCCL: #0 | Fragmentação completa SMDDP: #1 | Fragmentação híbrida SMDDP: #2 | Fragmentação híbrida SMDDP com TE: #3 | sdp* | tp* | desembarcar* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*No tamanho do modelo, comprimento de sequência e número de nós fornecidos, mostramos o rendimento e a configuração globalmente ideais após explorar várias combinações de sdp, tp e descarregamento de ativação.
A versão mais recente de SMP e SMDDP oferece suporte a vários recursos, incluindo PyTorch FSDP nativo, fragmentação híbrida estendida e mais flexível, integração de mecanismo de transformador, paralelismo de tensor e operação coletiva otimizada de todos os grupos. Para entender melhor como o SageMaker alcança treinamento distribuído eficiente para LLMs, exploramos contribuições incrementais do SMDDP e do seguinte SMP recursos principais:
- Aprimoramento de SMDDP sobre NCCL com fragmentação completa de FSDP
- Substituindo a fragmentação completa do FSDP pela fragmentação híbrida, o que reduz o custo de comunicação para melhorar o rendimento
- Um aumento adicional no rendimento com TE, mesmo quando o paralelismo de tensor está desativado
- Em configurações de recursos mais baixas, o descarregamento de ativação pode permitir um treinamento que de outra forma seria inviável ou muito lento devido à alta pressão de memória
Fragmentação completa de FSDP: aprimoramento de SMDDP sobre NCCL
Conforme mostrado na tabela anterior, quando os modelos são totalmente fragmentados com FSDP, embora as taxas de transferência de NCCL (TFLOPs #0) e SMDDP (TFLOPs #1) sejam comparáveis em 32 ou 64 nós, há uma enorme melhoria de 50.4% de NCCL para SMDDP em 128 nós.
Em tamanhos de modelos menores, observamos melhorias consistentes e significativas com o SMDDP em relação ao NCCL, começando em tamanhos de cluster menores, porque o SMDDP é capaz de mitigar o gargalo de comunicação de forma eficaz.
Fragmentação híbrida FSDP para reduzir custos de comunicação
No SMP 1.0, lançamos paralelismo de dados fragmentados, uma técnica de treinamento distribuído desenvolvida internamente pela Amazon MiCS tecnologia. No SMP 2.0, introduzimos o sharding híbrido SMP, uma técnica de sharding híbrido extensível e mais flexível que permite que os modelos sejam fragmentados entre um subconjunto de GPUs, em vez de todas as GPUs de treinamento, como é o caso do sharding completo do FSDP. É útil para modelos de tamanho médio que não precisam ser fragmentados em todo o cluster para satisfazer as restrições de memória por GPU. Isso faz com que os clusters tenham mais de uma réplica de modelo e cada GPU se comunique com menos pares em tempo de execução.
A fragmentação híbrida do SMP permite a fragmentação eficiente do modelo em uma faixa mais ampla, desde o menor grau de fragmentação, sem problemas de falta de memória, até o tamanho total do cluster (o que equivale à fragmentação completa).
A figura a seguir ilustra a dependência do rendimento do sdp em tp = 1 para simplificar. Embora não seja necessariamente o mesmo valor tp ideal para fragmentação completa NCCL ou SMDDP na tabela anterior, os números são bastante próximos. Ele valida claramente o valor de mudar de fragmentação completa para fragmentação híbrida em um cluster grande de 128 nós, que é aplicável tanto a NCCL quanto a SMDDP. Para tamanhos de modelo menores, melhorias significativas com a fragmentação híbrida começam em tamanhos de cluster menores, e a diferença continua aumentando com o tamanho do cluster.
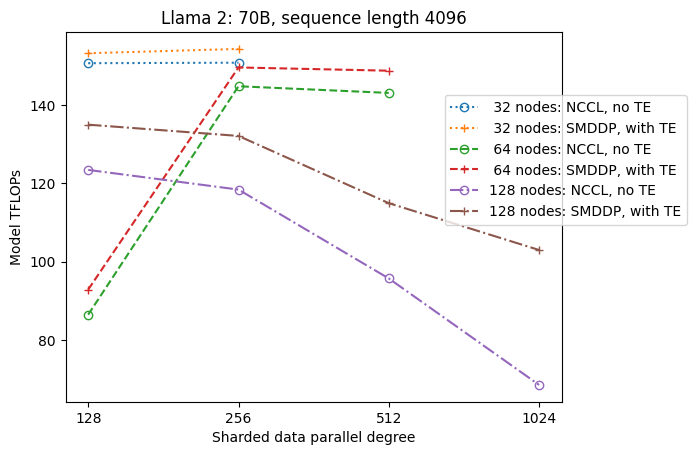
Melhorias com TE
TE foi projetado para acelerar o treinamento LLM em GPUs NVIDIA. Apesar de não usarmos FP8 porque não é compatível com instâncias p4d, ainda vemos uma aceleração significativa com TE em p4d.
Além do MiCS treinado com o back-end SMDDP, o TE introduz um aumento consistente na taxa de transferência em todos os tamanhos de cluster (a única exceção é a fragmentação completa em 128 nós), mesmo quando o paralelismo do tensor está desabilitado (o grau de paralelo do tensor é 1).
Para modelos menores ou vários comprimentos de sequência, o reforço TE é estável e não trivial, na faixa de aproximadamente 3–7.6%.
Descarregamento de ativação em configurações de poucos recursos
Em configurações de recursos baixos (dado um pequeno número de nós), o FSDP pode sofrer uma alta pressão de memória (ou até mesmo falta de memória, no pior caso) quando o ponto de verificação de ativação estiver habilitado. Para tais cenários com gargalos de memória, ativar o descarregamento de ativação é potencialmente uma opção para melhorar o desempenho.
Por exemplo, como vimos anteriormente, embora o Llama 2 no tamanho do modelo 13B e comprimento de sequência 4,096 seja capaz de treinar de forma otimizada com pelo menos 32 nós com checkpoint de ativação e sem descarregamento de ativação, ele atinge o melhor rendimento com descarregamento de ativação quando limitado a 16. nós.
Habilite o treinamento com sequências longas: paralelismo de tensor SMP
Comprimentos de sequência mais longos são desejados para conversas e contextos longos, e estão recebendo mais atenção na comunidade LLM. Portanto, relatamos vários rendimentos de sequência longa na tabela a seguir. A tabela mostra os rendimentos ideais para o treinamento do Llama 2 no SageMaker, com vários comprimentos de sequência de 2,048 a 32,768. No comprimento de sequência 32,768, o treinamento FSDP nativo é inviável com 32 nós em um tamanho de lote global de 4 milhões.
| . | . | . | TFLOPS | ||
| Tamanho do modelo | Comprimento de sequência | Número de nós | FSDP e NCCL nativos | SMP e SMDDP | Melhoria do SMP |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | NA | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | NA | 92.38 | . | |
| *: máx. | . | . | . | . | 8.3% |
| *: mediana | . | . | . | . | 5.8% |
Quando o tamanho do cluster é grande e recebe um tamanho de lote global fixo, algum treinamento de modelo pode ser inviável com PyTorch FSDP nativo, sem um pipeline integrado ou suporte para paralelismo de tensor. Na tabela anterior, dado um tamanho de lote global de 4 milhões, 32 nós e comprimento de sequência de 32,768, o tamanho efetivo do lote por GPU é 0.5 (por exemplo, tp = 2 com tamanho de lote 1), o que de outra forma seria inviável sem a introdução paralelismo tensorial.
Conclusão
Nesta postagem, demonstramos treinamento LLM eficiente com SMP e SMDDP em instâncias p4d, atribuindo contribuições a vários recursos principais, como aprimoramento de SMDDP sobre NCCL, fragmentação híbrida FSDP flexível em vez de fragmentação completa, integração TE e habilitação de paralelismo de tensor em favor de comprimentos de sequência longos. Depois de ser testado em uma ampla gama de configurações com vários modelos, tamanhos de modelo e comprimentos de sequência, ele exibe eficiências robustas de escalonamento quase linear, até 128 instâncias p4d no SageMaker. Em resumo, o SageMaker continua a ser uma ferramenta poderosa para pesquisadores e profissionais de LLM.
Para saber mais, consulte Biblioteca de paralelismo de modelo SageMaker v2ou entre em contato com a equipe do SMP em sm-model-parallel-feedback@amazon.com.
Agradecimentos
Gostaríamos de agradecer a Robert Van Dusen, Ben Snyder, Gautam Kumar e Luis Quintela pelos seus comentários construtivos e discussões.
Sobre os autores

Xinle Sheila Liu é um SDE no Amazon SageMaker. Nas horas vagas gosta de ler e praticar esportes ao ar livre.
 Suhit Kodgule é engenheiro de desenvolvimento de software do grupo AWS Artificial Intelligence e trabalha em estruturas de aprendizagem profunda. Nas horas vagas, ele gosta de fazer caminhadas, viajar e cozinhar.
Suhit Kodgule é engenheiro de desenvolvimento de software do grupo AWS Artificial Intelligence e trabalha em estruturas de aprendizagem profunda. Nas horas vagas, ele gosta de fazer caminhadas, viajar e cozinhar.
 Victor Zhu é engenheiro de software em Distributed Deep Learning na Amazon Web Services. Ele pode ser encontrado desfrutando de caminhadas e jogos de tabuleiro na área da baía de São Francisco.
Victor Zhu é engenheiro de software em Distributed Deep Learning na Amazon Web Services. Ele pode ser encontrado desfrutando de caminhadas e jogos de tabuleiro na área da baía de São Francisco.
 Derya Cavdar trabalha como engenheiro de software na AWS. Seus interesses incluem aprendizado profundo e otimização de treinamento distribuído.
Derya Cavdar trabalha como engenheiro de software na AWS. Seus interesses incluem aprendizado profundo e otimização de treinamento distribuído.
 Teng Xu é engenheiro de desenvolvimento de software no grupo de treinamento distribuído em AWS AI. Ele gosta de ler.
Teng Xu é engenheiro de desenvolvimento de software no grupo de treinamento distribuído em AWS AI. Ele gosta de ler.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

